
Sequencing of the Arabica coffee genome was published in April 2024. It was one of the latest major crop plants for which genome sequencing had not yet been published. According to Jarkko Salojärvi, who led the research, genes can now be found that will improve coffee’s yield and resistance to disease.
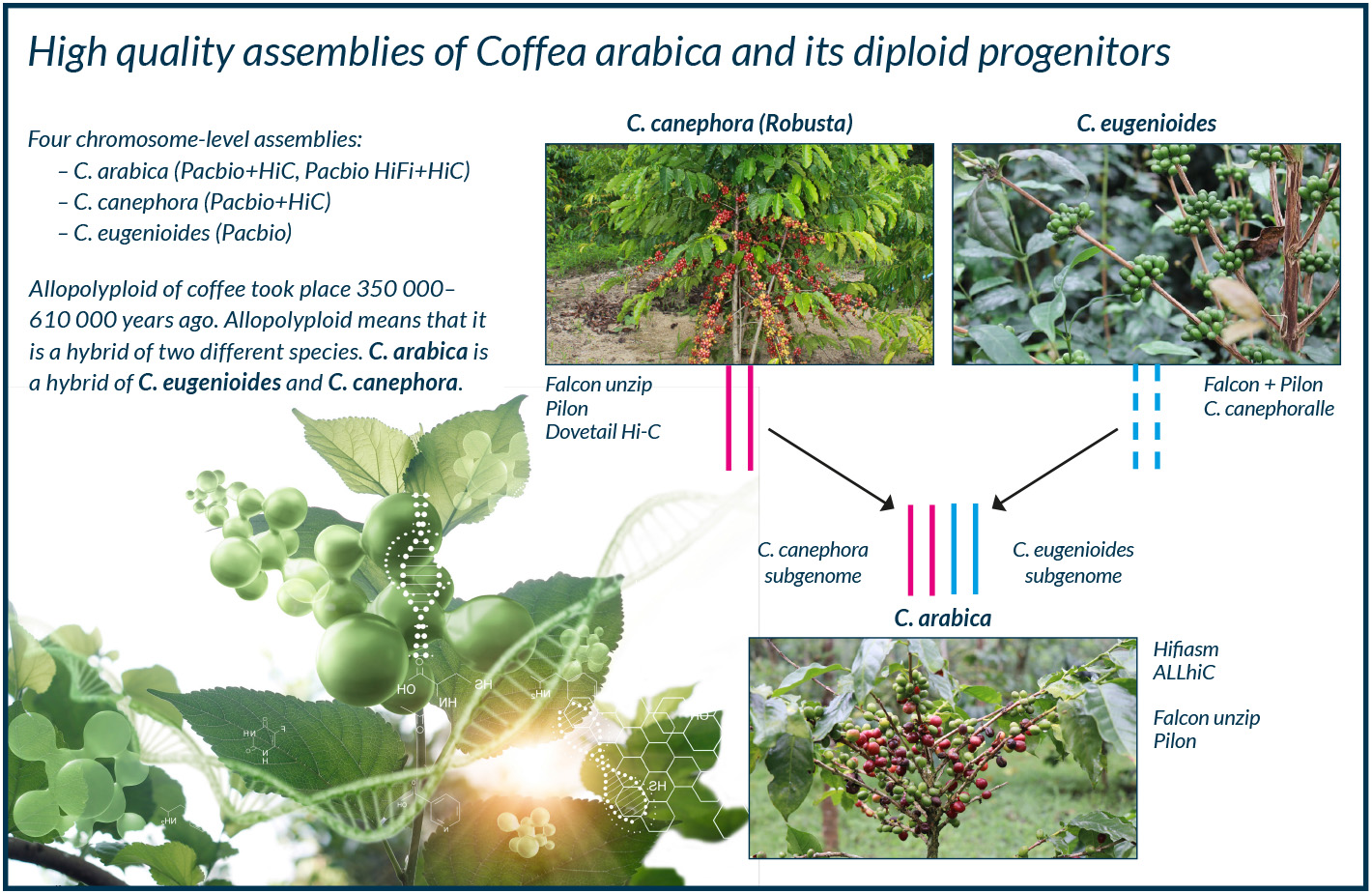
An international research consortium including researchers from the University of Helsinki and Nanyang Technological University in Singapore has compiled the genome of three coffee species from DNA sequences of coffee plant leaf cells. The genome of Arabica, or Coffea arabica, was assembled in Singapore and Helsinki, and those of Robusta (C. canephora) and C. eugenioides were assemled at Cornell University in the United States.

“The aim is to find traits that improve yield and quality. Cultivated Arabica is less genetically diverse, and therefore more susceptible to disease,” says Salojärvi, an assistant professor at Nanyang Technological University.
The economic importance of coffee is huge: it is grown in 70 countries and provides a livelihood for more than 100 million people. This makes coffee one of the world’s most important commercial products. Coffee breeding has its risks, however.
“In general, the genetic diversity of crops decreases with breeding. In cultivated coffee varieties, the genes that provide disease resistance are therefore not very diverse. That is why Arabica is vulnerable to pathogens.”
Altogether 60 per cent of the world’s coffee is produced from Coffea arabica. Besides Arabica, another species used for commercial production is Coffea canephora, or Robusta, which contains more caffeine than Arabica and is more bitter. It is used in instant coffee in particular. Vietnam is the world’s largest producer of Robusta. The rare Coffea eugenioides, or Eugenioides coffee, is sweet due to its low caffeine content. It has a lower yield than Arabica and Robusta.

Salojärvi specialises in plant genomics, and has been involved in research on the genomes of avocado, birch, lychee and Darrow’s blueberry. Salojärvi holds positions both at Nanyang Technological University and the University of Helsinki. The very broad and international research team makes extensive use of computational resources and databases in both countries.
Whole genome sequencing allows both common and rare mutations to be detected across the genome. Due to the complex structure, the genome of Arabica coffee was not sequenced until 2024.
Arabica is a hybrid of Coffea eugenioides and Robusta. Since both parental species are diploid – that is, they have two sets of homologous chromosomes – Arabica is a tetraploid, with four sets. Tetraploid plants often grow faster and larger than diploids. Their genome structure is often very complex, making assembly of the genome more difficult. The assembly of the Arabica genome was further complicated by the fact that the two subgenomes, Robusta and C. eugenioides, are very similar due to their close evolutionary history. Speciation – the process of biological species formation – occurred only about 4.5 to 7.2 million years ago.
In contrast, the Arabica hybrid, native to Ethiopia, is relatively young, around 350, 000 years old. Arabica has undergone many genetic bottlenecks, whereby a significant proportion of the population is prevented from reproducing and the population is substantially reduced. Due to these bottlenecks and the recent establishment of the species the genetic diversity of Arabica is not very high. The cultivated variants have even less genetic variation than the wild Arabica. This is due to a human-made bottleneck: most of the Arabica grown in the world is descended from just two coffee plants that lived ca. 300 years ago.
Arabica seeds were smuggled out of Yemen in the early 1600s, and since then Arabica began to be cultivated in Southeast Asia and later in the Caribbean. This variety of Arabica is called Typica, and its cultivation was managed by the Dutch. In the 1700s, the French started growing Arabica on the island of Réunion in the Indian Ocean. This variant is called Bourbon, in homage to the old name of Réunion. Roughly 95% of the current Arabica cultivars are descended from either Typica or Bourbon lineages.
Climate change is already affecting coffee yields. Drought has reduced yields in Brazil, Colombia and other countries. Arabica is grown at an altitude of over 1,500 metres in the tropics. As the climate warms, it will have to be grown at even higher altitudes, which will result in a reduction in the suitable area under cultivation.
Global warming will also increase the incidence of diseases. Hemileia vastatrix, or coffee leaf rust, causes the coffee bush to shed its leaves. The disease does not survive in temperatures below 10 ºC, so warmer nights at high altitudes contribute to its spread.
According to Salojärvi, however, the resilience of coffee can be improved through genome-based breeding.
“It’s possible to develop predictive models by sequencing the parents of a population and learning to predict the phenotypes of the offspring based on their parents’ genomes. This will help in identifying markers that can be used to select the next generation of individuals that are likely to produce better yields or be more resistant to pathogens. This is particularly important for coffee, for which the area under cultivation could be halved in the next 30 years or so due to climate change.”
Sequencing can be used to search the genomes of coffee species for genomic regions that are resistant to heat and disease. Robusta is known to be more resistant to hot weather than Arabica. It is also resistant to diseases such as coffee leaf rust. A hybrid between Robusta and Typica Arabica (Hibrido de Timor), found on the island of Timor in the 1930s, is particularly hardy.
According to Salojärvi, the regions found in its genome may enable genome-based breeding of Arabica.
“The genes from the Timor hybrid are only candidate genes, though. The next step is to examine whether the link is actually causal. It will probably take between five to ten years to test it, at which point that information can be used for breeding.”
The research will focus on the function of these candidate genes during onset of the disease.
“For example, it could be that those genes do get activated with the onset of coffee rust, but they may be such a late response that they are of no further use in preventing it,” Salojärvi points out.
“The next step would be to silence those genes and see if the resistance goes away. Or they could be transferred to a variety that is susceptible to coffee rust and see if it can build up resistance. Neither version can be used for coffee production because they would be transgenic individuals, but they can be used to ensure that the genes are the correct ones. Breeding can then focus on offspring with that resistance region.”
Establishing a chromosome-level assembly required also the determination of the three-dimensional structure of the chromosomes. The computing resources of the CSC– IT Center for Science, the Finnish ELIXIR Node, were used for this task. In the process the contiguous coffee genome sequences assembled in earlier steps were combined into chromosome-length scaffolds.
“This process means that a chromosome is made up of fully sequenced fragments and empty spaces in between. Among other things, the structural analysis will reveal the connection with genes and the regions of the genome that regulate them.”

After studying the coffee genome, Salojärvi will next study the genomes of rainforest plants. The Bukit Timah Nature Reserve in Singapore, which spans 163 hectares, is home to over 800 flowering plant species. In a project underway at Nanyang Technological University in his group is studying the rainforest biodiversity through sequencing the genomes of all the flowering plant species in the area. The focus now is on charting the gene content in a rainforest and to look for novel biosynthetic pathways, where plants use enzymes to make complex compounds from simple compounds.
“It’s particularly interesting to study what variations to the main biosynthetic pathways the different plant species have.”
Plant metabolites are important targets for research, for example to find new pharmaceuticals. According to Salojärvi, machine learning will revolutionise the study of drugs and metabolites.
“For instance, Alphafold 3, Google’s new AI software, can predict protein structures and different modifications to metabolites from the plant genome. Once the genome has been sequenced, this research will move forward rapidly thanks to artificial intelligence.”

All three coffee genomes have been shared via EBI/NCBI. Additionally, these annotations have been made accessible via ORCAE, a database with tools to further work on the gene structures, and containing annotations of diverse eukaryote genomes. It is operated by the Belgian ELIXIR Node.
The Belgian Node supports Plant and Biodiversity research. It provides resources for genomics and management of phenotyping data. Bioinformatics groups from VIB/UGent, who also participated in the coffee research, have developed tools for curation of annotations of genomes (ORCAE) and comparative genomics (PLAZA). ORCAE is an online genome curation and browsing portal for eukaryotic species, whereas PLAZA is an access point for plant comparative genomics, centralizing genomic data.
“Any publicly funded project has to release generated raw data to the scientific communities. Each system offers interfaces and procedures to help uploading the raw read data with their associated metadata”, says Principal Scientist Stephane Rombauts from VIB-UGent Center for Plant Systems Biology.
“We are developing better, newer interfaces to make the whole submission process easier”
Belgium ELIXIR node has also been developing tools to facilitate submission to ENA. The European Nucleotide Archive (ENA) is a fully open repository for storing raw sequencing data, assemblies, and annotation data.
The ENA Data Submission Toolbox simplifies the submission of sequence data by offering a single-step submission process, a graphical user interface, tabular-formatted metadata and client-side validation.
“The interfaces only offer a way to upload the data, while if serving as a backup, it would be an incentive to upload data sooner”, says Rombauts.
“Once uploaded the data has to be validated by experts before added to the system and it obtains its unique accession number only at the end. The process can sometimes be slow as sequencing gets cheaper and easier, while human experts still need to validate the ever increasing uploads.”
“Also, genomic data increasingly comes as long reads, or as raw, more rich, data in much larger quantities than before, making these interfaces sometimes inappropriate for the very latest types of data, or for the newest applications.”
Ari Turunen
22.7.2024
Read article in PDF
Citation
Turunen, A., & Nyrönen, T. (2024). Mapping the coffee genome to improve disease resistance. https://doi.org/10.5281/zenodo.13691962
More information:
The genome and population genomics of allopolyploid Coffea arabica reveal the diversification history of modern coffee cultivars.Nature Genetics, 56, 721-731 (2024).
https://doi.org/10.1038/s41588-024-01695-w
CSC – IT Center for Science
is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centra- lised IT infrastructure.
https://research.csc.fi/cloud-computing
ELIXIR
builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 Euro- pean countries and the EMBL European Molecular Biology Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish centre within this infrastructure.


 ELIXIR is partly funded by the European Commission
ELIXIR is partly funded by the European Commission