
Jokainen ELIXIRin jäsenmaa toimii osakeskuksena. Osakeskus on jäsenmaan sisällä toimivien organisaatioiden verkosto. Osakeskusta johtaa organisaatio, joka koordinoi paikallisia ELIXIR-toimintoja. CSC – Tieteen tietotekniikan keskus isännöi ja operoi ELIXIRiin kuuluvia resursseja ja palveluita, kuten yleiseurooppalaista ELIXIR-identiteetti- ja pääsyinfrastruktuuria. ELIXIR Suomen palveluita kehitetään osana eurooppalaista e-infrastruktuuria (esim. EuroHPC/LUMI, GAIA-X, EOSC, GEANT, NeIC).
ELIXIR Suomi lisää valmiuksia tehdä terveys- ja biotieteiden alan tutkimusta. Yhdistämme ELIXIRin biopankkien datanhallintaan ja koulutukseen sekä valtakunnalliseen bioinformatiikkaverkostoon (https://www.biocenter.fi/) Suomessa. Biopankkien Osuuskunta Suomi – FINBB kehittää Suomen terveys- ja biolääketieteellisen tutkimuksen kilpailukykyä tuomalla Suomen biopankkien ja niiden taustaorganisaatioiden tietovarannot tutkijoiden saataville. ELIXIR Suomi on vuodesta 2012 lähtien tehnyt aktiivista yhteistyötä Terveyden ja hyvinvoinnin laitoksen (THL) ja Helsingin yliopiston/Suomen molekyylilääketieteeninstituutti (FIMM) kanssa, joka operoi BBMRI– ja EATRIS osakeskuksia.
Tieteen ja tutkijoiden sivusto Fingenious.fi on valittu STM:n ja THL:n toimesta Suomen yhteiseksi brändiksi biolääketieteellisen tutkimuksen lisäämiseksi maassamme erityisesti toisiolain alla tapahtuvassa tutkimustoiminnassa.
CSC on solminut puitesopimuksen kaikkien suomalaisten korkeakoulujen ja tutkimuslaitosten kanssa.
CSC:n tutkimuspalveluiden kehitys edistää ELIXIR Suomen strategiaa. On tärkeää varmistaa Suomen datainfrastruktuurin yhteentoimivuus eurooppalaisten dataympäristöjen kanssa, jota työtä tehdään mm. European Health Data Spacen (EHDS) puitteissa.
ELIXIR Suomi on tiiviisti mukana mm. seuraavissa kansainvälisissä hankkeissa ja aloitteissa:
Lisäksi ELIXIR Suomi osallistuu suuriin julkisen ja yksityisen sektorin kumppanuuksiin, kuten Innovative Medicines Initiative (IMI2) BIGPICTURE-projektiin (2021-27), joka rakentaa laajaa digitaalista patologiakuvavarastoa.
Esimerkkejä ELIXIR Suomen rahoittajista, yhteistyökumppaneista sekä hankkeista:









Yhdistämällä perimästä saatavaa tietoa eli genomitietoa kansallisissa terveydenhuollon rekistereissä olevaan dataan, voidaan kehittää tekoälymalli, jolle voidaan esittää kysymyksiä mahdollisista tulevaisuuden sairaalahoidoista. Tällaiset tilastolliset ja koneoppimisen mallit kykenevät ennustamaan sairauksien esiintymistä.
Apulaisprofessori Andrea Ganna Helsingin yliopiston Suomen molekyylilääketieteen instituutista (FIMM) on kiinnostunut geneettisen ja tilastollisen datan yhdistämisestä.
”Terveydenhuollossa voidaan hyödyntää koneoppimista, koska se oppii koko ajan valtavasta datamäärästä. Tekoälylle voidaan esittää kysymyksiä tulevaisuuden mahdollisiin sairaalahoitoihin liittyen. Tekoäly voi kertoa, mikä on elinajanennuste tai kuinka paljon reseptilääkkeet maksavat tietynlaisella elämäntyylillä ensi vuonna. ”
Ganna on hyödyntänyt suuria aineistoja tunnistaakseen demografisia ja geneettisiä tunnusmerkkejä, jotka ovat yleisten ja monitekijäisten tautien taustalla. Tekoäly voi tehdä jokaiselle henkilökohtaisen riskilaskelman, joka tehdään mallintamalla sairauksien ja lääkitysten pitkittäisseurannasta saatua dataa yhdessä geeni-, perhe- ja väestödatan kanssa.
Ganna käyttää tutkimuksissaan erityisesti FinRekisterit-aineistoa. FinRekisterit on Terveyden ja hyvinvoinnin laitoksen (THL) ja Suomen molekyylilääketieteen instituutin yhteinen tutkimusprojekti, jonka vastuututkijana toimii tutkimusprofessori Markus Perola. Se on yksi maailman laajimpia rekisteridatan toisiokäyttöön perustuvia tutkimuksia.
”Datakokoelmassa on 7,2 miljoonaa yksilöä eli kaikki Suomen kansalaiset sekä osa jo kuolleita sukulaisia. Siinä on paljon erilaista ja monipuolista tietoa. Saatavilla on terveystietoa, tietoja perhesuhteista, sosio-ekonomista tietoa, laboratoriotuloksia ja lääkereseptejä. Tämä on todella laaja datakokoelma.”
Aineistossa on 19 eri maanlaajuista rekisteriä, kuten Syöpärekisteri, Lääkeostorekisteri ja Kanta. Kanta on rekisteri, johon kerätään terveydenhuollossa ja apteekeista saatuja asiakas- ja potilastietoja. Kokoelmassa yksinomaan lääkeostoja on rekisteröity kokoelmaan yli miljardi. Ne ovat datapisteitä eli jokainen yksittäinen fakta on datapiste. Niitä datakokoelmassa on yhteensä yli 6,5 miljardia.
”Pidän hanketta ainutlaatuisena. Data on rikasta ja monipuolista”, sanoo Ganna.
”Terveystiedon yhdistäminen sosiaaliseen ja ekonomiseen informaatioon on minulle erittäin olennaista. Monesti näitä pidetään erillisinä, mutta tietojen yhdistäminen on erittäin tärkeää terveydelle. Meidän täytyy tarkastella sosio-ekonomista tietoa ymmärtääksemme kuinka ”reiluja” tekoälymallit ovat. Emme halua tekoälymallia, joka tekisi työnsä huonoimmin väestömme kaikkein haavoittuvimmissa osissa.”

Kun data on kerätty eri rekistereistä, yksilölliset tiedot salataan ja tallennetaan Suomen ELIXIR-keskuksen CSC:n sensitiivisen datan palveluihin. Ganna tutkimusryhmineen analysoi dataa tässä tietoturvallisessa ympäristössä.
”Olemme yhteistyössä CSC:n kanssa kehittäneet palveluja hyödyllisemmiksi tutkijoille. Olemme aloittaneet yksinkertaisista analyyseista kulkien kohti monimutkaisempia malleja.”
Andrea Gannan tutkimuksissa sensitiivistä dataa on valtava määrä.
”Luomme datamatriisin tekoälyä ja koneoppimisen malleja varten. Olemme myös hyvin tietoisia datan sensitiivisestä luonteesta. Emme pysty tunnistamaan yksilöitä ja käytämme erittäin kehittyneitä turvatoimia estääksemme luvattoman pääsyn dataan.”
Näitä tietoja voidaan käyttää eri tarkoituksiin.
”Saamme paremman ymmärryksen eri tautiryppäistä ja parempia ennusteita. Voimme laatia jopa digitaalista ikääntymistä kuvaavan kellon. Siinä käytetään koko väestön dataa, jotta voisimme antaa jokaiselle Suomen kansalaiselle eräänlaisen digitaalisen iän, joka perustuu terveystiedoista saadulle suuntaa-antavalle kehityskululle.”
Suunnitteilla on, että Ganna tutkimusryhmineen integroi rekisteridataa biopankeissa olevaan genomidataan. Kunnianhimoisena tavoitteena on tunnistaa yksilöissä kehittyviä sairauksia, joiden puhkeaminen voitaisiin estää. Tulevaisuudessa datan perusteella voitaisiin löytää riskiryhmään kuuluvia yksilöitä, jotka voisivat hyötyä ennaltaehkäisevistä lääkehoidoista. Andrea Gannan mukaan dataa on jo tarpeeksi, jotta tämä olisi mahdollista. Yhtenä hyvänä esimerkkinä tutkimusaineistosta Ganna mainitsee FinnGen-tutkimushankkeen, joka on tuottanut genomitietoa puolesta miljoonasta suomalaisesta. Hankkeessa on selvitetty suomalaisen väestön eri sairauksien geneettistä taustaa. Seuraavaksi on alettu selvittää, miten geenit vaikuttavat sairauksien etenemiseen.
”Biopankeissa oleviin, riskiryhmään kuuluviin ihmisiin voitaisiin olla yhteydessä. Tämä tietysti edellyttää että biopankeissa olevat ihmiset ovat antaneet kontaktointiin suostumuksensa.”

Gannan mielestä CSC:n sensitiivisen dataan liittyviä palveluita pitäisi pystyä kehittämään siihen suuntaan, että ne tukisivat erityisesti koneoppimisen malleja. Toistaiseksi tekoälymalleja on kokeiltu vain tutkimuksessa koska nykyisen lainsäädännön puitteissa ei voida automaattisesti käyttää rekisteridataa, jotta voitaisiin ottaa uudelleen yhteyttä riskiryhmään kuuluviin ihmisiin.
”Voimme laatia näitä kauniita malleja, mutta emme voi varoittaa riskiryhmäläisiä,” Ganna toteaa, mutta huomauttaa, että jos malleja yksinkertaistetaan tarpeeksi, niitä voidaan käyttää myös kliinisessä hoidossa.
Yhtenä esimerkkinä hän mainitsee RS-viruksen, jonka riskitekijöitä THL:n Markus Perola yhdessä FIMM:n Pekka Vartiaisen kanssa tutki FinRekisterit-hankkeessa. RS-virus (respiratory syncytial virus) on maailmanlaajuisesti yleisin pienten lasten hengitystieinfektioita aiheuttava virus. Tutkijat loivat yksinkertaistetun mallin, jota voitaisiin hyödyntää RSV:n kliinisessä hoidossa. Nyt Suomessa lääkärit voivat rekisteridatan perusteella tunnistaa, ketkä ovat vaarassa saada viruksen ja kenelle voisi antaa ajoissa hoitoa.
Andrea Ganna uskoo, että tulevaisuudessa terveydenhuolto hyötyy tekoälymalleista, joka ymmärtää terveysdataa.
”Tekoäly tukee päätöksentekoa auttamalla lääkäreitä paremmin tekemään yhteenvetoja heidän potilaidensa terveyden kehityskuluista. Tulevaisuus on valoisa.”
Ari Turunen
30.5.2024
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). An AI model that understands health data warns of future diseases. https://doi.org/10.5281/zenodo.13691998
Lisätietoja:
Suomen molekyylilääketieteen instituutti (FIMM)
FIMM on osa Helsingin yliopiston HiLIFE Helsinki Institute of Life Science -tutkimuskeskusta.
https://www.helsinki.fi/en/hilife-helsinki-institute-life-science/units/fimm
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
Solujen mallintaminen ja niiden toiminnan simuloiminen parantaa huomattavasti henkilökohtaisia hoitosuunnitelmia. PerMedCoE- hankkeessa yhdistetään kliinistä potilastietoa geenien ja proteiinien ja solujen toimintaan liittyvään tietoon. Tavoitteena on kehittää täsmälääketieteessä käytettäviä työkaluja. Solujen mallintaminen yksityiskohtaisesti on kuitenkin valtava urakka ja vaatii paljon supertietokoneiden laskentatehoa.
Yksilöity lääketiede avaa tulevaisuudessa suuria mahdollisuuksia. Tavoitteena on, että potilaan kliininen data voidaan yhdistää geneettiseen dataan ja näiden tietojen pohjalta voidaan laatia yksilöllisiä hoitosuunnitelmia. PerMedCoE– hankkeessa (HPC/Exascale Centre of Excellence in Personalised Medicine) pyritään parantamaan yksilöidyn lääketieteen mallinnusohjelmistojen yhteensopivuutta eksaskaalan supertietokonejärjestelmiin. Eksaskaalan supertietokoneet ovat seuraavan sukupolven järjestelmiä joiden teoreettinen laskentateho vastaa jopa 10^18 laskutoimitusta sekunnissa. Hankkeeseen osallistuu tutkijoita useasta eurooppalaisesta yliopistosta ja sairaalasta. Projekti keskittyy neljään avoimen lähdekoodiin perustuvaan solutason mallinnusohjelmistoon. Ohjelmistokehityksen lisäksi tutkimushankkeessa pyritään edistämään täsmälääketieteen työkalujen helppokäyttöisyyttä ja toimivuutta useissa eurooppalaisissa suurteholaskentakeskuksissa.
”Tavoitteena on että nämä neljä ohjelmistoa pystyisivät tulevaisuudessa toimimaan useassa supertietokoneessa”, sanoo CSC:n projektipäällikkö Sampo Sillanpää.
”Tällä hetkellä tämä on teknisesti hyvin haastavaa toteuttaa, koska jokainen suurteholaskentaympäristö on omanlaisensa johtuen järjestelmäarkkitehtuurista.”
Ohjelmistojen ja datamassojen saumaton toiminta on tarkoitus saavuttaa yhteisesti sovituilla teknologioilla. PerMedCoE-hankkeessa tämä toteutetaan ns. konttitekniikan ja työvuo-ohjelmistojen avulla. Työvuo on tutkimusprosessin automaatio, jonka aikana dokumentteja, tietoa ja tehtäviä siirretään suoritettaviksi tiettyjen sääntöjen mukaisesti. Konttitekniikan avulla voidaan määrittää vakioitu ympäristö, jossa tieteellisiä ohjelmistoja ajetaan jokaisessa hankkeeseen osallistuvassa suurteholaskentaympäristössä. Kun ohjelman koodi kirjastoineen ja asetuksineen asetetaan konttiin, sitä voidaan siirrellä koneelta ja konesalista toiseen.
”Ohjelmistot ja data on tavallaan paketoitu omaan laatikkoonsa, jotta niitä voidaan siirtää ympäristöstä toiseen. CSC:llä on useita konttitekniikan asiantuntijoita, joten työkaluja pystytään siirtämään alustalta toiselle”, Sillanpää sanoo.
”Kontteja hyödyntämällä asiantuntijat pystyvät rakentamaan käyttäjäystävällisiä työnkulkuja, eli työvoita. PerMedCoE-hankkeessa työvuot koostuvat useammasta rakennuspalikasta, joista jokainen toteuttaa tietyn täsmälääketieteen laskentatehtävän. Yhdessä rakennuspalikassa voidaan tehdään esikäsittelyä datalle, toisessa varsinainen analyysi ja viimeinen antaa tuloksen loppukäyttäjälle. Käyttäjän ei siis välttämättä tarvitse huolehtia miten useasta rakennuspalikasta rakennettu automatisointi toimii, vaan keskittyä tulosten tulkintaan.”

Hankkeessa rakennettujen teknologioiden hyödyllisyyttä arvioidaan erilaisten käyttötapausten avulla. Työvoiden avulla analysoidaan, mitä häiriöitä taudit voivat aiheuttaa solutasolla tai miten lääkeaineet toimivat. Mallien avulla voidaan tutkia solujen aineenvaihduntaa tai signaalinvälitystä.
”PerMedCoE-käyttötapauksissa hyödynnetään julkisesti saatavilla olevia genomidata-aineistoja. Nyt voimme tutkia koronaviruspotilaista otettuja näytteitä ja etsiä genomidatasta sellaisia markkereita, jotka ilmentävät, mitkä potilasryhmät ovat erityisen alttiita taudin vaaralliselle muodolle.”
Projektissa mallinnetaan ihon epiteelikudosta, joka reagoi koronavirustartuntaan kutsumalla erilaisia immuuneja soluja vaikuttamaan virukseen. Näin voidaan mahdollisesti paremmin tunnistaa sellaisia potilasryhmiä, jotka ovat alttiita koronan vakavalle tautimuodolle.
“Ajatuksena on, että pystytään rinnakkain ajamaan useita malleja yksittäisille potilaille. Näin voidaan tehokkaasti analysoida riittävän suuria datamääriä, jotta mallinnustuloksia voitaisiin käyttää yksilöidyn lääketieteen apuna”, sanoo vanhempi datatieteilijä Jesse Harrison CSC:stä.
COVID 19-käyttötapauksen mallinnuksessa käytetään solutason RNA-sekvenssidataa. RNA-sekvensointi yhden solun tarkkuudella (scRNA-seq) voi paljastaa geenien välisiä säännöllisiä vuorovaikutusyhteyksiä, solujen syntyperälinjat, solujen eroavaisuuksia sekä solun viitekehyksen ympäristössään.

Toinen tärkeä projektin käyttötapaus on syöpädiagnostiikka. Tavoitteena on luoda mallinnustyökaluja syöpäkasvainten kasvun ennustamiseen ja potilaskohtaisten hoitojen kehittämiseen. Aineistona käytetään Wellcome-instituutin ja Massachusettsin syöpäkeskuksen keräämää aineistoa. Tietokantaan on kerätty yli tuhat erilaista kasvainkudoksen solulinjaa.
”Projektissa pyritään esimerkiksi tunnistamaan uusia lääkeyhdistelmiä, jotka voisivat olla syöpähoidossa hyödyllisiä” Jesse Harrison sanoo.
Tämä johtaisi toivottavasti potilaskohtaisten syöpähoitojen tarkempaan kohdistamiseen ja diagnostiikan nopeutumiseen.
”Jotta nämä tavoitteet täyttyisivät läheisempää yhteistyötä tarvitaan suurteholaskentakeskusten ja lääketieteellisen organisaatioiden kanssa. Tämä siksi, koska nyt puhutaan isoista datamassoista ja suurten potilaskohtaisen datan analysointi ei ole omalla pöytäkoneella mahdollista.”
PerMedCoE:n tulokset ja työkalut on tarkoitettu kaikille tutkijoille.
“Kun projekti päättyy kesällä 2023, meillä on päivitettyjä versioita avoimen lähdekoodin pohjalta kehitetyistä mallinnustyökaluista ja ne saatetaan tutkijayhteisön saataville. Hankkeessa luodaan myös uutta osaamista tukemaan täsmälääketieteen työkalujen käyttöä CSC:n laskentaympäristöissä.”

EU rahoittaa monia projekteja, jotka tulevaisuudessa mahdollistavat yksilölliset potilashoidot. Syöpä on yksi esimerkki taudista, joka on erittäin yksilöllinen, oli kyse sitten rinta-, keuhko-, maksa-, tai eturauhassyövästä.
Esimerkiksi Horisontti Eurooppa -puiteohjelman Conquering Cancer: Mission Possible näyttää Suomen molekyylilääketieteen instituutin (FIMM) tutkijan Esa Pitkäsen mukaan suuntaa tulevaisuuden syöpätutkimukselle ja -hoidoille. Kunnianhimoinen ohjelma tavoittelee syöpien syntyyn johtavien mekanismien ymmärtämistä, uusia menetelmiä syöpien aikaiseen havaitsemiseen, sekä henkilökohtaisen eli yksilöidyn syöpälääketieteen läpimurtoja.
”Kaikille näille tavoitteille yhteistä on monipuolisen ja laajan terveysdatan hyödyntäminen uusien laskennallisten menetelmien avulla. Koneoppimiseen perustuvien tekoälyalgoritmien avulla onkin jo saavutettu rohkaisevia tuloksia esimerkiksi digitaalisen patologian alalla. Seuraavat harppaukset tehdään yhdistelemällä useita eri tietolähteitä yksilöllisten syöpäseulonta- ja hoitosuositusten antamiseksi”, Pitkänen uskoo.
Ohjelmassa syöpäpotilaat halutaan mukaan syöpähoitojen kehitykseen esimerkiksi antamalla potilaille mahdollisuuksia lähettää tietoturvallisesti omaa terveysdataansa tutkijoiden käyttöön. Samalla potilaat saavat myös uutta tutkimustietoa omasta sairaudestaan.
”On tärkeää, että hoitomuotojen kehittyessä pidetään huolta siitä, että ihmisille taataan tasa-arvoinen mahdollisuus hyötyä uusista hoidoista taustasta riippumatta. Olen iloinen siitä, että tämä on huomioitu ohjelman suosituksissa. Lisäksi lasten ja nuorten syöpiin kiinnitetään erityistä huomiota.”
Ari Turunen
23.8.2022
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Sampo Sillanpää, Esa Pitkänen, & Tommi Nyrönen. (2023). Personalised medicine against cancer and viruses. https://doi.org/10.5281/zenodo.8154548
Lisätietoja:
HPC/Exascale Centre of Excellence in Personalised Medicine
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC –Tieteen tietotekniikan keskus Oy.

Diabetes on iso kansansairaus, mutta suuri haaste on myös tautiin liittyvät muut sairaudet. Diabeteksen liitännäissairauksia ovat mm. diabeettinen munuaistauti, diabeettinen retinopatia, sekä sepelvaltimotauti ja aivohalvaukset. Nyt Suomessa sekvensoidaan diabetes-potilaiden koko perimä ja etsitään geneettisiä riskitekijöitä.
Diabeetikoilla sydänsairauksien riski on paljon suurempi muuhun väestöön verrattuna. Kolmannes tyypin yksi eli nuoruustyypin diabeetikoista saa munuaissairauden, joka vaikuttaa suuresti kuolleisuuteen ja osaltaan myös sydänsairauksien riskiin. Retinopatia on ollut puolestaan merkittävin sokeuden aiheuttajista työikäisessä väestössä.
Suomalaisilla on maailman korkein ykköstyypin diabeteksen riski lapsilla ja nuorilla aikuisilla. Tyypin II diabetes mielletään usein enemmän länsimaiden elintasosairaudeksi, mutta suurimmat potilasmäärät löytyvät keskituloisista maista, ja yksittäisistä maista tilaston kärjessä on Kiina ja Intia.

”Diabeteksen yhteydessä puhutaan isoista ja vakavista komplikaatioista. Nämä muut sairaudet vaikuttavat vahvasti sekä diabeetikon elämänlaatuun että elinajan odotteeseen,” sanoo geneettisen epidemiologian tutkija Niina Sandholm Folkhälsan-tutkimuskeskuksesta. Sandholm työskentelee FinnDiane-tutkimusprojektissa, jonka tavoitteena on löytää diabeteksen liitännäissairauksille altistavia perinnöllisiä ja ympäristöön liittyviä riskitekijöitä. FinnDiane-tutkimus on Helsingin yliopiston, HUS:n ja Folkhälsanin tutkimuskeskuksen yhteistyöprojekti.
Sandholmin mukaan geenitiedosta on hyötyä erityisesti nuorille potilaille jo varhaisessa vaiheessa ennen kuin riskitekijät ilmenevät.
”Tällä hetkellä geenitietoa hyödynnetään klinikassa lähinnä harvinaisten sairauksien tapauksessa, mutta ryhmämme tekemät ja aiemmin tehdyt tutkimukset tukevat kattavan geenitiedon hyödyntämistä myös yleisten sairauksien varhaisessa ennaltaehkäisyssä.”

Vuonna 1997 professori Per-Henrik Groopin perustama FinnDiane on seurantatutkimus, johon osallistuu jo lähes 8000 diabetekseen sairastunutta. Potilasaineisto on saatu 80 sairaalasta ja terveyskeskuksesta eri puolilta Suomea. Se on yksi maailman laajimmista tyypin 1 diabeteksen ja sen liitännäissairauksien tutkimusaineistoista. Nyt tästä aineistosta sekvensoidaan 1700 potilaan koko perimä eli genomi.
Sandholm on aiemmin osallistunut tutkimusprojekteihin, joissa menetelmänä oli genominlaajuinen assosiaatiotutkimus (GWAS). Sitä käytetään erityisesti silloin, kun sairauden geneettinen tausta on monitekijäinen. Menetelmän avulla voidaan löytää sairastumisriskiä lisääviä tai sairaudelta suojaavia geenivariantteja. GWAS-menetelmässä osallistujien verinäytteistä mitataan geenivariantteja, joiden määrä vaihtelee sadoista tuhansista miljooniin. Potilaita on tuhansista satoihin tuhansiin.

Yli 5600 FinnDiane-potilaista tehty, toistaiseksi laajin sydänsairauksia ykköstyypin diabeetikoilla käsittelevä GWAS- tutkimus paljasti esimerkiksi uuden sydänsairauksiin liittyvän geneettisen lokuksen lähellä DEFB127-geeniä. Lokus on DNA-jakson sijaintipaikka kromosomissa. Jakson vaihtelua kutsutaan alleeliksi.
Samassa tutkimuksessa, jossa löydettiin DEFB127-geeni, löydettiin myös muita sydänsairauksille altistavia perintötekijöitä.
”Sydänsairauksille, kuten muillekin yleisille sairauksille on löydetty paljon altistavia perintötekijöitä, joista yksi vahvimmista sijaitsee geenien CDKN2A ja CDKN2B alueella. Diabeetikoilla sydänsairauksien riski on paljon suurempi kuin muussa väestössä eikä niiden perintötekijöistä tiedetä paljoa, mutta näytimme tässä tutkimuksessa, että tuo sama CDKN2A/B geenialue vaikuttaa sydänsairauksien riskiin myös ykköstyypin diabetesta sairastavilla.”
Kolmanneksella tyypin yksi diabeetikoista saa munuaistaudin. Joillekin voi kehittyä munuaisen vajaatoiminta, joka pahimmillaan voi johtaa keinomunuaishoitoon tai munuaisen siirtoon.
Toisessa tutkimuksessa analysoitiin eri datalähteitä yhdistäen 27 000 diabetekseen sairastuneen yhteyksiä munuaistautiin. GWAS on nopea ja taloudellinen menetelmä, mutta kaikkia variantteja ei sen avulla löydetä. Tätä yritetään nyt potilaan koko genomin sekvensoinnilla.
”GWAS-menetelmällä löydetyt variantit ovat useimmiten yleisiä, ja yksittäisten varianttien vaikutus sairastumisriskiin on varsin maltillinen. Sekvensoinnin tavoitteena on löytää harvinaisia variantteja, joilla voi olla yksilön kohdalla huomattavan suuri vaikutus sairauden puhkeamiselle. Pahimmillaan tällainen variantti voi estää koko proteiinin toiminnan.”
Sandholmin mukaan tutkimustulokset voivat auttaa sairastumisriskin ennakoimisessa tai viitoittaa tietä uusien lääkeaineiden kehittämiseksi.
”Laajempana tavoitteena geenitutkimuksessa on löytää sairastumisriskiin vaikuttavia tai sairauden aiheuttavia variantteja, jotta ymmärtäisimme paremmin diabeteksen liitännäissairauksien syntymekanismeja. ”
Pohjimmaisena tavoitteena on oppia ehkäisemään ja parantamaan diabeteksen liitännäissairaudet.
”Nyt luetaan koko DNA-sekvenssi kaikilta potilailta. Dataa tulee hirmuinen määrä,” Sandholm korostaa.
”DNA-dataa saadaan sekvensointilaitteesta 150 emäsparin pätkinä kerrallaan. Tavoitteena on lukea jokainen DNA:n kolmesta miljardista emäsparista keskimäärin 30 kertaa tiedon varmistamiseksi, joten näitä 150 emäsparin pätkiä tulee yli 600 000 kullekin henkilölle.”
Sekvensoidut pätkät täytyy järjestää ihmisen referenssigenomin avulla oikeaan järjestykseen, jotta koko sekvenssi saadaan selvitettyä. Tämä vaatii valtavasti laskentakapasiteettia, jota saadaan Suomen ELIXIR-keskuksesta CSC:stä.
”Tarkoitus olisi saada aineisto sellaiseen muotoon, että pystyttäisiin tietämään kulloisellakin potilaalla, mitkä emäsparien muutokset eli variantit liittyvät mihinkin sairauksiin. Tavoitteena on se, että pystytään tunnistamaan harvinaisia variantteja, joita ei löydy GWAS-menetelmällä. Harvinaisia variantteja löytyy aineistosta vain muutamalta potilaalta.”
Variantit DNA:n emäsparijaksoissa eli snipit ovat tavallaan lopputulos datan käsittelystä.
”DNA-juoste on siis muutettu snippimuotoon eli kullakin potilaalla voi olla alleeleja nolla, yksi tai kaksi varianttia. Nämä toimivat markkereina jotka selittävät mitä sairauksia variantti voi aiheuttaa.”
Tutkimusryhmä on jo saanut sekvensoitua 600 potilaan koko genomin.
”Alustavia tulosten perusteella esimerkiksi aivohalvauksille löydettiin yksittäisiä variantteja, jotka selvästi liittyvät aivohalvauksien riskiin. Muutoksia löytyy myös geeneissä, jotka on aiemmin liitetty synnynnäisiin munuaissairauksiin. Näiden ei ole ajateltu siis aiemmin liittyneen diabetekseen mutta jotka aiheuttavat erilaisia munuaisvaurioita. Nyt näyttää, että samoissa geeneissä olevat variantit myös vaikuttavat diabeettisen munuaistaudin syntyyn.”
Niina Sandholm ja hänen kollegansa tutkivat myös geenin proteiinia koodaavia osia sekä geenien säätelyalueita, jotka voivat liittyä sairauden riskitekijöihin.
”Geenien välissä oleva alue – 95% genomista – sisältää paljon säätelyalueita mikä kertoo, mikä geeni ilmentyy missäkin kudoksessa. DNA sinällään on sama ihmisen jokaisessa solussa, mutta geenien säätely aiheuttaa sen, että silmistä tulee silmät ja munuaisista munuaiset. Tässä nämä geenien säätelyalueet ja niiden muutokset ovat avainasemassa. ”
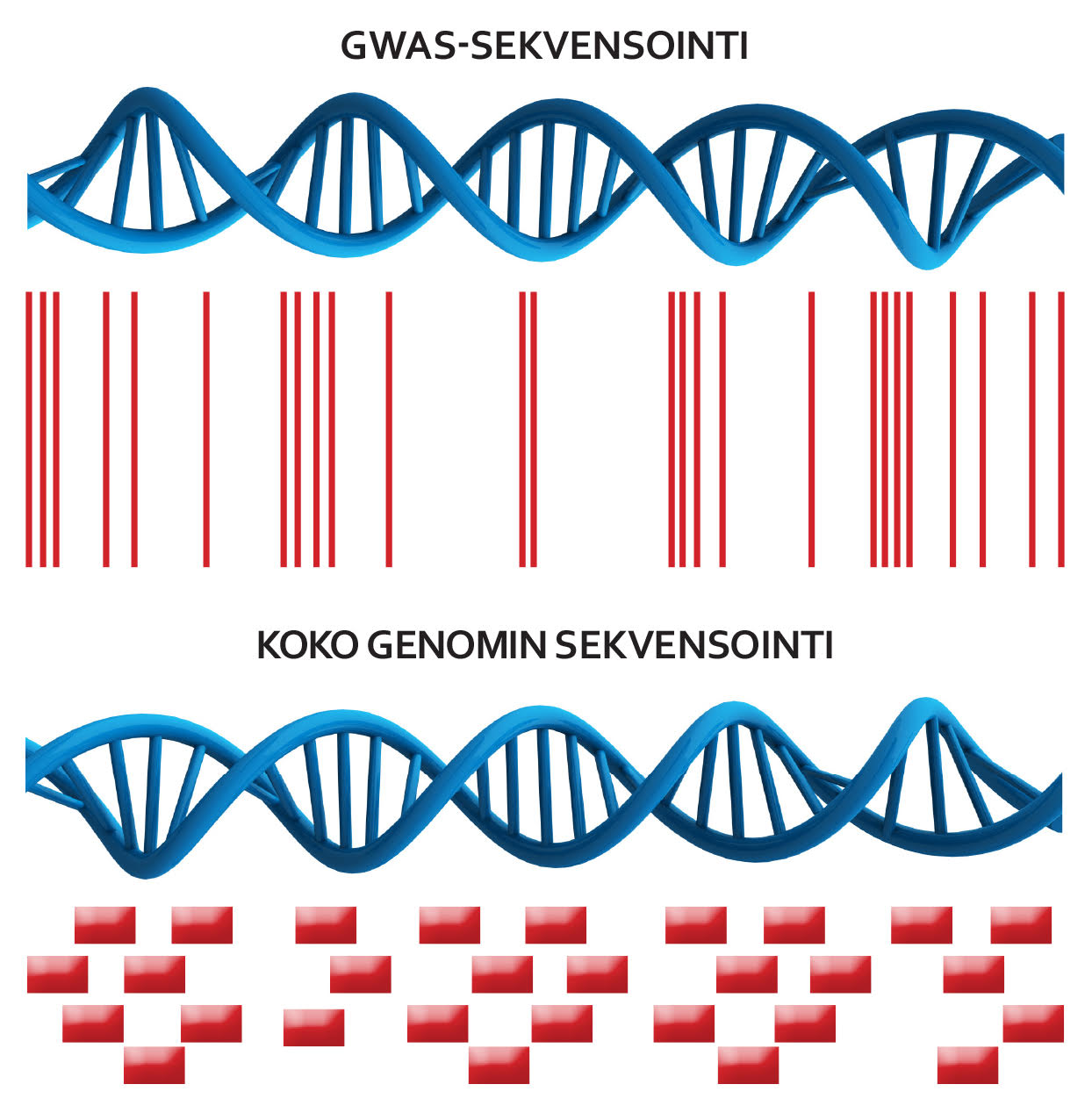
Tämä on maailmanlaajuisesti ensimmäisiä ja poikkeuksellisen laaja genomin sekvensointiprosessi. Toistaiseksi hyvin vähän on tehty koko genomin sekvensointia.
”Nyt trendinä on koko eksomin sekvensointi, jossa keskitytään proteiinia koodaavin osiin. On vain ajan kysymys milloin kuitenkin näitä koko genomin sekvensointeja aletaan tehdä lisää. Myös ELIXIR panostaa ja kehittää koko genomin käsittelymenetelmiin ja genomidatan työstämismenetelmiä.”
CSC tarjoaa ePouta-palvelua sensitiivisen datan käsittelyyn. Virtuaalipalvelimet toimivat CSC:n laskenta-alustalla korotetun tietoturvan ePouta-pilvipalvelussa. Käyttäjän tarvitsemat pilviresurssit on yksilöity ja varattu asianomaiselle käyttäjälle, eriytettynä CSC:n muusta laskentaympäristöstä. FinnDianen tutkimusryhmä käyttää Suomen molekyylilääketieteen instituutin FIMM:n laskentaklusteria, joka on yhdistetty CSC:n sensitiivisen datan laskenta-alustaan ePoutaan valopolun kautta. Valopolku mahdollistaa projektin käyttämän datan nopeamman käsittelyn, koska laskentaresurssit skaalautuvat. Tutkijoille on lisäksi allokoitu merkittävä tallennustila, jossa genomitiedot ovat.
Ari Turunen
3.2.2022
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Niina Sandholm, & Tommi Nyrönen. (2022). Finnish research team sequences the genomes of thousands of individuals with diabetes to look for genetic risk factors. https://doi.org/10.5281/zenodo.8154493
Lisätietoja
Folkhälsan
FinnDiane
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC –Tieteen tietotekniikan keskus Oy.

Glaukooma eli vanhalta nimeltään silmänpainetauti on näköhermon etenevä sairaus, joka aiheuttaa vaurioita näköhermonpäähän ja hermosäiekerrokseen. Riski sairastua glaukoomaan suurenee iän myötä. Glaukoomaa esiintyy yli 50-vuotiailla noin 2%:lla ja yli 75-vuotiailla yli 5 %:lla. Maailmassa on arviolta yli 60 miljoonaa glaukoomaa sairastavaa potilasta, heistä noin 6 miljoonan arvioidaan olevan näkövammaisia.
Haasteena taudissa on, että glaukooma on usein alkuvaiheessa täysin oireeton tai vähäoireinen. Koska vaurioita ei voida korjata, tauti tulisi löytää mahdollisimman varhain. Hoidon tavoitteena on ehkäistä glaukoomasta johtuvaa näkövammaisuutta. Suurimmalla osalla potilaista tautimuutokset etenevät hitaasti vuosien aikana. Pienellä osalla potilaista tauti voi johtaa vaurioihin jo lyhyessä ajassa.
Glaukooman havaitsemisen ja etenemisnopeuden tunnistamiselle olisi tärkeää, että terveydenhuollon järjestelmien avulla löydettäisiin mahdollisimman varhain suuren riskin tapaukset. Glaukooman varhaisen havaitsemisen avuksi on nyt kehitteillä tekoälymalleja.
Tutkija ja projektipäällikkö Ara Taalas on erikoistunut datatieteeseen, tekoälyyn ja koneoppimisen algoritmeihin lääketieteessä. Yksi hänen tutkimuskohteistaan on kehittää tehokkaita oppivia algoritmeja glaukooman havaitsemiseen Suomen molekyylilääketieteen instituutin (FIMM) ja Terveystalon yhteisessä projektissa. Aiemmin Taalas on mallintanut kantasolujen erilaistumisprosesseja ja tehnyt lääkeainesuunnittelua.
Terveystalon erikoisalajohtajan ja ylilääärin Matti Seppäsen mukaan glaukooman diagnoosi ja luokittelu perustuvat näköhermon pään, hermosäiekerroksen ja kammiokulman tutkimiseen, silmänpaineen mittaamiseen sekä näkökenttätutkimukseen.
”Glaukooman tarkkaa syntymekanismia ei tunneta, mutta todennäköisesti glaukoomavaurioiden taustalla ovat vauriot hermosolujen rakenteissa.”
Todennäköisesti noin 30-50 prosentilla potilaista silmänpaine on niin sanotulla normaalialueella (10-21 mmHg). Potilailla on yksilöllinen alttius glaukoomavaurioiden kehittymiseen eri painetasoilla. Osalla potilaista syntyy glaukoomavaurioita alhaisemmalla painetasolla, osalla potilaista muutokset voivat olla vähäisiä vaikka painetaso olisi suurempi.
”Nykyisin glaukoomadiagnoosiin tarvitaan silmälääkärin tutkimus ja useita lisätutkimuksia. Näköhermon päätä voidaan tutkia mm. biomikroskopian ja stereopapillakuvauksen avulla. Hermosäiekerrosta voidaan arvioida esim. värisuodatetun silmänpohjakuvauksen tai hermosäiekerroksen valokerroskuvauksen (ns. OCT-tutkimus) avulla. ”
Tutkimuksissa glaukoomaepäily voi herätä esimerkiksi näköhermonpään muodon perusteella. Näköhermonpään rakennetta voidaan arvioida ns. cup/disc –suhteen mittauksella, jossa näköhermon keskuskuopan suuruutta verrataan näköhermonpään ulkoreunan suuruuteen.
”Hermosäiekerroksen vauriot voivat tulla esiin hermosäiekerroksen valokerroskuvauksessa ohentuneena hermosäiekerroksena. Silmänpohjan värisuodatetussa valokuvauksessa voidaan myös saada esiin hermosäiekerroksen puutoksia. Glaukoomadiagnoosi perustuu usein useaan eri tutkimukseen ja tällä hetkellä ei ole saatavilla yksittäistä tutkimusmenetelmää, jonka avulla glaukooman seulontaa väestötasolla olisi päästy toteuttamaan. Tekoälysovellukset voivat tulevaisuudessa tuoda seulontaan ja diagnostiikkaan merkittävää apua.”
Esa Pitkänen Molekyylibiologian instituutista FIMM:stä (Helsingin yliopisto) kertoo glaukooman tutkimisesta algoritmien avulla.
Ara Taalaksen mielenkiinnon kohteena tekoälymallia kehitettäessä on mm. silmänpohjan hermokerrosten kuvautuminen kuvantamistutkimuksissa. Algoritmin avulla pyritään havaitsemaan silmänpohjakuvista niitä muutoksia, jotka voivat viitata hermosäiekerroksen vaurioon. Mallin avulla pyritään selvittämään, voivatko silmänpohjan hienosyiset verkottuneet muutokset muuttuessaan tummemmiksi ja monotonisiksi olla yhteydessä hermosäiekerroksen vaurioon.
”Tämä on yksi tekijöistä, joihin malli on kohdennettu. Jatkossa mallille opetetaan lisää silmänpohjan hermosäikeiden kuvioita. Tällaisten algoritmien tavoitteena on pyrkiä löytämään keinoja, jotka auttavat kehittämään päätöksentukijärjestelmiä lääkärin työhön. Pitkälle kehittynyt keinoäly voi löytää muutoksia, joita kokenutkaan kliinikon silmä ei välttämättä havaitse.”

Silmän rakennetta ja toimintaa mittaavissa tutkimuksissa esiintyy vaihtelua, joka johtuu käytössä olevasta tutkimusmenetelmästä, arvioijan kokemuksesta, tutkittavasta sekä taudin vaikeusasteesta. Näköhermon pään arvioimisella ei saavuteta aina riittävää tarkkuutta nykyisillä menetelmillä. Näkökenttätutkimus voi olla normaali, vaikka näköhermossa ja hermosäiekerroksessa esiintyisi vaurioita. Tämä johtuu siitä, että rakennevauriot tulevat yleensä ennen kuin näkökenttäpuutokset esiintyvät. Mikäli jatkossa pystytään kehittämään sovelluksia, jotka arvioivat aiempaa tarkemmin ja tehokkaammin rakenteellisia muutoksia, voidaan sillä varhaistaa glaukooman diagnostiikka.

Taalaksen mukaan eräänä sovelluskohteena mallille olisi, että tekoälymalli olisi käytettävissä aina kun tehdään näöntarkastus.
”Väestötutkimuksissa on todettu, että jopa puolet glaukoomaa sairastavista on tällä hetkellä diagnosoimatta. Nykyisillä seulontamenetelmillä ei ole päästy riittävän kustannusvaikuttavaan tulokseen ja yleisen väestöseulonnan esteenä on riittävän hyvien menetelmien puuttuminen.Jos keinoälysovellusten avulla pystytään riittävällä tarkkuudella tunnistamaan ne potilaat, joilla on keskimääräistä suurempi alttius sairastua glaukoomaan, voitaisiin oireettomasta väestöstä löytää sairaus helpommin jo niin varhaisessa vaiheessa että sen hoito olisi mahdollisimman tehokasta.”
Yhtenä tulevaisuuden visiona on, että esimerkiksi optikkokäynnin tai terveydenhoitajan tutkimuksen yhteydessä voitaisiin ottaa silmänpohjakuvaus ja samassa yhteydessä keinoäly analysoisi potilaan silmänpohjakuvan. Jos keinoäly ilmaisisi potilaalla olevan tavallista suuremman riskin glaukoomaan sairastumiseen, voitaisiin potilas ohjata jo varhaisessa vaiheessa jatkotutkimuksiin.
Tekoälysovellusten avulla työnjako tullee merkittävästi muuttumaan optisella alalla ja silmäsairauksien diagnostiikassa. Tämä tarjoaa myös avaimia merkittävästi lisääntyvän potilasmäärän hoitoon. Väestön ikärakenteen muuttumisen myötä glaukoomaa sairastavien potilaiden määrä Suomessa kaksinkertaistuu nykytasosta vuoteen 2030 mennessä.
Taalas on Suomen ELIXIR-keskuksen CSC:n laskentapalvelujen käyttäjä. Hän kehittää malleja yhteistyössä FIMM:in Machine Learning in Biomedicine-ryhmän tutkijoiden kanssa, ja samaa lähdekoodia pystytään käyttämään ristiin CSC:n ja Terveystalon laskentapalvelimilla.
”Suomessa ollaan datanhallinnassa nyt korkealla tasolla, mutta potilaista ei ole yksittäisillä terveydenalan toimijoilla tyypillisesti kaikenkattavaa kuvaa – potilasdataa on usein hajautuneena useille eri toimijoille. Kun asiakas vaihtaa organisaatiota, data ei aina liiku perässä, mikä voi vaikeuttaa hoidonohjausta. Tutkijan kannalta olisi ihanteellista, mikäli meillä olisi valtakunnallisesti keskitetty paikka, josta kansalaisen potilashistoria löytyisi kokonaisuudessaan.”
Myös datan kuvaaminen pitäisi saada standardoiduksi.
”Potilastietojärjestelmien rakenne vaikuttaa vahvasti syntyvän datan käytettävyyteen. Vapaatekstikentät ovat usein järjestelmän käyttäjälle miellyttäviä, mutta tuottavat tiedon hyödynnyksessä runsaasti päänvaivaa data-analyytikolle. Analyytikko joutuu usein tekemään runsaasti työtä tiedon standardoimiseksi, ja virheellisten kirjausten tunnistamiseksi. Modernit potilastietojärjestelmät ovat tässä mielessä menneet eteenpäin aiemmasta maailmasta, ja rakenteisuus korostuu niiden tietorakenteissa.”
Ari Turunen
23.11.2021
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Lila Kallio, Arho Virkki, & Tommi Nyrönen. (2021). Patient data creating better artificial intelligence models. https://doi.org/10.5281/zenodo.8135413
Lisätietoja:
Suomen molekyylilääketieteen instituutti (FIMM), Helsingin yliopisto
Terveystalo
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Syväoppiminen on mullistanut syöpäsairauksien tutkimisen. Syvillä neuroverkoilla voidaan automaattisesti löytää potilaan näytedatasta piirteitä, joiden perusteella voidaan tunnistaa syöpiä. Oppivat algoritmit voivat tunnistaa jatkossa verinäytteestä mahdollisia syövän esiasteita. Esa Pitkänen ja hänen tutkimusryhmänsä Suomen molekyylilääketieteen instituutista kehittävät uuden sukupolven syväoppimisen algoritmeja.
Algoritmeja on hyödynnetty kudosnäytteiden leikekuvien solujen tunnistamisessa. Esimerkiksi jos kudoksen solut näyttävät epätyypillisiltä, algoritmi tunnistaa sen ja päättelee onko kyseessä syöpä. Nyt kuvantamisdatan rinnalla käytetään syöpien tunnistamisessa kasvaimista saatua DNA-sekvenssidataa.
”Aikaisemmin on ollut vaikea sanoa DNA-sekvenssin perusteella, minkälaisesta kasvaimesta sekvenssi on tullut. Nyt on luotu uusia tekniikoita ja syväoppimisen algoritmeja”, sanoo tutkija Esa Pitkänen.
Pitkänen ryhmineen kehittää algoritmeja, jotka tunnistavat DNA-sekvensseistä lyhyitä, toisteisia pätkiä. Algoritmien avulla voidaan löytää pätkiä, jotka mutatoituvat tietyssä syöpätyypissä usein tai joihin tietyt geenien säätelyyn osallistuvat proteiinit sitoutuvat. Näitä pätkiä analysoimalla voidaan saada tietoa esimerkiksi syöpäsairauksien syiden kartoittamiseen ja lääkkeiden kehittämiseen.
”DNA:n kopioituminen solun jakautumisen yhteydessä ei ole täydellistä. Kun solu jakautuu niin on mahdollista, että mutaatioita syntyy. Kun solu jakautuu, kopioitavaa DNA:ta on kuuden miljardin merkin verran eli virheitä tapahtuu. Pienikin todennäköisyys riittää että mutaatioita tulee”, sanoo Pitkänen.
”Jos riittävästi mutaatioita tapahtuu esimerkiksi kasvaimen syntyä ehkäisevissä geeneissä, syöpä voi alkaa kehittyä.”
Esimerkiksi pistemutaatiossa yksi emäs vaihtuu toiseksi DNA-ketjussa. Virhe voi syntyä, kun solun jakautuessa DNA kopioidaan ja kopioinnista vastaavat entsyymit korjaavat esimerkiksi auringonvalon ultraviolettisäteilystä vaurioituneen kohdan väärin. Ihosyöpää aiheuttavan ultraviolettisäteilyn aikaansaama tyypillinen mutaatio on se, että ihmisen DNA:n emäspareissa kaksi peräkkäistä sytosiinia (C) muuttuvat kahdeksi tymiiniksi (T). Kun tällaisia, ihosyövälle tyypillisiä mutaatioita havaitaan riittävästi, oppivat algoritmit yhdistämään mutaatiot tiettyyn syöpätyyppiin.
”Yritämme ennustaa mutaatioiden perusteella mikä syöpätyyppi ja kasvain on kyseessä. Samalla saadaan tietoa, joka voi vaikuttaa hoitoon.”
Pitkänen ryhmineen analysoi sekvenssijaksoja ja algoritmeja opetetaan tunnistamaan sekvenssijaksojen poikkeavuuksia. Näistä poikkeavuuksista algoritmi pystyy tunnistamaan, että kyseessä on kasvain ja luokittelemaan kasvaimet eri syöpätyyppeihin.
“Ennen siirtymistäni Suomen molekyylilääketieteen instituuttiin olin Euroopan molekyylibiologian laboratoriossa EMBL Heidelbergissä, jossa osallistuin PCAWG-syöpägenomiprojektiin. Projektissa analysoitiin yli 2600 syövän kokogenomia. PCAWG-data toimii aineistona useassa ryhmäni syöpägenomiikkaa käsittelevissä projekteissa.”
Esa Pitkäsen ryhmän kehittämälle algoritmille on opetettu näiden 2600 syöpäpotilaan kasvainnäytteistä löydetyt löytyneet mutaatiot, joita on yhteensä 47 miljoonaa.
“Algoritmi on koulutettu siten, että se yrittää näistä sekvenssien muutoksista päätellä syöpätyypin. Kun algoritmille on annettu eri kasvainten kaikki mutaatiot sekvensseineen, se pystyy jatkossa päättelemään minkälainen kasvain on kyseessä. Päättely perustuu siihen, että algoritmi oppii nämä yhteydet.”
Algoritmi oppii kasvaimissa olevan sekvenssidatan poikkeamien kautta tunnistamaan, että kyseessä on tietylle syövälle olennainen mutaatio. Algoritmi pystyy ryhmittelemään kasvaimet pelkän sekvenssidatan perusteella.
”Ryhmässäni tutkija Prima Sanjaya on kehittänyt neuroverkkomalleja sekvenssidatan analysoimiseen. Silloin tällöin törmätään metastaattisiin eli levinneisiin syöpiin, josta ei tiedetä mistä se on levinnyt. Tulevaisuudessa voidaan hyödyntää myös ns. nestebiopsiaa. Tällöin pystytään toivottavasti verinäytteestä sanomaan, onko potilaalla syöpä ja jos on niin minkälainen.”

Nestebiopsia perustuu siihen, että elimistön solut vapauttavat verenkiertoon ja ruumiinnesteisiin DNA:ta, jota kutsutaan solunulkoiseksi tai soluvapaaksi DNA:ksi (cell free DNA, cfDNA). Myös syöpäsoluista vapautuu DNA:ta, joka mahdollistaa syöpämutaatioiden etsimisen veren plasmasta.
“Jos nestebiopsiassa näkyy jälkiä syövästä, emme tiedä suoraan mikä syöpä on kyseessä, koska se voi tulla verenkiertoon mistä vain kehosta. Jos meillä on keinoja katsoa tarkemmin, kuten syväoppimisen algoritmit, saamme arvokasta tietoa, mihin kohtaan potilaan kehossa tutkimus pitää suunnata. Algoritmi voi kehottaa katsomaan esimerkiksi paksusuoleen. Uskon, että tulevaisuudessa tällaisilla algoritmeilla on suuri merkitys. Nestebiopsian ja algoritmien ansiosta voidaan tehdä tutkimusta ilman potilasleikkauksia”
Syövän syntyyn vaikuttavat perintötekijöiden lisäksi elintavat. Helsingin yliopistossa on tutkittu paljon esimerkiksi suolistosyöpiä.
”Se tiedetään, että punaisen lihan syömisellä on yhteys paksunsuolen syövän syntyyn. Syntymekanismit vaativat vielä lisätutkimuksia mutta esimerkiksi punaisen lihan aiheuttamien DNA:n alkylaatioreaktioiden merkitystä on selvitetty viime vuosina paljon.”
Paksunsuolen syöpä (CRC) on yksi vaarallisimpia syöpiä länsimaissa ja johtaa 30% tapauksissa esimerkiksi Suomessa kuolemaan. Noin 15% paksunsuolen syövistä kuuluvat joukkoon, jossa esintyy ns. mikrosatelliiti-instabiliteettia (MSI). Mikrosatelliitit ovat DNA:n toistojaksoja, joiden pituus vaihtelee yksilöstä toiseen ja ovat siten yksilöllisiä “sormenjälkiä”. Mikrosatelliiti-instabiliteetissa solun DNA:n replikaation jälkeinen korjausmekanismi ei toimi, jolloin mutaatioita alkaa kertyä erityisesti mikrosatelliitteihin.
”MSI-kasvaimessa mikrosatelliitteihin tulee helposti yhden emäksen lisäyksiä tai poistoja. Esimerkiksi kahdeksan peräkkäisen adeniinin mikrosatelliitista häviää yksi adeniini. Osuessaan geeniin tällainen muutos aiheuttaa geenin koodaaman proteiinin aminohappoketjun sisällön muuttumisen täysin. Jos riittävästi muutoksia tapahtuu hallitsematonta solujakautumista estävissä geeneissä, saattaa syövän kehittyminen alkaa.”
MSI liittyy usein paksunsuolensyövän lisäksi muihin syöpiin, kuten vatsasyöpiin, kohdunrungon ja munasarjan syöpään tai aivosyöpään. Syövän ennusteen arvioinnissa voidaan käyttää apuna MSI-analyysiä. Analyysin perusteella on joskus mahdollista määrittää sopiva hoito.
”Mielenkiintoista on, että syvä neuroverkko oppii myös luokittelemaan eri syöpien alalajeja. Se tunnisti esimerkiksi suolisyöpien MSI-alatyypin”, Pitkänen sanoo.
Suomen ELIXIR-keskus CSC on yksi pääpartnereita PerMedCoE-hankkeessa. Kolmevuotisen HPC/Exascale Centre of Excellence in Personalised Medicine -hankkeen (PerMedCoE) avulla esimerkiksi syöpään liittyvä data saadaan tehokkaasti terveydenhoidon käyttöön ja diagnoosit nopeutuvat.
”Tulevaisuuden yksilöidyt hoidot kuten syöpähoidot rakentuvat täsmälliseen käsitykseen potilaasta ja hänen sairaudestaan. Tämä käsitys muodostetaan keräämällä suuri määrä erilaista tietoa, kuten syöpää hoidettaessa kasvaimen genomi- ja kuvantamistietoa. Monet tiedonkeruumenetelmät tuottavat valtavan määrän tietoa, joiden analysoimiseksi kehitetyt uudet laskennalliset menetelmät puolestaan vaativat suuria laskentaresursseja”, Pitkänen toteaa.
”Uuden laskennallisen menetelmän kehittäminen ideasta toimivaksi, terveydenhoidossa käytettäväksi työkaluksi on tällaisessa toimintaympäristössä valtava haaste. Erityisesti syöpähoidoissa on tärkeää, että potilaan hoitoon vaikuttava tieto saadaan lääkärin käyttöön mahdollisimman nopeasti. Uskon, että PerMedCoE:n tuloksilla luodaan pohjaa sille, että valtavasta terveystietomäärästä voidaan lääkärin avuksi jalostaa merkityksellistä tietoa ja näin parantaa hoitotulosta merkittävästi.”
Ari Turunen
16.9.2021
Lue artikkeli PDF-muodossa
Citation
Ari Turunen, Esa Pitkänen, & Tommi Nyrönen. (2023). Teaching an algorithm to identify cancer from sequence data. https://doi.org/10.5281/zenodo.8135303

Mutaatioiden lähteinä ovat 1.ulkoiset tekijät: esimerkiksi auringon UV-säteily. 2.sisäiset tekijät: spontaani deaminaatioreaktio eli emäksen amiiniryhmän muutos, jolloin alkuperäinen emäs muuttuu joksikin toiseksi, esimerkiksi adeniini urasiiliksi 3. DNA:n kopioinnissa aiheutuneet virheet.
Mutaatio tarkoittaa muutosta DNA:n tai RNA:n nukleotidijärjestyksessä. Nukleotidiin kuuluu emäs, sokeri ja fosfaatti. DNA:n sokeri on D-deoksiriboosi ja RNA:n D-riboosi. DNA:n emäksiä ovat guaniini (G), adeniini (A), sytosiini (C) ja tymiini (T). RNA:n emäsosassa tymiinin tilalla on urasiili (U). Mutaatio voi olla vain yhden nukleotidin muutos eli pistemutaatio, tai se voi käsittää useita nukleotideja. Pistemutaatiossa yksi emäs vaihtuu toiseksi RNA- tai DNA-ketjussa. Iso mutaatioita, jotka voivat käsittää tuhansia nukleotideja, kutsutaan rakennemuutoksiksi.
Rakennemuutos voi vaikuttaa yhtä aikaa useaan geeniin. Syövät ovat yleensä useiden somaattisten mutaatioiden aiheuttamia; somaattiset mutaatiot eivät periydy, ja niitä voi syntyä milloin tahansa alkionkehityksen aikana ja sen jälkeen. Mutaatioiden seurauksena normaalin solun toiminta voi muuttua siten, että solu alkaa jakautua hallitsemattomasti. rilaisia mutaatiotyyppejä mutaatioiden jakautuminen kromosomeihin epigeneettinen tieto. Epigeneettiseen periytymiseen vaikuttavat monet ulkoiset tekijät, kuten esimerkiksi ravinto. Esimerkiksi identtiset kaksoset, voivat kehittyä ulkoisilta olemuksiltaan erilaisiksi. Mutaatioiden mallintaminen lineaariset mallit syvät neuroverkot transformer-mallit. Transformerit ovat syväoppimismalliperhe, jotka toimivat erityisen hyvin esim. tekstimuotoiseen dataan, sovelluksena vaikkapa konekääntäminen. Syöpätutkimuksessa transformer-mallit voivat kiinnittää huomiota mutaatiotyyppeihin, jotka ovat tärkeitä tietyn syöpätyypin tunnistamiseksi. Esimerkiksi ihosyövissä, joissa on paljon auringonvalon aiheuttamia mutaatioita (C>T, CC>TT), huomio kohdistuu juuri näihin mutaatioihin.
Kuvassa keskellä erilaisia mutaatiotyyppejä ja miten mutaatiot jakautuvat kromosomeihin. Mutaatioihin liittyy epigeneettinen tieto. Epigeneettiseen periytymiseen vaikuttavat monet ulkoiset tekijät, kuten esimerkiksi ravinto. Esimerkiksi identtiset kaksoset, voivat kehittyä ulkoisilta olemuksiltaan erilaisiksi.
Mutaatioiden mallintaminen:
lineaariset mallit
syvät neuroverkot
transformer-mallit. Transformerit ovat syväoppimismalliperhe, jotka toimivat erityisen hyvin esim. tekstimuotoiseen dataan, sovelluksena vaikkapa konekääntäminen. Syöpätutkimuksessa transformer-mallit voivat kiinnittää huomiota mutaatiotyyppeihin, jotka ovat tärkeitä tietyn syöpätyypin tunnistamiseksi. Esimerkiksi ihosyövissä, joissa on paljon auringonvalon aiheuttamia mutaatioita (C>T, CC>TT), huomio kohdistuu juuri näihin mutaatioihin.
Lisätietoja:
HPC/Exascale Centre of Excellence in Personalised Medicine (PerMedCoE)
Suomen molekyylilääketieteen instituutti FIMM
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Uuden sukupolven geenien ja RNA-molekyylien analyysimenetelmät mahdollistavat entistä nopeammat ja vaivattomammat analyysit. Data saadaan myös hyvin talteen ja jaettavaksi tutkimusryhmille Suomen ELIXIR -keskuksen CSC:n Allas-käyttöliittymän kautta.
Uuden sukupolven sekvensointimenetelmien (NGS) avulla tutkitaan perimässämme olevia virheitä ja variaatiota sekä geenien ilmentymisen (ekspressio) muutoksia. Menetelmien tuottamien miljardien sekvenssipätkien analysointi on mahdollista kerralla yhdessä tietokoneajossa.
Uusien menetelmien avulla pystytään tutkimaan lukuisia geenejä ja kohteita useista eri näytteistä samanaikaisesti. Menetelmien avulla voidaan tehdä nopeasti yksittäisten solujen, kuten syöpäsolujen, analysointi. Nyt voidaan myös analysoida veren plasmasta eroteltu soluvapaa DNA, joka kertoo nopeasti ja luotettavasti valittujen hoitojen tehokkuudesta ja erityisesti siitä, onko etäispesäkkeitä jäljellä.
Suomen molekyylilääketieteen instituutin (FIMM) ja CSC:n alustoilla on käytössä erilaisia algoritmeja sekvensointiin perustuvien menetelmien, (eksomit, genomit ja trasnkriptomitn) tuottaman datan analysoimiseen. Yksi keskeisimpiä on Broad Instituten GATK -työkalupakki (Genome Analysis Toolkit). Sen avulla etsitään geenivariantteja ja tunnistetaan DNA- tai RNA-sekvenssin muutoksia solulinjassa. GATK -analyysiohjelmistosta on tullut bioinformatiikan standardi tiedeyhteisössä. GATK-ohjelmistot ajetaan huippunopean Dragen-alustan (Dynamic Read Analysis for GENomics) kautta. Suomen ELIXIR-keskus CSC ylläpitää Dragenia yhdessä FIMM:n kanssa. Dragen esiprosessoi datan eli kun ensimmäiset tulkinnat datasta on tehty, tehdään usein lisää analyysejä. Tällöin myös CSC:n tallennuskapasiteetista on hyötyä, koska analysoitu data ei mahdu tavanomaiseen tietokoneeseen vaan saadaan suoraan jaettua käyttäjille Allas-palvelun kautta. CSC:n ja FIMM:n yhteistyö on olennainen osa analyysien nopeaa läpimenoa.
”Kun käytössä ovat korkean kapasiteetin sekvensointitekniikan alustat, algoritmit ja laskentateho, saadaan erittäin nopeita tuloksia. Yksi genomi voidaan nyt analysoida jopa vuorokaudessa kun aikaisemmin siihen meni useita viikkoja”, sanoo Pekka Ellonen.
Ellonen on Suomen molekyylilääketieteen instituutin (FIMM) sekvensointiyksikön laboratoriopäällikkö. Yksikkö tuottaa tutkimusyhteisölle genomiikan (DNA) ja transkriptomiikan (RNA) analyysejä moderneilla menetelmillä. Yksikkö saa analysoitavakseen erilaisten tutkimusprojektien tuottamia näytteitä.
”Yhdessä tutkijoiden kanssa päätetään tarvittavista menetelmistä ja räätälöidään paras työkalupakki, jolla testataan tutkijoiden hypoteesia. Sellaisia menetelmiä voivat olla eksomisekvensointi, genomisekvensointi, erilaisten RNA-molekyylien (transkriptomi) sekvensointi sekä geeniekspressio,” sanoo Ellonen.
Näiden menetelmien avulla kudoksesta voidaan selvittää perimä (genomiikka) tai tunnistaa esimerkiksi kaikki kudoksessa ilmentyvät geenit (transkriptomiikka) ja proteiinit (proteomiikka). Genomin proteiinia koodaavan alueen eli eksomin sekvensointi auttaa esimerkiksi periytyvien tautien, synnynnäisten kehityshäiriöiden ja syövän tutkimisessa. Geenien ilmentymistä säädellään tarkasti soluissa ja muutokset voivat johtaa sairauksiin. Tutkimuksissa voidaan verrata esimerkiksi syöpäkudoksen ja terveen kudoksen geenien ilmentymisen eroja.

Uuden sukupolven sekvensointimenetelmät mahdollistavat monimutkaisten biologisten järjestelmien tutkimisen. Ellosen mukaan ylivoimaisesti suurin muutos bioinformatiikassa viime vuosina on ollut yksittäisten solujen analysointi. Yksittäisten solujen analyysi tapahtuu Suomen molekyylilääketieteen instituutin yksittäisten solujen analyyseihin erikoistuneen yksikön (SCA) sekä sekvensointiyksikön yhteistyönä.
Jokainen solu sisältää yksilön jokaisen geenin, mutta tietyt geenit ilmentyvät vain tietyissä soluissa sekä usein vain tietyissä olosuhteissa. Geenien ilmentyminen ja proteiinien tuotanto soluissa vaihtelee eri kehitysvaiheissa ja sairauksien vaikutuksesta. Se aiheuttaa muutoksia solujen ja kudosten toiminnassa. Yksittäisen solun analytiikka ei oikeastaan tarkoita yhtä solua.
”Nyt voidaan tutkia esimerkiksi syöpäsoluja yksittäisinä kohteina. Luotettavaan tulokseen ei riitä yhden solun DNA:n emäsjärjestyksen tai geeniekspression selvittäminen, vaan pitää tutkia tuhansien tai kymmenien tuhansien solujen otoksia”, sanoo Ellonen.
RNA-sekvensointi yhden solun tarkkuudella (scRNA-seq) voi paljastaa geenien välisiä säännöllisiä vuorovaikutusyhteyksiä, solujen syntyperälinjat, solujen eroavaisuuksia sekä solun viitekehyksen ympäristössään.
Sekvensointi yksittäisistä soluista paljastaa myös erilaisia ja jopa uusia solutyyppejä sekä geenien ilmentymiseen perustuvaa tietoa niiden toiminnallisuudesta. Yksittäisen solujen DNA-sekvensointi antaa puolestaan tietoja mutaatioista, jotka tapahtuvat pienissä solupopulaatioissa normaalien solujen seassa. Yksittäisen solun tarkkuus antaa tietoja kasvainten geneettisestä erilaisuudesta, mistä on apua hoidoissa.
”Elävien solujen määrä tutkittavassa näytteessä todennetaan laboratoriossa, jonka jälkeen kukin solu erotellaan omaan nestepisaraansa eli droplettiin mikä mahdollistaa yksittäisen solun DNA- tai RNA –molekyylien merkitsemisen molekyylikohtaisilla ja solukohtaisilla DNA-viivakoodeilla. Molekyylikohtaiset, solukohtaiset ja lopulta näytekohtaiset DNA-viivakoodit mahdollistavat sekä solunäytteen kuhunkin soluun kuuluvien molekyylien tunnistamisen sekä taloudellisesti tehokkaan sekvensoinnin,” kertoo FIMM Teknologiakeskuksen yksittäisten solujen analytiikan yksikön (SCA) johtaja Pirkko Mattila.
”Yhdessä sekvensointiajossa profiloidaan useista näytteistä kustakin tuhansia soluja kerrallaan. Näin saavutetaan tuhansien solujen tai jopa satojen tuhansien solujen analyysistä yhden solun resoluutio ja päästään tutkimaan yksittäisen solun ominaisuuksia.”
Nestemäinen biopsia tarkoittaa soluja tai solunosia sisältävän nestemäisen näytteen ottamista elävästä kudoksesta, kuten verestä. Nestemäinen biopsia on lupaava seurantatyökalu syövän hoitamiseen ilman kirurgisia toimenpiteitä.
”Luomme sekvenssikirjastoja genomialueista, joista ollaan kiinnostuneita eri syövissä,” Pekka Ellonen sanoo.
Nestemäistä biopsiaa voidaan käyttää syövän tunnistamiseen varhaisessa vaiheessa. Verinäytteestä saadaan tietoja kasvaimen syöpäsoluista tai niiden erittämistä DNA-fragmenteista, joita on mahdollisesti verenkierrossa.
”Kasvain on yleensä hankalassa paikassa, jolloin kasvaimen poistamiseksi ja näytteen pitää tehdä kirurginen operaatio. Kun kasvaimet kasvavat hallitsemattomasti, solukuolemia tapahtuu normaalia enemmän. Kuolevat syöpäsolut vapauttavat DNA-fragmentteja verenkiertoon. Verinäytteen soluvapaasta osasta, plasmasta ja seerumista, kerätään nämä DNA-fragmentit talteen sekvensointia varten. Sekvensointituloksia analysoimalla voidaan havaita, onko verenkierrossa DNA-fragmentteja, joissa on nähdään syöville ominaisia muutoksia,” Ellonen toteaa.

Ellosen mukaan nestemäistä biopsiaa käytetään paljon ja siihen liittyy monia uusia tutkimushankkeita. Nestemäistä biopsiaa voidaan käyttää perustutkimuksen lisäksi myös hoitosuunnitelman teossa, hoidon vaikutusten seurannassa tai syövän uusiutumisen monitoroinnissa. Se, että pystyy ottamaan useita verinäytteitä eri aikoina, auttaa lääkäreitä ymmärtämään minkälaisia molekyylitason muutoksia on tapahtunut elimistössä.
”Voidaan tunnistaa uusia geenimerkkejä ja parhaassa tapauksessa valita mutaatioiden perusteella toimiva täsmähoito. Vaihtoehtoisesti tiedetään mitä etsitään eli tutkitaan näkyykö verenkierrossa enää merkkejä jäännöstaudista ja saatiinko syöpä kirurgisen operaation jälkeen kokonaan leikattua pois.”
Pekka Ellonen on innostunut CSC:n Allas-tallennuspalvelun käyttöliittymästä, jota kautta laboratoriot ja tutkimuslaitokset voivat jakaa esikäsitellyt sekvensointitulokset ja molekyylien datan tutkijoiden, tutkimusryhmien ja konsortioiden käyttöön. Allas tarjoaa 12 petatavun tallennustilan. Data on saatavilla tietoturvallisesti suoraan www:n kautta. Datankäsittely voidaan tehdä tavanomaisia ohjelmointirajapintoja käyttäen mistä tahansa.
”Julkinen raha tuottaa dataa, joten se pitää jakaa aikanaan tiedeyhteisön käyttöön laajemminkin, asianmukaisesti pseudonymisoituna. Käyttöliittymä mahdollistaa isojen aineistojen, kuten hyödyllisen genomitiedon kohorttiaineistot, jakamisen.”
Ari Turunen
3.12.2020
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Esa Pitkänen, & Tommi Nyrönen. (2020). Efficient processing and sharing of data improving disease diagnosis and treatment. https://doi.org/10.5281/zenodo.8135239
Lisätietoja:
Suomen molekyylilääketieteen instituutti FIMM
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Ihmisen geeneistä ja proteiineista saatu data mahdollistaa sairauksien nopean diagnoosin sekä hyvät ja yksilölliset potilashoidot. Riskiryhmään kuuluvat voidaan seuloa paremmin ja lääkityksen tehoa voidaan parantaa kun tiedetään potilaan geeniperimä. Haasteena on, miten data käsitellään ja minne se tallennetaan.
Uusien datan analyysimenetelmien ja tietokoneiden lisääntyneen laskentatehon ansiosta geeni- ja proteiinidatan käsittely saadaan nopeutettua useista päivistä jopa alle puoleen tuntiin. Tämä edellyttää, että data on esikäsiteltyä eli siitä on poistettu toisteisuus ja että se on nopeasti ja tietoturvallisesti saatavissa.
Bioinformatiikan mittausmenetelmät ovat kehittyneet huimasti ja ne tuottavat valtavasti dataa. Nyt voidaan ymmärtää kokonaisen biologisen järjestelmän toiminta. Tällöin kaikkia geenejä tai niiden tuottamia proteiineja tutkitaan samanaikaisesti. Näitä ns. omiikkoja ovat DNA-sekvenssin selvittäminen (genomiikka) ja proteiinien rakenteiden tietokonemallinnus (proteomiikka), solukudoksessa ilmentyvät geenit (transkriptomiikka)sekä aineenvaihduntatuotteet (metabolomiikka). Näiden menetelmien avulla voidaan tutkia molekyylien vuorovaikutuksia ja löytää elimistön tilan muutoksista merkkejä tautien tunnistamiseksi.
”Nyt pystytään tekemään todella paljon, mutta geenidatan ja kliinisen datan yhdistäminen vaatii vielä paljon datan tallennus- ja laskentakapasiteettia ja kaiken tiedon käsittelyä tietoturvallisesti,” sanoo Suomen molekyylilääketieteen instituutin (FIMM) teknologiakeskuksen johtaja Katja Kivinen.

Datan oikeaoppinen esikäsittely ja mallintaminen ovat edellytys tulevaisuuden tutkimukselle, joka lupaa entistä tehokkaampia ennusteita taudeista ja jopa yksilöllistä täsmälääkitystä. Kivinen antaa kaksi esimerkkiä: tautien riskitekijöiden esiseulonnan ja lääkehoidot.
Nature Medicine -lehdessä julkaistiin keväällä 2020 artikkeli, joka perustui Finngen -hankkeessa tehtyihin data-analyyseihin. Professori Samuli Ripatin tutkimusryhmä Suomen molekyylilääketieteen instituutista pystyi genomitiedon perusteella tunnistamaan suomalaisen väestöryhmän, jolla oli 60% todennäköisyys sairastua elämänsä jossakin vaiheessa sydän- ja verisuonisairauksiin tai diabetekseen. Tutkimusaineistossa oli 135 000 suomalaista näytteenantajaa. Yksittäisistä riskitekijöistä saatu tieto yhdistettiin ns. perimänlaajuiseksi riskipistemääräksi.
”Kun geneettinen tausta selvitetään, lääkärit voivat kohdentaa sekä ennaltaehkäiseviä toimenpiteitä että hoitoja tarpeen mukaan ja yhteiskunta säästää aikaa ja rahaa”, sanoo Kivinen.
”Tulevaisuudessa väestölle tehtävät seulonnat voidaan kohdentaa nykyistä paremmin. Osalle väestöstä esimerkiksi kutsu rintasyöpäseulontaan tulee perinnöllisen riskin puolesta aivan liian aikaisin, toisille puolestaan aivan liian myöhään. Kun perinnölliset riskitekijät otetaan huomioon, voidaan seulontoihin kutsua optimaaliseen aikaan syövän varhaisen havaitsemisen kannalta ja samalla minimoida toistuvista mammografioista aiheutuvaa tarpeetonta säteilyannosta.”

Ihmiset reagoivat lääkkeisiin eri tavoin, osalla lääkehoidon teho jää puutteelliseksi ja osalle se aiheuttaa haittavaikutuksia. Syynä poikkeavaan vasteeseen voivat olla fyysiset ominaisuutemme, muu lääkitys ja geneettinen perimämme. HUS e-care for me –projektin pilottivaiheessa kehitetään parempia hoitomenetelmiä leukemiaan ja muihin verisyöpiin. Kesällä 2019 aloitetussa projektissa yhdistetään Suomen molekyylilääketieteen instituutissa tuotetusta potilaskohtaisesta biologisesta datasta kliinisiin tietoihin syövän tyypistä ja leviämisasteesta ja etsitään tekoälyn avulla kullekin potilaalle sopivin lääkitys syövän leviämisen pysäyttämiseksi.
”Joskus voi käydä niin, että lääke ei tehoa tai se on lakannut tehoamasta. Leukemiapotilaiden verinäytteistä otetaan soluviljelmät ja sitten analysoidaan, mitkä lääkeaineiden yhdistelmät toimivat.”
Samasta verinäytteestä tehdään genomi- ja transkriptomi -sekvensointi. Transkriptomi antaa tietoa mahdollisten geenimuutosten aiheuttamista muutoksista geenien toiminnassa.
”Jos lääkeaine ei enää toimi, voidaan selvittää minkälaisia geneettisiä muutoksia eli mutaatioita on tullut. Toimivatko jotkut geenit tai eivät mutaation seurauksena? Entä miten mutaatio vaikuttaa aineenvaihduntareitteihin? Nyt voidaan suoraan verikokeista katsoa, mikä lääke sopii parhaiten eri verisyöpäpotilaille.”
Yksikölliset lääkehoidot ovat mahdollisia, jos dataa on potilaasta tarjolla ja se on tallennettu ja esikäsitelty oikein. Suomen ELIXIR -keskus CSC ja Barcelonan supertietokonekeskus (BSC) yhdessä yhdentoista muun akateemisen ja kaupallisen toimijan kanssa, aloittivat lokakuussa 2020 European HPC Center of Excellence for Personalised Medicine (PerMedCoE) -hankkeen. Hankkeessa kehitetään algoritmeja, joilla pystytään merkittävästi lyhentämään analyysin vaatimaa laskenta-aikaa. Geeni- ja proteiinidatan analysointi nopeutuu, mikä helpottaa ja nopeuttaa sairauksien tunnistamista ja oikeiden hoitojen löytämistä. Nykyisin genomianalyysi voi kestää viikkoja tai jopa kuukausia. Superlaskennan ja oikeiden ohjelmistojen myötä esimerkiksi sairauksien diagnosointi onnistuu jatkossa tuntien tai päivien sisällä.
Tällaiset projektit ovat tärkeitä Suomen molekyylilääketieteen instituutin tutkimusryhmille, jotka ovat koko ajan tekemisissä valtavien datamäärien kanssa.
”Datan määrä kasvaa kiihtyvällä tahdilla entistä tehokkaampien laitteiden ja menetelmien myötä, sanoo Katja Kivinen. ”Tällä hetkellä datan tallennustilasta on jatkuva pula ja datan esikäsittely kestää liian kauan, jotta pääsisimme purkamaan muodostuvaa sumaa ja lähettämään valmiit datat eteenpäin tutkimusryhmille. Tietoturvallinen datan tallennus- ja käsittely-ympäristö on elintärkeä ihmisdataa käsitellessä. Kaupalliset pilvipalvelut tarjoavat turvallisia käyttöympäristöjä, mutta ovat liian kalliita useimmille tutkijoille. Lisäksi osa datoista vaatii tarkasti räätälöidyn esikäsittely- ja analyysiympäristön ja soveltuu huonosti kaupallisten pilvipalveluiden tarjoamiin vaihtoehtoihin.”
Datan käsittelyyn saadaan apua CSC:n ja FIMM:n työnjaolla. Pilottivaiheessa genomidata siirretään FIMM:istä CSC:lle huippunopean ja turvallisen valopolkuyhteyden ansiosta. Datan esikäsittely ja laadunvarmistus analyysia varten on nopeaa, koska data sijaitsee CSC:llä. CSC toimii jatkossa myös datan valtakunnallisena jakajana takaisin tutkimusryhmille.
”Aiemmin sen selvittäminen, minkälaisia genomisia muutoksia ihmisen genomissa on, on vienyt meiltä 2-3 päivää per genomi. Yhteistyön ansiosta olemme saaneet käyttöön sekventointilaitteemme valmistajalta optimoidun laskentapalvelimen, joka tiivistää yhden genomin prosessoinnin 20 minuuttiin. Tämä auttaa meitä purkamaan genomidatan käsittelyyn kertyneen jonon FIMM:issä ja vapauttamaan bioinformaatikoidemme aikaa muihin töihin – esimerkiksi erilaisten datojen integraation suunnitteluun ja mahdollistamiseen.”
CSC on kehittänyt FIMM:istä tulevan genomidatan jakamiseen suomalaisten tutkimusryhmien käyttöön yhteisen käyttöliittymän CSC:n Allas-palveluun. Tutkimusryhmät saavat viestin, kun heidän genomidatansa on valmis ja siirtävät sen omalle projektialueelleen CSC:n ePouta -ympäristössä. Pilottivaiheen jälkeen portaalin toimintaperiaatetta on tarkoitus tarjota laajemmin kaikille omiikka -dataa tuottaville tutkimusryhmille suomalaisissa yliopistoissa.
”Käyttöliittymä on meille elintärkeä mm. siksi, että datamäärän kasvun ja toisaalta tietoturvavaatimusten kiristymisen myötä meidän on yhä vaikeampi ylläpitää FIMMissä datan tallennus- ja prosessointiympäristöä.. Meidän on pakko alkaa siirtää enenevässä määrin raakadataa tai käsiteltyä dataa CSC:lle, josta tutkimusryhmät voivat ottaa sen käyttöönsä.”
Toinen tärkeä kehityskohde Kivisen mukaan ovat mikroskooppien tuottaman datan talllentamisen ja siihen liittyvät kuvantamispalvelut.
”Kuvien prosessointi tapahtuu yleensä itse instrumenttiin liitetyllä palvelimella, jossa on prosessointiin tarvittavat ohjelmistot. Prosessoinnin siirtäminen pilvipalveluun ei aina ole varteenotettava vaihtoehto varsinkaan koko maassa liian hitaan siirtonopeuden vuoksi. Kuvien prosessointi saattaa siis jatkossakin tapahtua ”paikan päällä”, mutta prosessoidun datan jakamisen tulisi mielestäni siirtyä genomidatan tapaan CSC:n jaettavaksi.”
Ari Turunen
10.11.2020
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Katja Kivinen, & Tommi Nyrönen. (2020). Bioinformatics to revolutionise healthcare: Efficient data processing speeds up diagnoses and enables personalised drug treatments. https://doi.org/10.5281/zenodo.8135131
Lisätietoja:
Suomen molekyylilääketieteen instituutti FIMM
Cleverhealth
https://www.cleverhealth.fi/fi/ecare-for-me
+1 million genomes
https://ec.europa.eu/digital-single-market/en/european-1-million-genomes-initiative
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Sydän- ja verisuonitaudit ovat yleisin kuolinsyy maailmassa. Suomessa yli kolmannes kuolemista johtuu sydän- ja verisuonitaudeista. Nyt tavoitteena on saada terveysdatan perusteella arvio jokaisen sairastumisriskistä Suomessa ennen lääkärillä käyntiä.
Andrea Ganna, Suomen molekyylilääketieteen instituutin (FIMM) ryhmän vetäjän ja Harvardin lääketieteellisen koulun opettaja, haluaa perustaa maanlaajuisen yksilöllisen riskiarvioinnin, joka olisi perustana, joilla voisi suunnitella julkisen terveydenhallinnon toimenpiteitä. Arviointi perustuu kansalaisten terveys, väestö- ja geenitietoon. Arviointi, joka hyödyntää teköälyä, parantaa ehkäisevien hoitojen kohdentamista nykyistä halvemmalla kustannustasolla.
“Pohjoismailla ja erityisesti Suomella on tähän ainutlaatuinen mahdollisuus ja miljöö, sillä nämä maat ovat keränneet terveys- ja väestödataa vuosia. Mutta tapa, jolla dataa on aiemmin kerätty, on jossain määrin vanhentunut. Datasta on katsottu vain tiettyjä riippuvuussuhteita ja yhteyksiä. Kuitenkin uudet menetelmät, kuten tekoäly, ovat tulossa ja antavat mahdollisuuden suurempaan ja kunnianhimoisempaan visioon.”
Andrea Ganna ja hänen tutkimusryhmänsä kehittävät tekoälyyn (AI) perustuvia lähestymistapoja yksittäisen ihmisen terveyshistorian mallintamiseksi.
“Jokaisella henkilöllä on tietynlainen terveys- ja lääkintähistoria. Haluamme tietää, onko muilla samantyyppisiä seurantatietoja. Heitä voi olla tuhansia. Me hyödynnämme näiden ihmisten terveystietoja ja selvitämme, mitä heille tapahtui. Näin autamme alentamaan sairastumisriskiä. Voimme käyttää kaikkea tätä dataa aiempaa paljon kokonaisvaltaisemmalla tavalla auttaaksemme julkista terveyshallintoa ja antaaksemme potilaille ja lääkäreille enemmän tietoa päätöksenteon tueksi.”
Andrea Ganna on kiinnostunut epidemiologiasta, genetiikasta ja tilastotieteestä. Hän on keskittynyt hyödyntämään suuria epidemiologisia aineistoja tunnistaakseen yhteiskunnallis-väestötieteellisiä, metabolisia ja geneettisiä tunnusmerkkejä, jotka ovat yleisten ja monimutkaisten tautien taustalla. Bostonissa ollessaan hän työskenteli laajojen eksomi- ja genomisekvenssidata-aineistojen parissa.
Gannan mukaan sydän- ja verisuonitaudit sopivat täydellisesti tekoälyn tekemiin analyyseihin, koska näiden tautien hoito on ennaltaehkäisevää.
“Tarkka korkean riskin yksilöiden tunnistaminen on yksi kulmakiviä kardiometabolisten sairauksien ennaltaehkäisyssä”, hän sanoo.
”Kuitenkin tällä hetkellä kardiometabolisten sairauksien riskitekijöiden arviointi edellyttää potilailta käyntiä lääkärillä lipidimittauksessa.”
Lipidi on yleisnimitys kaikille veressä kiertäville rasvoille ja rasvan kaltaisille aineille. Keho varastoi ravinnosta saatua rasvaa tulevaan käyttöön. Runsasrasvainen ruokavalio saa rasvan kiinnittymään valtimoiden seinämiin, mistä aiheutuu sydän- ja verisuonitauteja sekä valtimotauteja. Lipidimittauksessa saadaan selville, millaisia rasvoja testattavalla on elimistössään. Lipidimittaus on tehokas, mutta ongelma on, että osa väestöstä ei tiedä kuuluvansa riskiryhmään.
Ganna haluaa mullistaa sairausten ennaltaehkäisyn tarjoamalla riskiarvioinnin potilaalle ennen kuin hän menee lääkärin vastaanotolle.
“Jotkut eivät yksinkertaisesti mene lääkärille ja paljon ihmisiä puuttuu. Mutta koska kaikki lääkitykseen ja diagnooseihin liittyvä data on jo kerätty, voimme tunnistaa korkean riskin potilaat ennen kuin he menevät lääkärille. Voimme tehdä sydän- ja verisuonitautien riskikartan koko maasta mukaanlukien kaikki yksittäiset henkilöt.”
Riskilaskelma tehdään mallintamalla sairauksien ja lääkitysten pitkittäisseurannasta saatua dataa yhdessä geeni-, perhe- ja väestödatan kanssa.
“Yritämme ymmärtää, kuinka genetiikka vuorovaikuttaa sellaisen datan kanssa, joka saadaan lääkityksistä, diagnooseista, väestöstä ja perheestä. Tämä voi antaa ennennäkemättömän kokonaisvaltaisen näkökulman yksilön terveydentilaan.”
Ganna antaa esimerkin.
“Kun katkaiset jalkasi, menet lääkärille. Kuitenkin tänä päivänä lääkäri katsoo vain jalkaasi, vaikka samalla käynnillä voisit saada hyötyä myös muusta tiedosta. Me voimme informoida lääkäriä muista riskeistä, joita potilaalla on perustuen kerättyyn dataan. Voimme laskea ennalta potilaan muut riskit, kuten esimerkiksi, jos hänellä on korkea riski sydän- ja verisuonisairauksiin. Siten, samalla käynnillä, lääkäri voi myös antaa neuvoja tai ohjata potilaan asiantuntijalle.”

Ganna päätti tulla Suomeen laajan geeniprojektin, FinnGenin takia.
Elokuussa 2017 alkaneessa projektissa taltioidaan puolen miljoonan suomalaisen genomit. Hankkeessa hyödynnetään kaikkien suomalaisten biopankkien keräämiä näytteitä. Perimästä saatava data yhdistetään kansallisissa terveydenhuollon rekistereissä olevaan tietoon. FinnGen on yksi ensimmäisiä näin laajassa mittakaavassa tehtyjä erittäin yksilöllistettyjä lääketieteen projekteja. Julkisten ja yksityisten organisaatioiden yhteistyö on poikkeuksellista.
“Suomessa on sopiva lainsäädäntö, joka antaa pääsyn maanlaajuiseen populaatiodataan. Minulle tämä on ainutlaatuinen kattaus.”
Ganna ja hänen tutkimusryhmänsä integroivat rekistereissä olevan tiedon ja biopankkeihin tallennetun laajan tutkimustiedon auttaakseen tunnistamaan yksilöryhmiä, jotka voisivat eniten hyötyä olemassaolevista farmakologisista toimenpiteistä.
“Ehkä tärkein ryhmä on nuoret yksilöt jotka eivät käy lääkärissä kovinkaan usein. Nykyiset riskitekijät eivät toimi hyvin tässä ryhmässä. Genetiikka on erityisesti arvokasta, koska sen avulla voidaan löytää sairastumisen riskitekijät aikaisemmalla iällä verrattuna muihin riskitekijöihin. Ensimmäinen askel on ymmärtää, miten ihmiset hahmottavat tämän tiedon. Meidän täytyy varmistaa että lääkärit käyttävät dataa oikealla tavoin ja mitä sillä voidaan tehdä.”

Gannan tavoitteena on integroida kansalliset ja alueelliset rekisterit syvä- ja koneoppimiseen.
“Perinteisillä menetelmillä on etunsa, sillä ne ovat suhteellisen yksinkertaisia ja helppoja tulkita, mutta ne eivät skaalaudu. Viimeisten 20 vuoden aikana yli 500 miljoonaa lääketieteellistä diagnoosia on tehty suomalaisista. Puhumme valtavista datajoukoista. Joka vuosi tehdään miljoonia uusia lääkemääräyksiä ja diagnooseja. Tämän skaalaamiseksi ja hyödyntämiseksi tarvitaan syväoppimisen menetelmiä.
Keinotekoiset neuroverkot ovat tehokkaita koneoppimisen algoritmeja, joita voidaan hyödyntää hahmontunnistamisessa. Takaisinkytkeytävät neuroverkot (recurrent neural network) voivat hyödyntää niiden sisäistä muistia syötejonojen käsittelyssä. Tämä tekee niiistä soveltuvia sellaisiin tehtäviin, kuten segmentoitumattomaan tunnistamiseen. Ganna haluaa laajentaa nämä neuroverkot käyttämäänsä dataan.
”Voidaan ajatella, että terveydentilaa kuvaavien tapahtumien muutosjono, jota yritämme mallintaa, on ”tekstiä”, jossa jokainen sana on erilainen koko elämän aikana ollut tauti, lääkitys, väestötieteellinen tapahtuma jne. Nämä ovat luonnollisesti sovitettu mallintamaan muutosta kuvaavaa tapahtumaketjua, esimerkiksi niitä käytetään ennustamaan seuraavaa todennäköisintä sanaa tekstiviestissä.”
Syväoppimisen menetelmät edellyttävät suurta supertietokoneinfrastruktuuria.
”CSC on luonut turvallisen ympäristön laskentaan. Ilman turvallista superlaskennan ympäristöä, emme voisi toteuttaa tätä projektia. Onnistuaksemme me tarvitsemme yhtäältä tutkimusta ja kehitystyötä ja toisaalta tehokasta laskentaympäristöä.”
Potilasdata on tärkeää tutkimukselle, mutta henkilökohtainen data on myös suojeltua. Esimerkiksi Suomen molekyylilääketieteen instituutissa kehitetty VEIL.AI anonymisoi potilasdatan perinteisiä menetelmiä tehokkaammin, nopeammin ja informaatiota paremmin säilyttäen. Tarvittaessa sovelluksen avulla voidaan tuottaa myös synteettistä, täysin anonyymia eli siis yksittäisestä henkilöstä erillään olevaa tilastollista dataa.
“Meillä on tarve taata yksilöiden yksityisyys, mutta samalla meidän täytyy integroida paljon henkilökohtaista dataa, jotta voisimme todella hyötyä tekoälystä ja syväoppimisen lähestymistavoista ja jotta voisimme kohdentaa tulokset parempiin julkisen terveydenhuollon toimenpiteisiin. Luomalla synteettisiä terveystiedon historioita autetaan kunnioittamaan yksityisyyttä, mutta samaan aikaan pystytään yhdistämään paljon persoonakohtaista tietoa ei pelkästään Suomessa vaan Pohjoismaiden välillä.”
“Toivon, että rutiininomaisesta terveydenhuollossa kerätty persoonakohtainen data voi auttaa ja hyödyntää kaikkia. Toivon, että tämä tieto voi auttaa lääkäreitä tekemään parempia päätöksiä ja myös motivoimaan potilaita elämäntapamuutoksiin. Siten kaikki auttavat kaikkia.”
Ari Turunen
30.9.2019
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Andrea Ganna, & Tommi Nyrönen. (2019). Risk assessment of cardiovascular diseases for all citizens. https://doi.org/10.5281/zenodo.8131074
Lisätietoja:
FIMM
Suomen molekyylilääketieteen instituutti (FIMM) on kansainvälinen tutkimuslaitos, jonka toiminta keskittyy sairauksien molekyylitason mekanismien selvittämiseen genetiikan ja lääketieteellisen systeemibiologian menetelmin. Tavoitteena on tutkimustiedon siirtäminen terveydenhuollon käyttöön mm. henkilökohtaista lääketiedettä edistämällä.
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Potilasdata on tärkeää tutkimukselle. Henkilön tietosuojasta huolehditaan piilottamalla tai muokkaamalla tunnistetietoja, mutta samalle tutkijalle jää tutkimukselle merkittävä tilastollinen data. Uusi tekoälyä käyttävä palvelu mahdollistaa tämän.
VEIL.AI anonymisoi potilasdatan perinteisiä menetelmiä tehokkaammin, nopeammin ja informaatiota paremmin säilyttäen. Tarvittaessa sovelluksen avulla voidaan tuottaa myös synteettistä, täysin anonyymia eli siis yksittäisestä henkilöstä erillään olevaa tilastollista dataa.
Suomen molekyylilääketieteen instituutissa (FIMM) kehitetty sovellus on nyt tarjolla ELIXIR -infrastruktuuriin, jonka kanssa kehitetään yhteistä palvelua. Dataa hallinnoiva organisaatio voi suojata datansa syöttämällä metadatatiedot skaalautuvaan pilvipalveluun. Palvelu verhoaa yksilökohtaiset tunnisteet, jolloin tutkijat saavat käyttöönsä anonymisoitua ja tarvittaessa synteettistä dataa.

VEIL.AI –sovellus hyödyntää tekoälyyn perustuvaa mallintamista. Sovelluksessa luodaan huntu, joka suojelee potilaan tunnistetietoja mutta se osaa tunnistaa relevantin datan, jolloin se ei hävitä sitä.
“Toisinaan, esimerkiksi koneoppivia malleja kehitettäessä, tarvitaan dataa laajemmin ja nopeammin kuin mitä tutkimuseettiset lautakunnat mielellään antavat. He edellyttävät jokaisen muuttujan tarkkaa perustelua, mikä taas on koneoppivissa malleissa vaikeaa siinä vaiheessa, kun parasta mallia vasta haetaan,“ sanoo kaupallistamisasiantuntija Tuomo Pentikäinen.
Siksi varsinkin mallintamisen alkuvaiheessa onkin Pentikäisen mukaan järkevää käyttää synteettistä dataa, jota VEIL.AI -menetelmällä voidaan luoda.
“Tällä tarkoitetaan taustalla olevista ihmisistä kokonaan irrallaan olevaa dataa, joka kuitenkin käyttäytyy haluttujen muuttujien suhteen samoin kuin alkuperäinen data.”
VEIL.AI löytää henkilön tunnistamiselle herkät muuttujat ja pystyy nämä muuttujat anonymisoimaan automaattisesti.
”Sovelluksessa voidaan tehdä suunnitelmallisemmin ja järkevämmin laskennallisesti raskaita ja operatiivisesti työläitä datan osittamiseen ja anonymisointimetriikoiden laskemiseen liittyviä toimenpiteitä.”
Arkaluontoista potilasdataa pitää pystyä suojelemaan, mutta monet perinteiset anonymisointimallit hävittävät samalla tärkeääkin dataa. Perinteisesti potilastietoja on suojattu osittamalla ja karkeistamalla datassa olevia tunnistetietoja. Anonymisoinnissa tutkitaan sitä, miten muuttujat jakavat/osittavat tiedon erilaisiin ryhmiin. Sitten kutakin ryhmää tarkastellaan erikseen ja jos sieltä löytyy liian tunnistettavia muuttujia, niitä karkeistetaan. Karkeistuksessa esimerkiksi ikää voidaan pyöristää muutamalla vuodella ja ammattinimike vaihtaa sairaanhoitajasta ”terveydenalan ammattilaiseksi”.
”Liian tunnistettavat muuttujat karkeistetaan siis riittävän yleiselle tasolle tai jopa poistetaan. Terveysdatassa poistamisia joudutaan aika usein tekemään, kun jokin muuttuja on liian ainutlaatuinen ja tunnistettava”, sanoo Pentikäinen.
Karkeistaminen voi siis hukata tärkeää potilasdataa.

”Tyypillisesti tätä tapahtuu silloin, kun kiinnostava ilmiö (vaikkapa sairaus) on kohtalaisen harvinainen ja jakaantuu melko tasaisesti koko tietomassaan. Kun tietomassa sitten jaetaan ositteisiin anonymisointia varten, on tavallista että kiinnostuksen kohteena oleva ilmiö jakautuu entistäkin harvinaisempana kuhunkin uuteen ositteeseen. Tällöin on tavallista, että perinteiset menetelmät tulkitsevat kyseessä olevan kiinnostavan datan ”outlieriksi” kussakin uudessa ositteessa ja se siivotaan pois. Tämä on typerää, koska fiksummin valitulla strategialla kiinnostava ilmiö olisi saatu kerätyksi ositteisiin siten, että tärkeä informaatio voidaan säilyttää paremmin. ”
Suomen molekyylilääketieteen instituutin IT-päällikkö Timo Miettinen ottaa esimerkiksi potilaan, jolla on harvinainen versio rintasyövästä. Liian raju karkeistus voi kokonaan hävittää tiedot harvinaisesta versiosta, koska tällaisia potilaita on datajoukossa vähän.
”Rintasyöpäpotilaalla on yksi diagnoosi, mutta hänen geneettinen profiiliinsa kertoo, että hänellä on rintasyövästä harvinainen versio. Näitä potilastapauksia voi olla yhdessä sairaalassa muutamia, jolloin se voidaan luokitella outlieriksi ja deletoidaan. Mutta koko populaatiota ajatellen näin ei ole ole. Jos kokonaisuutta pystyttäisiin tarkastelemaan paremmin, tämä outlier, poikkeava havainto, ei olisi deletoitu.”
Timo Miettinen on pitkään ollut mukana suunnittelemassa tietojärjestelmiä, joissa hyödynnetään ja suojataan kliinistä dataa. Miettinen ryhmineen on kehittänyt VEIL.AI-sovelluksen, jota ollaan kaupallistamassa. Tällainen mikropalvelu on luotu EU:n tietosuoja-asetuksen GDPR:n takia.
Suomessa on jokaisella biopankilla käytössään oma koodirekisteri. Koodirekisterissä on henkilötunnus sekä synonyymitaulukko, jolloin luodaan tutkittavalle tunniste, joka on pseudonyymi eli peitetunniste.
”Joitakin asioita on vaikea muuttaa, kuten pituus, silmien väri ja syntymäpaikka. Ne ovat tilastollisilla menetelmillä tunnistettavissa. Samoin terveyteen liittyvä tapahtumasarja eli hoitohistoria”, sanoo Miettinen.
”Meillä on kaksi lupausta. Ensinnäkin lupaamme skaalautuvuutta ja enemmän suorityskykyä. Pystymme hyödyntämään jatkuvasti päivittyvää dataa monesta lähteestä. Ne voimme anonymisoida tehokkaasti ja tietoturvallisesti. Toinen lupauksemme on, että yritämme minimoida tietohävikkiä. Sovelluksella huomioidaan datan sisältö ja täytetään samalla anonymisointikriteerit”, sanoo Miettinen.

VEIL.AI -sovelluksessa käytetään neuroverkkoa, jopa on jopa tuhansia kertoja nopeampi kuin perinteiset menetelmät.
”Menetelmämme mahdollistaa aikaisempaa turvallisemman tiedon jakamisen, sillä neuroverkon opettamisen jälkeen kukin luottamuksellisen tiedon haltija voi suorittaa anonymisoinnin ennen kuin luovuttaa luottamuksellista tietoa partnereilleen. Usein menetelmämme tuottaa myös parempaa dataa, sillä voimme kokeilla valtavan määrän erilaisia datan osittamisstrategioita ja valita niistä sen, joka tuottaa pienimmän informaatiohävikin ja silti saavuttaa tavoitellun anonymiteettitason, ” sanoo Pentikäinen.
Tietoturvalle tärkeää on myös VEIL.AI -sovelluksen käytössä se, että potilasdata ei siirry minnekään.
”Me emme halua hallinnoida dataa. Meidän palvelumme läpi striimataaan dataa, joka anonymisoidaan ja palautetaan sitten välittömästi asiakkaan hallintaan,” sanoo Tuomo Pentikäinen.
”Tarjolla on skaalautuva pilvipalvelu. Käyttöliittymän kautta voidaan syöttää tarvittavat metadatatiedot (data dictionary) ja opettaa algoritmi tekemään datan anonymisointimallin jollakin esimerkkiaineistiolla. Algoritmi oppii käsittelemään dataa ja jos tulee lisädataa, se striimataan pilvipalvelun kautta ja anonymisoidaan,” Timo Miettinen korostaa.
Organisaatioiden ei siis tarvitse jakaa sensitiivistä dataa enää kenellekään. Data tulee anonymisoituna pilvipalvelun kautta tutkimuksen käyttöön.
Eri pseudotunnisteiden analysoimiseen tarvitaan paljon laskentaa, jota on saatu ELIXIR -infrastruktuurista.
Ari Turunen
3.6.2019
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Tuomo Pentikäinen, Timo Miettinen, & Tommi Nyrönen. (2019). VEIL.AI: patient data in a veil. https://doi.org/10.5281/zenodo.8119016
VEIL.AI
FIMM
Suomen molekyylilääketieteen instituutti (FIMM) on kansainvälinen tutkimuslaitos, jonka toiminta keskittyy sairauksien molekyylitason mekanismien selvittämiseen genetiikan ja lääketieteellisen systeemibiologian menetelmin. Tavoitteena on tutkimustiedon siirtäminen terveydenhuollon käyttöön mm. henkilökohtaista lääketiedettä edistämällä.
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Professori Samuli Ripatin ryhmä Suomen molekyylilääketieteen instituutissa ja Helsingin yliopiston lääketieteellisessä tiedekunnassa tutkii sydän- ja verisuonitautien syntymekanismeja geenitekniikan avulla. Suomalaisen populaation geeniperimä tarjoaa tähän hyvät mahdollisuudet.
Suomessa on noin 40 perinnöllistä tautia, jotka ovat tunnusomaisia suomalaiselle populaatiolle. Tautiperimään kuuluvat taudit johtuvat tietyistä mutaatioista, jotka ovat Suomessa muuta maailmaa yleisempiä ns. pullonkaulaefektin takia. Viimeisten 10 000 vuoden kuluessa Suomen alueelle on muuttanut suhteellisen pieni määrä uudisasukkaita. Tämän uuden populaation yksilöt edustivat pientä ja kapeaa geeniainesta, mikä sai aikaan joidenkin tautigeenien alueellisen rikastumisen.
Pullonkaulaefektistä on nyt hyötyä kun tautien geneettistä perimää selvitetään.
”Suomi on Euroopan skaalassa suurin pullonkaulaväestö. Tänne on tullut vähän ihmisiä vuosituhansien aikana. Sellaiset geenimuunnokset, jotka ovat muuttajien mukana Suomeen tulleet, voivat olla Suomessa sata kertaa yleisempiä, kuin muualla. Näin ei ole sellaisilla populaatioissa, joissa väestö on päässyt sekoittumaan. Pysyvää asutusta tuli ensin rannikkoseudulle. Ja vasta paljon myöhemmin sisämaahan ja pohjoiseen”, sanoo Samuli Ripatti.
Ripatin mukaan 1500-luvun aikana tapahtunut sisäinen muuttoliike oli toinen pullonkaula, jonka ansiosta nähdään isoja eroja Suomen väestössä idän ja lännen välillä. Vaikka populaatioisolaatteja on muuallakin, suomalaisen tautiperimän tutkimuksen tekee ainutlaatuiseksi se, että monen harvinaisen taudin geneettinen tausta on selvitetty. Tätä tietoa voidaan hyödyntää myös muita tauteja tutkittaessa.
”Nyt pystymme ymmärtämään monen geneettisesti periytyvän taudin syntyperiaatteet, jolloin tutkimustietoa voidaan soveltaa muualla. Vaikka taudit ovat erilaisia, niissä on samalla tavalla toimivia geneettisiä mekanismeja. Tämän dynamiikan ymmärtäminen on iso asia ja tarjoaa mahdollisuuksia uusien hoitojen kehittämiseen.”
Esimerkiksi Parkinsonin tautia tutkittaessa voidaan selvittää, olisiko tauti yleisempää jossakin osassa Suomea. Jos näin on, voi tämän osan maata tutkiminen tuottaa uutta geneettistä tietoa.
Ripatti on kiinnostunut populaatiogenetiikasta ja suomalaisten geneettisestä vaihtelusta. Vuodesta 2013 hän on toiminut biometrian professorina Helsingin yliopiston lääketieteellisessä tiedekunnassa. Biometria on tilastotieteen ala, joka on keskittynyt biologisten aineistojen analysointiin. Ripatin tutkimusryhmä yhdistää tilastolliset menetelmät ihmisen perimän sekvenssitason mittauksiin.
”Sekvensoinnilla saadaan tietoa geneettisestä vaihtelusta, joka voi olla pienessä populaatiossa harvinaista. Vaihtelun perusteella voidaan nähdä tiettyjen tautiriskiä muokkaavien geneettisten muutosten yleisyys jollakin Suomen alueella tai osoittaa altistuminen tiettyyn tautiin.”
Näin populaation geenidatasta voidaan yrittää seuloa arvokasta tietoa terveysvaikutuksista. Voidaan löytää henkilöt, joilla on korkea riski sairastua ja samalla etsiä keinoja tautien ehkäisemiseen.
”Me katsomme asiaa kansantautien näkökulmasta. Tutkimme Suomessa yleisiä tauteja, joita ovat esimerkiksi sydän- ja verisuonitaudit ja diabetes.”
Vaikka näihin tauteihin vaikuttavat esimerkiksi ruokavalio ja muut elämäntavat, myös perinnölliset tekijät ovat merkittäviä. Siksi tauteja kutsutaankin Suomessa kansantaudeiksi. Ripatin ryhmä on Suomen pullonkaulaefektin ansiosta tunnistanut geenimuunnoksia, erityisesti sydän- ja verisuonitaudeille altistavia geenejä sekä verestä mitattuja sairautta ennakoivia ja merkkiaineita sääteleviä geenejä. Ripatti ottaa esimerkiksi korkean kolesterolitason.
”Ne joilla on korkeat kolesterolitasot, voidaan ottaa tutkimuksiin ja heidän perimänsä sekvensoida tehokkaasti ja helposti. ”
Sydän- ja verisuonisairaudet aiheuttavat kolmanneksen kuolinsyistä maailmassa. Eniten siihen sairastuneita on Keski-Aasiassa ja Itä-Euroopassa. Suomi oli 1960-luvulla maailman kärkisijalla keski-ikäisten miesten sepelvaltimotautikuolleisuudessa. 2000-luvulle tultaessa miesten kuolleisuus oli vähentynyt noin viidennekseen korkeimmasta tasosta.
Alueelliset erot sydän- ja verisuonitautien sairastavuudessa ja kuolleisuudessa ovat kuitenkin Suomessa suuret. Tautien esiintyminen on Länsi- ja Etelä-Suomessa muuta maata selvästi vähäisempää. Tämä suuri alueellinen ero kiinnostaa tutkijoita. Länsi-Suomen väestöstä on löytynyt ns. sammuneita geenejä, jotka suojaavat diabetekselta ja sydän- ja verisuonitaudeilta.
Yksi kiinnostavia tutkimuskohteita on geenin muuttaminen tai muuttuminen toimintakyvyttömäksi. Tällaisia geenejä kutsutaan sammuneiksi geeneiksi. Professori Aarno Palotien johtamassa tutkimuksessa analysoitiin yli 80 harvinaista, mutta Suomessa muuta maailmaa yleisempää muutosta, joka hiljentää koko geenin. Aineisto saatiin yli 30 000 suomalaisen geeniperimästä.
Suomalaisilla on itse asiassa muita kansoja enemmän geenejä, jotka sammuttavat yksittäisen geenin toiminnan.
”Proteiinituotannon katkaisevat geenivariantit ovat ihmispopulaatioissa aika harvinaisia. Kuitenkin Suomeen uudisasukkaiden mukana tulleet proteiinituotannon katkaisevat geenivariantit ovat meillä muuta Eurooppaa yleisempiä ja siksi niiden tänne aikanaan saapuneiden varianttien terveysvaikutusten tutkiminen on Suomessa paljon helpompaa kuin muualla.”
Länsi-Suomen väestöstä on löydetty sellaisia poistogeenejä, joiden toimintakyvyttömyys ei aiheuta terveydellisiä ongelmia. Päinvastoin, ne suojaavat kantajaansa diabetekselta tai sydän- ja verisuonitaudeilta.
”Suomesta on löytynyt geenimuunnos, joka suojaa diabetekselta. Variantin kantajilla oli vähemmän diabetestä muihin verrattuna. Geenimuunnoksen kantajia on Pohjanmaalla enemmän kuin muualla maailmassa. Tästä voi olla hyötyä lääketeollisuudelle, jos pystytään matkimaan molekyylivalmisteilla tällaisen geenin toimintaa.”
Toinen esimerkki on lipoproteiini (a)n toimintaa ehkäisevä geeni. Sydäntautiriskiä voidaan arvioida mittaamalla verestä lipoproteiini (a). Lipoproteiini (a) eli LPA on LDL-kolesterolia kuljettavan lipoproteiiniperheen jäsen. Aineistosta löytyi esimerkiksi geenimuutoksia, joiden kantajilta puuttuu lähes kokonaan LPA-geenin tuottama lipoproteiini (a). Ihmiset, joilta lipoproteiini a puuttuu, sairastuvat muita harvemmin sydän- ja verisuonitauteihin.
”LPA-geenistä löytyy pari varianttia, jotka sulkevat pois sen toimintaa. LPA-proteiinia on tällöin veressä vähemmän, jolloin matalan tiheyden kolesteroli kiertää verenkierrossa vähemmän. Tällöin syntyy vähemmän verisuonitauteja. Proteiinitason alentaminen farmakologisin keinoin olisi mahdollista.”
Suomessa on tutkittu myös USF-1-geenin toimintaa. Ihmisillä geeni vaikuttaa veren rasva-arvoihn ja kolesteroliin. Kun geenin toiminta poistettiin hiirellä, veren hyvä HDL-kolesterolipitoisuus nousi.

SISu-hankkeen (Sequencing Initiative Suomi) ansiosta tiedot suomalaisten geneettisestä vaihtelusta on koottu yhteen tietokantaan.
”Sekvensoitu näyteaineisto on kerätty suomalaisista potilaista ja vapaaehtoisista. Aineistosta on laskettu tilastotietoa siitä, kuinka yleinen kunkin geneettisen variantin yleisyys on Suomessa. Kun on kerätty tarpeeksi iso tietokanta, niin saadaan selville minkälainen on ylipäätään suomalainen genominen variaatio.”
SISu-tietokannassa on tällä hetkellä perimän proteiineja koodaavat variantit reilulta 10000 suomalaiselta ja kaikkiaan koko perimäkin on sekvensoitu jo monelta tuhannelta suomalaiselta.
”SISu-tietokannan sekvenssidata antaa meillä mahdollisuuden täydentää meidän muita edullisemmilla genomisiruilla mitattuja aineistoja tilastollisilla imputaatioalgoritmeilla. Nyt pystymme aika tarkasti sanomaan minkälaisia geenivariantteja suomalaisilla on. Esimerkiksi jos yksi tuhannesta kantaa Suomessa tiettyä geenivarianttia, niin tällöin keskimäärin ainakin 20 henkilöltä pitäisi löytyä variantti nykyisestä tietokannasta.”
Tietokannasta on jo nyt apua potilaiden diagnostiikassa.
”Variaatiodata on tietokannassa ja dataa hyödynnetään koko ajan, erityisesti kliinisessä genetiikassa. Lähtökohta on, että sairaalan potilaan hoitoon saadaan lisäselvitystä tietokannasta. Jos siis epäillään, että geenissä oleva variantti saattaa olla taudin syynä, niin lääkäri tarkistaa tietokannasta kuinka usein suomalaisissa tätä varianttia esiintyy. Jos se on yleinen, ei ole todennäköistä, että se olisi harvinaisen taudin syynä. Jos se on harvinainen ja sen vaikutus geenin toiminnalle on merkittävä, niin todennäköisyys variantin merkitykselle myös taudin puhkeamisessa kasvaa. Tämä on hyvin konkreettinen kliininen käyttö tietokannalle.”

SISu-projektin dataa on kerätty tutkimusprojekteista ja potilaista. Projekti on kuitenkin keskittynyt pelkästään genomidataan, jolloin datan hyödyntämismahdollisuudet terveystutkimuksessa ovat rajalliset.
”Kaikista meistä pitäisi saada kerättyä talteen biopankkinäyte”, sanoo Ripatti. ”Ne, joilla on alttius sairastumiseen, pitäisi seuloa tarkemmin.”
Samuli Ripatin mielestä on suuri puute, että genomitietoa ei vielä ole saatavissa terveystarkastusten yhteydessä. Se pitäisi olla osana jokaisen rutiinitarkastusta, jotta voitaisiin tehdä konkreettisia päätöksiä hoidolle.
”Suomessa olisi tähän hyvät edellytykset. Meillä on hyvin toimiva työterveyshuolto ja perusterveydenhuolto sekä hyvä osaaminen geenitutkimuksessa.”
SISu:n jatkoksi alkoi elokuussa 2017 FinnGen-projekti, jossa taltioidaan puolen miljoonan suomalaisen genomit. Hankkeessa hyödynnetään kaikkien suomalaisten biopankkien keräämiä näytteitä. Perimästä saatava data yhdistetään kansallisissa terveydenhuollon rekistereissä olevaan tietoon.
”Työkalut riskiarviontien tekemiseen ovat olemassa ja tilastollisia malleja on kehitetty usealle taudille. Perimästä saadun datan tulkitseminen osana rutiiniterveydenhoitoa on lähivuosien tavoite. FinnGen osaltaan mahdollistaa tämän.”
Ripatti ryhmineen osallistuu tilastollisten algoritmien kehittämiseen, implementoimiseen ja testaamiseen.
”Kehitämme ennustealgoritmeja, jossa arvioidaan esimerkiksi sydän- ja verisuonitautien riskiä potilaalla. Yhdistämme genomidatan ja elintapatekijät, jonka perusteella tehdään ennuste. Haemme siis keinoja, jotka motivoivat potilasta muuttamaan elintapojaan.”
Ripatin ryhmä täydentää tilastollisilla algoritmeilla myös genomista tietoa. Suomen populaatiohistoriasta johtuen täällä pystytään ennustamaan paremmin ja tarkemmin kuin juuri missään muualla maailmassa puuttuvat genotyypit sirudatoihin. Algoritmi toimii hyvin suomalaisessa datassa, koska suomalaisten genomit ovat keskimäärin enemmän samankaltaisia kuin muualla. Laskennallisesti täydennetään sekvenssidatalla geenisiruilla kerättyä dataa.
”Jos oleelliset variaatiokohdat skannaavalla geenisirulla on 500 000 geenimerkkiä ja meillä on näiden mittausten lisäksi tiedossa geenisekvensseistä 30 miljoonaa genomivarianttia, me voimme täydentää geenisirulla tehdyn mittauksen kokonaiseksi genomisekvenssiksi hyvillä tilastollisilla laatumittareilla. Näin saadaan luotua riittävän luotettavia kokonaisia genomeja lisää huokeammin. Koko genomin sekvensointi on toistaiseksi huomattavasti kalliimpaa.”
Genomidatan säilyminen tulevaisuudessa ja sen analysointiympäristön suunnittelu on iso asia, jossa ELIXIR-infrastruktuurilla on keskeinen rooli.
”Meillä on olemassa tietovaranto, jota luvan saanut tutkija voi hyödyntää. Tietovarannon ollessa suuri, täytyy tutkijalle tarjota tietoturvallinen ja tehokas data-analyysiympäristö, jossa dataa voi tutkija analysoida.”
Tietosuojan takia parhain ratkaisu olisi esimerkiksi etätyöpöytä. Eri maiden populaatiodatasta tällä hetkellä on satoja kopioita eri tutkimusryhmien levypalvelimilla ympäri maailmaa. Se on suunnaton määrä dataa.
”Toisaalta meillä täytyy tulevaisuudessa olla genomidatan analysointiin soveltuvia ratkaisuja, jotka mahdollistavat valtavien aineistojen tehokkaan ja hajautetun tallennuksen ja analysoinnin. Tätä haastetta eivät nykyiset paljon vaatimattomampien datamäärien aikanaan kehitetyt suljetut etätyöpöytäratkaisut ratkaise vaan tarvitaan avoimia, tehokkaasti pilvipalveluita ja kansainvälistä yhteistyötä hyödyntäviä laskentaympäristöjä. Tämän miettiminen on ihan keskeistä.”
Ari Turunen
5.11.2018
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Samuli Ripatti, & Tommi Nyrönen. (2018). Help from the Finnish genome for the prevention of cardiovascular diseases. https://doi.org/10.5281/zenodo.8118771
Lue myös:
Massiivinen datanhallintaprojekti: suomalaisten perimä kerätään talteen
Lisätietoja:
FIMM
Suomen molekyylilääketieteen instituutti (FIMM) on kansainvälinen tutkimuslaitos, jonka toiminta keskittyy sairauksien molekyylitason mekanismien selvittämiseen genetiikan ja lääketieteellisen systeemibiologian menetelmin. Tavoitteena on tutkimustiedon siirtäminen terveydenhuollon käyttöön mm. henkilökohtaista lääketiedettä edistämällä.
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org


 ELIXIR is partly funded by the European Commission
ELIXIR is partly funded by the European Commission