
Arabica-kahvin genomi julkaistiin huhtikuussa 2024. Se oli yksi viimeisistä merkittävistä viljelykasveista, jonka perimän sekvensointia ei ollut vielä julkaistu. Tutkimusta johtaneen Jarkko Salojärven mukaan nyt voidaan löytää geenejä, jotka parantavat kahvin satoisuutta ja kestävyyttä tauteja vastaan.
Kansainvälinen tutkimuskonsortio, jossa oli mukana muun muassa Helsingin yliopiston ja Singaporen Nanyangin teknillisen yliopiston tutkijoita, on koostanut kolmen kahvilajin perimän kahvipensaan lehtisolujen DNA:n sekvenssipätkistä. Arabican (Coffea arabica) genomi koostettiin Singaporessa ja Helsingissä, ja robustan (C.canephora) sekä C. eugenioides-lajikkeen perimä Cornellin yliopistossa Yhdysvalloissa.

”Tarkoituksena on löytää satoisuutta ja laatua parantavia ominaisuuksia. Viljelty arabica on geneettisesti vähemmän moninainen ja altistuu siksi taudeille helposti”, sanoo apulaisprofessori Jarkko Salojärvi.
Kahvin taloudellinen merkitys on valtava. Sitä viljellään 70:ssä eri maassa ja yli 100 miljoonaa ihmistä saa siitä elantonsa. Kahvi onkin yksi maailman tärkeimmistä kaupallisista tuotteista. Kahvin jalostuksessa on kuitenkin riskinsä.
”Yleensäkin viljelykasvien geneettinen moninaisuus on jalostuksen myötä vähentynyt. Tautien vastustuskyvystä vastaavat geenit eivät siis ole viljellyissä kahvilajikkeissa kovin monimuotoisia. Siksi arabica on patogeeneille altis.”
Kaiken kaikkiaan 60% maailman kahvista on arabicaa (Coffea arabica). Arabican lisäksi kaupallisesti viljelty lajike on robusta (Coffea canephora), joka sisältää arabicaa enemmän kofeiinia ja on kitkerämpää. Sitä käytetään etenkin pikakahveissa. Vietnam on maailman suurin robustan tuottaja. Harvinainen Coffea eugenioides on makeaa, koska sen kofeiinipitoisuus on pieni. Sen satoisuus on heikompaa kuin arabican ja robustan.

Salojärvi on erikoistunut kasvien genomien selvittämiseen. Hän on ollut mukana tutkimassa avokadon, koivun, litsin ja Darrowin mustikan perimää. Salojärvi työskentelee Nanyangin teknillisessä yliopistossa Singaporessa sekä Helsingin yliopistossa. Hyvin laaja-alainen ja kansainvälinen tutkimusryhmä käyttää paljon laskennallisia resursseja ja tietokantoja molemmissa maissa.
Koko genomin sekvensointi mahdollistaa sekä yleisten että harvinaisten mutaatioiden paljastamisen koko genomissa. Arabican genomi sekvensointiin vasta vuonna 2024 johtuen sen perimän monimutkaista rakenteesta.
Arabica on Coffea eugenioidesin ja robustan risteymä. Koska kumpikin lajikkeista on diploidi, niin arabicassa kromosomeja on nelinkertainen määrä eli se on tetraploidi. Tällaiset kasvit kasvavat usein nopeammin ja suuremmiksi kuin diploidit. Niiden genomin rakenne on usein erittäin monimutkainen ja luo haasteita sen kokoamiselle. Arabican genomin kokoamista vaikeutti se, että kaksi alagenomia (C.canephora) ja C. eugenioides) ovat hyvin samankaltaisia johtuen niiden läheisestä evoluutiohistoriasta, niiden lajiutuminen tapahtui vain noin 4.5-7.2 miljoonaa vuotta sitten.
Näihin verrattuna arabica-risteymän villi, Etiopiasta kotoisin oleva versio on verrattain nuori, noin 350 000 vuotta vanha. Arabica on käynyt läpi monia ns. geneettisiä pullonkauloja, jolloin huomattava osuus populaatiosta estyy lisääntymästä ja populaatio supistuu oleellisesti. Siksi arabican geneettinen moninaisuus ei ole kovin suuri. Sen viljellyssä versiossa on villeihin versioihin verrattuna vielä vähemmän geneettistä variaatiota. Tämä johtuu ihmisen aikaansaamasta pullonkaulasta: suurin osa maailmassa viljellystä arabicasta periytyy oikeastaan vain kahdesta, noin 300 vuotta sitten eläneestä kasvista.
1600-luvun alussa arabican siemeniä salakuljetettiin Jemenin ulkopuolelle ja arabicaa ryhdyttiin viljelemään Kaakkois-Aasiassa ja myöhemmin Karibialla. Tätä arabican muunnosta kutsutaan nimellä typica ja sen viljelyä hallinnoivat alankomaalaiset. 1700-luvulla ranskalaiset aloittivat arabican viljelyn Intian valtameren Reunionin saarella. Tätä muunnosta kutsutaan Reunionin vanhan nimen mukaan nimellä bourbon. Nykyiset viljellyt arabica-pensaat periytyvät siis joko typicasta tai bourbonista.

Ilmastonmuutos vaikuttaa jo nyt kahvin satoisuuteen. Kuivuus on pienentänyt satoja esimerkiksi Brasiliassa ja Kolumbiassa. Arabicaa viljellään yli 1500 metrin korkeudessa tropiikissa. Kun ilmasto lämpenee, sitä on viljeltävä entistä korkeammalla, jolloin viljelyala pienenee.
Ilmaston lämpeneminen lisää myös sairauksia. Kahviruoste (Hemileia vastatrix) saa kahvipensaan pudottamaan lehtensä. Tauti ei selviä alle 10 asteen lämpötiloissa, joten vuoriston öiden lämpeneminen edistää taudin leviämistä.
Jarkko Salojärven mukaan kahvin kestävyyttä voidaan kuitenkin parantaa genomiin perustuvan jalostuksen avulla.
”Voidaan tehdä ennustettavia malleja sekvensoimalla jonkun populaation vanhemmat ja katsomalla, kuinka hyvin voidaan vanhempien genomien perusteella ennustaa ilmiasua jälkeläisille. Sen perusteella pystytään löytämään markkereita, joiden perusteella voidaan valita seuraavan sukupolven yksilöitä, jotka todennäköisesti tuottavat parempaa satoa tai ovat resistenttejä patogeeneille. Tällaistahan tarvitaan erityisesti kahville, jonka viljelypinta-ala voi puolittua ilmastonmuutoksen takia jo noin 30 vuoden sisällä. ”
Sekvensoinnin avulla voidaan etsiä kahvilajien genomeista geenialueita, jotka ovat lämmönkestäviä ja vastustuskykyisiä taudeille. Tiedetään, että robusta kestää kuumaa säätä paremmin kuin arabica. Se on myös vastustuskykyinen tauteja, kuten kahviruostetta, vastaan. Erityisen kestävä on Timorin saarelta 1930-luvulla löydetty robustan ja typica-arabican hybridi (Hibrido de Timor).
Salojärven mukaan sen genomista löydetyt alueet voivat mahdollistaa genomiin perustuvan arabican jalostuksen.
”Timorilaisesta hybridistä saadut geenit ovat tosin vasta kandidaattigeenejä. Seuraavaksi pitää tutkia onko yhteys oikeasti kausaalinen. Sen testaamiseen menee varmaan n. 5-10 vuotta, jolloin tuota tietoa voidaan käyttää jalostuksessa.”
Tutkimus kohdistuu näiden kandidaattigeenien toimintaan taudin iskiessä.
”Esimerkiksi voi olla, että nuo geenit kyllä aktivoituvat kahviruosteen hyökätessä, mutta ne voivat olla sen verran myöhäistä vastetta, että niistä ei ole sen estämiselle enää mitään hyötyä,” Salojärvi huomauttaa.
”Seuraavaksi pitäisi hiljentää nuo geenit ja selvittää, poistuuko resistenssi. Tai sitten siirtää ne kahviruosteelle alttiiseen lajikkeeseen ja katsoa, saadaanko sillä resistenssiä aikaiseksi. Kumpaakaan versiota ei voi käyttää kahvintuotantoon, koska ne olisivat siirtogeenisiä yksilöitä, mutta niillä saadaan varmistettua, että kyseessä ovat oikeat geenit. Jalostamisessa voidaan sitten keskittyä jälkeläisiin, joilla tuo resistenssialue on olemassa.”
Kahvin perimän kromosomi -tason määrittäminen vaati myös kromosomien kolmiulotteisen rakenteen selvittämistä. Suomen ELIXIR-keskuksen CSC:n laskentaresursseja käytettiin tähän tehtävään. Prosessissa kahvin yhtenäiset perimäjaksot yhdisteltiin rakennetta hyväksi käyttämällä kromosomin pituisiksi tikastuksiksi (scaffolding).
”Se tarkoittaa, että kromosomi koostetaan täysin sekvensoiduista paloista sekä tyhjistä palikoista niiden välillä. Rakenteen selvitys paljastaa muun muassa yhteyden geenien ja niitä säätelevien perimän alueiden kanssa.”

Kahvin genomin selvittämisen jälkeen Jarkko Salojärvi tutkii seuraavaksi sademetsän kasvien genomeja. Singaporen Bukit Timahin 163 hehtaarin luonnonsuojelualueella kasvaa yli 800 erilaista koppisiemenistä kasvilajia. Nanyangin teknillisen yliopiston hankkeessa hänen ryhmässään tutkitaan sademetsän biodiversiteettiä sekvensoimalla kaikki alueen kasvilajit. Painopiste on sademetsän geenien koostumuksessa. Samalla katsotaan ennen näkemättömiä biosynteesireittejä, joissa kasvit valmistavat yksinkertaisista yhdisteistä entsyymien avulla monimutkaisia yhdisteitä.
”Erityisen kiinnostavaa on tutkia, millaisia erilaisia muunnoksia eri kasvilajeilla on pääasiallisiin biosynteesireitteihin.”
Kasvien aineenvaihduntatuotteet, metaboliitit, ovat tärkeitä tutkimuskohteita esimerkiksi uusien lääkeaineiden löytämiselle. Salojärven mukaan koneoppiminen mullistaa lääkeaineiden ja metaboliittien tutkimisen.
”Esimerkiksi Googlen tekoälyohjelma Alphafold 3 pystyy ennustamaan kasvin genomista proteiinirakenteet ja erilaisia modifikaatioita metaboliiteille. Kun genomi on selvitetty, niin tämä tutkimus lähtee vauhdilla tekoälyn ansiosta eteenpäin.”

Kaikki kolme kahvin genomia on jaettu EBI/NCBI-tietokantoihin. Näiden lisäksi annotaatiotietoihin pääsee ORCAE-tietokannan kautta. ORCAE tarjoaa työkaluja geenien rakenteiden tutkimiseen ja sisältää annotaatioita eri aitotumaisten genomeista. Sitä operoi Belgian ELIXIR-keskus.
Belgian ELIXIR tukee kasvien ja biodiversiteetin tutkimusta. Se tarjoaa resursseja genomiikkaan ja fenotyyppidatan hallinnointiin. VIB-UGent -yliopiston bioinformatiikan ryhmät, jotka myös osallistuivat kahvitutkimukseen, ovat kehittäneet työkaluja genomien annotaatioiden kuratoimiseksi (ORCAE) sekä vertailevaan genomiikkaan (PLAZA). ORCAE on verkossa toimiva portaali aitotumaisten genomien kuvailutietojen selailuun, kun taas PLAZA on liityntäpiste vertailevan genomiikan ja genomisen datan keskittämiselle.
“Kaikki julkisesti rahoitettu projektidata pitää julkaista generoituna raakadatana tiedeyhteisöille. Kukin tallennusjärjestelmä tarjoaa käyttöliittymät ja toimintaohjeet auttamaan raakadatan ja siihen liittyvät metadatan tallentamisessa”, sanoo johtava tutkija Stephane Rombauts (VIB-UGent Center for Plant Systems Biology).
”Olemme kehittämässä parempia ja uudempia käyttöliittymiä jotta saisimme koko toimitusprosessin helpommaksi.”
Belgian ELIXIR-keskus on ollut kehittämässä työkaluja myös helpottamaan toimittamista Euroopan nukleotidiarkistoon (European Nucleotide Archive, ENA). ENA on täysin avoin arkisto raa’an sekvenssi, koonti- ja annotaatiodatan tallentamiseen.
ENA Data Submission Toolbox-työkalu yksinkertaistaa sekvenssidatan toimittamisen tarjoamalla yksivaiheisen toimitusprosessin, graafisen käyttöliittymän, taulukkomuotoillun metadatan ja asiakaspuolen todentamisen.
”Käyttöliittymät tarjoavat vain väylän datan lataamiselle, mutta jos ne toimisivat myös varmuuskopiona, se olisi kannuste ladata dataa nopeammin,” Rombauts sanoo.
“Asiantuntijoiden pitää validioida kertaalleen ladattu data, ennen kuin se liitetään järjestelmään ja vasta sitten lopuksi se saa ainutkertaisen käyttönumeronsa. Prosessi voi olla toisinaan hidas koska sekvensointi tulee halvemmaksi ja helpommaksi ja samaan aikaan asiantuntijoiden silti pitää validoida alati kasvavia latauksia.”
”Lisäksi genomista dataa saadaan kasvavassa määrin long-read-muodossa, tai raakana, rikkaampana, aiempaa suurempina määrinä tehden nämä käyttöliittymät toisinaan sopimattomiksi viimeisille datatyypeille tai uusimmille sovelluksille.”
Ari Turunen
22.7.2024
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). Mapping the coffee genome to improve disease resistance. https://doi.org/10.5281/zenodo.13691962
The genome and population genomics of allopolyploid Coffea arabica reveal the diversification history of modern coffee cultivars.
Nature Genetics, 56, 721-731 (2024).
https://doi.org/10.1038/s41588-024-01695-w
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

CSC oli mukana johtamassa eurooppalaista B1MG-projektia (Beyond One Million Genomes), joka keskittyi luomaan genomidatan käytölle turvallisen rajat ylittävään federoituun infrastruktuurin. Nyt hanketta seuraa genomidatan infrastruktuuri GDI, joka mahdollistaa tutkijoiden pääsyn eurooppalaiseen genomidataan ja kliiniseen dataan.
Tavoitteena on parantaa diagnostiikkaa ja farmakogenomiikkaa eli toisin sanoen perintötekijöiden yksilöerojen vaikutusta lääkevasteeseen. Toinen tavoite on tukea tutkimuksessa käytettävän datan toisiokäyttöä. Arvokasta dataa kerätään potilasaineiston perusteella syövistä, harvinaisista ja polygeenisistä (monitekijäisistä) sairauksista. Aineistoa on saatu myös sairautta aiheuttavista patogeeneistä sekä infektiotaudeista, kuten esimerkiksi COVID-19-viruksesta.
Tämä data voi luoda pohjan yksilöllisille lääkehoidoille, jossa hyödynnetään polygeenistä riskiarvioita. Geneettinen riski lasketaan henkilökohtaisen polygeenisen riskisumman (polygenic risk score, PRS) avulla, jossa on otettu huomioon miljoonia geneettisiä variaatioita.

Kolmivuotinen B1MG-projekti päättyi lokakuussa 2023. B1MG-hankkeessa Suomen ELIXIR-keskus CSC johti teknistä infrastruktuurityötä.
”B1MG oli koordinaatio- ja tukihanke, jonka tehtäväksi annettiin tiekartan ja parhaiden käytäntöjen määrittäminen vaadittavan infrastruktuurin käyttöönottamiseksi ja 1+Million Genomes -aloitteen tavoitteen tukemiseksi. CSC yhtenä teknisen infrastruktuurin työpaketin johtajana pystyi viemään sellaiset päätökset tiekarttaan, joilla varmistettiin, että ne olivat linjassa CSC:n nykyisen ja tulevien edellytysten, kuten sensitiivisen datan palvelujen, kanssa”, sanoo vanhempi koordinaattori tohtori Dylan Spalding CSC:stä.
Spalding työskenteli B1MG-projektissa yhden työpaketin toisena johtajana. Työpaketti keskittyi yksilölliseen lääkehoitoon.
”B1MG:n todellinen hyöty on siinä, että se on asetellut suunnan GDI-projektille, joka laittaa täytäntöön Euroopan laajuisen federoidun infrastruktuurin tukemaan rajat ylittävän pääsyn yli miljoonaan genomiin. Tässä on potentiaalia auttamaan tutkimuksen demokratisoitumista ja edistämään yksilöllistä lääkehoitoa EU:ssa.”
CSC:llä yhtenä infrastruktuuri-pilarin vetäjistä on johtava rooli tässä työssä. Myös Life Science AAI (Authentication and Authorization Infrastructure) ja REMS (Resource Entitlement Management System ) ovat sovelluksia, jotka ovat jo käytössä tukemassa dataan pääsemisen hallinnassa. Spaldingin mukaan tämän pitäisi olla hyvin linjassa jo olemassa olevan federoidun EGA-solmupisteen ja sensitiivisen datan palveluiden kanssa. Federoitu EGA (European Genome-phenome Archive) on hajautettu ratkaisu ihmisistä kerätyn omiikka-datan jakamiseen ja vaihtamiseen yli valtion rajojen.
”GDI on erittäin tärkeä harvinaisten sairauksien tutkimiselle ja yksilölliselle lääkehoidolle, mutta myös syövän, tartuntatautien ja yleisten ja monimutkaisten tautien tutkimiselle. Silti, infrastruktuuri ei ole erikoistunut millekään tietylle taudille vaan tukee kaikkien tautityyppien tutkimista, Kehitystä sysää eteenpäin 1+ Million Genomes -projektin käyttötapaukset, kuten myös Genome of Europe-hanke, jonka tavoitteena on rakentaa 500 000 kansalaisen viitekohortit Euroopassa.
Spaldingin mukaan B1MG näytti toteen konseptitodistetun version Starter Kit -palvelusta, joka liittyy harvinaisten sairauksien ja syövän käyttötapauksiin. Starter Kit on kokoelma ohjelmistoja, jotka 20 GDI:n solmua ovat kehittäneet.
GDI:n rakentamisen pohjaksi on luotu Starter Kit. B1MG määritteli viisi toiminnallisuutta joita tarvitsee tukea – datan vastaanottaminen, datan etsiminen, dataan pääsyn hallinta, tallentaminen sekä käyttöliittymät ja käsittely.

Starter Kit sisältää yli 2500 synteettistä genomia ja fenotyyppistä dataa syövästä ja harvinaisista sairauksista. Se on ensimmäinen askel kohti tuotanto-infrastruktuuria.
”Starter Kit mahdollistaa pääsyn sensitiivisen genomiikka-dataan ja fenotyyppisen dataan sekö datan etsimisen ja analyysin. Valikoima synteettistä dataa sisältyy siihen jolloin voidaan havainnollistaa näitä toiminnallisuuksia ilman riskiä siitä, että oikeaa genomiikka-dataa ja fenotyyppistä dataa vuotaisi muualle.”
Kehittynyt versio Starter Kit-palvelusta integroidaan GDI:n portaaliin.

Spalding uskoo, että GDI:n valtava datamäärä mahdollistaa yksilölliset hoidot entistä paremmin
”GDI:llä on potentiaalia tukea koneoppimista ja tekoäly-menetelmiä nopeuttaen siirtymistä yksilölliseen lääkehoitoon.”
Professori Arto Mannermaan ryhmässä Itä-Suomen yliopistossa kehitetään genomidatan ja kliinisen datan perusteella oppivia algoritmeja, jotka tunnistavat ja ennustavat rintasyövän riskitekijöitä. Genomidata ja kliininen data yhdistetään tekoälymalliksi, joka auttaa paitsi sairastumisriskin määrittämisessä, myös yksilöllisten hoitosuunnitelmien tekemisessä.
Mannermaan ryhmässä luodaan tekoälymalleja kuvadatasta. Mitä muuta dataa pitäisi yhdistää kuvadataan, jotta parannettaisiin terveydenhoitoa?
”Olemme liittäneet kuvantamisdataan nyt genomitietoa. Mitä enemmän data-modaliteetteja voidaan yhdistää, sitä paremmin pystymme tunnistamaan menestyksekkääseen syövän hoitoon liittyvät tekijät sekä todennäköisesti tunnistamaan tautiriskiin vaikuttavat tekijät.”
Tautiriskiin vaikuttavia tekijöitä ovat esimerkiksi tiedot hoitovasteesta tai muu hoitoon liittyvä kliininen tieto.
”Mitä enemmän dataa saamme käyttöömme, sitä isommaksi kasvavat laskentaympäristön vaatimukset. Liitännäisdataa voidaan saada esimerkiksi sähköisistä potilastietojärjestelmistä biopankkien kautta.”
Ari Turunen
29.4.2024
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). An infrastructure for genomic data. https://doi.org/10.5281/zenodo.13691595
Lisätietoja:
Genomic Data Infrastructure
https://gdi.onemilliongenomes.eu
Beyond One Million Genomes
https://b1mg-project.eu/1mg/genome-europe
Itä-Suomen yliopisto
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

THL yhteistyössä CSC:n kanssa on simuloinut miljoonan eurooppalaisen genomit. Simulointiin käytetty data oli aitoja julkisesti saatavissa olevia koko genomin sekvenssejä, mutta simuloinnissa niistä muodostettiin synteettisiä genomeja, jolloin ne eivät kerro oikeista ihmisistä. Simulointi tehtiin CSC:n LUMI-supertietokoneella. Tämä on yksi suurimpia ihmispopulaation perimän simulaatiota maailmassa. Simulaatio tehtiin EU:n 1+MG-aloitetta varten.
Vuonna 2018 EU julkisti 1+Million Genomes -aloitteen (1+MG), jonka kunnianhimoisena tavoitteena oli kerätä data, joka kattaa miljoonan eurooppalaisen ihmisen perimän. Projekti oli lajissaan yksi maailman suurimpia projekteja, johon osallistui 27 maata. Eurooppalaisen genomidatan tietoturvallinen käyttö mahdollistaa personoidun terveydenhoidon ja paremman diagnostiikan. Tämä parantaa erityisesti syöpien ja hermostollisten sairauksien hoitoennusteita.
Datakokoelma anonymisoidaan, joten yksiköllisiä ja tunnistettavia tietoja ei löydy. Tavoitteena on luoda kansalliset rajat ylittävä federoitu hallinto, jonka kautta on pääsy kansallisiin genomiarkistoihin.
”Minun näkökulmastani tämä 1+MG:n synteettisen datan projekti oli ainutlaatuinen haaste: miten imuloimme tehokkaasti populaation, jonka viimeisessä sukupolvessa on miljoona ihmistä ja joka vastaa kaikilta ominaisuuksiltaan, niin perimän, dataformaattien kuin kokonsa puolesta aitoa genomidataa, mutta on simuloituna täysin vapaasti jaettavissa ilman tietoturva-ongelmia? Loppujen lopuksi me simuloimme n. 25 miljoonan ihmisen populaation, joista vain hieman yli miljoonalle teimme synteettiset genomit. Tällainen datakokoelma mahdollistaa lukuisat erilaiset tutkimus-, harjoittelu- ja kehittämisprojektit, kuten 1+MG, ilman eettisjuridisia haasteita ja tietoturvaesteitä”, sanoo dosentti Tero Hiekkalinna THL.stä.
Nyt simuloitiin miljoonan ihmisen synteettinen aineisto kymmenine fenotyyppeineen. Mukana oli siis tietoja ympäristön aiheuttamista vaikutuksista yksilöiden fenotyyppeihin.
Miljoonan genomin simuloinnin rahoittivat Suomessa sosiaali- ja terveysministeriö sekä opetus-ja kulttuuriministeriö. Hiekkalinnan mukaan aineiston luomisessa ja hallinnassa oli valtavia haasteita.
”Aineistojen koko projektin aikana vaati kymmeniä teratavuja levytilaa.”
1+MG-aloitetta seurasi vuonna 2020 alkanut B1MG (Beyond 1 Million Genomes), joka päättyi tammikuussa 2024. B1MG-projektissa määritettiin suuntaviivat ja suositukset eri Euroopan maista saadun genomidatan federoidulle hallinnolle. Suomen ELIXIR-keskus CSC oli yksi hankkeen vetäjistä ja koordinaattoreista. Biopankkien toimintaa yritetään saada yhteensopivaksi valtakunnan rajat ylittävään datainfrastruktuuriin. B1MG-hankkeessa CSC johti teknistä infrastruktuurityötä.
THL:n ja CSC:n simuloima miljoonan genomin data laitetaan saataville eurooppalaiseen federoituun genomi-fenomi-arkistoon (FEGA). FEGA on on tarkoitettu biolääketieteellisten tietojen tallentamiseen ja jakamiseen tutkimusta varten, mutta dataa ei ole tarkoitus levittää täysin julkisesti. Suomen tietokantaa ylläpitää CSC. FEGA on yhteydessä Euroopan genomi-fenomi arkistoon (EGA). EGA on yksi maailman laajimmista julkisista datavarastoista.
Sama simuloitu data on tulevaisuudessa myös GDI-projektin käytössä. Vuonna 2022 käynnistettyä genomidatan infrastruktuuria (Genomic Data Infrastructure) koordinoi ELIXIR. GDI:n tarkoituksena on luoda lopullinen infrastruktuuri, joka mahdollistaa pääsyn eurooppalaisista kerättyyn genomidataan sekä kliiniseen dataan.
Tulevaisuudessa eurooppalaisia odottavat entistä nopeammat ja tarkemmat diagnoosit. Kerätty ja analysoitu genomidata mahdollistaa paremman lääkeainesuunnittelun ja ennaltaehkäisevät lääkehoidot. Kaikki tämä johtaa parempaan terveyteen ja elinajanodotteeseen. Tämän mahdollistamiseksi tarvitaan datan esikäsittelyä ja harmonisointia, kuten myös tietoturvallisia, skaalautuvia ja joustavia teknisiä ratkaisuja.

Nähin toisiinsa liittyvissä kolmessa hankkeessa hyödynnetään viittä käyttötapausta. Nämä käyttötapaukset ovat olennaisia lopullisen GDI-infrastruktuurin rakentamiselle. Euroopan genomi (Genome of Europe) luo viitedatakokoelman genomiikkaa hyödyntäville terveysohjelmille Euroopan maissa: kukin maa luovuttaa genomidataa suhteessa väkilukuun. Datamalli kehitetään syöpään liittyvästä kliinisestä informaatiosta ja genomiikasta saadusta metadatasta. Monigeeninen riskisumma (polygenic risk score, PRS) luodaan potilaan hoitoon liittyvää päätöksentekoa varten: yksilöllisessä riskisummassa otetaan huomioon miljoonia geneettisiä variaatioita. Harvinaisissa sairauksissa olennaista on geenivarianttien esiintyminen eri populaatioissa ja geenimutaation ja sairauden yhteyden selvittäminen. Lisäksi testataan Euroopan maiden välillä kunkin maan keräämän COVID-19-datan jakamista.
Ari Turunen
2.3.2024
Lue artikkeli PDF-muodossa
Sitaatti
Nyrönen, T., & Turunen, A. (2024). A million European genomes. https://doi.org/10.5281/zenodo.13691032
Lisätietoja:
Hiekkalinna, Tero; Heikkinen, Vilho; Perola, Markus; Terwilliger, Joseph (2023):
Simulated European Genome-phenome Dataset of 1,000,000 Individuals for 1+Million Genomes Initiative.
1+MG Framework
https://framework.onemilliongenomes.eu
Beyond 1 Million Genomes (B1MG)
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Diabetes on iso kansansairaus, mutta suuri haaste on myös tautiin liittyvät muut sairaudet. Diabeteksen liitännäissairauksia ovat mm. diabeettinen munuaistauti, diabeettinen retinopatia, sekä sepelvaltimotauti ja aivohalvaukset. Nyt Suomessa sekvensoidaan diabetes-potilaiden koko perimä ja etsitään geneettisiä riskitekijöitä.
Diabeetikoilla sydänsairauksien riski on paljon suurempi muuhun väestöön verrattuna. Kolmannes tyypin yksi eli nuoruustyypin diabeetikoista saa munuaissairauden, joka vaikuttaa suuresti kuolleisuuteen ja osaltaan myös sydänsairauksien riskiin. Retinopatia on ollut puolestaan merkittävin sokeuden aiheuttajista työikäisessä väestössä.
Suomalaisilla on maailman korkein ykköstyypin diabeteksen riski lapsilla ja nuorilla aikuisilla. Tyypin II diabetes mielletään usein enemmän länsimaiden elintasosairaudeksi, mutta suurimmat potilasmäärät löytyvät keskituloisista maista, ja yksittäisistä maista tilaston kärjessä on Kiina ja Intia.

”Diabeteksen yhteydessä puhutaan isoista ja vakavista komplikaatioista. Nämä muut sairaudet vaikuttavat vahvasti sekä diabeetikon elämänlaatuun että elinajan odotteeseen,” sanoo geneettisen epidemiologian tutkija Niina Sandholm Folkhälsan-tutkimuskeskuksesta. Sandholm työskentelee FinnDiane-tutkimusprojektissa, jonka tavoitteena on löytää diabeteksen liitännäissairauksille altistavia perinnöllisiä ja ympäristöön liittyviä riskitekijöitä. FinnDiane-tutkimus on Helsingin yliopiston, HUS:n ja Folkhälsanin tutkimuskeskuksen yhteistyöprojekti.
Sandholmin mukaan geenitiedosta on hyötyä erityisesti nuorille potilaille jo varhaisessa vaiheessa ennen kuin riskitekijät ilmenevät.
”Tällä hetkellä geenitietoa hyödynnetään klinikassa lähinnä harvinaisten sairauksien tapauksessa, mutta ryhmämme tekemät ja aiemmin tehdyt tutkimukset tukevat kattavan geenitiedon hyödyntämistä myös yleisten sairauksien varhaisessa ennaltaehkäisyssä.”

Vuonna 1997 professori Per-Henrik Groopin perustama FinnDiane on seurantatutkimus, johon osallistuu jo lähes 8000 diabetekseen sairastunutta. Potilasaineisto on saatu 80 sairaalasta ja terveyskeskuksesta eri puolilta Suomea. Se on yksi maailman laajimmista tyypin 1 diabeteksen ja sen liitännäissairauksien tutkimusaineistoista. Nyt tästä aineistosta sekvensoidaan 1700 potilaan koko perimä eli genomi.
Sandholm on aiemmin osallistunut tutkimusprojekteihin, joissa menetelmänä oli genominlaajuinen assosiaatiotutkimus (GWAS). Sitä käytetään erityisesti silloin, kun sairauden geneettinen tausta on monitekijäinen. Menetelmän avulla voidaan löytää sairastumisriskiä lisääviä tai sairaudelta suojaavia geenivariantteja. GWAS-menetelmässä osallistujien verinäytteistä mitataan geenivariantteja, joiden määrä vaihtelee sadoista tuhansista miljooniin. Potilaita on tuhansista satoihin tuhansiin.

Yli 5600 FinnDiane-potilaista tehty, toistaiseksi laajin sydänsairauksia ykköstyypin diabeetikoilla käsittelevä GWAS- tutkimus paljasti esimerkiksi uuden sydänsairauksiin liittyvän geneettisen lokuksen lähellä DEFB127-geeniä. Lokus on DNA-jakson sijaintipaikka kromosomissa. Jakson vaihtelua kutsutaan alleeliksi.
Samassa tutkimuksessa, jossa löydettiin DEFB127-geeni, löydettiin myös muita sydänsairauksille altistavia perintötekijöitä.
”Sydänsairauksille, kuten muillekin yleisille sairauksille on löydetty paljon altistavia perintötekijöitä, joista yksi vahvimmista sijaitsee geenien CDKN2A ja CDKN2B alueella. Diabeetikoilla sydänsairauksien riski on paljon suurempi kuin muussa väestössä eikä niiden perintötekijöistä tiedetä paljoa, mutta näytimme tässä tutkimuksessa, että tuo sama CDKN2A/B geenialue vaikuttaa sydänsairauksien riskiin myös ykköstyypin diabetesta sairastavilla.”
Kolmanneksella tyypin yksi diabeetikoista saa munuaistaudin. Joillekin voi kehittyä munuaisen vajaatoiminta, joka pahimmillaan voi johtaa keinomunuaishoitoon tai munuaisen siirtoon.
Toisessa tutkimuksessa analysoitiin eri datalähteitä yhdistäen 27 000 diabetekseen sairastuneen yhteyksiä munuaistautiin. GWAS on nopea ja taloudellinen menetelmä, mutta kaikkia variantteja ei sen avulla löydetä. Tätä yritetään nyt potilaan koko genomin sekvensoinnilla.
”GWAS-menetelmällä löydetyt variantit ovat useimmiten yleisiä, ja yksittäisten varianttien vaikutus sairastumisriskiin on varsin maltillinen. Sekvensoinnin tavoitteena on löytää harvinaisia variantteja, joilla voi olla yksilön kohdalla huomattavan suuri vaikutus sairauden puhkeamiselle. Pahimmillaan tällainen variantti voi estää koko proteiinin toiminnan.”
Sandholmin mukaan tutkimustulokset voivat auttaa sairastumisriskin ennakoimisessa tai viitoittaa tietä uusien lääkeaineiden kehittämiseksi.
”Laajempana tavoitteena geenitutkimuksessa on löytää sairastumisriskiin vaikuttavia tai sairauden aiheuttavia variantteja, jotta ymmärtäisimme paremmin diabeteksen liitännäissairauksien syntymekanismeja. ”
Pohjimmaisena tavoitteena on oppia ehkäisemään ja parantamaan diabeteksen liitännäissairaudet.
”Nyt luetaan koko DNA-sekvenssi kaikilta potilailta. Dataa tulee hirmuinen määrä,” Sandholm korostaa.
”DNA-dataa saadaan sekvensointilaitteesta 150 emäsparin pätkinä kerrallaan. Tavoitteena on lukea jokainen DNA:n kolmesta miljardista emäsparista keskimäärin 30 kertaa tiedon varmistamiseksi, joten näitä 150 emäsparin pätkiä tulee yli 600 000 kullekin henkilölle.”
Sekvensoidut pätkät täytyy järjestää ihmisen referenssigenomin avulla oikeaan järjestykseen, jotta koko sekvenssi saadaan selvitettyä. Tämä vaatii valtavasti laskentakapasiteettia, jota saadaan Suomen ELIXIR-keskuksesta CSC:stä.
”Tarkoitus olisi saada aineisto sellaiseen muotoon, että pystyttäisiin tietämään kulloisellakin potilaalla, mitkä emäsparien muutokset eli variantit liittyvät mihinkin sairauksiin. Tavoitteena on se, että pystytään tunnistamaan harvinaisia variantteja, joita ei löydy GWAS-menetelmällä. Harvinaisia variantteja löytyy aineistosta vain muutamalta potilaalta.”
Variantit DNA:n emäsparijaksoissa eli snipit ovat tavallaan lopputulos datan käsittelystä.
”DNA-juoste on siis muutettu snippimuotoon eli kullakin potilaalla voi olla alleeleja nolla, yksi tai kaksi varianttia. Nämä toimivat markkereina jotka selittävät mitä sairauksia variantti voi aiheuttaa.”
Tutkimusryhmä on jo saanut sekvensoitua 600 potilaan koko genomin.
”Alustavia tulosten perusteella esimerkiksi aivohalvauksille löydettiin yksittäisiä variantteja, jotka selvästi liittyvät aivohalvauksien riskiin. Muutoksia löytyy myös geeneissä, jotka on aiemmin liitetty synnynnäisiin munuaissairauksiin. Näiden ei ole ajateltu siis aiemmin liittyneen diabetekseen mutta jotka aiheuttavat erilaisia munuaisvaurioita. Nyt näyttää, että samoissa geeneissä olevat variantit myös vaikuttavat diabeettisen munuaistaudin syntyyn.”
Niina Sandholm ja hänen kollegansa tutkivat myös geenin proteiinia koodaavia osia sekä geenien säätelyalueita, jotka voivat liittyä sairauden riskitekijöihin.
”Geenien välissä oleva alue – 95% genomista – sisältää paljon säätelyalueita mikä kertoo, mikä geeni ilmentyy missäkin kudoksessa. DNA sinällään on sama ihmisen jokaisessa solussa, mutta geenien säätely aiheuttaa sen, että silmistä tulee silmät ja munuaisista munuaiset. Tässä nämä geenien säätelyalueet ja niiden muutokset ovat avainasemassa. ”
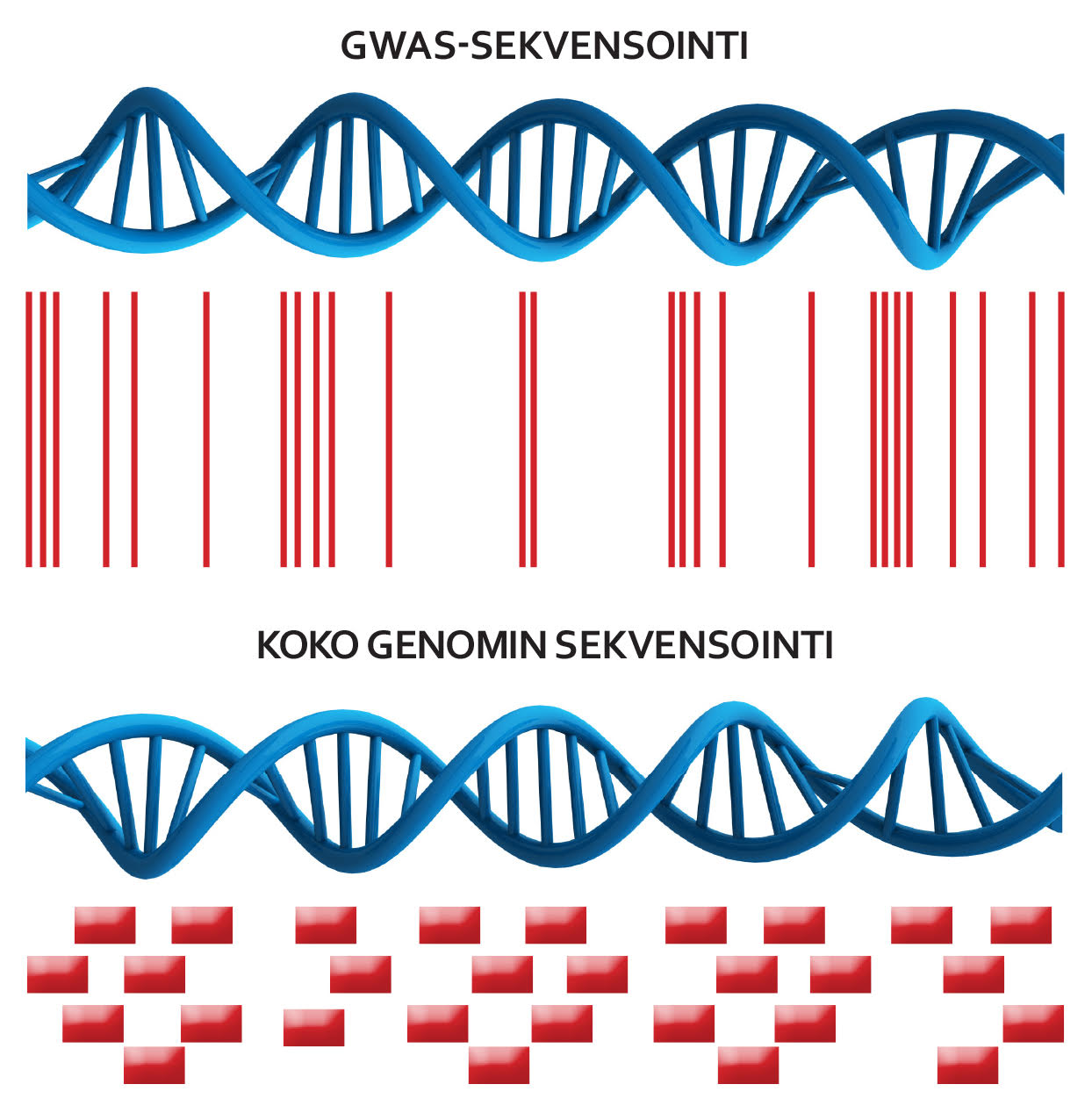
Tämä on maailmanlaajuisesti ensimmäisiä ja poikkeuksellisen laaja genomin sekvensointiprosessi. Toistaiseksi hyvin vähän on tehty koko genomin sekvensointia.
”Nyt trendinä on koko eksomin sekvensointi, jossa keskitytään proteiinia koodaavin osiin. On vain ajan kysymys milloin kuitenkin näitä koko genomin sekvensointeja aletaan tehdä lisää. Myös ELIXIR panostaa ja kehittää koko genomin käsittelymenetelmiin ja genomidatan työstämismenetelmiä.”
CSC tarjoaa ePouta-palvelua sensitiivisen datan käsittelyyn. Virtuaalipalvelimet toimivat CSC:n laskenta-alustalla korotetun tietoturvan ePouta-pilvipalvelussa. Käyttäjän tarvitsemat pilviresurssit on yksilöity ja varattu asianomaiselle käyttäjälle, eriytettynä CSC:n muusta laskentaympäristöstä. FinnDianen tutkimusryhmä käyttää Suomen molekyylilääketieteen instituutin FIMM:n laskentaklusteria, joka on yhdistetty CSC:n sensitiivisen datan laskenta-alustaan ePoutaan valopolun kautta. Valopolku mahdollistaa projektin käyttämän datan nopeamman käsittelyn, koska laskentaresurssit skaalautuvat. Tutkijoille on lisäksi allokoitu merkittävä tallennustila, jossa genomitiedot ovat.
Ari Turunen
3.2.2022
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Niina Sandholm, & Tommi Nyrönen. (2022). Finnish research team sequences the genomes of thousands of individuals with diabetes to look for genetic risk factors. https://doi.org/10.5281/zenodo.8154493
Lisätietoja
Folkhälsan
FinnDiane
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC –Tieteen tietotekniikan keskus Oy.

Bioinformatiikan menetelmien kehittyessä myös kustannukset ovat laskeneet. Eri eliöiden perimä saadaan selvill entistä nopeammin ja halvemmin. Edessä oleva urakka eri eliöiden ja ihmisten genomien sisältämän tiedon ymmärtämisessä on kuitenkin valtava. Se edellyttää eri tutkimusorganisaatioiden yhteistyötä ja hyvin järjestettyjä tietokantoja.
Ihmisen koko perimä selvitettiin vuonna 2003. Human Genome Project-hanke saatiin valmiiksi ennakoitua aiemmin internetin ansiosta. Se mahdollisti eri laboratorioiden tehokkaan yhteistyön. Ihmisen koko DNA saatiin sekventoitua. Ihmisen geenit on pakattu kolmeen miljardiin emäspariin. Nyt seuraavana on selvittää miten nämä geenit toimivat. Genomin emäsparien selvittämisen kautta aletaan ymmärtää eri sairauksien syntymekanismeja ja tehokkaita hoitomuotoja.
Nykyään tutkimus tuottaa genomitietoa varsin monipuolisesti. Tavoitteena on esimerkiksi arvioida tiedon avulla ympäristön tilaa ja terveysvaikutuksia tarkastelemalla mikrobeja, jalostaa ruokakasveja paremmin kuivuutta sietäviksi viljelykasveiksi ilmastonmuutoksen kriisien lievittämiseksi, tai kehittää lääkeaineita tauteihin, joihin ei tällä hetkellä tunneta hoitokeinoja. Näihin tarkoituksiin tarvitaan tietolähteiden uudenlaista yhdistämistä ja analysointia.

Eri eliöiden genomien selvittäminen on entistä helpompaa ja halvempaa. Nyt EBP-projektin (Earth Bio-Genome Project) tavoitteena on selvittää kaikkien aitotumaisten eliöiden eli eukaryoottien genomit. Esitumalliset arkit ja eubakteerit eli prokaryootit ovat soluja, joiden DNA muodostuu vain yhdestä kromosomista. Eukaryootteihin kuuluvat yksisoluiset alkueläimet ja kolme monisoluisten elöiden ryhmät: kasvit, sienet ja eläimet.
Bioinformatiikan avulla voidaan selvittää loput 80-90% niistä eliöistä, joiden genomia ei vielä tiedetä. Vuonna 2011 Census of Marine Life arvioi eläinlajien määräksi noin 8,7 miljoonaa, joista 6,5 miljoonaa on maaeläimiä ja 2,2 miljoonaa merieläimiä. Korkean suoritustehon sekvensointimenetelmiin perustuvan arvion mukaan sienilajeja voi olla jopa 5,1 miljoonaa. Kasvilajeja on arviolta 400 000.
Ensimmäistä kertaa ihmiskunnan historiassa on mahdollisuus tehokkaasti sekvensoida kaikkien tunnettujen aitotumaisten eliöiden genomi. EPB:n tavoitteena on sekvensoida kaikki 1,5 miljoonaa tunnettua eukaryoottia. Näytteitä kerätään ympäri maailmaa. Osa, ehkä noin puoli miljoonaa, saadaan kasvitieteellisistä puutarhoista. Loput joudutaan keräämään suoraan luonnosta. Yksi merkittävä keräyspaikka on Amazon. EPB aloitti tammikuussa 2018 yhteistyön brasiliaisen geenipankki-projektin kanssa, joka keskittyy Amazonin alueen eliöihin.
Amazonin alueella on eniten kasvi- ja eläinlajeja kuin missään muussa paikassa maailmassa. Ehkä kolmannes lajeista löytyy sieltä. Sademetsiin kätkeytyy valtavasti esimerkiksi potentiaalisia lääkeaineita.
Amazonin jararaca-kyykäärmeen myrkystä löydettiin ACE- estäjä eli angiotensiinikonvertaasi-niminen entsyymi, jonka vaikutuksesta syntyy verenpainetta alentavaa ja sydämen pumppaustyötä keventävää angiotensiiniä. 1970-luvulla tutkijat kehittivät synteettisen version käärmeen myrkystä.

Valtameret ovat maailman suurin yhtenäinen ekosysteemi. Planktonin merkitys maailman ilmastolla on vähintään yhtä merkittävä kuin sademetsien. Kuitenkin vain pieni osa niistä organismeista, jotka luovat tämän ekosysteemin, on luokiteltu ja analysoitu. Planktoneiden muodostamat ekosysteemit sisältävät valtavasti elämää: yli 10 miljardia organismia on jokaisessa litrassa valtameren vettä sisältäen viruksia, prokaryootteja, yksisoluisia eukaryootteja ja polttiaiseläimiä. Nämä ainutlaatuiset organismit sisältävät bioaktiivisia yhdisteitä, joille on käyttöä lääketeollisuudessa, elintarvikkeina, kosmetiikassa, bioenergiassa ja nanoteknologiassa. Vuosina 2009-2013 kansainvälinen tutkimusmatka Tara Oceans keräsi 210 mittauspaikasta maailman valtameristä 35 000 biologista näytettä. Se on laajin planktonista kerätty kokoelma. Ocean Sampling Day oli kampanja jossa myös kerättiin näyttetä merestä. Tutkimusasemia pyydettiin ottamaan näytteitä ja tuottamaan dataa. BioSamples kerää kuvauksia ja metadataa biologisista näytteistä, joita on käytetty tutkimuksessa. Näytteet ovat referenssejä tai niitä on käytetty eri tietokannoissa.

Genomien ja niiden toimintaa määrittävien proteiinien selvittäminen on valtava urakka, joka ei onnistu ilman yhteistyötä. Eurooppalainen biotieteiden tutkimusinfrastuktuuri ELIXIR tarjoaa tehokkaan alustan yhteistyölle. Siihen on liittynyt lähes 200 tutkimusorganisaatiota ja infrastruktuuria käyttää yli puoli miljoonaa tutkijaa. ELIXIR mahdollistaa pääsyn eri data-arkistoihin.
Massiivinen viljely- ja metsäkasvien sekvensointi mahdollistaa kasvitautien aiheuttajien tutkimisen. EURISCO (European Search Catalogue for Plant Genetic Resources ) sisältää informaatiota 1,9 miljoonasta viljelykasvista ja sen villeistä sukulaisista. Näytteet on kerätty lähes 400 eri organisaatioon. Mukana on 43 jäsenmaata ja tarkoituksena on säilyttää maailman agrobiologinen moninaisuus.
UniProt (Universal Protein Resource) kerää proteeinisekvenssit ja annotaatiodataa. Annotaatio tarkoittaa proteiinin toiminnan määrittelyä sekvenssin perusteella. Uniprotin datan ansiosa voidaan tietää enemmän proteiinien toiminnasta ja niiden vuorovaikutuksesta muiden molekyylien kanssa, niiden sijainnista soluissa ja organismeissa. Tavoitteena on kerätä kaikki julkisesti saatavulla oleva proteiinisekvenssidata. Uniprot on laajin julkisesti avoin olema proteenisekvenssitietokanta.
Euroopan nukleotidiarkisto ENA on kokoelma joka tarjoaa vapaan pääsyn kaikkiin julkaistuihin nukleotidisekvensseihin ja annotoituihin (geenin ja proteiinin toiminnan määrittely) DNA- ja RNA-sekvensseihin. The International Nucleotide Sequence Database on yhteistyöfoorumi, jossa ovat mukana DNA Data Bank of Japan (Japani), GenBank (Yhdysvallat) ja ENA. Uusi data synkronoidaan joka päivä kolmen tietokannan välillä. Jo vuonna 2012 näissä tietokannoissa oli 5682 organismin kokonaiset genomit. Data kaksinkertaistuu joka kymmenes kuukausi.
Euroopan genomiarkisto EGA on yksi maailman laajimmista julkisista datavarastosta, joihin on tallennettu potilasdataa biolääketieteellisistä projekteista. EGA säilöö ihmisistä kerättyä geno- ja fenotyyppidataa erikseen kysyttävällä suostumuksella näytteen ja datan tutkimuskäyttöön. EGA:n ansiosta moni ELIXIRin tutkimusprojekti on mahdollinen.

ELIXIR-infrastruktuurissa on yli 20 jäsenmaata Euroopasta. Jäsenmaiden keskusten kautta tarjotaan erilaista biolääketieteellistä dataa tutkijoiden käyttöön. Hyödyt ovat kiistattomia. Ihmisten harvinaisten sairauksien selvittämisessä on ollut hyötyä esimerkiksi koirien ja kissojen geeneistä. Suomen keskuksen kautta tutkijoilla on pääsy koirien ja kissojen DNA-pankkeihin, joiden aineistojen ansioista on onnistuttu löytämään esimerkiksi hermorappeumasairauden geeni. Tavoitteena on kehittää tähän sairauteen lääke. Koirien geeneistä on hyötyä ihmisten sairauksien tutkimisessa, sillä koiran ja ihmisen geeniperimä on 95-prosenttisesti samanlainen. Koirien geenipankissa on yli 70 000 näytettä 60 000 koirasta yli 300 rodusta. Se on tiettävästi lajissaan maailman suurin.
Arvioiden mukaan vuoteen 2025 mennessä voidaan sekvensoida 100 miljoonasta kahteen miljardiin ihmisen genomia. Jos datasta halutaan saada hyödyt, genotyyppinen data pitää linkittää muihin terveystietoihin. ELIXIR pystyy tähän. Tutkimusinfrastruktuuriin kuuluu lähes 200 organisaatiota, joiden muodostama federaatio, luottamusverkosto, mahdollistaa ihmisdatan käsittelyn tietoturvallisesti. Vuoteen 2016 mennessä ELIXIR-infrastruktuurin avulla oli laadittu 21000 tieteellistä artikkelia ja saatu 8500 patenttia. Patentteja oli haettu rokotteisiin, biomarkkereihin, entsyymeihin ja ebola-viruksen torjuntaan.
Elämän biologisten molekyylien yksittäisen atomin mittakaava on nanometrin kymmenesosa. Jos tuon biomolekyylin yksi hiiliatomi olisi ihmisen kokoinen kappale, se tarkoittaisi, että sen toiminnalla voisi olla ratkaiseva vaikutusta tapahtumiin, jotka tapahtuvat kymmenien miljoonien kilometrin päässä. Aurinkokuntamme halkaisija on samaa luokkaa.
Jos yksikin hiili vaihdetaan biologisessa molekyylissä toiseen atomiin, vaikka typpeen, se voi olla ratkaiseva piirre sille, tepsiikö esimerkiksi otettu lääke. Juuri tuon atomin avulla lääkemolekyyli voi olla tarttumassa proteiiniin, mutta ei onnistukaan muutoksen seurauksena saamaan riittävän pitävää otetta.
Proteiini, johon lääkkeen oli tarkoitus vaikuttaa puolestaan jakaa käskyjä eteenpäin toisille proteiineille soluissamme. Jos käskyyn vaikuttaminen jää tekemättä, biologiseen viestiketjun vaikuttaminen jää tekemättä.
Kysymys on myös siitä, ovatko solussa sijaitsevan viestiketjun kaikki osat virheettömiä? Kaikki nämä tekijät vaikuttava siihen voivatko tutkijat suunnitella lääkemolekyylin oikein, että se voi auttaa soluja parantumaan. Solussa ei ole tyhjiötä toisin kuin avaruudessa. Solut ovat täynnä toistensa kanssa koko ajan vuorovaikuttavia biomolekyylejä. Ihmisen vaikutusmahdollisuuden esimerkiksi auringon fuusioreaktioon ovat paljon rajallisempia kuin elämän molekyyleihin tallentuneen atomitason digitaalisen informaation vaikutus ihmisen sairastumiseen, vaikka mittakaavaero on sama.
Tommi Nyrönen
Ari Turunen
20.2.2018
Artikkeli PDF-muodossa
Sitaatti
Ari Turunen, & Tommi Nyrönen. (2018). Mapping the genomes of all organisms enables the development of new vaccines and medicines. https://doi.org/10.5281/zenodo.8070219
Lisätietoja:
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Biotekniikan instituutissa Jukka Jernvallin ja Petri Auvisen tutkimusryhmissä selvitetään eri lajien perimää ja populaatioiden rakenteita. Tavoitteena on ymmärtää, milloin lajit syntyivät ja eriytyivät toisistaan. Erityisen kiinnostuksen kohteena on saimaannorppa, jonka koko perimä eli genomi selvitetään.
Saimaannorppa on erinomainen tutkimuskohde, kun halutaan tutkia perimän monimuotoisuutta,
eristäytymistä ja sisäsiittoisuutta. Saimaannorpalla ei ole ollut yli kymmeneentuhanteen vuoteen kosketusta muihin hyljelajeihin. Sen silmät, aivot ja kallo ovat erilaiset muihin norppalajeihin verrattuna. Saimaannorppa kehittyi hyljekannasta, joka todennnäköisesti tuli Itämerestä Laatokkaan ja siirtyi sieltä Saimaan saaristoon.
”Jos laatokannorppa siirrettäisiin Saimaaseen, se ei välttämättä pärjäisi. Saimaannorppa on sopeutunut humuspitoiseen sameaan veteen ja sokkeloiseen saaristoon,” Biotekniikan instituutin laboratorion johtaja Petri Auvinen kertoo.
Biotekniikan instituutin DNA-sekvensointi ja genomikka -laboratorio on erikoistunut geenien sekvensointiin eli DNA:n emäsjärjestyksen selvittämiseen. Laboratoriossa on sekvensoitu useiden eliöiden kokonainen genomi kylmäruokaa pilaavasta Lactococcus piscium-bakteerista alkaen. Lisäksi laboratoriossa tutkitaan sekvensoimalla myös geenien ilmentymistä. Keskeisinä tapahtumina eliöiden kehityksessä ovat solujen jakautuminen ja erilaistuminen, mikä on ajallisesti ja paikallisesti tarkasti säädeltyä.
Solujen erilaistuminen tapahtuu vaiheittain. Joskus geeni kytkeytyy päälle ja joskus lakkaa toimimasta. Tätä aktiivista toimintaa kutsutaan geenin ilmentymiseksi. Kun geenien ilmentyminen saadaan mitattua, voidaan esimerkiksi voidaan seurata sitä, mitkä geenit alkavat toimia vaikkapa puun valmistautuessa talveen. EST (expressed sequence tag)-tekniikka antaa tietoa geenin sijainnista ja toiminnasta. Selvittämällä geenien emäsjärjestys saadaan kullekin ilmenevälle geenille tunnistin (tag). Nykyisin geenien toiminnan tutkimiseen käytetään lähinnä RNA-seq menetelmää.

Helsingin yliopistossa toimivan Biotekniikan instituutin tutkijoiden tavoitteena on saada mahdollisimman korkealaatuinen referenssigenomi saimaannorpasta. Referenssigenomi on digitaalinen sekvenssitietokanta yhden lajin koko emäsjärjestyksestä, joka on saimaannorpan tapauksessa koottu yhdestä yksilöstä ja ihmisen tapauksessa lukuisista genomeista. Hyvän referenssigenomin kerääminen edellyttää erilaisten, kehittyneiden tekniikoiden käyttöä.
Populaatiota voidaan tutkia tehokkaasti referenssigenomin ja yksilöiden genomeissa esiintyvien poikkeamien avulla. STR-menetelmässä (short tandem repeat) verrataan DNA:n yhtä tiettyä kohtaa, jossa toistuu aina muutaman emäsparin toisto, kahteen tai useampaan DNA-näytteeseen. STR:n avulla yksilöiden DNA:t erottuvat selvästi. Mitokondrio-DNA:n avulla voidaan puolestaan selvittää yksilöiden äiti-linjaa tuhansien vuosien taakse. DNA- sekvensointitekniikoiden nopea kehittyminen on mahdollistanut yhden nukleotidin polymorfismien (SNP) selvittämisen, joka antaa hyvin tarkan arvion yksilöiden välisistä eroista. Tätä menetelmää käytetään myös saimaanorpan genomiprojektissa. Datan kerääminen edellyttää paljon tallennustilaa ja laskentatehoa, jota tieteen tietotekniikan keskus CSC tarjoaa ELIXIR-infrastruktuurin kautta.
Saimaannorpan genomi on 2,5 miljardin emäsparin pituinen, saman kokoinen kuin koiran genomi. Saimaannorpan perimän selvittämisessä akatemiaprofessori Jukka Jernvallin ryhmä keskittyy hylkeiden hampaiden tutkimiseen, Petri Auvisen ryhmä populaatiohistoriaan ja genomin rakenteeseen. Kun genomi on selvitetty, saimaannorpan genomia verrataan Laatokan,
Itämeren ja Jäämeren norppien perimään.
Tutkijat yhdessä Oulun ja Itä-Suomen yliopistojen tutkijoiden kanssa keräävät dataa genotyypin (geneettiset tekijät) ja fenotyypin (ympäristötekijät) yhteyksistä. Paljon kehitysbiologista tietoa saadaan analysoimalla hampaita. Kun hammas puhkeaa, se ei enää kehity eikä se muutu ympäristön vaikutuksesta. Hampaissa on kuitenkin valtava variaatio. Siksi tutkitaan, mitkä geenit ovat vaikuttaneet erikoisiin hampaisiin. Esimerkiksi grillihylkeen hampaat ovat evoluution myötä tulleet hyvin monimuotoisiksi ja toimivat valaiden hetuloiden tapaan, koska hylkeet syövät grilliä.
”Meillä on tietokonemallit kaikista norpan kalloista. Voimme laatia tarkkoja fenotyyppejä ja etsiä todennäköisiä geenejä, jotka aiheuttivat tietyn hampaan. Geenin toimintaa voidaan mallintaa tietokoneella ja analysoida, mitkä alueet genomista voisivat vaikuttaa hampaaseen.”
Erilainen kallo ja hampaat kertovat adaptaatiosta tai lajiutumisesta, sopeutumisesta erilaisiin olosuhteisiin. Koska saimaannorpan silmäkuopat ovat erilaiset muihin läheisiinkin norppiin verrattuna, voidaan esimerkiksi päätellä, että se on sopeutunut sameisiin ja sokkeloisiin vesiin.
Auvisen ja Jernvallin ryhmillä on käytössä maailman ainoa tunnettu norpan ja harmaahylkeen risteymän DNA. Vuonna 1929 Skansenin eläintarhassa syntyi poikanen, jonka hampaasta Auvisen onnistui eristämään DNA:n. Valtavan harmaahylkeen ja pienen norpan jälkeläinen eli vain lyhyen aikaa. Risteymän hampaat ja kallo kertovat välimuodosta. Auvisen mukaan se vastaisi ehkä simpanssin ja ihmisen risteymää. Nyt pystytään vertaamaan, miksi tietynlainen hammas tai kallo kehittyy.
Auvisen mielestä tämä on myös ihmisen evoluutiolle merkittävää tutkimusta, koska ei tiedetä, milloin nykyihmisen eriytyi omaksi lajikseen. Risteytymiä on tapahtunut myös ihmisen evoluutiossa. On löydetty ihmisen kallonpalasia, jotka ovat Cro-Magnonin ihmisen ja Neanderthalin ihmisen väliltä. Eurooppalaisista 2-5% kantaa Neanderthalin ihmisiltä periytyviä
geenejä. Denisovan luolasta Siperiasta puolestaan löytyi ihmislajin luuranko, joka nimettiin Denisovan ihmiseksi. Se kuoli sukupuuttoon 40 000 vuotta sitten, aiemmin kuin serkkunsa Neanderthalin ihminen. Kun Denisovan ihmisen luurangon sormesta eristettiin DNA, havaittiin, että tiibetiläisillä on Denisovan ihmisen geenejä. Yksi periytyvä geeni auttaa tiibetiläisiä selviytymään korkeassa ilmanalassa.

Biotekniikan instituutin tutkijat haluavat selvittää onko saimaannorppa oma lajinsa vai alalaji. Tutkijat tietävät tarkasti, kuinka monta sukupolvea norppa on ollut eristyksissä Saimaalla. Saimaannorpan populaatio on pieni. 1980-luvulla jäljellä oli vain 140 yksilöä, nyt 320. Kun vanhoja näytteitä Saimaalta, Itämerestä ja Laatokasta verrataan saimaannorpan referenssigenomiin, voidaan tutkia minkälainen populaatio on mennyt ns. pullonkaulan läpi.
Nykyisin on olemassa myös laskennallisia menetelmiä joilla voidaa jopa yhdestä genomista kohtuullisen tarkasti päätellä millaisessa populaatiossa sen esiisät ja -äidit ovat eläneet. Populaation kohtaama pullonkaulailmiö tarkoittaa tapahtumaa, jossa suurikin osa populaatiosta tuhoutuu tai vain pieni joukko yksilöitä perustaa uuden joukon kuten esimerkiksi Suomeen aikanaan saapuneet ihmiset. Tuhoutumisen syynä voivat olla ympäristön muutokset tai siirtyminen uuteen ympäristöön, joka voi estää lisääntymisen.
Saimaannorpan geneettisen historian tutkimisesta on apua myös ihmisen perimän tutkimiseen. Pullonkaulat voivat lisätä sisäsiittoisuutta ja siten vaikuttaa myös tautiperimään. Suomessa pullonkaulat ovat synnyttäneet väestöön noin neljäkymmentä perinnöllistä sairautta, jotka ovat täällä huomattavasti yleisempiä kuin muualla. Suomalaisia geneettisiä pullonkauloja ovat olleet maanviljelyn omaksuminen 4000 vuotta sitten ja asutuksen leviäminen pohjoiseen ja itäiseen Suomeen 1500-luvulla.
”Nyt pystytään tutkimaan tautigeenien vaikutusta populaation rakenteeseen ja luonnon ja ihmisten aiheuttamia pullonkauloja. Suomalainen tautiperimä on tässä suhteessa mielenkiintoinen. Voidaan saada selville, minkälainen on ollut suomalaisten kantama tautiperimä, kun on menty pullonkaulan läpi,” Auvinen toteaa.
Referenssigenomin luomisesta on paljon hyötyä. Referenssigenomin dataa voidaan käyttää aina uudestaan. Mitä parempi referenssigenomi, sitä helpompi on analysoida uutta dataa, jota voidaan verrata referenssigenomin dataan.
Esimerkiksi koivun referenssigenomin analysoiminen nopeuttaa ja tehostaa puun tutkimusta teollisuuden ja lääketieteen tarpeisiin. Koivun genomista voidaan etsiä uusia ominaisuuksia, jotka vaikuttavat puun laatuun ja määrään. Lisäksi tätä dataa voidaan hyödyntää muiden puulajien tutkimisessa.
”Toisin kuin koivulla, esimerkiksi poppelilla ja eukalyptuksella kestää ominaisuuksien selvittäminen 10 vuotta. Koivua voidaan geneettisesti modifioida. Koska koivu saadaan jopa kolme kertaa vuodessa kukkimaan, uusia ominaisuuksia saadaan koivulle yhdessä, kahdessa vuodessa. Näitä tekniikoita voidaan soveltaa myös muihin puulajeihin. Koivun geneettistä mallia voidaan käyttää hyväksi esimerkiksi eukalyptuksen tutkimisessa,” toteaa Petri Auvinen.
Koivun referenssigenomin projektia oli seuraamassa myös teollisuuden edustajia. Geenitiedon ansiosta koivun ominaisuuksia voidaan jalostaa ja metsäteollisuus voi käyttää puuta muuhun kuin laudan tekemiseen.
Uusia sovelluskohteita ovat nanomateriaalit, puunjalostusteollisuuden sivuvirrat sekä esimerkiksi hemiselluloosa. Auvinen mainitsee myös koivun kaarnassa olevan betuliinin, jolla on raportoitu olevan syöpää torjuvia ja antiviraalisiakin vaikutuksia. Betuliinista on jo tehty emulsiolääkevoiteita. Voidaan myös pyrkiä tavanomaisin jalostusmenetelmin aikaan saada sellaisia koivuja, joissa on enemmän betuliinihappoa.
Ari Turunen
10.8.2015
Artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Petri Auvinen, & Tommi Nyrönen. (2015). Saimaa ringed seal aids the study of population genomes. https://doi.org/10.5281/zenodo.8068837
Lisätietoja:
Biotekniikan instituutti
Biotekniikan instituutti on Helsingin yliopiston erillinen tutkimus- ja koulutuslaitos,
joka edistää korkeatasoista tutkimusta ja koulutusta biotekniikassa ja molekyylibiologiassa.
http://www.biocenter.helsinki.fi/bi/dnagen/index.htm
CSC – Tieteen tietotekniikan keskus Oy
CSC on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon
osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa Eurooppaan biologisen informaation infrastruktuurin bioalan tutkimuksen tueksi. Sen Suomen keskus on CSC.
http://www.elixir-europe.org


 ELIXIR is partly funded by the European Commission
ELIXIR is partly funded by the European Commission