
Each member state of ELIXIR establishes a ‘Node’. A Node is a network of organisations that work within a member state. Each Node has a lead organisation that coordinates the local ELIXIR activities. ELIXIR Finland is hosted at CSC – IT Center for Science. CSC operates resources and services that are part of ELIXIR, like pan-European ELIXIR identity and access infrastructure. ELIXIR-FI services are developed with the European e-Infrastructure (e.g. EuroHPC/LUMI, GAIA-X, EOSC, GEANT, NeIC).
The ELIXIR node in Finland increases capabilities to support research on health & life sciences data. We connect ELIXIR to biobank data management and training in Finland, and link the national bioinformatics network (https://www.biocenter.fi/). The mission of Finnish Biobank Cooperative –FINBB is to enhance the competitiveness of Finnish health and biomedical research by providing researchers a centralized access to collections and services of the Finnish biobanks and their background organizations. ELIXIR Finland has actively collaborated since 2012 with the National institute of health and welfare (THL) and Univ. of Helsinki/Institute for Molecular Medicine (FIMM) operating BBMRI and EATRIS Finland nodes.
The website of science and researchers, Fingenious.fi, has been chosen by STM and THL as Finland’s common brand to increase biomedical research in our country, especially in research activities under Act on Secondary Use of Health and Social Data.
Node seeks to form a legal link accepted by the European Commission to all Finnish higher education institutes and research organisations. CSC has formed a general framework agreement between all these organisations.
ELIXIR-Finland co-lead the ELIXIR Compute Platform, and the Global Alliance for Genomics Health (GA4GH), Data Use and Researcher Identities workstream, as well as technical infrastructure for the European 1+ Million Genomes initiative. The research service development at CSC in these contexts contributes to the ELIXIR-FI Node positioning and strategy. One of the expected outcomes is leadership in the upcoming implementation of European Health Data Space (EHDS), such as Genomics Data Space, to ensure Finnish data infrastructure will be interoperable with the European data spaces. In addition, CSC participates in large public-private partnerships like the Innovative Medicines Initiative (IMI2) BIGPICTURE project (2021-27) that is building a large-scale digital pathology image repository.
Examples of ELIXIR Finland funders, collaborators and projects:









By combining genomic data with data in national health registries, an artificial intelligence model can be developed that can be asked questions about potential future disease treatment. Such statistical and machine learning models are able to predict the occurrence of a disease.
Associate Professor Andrea Ganna from the Institute for Molecular Medicine Finland (FIMM) at the University of Helsinki is interested in combining genetic and statistical data.
“Healthcare can benefit from machine learning, which is constantly learning from the huge amount of data available to it. Questions can be posed to AI about potential hospital treatments in the future. AI can tell what a person’s life expectancy is, or how much prescription drugs will cost next year with certain life choices.”
Ganna uses large datasets to identify the demographic and genetic traits that underlie common and complex diseases. AI can make a risk calculation for each individual by modelling data from longitudinal tracking of diseases and medications along with genetic, family and demographic data.
In particular, Ganna uses FinRegistry data in his research. FinRegistry is a joint research project of the Finnish Institute for Health and Welfare (THL) and FIMM, led by Research Professor Markus Perola from THL. It is one of the world’s largest studies that makes secondary use of registry data.
“The dataset contains data from 7.2 million individuals, i.e. the entire population of Finland and many relatives who have already died. It contains a lot of different, wide-ranging information, including health information, information on family relationships, socio-economic information, and laboratory results and prescriptions. This is an enormous data set.”
The database includes data from 19 national registers, such as the Finnish Cancer Registry, the Drug Purchase Register and Kanta. Kanta is a register that brings together customer and patient data from healthcare and pharmacies. More than one billion pharmaceutical purchases alone have been registered in the collection so far. These are data points, with each individual fact being one data point. In total, there are more than 6.5 billion data points in the dataset.
“I consider the project to be unique. The data is rich and varied,” Ganna says.
“Combining health information with social and economic information is extremely important to me. These are often considered to be separate from each other, but combining the data is vital for health. We need to consider socio-economic information to understand how “fair” AI models are. We don’t want AI model to work worst in the most fragile sectors of our population. ”

Once the data has been collected from different registers, the individual data is encrypted and stored in the sensitive data services of the Finnish ELIXIR node of the CSC - IT Center for Science. Ganna and his research team analyse the data in this secure environment.
“We have worked with the CSC to make services more useful for researchers. We started with simple analyses and moved towards more complex models.”
There is a colossal amount of sensitive data in Ganna’s research.
“We are creating a data matrix for AI and machine learning models, but we are also very aware of the sensitive nature of the data. We cannot re-identify individuals and we use very advanced security measures to avoid unauthorized access. ”
This information may be used for various purposes.
“We are gaining a better understanding of the different clusters of disease, and are able to make better predictions. We can even create a digital clock that describes ageing. It uses data from the whole population to give each person in Finland a kind of digital age, based on an indicative trajectory derived from health data.”
The plan is to integrate the registry data by Ganna and his research team into the genomic data in the biobanks. This is an ambitious project, aiming to identify emerging diseases in individuals that could be prevented from developing. In the future, the data could be used to identify at-risk individuals who could benefit from preventive drug treatment.
There is already enough data to make this possible, according to Ganna. Ganna cites the FinnGen research project, which has already produced genome data on half a million people in Finland deposited in the biobanks. The project involves investigating the genetic background of various diseases in the Finnish population. The next step is to determine how genes influence the progression of diseases.
“It would be possible to contact people at risk, as their information is in the biobanks. Of course, this assumes that the people in the biobanks have given their consent to be contacted.”

In Ganna’s view, the CSC’s sensitive data services should be further developed to support machine learning models in particular. So far, AI models have only been tested in research. This is because, under current Finnish legislation, it is not possible to automatically use registry data to re-contact people at risk.
“We can make these beautiful models, but we can’t warn people at risk,” Ganna says. However, he adds that if the models are simplified enough, they can be used in clinical care.
One example he cites is the respiratory syncytial virus (RSV) that Pekka Vartiainen from FIMM and Markus Perola from THL studied in the FinRegistry project. RSV is the commonest virus causing respiratory infections in young children worldwide. The researchers created a simplified model that can be used in the clinical management of RSV. In Finland, doctors could now use registry data to identify who is at risk of contracting the virus and who could be treated in time.
Ganna believes that in the future, healthcare will benefits from AI models that understands health data.
“AI will support clinical decision making, by helping doctors to better summarize health trajectories of their patients. The future is bright.”
Ari Turunen
30.5.2024
Read article in PDF
Citation
Turunen, A., & Nyrönen, T. (2024). An AI model that understands health data warns of future diseases. https://doi.org/10.5281/zenodo.13691998
More information:
Finnish Institute for Life Science (FIMM)
FIMM is part of HiLIFE Helsinki Institute of Life Science -research center.
https://www.helsinki.fi/en/hilife-helsinki-institute-life-science/units/fimm
CSC – IT Center for Science
is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centra- lised IT infrastructure.
https://research.csc.fi/cloud-computing
ELIXIR
builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 Euro- pean countries and the EMBL European Molecular Biology Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish centre within this infrastructure.

The iCAN-PEDI study, investigating drug treatments and drug responses in children with cancer, is a part of the large-scale iCAN Flagship project of Academy of Finland. The study combines genetic and epigenetic information on the patients’ cancer with data on the drug testing of patient derived cancer cells. Together with collaborators, the team also develops artificial intelligence (AI) -guided analysis for the drug testing data. The project aims to deliver findings that may affect treatment approaches back to the doctors. This helps the doctors to construct more individualised treatment approaches.
Vilja Pietiäinen, senior scientist and adjunct professor (docent) in cell and molecular biology at the Finnish Institute for Molecular Medicine (FIMM), leads the iCAN-PEDI project with Minna Koskenvuo, a clinician (in Pediatric Hematology and Oncology) at the HUS New Children’s hospital and at Turku University hospital. In addition, many clinicians from HUS’s New Children’s Hospital and researchers from the University of Helsinki are involved in the project. Pietiäinen says she wants to make cancer treatments more individualised.
“From a medical perspective, the way we treat childhood cancers is already individualised. However, studying children’s tumours on a molecular level can help us find more effective drugs for specific types of cancers. The solid tumours in children are often heterogeneous and difficult to diagnose only based on pathology. In addition, some of these tumours are very rare. The types of cancer seen in children generally include fewer genetic changes, which means more molecular-level data is required for a diagnosis. The diagnosis, in turn, will affect the treatment approach.”
According to Pietiäinen, collecting large amounts of data on individual patients can significantly improve the diagnostic process and help find new ways to classify different cancers. It will also allow researchers to understand how much variation can be found even within well-known types of cancer.
“We want to better understand why a certain patient responds to drugs the way that they do. This will allow us to develop better and more individualised ways for choosing a treatment approach for a specific patient.”
She and her team combines patient’s molecular-level cancer data with cell models that represent each patient’s individual cancer cells. Exome sequencing allows researchers to examine the information of roughly 20,000 genes in a single run. Transcriptomics, in turn, makes it possible to analyse thousands of RNA molecules simultaneously. This process provides information on how different genes are expressed. Tissue imaging serves to illustrate the biomarkers expressed by different types of cancer tissue. The resulting data is stored in HUS Acamedic, the secure environment used by the iCAN project.
Pietiäinen says that often, genetic data alone is not enough to determine how an individual patient’s cancer will respond to a specific drug.
“We need to study the drug responses of individual patient’s cancer cells with the help of microscopic imaging in the laboratory. Cancer is a very heterogeneous disease: not all cells will necessarily respond to the same drug(s). However, we are also interested in those cells that do not show a response, and have developed the resistance to the used treatments. A combination of different drugs may be required to eradicate all the cancer cells.”

Once the study-consented patient has been operated on, a cancer tissue sample is sent directly to a pathologist, who do the diagnosis and will forward the additional sample directly to the researchers involved in the study. Drug susceptibility is tested with a multi-well cell culturing plate in a process that utilises robotics. The wells are very small, which means that only a small amount of the valuable cell samples is required. A single plate can be used to test dozens of drugs at a time.
Researchers fill the wells with different concentrations of specific drugs and cancer cell samples. With the help of microscopic imaging, they can inspect how the drugs influence the cancer cells in the wells of the plate. Machine learning models allow researchers to more effectively analyse the images of cancer cells. The artificial intelligence used by the research team has been trained with the Finnish ELIXIR node’s, CSC’s high-performance computing clusters.
“We call this phenotypic imaging. Microscopic imaging allow us to identify hundreds of different cell characteristics from images of drug-treated cancer cells. This information is important for further training the machine learning model. If we are able to clearly identify certain phenotypes, we can also teach the machine to do the same by showing it how certain cells have responded to a certain drug. After this, we can provide the machine with a new dataset, in which case it will be able to classify the cells by how they show up in the images. On the other hand, artificial intelligence, especially deep-learning solutions, can also help us to discover traits or phenotypes that we as humans are not able to either detect or classify.”
Once the hundreds of analysed traits are fed into the artificial intelligence, it will be able to differentiate between different drug responses at single-cell level. The data can also be used to sort patients into groups based on the drug responses they exhibit.
Identifying the optimal drug response requires several different data sources. As an example, Pietiäinen mentions a large European project (ERA PerMed) that the project researchers were previously involved in.
“We know that there is currently no targeted drug treatment for up to 90 per cent of cancerous gene mutations. Therefore, we were only able to partially determine the efficacy of different drugs and drug targets for different drugs based on genetic information. However, drug testing did show that patients’ cells responded to certain drugs.”
Pietiäinen considers it crucial to be able to compare drug testing data from cancer studies to the response shown by healthy cells, for example.
“This way, we will be able to see such things as whether a particular patient’s cells respond particularly well to certain drugs. This information can then be compared to patients’ genetic and gene expression data. For instance, we could find out that a specific patient has a mutation that makes the cancer more susceptible for a certain drug, causing them to respond better to that drug. On the other hand, non-mutational information, such as how genes are expressed, how signal pathways are activated, or how epigenetic changes arise, may help us better understand how cells respond to different drugs. These different types of data can then be used at the individual level but also to divide patients into different subgroups to find more suitable treatment approaches.”
The patient’s blood samples or cerebrospinal fluid samples can be used for fluid biopsies and used to inspect how the tumour’s DNA is expressed. This will show how well the patient is responding to the drug, or if the cancer has recurred.

The iCAN research project, which is funded by Academy of Finland, covers most currently known types of cancer. Several research groups who concentrate on different types of cancers and research groups working on improving the relevant research methods are involved in the project. Information on the cancer is compared with the patient’s other health data in the secure HUS Acamedics environment.
“All the data we upload on Acamedics is available to all researchers participating in the iCAN project. We have a wealth of material that we can compare our findings against. This allows us to identify, for example, patient group and patient specific genetic markers in the genetic and other omics data.
All data, which includes data types such as drug testing data, genetic data and transcriptomics data, are combined using a powerful tool called an Integrated Molecular Tumour Board system (iMTB). In their research project on children with cancer, Pietiäinen and her colleagues are also evaluating how doctors can quickly make use of the results of recent or ongoing research.
“We aim to report clinically relevant findings to the doctors, thereby hopefully helping to choose a better treatment approach if they have ran out of recommended approaches.”

The iCAN utilises the SD Connect service provided by the Finnish ELIXIR node CSC for transferring sequencing data to the Academics environment.
The data is encrypted using Crypt4GH, a protected standard encryption method developed by the Global Alliance for Genomics & Health for sharing human genetic information.
“This ensures that the information can be used in all of the services included in CSC’s SD service suite, and may even be potentially shared with other service providers who possess similar information.”
The sheer magnitude of the iCAN project is illustrated by the fact that the accumulated data is expected to reach three petabytes by 2026.
“All of this data makes it possible for us to understand the molecular makeup of different types of cancer and patients’ drug responses.”
Ari Turunen
29.9.2023
Read article in PDF
Citation
Turunen, A., & Nyrönen, T. (2023). Artificial intelligence helps researchers find suitable drugs based on patient’s genetic data and cancer cell samples. https://doi.org/10.5281/zenodo.10796468
Institute for Molecular Medicine Finland (FIMM)
FIMM is part of HiLIFE Helsinki Institute of Life Science -research center.
https://www.helsinki.fi/en/hilife-helsinki-institute-life-science/units/fimm
CSC – IT Center for Science
is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centra- lised IT infrastructure.
https://research.csc.fi/cloud-computing
ELIXIR
builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 Euro- pean countries and the EMBL European Molecular Biology Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish centre within this infrastructure.
Modelling cells and simulating how they work gives a boost to personalised treatment plans. The PerMedCoE project combines clinical patient data with data related to the operation of genes, proteins and cells. The goal is to develop tools that can be used in precision medicine. The modelling of cells in detail is, however, a major undertaking, requiring a lot of computing power by supercomputers.
Personalised medicine will open up great opportunities in the future. The goal is to be able to combine a patient’s clinical data with genetic data to create personalised treatment plans. The PerMedCoE project (HPC/Exascale Centre of Excellence in Personalised Medicine) is working to improve the compatibility of personalised medicine modelling software with next-generation exascale supercomputer systems. Their theoretical computing power is as much as 10^18 operations per second. The project involves researchers from several European universities and hospitals, and focuses on four cellular-level modelling software systems based on open source code. Further to working on software development, the research project aims to make precision medicine tools easier to use and compatible with a number of European high-capacity computer centres.
“Our aim is that these four software systems could be used in many supercomputers,” says Project Manager Sampo Sillanpää from CSC – Finnish IT Center for Science.
“At the moment this is technically very challenging to implement, because all high-performance computing environments are unique in terms of their system architecture.”
The plan is to achieve seamless operation of software and data masses through jointly agreed technologies. In the PerMedCoE project, this is done by means of workflow software and what is known as container technology. Workflows are used to automate different steps required to analyse data. Further to the actual modelling step, a workflow may involve, for example, data pre-processing and steps relying on results produced by the modelling tool. Container technology can be used to specify a standardised environment in which scientific software is run in each high-performance computing environment taking part in the project. Once the software code and libraries and settings are placed in the container, they can be transferred from one computer to another.
“The software and data are, in a manner of speaking, packaged in a single box, making it easy to move it from one environment to another. CSC have several container technology experts, so the tools can be transferred from one platform to another,” says Sillanpää.
“The containers enable experts to create user-friendly workflows. Workflows in the PerMedCoE project consists of several building blocks, each performing a specific precision-medicine calculation. One building block may pre-process data, a second one carrying out the actual analysis, and a final one delivering the outcome to the end user. This means that the users may not even have to know how many building blocks the automation contains, but focus on analysing the results.”

The usefulness of technologies built in the project is assessed by means of various use cases. Workflows are used to analyse which disturbances may be caused at the cellular level by diseases and how the drugs that have been administered actually work. The models can be used to examine cellular metabolism and signal transmission.
“In PerMedCoE use cases, we make use of publicly available genomic data. Now we can study samples taken from coronavirus patients and look for markers in the genomic data to learn which patient groups are particularly susceptible to the dangerous forms of the disease.”
The project models the skin’s epithelial tissue that reacts to a coronavirus infection by calling various immune cells to work against the virus. This may help to identify patient groups that are susceptible to the serious form of the disease.
“The idea is that we are able to run several models simultaneously for individual patients. This results in efficient analysis of sufficiently large amounts of data, so that the modelling results can be used for personalised medicine,” says Senior Data Scientist Jesse Harrison of CSC.
When modelling the COVID-19 use case, cellular-level RNA sequence data is used. Single-cell RNA sequencing (scRNA-seq) may reveal regular interaction between genes, cell lineages, cellular difference and the cellular frame of reference in its environment.

Another key use case of the project concerns cancer diagnostics. The goal is to create modelling tools for the prediction of cancer tumours and the development of patient-specific treatments. The material has been collected by the Wellcome Institute and the Massachusetts General Hospital Cancer Center. The database contains more than a thousand tumour-tissue cell lines.
“The project aims, among other things, to identify new drug combinations that could be useful in cancer treatment,” says Jesse Harrison.
This will hopefully lead to more personalised cancer treatments and faster diagnostics.
“In order for this to become reality, closer collaboration will be needed between high-performance computing centres and medical organisations. This is because we are talking about large amounts of data, and analysing such large-scale personalised data sets is simply not possible with a desktop computer.”
The results and tools of PerMedCoE are open to all researchers.
“When the project ends in summer 2023, we will have updated versions of modelling tools developed from open source code, and these will be made available to the research community. The project will also create new expertise to support the use of precision medicine tools in CSC computing environments.”

The EU is funding a number of projects that will enable personalised patient treatment in the future. Cancer is an example of a disease that is extremely individualised, whether it is breast, lungs, liver or prostate cancer.
For example, the Conquering Cancer: Mission Possible programme under Horizon Europe will – according to Esa Pitkänen, researcher at FIMM (the Institute for Molecular Medicine Finland) – pave the way to future cancer research and treatments. The ambitious programme strives to understand the mechanisms that lead to cancer, to discover methods for early detection of cancers, and to achieve breakthroughs in personalised cancer medicine.
“What is common to all these goals is a versatile and comprehensive use of health data by means of new calculation methods. Artificial intelligence algorithms based on machine learning have indeed already achieved some encouraging results in terms of, for example, digital pathology. The next leaps will be made by combining various data sources in order to make individualised cancer screening and treatment recommendations,” says Pitkänen confidently.
Within the programme, cancer patients become active participants in cancer treatment development, for example by being able to send their health data securely to researchers. This also gives the patients new research data about their own illness.
“It is important that as treatments develop, people are given an equal opportunity to benefit from new treatments regardless of their background. I am glad to see that this has been taken into account in the programme’s recommendations. There is also special emphasis on cancers among children and young people.”
Ari Turunen
23.8.2022
Read article in PDF
Citation
Ari Turunen, Sampo Sillanpää, Esa Pitkänen, & Tommi Nyrönen. (2023). Personalised medicine against cancer and viruses. https://doi.org/10.5281/zenodo.8154548
Mode information:
HPC/Exascale Centre of Excellence in Personalised Medicine
CSC – IT Center for Science
is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centralised IT infrastructure.
https://research.csc.fi/cloud-computing
ELIXIR
builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 European countries and the EMBL European Molecular Biology Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish centre within this infrastructure.

Diabetes is a major chronic disease that comes with a number of associated conditions that pose remarkable challenges. Such diseases include diabetic kidney disease, diabetic retinopathy, coronary heart disease and strokes. Now, a Finnish research team sequences the genomes of thousands of individuals with diabetes to look for genetic risk factors.
Individuals with diabetes have a higher risk of cardiac diseases in comparison to the rest of the population. A third of individuals with type 1 diabetes, earlier also called juvenile diabetes, develop kidney disease that has a remarkable impact on mortality and the risk of cardiac disease. On the other hand, diabetic retinopathy is the most significant cause of blindness among working-age population.
Finnish children and young adults have the highest risk of type 1 diabetes in the world. Type 2 diabetes is often considered a disease of the western life style, but the highest patient concentrations are found in middle-income countries with China and India topping the statistics of individual countries.

“Diabetes is associated with remarkable and severe complications. The associated conditions have a major impact on the quality of life and life expectancy,” explains Niina Sandholm, Genetic Epidemiologist at Folkhälsan Research Centre. Sandholm is involved in the FinnDiane research project, the objective of which is to identify hereditary and environmental risk factors predisposing to diabetic complications. FinnDiane-study is a collaboration project between University of Helsinki, Helsinki University Hospital (HUS) and Folkhälsan Research Center
According to Sandholm, genetic data could be beneficial to young patients in particular, already at an early stage prior to the emergence of risk factors.
“Currently, the use of genetic data in clinical treatment is mostly associated with rare diseases, but our results and earlier research suggest that extensive genetic data could also be utilised in the early prevention of common diseases.”

FinnDiane, established by Professor Per-Henrik Groop in 1997, is a follow-up study participated in by almost 8,000 individuals with type 1 diabetes. The participants are recruited at 80 hospitals and health centres across Finland. It is one of the most extensive research materials on type 1 diabetes and associated complications in the world. Now, this material is used for sequencing the genome of 1,700 patients.
Sandholm has experience in research projects where genome-wide association study (GWAS) is applied as research method. The method is particularly useful when the genetic background of the studied disease is complex. It enables identifying genetic variants that either increase the risk of diabetes or protect from the disease. The GWAS method involves identifying genetic variants from the participants’ blood samples. The number of these variants ranges from hundreds of thousands to millions, and the number of patients may vary between thousands and hundreds of thousands.

A GWAS study on 5,600 FinnDiane participants with type 1 diabetes revealed, for example, a new genetic locus related to cardiac diseases close to the DEFB127 gene. It is the most extensive study of its kind to date. Locus means the location of a DNA sequence on a chromosome. The variation of a sequence is called an allele.
The same study that identified the DEFB127 gene also revealed other genetic factors predisposing to cardiac diseases.
“Many predisposing genetic factors have been identified for cardiac diseases and other common medical conditions. One of the most significant factors lies within the region of genes CDKN2A and CDKN2B. Diabetics have a remarkably higher risk of cardiac disease than the rest of the population, and there is little knowledge of the related genetic factors. Our research indicated that the same genetic area CDKN2A/B affects the risk of cardiac disease also in individuals with type one diabetes.”
A third of individuals with type 1 diabetes develop a kidney disease. Some may develop renal failure that may, at worst, lead to the need for dialysis treatment or a kidney transplant.
Another study analysed various data sources to identify connections to kidney disease in 27,000 diabetics. GWAS is a fast and economic method, but it cannot identify all variants. Therefore, the research team have turned to sequencing the entire genomes of patients.
“Variants identified with the GWAS method are common, and individual variants’ impact on the risk of developing a condition is quite moderate. The objective of sequencing is to identify rare variants that may have a significant impact on developing a condition at the level of individual patients. The worst case scenario is that such a variant prevents the functioning of an entire protein.”
According to Sandholm, the research results may help predict the risk of developing a condition or lead the way in developing new medicines.
“The broader goal of genetic research is to identify variants that affect the risk of developing a disease or directly cause a disease. This enables a better understanding of the causes of diabetic complications.”
The ultimate goal is to learn to prevent and find cures to diseases associated with diabetes.
“Our aim is to read the entire DNA sequence of all patients. This will result in a huge amount of data,” says Sandholm.
“The sequencer produces DNA data in strands of 150 base pairs. To verify the data, our goal is to read each one of the three billion DNA base pairs an average of 30 times. This means that there will be 600,000 strands of 150 base pairs per patient.”
To map the entire sequence, the sequenced strands must be placed in the correct order with the help of a reference human genome. This requires enormous computing capacity which is provided by the ELIXIR centre at CSC, the Finnish IT Centre for Science.
“The purpose is to organise the data so that it would enable identifying how each base pair variant affects a given disease at the level of individual patients. Our aim is to identify rare variants that cannot be identified with the GWAS method. Only a few patients in the sample exhibit rare variants.”
Single nucleotide polymorphisms (SNP), or variants in the DNA base pairs, are a sort of end result of the data processing.
“The variation in the DNA sequence is expressed as SNPs. Each patient has either no alleles or one or two variants. They are markers that indicate which diseases the variant may cause.”
The research group has already sequenced the entire genomes of 600 patients.
“Based on the initial results, we identified individual variants that are clearly associated with the risk of stroke, for example. There are also variants in genes that have previously been associated with congenital kidney diseases. Now it appears that variants in the same genes also affect the development of diabetic kidney disease.”
Along with her colleagues, Niina Sandholm studies the protein-coding parts of the gene and gene regulatory regions that may have links to risk factors contributing to diabetes.
“The area between genes – 95% of the genome – contains plenty of regulatory regions that determine which gene appears in which tissue. As such, the DNA sequence is the same in each human cell, but gene regulation causes eyes to develop into eyes and kidneys into kidneys. In this respect, gene regulatory regions and their changes play a key role.”

This study is one of the world’s first to sequence the entire genome this extensively with regard to a specific disease. For the time being, the sequencing of the entire genome is relatively rare.
“The current trend is to sequence the exome with a focus on the protein-coding parts. However, it is only a matter of time that sequencing the entire genome becomes more common. ELIXIR, for one, invests in the development of full genome sequencing and genomic data processing methods.”
CSC provides the ePouta service for processing sensitive data. In the ePouta cloud service, virtual private servers operate on CSC’s computing platform under increased data security. The users receive dedicated cloud resources which are separated from CSC’s other computing environments. The FinnDiane research group uses the computing cluster of Institute for Molecular Medicine Finland (FIMM) which is connected to CSC’s sensitive data computing platform via the ePouta light path. By scaling the computing resources, the light path enables faster processing of the project data. In addition, the researchers have been allocated a remarkable amount of storage space to store the genomic data.
Ari Turunen
3.3.2022
Read article in PDF
Citation
Ari Turunen, Niina Sandholm, & Tommi Nyrönen. (2022). Finnish research team sequences the genomes of thousands of individuals with diabetes to look for genetic risk factors. https://doi.org/10.5281/zenodo.8154493
More information:
Folkhälsan
FinnDiane
CSC – IT Center for Science
is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centra- lised IT infrastructure.
https://research.csc.fi/cloud-computing
ELIXIR
builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 Euro- pean countries and the EMBL European Molecular Bio- logy Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish centre within this infrastructure.

Glaucoma is a progressive disease of the optic nerve that causes damage to the optic nerve head and nerve fibre layer. The risk of developing glaucoma increases with age. Some 2% of people over the age of 50 have glaucoma, and more than 5% of those over 75. There are estimated to be more than 60 million patients with glaucoma globally, of which around 6 million are categorised as being visually handicapped.
The challenging thing about glaucoma is that in its early stages it exhibits no or very few symptoms. Early diagnosis is very important because any damage that has already occurred cannot be reversed. The objective with treatment is to prevent any visual handicap caused by glaucoma. With most patients, the condition advances gradually over many years. However, with a small percentage of patients, the disease may lead to damage in a shorter period.
For purposes of glaucoma detection and identification of progressing speed, it would be best if healthcare systems found the high-risk cases as early as possible. Artificial intelligence models are currently being developed for early detection of glaucoma.
Researcher and project manager Ara Taalas specialises in data science, artificial intelligence and machine learning algorithms in medicine. One of his research objectives, in a joint project involving the Institute for Molecular Medicine Finland (FIMM) and Terveystalo health clinic, is to develop effective learning algorithms for glaucoma detection. Previously, Taalas modelled stem cell differentiation processes and worked in drug design.
According to Matti Seppänen, chief physician and Head of Ophthalmology at Terveystalo health clinic, glaucoma diagnosis and classification are based on the examination of the optic nerve head, nerve fibre layer and anterior chamber angle, intraocular pressure measurement, and a visual field test.
“The pathogenesis of glaucoma is not known, but damage to nerve cell structures probably contributes to glaucoma damage.”
Probably some 30–50 per cent of patients have intraocular pressure which is considered normal (10–21 mmHg). Patients have an individual susceptibility to the development of glaucoma damage at different intraocular pressure levels. Some patients develop glaucoma damage at lower pressure levels, while other patients may have minor damage even at higher pressure levels.
“At the moment, a glaucoma diagnosis requires examination by an ophthalmologist and several additional examinations. The optic nerve head can be examined by means of, for example, biomicroscopy and stereo papilla photography. The nerve fibre layer can be examined with colour fundus photography or optical coherence tomography (OCT) of the nerve fibre layer.”
During an examination, glaucoma may be suspected on the basis of the shape of the optic nerve head, for example. The structure of the optic nerve head can be evaluated with a measurement of the cup/disc ratio, meaning that the size of the optic nerve cup is compared to the size of the outer edge of the optic nerve head.
“Damage to the nerve fibre layer may show in an OCT examination as a thinned nerve fibre layer. In colour fundus photography, defects in the nerve fibre layer may also be discovered. A glaucoma diagnosis is often based on several examinations, and currently there is no single method for screening the entire population for glaucoma. Artificial intelligence applications may in the future bring considerable help for screening and diagnostics.”
Esa Pitkänen from the Institute for Molecular Medicine Finland FIMM (University of Helsinki) tells how glaucoma can be studied with the help of algorithms.
When developing the artificial intelligence model, Ara Taalas focused on how the nerve layers of the fundus appear in the photographs. The algorithm will help to detect changes in the fundus pictures that can indicate damage to the nerve fibre layer. The purpose of the model is to find out whether subtle changes in the network in the fundus, as they become darker and more monotonous, can be linked to damage in the nerve fibre layer.
“This is one of the factors the model is designed to focus on. In the future, the model will be taught more nerve fibre patterns in the fundus. The purpose of these algorithms is to find ways that will help doctors to make decisions. And advanced artificial intelligence system may detect changes that not even the most experienced clinician can see.”

Examinations on the eye’s structure and operation involves variations caused by the examination method used, experience of the person assessing the case, and the patient and how serious the disease is. Evaluating the optic nerve head does not always result in sufficient accuracy using the current methods. The result of the visual field examination may be normal even if the optic nerve and nerve fibre layers have been damaged. This is because structural damage usually occurs before any visual field defects. If we are able to develop applications that examine more accurately and more efficiently any structural changes, glaucoma diagnoses may be made earlier.
According to Taalas, one application for the model could be that the artificial intelligence model is always used when performing an eye examination.

“Population surveys have found that up to half of those who have glaucoma have not actually been diagnosed with it. The existing screening methods are not cost-effective enough and a general screening of the population cannot be done for lack of sufficiently good methods. If artificial intelligence applications were able to identify with sufficient accuracy patients that have a higher-than-average susceptibility to develop glaucoma, it would be easier to screen out those among the population that do not yet have the symptoms and offer them early treatment for best results.”
One of the future versions is that during a visit to the opticians or healthcare worker, the examination would include fundus photography, and at the same time artificial intelligence would analyse the patient’s fundus photo. If artificial intelligence indicated that the patient had a higher risk than average to develop glaucoma, the patient would be referred to further examinations at an early stage.
With artificial intelligence applications, the division of work would probably change dramatically in the optical field and the diagnosis of eye diseases. This would also result in significantly higher numbers of patients being treated. As the age structure of the population is changing, the number of glaucoma patients in Finland will double from the current figures by 2030.
Taalas uses the computing services of Finland’s ELIXIR Center CSC. He develops models together with researchers in FIMM’s Machine Learning in Biomedicine team, and the same source code can be used on the computing servers of both CSC and Terveystalo.
“Finland is at a high level in terms of data management, but individual healthcare actors typically do not have a comprehensive picture of their patients – patient data is often scattered between various service providers. When customers go to a different organisation, the data does not follow them, which may make diagnosis and treatment more difficult. From the viewpoint of a researcher, the ideal thing would be to have a site for the entire country where each patient’s medical history could be found in its entirety.”
Data description should also be standardised.
“The structure of patient data systems has a major effect on the usability of any data entered into it. Fields where data can be entered in free form may be convenient for the person typing it in, but cause a lot of trouble to data analysts when trying to utilise it. Analysts often have to do a lot of work to standardise the data and to identify entries that contain errors. Modern patient data systems have in this respect become better in that they are much more structured.”
Ari Turunen
23.11.2021
Read article in PDF
Citation
Ari Turunen, Lila Kallio, Arho Virkki, & Tommi Nyrönen. (2021). Patient data creating better artificial intelligence models. https://doi.org/10.5281/zenodo.8135413
More information:
Institute for Molecular Medicine Finland FIMM, University of Helsinki
Terveystalo
CSC – IT Center for Science
is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centra- lised IT infrastructure.
https://research.csc.fi/cloud-computing
ELIXIR
builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 Euro- pean countries and the EMBL European Molecular Bio- logy Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish centre within this infrastructure.

Deep learning has revolutionised cancer research. Deep neural networks can automatically detect features within a patient’s sample data that can be used to identify cancers. In the future, learning algorithms will be able to identify potential early-stage cancers from a blood sample. Esa Pitkänen and his research group at the Institute for Molecular Medicine Finland (FIMM) are developing a new generation of deep-learning algorithms.
Algorithms have been used to identify cells in sectional images of tissue samples. For instance, if tissue cells appear atypical, the algorithm will spot this and determine if the cells are cancerous. DNA sequence data from tumours is now being used along with imaging data to identify cancers.
“Until recently, it was difficult to tell from a DNA sequence what kind of tumour an identified sequence came from. Now new technologies and deep learning algorithms have been created,” Pitkänen says.
Pitkänen and his team are developing algorithms that identify short, repetitive snippets of DNA sequences. These algorithms can be used to find DNA sequences that mutate frequently in a particular type of cancer or to which certain proteins involved in gene regulation bind. Analysis of these sequences can be used for various purposes, such as charting the causes of cancer and developing medicines.
“The replication of DNA in cell division is not perfect; mutations can occur during the process. The division of a single cell involves the copying of about six billion nucleotide pairs in DNA, so errors will inevitably occur. Even the slightest probability of errors is enough to guarantee mutations,” says Pitkänen.
“If enough mutations occur in genes that prevent tumour growth, for example, cancer may start to develop.”
An example of this is a point mutation in which one base within the DNA strand is replaced with another. The enzymes involved in copying DNA may make a mistake when a cell is dividing, for instance by incorrectly repairing the part of DNA that was damaged by ultraviolet radiation from sunlight. A typical mutation caused by ultraviolet radiation that can result in skin cancer is that two consecutive cytosine (C) base molecules in the base pairs of human DNA are converted to two thymine (T) base molecules. When skin cancer-specific mutations of this type are detected in sufficient numbers, the algorithms can learn to associate them with a particular type of cancer.
“We try to predict the type of cancer and tumour from the mutations. This also provides information on how treatment can be developed.”
Pitkänen and his group analyse blocks of sequences and train algorithms to pinpoint deviations in them. From these abnormalities, the algorithm can detect tumours and classify them into different cancer types.
“Before joining the Institute for Molecular Medicine Finland, I worked at the European Molecular Biology Laboratory in Heidelberg, where I participated in the Pan-Cancer Analysis of Whole Genomes (PCAWG) project. This project involved the analysis of more than 2,600 entire cancer genomes. My group is using data from the PCAWG project in several of our cancer genomics projects.”
An algorithm developed by the group has been taught the mutations found in the tumour samples of 2,600 cancer patients. This sample set contained about 47 million mutations. Approximately 50 million somatic mutations were found in the sequence data.
“We trained the algorithm to try to deduce the type of cancer from these sequence changes. Once the algorithm is given all the mutations of different tumours and their sequences, in the future it will be able to determine the kind of tumour that has been detected. This deduction process is based on the algorithm learning these connections.”
Through deviations in the sequence data in tumours, the algorithm learns to identify when a given tumour corresponds to a particular type of cancer. It can group tumours based on sequence data alone.
“A researcher in my group, Prima Sanjaya, has developed neural network models for analysing sequence data. Every now and then, researchers come across cases in which a cancer has metastasised without being able to tell where it has spread from. Such cases could in the future be dealt with by means of a liquid biopsy – that is, it will hopefully be possible to determine from a blood sample if the patient has cancer, and if so, what kind.”

Liquid biopsies are based on the fact that cells release into the bloodstream and other body fluids a type of DNA called cell-free DNA (cfDNA). Cancer cells also release DNA, which makes it possible to test for cancer mutations in the blood plasma.
“If a liquid biopsy shows traces of cancer, we don’t know exactly what kind of cancer it is, as it could have entered the bloodstream from anywhere in the body. If we have the means to examine these cases more closely, for example with deep learning algorithms, we could obtain valuable information on where in the patient’s body the tests should be focused. The algorithm may indicate that the source of the cancer DNA could be the large intestine, for example. I believe that such algorithms will become extremely important. Liquid biopsy and algorithms can make it possible to diagnose cancers without surgery.”
In addition to hereditary factors, the development of cancer also depends on the person’s lifestyle. Plentiful research has been conducted at the University of Helsinki on various cancers, such as intestinal cancers.
“It is known that eating red meat contributes to the incidence of colorectal cancer. The mechanisms by which the disease is caused require further research, but in recent years a lot of progress has been made in understanding the significance of DNA alkylation reactions, which are caused by red meat, for example.”
Colorectal cancer is one of the most dangerous cancers in Western countries. In countries such as Finland, it leads to death in 30 per cent of cases. About 15 per cent of colorectal cancers belong to the cancer group that exhibits microsatellite instability (MSI). Microsatellites are sequences of DNA that can vary in length from person to person, and thus function as individual identifiers in much the same way as fingerprints. Microsatellite instability occurs when the post-replication repair mechanism of cellular DNA does not function properly. This causes mutations to begin to accumulate, especially in microsatellites.
“In an MSI tumour, microsatellites are easily vulnerable to single-base additions or deletions. For example, out of eight consecutive adenine microsatellites, one adenine may be lost. When it occurs in a gene, such a change causes a complete transformation in the content of the amino acid chain of the protein that is encoded by the gene. If there are enough changes in genes that are important for preventing uncontrolled cell growth, cancer may begin to develop.”
MSI is often associated with other cancers as well as colorectal cancer, such as stomach, uterine, ovarian and brain cancer. MSI analysis can be used in the prognosis of cancer. The treatment choice may be influenced by the analysis.
“An interesting thing is that the deep neural network is also learning to classify different subtypes of cancers. For instance, it identified the MSI subtype of colorectal cancers,” says Pitkänen.
The ELIXIR Node in Finland, hosted by CSC – IT Center for Science, is one of the main partners in the Personalised Medicine in Europe (PerMedCoE) project. For example, the three-year the HPC/Exascale Centre of Excellence for Personalised Medicine in Europe project is aimed at making effective use of cancer-related data in healthcare and speeding up the process of diagnosis
“Individualised treatments of the future, among them cancer treatments, will be based on a precise understanding of the patient and their illness. This will result from gathering a large volume of data of different types, such as tumour-related data and imaging data during cancer treatment. Many data collection methods produce a mass of data, and the new computational methods developed for analysing it require a very large amount of computational resources,” says Pitkänen.
“Developing a new computational method from the idea stage into a functional healthcare technology is a huge challenge in an operating environment like this. With cancer treatments in particular, it is important that information relevant to patient care be made available to the doctors as rapidly as possible. I’m confident that the results of the PerMedCoE project will provide a basis for deriving relevant information from a colossal volume of health data to help doctors in their work, and thus significantly improve treatment outcomes.”
Ari Turunen
16.9.2021
Read article in PDF
Citation
Ari Turunen, Esa Pitkänen, & Tommi Nyrönen. (2023). Teaching an algorithm to identify cancer from sequence data. https://doi.org/10.5281/zenodo.8135303

1.External factors (e.g. UV radiation from sunlight), 2.Internal factors (e.g. a spontaneous deamination reaction, in which the amine group of a base changes, for example from adenine to uracil) 3. DNA copying errors.
A mutation is a change in the nucleotide sequence of DNA or RNA. A nucleotide consists of a base, a sugar molecule and a phosphate group. The sugar in DNA is deoxyribose and the sugar in RNA is ribose. The four nitrogenous bases that DNA contains are guanine (G), adenine (A), cytosine (C) and thymine (T). RNA has three of the same bases as DNA, but instead of thymine its fourth base is uracil (U).
A mutation may be a change of a single nucleotide – that is, a point mutation – or the change may involve multiple nucleotides. In a point mutation, one base is replaced by another in the RNA or DNA strand. Large mutations can involve thousands of nucleotides, and are called structural changes. A structural change can affect multiple genes at the same time. Cancers are usually caused by several somatic mutations. Mutations of this kind are not inherited, and can occur at any time of life from embryonic development onwards. Mutations may bring about a change in the functioning of a normal cell, causing it to begin to divide uncontrollably.
At the middle of the picture are presented different types of mutations, distribution of mutations on chromosomes and epigenetic information. Epigenetic inheritance is influenced by many external factors, such as nutrition. An example is the development of identical twins so as to become distinct from each other in appearance.
Modelling mutations:
Linear models
Deep neural networks
Transformer models. Transformers are a family of deep learning models that work particularly well with certain types of data, such as textual data. This makes them well suited to machine translation, for instance. In cancer research, transformer models can draw attention to mutation types that are important for identifying a particular type of cancer. For example, in skin cancers that contain many sunlight-induced mutations (C> T, CC> TT), the transformer will focus on these particular mutations.
Ari Turunen
For more information:
HPC/Exascale Centre of Excellence in Personalised Medicine (PerMedCoE)
Institute for Molecular Medicine Finland (FIMM)
CSC – IT Center for Science
CSC – The Finnish IT Center For Science is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centralised IT infrastructure.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 European countries and the EMBL European Molecular Biology Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish
centre within this infrastructure.
https://www.elixir-finland.org
http://www.elixir-europe.org

Next-generation analysis methods of genes and RNA molecules enable faster and easier analyses. Data can also be stored well and shared with research teams through the Allas user interface of CSC.
Next-generation sequencing (NGS) methods are used to study variations in the human genome and changes in genetic expression. The analysis of billions of sequence fragments provided by the NGS methods can be performed in a single computer run.
The new methods enable us to study numerous genes and targets from different samples simultaneously. This means that we can quickly analyse individual cells, such as cancer cells. We can also analyse cell-free DNA from blood plasma, indicating quickly and reliably whether the selected treatments have been effective and specifically whether any metastases remain.
Platforms used by the Institute for Molecular Medicine Finland (FIMM) and CSC use a range of algorithms to analyse data produced by sequencing methods (exomes, genomes and transcriptomes). One of the most important ones is Broad Institute’s Genome Analysis Toolkit (GATK). This is used to look for gene variants and identify changes in the DNA or RNA sequence in the cell line. GATK analysis software has become the de facto bioinformatics standard in the scientific community. GATK software can also be run on the superfast Dynamic Read Analysis for GENomics (Dragen) platform. The Finland ELIXIR Node CSC maintains Dragen, in collaboration with FIMM. Dragen perfroms the computing-intensive primary analysis of the sequence data, which is followed by the downstream bioinformatics analysis by the researchers. This make the CSC storage capacity beneficial, because analysed data will not fit into any conventional computer, instead it is shared directly to users through the Allas service. Cooperation between CSC and FIMM is crucial in terms of completing the analyses quickly.
“When we have at our disposal high-capacity sequencing platforms, algorithms and computing power, we get quick results. Today we can analyse one genome in a single day, as opposed to several weeks using older systems,” says Pekka Ellonen.
Mr Ellonen is Head of Laboratory at the Institute for Molecular Medicine Finland (FIMM). The unit uses modern methods to provide the research community genomics (DNA) and transcriptomics (RNA) analyses. The unit receives samples from various research projects.
“We agree with the researchers on the most suitable methods and customise the optimal toolkit to test their hypothesis. Such methods may include exome sequencing, genome sequencing, the sequencing of various RNA molecules (transcriptome), and genetic expression,” says Ellonen.
These methods are able to determine a tissue sample’s genes (genomics) or identify all genes (transcriptomics) and proteins (proteomics) present in the tissue. The sequencing of the exome, that is, the regions that code the proteins can help in the study of hereditary diseases, congenital developmental disorders and cancer. Genetic expression is regulated accurately in cells and any changes may lead to illness. The research can focus on, for example, the differences between cancerous and healthy tissue.

Next-generation sequencing methods enable the study of complex biological systems. According to Ellonen, by far the greatest development in bioinformatics in recent years has been the analysis of single cells. Single cells are analysed in collaboration by the Single-Cell Analytics (SCA) unit of the Institute for Molecular Medicine Finland and the sequencing unit.
Each cell contains the individual’s every gene, but certain genes are only expressed in certain cells and often only under certain conditions. Genetic expression and protein production in cells varies at different stages of development and as a result of illnesses. This causes changes in the cellular and tissue functions. The analytics of a single cell does not actually refer to a single cell.
“Now we are able to study, for example, cancer cells as individual targets. We cannot reach a reliable result merely by determining the base sequence or genetic expression in a single cell; we must study samples of thousands or tens of thousands of cells,” says Ellonen.
Single-cell RNA sequencing (scRNA-seq) can reveal regular inter-gene interaction, cell lineages and differences and the cell’s framework in its environment.
Single-cell sequencing also shows various and even new types of cell and genetic expression data about the functioning. Single-cell DNA sequencing, on the other hand, provides information about mutations taking place in small cell populations among normal cells. Single-cell accuracy provides information on the genetic differences of tumours, which is helpful in their treatment.
“The number of living cells in the sample being studied is verified in the laboratory, after which each cell is separated into its own droplet, enabling single-cell DNA or RNA molecules to be marked with molecule- and cell-specific DNA barcodes. The molecule-specific, cell-specific and eventually the sample-specific DNA barcodes enable both the identification of molecules in each cell and a financially efficient sequencing,” says Pirkko Mattila, head of the Single-Cell Analytics (SCA) unit of the Institute for Molecular Medicine Finland.
“One sequencing run will profile thousands of cells at a time from multiple samples. This results in, from the analysis of thousands or up to hundreds of thousands of cells, a single-cell resolution, enabling us to study the properties of a single cell.”
Liquid biopsy refers to taking a liquid sample, containing cells or parts of cells, from living tissue, such as blood. Liquid biopsy is a promising monitoring tool for cancer treatment without invasive surgical operations.
“We create sequencing libraries from genomic regions interesting from the viewpoint of various cancers,” says Pekka Ellonen.
Liquid biopsy can also be used for identifying cancer in its early stages. A blood sample provides information on tumour blood cells or DNA fragments they have secreted into the bloodstream.
“Tumours are usually in a difficult place, requiring a surgical procedure to remove them or take a sample of them. When tumours grow uncontrollably, there is a higher than normal amount of cell deaths. Dying cancer cells release DNA fragments into the bloodstream. These DNA fragments are collected for sequencing from a blood sample’s cell-free fraction, plasma and serum. Analysis of the sequencing results can show whether the bloodstream contains DNA fragments containing changes typical of cancers,” says Ellonen.

Ellonen says that liquid biopsy is used extensively and it is related to many new research projects. Liquid biopsy can be used not only in basic research but also to make a treatment plan and to monitor treatment effects or cancer recurrence. Being able to take many blood samples at different times will help doctors understand what kind of molecule changes have taken place in the body.
“New genetic markers may be identified and, in the best-case scenario, an accurate treatment method can be selected on the basis of the observed mutations. Alternatively, you may know what you are looking for, that is, you are monitoring for residual signs of the disease in the body, in other words whether the surgical procedure removed the cancer completely.”
Pekka Ellonen is enthusiastic about CSC´s Allas storage service’s user interface, enabling laboratories and research institutions to share pre-processed sequencing results and molecular data with researchers, research teams and consortia. Allas provides 12 petabytes of storage space. The data is securely available through the Web. Data processing can be performed using standard programming interfaces from anywhere.
“Public money produces data, which should be shared in time with the wider scientific community, obviously appropriately pseudonymised. The user interface enables the sharing of large materials, such as the cohort material of useful genomic data.”
Ari Turunen
3.12.2020
Read the article in PDF
Citation
Ari Turunen, Esa Pitkänen, & Tommi Nyrönen. (2020). Efficient processing and sharing of data improving disease diagnosis and treatment. https://doi.org/10.5281/zenodo.8135239
More information:
FIMM
CSC – IT Center for Science
CSC – The Finnish IT Center For Science is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centralised IT infrastructure.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 European countries and the EMBL European Molecular Biology Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish
centre within this infrastructure.
https://www.elixir-finland.org
http://www.elixir-europe.org

Data obtained from human genes and proteins enables quick diagnosis of illnesses and more detailed and personalised patient treatment. Those at risk can be screened better and more effective medication can be chosen once the patient’s genome is known. The challenge lies in how data is processed and where it is stored.
Owing to new data analysis methods and improved computing power, the processing of gene and protein data can be accelerated from several days to less than half an hour. But in order to do this, data must be pre-processed, that is, redundancies removed, and be quickly and securely available.
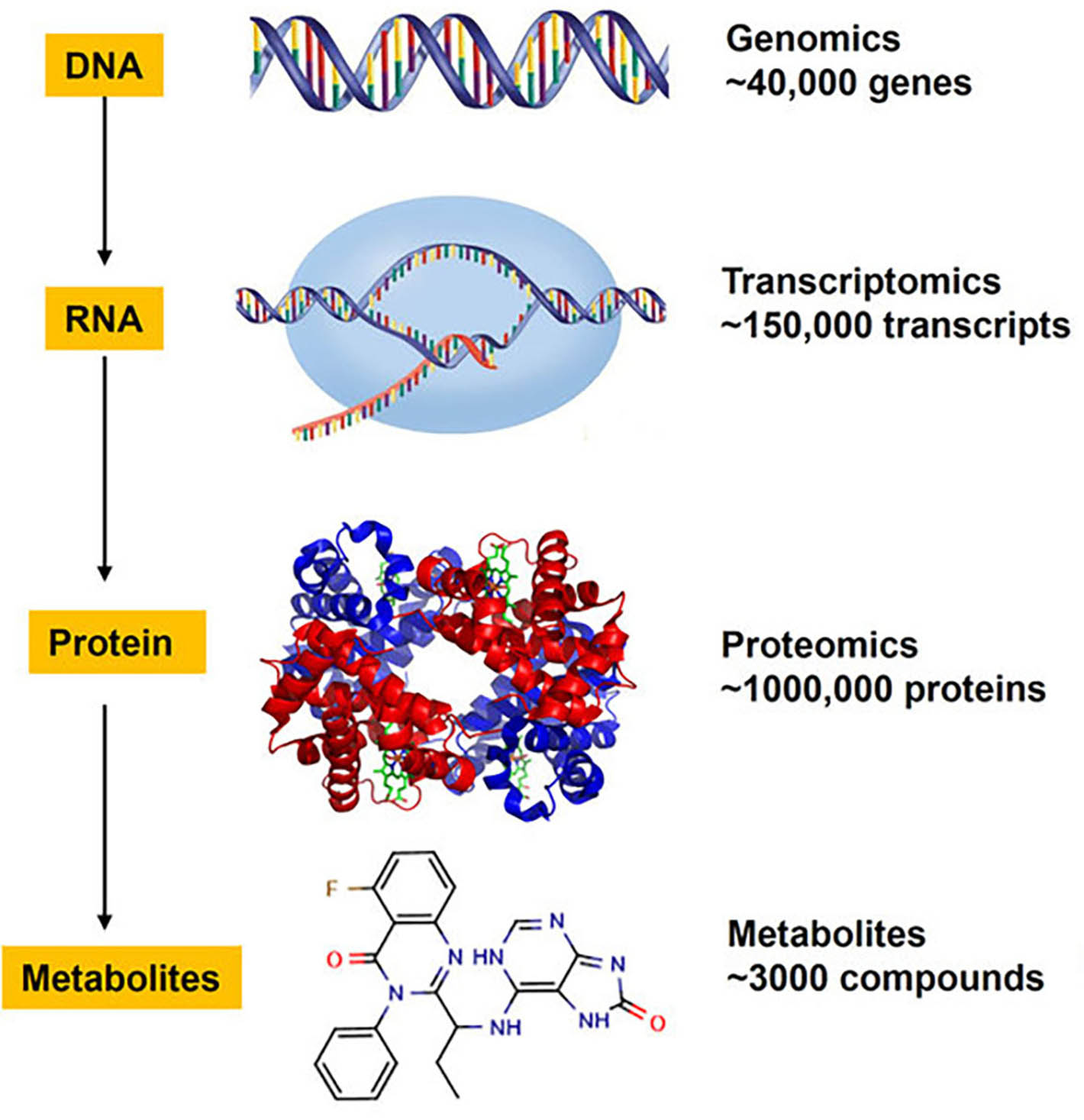
Bioinformatics measurement methods have developed apace, producing huge amounts of data. Now we are in a position to understand the operation of an entire biological system. This means that genes – or the proteins created by them – are studied simultaneously. These ‘omics’, if you like, include determining DNA sequences (genomics), computer modelling of protein structures (proteomics), study of genes in cell tissue (transcriptomics) and metabolic products (metabolomics). Such methods can be used to study molecular interaction and find signs of changes in the human body to identify diseases.
“We can already do a great deal, but combining genetic and clinical data requires a lot more data storage and computing power, and all this in a secure way,” says Katja Kivinen, Head of the FIMM Technology Center from the Institute for Molecular Medicine Finland (FIMM).
The proper pre-processing and modelling of data are requirements for future research, with a view to providing more accurate disease prediction and even personalised ‘silver bullets’ in terms of medication. Kivinen gives two examples: pre-screening of disease risk factors, and drug treatments.
Nature Medicine ran an article in spring 2020 based on data analyses made in the Finngen project. On the basis of genomic data, Professor Samuli Ripatti’s research team at FIMM was able to identify a Finnish population group that had a 60% probability of suffering from cardiovascular diseases or diabetes at some point in their lives. The research material consisted of 135,000 Finnish people providing a blood sample. Data obtained about individual risk factors was combined into a genome-wide risk score.
“Once a person’s genetic background is known, clinicians will be able to offer preventive measures and treatments to improve health as well as save time and money,” says Kivinen.
“In future, population-wide screening can be customised. For example, some women are now screened too early for breast cancer given their small inherited risk, while others are screened far too late. If we use genomic data to take account of inherited risk factors, women could be invited for their first mammography at the optimal time, thereby maximising the chances of discovering cancer at an early stage while minimising unnecessary radiation from repeated screening.”

People react to drugs differently: some do not get the necessary dose, while others suffer from side effects. The reason for varying responses may be our physical characteristics, other medication, or genome. Through the pilot phase of ‘HUS e-care for me’ project, we are optimising treatment for patients with leukaemia and other blood cancers. The project kicked off in summer 2019 and uses artificial intelligence to combine patient-specific biological data produced at FIMM with information about cancer type and status to identify suitable, personalised treatments and stop cancer progression.
“Sometimes a drug may not be effective, or have lost its effect. Cell cultures are made from leukaemia patients’ blood samples, in order to analyse which combination of drugs works best.”
Genome and transcriptome sequencing are performed on the same blood sample. A transcriptome provides information on whether the operation of genes has changed as a result of genetic mutations.
“If a drug no longer has the desired effect, we can find out what kinds of mutations have occurred. Are some genes working, or not, as a result of a mutation? And how do mutations affect metabolic pathways? Now we can see which drug is the best suited for different blood cancer patients directly from blood samples.”
Personalised drug treatments are possible if enough data is available on the patient, and it has been stored and pre-processed correctly. Alongside eleven other academic and commercial players, the Finnish ELIXIR Center CSC and the Barcelona Supercomputing Center (BSC) kicked off the European HPC Center of Excellence for Personalised Medicine (PerMedCoE) project in October 2020. The project is developing algorithms that can significantly reduce the computing time required for analysis. Analysis of genetic and protein data is becoming faster, facilitating and speeding up disease diagnosis and identification of the appropriate treatments. A genome analysis can take weeks or even months. Thanks to super computation and better software, diseases can be diagnosed in future within just hours or days.
Projects like this are important for research teams at FIMM who are routinely working with massive amounts of data.
“The amount of data is increasing at an accelerating pace owing to more powerful equipment and methods,” says Katja Kivinen. “At the moment, we are chronically in short supply of data storage space, and data pre-processing takes too long to enable us to clear up job backlogs and send analysed data to research teams. A secure environment for storing and processing data is vital when dealing with human data. Commercial cloud services offer a secure operating environment, but are too expensive for most researchers. What is more, some data requires a carefully tailored pre-processing and analysis environment and is poorly suited to the options available in cloud services.”
Data processing can be alleviated by dividing work between CSC and FIMM. In the pilot stage, genomic data is transferred from FIMM to CSC on a superfast and secure optic cable. Data pre-processing and quality assurance of analysis are fast, because the data is located at CSC. In future, CSC will distribute data back to research teams on a national basis.
“Previously, it took us 2–3 days per human genome to determine what kinds of changes had taken place. Thanks to this cooperation, the manufacturer of our sequencing equipment has given us access to an optimised computing server that can compress the processing of one genome into 20 minutes. This will help us deal with the backlog of genomic data processing at FIMM and free our bioinformatics specialist to perform other work – such as planning and facilitating various data integration procedures.”
CSC has developed a a new interface to its Allas -service for genomic data from FIMM, to be used by Finnish research teams. The research teams will receive a message once their genomic data is ready, and transfer it to their own project area in CSC’s ePouta environment. Following the pilot stage, the portal’s operating principle will be offered on a larger scale to all research teams in Finnish universities producing ‘omics’ data.
“The interface is vital for us, as data volumes are increasing and data security requirements are becoming tighter, and it is increasingly difficult for us to maintain a data storage and processing environment at FIMM. We must start moving more and more raw data and process data to CSC and make it accessible for research teams.”
Another important area of development, according to Kivinen, relates to data storage and related imaging services.
“Image processing is usually done on the server connected to the actual instrument, which contains the necessary processing software. Owing to slower transfer speeds, moving processing to a cloud service is not always a viable alternative, at least not in all parts of the country. So image processing may also occur on location in the future but, like genomic data, processed data should be shared through CSC .”
Ari Turunen
10.11.2020
Read article in PDF
Citation
Ari Turunen, Katja Kivinen, & Tommi Nyrönen. (2020). Bioinformatics to revolutionise healthcare: Efficient data processing speeds up diagnoses and enables personalised drug treatments. https://doi.org/10.5281/zenodo.8135131
More information:
FIMM
Cleaverhealth
https://www.cleverhealth.fi/fi/ecare-for-me
+1 million genomes’
https://ec.europa.eu/digital-single-market/en/european-1-million-genomes-initiative
CSC – IT Center for Science
CSC – The Finnish IT Center For Science is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centralised IT infrastructure.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 European countries and the EMBL European Molecular Biology Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish
centre within this infrastructure.
https://www.elixir-finland.org
http://www.elixir-europe.org

Cardiovascular diseases are the most common cause of death in the world. More than a third of deaths in Finland are caused by cardiovascular diseases. The current objective is to create an assessment, based on health data, of each person’s risk of illness before they consult a doctor.
Andrea Ganna, Group Leader from Institute for Molecular Medicine Finland FIMM at the University of Helsinki and instructor from Harvard Medical School, wants to establish a nationwide, personalised risk assessment as foundation for planning public health interventions. The assessment is based on the health, demographic and genetic information of the citizens. The assessment, which uses artificial intelligence, improves the allocation of preventive treatments with a lower cost than today.
”Nordic countries and specifically Finland have a unique opportunity and setting, since they have been collecting health and demographic data for years. But the way they have used this data in the past is somewhat outdated. Only very specific correlations and associations in the data have been looked at. However, new methods, such as AI, are emerging, which now allow us to push for a much bigger and ambitious vision.”
Andrea Ganna and his group is developing artificial intelligence (AI) approaches to model health trajectories.
”You have a certain health trajectory and have taken certain medication. We ask if there are other people who have followed a similar path. There may be thousands out there. We leverage those people and ask: What happened to those? Let’s take that experience and bring it back to you to help you to reduce your disease risk. We can use all this data in a more comprehensive way to help public health and give more information to patients and doctors for decision-making.”
Andrea Ganna is interested in epidemiology, genetics and statistics. He has been focusing on leveraging large-scale epidemiological data sets to identify socio-demographic, metabolic and genetic markers of common, complex diseases. In Boston he worked with large-scale exome and genome sequencing data.
According to Ganna, cardiovascular diseases are ideally suited for analysis by artificial intelligence, since their treatment is preventive.
”Accurate identification of individuals at high risk is one of the cornerstones of primary prevention of cardiometabolic diseases,” he says. ”However, at the moment, risk factor assessment for cardiometabolic diseases requires patients to go to the doctor for lipid measurement. ”
Lipid is the umbrella term used for all fatty acids or their derivatives that circulate in the blood. The body stores fats from food for later use. A diet rich in fats will cause them to attach to the walls of the arteries, leading to cardiovascular and arterial diseases. Lipid measurement is effective, but some members of the population are unaware that they belong to a risk group.
Ganna wants to revolutionize primary prevention by providing risk assessment before an individual even steps into the doctor’s office.
”Some simply don’t go to the doctor’s and so lots of people are missed. However, since all the data on medication and diagnoses has already collected, we can identify high-risk patients without them going to doctor. We can make a risk map of cardiovascular diseases of the whole country by including every individual.”
Calculating the risk is done by modelling longitudinal histories of diseases and medications with the gene data, family and demographic data.
”We are trying to understand how genetics interact with data regarding medications, diagnoses, demographics, and familial risk. This can provide an unprecedented holistic view of an individual’s health status.”
Ganna gives an example.
”When you break your leg, you go to the doctor. However, today the doctor is just looking at the leg, although during the same visit other information could also be obtained. We can inform the doctor about other risks the patient has based on the collected data. We can precompute the other risks of the patient, for example if this patient has also high risk for cardiovascular diseases. Thus, during the visit, the doctor can also give advice or refer the patient to a specialist.”

Ganna chose to come to Finland because of the large genetic project, FinnGen. The FinnGen project will record the genomes of half a million Finns. The project, launched in August 2017, utilises samples collected by all Finnish biobanks. The data from genomes is combined with the information in national health care registers. FinnGen is one of the very first personalised medicine projects of this scale and the public-private collaborative nature of the project is exceptional.
“Finland also has a favourable legislation, giving access to nationwide population data. For me, this is a unique setting,” says Ganna.
Ganna and his research group integrate registry-based information with genetic information from large biobank-based studies (e.g. FinnGen) to help identify groups of individuals that can most benefit from existing pharmacological interventions.
”Probably the most important population is younger individuals who do not see a doctor very often. Current risk factors do not work well in this group. Genetics is particularly valuable because it can capture disease risk at an earlier age than other risk factors,” says Ganna.
”The first step is to understand how people perceive this information. We have to ensure that doctors use the data in a right way and what can be done with it.”

Ganna aims to integrate national and regional registries with deep and machine learning.
”Traditional methods have an advantage since they are relative simple and easy to interpret, but they simple do not scale. In the past 20 years, more than 500 million medical diagnoses have been made of Finns. We are talking about huge data sets. Every year there are millions and millions of new medication purchases and diagnoses. To scale and to leverage this massive data, deep learning methods are needed.”
Artificial neural networks are efficient machine learning algorithms, which can be used in pattern recognition. Recurrent neural networks can use their internal memory to process sequences of inputs. This makes them applicable to tasks such as unsegmented recognition. Ganna wants to expand long short-term memory recurrent neural networks to data.
”You can imagine the sequence of health events that we are trying to model as “text” in which each word is a different disease, medication, sociodemographic event etc. across the lifetime. These are naturally suited to model the sequential happening of events, for example they are used to predict the next most likely word in a text message.”
Deep learning methods need large supercomputing infrastructure.
“CSC has created a secure environment for this computation. Without a secure supercomputing environment, we could not carry out this project. To be successful, we need, on the one hand, research and development, and, on the other hand, a powerful computing environment.”
Patient data is important for research, but personal data is also protected. For example, VEIL.AI application created by FIMM anonymises patient data better and faster than traditional methods, and retains information more effectively. If necessary, the application can also produce synthetic, fully anonymous statistical data, which cannot be traced back to any individual.
“We need to guarantee individuals’ privacy but, at the same time, we need to integrate a lot of personal data to really leverage the power of artificial intelligence/deep learning approaches to better target public health interventions. Generating synthetic health trajectories will help to respect privacy and, at the same time, to combine a lot of personal information within Finland, but also across Nordic countries.”
”My hope is that personal data that is routinely collected in healthcare can help and benefit everyone. My hope is that that this information can help doctors to make better decisions, but also help patients in motivating life style changes. Thus everyone is helping everyone.”
Ari Turunen
30.9.2019
Read article in PDF
Citation
Ari Turunen, Andrea Ganna, & Tommi Nyrönen. (2019). Risk assessment of cardiovascular diseases for all citizens. https://doi.org/10.5281/zenodo.8131074
More information:
Institute for Molecular Medicine Finland (FIMM)
The mission of the Institute is to advance new fundamental understanding of the molecular, cellular and etiological basis of human diseases. This understanding will lead to improved means of diagnostics and the treatment and prevention of common health problems. Finnish clinical and epidemiological study materials will be used in the research.
CSC – IT Center for Science
CSC – The Finnish IT Center For Science is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centralised IT infrastructure.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 European countries and the EMBL European Molecular Biology Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish
centre within this infrastructure.
https://www.elixir-finland.org
http://www.elixir-europe.org

Patient data is important for research. Personal data is protected by hiding or modifying identity attributes, while maintaining the level of statistical data significant for research purposes. This is enabled by a new, AI-based service.
VEIL.AI anonymises patient data better and faster than traditional methods, and retains information more effectively. If necessary, the application can also produce synthetic, fully anonymous statistical data, which cannot be traced back to any individual.
Developed by the Institute for Molecular Medicine Finland (FIMM), the application is now available for the ELIXIR infrastructure, alongside which a joint service is now being developed. An organisation managing data can protect it by entering the related metadata into a scalable cloud service. The service disguises any identity attributes, providing researchers with anonymised and, if necessary, synthetic data.

The VEIL.AI application employs a model based on artificial intelligence. The application creates a veil that protects the patient’s identity attributes, but can identify relevant data, which it keeps.
“Occasionally, for example when creating machine-learning models, more data is required–and more quickly–than research ethics committees tend to allow. They require justification for each variable, which is against the essence of machine-learning where maximum amount of variables is wanted without, a priori, assuming too much of their impact as far as the best mode is still being sought,” says commercialisation expert Tuomo Pentikäinen.
This is why, according to Pentikäinen, it makes sense to use synthetic data in the early stages of modelling, as this is what the VEIL.AI method can produce.
“This means data which is totally detached from the people it was derived from, but which, in terms of the desired variables, behaves like the original data. However, synthetic data is only one type of data we provide. Usually customers want anonymised data.”
VEIL.AI can find variables regarded as sensitive in terms of revealing a person’s identity, and anonymise them automatically.
“In a better and more organised way, the application can perform heavy calculations and operations concerning the calculation of data partitioning and anonymisation metrics.”
It must be possible to protect sensitive patient data, but many traditional anonymisation models also lose important data in the process. Traditionally patient data has been protected by partitioning and generalising identity attributes within the data. Anonymisation studies how variables divide/partition data into different groups. Then each group is examined separately, and if some variables are too easy to identify, they are coarsened. Generalisation means that a person’s age can be rounded off by a few years and a professional title can be changed from, say ‘nurse’ to ‘health care professional’.
“So any variables that are too easy to identify are generalised to a sufficiently general level, or perhaps even removed completely. When processing health data, deletion may have to be used quite often if a variable is unique or too easily identifiable,” says Pentikäinen.
This means that generalisation can result in the loss of important patient data.

“This tends to happen when an interesting phenomenon (such as an illness) is relatively rare and fairly evenly distributed across the data set. When such data is divided into partitions for anonymisation, it is common for the phenomenon of interest to be even rarer in each partition. In cases like this, traditional methods commonly interpret the interesting data as “outliers” in each partition, and therefore remove it. This is stupid, because with a better chosen strategy, the phenomenon of interest could have been included in the partitions, while retaining important information more effectively.”
Timo Miettinen, Information Systems Manager at the Institute for Molecular Medicine Finland, has an example: a patient with a rare type of breast cancer. Creating data that is too coarse can lead to the disappearance of data on the rare type of disease, because there are so few such patients in the data set.
“A breast cancer patient has one diagnosis, but her genetic profile indicates that she has a rare type of breast cancer. There may be a few cases like this per hospital, meaning that they may be classified as outliers and deleted. But this does not apply to the entire population. If a better view could have been gained of the big picture, this outlier would not have been deleted.”
Timo Miettinen has been involved for a long time in designing information systems that make use of and protect clinical data. Miettinen and his team have developed the VEIL.AI application, which is about to become commercially available. This micro service was created due to GDPR.
Each biobank in Finland has its own code register. The code register consists of personal identity codes and a synonym table, used to create an identifier–that is, a pseudonym–for each person.
“Certain things are difficult to change, such as height, eye colour and place of birth. They are identifiable through statistical methods. The same applies to a person’s medical history,” says Miettinen.
“We make two promises. First, we promise scalability and better performance. We are able to make use of continuously updated data from a number of sources. We can anonymise this effectively and securely. Our second promise is to try to minimise data loss. The application takes account of the data content, while fulfilling the anonymisation criteria,” says Miettinen.

The VEIL.AI application uses a neural network that can be thousands of times faster than conventional methods.
“Our system enables safer data distribution, because once the neural network has been taught what to do, each owner of confidential data can anonymise data before passing it onto its partners. Our method also produces better data, because we can test a huge number of different data partitioning strategies and pick the one that results in the smallest loss of information, while nevertheless achieving the desired level of anonymity,” says Pentikäinen.
And crucially, in terms of data security, the VEIL.AI application does not store patient data in a new location.
“We do not want to manage data. Instead, data is streamed through our service, during which we anonymise it and return it immediately to the customer,” says Tuomo Pentikäinen.
“We offer a scalable cloud service. Through the user interface, we can enter the necessary data dictionary and teach the algorithm to create the data anonymisation model using example material. The algorithm will learn to process the data, and if more data is added, it is streamed through the cloud service and anonymised,” says Timo Miettinen.
This means that organisations no longer have to share any of their sensitive data with anyone. Data arrives anonymised from the cloud service for research purposes.
The analysis of various pseudo identifiers requires plenty of processing power, which has been obtained from the ELIXIR infrastructure.
Ari Turunen
3.6.2019
Read article in PDF
Citation
Ari Turunen, Tuomo Pentikäinen, Timo Miettinen, & Tommi Nyrönen. (2019). VEIL.AI: patient data in a veil. https://doi.org/10.5281/zenodo.8119016
VEIL.AI
Institute for Molecular Medicine Finland (FIMM)
The mission of the Institute is to advance new fundamental understanding of the molecular, cellular and etiological basis of human diseases. This understanding will lead to improved means of diagnostics and the treatment and prevention of common health problems. Finnish clinical and epidemiological study materials will be used in the research.
CSC – IT Center for Science
CSC – The Finnish IT Center For Science is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centralised IT infrastructure.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 European countries and the EMBL European Molecular Biology Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish
centre within this infrastructure.
https://www.elixir-finland.org
http://www.elixir-europe.org

Professor Samuli Ripatti’s group at the Institute for Molecular Medicine Finland and the Faculty of Medicine of the University of Helsinki studies the underlying mechanisms of cardiovascular diseases through genetic variation. The genetic heritage of the Finnish population provides a good opportunity for this.
In Finland, there are about 40 hereditary diseases that are characteristic of the Finnish population. The illnesses included in the disease heritage are caused by certain mutations that are more common in Finland than elsewhere in the world due to the so-called bottleneck effect. In the last 10,000 years, a relatively small number of settlers have moved to the Finnish territory. The individuals of this new population represented small and narrow genetic material, resulting in the regional enrichment of certain disease gene variants.
The bottleneck effect is beneficial today for determining the genetic heritage of diseases.
“Finland is the largest bottleneck population on the European scale. Few people have moved here over millennia. The genetic variants that have come to Finland with these immigrants can be a hundred times more common in Finland than elsewhere. This is not often the case in more admixed populations. In Finland, permanent settlements were first established in closer to the coastal areas and only much later in the east and in the north”, says Samuli Ripatti.
According to Ripatti, the internal migration that took place in the 16th century was a second bottleneck thanks to which large differences are discernible in the Finnish population between the east and the west. Although population isolates also exist elsewhere, defining the genetic background of the Finnish disease heritage has also inspired investigations of other diseases.
“We are now able to understand the onset principles of many genetically inherited diseases, allowing the research data to be applied elsewhere. Although the diseases are different, they have genetic mechanisms that operate in the same way. Understanding this dynamic is a big thing and may provide new opportunities for developing new treatments.”
For example, when studying Parkinson’s disease, it is possible to determine whether the disease is more common in some parts of Finland. If this is the case, research into these parts of the country may produce new genetic information.
Ripatti is interested in population genetics and genetic variation in Finns. He has been a Professor of Biometry at the Faculty of Medicine of the University of Helsinki since 2013. Biometry is a field of statistics that focuses on the analysis of biological data. Ripatti’s research group combines statistical methods with sequence-level measurements of the human genome.
“Sequencing provides information on genetic variation, which may be rare in a population. Based on variation, it is possible to see the prevalence of certain genetic changes that modify disease risk in some areas of Finland or demonstrate predisposition for a certain illness.”
This allows the screening of valuable information about the health effects from the population’s genetic data. People at a high risk of getting sick can be found while also looking for ways to prevent diseases.
“We look at this from the point of view of diseases which touch many individuals. We study illnesses that are common in Finland, such as cardiovascular diseases and diabetes.”
Even though these diseases are affected by, for example, diet and other lifestyle choices, hereditary factors are also significant. That is why these conditions are referred to as common complex diseases. Thanks to the Finnish bottleneck effect, Ripatti’s group has identified genetic variants, genes that predispose you to cardiovascular diseases, in particular, and predictive and marker-controlling genes measured in blood. Ripatti uses high cholesterol levels as an example.
“Those with high cholesterol levels can be examined and their genomes sequenced in an efficient and easy manner.”
Cardiovascular diseases are the cause of one in three deaths in the world. The most affected areas are Central Asia and Eastern Europe. In the 1960s, Finland was the world leader in coronary artery disease mortality of middle-aged men. Upon entering the 2000s, men’s mortality had fallen to about one fifth of the highest level.
However, regional disparities in cardiovascular disease morbidity and mortality are high in Finland. The incidence of the diseases is much lower in Western and Southern Finland than elsewhere in the country. This large regional difference is of interest to researchers. So-called silenced genes that protect against diabetes and cardiovascular diseases have been found in the population of Western Finland.
One interesting area of study is a gene being turned or becoming inoperative. Such genes are referred to as silenced genes. A study led by Professor Aarno Palotie analysed over 80 mutations silencing an entire gene that are rare but more common in Finland than elsewhere in the world. The material was obtained from the genomes of more than 30,000 Finns.
In fact, Finns have more genes that silence the function of an individual gene than other populations.
“Gene variants that disrupt protein production are generally quite rare in human populations. However, the gene variants that disrupt protein production brought to Finland with settlers are more common here than in the rest of Europe and that is why studying the health effects of those variants that arrived here at that time is much easier in Finland than elsewhere.”
Gene knockouts whose inoperability does not cause health problems have been found in the population of Western Finland. On the contrary, they protect their carrier against diabetes or cardiovascular diseases.
“A gene variant that protects against diabetes has been found in Finland. Carriers of the variant have less incidence of diabetes compared to others. There are more carriers of the gene variant in Ostrobothnia than elsewhere in the world. This may benefit the pharmaceutical industry if it is possible to mimic the function of such a gene through molecular preparations.”
Another example is a gene that prevents the function of lipoprotein(a). Heart disease risk can be assessed by measuring lipoprotein(a) in the blood. Lipoprotein(a) or LPA is a member of the lipoprotein family that carries LDL cholesterol. The data contained, for example, genetic variants whose carriers lacked lipoprotein(a) produced by the LPA gene almost completely. People lacking lipoprotein(a) develop cardiovascular diseases less frequently than others.
“There are a few variants of the LPA gene that shut off its function. In such cases, there is less lipoprotein(a) in the blood. This results in less vascular disease. Lowering the protein level by pharmacological means would be possible and this could be beneficial in preventing coronary artery disease.”
The function of the USF-1 gene has also been studied in Finland. In humans, the gene affects blood fat levels and cholesterol. When the function of the gene was knocked out in mice, the level of the good HDL cholesterol in the blood increased.

Thanks to the SISu (Sequencing Initiative Suomi) project, the data on genetic variation in Finns has been compiled into one database.
“The sequenced sample material has been collected from Finnish patients and volunteers. The material has been used to calculate statistics on how prevalent each genetic variant is in Finland. Once a large enough database has been compiled, it is possible to determine what Finnish genomic variation is like in general.”
The SISu database currently has the protein-encoding variants of the genomes of some 10,000 Finns, and even the full genome of several thousand Finns has already been sequenced.
“The sequence data of the SISu database gives us the opportunity to supplement our material measured with more favourable genome microarrays than others with statistical imputation algorithms. We can now tell quite accurately what kinds of gene variants Finns have. For example, if one in a thousand carries a specific gene variant in Finland, it means that at least 20 people on average should have the variant in the current database.”
The database is already helping patient diagnostics.
“The variation data is in the database and the data is utilised all the time, especially in clinical genetics. The starting point is that the database provides further clarification for the treatment of a hospital patient. Therefore, if it is suspected that a variant in a gene may be the cause of a disease, the doctor will check the database to see how often this variant occurs in Finns. If it is common, it is unlikely that it would be the cause of a rare disease. If it is rare and its effect on gene function is significant, then the likelihood of the variant’s significance in the onset of a disease is also increased. This is a very concrete clinical application of the database.”

The SISu project data has been collected from research projects and patients. However, the project has focused solely on genomic data, meaning that the potential for utilising the data in health research is limited.
“A biobank sample should be collected from all of us”, says Ripatti. “Those with a predisposition for illness should be screened more closely.”
In Samuli Ripatti’s view, it is a great shortcoming that genomic data is not yet available in connection with medical examinations. It should be part of everyone’s routine check-up to allow concrete decisions for treatment.
“Finland would have excellent setting for this. We have well-functioning occupational and basic health care as well as good expertise in genetic research.”
As a continuation of SISu, the FinnGen project that will record the genomes of half a million Finns launched in August 2017. The project utilises samples collected by all Finnish biobanks. The data from genomes is combined with the information in national health care registers.
“Tools for risk assessments exist and statistical models have been developed for several diseases. Interpreting the data obtained from the genome as part of routine health care is the goal of the next few years. FinnGen contributes to this.”
Ripatti and his team participate in the development, implementation and testing of statistical algorithms.
“We develop prediction algorithms that evaluate, for example, the risk of cardiovascular diseases in a patient. We combine genomic data and lifestyle factors, based on which a prediction is made. Therefore, we are looking for ways to motivate the patients to change their lifestyles.”
Ripatti’s group also supplements genomic data with statistical algorithms. Due to Finland’s population history, it is possible to predict the missing genotypes in microarray data better and more precisely here than almost anywhere else in the world. The algorithm works well in Finnish data because Finnish genomes are on average more alike than elsewhere. Sequence data is used to computationally supplement data collected using gene microarrays.
“If a gene microarray scanning the essential variation points has 500,000 genetic markers and we know 30 million genome variants of gene sequences in addition to these measurements, we can supplement the measurement done using the gene microarray into a full genome sequence with good statistical quality indicators. This allows the creation of more sufficiently reliable full genomes at a lower cost. For the time being, sequencing the entire genome is considerably more expensive.”
Preserving genomic data in the future and designing its analysis environment are big issues in which the ELIXIR infrastructure plays a key role.
“We have an existing pool of data that can be used by authorised researchers. With large databases, it is necessary to provide researchers with a secure and efficient data analysis environment where the data can be analysed.”
Due to data protection, the best solution would be, for example, a remote desktop. At present, there are hundreds of copies of the population data of different countries on the disk servers of various research groups around the world. It is an enormous amount of data.
“On the other hand, in the future, we must have solutions suitable for analysing genomic data that enable the efficient and decentralised storage and analysis of enormous data sets. This challenge will not be resolved by the closed remote desktop solutions developed previously for much more modest data volumes. Instead, what is required are open computing environments that efficiently utilise cloud services and international cooperation. Considering this is quite essential.”
Ari Turunen
5.11.2018
Read the article in PDF
Citation
Ari Turunen, Samuli Ripatti, & Tommi Nyrönen. (2018). Help from the Finnish genome for the prevention of cardiovascular diseases. https://doi.org/10.5281/zenodo.8118771
Read also:
Massive data management project: Finns’ heredity is collected and safeguarded
More information:
Institute for Molecular Medicine Finland (FIMM)
The mission of the Institute is to advance new fundamental understanding of the molecular, cellular and etiological basis of human diseases. This understanding will lead to improved means of diagnostics and the treatment and prevention of common health problems. Finnish clinical and epidemiological study materials will be used in the research.
CSC – IT Center for Science
CSC – The Finnish IT Center For Science is a non-profit, state-owned company administered by the Ministry of Education and Culture. CSC maintains and develops the state-owned, centralised IT infrastructure.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR builds infrastructure in support of the biological sector. It brings together the leading organisations of 21 European countries and the EMBL European Molecular Biology Laboratory to form a common infrastructure for biological information. CSC – IT Center for Science is the Finnish
centre within this infrastructure.
https://www.elixir-finland.org
http://www.elixir-europe.org


 ELIXIR is partly funded by the European Commission
ELIXIR is partly funded by the European Commission