
Data obtained from human genes and proteins enables quick diagnosis of illnesses and more detailed and personalised patient treatment. Those at risk can be screened better and more effective medication can be chosen once the patient’s genome is known. The challenge lies in how data is processed and where it is stored.
Owing to new data analysis methods and improved computing power, the processing of gene and protein data can be accelerated from several days to less than half an hour. But in order to do this, data must be pre-processed, that is, redundancies removed, and be quickly and securely available.
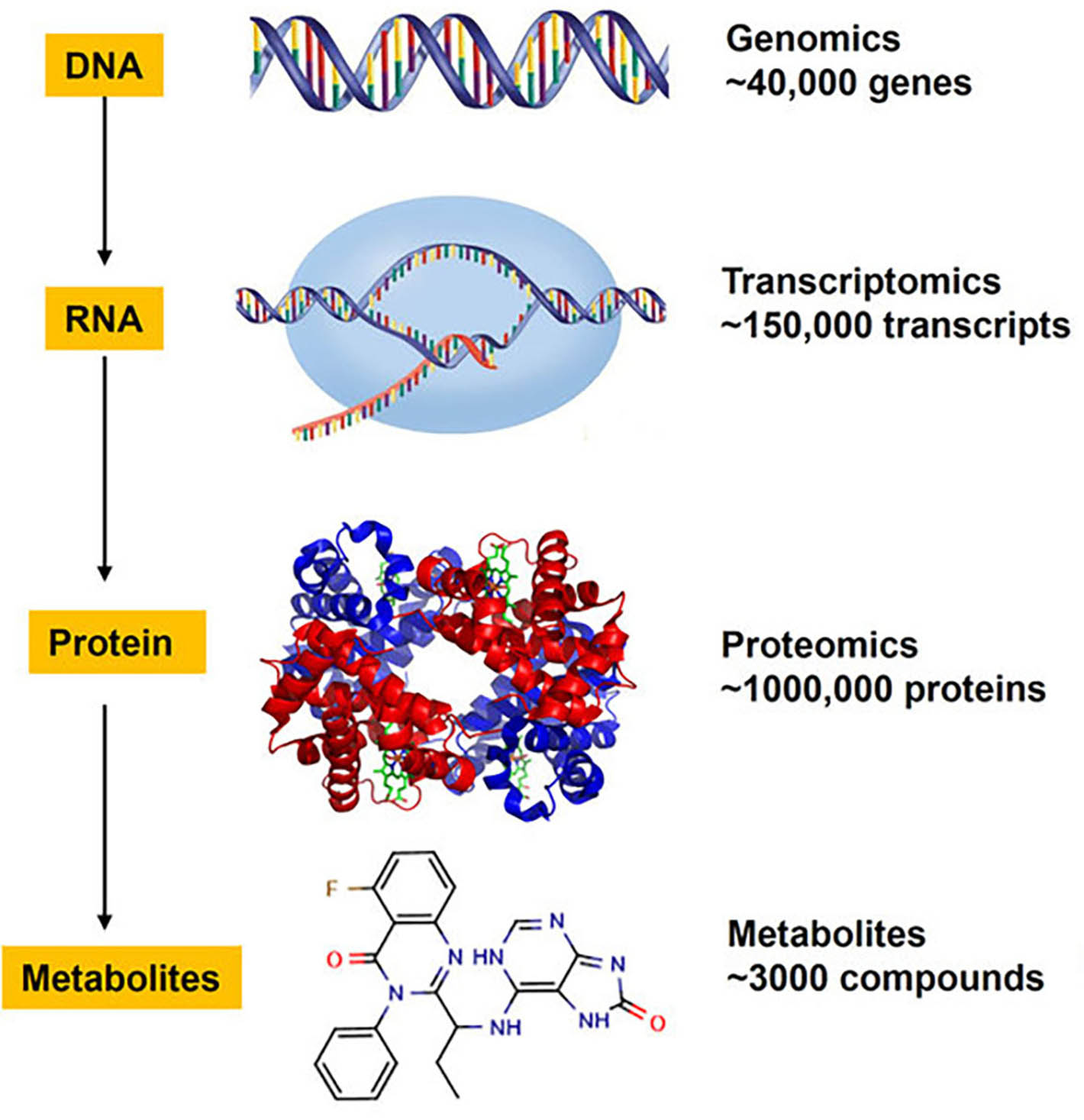
Bioinformatics measurement methods have developed apace, producing huge amounts of data. Now we are in a position to understand the operation of an entire biological system. This means that genes – or the proteins created by them – are studied simultaneously. These ‘omics’, if you like, include determining DNA sequences (genomics), computer modelling of protein structures (proteomics), study of genes in cell tissue (transcriptomics) and metabolic products (metabolomics). Such methods can be used to study molecular interaction and find signs of changes in the human body to identify diseases.
“We can already do a great deal, but combining genetic and clinical data requires a lot more data storage and computing power, and all this in a secure way,” says Katja Kivinen, Head of the FIMM Technology Center from the Institute for Molecular Medicine Finland (FIMM).
The proper pre-processing and modelling of data are requirements for future research, with a view to providing more accurate disease prediction and even personalised ‘silver bullets’ in terms of medication. Kivinen gives two examples: pre-screening of disease risk factors, and drug treatments.
Nature Medicine ran an article in spring 2020 based on data analyses made in the Finngen project. On the basis of genomic data, Professor Samuli Ripatti’s research team at FIMM was able to identify a Finnish population group that had a 60% probability of suffering from cardiovascular diseases or diabetes at some point in their lives. The research material consisted of 135,000 Finnish people providing a blood sample. Data obtained about individual risk factors was combined into a genome-wide risk score.
“Once a person’s genetic background is known, clinicians will be able to offer preventive measures and treatments to improve health as well as save time and money,” says Kivinen.
“In future, population-wide screening can be customised. For example, some women are now screened too early for breast cancer given their small inherited risk, while others are screened far too late. If we use genomic data to take account of inherited risk factors, women could be invited for their first mammography at the optimal time, thereby maximising the chances of discovering cancer at an early stage while minimising unnecessary radiation from repeated screening.”

People react to drugs differently: some do not get the necessary dose, while others suffer from side effects. The reason for varying responses may be our physical characteristics, other medication, or genome. Through the pilot phase of ‘HUS e-care for me’ project, we are optimising treatment for patients with leukaemia and other blood cancers. The project kicked off in summer 2019 and uses artificial intelligence to combine patient-specific biological data produced at FIMM with information about cancer type and status to identify suitable, personalised treatments and stop cancer progression.
“Sometimes a drug may not be effective, or have lost its effect. Cell cultures are made from leukaemia patients’ blood samples, in order to analyse which combination of drugs works best.”
Genome and transcriptome sequencing are performed on the same blood sample. A transcriptome provides information on whether the operation of genes has changed as a result of genetic mutations.
“If a drug no longer has the desired effect, we can find out what kinds of mutations have occurred. Are some genes working, or not, as a result of a mutation? And how do mutations affect metabolic pathways? Now we can see which drug is the best suited for different blood cancer patients directly from blood samples.”
Personalised drug treatments are possible if enough data is available on the patient, and it has been stored and pre-processed correctly. Alongside eleven other academic and commercial players, the Finnish ELIXIR Center CSC and the Barcelona Supercomputing Center (BSC) kicked off the European HPC Center of Excellence for Personalised Medicine (PerMedCoE) project in October 2020. The project is developing algorithms that can significantly reduce the computing time required for analysis. Analysis of genetic and protein data is becoming faster, facilitating and speeding up disease diagnosis and identification of the appropriate treatments. A genome analysis can take weeks or even months. Thanks to super computation and better software, diseases can be diagnosed in future within just hours or days.
Projects like this are important for research teams at FIMM who are routinely working with massive amounts of data.
“The amount of data is increasing at an accelerating pace owing to more powerful equipment and methods,” says Katja Kivinen. “At the moment, we are chronically in short supply of data storage space, and data pre-processing takes too long to enable us to clear up job backlogs and send analysed data to research teams. A secure environment for storing and processing data is vital when dealing with human data. Commercial cloud services offer a secure operating environment, but are too expensive for most researchers. What is more, some data requires a carefully tailored pre-processing and analysis environment and is poorly suited to the options available in cloud services.”
Data processing can be alleviated by dividing work between CSC and FIMM. In the pilot stage, genomic data is transferred from FIMM to CSC on a superfast and secure optic cable. Data pre-processing and quality assurance of analysis are fast, because the data is located at CSC. In future, CSC will distribute data back to research teams on a national basis.
“Previously, it took us 2–3 days per human genome to determine what kinds of changes had taken place. Thanks to this cooperation, the manufacturer of our sequencing equipment has given us access to an optimised computing server that can compress the processing of one genome into 20 minutes. This will help us deal with the backlog of genomic data processing at FIMM and free our bioinformatics specialist to perform other work – such as planning and facilitating various data integration procedures.”
CSC has developed a a new interface to its Allas -service for genomic data from FIMM, to be used by Finnish research teams. The research teams will receive a message once their genomic data is ready, and transfer it to their own project area in CSC’s ePouta environment. Following the pilot stage, the portal’s operating principle will be offered on a larger scale to all research teams in Finnish universities producing ‘omics’ data.
“The interface is vital for us, as data volumes are increasing and data security requirements are becoming tighter, and it is increasingly difficult for us to maintain a data storage and processing environment at FIMM. We must start moving more and more raw data and process data to CSC and make it accessible for research teams.”
Another important area of development, according to Kivinen, relates to data storage and related imaging services.
“Image processing is usually done on the server connected to the actual instrument, which contains the necessary processing software. Owing to slower transfer speeds, moving processing to a cloud service is not always a viable alternative, at least not in all parts of the country. So image processing may also occur on location in the future but, like genomic data, processed data should be shared through CSC .”
Ari Turunen
10.11.2020
Read article in PDF
Citation
Ari Turunen, Katja Kivinen, & Tommi Nyrönen. (2020). Bioinformatics to revolutionise healthcare: Efficient data processing speeds up diagnoses and enables personalised drug treatments. https://doi.org/10.5281/zenodo.8135131
More information:
FIMM
Cleaverhealth
https://www.cleverhealth.fi/fi/ecare-for-me
+1 million genomes’
https://ec.europa.eu/digital-single-market/en/european-1-million-genomes-initiative
CSC – IT Center for Science
CSC – The Finnish IT Center For Science is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centralised IT infrastructure.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 European countries and the EMBL European Molecular Biology Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish
centre within this infrastructure.
https://www.elixir-finland.org
http://www.elixir-europe.org

The human genome contains millions of genetic variants that make each individual unique. Some variants affect eye colour or blood type and others affect hereditary diseases. The DNA sequence may also include a pathogenic sequence variant that causes various disruptions in the function of the gene. The disruptions manifest themselves as hereditary diseases. Blueprint Genetics from Finland classifies genetic variants found in the genome from patient samples and analyses their connection to the described symptoms of the patients.
Blueprint Genetics started its operations focusing on the diagnostics of cardiovascular diseases. The company is now able to analyse majority of hereditary diseases based on the patient samples it receives. More than 6,000 disorders resulting from a defect in a single gene are known in humans. On average, one in two hundred will inherit a genetic defect from their parents. There are also many multi-factor disorders in which the combination of multiple genetic variants causes the disease or increases the risk of illness. These include, for example, Alzheimer’s, diabetes, rheumatoid arthritis or cancer.
Jussi Paananen, Director of Data Science at Blueprint Genetics and researcher at the University of Eastern Finland, has a background in computer science with data science as his field of specialisation. Paananen became interested in biomedicine at an early stage because it utilises technologies that produce a lot of data. In recent years, he has been interested in machine learning and artificial intelligence, which are on their way to becoming research methods in bioinformatics thanks to increasing computing power.
“I am interested in how artificial intelligence can help geneticists in decision-making as well as processing large amounts of data.”
Research into artificial intelligence is on the rise and the methods are changing. In machine learning, the computer learns to arrive at a particular outcome independently. Machine learning algorithms find patterns that people are not able to detect from large data sets. Machine learning utilises neural network research, which has a long tradition in Finland. The neural network learns the non-linear dependencies of the variables directly from the observation data. It is able to classify the ears from animal-themed images, for example.
“Neural networks are at their best in solving classification problems”, says Paananen.
“In image analysis, images or parts of images are identified and classified. A machine can identify objects and things: this is a human, this is a car, this is a cancerous tumour. What we do is classify DNA variants. From patient samples, we try to find which DNA variants cause diseases as well as which genetic variants are a part of our normal genome.”

The customers of Blueprint Genetics are doctors treating patients. The doctors want to find out whether the illnesses of their patients are due to hereditary factors or not. Doctors from around the world send Blueprint Genetics their patients’ blood or saliva samples, the isolated DNA of which is then sequenced. Sequencing generates a huge amount of data from which the interesting variants are drawn. In practice, this means that the patient’s genetic variants are compared to the average human reference DNA.
Blueprint Genetics employs top professionals, geneticists and doctors who classify the variants. They go over the data mass that has already been processed and divided into smaller parts. The experts practically sieve through existing scientific literature and databases.
“We are trying to figure out which of these variants explains the disease or its symptoms.”
Since similar information has been collected around the world, a single DNA variant that explains the disease can often be found in scientific articles and databases.
“We issue a clinical statement based on the results. The clinical statement is typically a few pages long document, that is delivered to the customer physician. The physician uses the statement as an aid in diagnosis and planning of treatment.”
Blueprint Genetics utilises a variety of data sources. Where possible, the analysis of the data is automated. Software analyses the data and performs complex data processing. The field is under constant development. Software is updated several times a year, data volumes and computing power are increasing. Methods evolve and change rapidly.
Initially, Blueprint Genetics focused on certain interesting genes, or gene panels, based on the patient’s symptoms. A panel typically includes about a hundred known genes associated with a particular disease. A team of geneticists sieves through the approx. 2,000 variants studied using the panel. The company has now shifted to exome sequencing, meaning that it sequences all protein-encoding genes, of which there are approx. 21,000 in our genome.
The human exome is the part of DNA with which all human proteins are produced. The part of the gene that encodes and directly guides protein production is called the exon. All the human exons in our genome together are called the exome. The human exome is approx. 1.5% of the entire genome.
“When our analysis focused on gene panels, we obtained, for example, 2,000 variants that a team of geneticists went through. Now, there may be 200,000 variants. As we advance to sequencing the entire genome, the number of variants will be 5 million. This amount of data cannot be sieved through manually.”
External databases are important in interpreting the data collected from patient samples. Genomic variants have been catalogued in various international databases, the most important of which are located in the organisations of EMBL-EBI in Europe and NCBI (The National Center for Biotechnology Information) in the US. In addition, ELIXIR coordinates the public biomedical infrastructure in Europe, enabling genetic variants to be mined from these international databases.
Variant databases provide useful lists that can be used to find correlations between genetic variants and phenotypic data. EMBL-EBI classifies, stores and distributes information on genetic variants. The most important databases include the European Genome-phenome Archive (EGA) where patient data from biomedical research is stored, the European Variation Archive (EVA) that includes genetic variants, Ensembl that provides interpretation for these variants, the gnomAD service for population-level variant occurrence data and the ClinVar archive for clinically significant variants. Therefore, the doctor often needs information from more than one service in order to produce the correct interpretation of the genomic variant for the patient. For this reason, European and American services regularly exchange information on the latest research results so that the services would always provide the latest information on our genome for research and medicine.
“Genetic variant databases are important because they have information on the prevalence of the variants in healthy people. This information can be utilised, for example, when it is known that only 1% of people have a certain rare hereditary disease. When we see that there is a variant that 5% of people have, it can be concluded that this cannot be the variant causing the disease. Thus, it is possible to filter out major, common DNA variants that cannot be associated with the rare disease.”
Public sector data services offered by ELIXIR are important.
“We utilise our own local copies of different data sources. Physical distance and communications links require the sources to be in the same place. From public services, I would like to see more measures related to the versioning of databases. Old versions should not be discarded. Long-term storage should be available for different versions.”

A major challenge in both public research organisations and the private sector is the standardisation of the data used for interpretation. Data notations can vary greatly. The big challenge for Blueprint Genetics is the so-called phenotypic data.
“In one sense, it is metadata in itself, i.e. information accompanying a patient sample: symptoms, diagnosis and other background information. A sample may be accompanied by a lot of metadata or none at all.”
The standardisation of phenotypic data has the same problem as patient data in health care, where the challenge is different notations.
“We obtain information from different countries that has been recorded in different ways. The background information varies.”
Jussi Paananen thinks that firms like Blueprint Genetics find it difficult to utilise data produced and managed by publicly funded and research-focused organisations.
“Research organisations and joint infrastructures are interested in large population cohorts, in which case we are talking about a huge amount of data being collected and harmonised. We process information in different ways than cohorts which, for example, compile the information of tens of thousands of people living in the same geographical area. We, however, always deal with individuals.”
Blueprint Genetics seeks to use internationally consistent classification, terminology and standards in its operations.
“We produce the DNA data ourselves and can decide what form it is in and which standards it conforms to. However, we utilise guidelines provided by others when interpreting the results.”
The first attempt at such a standard was made a few years ago. The American College of Medical Genetics and Genomics (ACMG) has issued guidelines on how sequence variants should be classified. ACMG has proposed the following common terminology for single-gene disorders: pathogenic, likely pathogenic, uncertain significance, likely benign and benign.
“We have our own modified version of ACMG’s classification.”
The challenge for companies like Blueprint Genetics is the ability to utilise data. There is a lot of information in peer-reviewed publications, and the aim is to develop good text mining tools in order to automate the screening of articles.
“There should be centralised access to all publications. We have now long been negotiating with academic publishers about licence fees, which are high.”
“We have our own software production combining different data sources and facilitating literature searches. However, the final interpretation is always carried out by a geneticist.”
Analysis and interpretation of patient data is demanding work because it involves a lot of legislation and regulation. Blueprint Genetics provides medical doctors with processed information, but the doctors always make the actual decision.
Blueprint Genetics is also interested in cooperation between the public and private sectors.
“The utilisation of genetic data is an enormous challenge that concerns the whole human race. The solution requires cooperation from companies, academic research groups as well as publicly funded organisations. Blueprint Genetics strives to contribute to the development of open science solutions and is constantly looking for new partners.”
Ari Turunen
29.5.2018
Read article in PDF
More information:
https://www.elixir-europe.org/platforms/data/core-data-resources
CSC – IT Center for Science
CSC – The Finnish IT Center For Science is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centralised IT infrastructure.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 European countries and the EMBL European Molecular Biology Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish
centre within this infrastructure.
https://www.elixir-finland.org
http://www.elixir-europe.org

More than a million tissue samples and tens of thousands of blood samples are stored in Auria, the first hospital biobank in Finland. The biobank is also able to combine donor-related data to the collections, providing significant assistance for research. The data can be requested from the donor of the sample, patient records or national registers.
An electronic health record accessed with your identity number has been in use in Finland for a long time. Registers requiring an identity number create good conditions for the efficient future utilisation of sample collections from people and the data linked to them. This is a great advantage over many countries.
The sample collections of Auria Biobank, which operates in connection with the Turku University Hospital and the University of Turku, are physically located in hospitals in southwest and west Finland. Samples are collected and combined with the necessary metadata, indicating the clinical information on the sample donor, quantity, date and how the sample has been processed. The samples of Auria Biobank include tissue, blood and DNA isolated from cells.

The Finnish legislation relating to biobanks is progressive. Consent provided once from the donor of the samples is sufficient for the stored samples to be utilised in various studies and in the future too. The law allows the biobank to contact the sample donors who have given their consent, for example, to enquire about the willingness of the donor to participate in a study not covered by the consent or to donate additional samples.
“In most cases, the contact has to do with drug research. If the patient is interested, they will contact the author of the study directly, and then they will form a separate agreement with the research organisation, after which the matter no longer involves the biobank”, says Perttu Terho, Vice Director of Auria Biobank.
The Personal Data Act and the Biobank Act are complied with in the transfer of data, safeguarding the privacy and confidentiality of patient information.
Consent for the donation of samples can be given in hospitals or online through an electronic form.

New samples are collected from consenting patients in connection with normal diagnostics and treatment. Tissue samples filed in hospitals are scanned, digitised and transferred to databases. Before transfer to the biobank, personal data is removed from the samples and replaced with a code. This ensures the efficient protection of personal data.
Auria collects tissue samples taken in connection with surgery that are left over from a diagnostic procedure, such as cancer tissue, and biobank blood samples taken in connection with laboratory visits.
“After surgery, the tissue sample is taken to a pathologist for examination. Typically, the sample is cast into paraffin and cut into slices with a thickness of a few micrometres which are stained with the colours needed for diagnostic purposes. The pathologist examines the stained tissue sections to establish whether there is a tumour present in the sample, for example. If some of the sample remains, it can be utilised in biobank studies. The sample must not run out, so there should be enough for the hospital to use. Once this has been confirmed, the tissue sample can be used for other research”, says Terho.
Auria Biobank digitises the samples that are needed for research projects.
“The purpose of digitisation is that we can, for example, ask a pathologist to assess the samples and mark the spots where cancerous tissue is found and where there is healthy tissue. The pathologist can do this from anywhere on their own computer, and the samples themselves do not need to be transferred. The digitised images can also be analysed in an automated way using pattern recognition algorithms and methods based on artificial intelligence.”
Auria has previously isolated DNA only from those blood and tissue samples that were needed in projects. Now, DNA isolation is to be done from every blood sample stored.
“Isolating DNA from every sample enhances research. Samples are received and stored, but nothing is yet studied. The samples are left to wait for future research as it is not yet known what the samples may be needed for.”
DNA will be isolated from 16,000 blood samples this year. Going forward, more than 20,000 samples will be taken every year.
The blood sample is taken in conjunction with a normal diagnostic or clinical blood sample.
“We are talking about one extra 10 ml blood sample for the biobank. The blood plasma and white blood cells from the sample are placed in different tubes before being frozen.”
Perttu Terho emphasises that the donated sample is valuable when it can be combined with patient data.
“Researchers may want data on patients with a specific diagnosis, medication and blood count. In this case, it is possible to quickly check the biobank and see whether there are samples that meet these criteria and the associated data exist.”
Biobank material can be used to identify the special characteristics of diseases and drugs. For example, it is possible to learn more about why some patients have side effects from medication and others do not.
“It is important to collect a sensible amount of relevant patient data from as large a number of people as possible. This allows samples from patients who are of interest to research to be obtained for the biobank.”
Sample-related requests from researchers are received every week.
“Based on an analysis, we map the quantity of samples and data in the biobank that the researcher is interested in. If the researcher is satisfied with the outcome of the pre-analysis, they will submit a request for data and samples describing the study and defining the required samples and data.”
The requests for data and samples are processed by the biobank’s Scientific Steering Committee which convenes once a month. The steering committee evaluates the requests. If the steering committee decides in favour of the study, the applicant can proceed to the preparation of a Material Transfer Agreement.
In principle, the operations of the biobanks operating in connection with Finnish hospitals are the same. They collect samples from their own hospital districts and store associated data. It would, of course, be a tempting idea to be able to search all the available sample collections in one go. The challenge is that, over the years, the different hospitals have stored and classified the samples in different ways. Different systems have different information registered, meaning that there is variation in the data provided on patient samples. Data should flow smoothly between the different biobanks.
“Hospital data is difficult to analyse. The expertise of a clinician is required to interpret what has been recorded. The data available is not directly commensurable. It would be important to create an availability service that is able to combine the data of the different biobanks so that at least the basic data would be available.”
The Finnish Biobank Cooperative was established in 2017. Its members include hospital districts and universities with faculties of medicine. The purpose of the biobank cooperative is to provide the material in the sample and the data collections of Finnish biobanks to be used by researchers under a one-stop principle. It would provide customers with a unified view and a centralised channel to the materials of Finnish biobanks. The biobank cooperative is responsible for the development of information systems, among other things.
According to Terho, it is possible to combine the associated clinical data relevant to research to the samples. Biobanks will utilise the sensitivive data platforms developed by CSC – IT Center for Science when designing the information services of their own.

Auria Biobank is involved in the establishment of the future genome centre. According to Lila Kallio, Acting Director of Auria Biobank, the way in which the transfer and storage of research and diagnostic sequences will be organised is, so far, only at the consideration stage.
“Genome legislation is being drafted and reform of the Biobank Act is underway. In addition, the new data protection regulation of the EU will also clarify the operations of biobanks.”
According to preliminary plans, the Finnish Genome Center will start its operations in 2019.
Ari Turunen
19.3.2018
Read article in PDF
Citation
Ari Turunen, Tommi Nyrönen, Perttu Terho, & Lila Kallio. (2018). Bank of million patient samples. https://doi.org/10.5281/zenodo.8081169
More information:
CSC – IT Center for Science
CSC – The Finnish IT Center For Science is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centralised IT infrastructure.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 European countries and the EMBL European Molecular Biology Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish
centre within this infrastructure.
https://www.elixir-finland.org
http://www.elixir-europe.org


 ELIXIR is partly funded by the European Commission
ELIXIR is partly funded by the European Commission