ELIXIR, eurooppalainen biotieiden infrastruktuuri, on sitoutunut järjestämään ja ylläpitämään biotieteistä tuotettua dataa mahdollistaakseen sen tulkinnan. ELIXIR mahdollistaa esimerkiksi ihmisdatan tietoturvallisen käsittelyn uusimpien IT-alan innovaatioiden avulla estääkseen datan laittoman käytön. ELIXIR-infrastruktuurissa on 22 jäsentä, 21 jäsenmaata sekä EMBL – Euroopan molekyylibiologian laboratorio. ELIXIR kattaa lähes 200 organisaatiota, jotka muodostavat uskottujen osapuolten federaation. Vuoden 2017 alussa, ELIXIR-infrastruktuurin avulla, 21 000 tieteellistä artikkelia oli julkiastu ja 8 500 patenttia myönnetty. Patentteja myönnettiin rokotteisiin, biomarkkereihin, entsyymeihn ja Ebola-viruksen ehkäisemiseen.
Lataa kirja, joka esittelee suomalaisia ELIXIR-infrastuktuuriin liittyviä tutkimushankkeita vuosilta 2014-2018. ELIXIR-infrastuktuurin Suomen solmupisteestä vastaa CSC – Tieteen tietotekniikan keskus. Vuonna 2018, ELIXIR Suomi tuki yli 300 bioalan tieteellistä projektia, monet niistä julkisrahoitteisia.


Resource Entitlement Management System (REMS) on CSC:n kehittämä työkalu, jolla hallinnoidaan pääsyoikeuksia erilaisiin resursseihin, kuten tutkimusaineistoihin. REMSin avulla rekisterinpitäjät voivat hallita aineistojen uudelleenkäyttöä ja siihen liittyviä lupaprosesseja keskitetysti.
Tutkijat voivat kirjautua REMSiin federoidulla käyttäjätunnuksellaan (kuten HAKA), täyttää aineiston käyttölupahakemuksen ja hyväksyä aineiston käyttöön liittyvät käyttöehdot. REMS välittää hakemuksen rekisterinpitäjän määrittämälle Data Access Committeelle (DAC), joka tarkastaa hakemuksen ja päättää luvan myöntämisestä. Järjestelmä tuottaa myös tarvittavat raportit hakemuksista ja myönnetyistä käyttöluvista.
REMS noudattaa GA4GH Passport -standardia. GA4GH-viisumi on koneluettava tutkijan digitaaliseen identiteettiin liitetty datankäyttöoikeus, joka mahdollistaa sujuvan ja turvallisen pääsyn käyttöoikeusrajoitettuun dataan yhteensopivissa tietoturvallisissa käsittely-ympäristöissä (SPE).
REMSiin kirjautumisessa voidaan hyödyntää HAKA-tunnistusjärjestelmää, joka on Suomen korkeakoulujen ja CSC:n kehittämä. Vaikka palvelu sijaitsisi toisen organisaation palvelimella, kirjautuminen onnistuu oman kotikorkeakoulun käyttäjätunnuksella ja salasanalla. Euroopan tasolla käytössä on eduGAIN-järjestelmä.
https://github.com/CSCfi/rems/
https://www.elixir-europe.org/services/aai

CSC:n kehittämä Chipster-ohjelmisto tarjoaa satoja geenidatan analyysityökaluja helppokäyttöisessä muodossa. Se sisältää merkittävän kokoelman analysointityökaluja sekvenssi- ja proteomiikkadatalle sekä mikrosirujen tuottamalle datalle.
CSC tarjoaa suomalaisille tutkijoille Chipster-palvelun, jossa analyysityöt ajetaan cPouta pilvipalvelussa. Chipsterin lähdekoodi ja asennuspaketti on myös vapaasti saatavilla, ja Chipster onkin käytössä monissa instituuteissa ympäri maailmaa.
Kaikki ELIXIR Euroopan tarjoamat työkalut:
https://www.elixir-europe.org/services/tools

Eurooppalaiset dataresurssit ovat olennaisen tärkeitä biotieteiden yhteisölle ja biologisen datan pitkäaikaiselle säilyttämiselle. ELIXIR pyrkii varmistamaan, että nämä resurssit ovat saatavilla pitkällä aikavälillä ja että niiden elinkaari hallitaan siten, että ne tukevat biotieteiden tutkimuksen tarpeita. Alla listaus ELIXIR sivuilta:
Kuvaus ELIXIR Europen sivuilta, mistä ELIXIR Core Data Resources -koostuu.
ELIXIR on koonnut luettelon resursseista, joita se suosittelee datojen tallentamiseen. Tiedeyhteisöllä on yhteinen vastuu datan pitkäaikaisen säilymisen ja saatavuuden varmistamisesta. Tämän luettelon tarkoituksena on opastaa linjauksia ja työskentelysuosituksia laativille sopivia tietovarastoja biotieteiden avoimen datan julkaisemiseen.
ELIXIR Deposition Database määritellään osaksi ELIXIR-keskusten palveluportfoliota.
Suomella on pitkät perinteet biopankkinäytteiden ja niihin liittyvän kliinisen tiedon keräämisessä ja analysoinnissa. Terveyden ja hyvinvoinnin laitos (THL), Suomen molekyylilääketieteen laitos (FIMM) ja CSC – Tieteen tietotekniikan keskus tekevät yhteistyötä kolmen biolääketieteen infrastruktuurihankkeen puitteissa Euroopassa: Biopankki- ja Biomolekyyliresurssien tutkimusinfrastruktuuri (BBMRI), European Advanced Translational Research Infrastructure in Medicine (EATRIS) ja European Life Science Infrastructure for Biological Information (ELIXIR).
BBMRI vastaa biopankeista, joita hyödynnetään sekä kliinisissä tutkimuksissa että elintapojen ja ympäristön terveysvaikutusten tutkimuksessa. EATRIS puolestaan soveltaa perustutkimuksen tuloksia lääketieteeseen.
Biopankkien Osuuskunta Suomi – FINBB perustettiin vuonna 2017 osana Suomen terveysalan kasvustrategian toteuttamista kehittämään Suomeen kansainvälisesti merkittävää biopankkien yhteistyöverkostoa. FINBB tehtävä on kehittää Suomen terveys- ja biolääketieteellisen tutkimuksen kilpailukykyä tuomalla Suomen biopankkien ja niiden taustaorganisaatioiden tietovarannot keskitetysti tutkijoiden saataville. FINBB on ollut virallinen FinnGen-projektin kumppani elokuusta 2020 lähtien.
Jäsenbiopankkeja on tällä hetkellä kahdeksan:
Biopankkiverkoston toiminnassa ovat mukana lisäksi Veripalvelun Biopankki ja Hematologinen Biopankki. Suomen Terveystalon Biopankki tekee verkoston kanssa yhteistyötä.
Muita kansallisia dataresursseja
| Data resurssi | Instituutti | Kuvaus |
|---|---|---|
| SISu | FIMM | Sequencing Initiative Suomi (SISu) -hakukone tarjoaa tavan etsiä dataa suomalaisten sekvenssivarianteista. |
| FinHealth Study | THL | FinTerveys-tutkimuksen tavoitteena on tuottaa ajankohtaista tietoa Suomessa asuvien aikuisten terveydestä ja hyvinvoinnista sekä niihin vaikuttavista tekijöistä. |
| Findata | Sosiaali- ja terveysalan tietolupaviranomainen | Findata myöntää lupia tietojen toissijaiseen käyttöön, yhdistää aineistot tietoturvallisesti ja edistää kansalaisten tietosuojaa. |
| Koirien geenitutkimus | Helsingin yliopisto ja Folkhälsanin tutkimuskeskus | Koirien geenitutkimuksen tavoitteena on tunnistaa geenivirheitä koirien erilaisiin perinnöllisiin sairauksiin ja ominaisuuksiin, kehittää geenitestejä jalostuksen apuvälineeksi ja soveltaa saatua tietoa ihmissairauksien selvittämiseen. |
| Kissojen geenitutkimus | Helsingin yliopisto ja Folkhälsanin tutkimuskeskus | Kissojen DNA-pankki hyödyttää perinnöllisten sairauksien ja ominaisuuksien tutkimusta. Laaja näytemäärä päivitetyin terveystiedoin yhdistettynä tietoihin muista kissan ominaisuuksista (esim. käyttäytyminen) mahdollistaa lukemattomat erilaiset geenitutkimukset. |
Mikäli sinulla on tarjottavana dataresursseja, älä epäröi ottaa yhteyttä servicedesk@csc.fi Aihe ”ELIXIR”

Kuvasarja esittää vasemmalta oikealle, kuinka vaihtomutaatio muuttaa SynGAP1-proteiinin rakennetta.
Pekka Postilan johtamassa tutkimusprojektissa mallinnetaan vaihtomutaatioiden vaikutuksia SynGAP1-proteiinin rakenteeseen ja toimintaan. Tämän proteiinin toimintahäiriöt aiheuttavat muun muassa vakavaa älyllistä kehitysvammaisuutta, epilepsiaa ja autismia. Tutkimus vaatii tekijöiltään pikkutarkkaa otetta, paljon kärsivällisyyttä ja valtavasti laskentatehoa.
Joskus vain yhden ainoan nukleotidin muutos perimässä voi johtaa merkittäviin terveysongelmiin ja taudin puhkeamiseen. Kun tällainen muutos vaihtaa tärkeän geenin koodaamassa proteiinissa yhden aminohapon toiseksi, puhutaan vaihtomutaatiosta. Tällainen muutos voi näyttää mitättömän pieneltä, mutta vaikutukset voivat olla hyvin suuria.
Yksi erityisen herkkä geeni tällaisille muutoksille on SYNGAP1, jonka tuottamaa SynGAP1-proteiinia on runsaasti etuaivojen hermosoluissa. SynGAP1-proteiini osallistuu solunsisäisen kasvun säätelyyn ja estää näin esimerkiksi kasvainten leviämistä. Kyseessä on iso, yli 1300 aminohaposta koostuva proteiini, joten tämä ei kuitenkaan ole sen ainoa tai välttämättä edes tärkein tehtävä ihmiskehon toiminnassa.
”Viime vuosina SynGAP1:n monimutkainen biologia on alkanut lopultakin selvitä”, kertoo erikoistutkija ja dosentti Pekka Postila MedChem.fi-laboratoriosta Biolääketieteen laitokselta Turun yliopistolta.
SynGAP1 toimii ikään kuin synapsin portinvartijana. Kun opimme jotain uutta, SynGAP saa kemiallisen merkin ja siirtyy hetkeksi syrjään. Silloin kyseiset reseptorit pääsevät paikalle, ja hermosolujen välinen viestinvälitys vahvistuu.

SynGAP1-mutaatioiden aiheuttamat hermosto-oireet ovat harvinaisia: tautia esiintyy vain noin kuudella sadastatuhannesta ihmisestä. Tauti havaitaan varhaislapsuudessa, ja se vaikuttaa hermoston kehitykseen ratkaisevasti läpi elämän.
Perimässämme jokaisesta geenistä on kaksi kopiota, toinen äidiltä ja toinen isältä. Tämän vuoksi yhden geenikopion virhe ei aina välttämättä aiheuta merkittäviä ongelmia. SYNGAP1-geenin kohdalla tilanne on kuitenkin toinen: jo yhden geenialleelin heikentynyt ilmentyminen riittää aiheuttamaan vakavan hermostosairauden.
Taudinkuva on moninainen: tyypillisiä oireita ovat eriasteinen älyllinen kehitysvammaisuus, epilepsia ja autismikirjon piirteet. Juuri moninaisuuden vuoksi tautia ei enää kutsutakaan SynGAP-syndroomaksi.
SYNGAP1-geenin mutaatiot eivät ole yleensä vanhemmilta perittyjä, vaan ne syntyvät lapsen perimään alkiovaiheessa. Mutaatiotyyppejä on useita, mutta ne jaetaan yleensä kahteen ryhmään: trunkaatioihin ja vaihtomutaatioihin.
Trunkaatiot lyhentävät SynGAP1-proteiinia tai voivat estää sen syntymisen kokonaan. Tällaiset suuret muutokset ovat yleensä helppo tunnistaa geenitestien avulla. Suurimman osan haitallisista SYNGAP1-mutaatioista arvioidaan kuitenkin olevan pieniä vaihtomutaatioita, joissa yksi aminohappo vaihtuu toiseksi.
Yksittäinen aminohappovaihdos pitkässä aminohappoketjussa ei aina aiheuta merkittäviä toiminnallisia muutoksia. Vaikutus riippuu ratkaisevasti siitä, missä kohtaa proteiinin kolmiulotteista rakennetta muutos tapahtuu ja millainen aminohappo vaihtuu toiseen. Yhdessä kohdassa muutos voi olla harmiton mutta toisessa toiminnalle tuhoisa.
Tämän vuoksi vaihtomutaatiot ovat erityisen haastavia diagnosoida. Ei myöskään ole olemassa kokeellisia menetelmiä, joilla SYNGAP1-vaihtomutaatioiden haitallisuus voitaisiin luotettavasti todentaa. Diagnoosien tueksi tarvitaankin tarkkoja laskennallisia menetelmiä, jotka arvioivat muutosten vaikutuksia proteiinin toimintaan ja rakenteeseen.
Pekka Postila on saanut tutkimusryhmineen yhteensä 230 000 dollarin rahoituksen vaihtomutaatioiden tutkimiseen Kaliforniassa toimivalta Cure SYNGAP1 -säätiöltä. Tutkimuksen tavoitteena on parantaa SYNGAP1-vaihtomutaatioiden diagnostiikkaa hyödyntämällä erityisesti laskennallista rakennetutkimusta.
Vaihtomutaatioita ja niiden merkitystä proteiinirakenteille ymmärtääksemme on hyvä katsoa hieman taaksepäin. Kaikki proteiinit muodostuvat aminohappoketjusta, jonka lenkit ovat toisiinsa peptidisidoksilla kiinnittyneitä aminohappoja. Näitä proteiinin peruspalikoita on 20 erilaista.
Proteiinien rakennusosat ja niiden merkitys elämälle tunnistettiin jo 1800-luvulla, mutta proteiinien tarkkaa rakennetta ei ymmärretty ennen 1950-lukua. Silloin Cambridgen yliopiston tutkijat John Kendrew ja Max Perutz onnistuivat kuvaamaan proteiineja ensimmäistä kertaa kolmiulotteisesti röntgenkristallografialla.
Näky oli yllätys: proteiinit muistuttivat sykkyräisiä spagettikasoja tai lankakeriä, täynnä monenlaisia laskoksia, palmikoita ja silmukoita. Muoto ei kuitenkaan ollut satunnainen. Juuri proteiinin kolmiulotteinen rakenne määrää sen vuorovaikutukset ympäristönsä kanssa: sen, mihin proteiini tarttuu, mitä se päästää lähelleen ja mitä se hylkii. Kendrew ja Perutz saivat uraauurtavasta työstä Nobelin palkinnon vuonna 1962.
Amerikkalaistutkija Christian Anfinsen osoitti vuonna 1961, että proteiinin muoto on koodattu suoraan sen aminohappojärjestykseen. Identtinen aminohappoketju tuottaa siis aina saman proteiinirakenteen. Tämäkin oivallus johti Nobelin palkintoon, vuonna 1972.
Samalla syntyi uusi arvoitus, joka jäi vuosikymmeniksi ratkaisematta: vaikka proteiinien aminohappojärjestyksiä pystyttiin selvittämään spektrometrian avulla, kukaan ei ymmärtänyt, millä mekanismeilla nämä ketjut laskostuvat monimutkaisiksi kolmiulotteisiksi kokonaisuuksiksi.
Vuonna 1994 käynnistettiin kilpailu, jonka tavoitteena oli ennustaa proteiinien kolmiulotteisia muotoja pelkän aminohappojärjestyksen perusteella. Ensimmäiset tietokonemallit olivat kuitenkin karkeita, ja yli kahden vuosikymmenen ajan ennustusten tarkkuus ei juuri parantunut.
Tilanne muuttui vuonna 2018, kun neuroverkkotutkija Demis Hassabis ja biokemisti John Jumper esittelivät uuden työkalun. Googlen DeepMind-laboratoriossa kehitetty AlphaFold hyödynsi oppivia neuroverkkoja, jotka etsivät yhtäläisyyksiä tunnettujen proteiinien rakenteiden ja uuden aminohappoketjun välillä.
Yksinkertaistettuna AlphaFold ennustaa proteiinin muodon yhdistämällä tietoa sukulaisproteiinien jo ratkaistuista rakenteista perinteisen homologiamallituksen tavoin. AlphaFold2:lla on sittemmin ennustettu yli 200 miljoonan proteiinin rakenteet. Hassabis ja Jumper palkittiin Nobelin palkinnolla vuonna 2024.
AlphaFold2:n tuottamaa SynGAP1-proteiinin rakennetta on käytetty vaihtomutaatioiden mallintamisessa apuna. Menetelmällä on kuitenkin merkittäviä rajoituksia mutaatioiden kanssa.
”Oppiva neuroverkko ei osaa varautua mutaatioihin, ja siinä se voi mennä kunnolla metsään. Vaikka proteiinin aminohappoketjuun tulisi mutaatio, joka oikeasti vääristäisi koko rakenteen, AlphaFold tekee silti mallista ehjän ja niin sanotusti terveen version”, Postila selittää.
AlphaFold ei siis yksin riitä arvioimaan vaihtomutaatioiden vaikutuksia. Tarkemman kuvan saaminen edellyttää muita laskennallisia menetelmiä, ja kokeellisesti ratkaistuja proteiinirakenteita.
AlphaFold-mallin pohjalta Postilan tutkimusryhmä on mallintanut kaikki todennäköiset yhden nukleotidin vaihtumisesta syntyvät mutaatiot SynGAP1-proteiinin rakenteeseen. Jos luotettavaa rakennetietoa ei ollut saatavilla, ryhmä hyödynsi sekvenssipohjaisia ja muita ei‑rakenteellisia ennustusmenetelmiä taudinaiheuttavuuden arviointiin.
Mallituksen tuottamat tulokset on kerätty SGM-serveriin (SynGAP Missense server), joka tarjoaa kaikille avoimen nettiportaalin SYNGAP1-vaihtomutaatioiden taudinaiheuttavuuden arviointiin.
Rakennetasolla SGM-serveri sisältää tällä hetkellä yhteensä 3325 vaihtomutaatiovarianttia ja sekvenssitasolla jopa 8751 varianttia. Tietokanta esittää parhaiden menetelmien pohjalta tehdyn konsensusennusteen, tekoälyn tuottaman kirjallisen ennusteyhteenvedon, linkit kliinisiin tietokantoihin sekä kunkin vaihtomutaation kolmiulotteisen mallin että kaksiulotteisen interaktiodiagrammin.
SGM-serverin ja tietokannan on koodannut ja sitä ylläpitää tutkija Jukka Lehtonen Structural Bioinformatics Laboratory:sta Åbo Akademista. Koska tietokanta on tehty potilasjärjestön pyynnöstä, se pyrkii vastaamaan todelliseen diagnostiseen tarpeeseen.

Kliinisessä ClinVar-tietokannassa listattujen SynGAP1‑vaihtomutaatioiden kohdalla Postilan ryhmä on vienyt rakenteisiin perustuvan analyysin vielä askelta pidemmälle. Mutaatioita ei ainoastaan mallinnettu staattisina kolmiulotteisina rakenteina vaan niiden aiheuttamia rakennemuutoksia tutkittiin perusteellisesti myös molekyylidynamiikkasimulaatioilla (MD).
Nämä simulaatiot perustuvat puoliempiiriseen voimakenttämalliin, jossa aminohappojen atomit esitetään ikään kuin palloina ja näiden pallojen väliset sidokset toimivat kuin pieninä jousina. Kun malliin lisätään lämpöä, atomit alkavat liikkua, sidokset joustavat ja proteiinin osat vuorovaikuttavat keskenään. Proteiini alkaa ”elää” tai ”hengittää” samalla tavoin kuin tapahtuu oikeissa soluissakin.
Näiden tietokonesimulaatioiden avulla voidaan tarkasti selvittää, miten vaihtomutaatiot muuttavat proteiinin kolmiulotteista rakennetta.
Menetelmän näennäisestä yksinkertaisuudesta huolimatta laskennallinen kuorma on valtava, ja jo nanosekuntien mittaiset simulaatiot edellyttävät supertietokoneiden käyttöä. Tutkimuksessa 211 vaihtomutaatiovarianttia on MD-simuloitu yhteensä noin 100 mikrosekuntia (150 ns × 3 × 211). Lisäksi MD‑simulaatioihin pohjautuvia laskostumisenergialaskuja on tehty muillekin rakenneosien varianteille. Laskujen tarkkuus on käytettävissä olevan tiedon perusteella omaa luokkaansa.
Ilman CSC – Tieteen tietotekniikan keskuksen tarjoamaa suurteholaskentaa näin mittava laskenta ei olisi ollut mahdollista. Postila kiittelee yhteistyötä CSC:n kanssa vuolaasti.
”Kun aina välillä tuntuu, että kaikista resursseista vain leikataan, on CSC:n kaltainen keskitetty palveluorganisaatio kaltaisellemme tutkimusryhmälle erinomainen järjestely. Toivottavasti tämä asia ei muutu tulevaisuudessakaan.”
Projektin simulaatioita on ajettu pääosin Puhti‑supertietokoneen GPU-osiolla. Postilan ryhmä on käyttänyt kuitenkin simulaatioissa ja AlphaFold‑mallituksessa lisäksi Mahti‑supertietokonetta. Yhden noin 140 000 atomia kattavan simulaation ajaminen kestää tavallisesti pari päivää, ja lisäksi kaikki simulaatiot on toistettava vähintään kolme kertaa.
”Malli ei ole täysin deterministinen, ja peräkkäisissä simulaatioissa voi olla pieniä eroja. Useampi ajo varmistaa, että olemme ymmärtäneet oikein.”, Postila toteaa.
Postilan johtama tutkimus pyrkii aktiivisesti laajentamaan SGM-serveriä sisältämään parasta tietoa vaihtomutaatioiden taudinaiheuttavuudesta. Uusia ennustusmenetelmiä kuten AlphaFoldiin perustuva AlphaMissense, ilmestyy kiihtyvällä tahdilla.
Rakennetasolla ryhmä selvittää, miten vaihtomutaatiot vaikuttavat SynGAP1-proteiinin vuorovaikutuksiin muiden proteiinien tai esimerkiksi solukalvon kanssa.
Tarkastellessa geenisekvenssejä ja proteiinirakenteita sekä abstrakteja ennusteita, voi helposti unohtua, että proteiinit eivät toimi yksin. Solun sisällä ne ovat jatkuvassa ja dynaamisessa vuorovaikutuksessa toistensa kanssa.
SynGAP1 ei ole tässä asiassa poikkeus. Sen proteiiniketjuissa oleva CC‑domeeni (engl. coiled‑coil, ”kierteinen kierre”) kietoutuu viereisten ketjujen ympärille ja muodostaa kimpun, joka sitoo kolme SynGAP1‑proteiinia yhteen.
Itsensä lisäksi SynGAP sitoutuu myös Ras‑ ja Rap‑GTPaasien kaltaisiin säätelyproteiineihin sekä erilaisiin tukiproteiineihin, kuten PSD95‑proteiiniin, jotka ovat keskeisiä hermosolujen viestinnässä ja synapsien toiminnassa.
”Laskentatehon kasvaessa voimme lisätä ymmärrystämme ajamalla yhä pidempiä simulaatioita ja mallintamalla yhä suurempia järjestelmiä, joissa on mukana useita vuorovaikutuksessa olevia komponentteja”, Postila toteaa.
Pekka Postila esittelee videolla (YouTube), miten SynGAP Missense Server toimii käytännössä.
Teksti, tutkijoiden ryhmäkuva ja video: Juha Merimaa
27.1.2026
Lue artikkeli PDF-muodossa
Lisätietoja:
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR on hajautettu eurooppalainen bioalan tutkimusta palveleva infrastruktuuri. Se tarjoaa yhdistetysti 21 maan ja Euroopan molekyylibiologian laboratorion EMBL:n dataresursseja, ohjelmistotyökaluja, koulutusta, pilvipalveluita ja suurteholaskentaresursseja. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Suomen ELIXIR-keskuksen palvelut ovat saatavilla luotettavan tunnistautumisen kautta. ELIXIR AAI (Authorisation and Identification Infrastructure) on palvelu, jonka kautta tutkijat tunnistautuvat ja saavat käyttöluvan eri ELIXIR-keskusten palveluihin. Tutkijat pääsevät yhdellä käyttäjätunnuksella ja yhdellä sisäänkirjoituksella kaikkiin ELIXIR-palveluihin, jotka heille on myönnetty. ELXIR AAI-palvelun tuottavat Suomen ja Tsekin ELIXIR-keskukset. Euroopan tason yhteisestä tunnistautumisratkaisu on kytketty tietoturvalliseen datan jakeluun.
REMS- käyttäjähallintaohjelma on osa tätä palvelua. Suomen ELIXIR-keskus tukee tutkijan tunnistautumista ja hänen käyttöoikeuksiensa hallintaa osana Eurooppalaista käyttäjähallintoa. ELIXIR palveluihin voi tunnistautua Suomessa Suomen korkeakoulujen ja tutkimuslaitosten yhteisen käyttäjätunnistusjärjestelmän HAKA:n avulla. Tutkimusaineistojen käyttöluvat integroituvat tunnistautumisen yhteydessä osaksi datan analyysipalvelua. Käyttöluvat myöntänyt organisaatio on myöntänyt ne tutkijalle ELIXIR Suomen rahoittaman REMS järjestelmän avulla. ELIXIRin kautta tätä työkalua voidaan käyttää myös Euroopassa biolääketieteen aineistoihin. REMSiä käytetään myös muilla tieteenaloilla, kuten yhteiskuntatieteissä ja kielitutkimuksessa.
Haka on Suomen korkeakoulujen ja CSC:n kehittämä käyttäjätunnistusjärjestelmä. Vaikka palvelu sijaitsisi toisen organisaation palvelimella, voidaan käyttää oman kotikorkeakoulunsa käyttäjätunnusta ja salasanaa kirjautuessaan palveluun. Haka kytkeytyy myös kansainväliseen eduGAIN-käyttäjätunnistukseen.
ELIXIR AAI- palvelua vetävät Mikael Linden (ELIXIR Finland) ja Michal Prochazka (ELIXIR Czech Republic). Yhteystiedot: aai-contact@elixir-europe.org.
https://www.elixir-europe.org/services/compute/aai

Immuunivälitteiset sairaudet, kuten allergiat, astma ja autoimmuunisairaudet, ovat lisääntyneet kaupungistumisen myötä. Syyksi on epäilty liian puhdasta ympäristöä, jossa menetetään kosketus luontoon ja sen mikrobeihin. Dosentti Olli Laitinen tutkii Tampereen yliopistossa mikrobialtistuksen terveysvaikutuksia. Hän on myös Uute Scientific Oy:n päätutkija. Yritys valmistaa inaktivoituja mikrobeja sisältävää uutetta, jota voidaan käyttää esimerkiksi kosmetiikassa voiteiden raaka-aineena.
Mikrobialtistusta voidaan lisätä helposti liikkumalla luonnossa ja olemalla kosketuksissa maaperän kanssa. Luontopohjaisten ja mikrobistoltaan rikkaiden materiaalien käsittely muuttaa kehon mikrobistoa. Laitisen hankkeissa tutkitaan kaupunkialueille sopivia ratkaisuja vaikuttaa immuunijärjestelmän häiriöiden yleisyyteen viherympäristöä ja kuluttajatuotteita muokkaamalla
Laitisen mielestä mikrobialtistus alkaa syntymästä.
”Kun me synnymme, meidän elimistömme ei ole immunologisesti valmis. Syntymähetkellä me käytännössä kohtaamme miljoonia erilaisia elämänmuotoja. Siinä vaiheessa immuunijärjestelmämme alkaa opiskella sitä, mikä on vaarallista ja mikä vaaratonta.”
Laitinen korostaa sitä, että perimmäinen syy nykyajan immuunivälitteisiin sairauksiin on juuri se, että olemme kadottaneet kosketuksen luontoon ja elämme liian puhtaassa ympäristössä.
”Ihminen on elänyt satoja tuhansia vuosia luonnonolosuhteissa. Ollaan synnytty eläintentaljoille, ja vauvat kiedottu kasviperäisiin materiaaleihin. Ollaan oltu heti kosketuksissa maaperään ja luontoon. Tähän altistukseen sopeuduttiin.”
”Syntymähetkellä kaikki levähtää keholle ja immuunijärjestelmä alkaa toimia. Silloin on tärkeää immuunijärjestelmälle osata erottaa mikä on vaarallista ja vaaratonta. Vaaratonta on tietenkin oma keho. Immuunijärjestelmän on myös tunnistettava, että kaikki ulkopuolelta tuleva ei ole vaarallista. Ei siis kannata synnyttää allergioita eläinten hilsettä vastaan. Immuunijärjestelmän olisi opittava, mitkä ovat oikeasti vaarallisia patogeenejä.”
Synnytys sairaalassa on varsin steriiliä luontoon verrattuna.
”Jos ollaan sellaisessa ympäristössä, jossa ei ole opetusmateriaalia paljon, niin helposti järjestelmä kokee, että kaikki ulkopuolinen on vaarallista. Tällöin syntyy allergioita ja astmaa, atooppista ihottumaa tai sitten kohdataan vielä pahempi tilanne: immuunijärjestelmä ei pysty erottamaan, mitkä ovat elimistön omia soluja, jolloin se ryhtyy tuhoamaan niitä, mikä johtaa erilaisiin autoimmuunisairauksiin.”

Lupaavia tuloksia on nyt saatu siitä, miten monimuotoinen ympäristö voi estää autoimmuunisairauksien, kuten tyypin 1 diabeteksen kehittymisen. Laitinen viittaa Tampereen yliopistossa tutkivan Noora Nurmisen väitöskirjan osatyöhön, jossa Nurminen tutki vihreän ympäristön määrää ja sen vaikutusta tyypin 1 diabeteksen kehittymiseen.
”Tyypin 1 diabetes syntyy, kun immuunijärjestelmän tulehdussolut aktivoituvat haimassa ja tuhoavat insuliinia tuottavat solut. Nurminen käytti aineistonaan 15 000 lapsen kohorttia ja tutki miten kasvuympäristö ensimmäisen elinvuoden aikana vaikutti diabeteksen kehittymiseen. Tutkimustulokset osoittivat, että agraariympäristö oli lapsille terveellinen. Maaseudulla asuville lapsille ei kehittynyt diabetesta tai siihen johtavaa autoimmuuniprosessia yhtä usein kuin kaupunkimaisissa ympäristössä eläneille lapsille tai tautiin johtava prosessi käynnistyi huomattavasti myöhemmin kuin kaupungissa asuvilla lapsilla.”
Monipuolinen mikrobisto ihmisen kehossa on vähentynyt huomattavasti, etenkin länsimaissa. Erään arvion mukaan kaupungistuneiden ihmisten iholla on jäljellä 60% alkuperäisestä mikrobistosta ja suolistossa vain 50%. Yhdysvalloissa mikrobikato on paikoin vielä suurempi. Amerikkalaisilla onkin enemmän tulehdussairauksia kuin muilla.
Olli Laitisen mielestä viimeistään siinä vaiheessa, kun lähdetään kotiin synnytyssairaalasta, pitäisi vastasyntyneen keholle saada immuunijärjestelmän koulutusta, toisin sanoen luontoaltistusta. llman altistumista luonnolle ja sen mikrobeille elimistömme immuunipuolustus ei toimi tarkoituksenmukaisesti. Kehon puolustusjärjestelmän ylireagointi voi johtaa sairauksiin. Esimerkiksi allergiassa keho tulkitsee siitepölyn virheellisesti virukseksi.
”Pohjaamme tutkimuksemme immuunijärjestelmän toimintaan ja luontoaltistuksen puutteen aiheuttamiin häiriöihin. Immunoglobluliini E:n luonnollinen tehtävä on ollut taistella loistartuntoja vastaan, mutta kun niitä on nyt huomattavasti vähemmän, IgE on vapaa agentti ja etsii uusia tehtäviä. Sellainen on esimerkiksi reagointi siitepölyyn. ”
Immunoglobuliinit eli vasta-aineet ovat valkuaisaineita, joita elimistön puolustusjärjestelmän solut tuottavat. Vasta-aineiden tehtävänä on auttaa puolustusjärjestelmää tuhoamaan tunkeilijoita, kuten bakteereita ja viruksia. IgE-luokan vasta-aineet ovat jääneet liiallisen hygienian ja steriilisyyden takia vaille luontaista aktiviteettiaan ja siten toimettomaksi. Nyt IgE-vaste aktivoituu väärin siitepölyn proteiineja kohtaan ja aiheuttaa allergisia yliherkkyysreaktioita.
Immunoglobuliini E esiintyy allergioiden ja allergisten sairauksien yhteydessä. Allergiassa elimistö tuottaa sitä esimerkiksi siitepölyä tai ruoka-aineita kohtaan. Vasta-aine kiinnittyy ihon ja limakalvojen soluihin, ja vapauttaa histamiinia. Sitten aivastellaan, henki salpautuu ja silmät muurautuvat umpeen. Kehitysmaissa, joissa loistartuntoja on yleisemmin, IgE:tä esiintyy usein korkeina pitoisuuksina ilman allergiaoireita.
Immunoglubuliinien ”väärät viholliset” on hyvä esimerkki biodiversiteetin vähenemisestä, mikä koskee myös mikrobistoa.
”Nyt kun meille myydään paljon antibakteerisia torjunta-aineita, kaikki bakteerit itse asiassa siivotaan pois. Tämä ei ole suotavaa. Olisi parempi, että meillä olisi vakiintunut mikrobiyhteisö ympärillämme, koska siiloin ei tapahdu liian isoja muutoksia.”
Muutokset mikrobistossa voivat aiheuttaa antibioottiresistenssia, joka on iso ongelma. Antibiooteille vastustuskykyiset bakteerit kantavat resistenssigeenejä ja niistä tulee usein mikrobipopulaatioissa vallitsevia.
”Patogeenit ovat nopeasti kasvavia mikrobeja. Runsas patogeenien määrä lisää geenien vaihdantaa niiden välillä, jolloin niiden vastustuskyky antibiootteja vastaan vahvistuu”, sanoo Laitinen, joka on tutkinut myös antibioottiresistenssiä.
”Toivottavasti tulevaisuudessa meillä olisi turvallinen määrä monimuotoisia mikrobeja ympäristössämme, jotta antibioottiresistentit bakteerit eivät menestyisi.”

Atooppinen ihottuma on yleinen, osin perinnöllinen tauti, jota sairastaa Suomessa noin 20–30 % väestöstä. Sen oireita ovat ihon kutina, kuivuus, karheus, punoitus ja rikkoumat. Syynä on immuunijärjestelmän poikkeava toiminta.
”Pohjoismaissa atooppinen ihottuma on yleistä. On huomattu, että monet immuunivälitteiset taudit yleistyvät populaatiotasolla pohjoista kohti mentäessä.”
Tampereen ja Helsingin yliopistojen vetämässä PREVALL-hankkeessa on tutkitttu kasvi- ja maapohjaisen materiaalin vaikutusta lasten allergisoitumiseen. Hankkeessa on myös selvitetty, pystyttäisiinkö atooppisen ihottuman kehittyminen estämään vauvaikäisillä. Tutkimukseen otettiin mukaan lapsia, joiden molemmilla vanhemmilla on todettu atooppinen ihottuma.
”Tällöin lapsella on noin 40% riski saada sama sairaus,” Laitinen huomauttaa.
Johanna Kalmarin ja Iida Mäkelän tutkimuksessa, joka on Uutteen ja Tampereen yliopiston yhteishanke, atooppiseen ihottumaan sairastuneille annettiin Uute Scientificin uutetta sisältävää mikrobivoidetta. Mikrobit eivät olleet eläviä, mutta voide sisälsi mikrobien ainesosia, joihin keho ja immuunipuolustus pystyy reagoimaan. Luontoaltistusta annettiin siis voiteen kautta. Voiteen käyttö aloitettiin loppukesästä ja syksyllä, koska talvella atoopikkojen iho on huonommassa kunnossa kuivan ilman ja lämpötilan laskun vuoksi. Myös luonnonvalon määrän vähenemisellä on vaikutusta. Voidetta käytettiin vähintään kolme kertaa viikossa. Koehenkilöistä otettiin erilaisia näytteitä ja tutkittiin ihon veden läpäisevyyttä ja punoitusta, jotka ovat tulehduksen indikaattoreita.
”Suurin ero nähtiin lääkkeen käytössä. Voidetta käyttänyt ryhmä käytti selvästi vähemmän lääkkeitä 7 kuukauden koejakson jälkeen. Voiteella pystyttiin estämään ihon huonontumista. Voide on ns. luontoaltistuslääke. Se on tukeva hoitomuoto, jotta voi käyttää vähemmän lääkkeitä.”
Uutena aluevaltauksena on, ei enempää eikä vähempää, avaruus.
”Astronautit kärsivät erilaisista iho-ongelmista. Kansainvälisellä avaruusasemalla on hyvin köyhä mikrobiympäristö, mikä ei ole yllättävää. Meidän uutettamme voitaisiin viedä avaruuteen. Keskusteluja on käyty voiteen käytöstä Euroopan avaruusjärjestön ESA:n kanssa.”
Olli Laitisen tutkimusryhmä Tampereen yliopistossa ja Uute Scientific ovat käyttäneet tutkimuksissaan Suomen ELIXIR-keskuksen CSC:n laskentapalveluja ja sensitiivisen datan palveluja. yli 10 vuotta kestäneissä Tutkimuksissa on otettu näytteitä yli 500 yksilöltä vauvoista, päiväkoti-ikäisiltä ja aikuisilta. Osa datasta on säilytetty CSC:n tietoturvallisessa ympäristössä.
Uute Scientificin mikrobiuute on valmistettu yhdistelemällä erilaisia kasvikomposteja. Se sisältää toimintakyvyttömiä mikrobeja. Näistä ei ole siis mitään harmia. Immuunijärjestelmä kuitenkin tunnistaa mikrobit, mikrobiosaset ja myös tuhotut patogeenit eli taudinaiheuttajat. Materiaali on kehitetty alun perin Helsingin ja Tampereen yliopistoissa. Se on biodiversiteetiltään ainutlaatuinen kosmetiikan ja muiden kuluttajatuotteiden raaka-aine koko maailmassa. Siinä on vähintään 600 eri mikrobilajia.
Ari Turunen
23.6.2025
Lue artikkeli PDF-muodossa
Lisätietoja:
Tampereen yliopisto
Uute Scientific
https://www.uutescientific.com/fi/
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Puun kuori on tärkeä kemiallinen ase tuholaisia kohtaan. Kun kasvia uhkaa bakteeri tai hyönteinen, niissä olevat alkaloidit voivat esimerkiksi estää tuholaisten DNA:n tai solunjakautumisen toiminnan, mikä pysäyttää niiden lisääntymisen. Näin toimivat paklitakseli ja kamptotesiini, kaksi eri puiden kuoresta eristettyä yhdistettä, joista kehitettiin tehokkaita syöpälääkkeitä. Puiden ja muiden kasvien sisältämien bioaktiivisten yhdisteiden selvittämisen avuksi ovat nyt tulleet data-analyysit ja tietokannat.
Maailmassa on puoli miljoonaa kasvia, joista arviolta 7 prosenttia on käytetty lääkinnässä. Noin 25 % nykyisistä reseptilääkkeistä on kasvipohjaisia. Tämä tarkoittaa lääkkeitä, joissa on puhtaita kasveista eristettyjä yhdisteitä tai niistä kehitettyjä synteettisiä johdannaisia. Luonnon monimuotoisuuden säilyttäminen on ensiarvoisen tärkeää myös lääkkeiden takia, koska koko ajan löydetään uusia kasvilajeja ja tunnettujenkin kasvilajien kemiallinen koostumus on pääosin selvittämättä.
Paklitakseli ja kamptotesiini ovat esimerkkejä syöpälääkkeistä, jotka löydettiin, kun potentiaalisen lääkekasvien näytteitä alettiin seuloa järjestelmällisesti. Yhdysvaltain kansallinen syöpäinstituutti NCI seuloi yli 35 000 kasvinäytettä tutkimusohjelmassa, joka käynnistettiin 1956 ja jatkui vuoteen 1981 asti. Ohjelman tarkoituksena oli etsiä kasveista yhdisteitä, joilla voisi olla syöpää ehkäiseviä tai hoitavia vaikutuksia.
Kunnianhimoinen ohjelma hyödynsi myös etnobotaniikkaa ja historiaa. Ohjelman johtaja Jonathan Hartwell kokosi kattavan kokoelman muinaisten kiinalaisten, egyptiläisten, kreikkalaisten ja roomalaisten tekstejä kasvien lääkekäytöstä. Näytteiden löytämiseksi ja tarkkojen kasvitieteellisten tietojen saamiseksi Hartwell kääntyi Yhdysvaltain maatalousministeriön (USDA) puoleen. USDA:n kasvitieteilijät alkoivat kerätä kasveja eri puolilta maailmaa analysoitaviksi laboratorioissa.

Research Triangle Institute -tutkimuslaitoksen kemistit Monroe E. Wall ja Mansukh C. Wani saivat Camptotheca acuminata -puun näytteet tutkittavakseen. Puuta kutsutaan Kiinassa ”onnen puuksi” ja se kasvaa luontaisesti kosteilla penkoilla Jangtse-joen rannoilla. Kiinalaisessa perinteisessä lääketieteessä puun lehtiä ja kuorta on käytetty erilaisten tulehdusten ja infektioiden hoitoon.
Wall ja Wani huomasivat, että C. acuminatan sisältämät aineet olivat erittäin aktiivisia hiiren leukemian L1210-solulinjassa eli vaikutuksia oli nähtävissä syöpäsoluissa. L1210-linjaa käytetään yleisesti syöpätutkimuksessa ja uusien syöpälääkkeiden testaamisessa. Se on peräisin hiirestä, jolla oli lymfaattinen leukemia. Wall ja Wani eristivät puusta aktiivisen yhdisteen, joka sai nimen kamptotesiini. Sen havaittiin olevan erittäin tehokas leukemiasoluja vastaan.
Kamptotesiini sitoo solujen tärkeän entsyymin, topoisomeraasi I:n, DNA-komplekseihin. Tämä estää syöpäsolujen DNA:n kopioitumisen ja johtaa solun kuolemaan. Huolimatta tehokkuudestaan kamptotesiinillä on vakavia sivuvaikutuksia ja huono liukoisuus. Lääkkeen vesiliukoisuus on tärkeä, koska se vaikuttaa lääkkeen imeytymiseen ja jakautumiseen elimistössä. Myöhemmin kehitettiin kamptotesiinin johdannaisia, jotka olivat paremmin siedettyjä, vesiliukoisia ja säilyttivät tehokkuutensa. Näitä ovat topotekaani ja irinotekaani. Topotekaania (Hycamtin) käytetään munasarja-, keuhko- ja kohdunkaulansyövässä, irinotekaania (Camptosar) ensisijaisesti paksusuolen- ja peräsuolisyövän hoitoon.
Luonnollisesta yhdisteestä jatkokehitetyt synteettiset johdannaiset voivat olla alkuperäistä yhdistettä huomattavasti tehokkaampia. 1980-luvulla japanilainen Yakult Honsha -yhtiö kehitti kamptotesiinin johdannaisen irinotekaanin. Silloin selvisi, että sen aktiivinen muoto elimistössä on sen aineenvaihduntatuote 7-etyyli-10-hydroksikamptotesiini, joka on noin 100–1000 kertaa aktiivisempi kuin itse iritotekaani. Yhdistettä alettiin kutsua nimellä SN-38. Yhdisteen nimi on lääkeyhtiön koodi ”SmithKline Number 38”. Se ei ole aktiivinen sellaisenaan, vaan toimii ns. prolääkkeenä. SN-38 on voimakas syöpälääkeaine, joka syntyy elimistössä, kun irinotekaanimuuttuu aktiiviseksi muodokseen. Iritotekaani muuttuu maksassa ja muissa kudoksissa SN-38:ksi. Se on siis muokattu versio luonnosta löytyvästä kamptotesiinista, johon on lisätty etyyli- ja hydroksyyliryhmät. Näillä muutoksilla saatiin aikaan erittäin tehokas lääkeaine.
Joillakin ihmisillä on UGT1A1*28-mutaatiota. Jos UGT1A1-geenissä on mutaatio (kuten UGT1A1*28), se voi vähentää entsyymin toimintaa, jolloin SN-38:n eliminoituminen hidastuu ja sen toksisuus voi kasvaa. Tämä voi lisätä haittavaikutuksia. Ensembl-tietokannasta voi esimerkiksi tutkia UGT1A1-geeniä, sen mutaatioita ja mahdollisia vaikutuksia SN-38:n metaboliaan.

Wall ja Wani jatkoivat kasvinäytteiden tutkimista kamptotesiinin löytämisen jälkeen. He saivat analysoitavakseen Tyynenmeren marjakuusen (Taxus brevifolia) näytteitä.
Tyynenmeren marjakuusi on yksi viidestä suvusta Taxaceae-heimossa. Se kasvaa Pohjois-Amerikassa hyvin hitaasti jättimäisten havupuiden varjossa purojen rannoilla, syvissä rotkoissa ja kosteissa solissa. Sen puu on kovaa mutta vain vähän hyödynnettävissä. Puulla on vain vähän luonnollisia tuholaisia, koska suurin osa kasvista on myrkyllistä. Vuonna 1971 Wall, Wani ja heidän työtoverinsa julkaisivat tutkimustuloksen, jossa he esittelivät marjakuusen kuoresta eristetyn yhdisteen. Se estää mikrotubulusten hajoamisen ja pysäyttää syöpäsolun jakautumisen. Yhdiste sai nimekseen paklitakseli (Taxol).
Paklitakseli oli tehokas syöpälääke, mutta se aiheutti ympäristöhuolia. Yhdisteen eristäminen tappoi harvinaisia marjakuusia. Koska luonnollinen lähde (marjakuusen kuori) ei riittänyt laajamittaiseen lääkkeiden tuotantoon, 1990-luvulla kehitettiin puolisynteettinen menetelmä, jossa lähtöaineena käytetään marjakuusen neulasista saatavaa 10-deasetyylibakkatiinia. Tuo yhdiste (10-DAB) on paklitakselin esiaste, mutta kun siihen lisätään bentsyyliamiinia, saadaan puhdasta ja ekologisesti kestävää paklitakselia. Paklitakseli on yksi yleisimmin käytetyistä lääkkeistä rintasyövän ja munasarjasyövän hoidossa.
ELIXIR Core Data Resources (CDR) on valittu niiden laadun, laajan käytön ja pitkäaikaisen merkityksen perusteella. Ne ovat keskeisiä monille tutkimusaloille, kuten genomiikalle, proteomiikalle ja lääkekehitykselle. ELIXIR Core Data Resources tarjoaa tutkijoille avoimen ja luotettavan pääsyn biologisiin tietoaineistoihin, mikä edistää uusia löytöjä ja nopeuttaa esimerkiksi uusien lääkkeiden kehittämistä, tautien ymmärtämistä ja biomarkkerien tunnistamista.
ELIXIR-infrastruktuurin tarjoamat data-analyysipalvelut ja koneoppimismallit voivat auttaa tunnistamaan uusia lääkeaihioita suurista tietomassoista. Näiden resurssien sekä tietokantojen avulla luonnosta löydettyjä yhdisteitä voidaan analysoida nopeammin ja tarkemmin, mikä edistää niiden kehitystä turvallisiksi ja tehokkaiksi lääkeaineiksi.

ENA on Euroopan bioinformatiikkainstituutin (EMBL-EBI) ylläpitämä tietokanta, joka tallentaa ja jakaa sekvenssidataa eri eliöistä, mukaan lukien mikrobit, kasvit, eläimet ja ihmiset. Koska ENA sisältää genomi- ja sekvenssidataa kaikista elämänmuodoista, se on keskeinen tietokanta biodiversiteettitutkijoille, jotka analysoivat lajien geneettistä monimuotoisuutta, populaatiogenetiikkaa ja evoluutiota. Se auttaa uusien lajien tunnistamisessa (DNA-viivakoodaus ja metagenomiikka) sekä lajien välisen sukulaisuuden tutkimisessa (fylogeneettiset analyysit).
ENA:n sisältämät geneettiset tietokannat tarjoavat mahdollisuuden suorittaa laajoja meta-analyysejä ja verrata eri väestöjen tai lajien geneettisiä tietoja. Tämä voi tukea monenlaisten tutkimusalueiden, kuten evoluutiobiologian, sairauksien tutkimuksen ja lääketieteen, edistymistä. ENA on avoin tutkijoille ympäri maailmaa.
![]()
ChEBI (Chemical Entities of Biological Interest) on biokemiallinen tietokanta, joka sisältää tietoa pienimolekyylisistä yhdisteistä, joilla on biologista merkitystä. Se on kuratoitu ja tarjoaa tarkkoja kemiallisia ja biologisia tietoja muun muassa lääkeaineista, metaboliiteista ja luonnonaineista. ChEBI tarjoaa tarkan kemiallisen rakenteen, molekyylikaavan, massan ja isomeerisen tiedon, mikä auttaa tutkijoita analysoimaan lääkeyhdisteiden kemiallisia ominaisuuksia.
Haku: tietokannasta voi hakea tietoa esimerkiksi paklitakselin biologista vaikutuksesta ja sen kohdemolekyylit
![]()
Ensembl on genomi- ja bioinformatiikkatietokanta, joka tarjoaa analysoituja genomitietoja useista eliöistä, mukaan lukien ihmiset, eläimet, kasvit ja mikrobit.
Haku: paklitakselin pääasiallinen vaikutuskohde on tubuliini -proteiini. Ensembl tarjoaa geneettistä ja proteiinirakennetietoa tubuliinista ja siihen liittyvistä geeneistä, mikä auttaa tutkimaan lääkeresistenssiä ja mutaatioiden vaikutuksia. Ensembl sisältää tietoa geneettisistä variaatioista, jotka voivat vaikuttaa Taxolin tehoon ja aiheuttaa haittavaikutuksia. Esimerkiksi CYP3A4- ja CYP2C8-entsyymit metabolisoivat Taxolia, ja niissä esiintyvät mutaatiot voivat vaikuttaa lääkkeen tehokkuuteen.

Ari Turunen
8.5.2025
Lue artikkeli PDF-muodossa
Lisätietoja:
ELIXIR Core Data Resources
https://elixir-europe.org/platforms/data/core-data-resources
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
Datan hyödyntäminen edellyttää analyysimenetelmien osaamista. ELIXIR tarjoaa koulutusmahdollisuuksia ympäri Eurooppaa. Suomen ELIXIR-keskus CSC järjestää monipuolisia bioinformatiikan kursseja, joissa opastetaan ohjelmistojen ja pilvipohjaisten palvelujen käytössä. CSC:n asiantuntijat neuvovat tutkijoita laskentamenetelmien ja niihin liittyvien ohjelmien käytössä ja kehittämisessä sekä auttavat tietoteknisissä ongelmissa.
Kansainvälisen ELIXIR-verkoston kouluttajat vierailevat eri keskuksissa ja pitävät koulutustilaisuuksia. ELIXIRin koulutusportaali TeSS (https://tess.elixir-europe.org/) listaa Euroopassa järjestettäviä bioinformatiikkakursseja, ja sen avulla voi myös etsiä linkkejä jo pidettyjen kurssien opetusmateriaaleihin.
Kaikki ELIXIR Euroopan koulutuspalvelut:
https://www.elixir-europe.org/services/training

CSC-Tieteen tietotekniikan keskus Oy operoi ELIXIR Suomen solmupistettä ja tarjoaa kattavan kokonaisuuden tieteellisen laskennan, datahallinnon- ja analyysin palveluja ja ratkaisuja biolääketieteen tutkijoille. Useimmat palveluista ovat ilmaisia suomalaisille yliopistojen tutkijoille, mutta yleensä CSC:n käyttäjätunnus vaaditaan.
CSC:n palvelut ovat suomalaisissa tutkimusorganisaatioissa kirjoilla olevien tutkijoiden käytettävissä. Tämän lisäksi ELIXIR Suomi tarjoaa palveluita kansainvälisille käyttäjille ELIXIR-sopimuksen perusteella seuraavasti:
ELIXIR Suomen keskus CSC järjestää bioinformatiikan, tieteellisen laskennan, datanhallinnan, identiteetin ja pääsynhallinnan teknologioiden sekä tietoverkkojen koulutusta. Kansainväliset tutkijat voivat osallistua ELIXIR Suomen keskuksen tarjoamiin koulutuksiin. Löydät CSC:n järjestämät koulutukset täältä:
ELIXIR koulutusportaali TeSS kokoaa eri ELIXIR-keskusten ja muiden koulutustarjoajien biotieteiden koulutusresurssit yhteen.
Chipster on käyttäjäystävällinen analyysiohjelmisto suurikapasiteettiselle (high-throughput) datalle, kuten yksittäisen solun RNA-sekvensoinnille. Chipster-alusta sisältää yli 400 analysointityökaluja ja laajan kokoelman referenssidataa. Käyttäjät voivat tallentaa ja jakaa automaattisia analyysiputkia, sekä visualisoida dataa interaktiivisesti.

Ruusukatara (Catharanthus roseus) on kaunis Madagaskarin saarella kasvava kukka. Se on yksi merkittävimmistä kasvilääkkeistä syövän hoidossa. Kukka on pelastanut tuhansia lymfaattiseen leukemiaan sairastuneita lapsia. Ruusukatara on loistava esimerkki siitä, miksi luonnon monimuotoisuutta pitää suojella. Saarella eristyksissä kasvaneen ruusukataran genomin mutaatiot ovat antaneet kasville sekundaarisia aineenvaihduntatuotteita, jotta tämä selviytyisi Madagaskarin ekosysteemissä. Ruusukatarasta löytyy yli 200 alkaloidiyhdistettä, joista vinkristiiniä ja vinblastiinia käytetään lääkehoidoissa. Vaikka uusia syöpälääkkeitä kehitetään jatkuvasti, vinkristiini ja vinblastiini eli vinka-alkaloidit ovat edelleen tärkeitä lääketieteessä.
Ruusukataran biosynteesiä, prosessia, jossa uusia yhdisteitä syntyy entsyymien nopeuttamina yksinkertaista lähtöaineista, selvitettiin vuosia. Ruusukataran lehtiä on perinteisesti käytetty Madagaskarilla verensokerin alentamiseen ja diabeteksen hallintaan sekä tulehdusten ja haavojen hoitoon. Kun kanadalaiset tutkijat Robert Noble ja Charles Beer alkoivat 1950-luvulla selvittää, miten ruusukatara alensi verensokeria, he löysivätkin muuta mielenkiintoista.
Noble ja Beer antoivat rotille suun kautta kukan uutteita, mutta seerumin glukoositasoissa ei havaittu vaikutusta. Tutkijat kokeilivat toista lähestymistapaa ja antoivat rotille uutetta suonensisäisesti toivoen sen voimistavan verensokeria alentavaa vaikutusta. Tämä johti odottamattomiin seurauksiin: kaikki rotat kuolivat bakteerien aiheuttamiin infektioihin. Tutkijat kuitenkin huomasivat, että kasvin uutteet vaikuttivat immunosuppressiivisesti eli voimakkaasti valkosoluihin ja luuytimeen. Tämä johti tarkemmassa tutkimuksessa syöpää estävien ominaisuuksien löytämiseen. Noble ja Beer analysoivat ruusukatarasta saatuja aineita, kunnes tunnistivat vaikuttavan yhdisteen, jonka he nimesivät vinkaleukoblastiiniksi (vinblastiini). Vinblastiini häiritsee solun sisäistä aineenvaihduntaa ja pysäyttää solun jakautumisen – toisin sanoen se on solunsalpaaja.
Charles D. Carmichael ja Harold P. S. Harington eristivät vinkristiinin ruusukatarasta 1950-luvulla. Carmichael ja Harington työskentelivät Canadian Cancer Research Foundationin alaisuudessa, ja heidän tutkimuksensa keskittyivät syöpälääkkeiden etsimiseen luonnonvaraisista kasveista. Vinkristiini oli yksi heidän löytämistään tehokkaista aineista, jotka estivät syöpäsolujen jakautumista.
Samaan aikaan Gordon Svoboda ja Irving Johnson Eli Lilly and Company-lääkeyhtiössä tutkivat kasvinäytteitä eri puolilta maailmaa toivoen löytävänsä kasviuutteita, joista voitaisiin kehittää syöpälääkkeitä. He osallistuivat konferenssiin, jossa kanadalaiset tutkijat esittelivät tutkimuksiaan.
He huomasivat jakavansa yhteisen kiinnostuksen ruusukataraan. Tämä johti yhteistyöhön.

Svoboda ja Irving tutkivat, miten vinkristiini vaikutti mikrotubulusten muodostumiseen ja solujen jakautumisprosessiin. Mikrotubulukset ovat tärkeitä monille solun toiminnoille, kuten jakautumiselle, aineiden kuljetukselle ja solun rakenteen ylläpidolle. Soluviljelmät saivat vinkristiiniä, mikä mahdollisti sen, että tutkijat pystyivät seuraamaan vinkristiinin vaikutuksia mikroskoopilla ja arvioimaan sen tehokkuutta solujen jakautumisen estämisessä.
Vinkristiini ja vinblastiini ovat myrkyllisiä hyönteisille ja kasvinsyöjille. Ne ovat indolialkaloideja, jotka estävät solunjakautumista ja voivat lamauttaa tai tappaa ruusukataran syöjät. Ihmisessä yhdisteiden vaikutus on toinen, niiden on todettu auttavan elimistöä taistelussa syöpäsoluja vastaan.
Suurin osa kasvipohjaisista syöpälääkkeistä kohdistuu tavalla tai toisella solun jakautumiseen. Tämä tekee niistä tehokkaita syövän torjunnassa. Koska syöpäsolut jakautuvat hallitsemattomasti, monet lääkkeet tähtäävät juuri jakaantumisprosessin estämiseen. Vinkristiini ja vinblastiini sekä Tyynenmeren marjakuusesta (Taxus brevifolia) saadun paklitakselin vaikutus kohdistuu mikrotubuluksiin eli solun tukirankaan. Tukiranka rakentuu tubuliini-nimisistä proteiineista, jotka muodostavat pitkiä säikeitä. Vinkristiini ja vinblastiini sitoutuvat tubuliinin ß-osaan ja estävät säikeiden muodostumisen, jolloin solut eivät pysty jakautumaan normaalisti. Kaikki kolme ainetta vaikuttavat mirotubulusten toimintaan mutta eri tavoin. Ne pysäyttävät solun jakautumisen metafaasivaiheeseen. Mikrotubuluksiin vaikuttaminen estää siis kasvaimen kasvua, mikäli syöpäsolujen rakenne muuttuu lääkkeen ansiosta epävakaaksi.
Vinkristiini on tyypillisesti tehokkaampi verisyövissä, kuten akuutin lymfaattisen leukemian hoidossa. Vinblastiini on parempi kiinteiden kasvainten hoidossa. Sitä käytetään Hodgkinin lymfooman, non-Hodgkinin lymfooman, rintasyövän ja kivessyövän hoidossa.
”On kiehtovaa, että kasvien ja hyönteisten keskinäisen selviytymisen prosessin myötä syntyneet molekyylit voivat vaikuttaa ihmisen biologisiin prosesseihin. Luonnossa kemiallinen aktiivinen rakenne ei ole sattumaa, mutta näiden harvinaisten molekyylien uusiokäyttö uuteen käyttötarkoitukseen kuten lääkkeeksi vaatii innovaation”, sanoo Suomen ELIXIR-keskuksen johtaja Tommi Nyrönen. Nyrönen on tutkinut lääkeaineita.
”Luonnonaineiden rakenteet, jotka voivat olla myrkyllisiä yhdelle lajille voivat oikein annosteltuna kuitenkin auttaa toista lajia kuten vinka-alkaloiden tapauksessa. Jännittävää on se, mitä emme vielä tiedä, koska emme vielä tunne kaikkia maapallon mikrobeja tai kasveja. Vastaavia löytöjä on mahdollista tehdä jatkossa keräämällä ja analysoimalla tutkimuksen tuottamaa molekyylitason dataa elävästä luonnosta.”

Tietoa vinka-alkaloideista löytyy monista tietokannoista. Esimerkiksi ChEMBL, BioStudies, UniProt ja Reactome tarjoavat tietoa farmakologisista ominaisuuksista, kohdeproteiineista (kuten tubuliini), mekanismeista ja solutason vaikutuksista.
”ELIXIR on elävän luonnon tiedon infrastruktuuri. Nämä tietokannat ovat osa ELIXIRin tietovarantoja, jotka ovat vapaassa käytössä niin tieteelle tutkimukselle, opetukselle kuin teollisuudelle”, sanoo Nyrönen.

ChEMBL (Chemical Database) on kemikaalitietokanta, joka keskittyy erityisesti lääkkeiden ja niiden kohdeproteiinien vuorovaikutukseen, ja sen avulla voidaan tarkastella lääkkeiden biologisia vaikutuksia ja farmakologisia profiileja. Tietokanta sisältää tietoa lääkeaineiden tehokkuudesta, turvallisuudesta ja muista biologisista vasteista.
Metabolian avulla keho muuntaa lääkkeen aktiivisia yhdisteitä vähemmän aktiivisiksi tai helposti poistettaviksi yhdisteiksi. Usein sytokromi P450 -entsyymit aiheuttavat nämä kemialliset muutokset. Lääkkeen metabolia vaikuttaa siihen, kuinka pitkään lääke vaikuttaa kehossa, kuinka nopeasti se poistuu ja kuinka tehokas se on. Jos lääkkeen metabolia on hidas, se voi jäädä elimistöön pidemmäksi aikaa, kun taas nopea metabolia heikentää lääkkeen vaikutuksen kestoa. Metaboliareitti voi vaihdella eri henkilöillä geneettisten tekijöiden, ympäristön ja muiden lääkkeiden mukaan. Siksi kahden eri henkilön vaste tiettyyn lääkkeeseen voi olla erilainen.
Bioassay (biologinen koe) tarkoittaa kokeellista menetelmää, jossa mitataan biologisen vasteen voimakkuus tai tehokkuus tietylle aineelle, kuten lääkkeelle, kemikaalille tai luonnontuotteelle. Tämä on erityisen tärkeää lääkkeiden kehityksessä, koska se antaa arvokasta tietoa siitä, miten aine vaikuttaa elimistössä.
Haku: Tietokannasta voi etsiä tiettyjä yhdisteitä ja niiden Bioassay-tuloksia sekä arvioida niiden vaikutuksia erityisesti sytotoksisuuteen tai reseptorivasteisiin. Tietokanta mainitsee vuorovaikutukset haetun aineen ja eri lääkeyhdisteiden välillä (drug matrix).
.
BioStudies-tietokanta tarjoaa keskitetyn paikan biologisten tutkimusten kuvausten tallentamiseen. Se sisältää linkkejä näiden tutkimusten dataan muissa tietokannoissa sekä dataa, joka ei sovi olemassa oleviin rakenteellisiin arkistoihin. Tämä mahdollistaa monenlaisten tutkimustyyppien tallentamisen yksinkertaisen formaatin avulla. ArrayExpress toimi yli 20 vuoden ajan funktionaalisen genomiikan tietokantana. Syyskuussa 2022 ArrayExpressin käyttöliittymä poistettiin käytöstä, ja kaikki data siirrettiin BioStudies-tietokantaan. Tämä muutos mahdollistaa datan paremman integroinnin ja saavutettavuuden tutkimusyhteisölle.
Haku: Jos tutkitaan esimerkiksi vinkristiinin vaikutusta syöpäsolujen kasvuun, BioStudies voi sisältää koeasetelmia, analyysimenetelmiä ja tuloksia, jotka auttavat tulkinnassa.

Lääkkeellä, kuten vinblastiinilla, voi olla useita kohdeproteiineja, jotka se voi aktivoida, estää tai modifioida sen biologisten vaikutusten saavuttamiseksi. Lääkkeen kohdeproteiinit voivat liittyä useisiin biologisiin prosesseihin ja solukalvoihin eri elinjärjestelmissä, ja niiden määrä voi vaihdella lääkkeen rakenteen ja toiminnan mukaan.
UniProt (Universal Protein Resource) on maailman johtava korkealaatuinen, kattava ja vapaasti saatavilla oleva proteiinisekvenssien ja -toimintojen tietokanta, jota ylläpitää UniProt-konsortio. UniProt tarjoaa laajan ja yksityiskohtaisen tietopaketin proteiinien rakenteesta, toiminnasta, vuorovaikutuksista, geneettisistä taustoista ja sairauksista. Tietokanta on erityisen hyödyllinen lääkekehityksessä ja lääkeaineiden vaikutusmekanismien ymmärtämisessä, koska se auttaa kartoittamaan, miten lääkkeet vaikuttavat proteiinien toimintaan.
UniProt sisältää proteiinien aminohapposekvenssejä (sekvenssejä, jotka määrittävät proteiinien rakenteen). Se voi sisältää tietoa siitä, miten proteiinit ovat kehittyneet ja miten ne eroavat toisistaan eri lajeilla. Tietokanta linkittyy proteiinien kolmiulotteisten rakenteiden tietokantaan PDB:hen, joka auttaa ymmärtämään niiden toimintamekanismeja ja vuorovaikutuksia muiden molekyylien kanssa. UniProt tarjoaa tietoa siitä, mitä tapahtuu, jos lääkeaineen tiedetään sitoutuvan proteiineihin ja vaikuttavan niiden toimintaan. Tällöin voidaan löytää tietoa siitä, miten lääkkeet muuttavat proteiinien toiminnan ja miten proteiinit voivat muuttaa lääkkeiden tehokkuutta. UniProt tarjoaa tietoa myös siitä, mistä geeneistä proteiinit syntyvät, kuinka geenejä säädellään ja miten geneettiset muutokset (esimerkiksi mutaatioiden kautta) voivat vaikuttaa proteiinien toimintaan ja aiheuttaa sairauksia.
Haku: Tietokannan avulla voi tutkia tubuliiniproteiinien vuorovaikutuksia vinkristiinin kanssa ja sen vaikutusta solujen jakautumiseen.

Tietokanta sisältää solutason tapahtumia ja signalointireittejä. Se on käsintarkistettu tietokanta, joka tarjoaa tietoa solujen ja elinten toiminnan biokemiallisista reaktioista. Näihin kuuluvat proteiinien, RNA:n ja muiden biomolekyylien vuorovaikutukset, kuten signalointireitit, metaboliareitit ja geeniekspressio.
Se tarjoaa myös tietoa, miten tiettyjen elimistön biologisten reaktioiden häiriöt voivat johtaa sairauksiin. Tämä voi olla hyödyllistä lääkekehityksessä ja biomarkkerien etsinnässä. Reactome tarjoaa visuaalisia reittikarttoja, joissa on kuvattu eri biologisia reittejä ja niiden molekyylitason vuorovaikutukset. Esimerkiksi vinkristiinin vaikutus voidaan liittää tiettyihin reitteihin, kuten solun jakautumisen säätelyyn ja apoptoosiin (solukuolema).
Haku: Tietokannan avulla voidaan selvittää, miten vinkristiini vaikuttaa eri signalointireitteihin ja miten sen vaikutus ilmenee koko solussa.
27.3.2025
Lue artikkeli PDF-muodossa
Lisätietoja:
ELIXIR Core Data Resources
https://elixir-europe.org/platforms/data/core-data-resources
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Suomalaisten näytekokoelmat ovat merkittäviä tutkittaessa sairauksien perinnöllisiä syitä. SISu-projektin ansiosta tiedot suomalaisten geneettisestä vaihtelusta on koottu yhteen tietokantaan. Sisuproject.fi -sivustolta löytyvä avoin tieto geeniperimästä on maailmanlaajuisestikin ainutlaatuinen.
Pitkän tähtäimen tavoitteena on luoda mittava tietovaranto, joka sisältää genomitiedon lisäksi anonyymiä tietoa osallistujien terveystiedoista. Hyödyntämällä tätä tietoa lääkärit voivat saada tarkempaa tietoa potilaan sairastumisriskeistä vertaamalla hänen genomi- ja terveystietojaan SISu-tietovarantoon perustuvaan tietoon.
SISu (Sequencing Initiative Suomi) on tietokanta suomalaisten perimästä. Tutkijoiden ja lääkäreiden vapaasti käytettävissä on nyt ensimmäinen versio, joka sisältää tiedon 3325 suomalaisen geenimerkeistä (www.sisuproject.fi). Jo 9000 suomalaisen perimä on luettu läpi ja kymmenientuhansien perimät luetaan lähivuosina. Tietokantaan viedään 30 000 suomalaisen geenitiedot ja 30 miljoonaa geenimerkkiä. Laajempi tietokanta palvelee paremmin potilaita ja heitä hoitavia lääkäreitä sekä tutkijoita, jotka tutkivat sairauksien alttiustekijöitä ja etsivät uusia hoitokeinoja. Lisäksi suomalainen geenitieto säilyy Suomessa.
eSISu-projekti (e-Infrastructure for Sequencing Initiative Suomi) taltioi tietoturvallisesti suomalaisen geneettisen perimän yksityiskohdat eli geenivariaatiot. Variaatioita analysoimalla saadaan selville uutta tietoa perinnöllisistä sairauksista. Lue artikkeli projektista täältä.

Kaikki ELIXIR Euroopan tarjoamat datakokoelmat:
https://www.elixir-europe.org/services/database

Helsingin yliopiston farmakogenetiikan professori Mikko Niemi tutkii geenien vaikutusta lääkkeiden tehoon ja turvallisuuteen. Vastikään julkaistussa tutkimuksessa analysoitiin 1,4 miljoonan suomalaisen potilaan lääkityksiä ja saatiin selville, että neljäsosa potilaista sai lääkehoitoa, jonka tehoa tai turvallisuutta olisi voitu parantaa huomioimalla potilaan perimä. Tutkimuksessa hyödynnettiin THL:n rekistereitä ja biopankkien dataa.
Ihmiset reagoivat lääkkeisiin eri tavoin, osalle lääkehoidon teho jää puutteelliseksi ja osalle se aiheuttaa haittavaikutuksia. Syynä poikkeavaan vasteeseen voivat olla fyysiset ominaisuutemme, muu lääkitys ja geneettinen perimämme. Jos potilaiden perimästä saatu tieto olisi lääkäreiden saatavilla, lääkekulut ja merkittävät haittavaikutukset usein vähentyisivät. Myös sairauspäivien määrä vähenisi.
Viimeisen viiden vuoden aikana geenitestaus terveydenhuollossa on lisääntynyt.
”Tutkimusnäyttöä alkaa olla paljon. Nyt on varmaankin löydetty keskeiset geenit lääkevasteelle. Monet ovat sellaisia, jotka säätelevät lääkkeiden määrää elimistössä. Usein yksi geeni vaikuttaa moneen erityyppiseen lääkkeeseen,” sanoo Mikko Niemi.

Viime vuosina on kehitetty erilaisia geenipaneeleja, joilla voi analysoida useita geenejä samanaikaisesti. Tätä voi pitää terveydenhuollossa läpimurtona. Potilaan verestä, syljestä tai kudoksesta eristetään DNA. Massiivinen rinnakkaissekvensointi mahdollistaa monien geenien samanaikaisen kohdennetun tutkimisen. Paneeleita voidaan suunnitella tunnistamaan geneettisiä variaatioita, jotka vaikuttavat esimerkiksi sairastumisriskiin, lääkevasteeseen tai tiettyjen perinnöllisten sairauksien esiintymiseen.
Farmakogeneettisten laboratoriotutkimusten käytössä tapahtui edistys vuonna 2020 Euroopan lääkeviraston (EMA) myötä.
”Tuolloin virasto antoi fluoropyrimidiini-syöpälääkkeisiin liittyvän suosituksen testata perinnöllinen DPYD-puutos ennen lääkityksen aloittamista. Näin voidaan ehkäistä kyseisten syöpälääkkeiden aiheuttamia vakavia haittavaikutuksia. Testaus on ollut rutiinia viraston suosituksesta lähtien.”
Farmakogeneettiset paneelit käsittävät tavallisesti 10-20 geeniä.
”Ihmisillä on 20 000 geeniä. 10-20 geenin vaikutukset lääkehoitoihin tunnetaan hyvin. Ne ovat keskeisiä lääkevaikutukselle”, sanoo Niemi.
HUS:n farmakogeneettinen geenipaneeli kattaa 12 yleisintä ja kliinisesti merkittävintä lääkehoitoihin vaikuttavaa geeniä. Näiden valinnassa on otettu huomioon kansainväliset hoitosuositukset, lääkkeiden valmisteyhteenvedot ja geenimuunnosten esiintyvyydet eri väestöissä. Testin tulos näkyy OmaKannassa (https://www.kanta.fi/omakanta), nimikkeellä B -PGx-D, Farmakogeneettinen paneeli. OmaKanta on kansalaisten verkkopalvelu, jossa voit nähdä reseptit, tutkimustulokset sekä hoitoon liittyvät kirjaukset.
”Paneelissa on ideana se, että kun yhden lääkkeen sopivuutta testataan, niin potilaalla on tulevaisuutta ajatellen myös moniin muihin lääkkeisiin liittyvät geneettiset tekijät jo valmiiksi testattuina.”
Niemen mukaan testauksen parannuttua tiedossa on nyt enemmän sellaisia lääkkeitä, joihin geeneillä on merkitystä. Tämän ansiosta esimerkiksi syöpäsairauksien lääkehoito on parantunut. Myös psykiatriassa geenitiedon käyttö on yleistynyt.
”Meillä alkaa olla hyvää tutkimusnäyttöä farmakogenetiikan hyödyistä masennuksen hoidossa. Geenitestaus on päätynyt masennuksen Käypä-hoito suositukseen.”
Käypä hoito -suositus on suomalaisen lääkäriseura Duodecimin julkaisema asiantuntijayhteenveto yksittäisen sairauden diagnostiikasta ja hoidon vaikuttavuudesta.

Yksittäisten lääkeaineiden annostarve saattaa vaihdella eri yksilöillä jopa yli 10-kertaisesti. Se voi johtua siitä, miten nopeasti tai hitaasti lääkeaine poistuu elimistöstä. Sytokromi-entsyymit (CYP) ovat keskeisiä lääkkeiden pilkkomisessa ja poistamisessa elimistöstä. CYP-entsyymien aktiivisuuden geneettinen vaihtelu on suurta. Vaihtelu voi johtaa eri lääkeaineen pitoisuuksien ja vasteiden moninkertaisiin eroihin eri yksilöissä.
Toistaiseksi on vain vähän tietoa siitä, kuinka hyödyllisiä ja kustannustehokkaita farmakogeneettiset testit olisivat, jos kaikkien sairaalapotilaiden geneettinen tausta selvitettäisiin. Mikko Niemen johtamassa tutkimuksessa tehtiin maanlaajuinen analyysi, jossa olivat mukana kaikki sisätautien ja kirurgisella osastolla olleet sairaalapotilaat Suomessa. Lisäksi mukana oli yliopistosairaalan potilaita, joista oli saatavilla geenitietoa THL:n biopankista. Biopankkiin on tallennettu FINRISKI-aineistoa, joka sisältää poikkeuksellisen paljon monipuolista dataa suomalaisen väestön terveydestä, kuten laboratoriomittauksia ja terveysrekisteritietoja.
Maanlaajuisessa kohortissa oli 1,4 miljoonan suomalaisen tiedot, jotka oli saatu THL:n hallinnoimista rekistereistä. Kaksi vuotta sairaalahoidon jälkeen 60% potilaista oli ostanut apteekista jotakin sellaista reseptilääkettä, johon geenitiedolla on merkitystä.
”Seurasimme sellaisten lääkkeiden ostoja, joista tiesimme, että genetiikka vaikuttaa lääkkeen sopivuuteen. Kun analysoimme geenimuunnokset, tiedämme nyt varmasti, että 99 % suomalaisista on johonkin lääkkeeseen kliinisesti merkittävästi vaikuttava geneettinen muoto jossakin geenissä.”
Yliopistosairaalan otoksessa oli 1000 potilasta, joiden geneettinen tieto oli biopankista saatavissa. 40% potilaista sai sairaalassa ollessaan jotakin sellaista lääkettä, jonka käytössä geenitesteillä voi olla hyötyä. Neljäsosalla oli sellainen geenin ja lääkkeen yhdistelmä, joita tutkijat eivät suosittele: lääkettä tulisi käyttää eri annoksella tai olisi hyvä valita kokonaan toinen lääke.
”Geneettinen vaihtelu on yleistä ja vaikuttaa yleisesti käytettyihin lääkkeisiin”, kiteyttää Niemi tutkimuksen tulokset.
Niemen mukaan geenitiedosta voisi olla suurta hyötyä lääkehoidossa.
”Tutkimusnäytön perusteella moni potilas voisi hyötyä lääkehoidon muuttamisesta geenitiedon perusteella.”
Hyödyt ovat myös yhteiskunnalle suuret. Suomessa on hyvä rekistereiden ja genomidatan hallinnointi. Farmakogeneettisten paneelien käytössä Suomi on edelläkävijä.
”Jatkossa on tarkoitus arvioida farmakogeneettisen paneelitutkimuksen taloudellista ja terveydellistä hyötyä. Tarkoitus on selvittää farmakogeneettisesti testattujen suomalaisten potilaiden hoidon kustannuksia ja verrata tätä tilanteeseen missä geenitestejä ei ole käytetty. Jos esimerkiksi voitaisiin tunnistaa se kymmenesosa potilaista, jotka eniten hyötyvät geenitiedosta, säästettäisiin terveydenhuollon kustannuksissa, lääkkeissä ja sairaspoissaoloissa.”
Mikko Niemen tutkimusryhmä on käyttänyt Suomen ELIXIR-keskuksen CSC:n laskentapalveluja geenidatan analysoimiseen. Datan hallinnassa on käytetty CSC:n sensitiivisen datan alustaa.
Vuonna 2022 käynnistettyä genomidatan infrastruktuurin GDI:n (Genomic Data Infrastructure) tarkoituksena on luoda federoitu infrastruktuuri, joka mahdollistaa tutkijoille pääsyn eurooppalaisista kerättyyn genomidataan sekä kliiniseen dataan.
Tulevaisuudessa eurooppalaisia odottavat entistä nopeammat ja tarkemmat diagnoosit. Kerätty ja analysoitu genomidata mahdollistaa paremman lääkeainesuunnittelun ja ennaltaehkäisevät lääkehoidot.
Mikko Niemen mielestä on keskeistä, että tutkijoilla on tällainen infrastruktuuri käytössä.
”Laadukkaasti tallennettu genomidata on olennainen tulevaisuuden tutkimukselle. Se varmistaa, että pystytään löytämään uusia lääkehoidon tehoon ja turvallisuuteen vaikuttavia geneettisiä tekijöitä, arvioimaan niiden vaikutusta ja merkitystä ja saamaan ne lopulta käyttöön.”
GDI mahdollistaa retrospektiivisen tutkimuksen, kuten kustannus-hyötyanalyysin eurooppalaisissa laajoissa väestötutkimuksissa, kuten Niemi on kuvannut.
”Yhdistämällä geneettisiä tietoja sairaus- ja hoitotietoihin GDI auttaa tutkijoita tunnistamaan erityisiä hoitoja ja geneettisiä variaatioita sisältäviä potilasryhmiä eri puolilta Eurooppaa. Tämä kasvattaa kohorttien kokoa ja tukee uusien geneettisten vaikutusten löytämistä lääkehoitoon”, kertoo CSC:n vanhempi koordinaattori Dylan Spalding, joka on GDI:n työpaketti 5:n toinen vetäjä.
”Lääkäreille, joilla on potilas, joka ei reagoi lääkitykseen odotetusti, GDI tarjoaa mahdollisuuden löytää kollegoita muista Euroopan maista, joilla voi olla samankaltaisia potilaita. Näin he voivat hyödyntää toisten kokemuksia tehokkaammista hoitomuodoista ja parantaa potilaidensa hoitoa.”
Ari Turunen
6.2.2025
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2025). Genetic testing improves medication safety and effectiveness. https://doi.org/10.5281/zenodo.14823385
Lisätietoja:
Value of Pharmacogenetic Testing Assessed with Real-World Drug Utilization and Genotype Data
Kaisa Litonius, Noora Kulla, Petra Falkenbach, Kati Kristiansson, Katriina Tarkiainen, Liisa Ukkola-Vuoti, Mari Korhonen, Sofia Khan, Johanna Sistonen, Arto Orpana, Mats Lindstedt, Tommi Nyrönen, Markus Perola, Miia Turpeinen, Ville Kytö, Aleksi Tornio, Mikko Niemi
https://ascpt.onlinelibrary.wiley.com/doi/full/10.1002/cpt.3458
DOI: 10.1002/cpt.3458
Tutkimusta oli rahoittamassa Suomen Akatemia ja Sosiaali- ja terveysministeriö. Farmakogenetiikan pilottia olivat mukana suunnittelemassa ja toteuttamassa Helsingin yliopiston ja HUSin Kaisa Litonius, Mikko Niemi ja Katriina Tarkiainen, Turun yliopiston ja TYKSin Noora Kulla, Aleksi Tornio, Kristiina Cajanus ja Ville Kytö, Oulun yliopiston Petra Falkenbach ja Miia Turpeinen, THL:n Markus Perola, Kati Kristiansson ja Liisa Ukkola-Vuoti, HUS:n Arto Orpana, Mari Korhonen, Johanna Sistonen ja Sofia Khan sekä CSC:n Tommi Nyrönen ja Mats Lindstedt.
HUS
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Jokainen ELIXIRin jäsenmaa toimii osakeskuksena. Osakeskus on jäsenmaan sisällä toimivien organisaatioiden verkosto. Osakeskusta johtaa organisaatio, joka koordinoi paikallisia ELIXIR-toimintoja. CSC – Tieteen tietotekniikan keskus isännöi ja operoi ELIXIRiin kuuluvia resursseja ja palveluita, kuten yleiseurooppalaista ELIXIR-identiteetti- ja pääsyinfrastruktuuria. ELIXIR Suomen palveluita kehitetään osana eurooppalaista e-infrastruktuuria (esim. EuroHPC/LUMI, GAIA-X, EOSC, GEANT, NeIC).
ELIXIR Suomi lisää valmiuksia tehdä terveys- ja biotieteiden alan tutkimusta. Yhdistämme ELIXIRin biopankkien datanhallintaan ja koulutukseen sekä valtakunnalliseen bioinformatiikkaverkostoon (https://www.biocenter.fi/) Suomessa. Biopankkien Osuuskunta Suomi – FINBB kehittää Suomen terveys- ja biolääketieteellisen tutkimuksen kilpailukykyä tuomalla Suomen biopankkien ja niiden taustaorganisaatioiden tietovarannot tutkijoiden saataville. ELIXIR Suomi on vuodesta 2012 lähtien tehnyt aktiivista yhteistyötä Terveyden ja hyvinvoinnin laitoksen (THL) ja Helsingin yliopiston/Suomen molekyylilääketieteeninstituutti (FIMM) kanssa, joka operoi BBMRI– ja EATRIS osakeskuksia.
Tieteen ja tutkijoiden sivusto Fingenious.fi on valittu STM:n ja THL:n toimesta Suomen yhteiseksi brändiksi biolääketieteellisen tutkimuksen lisäämiseksi maassamme erityisesti toisiolain alla tapahtuvassa tutkimustoiminnassa.
CSC on solminut puitesopimuksen kaikkien suomalaisten korkeakoulujen ja tutkimuslaitosten kanssa.
CSC:n tutkimuspalveluiden kehitys edistää ELIXIR Suomen strategiaa. On tärkeää varmistaa Suomen datainfrastruktuurin yhteentoimivuus eurooppalaisten dataympäristöjen kanssa, jota työtä tehdään mm. European Health Data Spacen (EHDS) puitteissa.
ELIXIR Suomi on tiiviisti mukana mm. seuraavissa kansainvälisissä hankkeissa ja aloitteissa:
Lisäksi ELIXIR Suomi osallistuu suuriin julkisen ja yksityisen sektorin kumppanuuksiin, kuten Innovative Medicines Initiative (IMI2) BIGPICTURE-projektiin (2021-27), joka rakentaa laajaa digitaalista patologiakuvavarastoa.
Esimerkkejä ELIXIR Suomen rahoittajista, yhteistyökumppaneista sekä hankkeista:









Turun yliopiston biolääketieteen laitoksen apulaisprofessori Pekka Ruusuvuori johtaa ComPatAI-konsortiota, jossa kehitetään histopatologisten kudosnäytteiden mallinnusta uutta sisältöä luovien ja ennustavien tekoälymenetelmien avulla. Histologisen eli kudosopillisen näytteen perusteella arvioidaan, tarvitseeko potilas hoitoa. Tavoitteena on kehittää erittäin suuriin data-aineistoihin perustuvia tekoälymalleja, joiden avulla saadaan entistä tarkempaa patologian diagnostiikkaa.
CompPatAI-konsortiossa on lisäksi kehitteillä generatiiviseen tekoälyyn perustuvia kudoksen virtuaalivärjäysmalleja. Konsortion muut osapuolet ovat tutkimusjohtaja, dosentti Leena Latonen Itä-Suomen yliopistosta sekä patologian osaston ylilääkäri, dosentti Teemu Tolonen Fimlab-laboratorioista.
ComPatAI-konsortioissa analysoidaan ensisijaisesti rintasyöpään ja eturauhassyöpään liittyviä kudosleikekuvia. Digitoitu kuva antaa mahdollisuuden mittauksiin ja erilaisten solutyyppien automaattiseen laskentaan.
”Olemme toimineet eturauhassyövän ja rintasyövän parissa. Näistä on ollut dataa tarjolla, koska ne ovat kaikkein yleisimmät syöpätyypit naisilla ja miehillä. Tavoitteena on kuitenkin, että meillä olisi hyvin yleiskäyttöinen malli, jonka päälle voitaisiin rakentaa ratkaisuja erilaisiin ja uusiin käyttökohteisiin.”
Ruusuvuoren mukaan digitalisaatio on tapahtumassa patologiassa nyt ja Suomi on tietyssä mielessä edelläkävijä.
”Tampereella ja Turussa on siirrytty kokonaan digitaaliseen patologiaan diagnostiikassa. Joka kerta kun näyte otetaan, se skannataan korkearesoluutioiseksi digitaalikuvaksi. Rutiinidiagnostiikkaa tehdään paljon. Koska väestö ikääntyy, syöpätapaukset ovat nousussa. Dataa saadaan koko ajan kovalla tahdilla.”
Skannatut kokolasikuvat saadaan tutkimukseen Fimlabista, joka on Suomen suurin terveydenhuollon laboratorioyhtiö. Sen asiakkaita ovat sairaalat, terveyskeskukset, työterveyshuolto ja yksityiset lääkäriasemat. Lääkealan turvallisuus- ja kehittämiskeskus Fimean lupa käsittää tällä hetkellä 160 050 tapausta eli noin 600 000 kokoleikekuvaa. Koko on yhteensä noin 0,8 petatavua, jolloin yhden tiedoston koko on noin 1,3 GB. Massiivista datamäärää siirretään parhaillaan anonymisoinnin jälkeen Suomen ELIXIR-keskuksen CSC:n LUMI- supertietokoneelle. Se on suurimpia koneelle tehtyjä datan siirtoja.
”Se, että saamme hyödyntää näitä aineistoja tutkimuskäytössä, on valtavan hieno juttu. Tarkoitus on käyttää tätä isoa datamassaa siihen, että pystyttäisiin tekemään mahdollisimman hyvin toimivia tekoälyratkaisuja patologien käyttöön”, sanoo Ruusuvuori.
Tavoitteena on, että projektin lopussa tutkijoiden käytössä olisi jopa 2,5 miljoonaa digitoitua kokoleikekuvaa, jolloin dataa olisi kolme petatavua.
”Meillä on lupateknisesti mahdollisuus käyttää kaikkea sitä dataa mitä rutiinisti Fimlabilla tuotetaan digipatologiassa.”’

Pekka Ruusuvuoren tausta on signaalinkäsittelyssä ja hänen erityisosaamisalueensa on kuva-analyysi. Hän on kiinnostunut siitä, miten tekoälymenetelmissä hyödynnetyistä syvistä neuroverkoista voitaisiin kehittää kohti paremmin erilaisiin käyttötarkoituksiin yleistyviä.
Ruusuvuoren mukaan lähtökohtaisesti kone voidaan opettaa tunnistamaan samoja asioita kuin ihminen. Se voidaan opettaa tunnistamaan erilaisia kudostyyppejä ja erottamaan syöpäkudos terveestä kudoksesta. Se voi mitata solusta tai kuvista erilaisia asioita, kuten kuinka aggressiivinen syöpä on ja kuinka pitkälle se on edistynyt. Tekoäly voi tehdä erottelua ja löytää kudosnäytteestä syöpäalueet ennen kuin patologi alkaa tutkia näytettä. Se voi myös ehdottaa luokitusta. Esimerkiksi eturauhasen syöpäkasvaimesta annetaan ns. Gleason-luokitus, joka kertoo miten aggressiivinen tai edennyt tauti on.
”Tekoälylle on opetettavissa melko tarkasti siis sellaiset tehtävät mitä patologit tekevät”, Ruusuvuori toteaa.
”Perinteisesti koneoppimismenetelmät on rakennettu niin, että meillä on joku kohdemuuttuja ja opetusaineisto, jossa näytetään, että tässä kohtaa tätä kuvaa on tämä objekti ja se kuvaa tätä luokkaa. Sehän on hirveän työlästä, jos meidän pitäisi merkitä kaikkiin satoihin tuhansiin kuviin tätä tietoa.”
Nämä ns. annotaatiotiedot ovat olleet olennaisia, jotta on voitu opettaa tekoälyä automaattisesti tunnistamaan näytteistä esimerkiksi syöpäsolut. Ruusuvuoren mukaan algoritmit ovat kuitenkin kehittyneet siihen suuntaan, että ne pystyvät hyödyntämään raakadataa ilman annotointeja.
”Mielestäni kaikkein kiinnostavinta onkin se, mitä kaikkea muuta kuvista on irrotettavissa eli ominaisuuksia, mitkä eivät välttämättä ole itsestään selvästi ihmisen havaittavissa. Ainoa data mitä on nähtävillä, on leikekuvassa. Jos siinä on joku tilastollinen yhteys osoitettavissa, koneoppimisalgoritmi sen löytää – mutta ne yhteydet saattavat olla hyvin kompleksisia. Nykyaikaiset neuroverkot ovat erittäin tarkkoja havaitsemaan kompleksisia yhteyksiä spatiaalisen datan ja ennustettavan muuttujan välillä. Ne voivat olla hyvin vaikeita hahmottaa meille ihmisille.”
Ruusuvuori on tutkimusryhmänsä kanssa pystynyt koneoppimismallien avulla ennustamaan geeniekspressiota ja mutaatioita suoraan histologisista kuvista. Geenin eskpressio eli ilmentyminen tarkoittaa, että solu tuottaa DNA:n koodaamaa molekyyliä. Geenien ekspressio on erilainen eri kudoksissa. Tekoäly voi havaita kuvasta ihmissilmälle näkymättömiä pieniä muutoksia.
”Kuvissa koneelle on siis näkyvissä jotain, mitä geeniekspressio aiheuttaa soluissa ja kudoksissa. Kone pystyy havaitsemaan erittäin pienenkin eron muuttuneessa ilmiasussa. Kone havaitsee sen, mitä ihmissilmä ei ole harjaantunut näkemään. Korostan, että tämä on hyvin suuntaa antavaa ja ei toki toimi kaikille kudoksille tai geeneille. Kaikkien geenien ekspressoituminen ei johda muutoksiin kudostasolla sillä tavoin, että se on ennustettavissa kudosleikekuvasta. ”
ComPatAI-konsortio kehittää suurten datamassojen hyödyntämiseen ns. foundation-mallia. Foundation-malli luo yleiskäyttöisen perustan erilaisille tekoälyratkaisuille oppien histologiaa suuresta näytemäärästä ilman kohdemuuttujia tai annotointeja.

”Kun tälle mallille aletaan opettaa vaikkapa rintasyövän tai eturauhassyövän tunnistusta, malli alkaa oppimaan pyydettyä tehtävää. Näin pääsemme paljon nopeammin tarkempiin ratkaisuihin. Pystymme hyödyntämään mittavaa data-aineistoa, vaikka meillä ei olisi annotointeja. Se on hieno esitysaskel.”
ComPatAI-konsortio luo omaa foundation-tekoälymallia suomalaiseen dataan perustuen.
”Tämä on perustutkimusta, joka mahdollistaa sen, että olemme ensimmäisten joukossa kehittämässä tähän maahan näitä malleja. Toivon, että emme olisi pelkästään isojen ulkomaisten firmojen ja tutkimusryhmien varassa vaan että meillä rakennettaisiin suomalaiseen dataan perustuvaa mallia. Meillä on tässä maassa laadukasta populaatiotason kohorttidataa, jota pitää päästä hyödyntämään. Toivon, että se johtaa siihen, että saadaan Suomeen yrityksiä, joiden kehittämät ratkaisut viedään potilaan hyödyksi rutiinidiagnostiikkaan.”
Tärkeä kysymys on, kuinka nopeasti dataa pystytään siirtämään ja hyödyntämään. Laskentaa ja datan tallennuskapasiteettia tarvitaan koko ajan. Tähän tulevat apuun Suomen ELIXIR-keskuksen CSC:n tarjoamat palvelut.
”Olemme erittäin tyytyväisiä CSC:ltä saamaamme tukeen, kun puhutaan näin poikkeuksellisen isosta hankkeesta ja datamäärästä. Olemme etuoikeutetussa asemassa, koska meillä on apuna CSC:n tapainen toimija, jolta voimme saada resursseja tällaiseen tutkimukseen. Se on selvästi kilpailuetu ja sellainen asia, mistä voi olla valtavan kiitollinen.”

Digipatologian ja muiden potentiaalistesti sensitiivisten terveysdatan datatyyppien kuten rekisteri- ja omiikkatietovarantojen saatavuus tietoturvallisessa CSC:n käyttöympäristössä kasvaa tulevaisuudessa.
”Kehitys on vasta alussa”, sanoo Tommi Nyrönen, joka on Suomen ELIXIR-toimintojen johtaja.
”Suomen ELIXIR on edistänyt CompPatAI-tutkimuksen edellyttämien biolääketieteellisten resurssien muuttamista CSC:n alustapalveluksi. Työn tuloksena syntynyt CSC Sensitive Data-alusta tukee muitakin vastaavia hankkeita. Tällainen on esimerkiksi EU:n digipatologian arkiston rakennushanke bigpicture.eu, joka suunnitelman mukaan alkaa vuonna 2026 tarjota kestävää ratkaisua hallita ja tuoda digipatologian data-aineistoja suurteholaskentapalveluihin Euroopan laajuisesti.”
Ari Turunen
26.12.2024
Lue artikkeli PDF-muodossa.
Sitaatti
Turunen, A., & Nyrönen, T. (2024). The ComPatAI consortium uses large datasets to create an AI learning model for pathology. https://doi.org/10.5281/zenodo.14823370
Lisätietoja:
FIRI
Suomen Akatemia on tukenut artikkelin tuotantoa apurahalla numerolla 345591, joka on myönnetty FIRI 2021-hankkeelle ”ELIXIR European Life-Sciences Infrastructure for Biological Information”.
Ruusuvuorilab
Fimlab
Turun yliopisto
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Mikael Niku tutkii sikiöitä ja minkälaiseksi bakteeristo muodostuu syntymän jälkeen. Häntä kiinnostaa, miten äidin tai emon mikrobisto eri nisäkkäillä vaikuttaa sikiön kehittymiseen ja immuunijärjestelmään.
Pitkään on tiedetty, että syntymän jälkeen äidin mikrobit siirtyvät jälkeläiseen. Tämä siirtyminen valmistaa lasta syntymänjälkeiseen elämään.
”Emon mikrobisto vaikuttaa myös immuunijärjestelmän kehitykseen. Immuunijärjestelmä oppii hyväksymään hyödylliset suolistomikrobit ja toisaalta torjumaan taudinaiheuttajat. Monimuotoinen mikrobisto estää itsessäänkin taudinaiheuttajia asettumaan taloksi,” sanoo dosentti Mikael Niku, joka työskentelee Helsingin yliopiston Vuorovaikutukset yksilönkehityksessä (Developmental Interaction Lab)-tutkimusryhmässä.

Niku haluaa selvittää, millaisilla mekanismeilla äidin tai emän mikrobit ohjaavat immuunijärjestelmän kehitystä. Data-analyysejä tehdään Suomen ELIXIR-keskuksen CSC:n koneilla.
Niku analysoi mikrobistoja amplikonisekvensoinnilla, joka kohdentaa analyysin 16S-ribosomaalisen RNA:n (rRNA) geenialueelle. Näin voidaan tutkia mikrobiston koostumusta. 16S-geenialueet sekvensoidaan ja tunnistetaan julkisten tietokantojen kautta.
Suolistossa on iso osa kehon immuunisoluista. Ne kehittyvät verikantasoluista ja muuttuvat erilaisiksi valkosoluiksi. Ruokavalio, elämäntyyli, lääkkeet ja ympäristön kemikaalit vaikuttavat suoliston mikrobistoon. Mikrobit hajottavat elimistöön imeytyneet aineet aineenvaihduntatuotteiksi, metaboliiteiksi.
”Aikaisemmin me muiden tutkimusryhmien tavoin selvitimme, meneekö sikiöön äidin bakteereita. Terveessä sikiössä ei juurikaan ole eläviä bakteereita. Tiedetään kuitenkin, että sikiöön kulkeutuu mikrobien tuottamia pienimolekyylisiä metaboliitteja.”
Nikua kiinnostaa, minkälaisia metaboliitteja sikiöön kulkeutuu ja miten ne vaikuttavat kehitykseen.
”Mikrobien tuottamat metaboliitit imeytyvät suolistosta vereen ja veren kautta istukkaan ja sieltä sikiöön. Havaitsimme, että joidenkin metaboliittien pitoisuudet ovat yhteydessä sikiön geenien toimintaan. Nämä geenit usein liittyvät immuunijärjestelmään ja sen kehittymiseen.”
Yhtenä mielenkiinnon kohteena ovat bakteerien tuottamat solunulkoiset vesikkelit. Vesikkelit ovat solujen tuottamia kalvorakkuloita, joita tuottavat sekä eläin- että bakteerisolut. Niitä löytyy kaikista kehon nesteistä. Vesikkelit löydettiin jo 1946, mutta vasta 2000-luvulla tutkimus lisääntyi. Vesikkelit sisältävät monenlaisia solujen tuotteita.

”Vesikkelit ovat mahdollisesti tärkeitä mm. materiaalien kierrätyksessä, solujen välisessä viestinnässä, immuunijärjestelmän säätelyssä ja erilaisissa sairauksissa.”
Oulun yliopiston tutkijat julkaisivat ensimmäisen tutkimuksen maailmassa, jossa osoitettiin, että äidin tai emon mikrobiston vesikkeleitä menee sikiöön. Löydettiin aiemmin tuntematon vuorovaikutusmekanismi äidin mikrobiston ja kehittyvän sikiön välillä.
Nikua kiinnostaa sikiön immuunijärjestelmän kehitys ennen syntymää. Oppiiko sikiön immuunijärjestelmä jo silloin tunnistamaan hyviä bakteereita, joita vastaan ei pidä hyökätä?
”Vesikkeleiden mukana sikiöön pääsisi bakteerien makromolekyylejä, esimerkiksi proteiineja, jotka mahdollisesti kouluttaisivat sikiön immuunijärjestelmää. Näin jälkeläinen, jo ennen syntymäänsä, voisi oppia tuntemaan äitinsä tai lajinsa suolistomikrobit.”
Seuraavaksi Niku selvittää, millä tavoin vesikkeleitä esiintyy sikiön kudoksissa ja miten ne pääsevät istukasta läpi ja miten ne vaikuttavat sikiössä.
Nikun mukaan voidaan ennen pitkää sitten sanoa, minkälaisia bakteereja ja bakteerien tuotteita sikiö tarvitsee, jotta immuunijärjestelmä kehittyisi optimaalisesti.
”Voitaisiin ehkä kehittää esimerkiksi sellaisia probioottivalmisteita, joissa on elimistölle tarpeellisia mikrobeja tai mikrobien tuottamia aineita, joita ei nyt ole saatavilla.”
Ari Turunen
14.11.2024
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). Microbiota affects the immune system. https://doi.org/10.5281/zenodo.14823362
Lisätietoja:
Helsingin yliopisto. Vuorovaikutukset yksilönkehityksessä-tutkimusryhmä
https://www.helsinki.fi/en/researchgroups/developmental-interactions
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Ihon mikro-organismeilla on suoliston tavoin merkittävä rooli kehon immuunijärjestelmän parantamisessa. Helsingin yliopiston yhteisöekologi Mira Grönroos tutkii elinympäristön, mikrobiyhteisöjen ja ihmisen terveyden välisiä yhteyksiä. Hän on kiinnostunut millä tavalla metsässä oleskelu ja erilaiset kontaktit luontoon vaikuttavat ihon mikrobistoon. Tavoitteena on löytää ratkaisuja ihmisen immuunipuolustuksen toiminnan parantamiseksi. Aihetta ei ole paljon tutkittu.
Allergialääkäri Tari Haahtela on esittänyt erityisen terveyden biodiversiteettihypoteesin: llman altistumista muulle luonnolle ja sen mikrobeille, elimistömme immuunipuolustus ei toimi tarkoituksenmukaisesti. Jos vuorovaikutus on heikkoa, kehon puolustus ei opi erottamaan, mikä on vaarallista ja mikä ei. Elimistö menee stressitilaan, josta seuraa matala-asteista tulehdusta. Kehon puolustusjärjestelmän ylireagointi voi johtaa sairauksiin.
Mira Grönroos on tutkijatohtorina Suomen Akatemian rahoittamassa monitieteisessä NATUREWELL-hankkeessa (2019-2025). Dosentti Riikka Puhakan vetämässä hankkeessa tutkitaan suomalaisnuorten ulkoiluharrastusten vaikutuksia terveyteen ja hyvinvointiin. Grönroos keskittyy hankkeessa siihen, miten ulkoilu ja luonnossa liikkuminen vaikuttavat nuorten elimistön mikrobiston koostumukseen.

”Nuoret osallistuivat erilaisiin luontoaktiviteetteihin. Heidän iholtaan otettiin mikrobinäytteet ennen ja jälkeen näiden aktiviteettien. Tutkimme muuttaako metsävaellus tai ulkoilu kaupunkiluonnossa nuorten mikrobistoa. Etsimme myös keinoja, miten nuoria voidaan kannustaa luontoon”, Grönroos kertoo.
Grönroos toimii tutkimusryhmässä, jota johtaa Luonnonvarakeskuksen erikoistutkija Aki Sinkkonen. Tutkimusryhmän muissa tutkimuksissa on mitattu interleukiinien ja T-solujen määriä. Pienimolekyyliset proteiinit, sytokiinit, toimivat elimistön solujen toimintoja ohjaavan säätelyjärjestelmän viestinviejinä. Niihin kuuluvat interleukiinit, jotka lisäävät tai vähentävät tulehduksia. T-solut auttavat tuhoamaan solujen sisällä eläviä taudinaiheuttajia. B-solut huolehtivat vasta-ainevälitteisestä immuniteetista. Tutkimuksissa havaittiin, että tulehdusta vähentävien interleukiini 10-proteiinien tasot nousivat mikrobialtistuksen jälkeen.
Grönroosin mukaan immuunijärjestelmä ja mikrobit ovat jatkuvassa vuorovaikutuksessa keskenään.
”Tähänastiset tulokset ovat hyvin rohkaisevia. Nyt tutkitaan, kuinka voimakas luontoaltistus olisi tarpeen. Luonnossa oleskelulla on myös monia muitakin hyvinvointihyötyjä ja jo niidenkin takia metsään kannattaa mennä. Jos haluaa retkeltä lisäksi enemmän mikrobikontaktia, voi hyvin vaikka unohtaa käsien desinfioinnin ennen eväiden syöntiä”, sanoo Grönroos.
Sinkkosen tutkimusryhmässä on tehty interventiotutkimuksia. Tiedonkeruussa tutkijoiden puuttuminen tutkittavaan ilmiöön on menetelmän olennainen osa. Yhdessä tutkimuksessa lisättiin päiväkotien lapsien kontakteja luonnon mikrobistoon. Tutkimuksessa seurattiin kuukauden ajan 3 – 5-vuotiaita päiväkotilapsia kymmenessä päiväkodissa Lahdessa ja Tampereella.
”Päiväkodin piha viherrettiin ja lapset olivat sitä kautta enemmän luonnonmateriaaleihin kontaktissa. Toisessa tutkimuksessa hiekkaan lisättiin mikrobistoa sisältävää materiaalia”, kertoo Sinkkonen.

Kokeilla osoitettiin ensimmäistä kertaa maailmassa, että lasten immuunijärjestelmän säätely muuttui, kun lapset olivat kontaktissa monimuotoiseen, luonnon materiaaleista peräisin olevaan mikrobistoon.
Hiekasta, ihosta ja suolistosta kerätty mikrobisto sekvensoitiin. Tutkimuksessa selvitettiin, miten mikrobisto muuttui koeryhmällä ja kontrolliryhmällä. Tutkimuksessa sekvensoitiin 16S- ribosomaalisen RNA:n geenialue (16S rRNA) ja bioinformatiikka tehtiin Suomen ELIXIR-keskuksen CSC:n resursseilla. 16S- geenialueet ovat säilyneet evoluutiossa muuttumattomana miljoonia vuosia bakteereilla, minkä vuoksi näiden geenialueiden perusteella voidaan tunnistaa eri lajeja.
Lasten ihosta saatiin selville bakteeriyhteisön koostumus, metagenomi. Yli 30 bakteerisuvun suhteellinen runsaus kasvoi lasten iholla. Iholla olevien immuunipuolustusta tehostavien gammaproteobakteerien runsastuminen oli yhteydessä allergioiden ja immuunivälitteisten sairauksien syntyyn yhdistetyn interleukiini-17A:n muutokseen.
”Tehokkaat sekvensointimenetelmät ja niillä saatu data ovat elinehto mikrobien monimuotoisuuden sekä sen vaikutusten tutkimiselle. Pelkillä kasvatusmenetelmillä ei pystytä tutkimaan tällaisia kysymyksiä”, sanoo Grönroos.
Rinnakkaissekvensointi tarkoittaa miljoonien, jopa miljardien DNA-pätkien tunnistamista yhdestä näytteestä yhdellä kertaa. Sinkkosen tutkimusryhmässä on aloitettu myös shotgun -sekvensointi eli satunnaissekvensointi.
”Tällä menetelmällä saadaan tarkempaa tietoa koko mikrobiomin taksonomisesta profiilista sekä sen toiminnallisuudesta, kuten geeneistä ja aineenvaihduntareiteistä”, sanoo Sinkkonen.

Mira Grönroosin tutkimus on monitieteistä. Mukaan on tullut myös yhteiskunta- ja kasvatustieteellinen näkökulma. Nyt halutaan edistää vuorovaikutusta luonnon kanssa. Jo aiemmissa päiväkotitutkimuksissa havaittiin, että lapset rakastivat leikkimistä luonnon materiaaleissa. Vastikään alkaneessa Tampereen yliopiston hankkeessa tutkitaan lasten suhtautumista mikrobeihin. ”Mikrobeja tuodaan näkyviksi sekä taiteen että tieteen keinoin. Itse toteutan tiedeosuuden. Lapset saivat päättää, mistä haluavat ottaa näytteet. Videoviestien kautta he pääsevät seuraamaan näytteiden matkaa laboratoriossa. Lopuksi esittelen sekvensoinnin tulokset lapsille.”
21.10.2024
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). The skin’s wide range of microbiota improves the immune system. https://doi.org/10.5281/zenodo.14823352
Lisätietoja:
Helsingin yliopisto
https://www.helsinki.fi/en/researchgroups/nature-based-solutions
Luonnonvarakeskus
https://www.luke.fi/en/projects/biwe
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Itä-Suomen yliopiston farmasian laitoksen lääketutkijan Piia Bartoksen kiinnostuksen kohteena on RNA, RNA:ta sitovat proteiinit ja miten tähän järjestelmään vaikuttamalla voisi estää syövän kasvua. RNA:ta ja siihen sitoutuvan argonautti- proteiinin toimintaa hän on tutkinut massiivisilla simulaatioilla.
Molekyylidynamiikan simulaatiot ovat antaneet tietoa, miten biomolekyylit vuorovaikuttavat toisiinsa atomien tasolla. Koska atomit ovat jatkuvassa liikkeessä, niiden väliset voimat lasketaan ja tämän perusteella selvitetään esimerkiksi proteiinin atomien uudet sijainnit, nopeudet ja energiat. Näin saadaan uutta tietoa lääkeainesuunnitteluun.
Bartos on tutkinut RNA:han sitoutuvia proteiineja (RBP-proteiinit), joilla voi olla merkitystä syövän hoitamisessa. Niillä on havaittu olevan merkitystä syöpäsoluille etenkin lääkevasteissa ja lääkeresistenssin muodostumisessa. Yli 1500 RBP-proteiinia on löydetty. Muutoksen näiden proteiinien toiminnassa voivat vaikuttaa syöpägeenien ilmentymisen tasoon.
RNA-häirintä (RNA-interferenssi eli RNAi) on biokemiallinen mekanismi, jossa RNA aiheuttaa lähetti-RNA:n pilkkoutumisen solussa, jolloin geenin ilmentyminen häiriintyy. RNAi:n löytäneet tutkijat Andrew Fire ja Craig Mello saivat työstään lääketieteen Nobelin palkinnon vuonna 2006. RNAi:n avulla voidaan sammuttaa syövän kasvua edistävien proteiinien ilmentyminen.
”Erityisenä kiinnostuksen kohteenamme ovat argonauttiproteiinit, joilla on tärkeä rooli RNA-välitteisessä geenien hiljentämisessä eli RNA-häirinnässä. Näistä tärkeimpänä on Ago2,”sanoo Bartos.
Kun RNA on sitoutunut Ago2-proteiiniin, tätä yhdistelmää kutsutaan RNA-Ago2-kompleksiksi. Argonautti 2-proteiini sitoo mikro-RNA -molekyylejä soluissa.
”Koska argonautti-2 on solun toiminnalle elintärkeä proteiini, se todennäköisesti vaikuttaa kaikkiin syöpätyyppeihin. Jos se poistetaan soluista, solut eivät pysy elossa. Jos sen toiminta pystyttäisiin poistamaan syöpäsoluissa, syöpäsolutkaan eivät pysyisi elossa. Näin voitaisiin estää syöpäsolujen kasvaminen ja leviäminen.”

Haasteena on, että RNA-Ago2-kompleksissa voi olla sitoutuneena kahdenlaisia RNA-molekyylejä. Ensimmäinen estää, mutta toinen lisää proteiinin tuotantoa. Jälkimmäisessä tapauksessa syöpäsolujen tuotanto voikin lisääntyä.
”Simuloin RNA:n toimintaa erikseen ja yhdessä Ago-2-proteiinin kanssa. Olen pyrkinyt selittämään, miten Ago-2- kompleksit eroavat rakenteellisesta toisistaan, siis silloin kun siinä on sellainen RNA, joka lisää proteiinin tuotantoa ja silloin kun siinä on proteiinin tuotantoa vähentävä RNA. Olemme vasta saaneet simulaatiot ajettua ja nyt tuloksia analysoidaan.”
Molekyylidynamiikkasimulaation avulla voidaan tehdä eräänlaisia videoita Ago2-RNA-kompleksien liikkeistä ja vertailla aktivoivien ja hiljentävien kompleksien eroja.
Simulaatiossa käytetty RNA-sekvenssidata saatiin A.I Virtanen-instituutista. Simulaatioissa oli kuusi RNA-molekyyliä, joista kolme lisäsi ja kolme vähensi proteiinien tuotantoa. Näille kaikille tehtiin molekyylidynamiikan simulaatioita noin 50 mikrosekuntia eli sekunnin miljoonasosa systeemiä kohden. Simulaatioissa tarvittiin paljon Suomen ELIXIR-keskuksen CSC:n laskentaresursseja.
”Se on aika iso proteiini. Yhdessä RNA:n ja ympäröivän veden kanssa siinä on noin 300 000 atomia, ja niille kaikille piti laskea nopeus ja paikka neljän femtosekunnin välein.”
Femtosekunti on miljoonasosa sekunnin miljardisosasta. Bartos haluaa selvittää, muuttuuko kompleksin muoto ja liikkuuko joku proteiinin osa eri tavalla, kun siinä on lisäävä tai vähentävä RNA sitoutuneena.
”Kompleksin muodon muuttuminen voi todennäköisesti indikoida sitä, että kompleksi sitoutuu eri proteiineihin.”
Kompleksien rakenteissa tai liikkeissä täytyy siis olla jokin ero, joka saa aikaan erilaiset geenien ilmentymistä lisäävät ja vähentävät vaikutukset.
Ymmärtämällä geenien ilmentymistä vähentävien ja lisäävien RNA-proteiinikompleksien rakenteelliset erot, pystytään suunnittelemaan ja etsimään lääkeaineita, jotka sitoutuvat vain haluttuun kompleksiin. Bartosin mukaan tällaiset lääkeaineet olisivat lääketieteellinen läpimurto ja tarjoaisivat uuden mahdollisuuden hoitaa syöpäsairauksia, joissa proteiinien tuotanto on häiriintynyt.
”RNA-häirintään perustuvat lääkkeet ovat hyvä vaihtoehto. Nämä lääkkeet verrattuna tavalliseen pienimolekyyliseen syöpälääkkeeseen voisivat olla spesifisempiä ja tarkemmin syöpäsoluun kohdentuvia. RNA-häirinnällä pystyisimme tarvittaessa estää minkä tahansa haluamamme proteiinin ilmentymisen syövässä. Eli siitä saisi täsmälääkkeitä.”
Bartosin mukaan RNA:n toiminnan mallintaminen on kuitenkin vielä haasteellista. Simulaatioissa voimakenttämallit toimivat hyvin proteiineille, mutta eivät RNA:lle.
”Se johtuu siitä, että se RNA on kemiallisesti ja fysikaalisesti aika erilainen kuin proteiinit.”
Ongelma on esimeriksi fosfaatti, joka muodostaa RNA:n rangan yhdessä deoksiriboosin kanssa.
”RNA:n fosfaatti on sähköisesti varautunut ja sitä nämä nykyiset voimakenttäyhtälöt eivät kovin hyvin pysty mallintamaan. Eli tässä on selkeästi työsarkaa työkalujen kehittämisessä.”
Lääkeainesuunnittelu etenee suurin harppauksin monella tasolla. DeepMindin tekoäly Alphafold osaa jo ratkaista, miten sekvenssi muuttuu proteiinirakenteeksi. Se käyttää tunnettuja proteiinirakenteita ja ennustaa rakenteen kaikille tunnetuille proteiineille. Sekvensoinnin avulla voidaan puolestaan selvittää syövässä esiintyvät mutaatiot ja mallien avulla tutkia, miten mutaatiot vaikuttavat syöpälääkkeiden toimintaan.
”Mutaatio voi esimerkiksi estää syöpälääkkeen sitoutumisen kohdeproteiiniin lääkevaikutuskohteeseen, jolloin kyseisestä lääkityksestä harvoin on potilaalle hyötyä.”
Laskentakapasiteetin kasvaessa voidaan tulevaisuudessa myös simuloida isompia kokonaisuuksia.
”Olisi hienoa simuloida yksittäistä proteiinia isompaa yksikköä, esimerkiksi solutasolla. Voitaisiin simuloida, miten proteiini vaikuttaa muiden proteiinien, solukalvojen ja soluelinten kanssa.”
Ari Turunen
30.9.2024
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). New drug targets from RNA-binding proteins. https://doi.org/10.5281/zenodo.14810576
Lisätietoja:
Hanna Baltrukevich & Piia Bartos: RNA-protein complexes and force field polarizability. Front. Chem., 22 June 2023
Sec. Theoretical and Computational Chemistry
Volume 11 – 2023 | https://doi.org/10.3389/fchem.2023.1217506
Milla Kurki et all: Structure of POPC Lipid Bilayers in OPLS3e Force Field. Journal of Chemical Information and Modeling. Vol 62/Issue 24
https://pubs.acs.org/doi/full/10.1021/acs.jcim.2c00395
Itä-Suomen yliopisto
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Itä-Suomen yliopistossa seulottiin virtuaalisesti 1,56 miljardia molekyyliä kahdelle lääkekohde-ehdokkaalle. Seulonta oli maailman suurin lajissaan.
Suurin osa käytössä olevista lääkkeistä on suunniteltu niin, että niiden kohdemolekyyleinä ovat elimistön proteiinit. Kun proteiiniperheen yhden jäsenen rakenne on selvitetty, voidaan muiden samaan perheeseen kuuluvien proteiinien rakenne ennustaa mallintamalla. Toimiva lääke voidaan kehittää esimerkiksi siten, että seulotaan isosta kirjastosta molekyyli, jonka kolmiulotteinen rakenne mahdollistaa vuorovaikutuksen kohdeproteiinin kanssa.
Professori Antti Poson tutkimusryhmässä etsittiin kahden lääkevaikutuskandidaatin, SurA-kaperonin ja GAK-kinaasin kanssa reagoivia molekyylejä. Hankkeessa testattiin seulontaan kehitetyn HASTEN-algoritmin toimivuutta ja luotiin uusi koneoppimisen malli.
”Nämä kohdeproteiinit, eli SurA ja GAk, olivat meille entuudestaan tuttuja, olemassa olevista akateemisista tutkimushankkeista. Massiivisten seulontojen tuloksia voidaan nyt hyödyntää muissa tutkimuksissa. Emme siis pelkästään validoineet menetelmää vaan voimme myös auttaa erillisiä akateemisia tutkimushankkeita”, sanoo Poso.
Kaperonit auttavat proteiinien laskostumisessa ja säätelevät proteiinien välisiä vuorovaikutuksia. Kinaasit toimivat mm. solujen signaalienvälittäjinä.
”SurA –kaperoni liittyy Tübingenin yliopiston yhteistyöhankkeeseen, jossa tavoitteena on kehittää uusia antibiootteja. Kinaasit taas ovat iso proteiiniperhe. Syöpälääkkeistä iso osa on kinaasi-inhibiittoreita. Kinaaseja on noin 500 erilaista ja GAK (Cyclin-G-associated kinase) on yksi niistä. GAK:n potentiaali on syöpälääkkeissä ja virusinfektoiden torjunnassa.”
Poson ryhmässä tutkitaan lääkeaineiden vuorovaikutuksia proteiinien kanssa ja rakennetaan kohdeproteiinimalleja. Kohdeproteiinin rakenteesta voidaan yleensä tunnistaa lääkeaineen sitoutumispaikka proteiinin ja saada siten lääkeaine toimimaan. Mallia voidaan erityisesti käyttää virtuaaliseulontaan, jossa suurista molekyylitietokannoista etsitään uusia ideoita lääkekehitykseen.
”Kaperoni on proteiinirakenteeltaan hyvin erityyppinen kuin kinaasi. Kyseessä on siis kaksi hyvin erilaista kohdeproteiinia, joita oli hyvä testata yhdessä.”

Kahden lääkeaihion rakenteen erilaisuus oli tärkeä tekijä, koska algoritmin pitää toimia kaikissa proteiiniperheissä.
”Kahdella lääkeaineaihiolla testattiin, miten Orionin Tuomo Kalliokosken kehittämä HASTEN-algoritmi toimisi CSC:n superlaskentaympäristössä. Skaalautuvuus onnistui.”
Kohdeproteiinien seulontaa tehtiin vertailun vuoksi HASTEN-algoritmilla ja perinteisellä telakointi -menetelmällä (docking). Telakoinnissa hakualgoritmi laskee vuorovaikutukset proteiinin ja tietokannassa olevan lääkeainekandidaatin välillä. Algoritmin antama lukuarvo kertoo, miten hyvin lääkeaine sitoutuu proteiiniin.
Poson ryhmässä seulottiin 1,56 miljardia lääkeainekandidaattia sisältävää molekyyliä. Molekyylit seulottiin ison ukrainalaisen kemian alan yrityksen Enaminen REAL-tietokannasta.
”Ensin laskettiin joka ikinen tietokannassa oleva piirretty kaksiulotteinen molekyyli ja ne muutettiin kolmiulotteiseen muotoon. Sitten tietokoneohjelma yritti sovittaa kunkin molekyylin GAK:n tai SurA:n sisään. Yksittäinen sovitus voi käsittää jopa satojatuhansia potentiaalisia vaihtoehtoja.”
Sitten tutkijat kokeilivat, miten koneoppimisen malli pärjäsi telakointiin verrattuna. Koneoppimiseen käytettiin HASTEN-algoritmia.
”Valitsimme ensin satunnaisesti miljoona molekyyliä ja katsoimme, miten telakointi sujui. Sitten tämä tulos kerrottiin tekoälylle. Kone siis opetteli miljoonan molekyylin perusteella ennustamaan tuloksen. Eli kun molekyyli näyttää tietynlaiselta, se telakoituu tiettyyn kohtaan.”
Tämän jälkeen tekoälylle syötettiin kaikki 1,56 miljardia molekyyliä ja ennustetiin tulokset perustuen miljoonan molekyylin tuloksiin. Parhaiksi ennustetut telakoitiin ja tulosten perusteella koneoppimine tehtiin uudelleen. Muutaman kierroksen jälkeen tekoäly ennusti telakoinnin 90% tarkkuudella.
”Opetettu kone pystyi tekemään seulonnan huomattavasti nopeammin kuin perinteisen telakointimenetelmän avulla. Kun telakoinnin laskemiseen meni pari kuukautta tehokkaillakin tietokoneilla, koneoppimisen avulla oppimisprosessi ja ennustaminen vei muutaman päivän.”
Poson mukaan nyt tutkijat pystyvät rutiininomaisesti seulomaan miljardeja molekyylejä samassa ajassa kuin missä aiemmin seulottiin miljoona. Lisäksi koneoppimisen mallin takia miljardien molekyylien seulonnan voi nyt tehdä ilman supertietokonetta.
”Nyt tietenkin voidaan supertietokoneella seuloa vieläkin suuremmista tietokannoista tuhansia miljardeja molekyylejä tämän menetelmän avulla. ”
Poson ryhmä tutkii seuraavaksi ns. vivid screening-menetelmää.
”Sen sijaan, että ennustetaan jokin tietty yksittäinen aktiivisuus tai telakointi, voidaankin samaan aikaan ennustaa useita erilaisia ominaisuuksia, esim. välttää jotakin sivuvaikutuksen omaavaa sitoutumispaikkaa samalla kun pidetään sitoutuminen oikeaan kohteeseen hyvänä.”
Tutkimuksessa käytettiin Suomen ELIXIR-keskuksen CSC:n superlaskentaresursseja, datantallennusta sekä tarvittavien työkalujen kontitusta.
Ari Turunen
31.8.2024
Lue artikkeli PDF-muodossa
Sitaatti:
Turunen, A., & Nyrönen, T. (2024). New machine learning method speeds up drug screening hundred-fold. https://doi.org/10.5281/zenodo.13691983
Lisätietoja:
Toni Sivula, Laxman Yetukuri, Tuomo Kalliokoski, Heikki Käsnänen, Antti Poso & Ina Pöhner (2023): Machine Learning-Boosted Docking Enables the Efficient Structure-Based Virtual Screening of Giga-Scale Enumerated
Chemical Libraries. J. Chem. Inf. Model. DOI: 10.1021/acs.jcim.3c01239. Available at: https://pubs.acs.org/doi/full/10.1021/acs.jcim.3c01239
HASTEN-algoritmi
https://github.com/TuomoKalliokoski/HASTEN
Itä-Suomen yliopisto
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Arabica-kahvin genomi julkaistiin huhtikuussa 2024. Se oli yksi viimeisistä merkittävistä viljelykasveista, jonka perimän sekvensointia ei ollut vielä julkaistu. Tutkimusta johtaneen Jarkko Salojärven mukaan nyt voidaan löytää geenejä, jotka parantavat kahvin satoisuutta ja kestävyyttä tauteja vastaan.
Kansainvälinen tutkimuskonsortio, jossa oli mukana muun muassa Helsingin yliopiston ja Singaporen Nanyangin teknillisen yliopiston tutkijoita, on koostanut kolmen kahvilajin perimän kahvipensaan lehtisolujen DNA:n sekvenssipätkistä. Arabican (Coffea arabica) genomi koostettiin Singaporessa ja Helsingissä, ja robustan (C.canephora) sekä C. eugenioides-lajikkeen perimä Cornellin yliopistossa Yhdysvalloissa.

”Tarkoituksena on löytää satoisuutta ja laatua parantavia ominaisuuksia. Viljelty arabica on geneettisesti vähemmän moninainen ja altistuu siksi taudeille helposti”, sanoo apulaisprofessori Jarkko Salojärvi.
Kahvin taloudellinen merkitys on valtava. Sitä viljellään 70:ssä eri maassa ja yli 100 miljoonaa ihmistä saa siitä elantonsa. Kahvi onkin yksi maailman tärkeimmistä kaupallisista tuotteista. Kahvin jalostuksessa on kuitenkin riskinsä.
”Yleensäkin viljelykasvien geneettinen moninaisuus on jalostuksen myötä vähentynyt. Tautien vastustuskyvystä vastaavat geenit eivät siis ole viljellyissä kahvilajikkeissa kovin monimuotoisia. Siksi arabica on patogeeneille altis.”
Kaiken kaikkiaan 60% maailman kahvista on arabicaa (Coffea arabica). Arabican lisäksi kaupallisesti viljelty lajike on robusta (Coffea canephora), joka sisältää arabicaa enemmän kofeiinia ja on kitkerämpää. Sitä käytetään etenkin pikakahveissa. Vietnam on maailman suurin robustan tuottaja. Harvinainen Coffea eugenioides on makeaa, koska sen kofeiinipitoisuus on pieni. Sen satoisuus on heikompaa kuin arabican ja robustan.

Salojärvi on erikoistunut kasvien genomien selvittämiseen. Hän on ollut mukana tutkimassa avokadon, koivun, litsin ja Darrowin mustikan perimää. Salojärvi työskentelee Nanyangin teknillisessä yliopistossa Singaporessa sekä Helsingin yliopistossa. Hyvin laaja-alainen ja kansainvälinen tutkimusryhmä käyttää paljon laskennallisia resursseja ja tietokantoja molemmissa maissa.
Koko genomin sekvensointi mahdollistaa sekä yleisten että harvinaisten mutaatioiden paljastamisen koko genomissa. Arabican genomi sekvensointiin vasta vuonna 2024 johtuen sen perimän monimutkaista rakenteesta.
Arabica on Coffea eugenioidesin ja robustan risteymä. Koska kumpikin lajikkeista on diploidi, niin arabicassa kromosomeja on nelinkertainen määrä eli se on tetraploidi. Tällaiset kasvit kasvavat usein nopeammin ja suuremmiksi kuin diploidit. Niiden genomin rakenne on usein erittäin monimutkainen ja luo haasteita sen kokoamiselle. Arabican genomin kokoamista vaikeutti se, että kaksi alagenomia (C.canephora) ja C. eugenioides) ovat hyvin samankaltaisia johtuen niiden läheisestä evoluutiohistoriasta, niiden lajiutuminen tapahtui vain noin 4.5-7.2 miljoonaa vuotta sitten.
Näihin verrattuna arabica-risteymän villi, Etiopiasta kotoisin oleva versio on verrattain nuori, noin 350 000 vuotta vanha. Arabica on käynyt läpi monia ns. geneettisiä pullonkauloja, jolloin huomattava osuus populaatiosta estyy lisääntymästä ja populaatio supistuu oleellisesti. Siksi arabican geneettinen moninaisuus ei ole kovin suuri. Sen viljellyssä versiossa on villeihin versioihin verrattuna vielä vähemmän geneettistä variaatiota. Tämä johtuu ihmisen aikaansaamasta pullonkaulasta: suurin osa maailmassa viljellystä arabicasta periytyy oikeastaan vain kahdesta, noin 300 vuotta sitten eläneestä kasvista.
1600-luvun alussa arabican siemeniä salakuljetettiin Jemenin ulkopuolelle ja arabicaa ryhdyttiin viljelemään Kaakkois-Aasiassa ja myöhemmin Karibialla. Tätä arabican muunnosta kutsutaan nimellä typica ja sen viljelyä hallinnoivat alankomaalaiset. 1700-luvulla ranskalaiset aloittivat arabican viljelyn Intian valtameren Reunionin saarella. Tätä muunnosta kutsutaan Reunionin vanhan nimen mukaan nimellä bourbon. Nykyiset viljellyt arabica-pensaat periytyvät siis joko typicasta tai bourbonista.

Ilmastonmuutos vaikuttaa jo nyt kahvin satoisuuteen. Kuivuus on pienentänyt satoja esimerkiksi Brasiliassa ja Kolumbiassa. Arabicaa viljellään yli 1500 metrin korkeudessa tropiikissa. Kun ilmasto lämpenee, sitä on viljeltävä entistä korkeammalla, jolloin viljelyala pienenee.
Ilmaston lämpeneminen lisää myös sairauksia. Kahviruoste (Hemileia vastatrix) saa kahvipensaan pudottamaan lehtensä. Tauti ei selviä alle 10 asteen lämpötiloissa, joten vuoriston öiden lämpeneminen edistää taudin leviämistä.
Jarkko Salojärven mukaan kahvin kestävyyttä voidaan kuitenkin parantaa genomiin perustuvan jalostuksen avulla.
”Voidaan tehdä ennustettavia malleja sekvensoimalla jonkun populaation vanhemmat ja katsomalla, kuinka hyvin voidaan vanhempien genomien perusteella ennustaa ilmiasua jälkeläisille. Sen perusteella pystytään löytämään markkereita, joiden perusteella voidaan valita seuraavan sukupolven yksilöitä, jotka todennäköisesti tuottavat parempaa satoa tai ovat resistenttejä patogeeneille. Tällaistahan tarvitaan erityisesti kahville, jonka viljelypinta-ala voi puolittua ilmastonmuutoksen takia jo noin 30 vuoden sisällä. ”
Sekvensoinnin avulla voidaan etsiä kahvilajien genomeista geenialueita, jotka ovat lämmönkestäviä ja vastustuskykyisiä taudeille. Tiedetään, että robusta kestää kuumaa säätä paremmin kuin arabica. Se on myös vastustuskykyinen tauteja, kuten kahviruostetta, vastaan. Erityisen kestävä on Timorin saarelta 1930-luvulla löydetty robustan ja typica-arabican hybridi (Hibrido de Timor).
Salojärven mukaan sen genomista löydetyt alueet voivat mahdollistaa genomiin perustuvan arabican jalostuksen.
”Timorilaisesta hybridistä saadut geenit ovat tosin vasta kandidaattigeenejä. Seuraavaksi pitää tutkia onko yhteys oikeasti kausaalinen. Sen testaamiseen menee varmaan n. 5-10 vuotta, jolloin tuota tietoa voidaan käyttää jalostuksessa.”
Tutkimus kohdistuu näiden kandidaattigeenien toimintaan taudin iskiessä.
”Esimerkiksi voi olla, että nuo geenit kyllä aktivoituvat kahviruosteen hyökätessä, mutta ne voivat olla sen verran myöhäistä vastetta, että niistä ei ole sen estämiselle enää mitään hyötyä,” Salojärvi huomauttaa.
”Seuraavaksi pitäisi hiljentää nuo geenit ja selvittää, poistuuko resistenssi. Tai sitten siirtää ne kahviruosteelle alttiiseen lajikkeeseen ja katsoa, saadaanko sillä resistenssiä aikaiseksi. Kumpaakaan versiota ei voi käyttää kahvintuotantoon, koska ne olisivat siirtogeenisiä yksilöitä, mutta niillä saadaan varmistettua, että kyseessä ovat oikeat geenit. Jalostamisessa voidaan sitten keskittyä jälkeläisiin, joilla tuo resistenssialue on olemassa.”
Kahvin perimän kromosomi -tason määrittäminen vaati myös kromosomien kolmiulotteisen rakenteen selvittämistä. Suomen ELIXIR-keskuksen CSC:n laskentaresursseja käytettiin tähän tehtävään. Prosessissa kahvin yhtenäiset perimäjaksot yhdisteltiin rakennetta hyväksi käyttämällä kromosomin pituisiksi tikastuksiksi (scaffolding).
”Se tarkoittaa, että kromosomi koostetaan täysin sekvensoiduista paloista sekä tyhjistä palikoista niiden välillä. Rakenteen selvitys paljastaa muun muassa yhteyden geenien ja niitä säätelevien perimän alueiden kanssa.”

Kahvin genomin selvittämisen jälkeen Jarkko Salojärvi tutkii seuraavaksi sademetsän kasvien genomeja. Singaporen Bukit Timahin 163 hehtaarin luonnonsuojelualueella kasvaa yli 800 erilaista koppisiemenistä kasvilajia. Nanyangin teknillisen yliopiston hankkeessa hänen ryhmässään tutkitaan sademetsän biodiversiteettiä sekvensoimalla kaikki alueen kasvilajit. Painopiste on sademetsän geenien koostumuksessa. Samalla katsotaan ennen näkemättömiä biosynteesireittejä, joissa kasvit valmistavat yksinkertaisista yhdisteistä entsyymien avulla monimutkaisia yhdisteitä.
”Erityisen kiinnostavaa on tutkia, millaisia erilaisia muunnoksia eri kasvilajeilla on pääasiallisiin biosynteesireitteihin.”
Kasvien aineenvaihduntatuotteet, metaboliitit, ovat tärkeitä tutkimuskohteita esimerkiksi uusien lääkeaineiden löytämiselle. Salojärven mukaan koneoppiminen mullistaa lääkeaineiden ja metaboliittien tutkimisen.
”Esimerkiksi Googlen tekoälyohjelma Alphafold 3 pystyy ennustamaan kasvin genomista proteiinirakenteet ja erilaisia modifikaatioita metaboliiteille. Kun genomi on selvitetty, niin tämä tutkimus lähtee vauhdilla tekoälyn ansiosta eteenpäin.”

Kaikki kolme kahvin genomia on jaettu EBI/NCBI-tietokantoihin. Näiden lisäksi annotaatiotietoihin pääsee ORCAE-tietokannan kautta. ORCAE tarjoaa työkaluja geenien rakenteiden tutkimiseen ja sisältää annotaatioita eri aitotumaisten genomeista. Sitä operoi Belgian ELIXIR-keskus.
Belgian ELIXIR tukee kasvien ja biodiversiteetin tutkimusta. Se tarjoaa resursseja genomiikkaan ja fenotyyppidatan hallinnointiin. VIB-UGent -yliopiston bioinformatiikan ryhmät, jotka myös osallistuivat kahvitutkimukseen, ovat kehittäneet työkaluja genomien annotaatioiden kuratoimiseksi (ORCAE) sekä vertailevaan genomiikkaan (PLAZA). ORCAE on verkossa toimiva portaali aitotumaisten genomien kuvailutietojen selailuun, kun taas PLAZA on liityntäpiste vertailevan genomiikan ja genomisen datan keskittämiselle.
“Kaikki julkisesti rahoitettu projektidata pitää julkaista generoituna raakadatana tiedeyhteisöille. Kukin tallennusjärjestelmä tarjoaa käyttöliittymät ja toimintaohjeet auttamaan raakadatan ja siihen liittyvät metadatan tallentamisessa”, sanoo johtava tutkija Stephane Rombauts (VIB-UGent Center for Plant Systems Biology).
”Olemme kehittämässä parempia ja uudempia käyttöliittymiä jotta saisimme koko toimitusprosessin helpommaksi.”
Belgian ELIXIR-keskus on ollut kehittämässä työkaluja myös helpottamaan toimittamista Euroopan nukleotidiarkistoon (European Nucleotide Archive, ENA). ENA on täysin avoin arkisto raa’an sekvenssi, koonti- ja annotaatiodatan tallentamiseen.
ENA Data Submission Toolbox-työkalu yksinkertaistaa sekvenssidatan toimittamisen tarjoamalla yksivaiheisen toimitusprosessin, graafisen käyttöliittymän, taulukkomuotoillun metadatan ja asiakaspuolen todentamisen.
”Käyttöliittymät tarjoavat vain väylän datan lataamiselle, mutta jos ne toimisivat myös varmuuskopiona, se olisi kannuste ladata dataa nopeammin,” Rombauts sanoo.
“Asiantuntijoiden pitää validioida kertaalleen ladattu data, ennen kuin se liitetään järjestelmään ja vasta sitten lopuksi se saa ainutkertaisen käyttönumeronsa. Prosessi voi olla toisinaan hidas koska sekvensointi tulee halvemmaksi ja helpommaksi ja samaan aikaan asiantuntijoiden silti pitää validoida alati kasvavia latauksia.”
”Lisäksi genomista dataa saadaan kasvavassa määrin long-read-muodossa, tai raakana, rikkaampana, aiempaa suurempina määrinä tehden nämä käyttöliittymät toisinaan sopimattomiksi viimeisille datatyypeille tai uusimmille sovelluksille.”
Ari Turunen
22.7.2024
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). Mapping the coffee genome to improve disease resistance. https://doi.org/10.5281/zenodo.13691962
The genome and population genomics of allopolyploid Coffea arabica reveal the diversification history of modern coffee cultivars.
Nature Genetics, 56, 721-731 (2024).
https://doi.org/10.1038/s41588-024-01695-w
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Koronavirus ei ole kadonnut maailmasta ja voi muuntautua jälleen vaaralliseksi. THL:n tutkimusprofessori Markus Perola selvittää ryhmänsä kanssa rekisteri- ja genomitietojen perusteella, mitkä tekijät vaikuttavat siihen, että osa väestöstä sairastuu vaikeaan koronaan ja joutuu sairaalahoitoon. Tutkimus vaatii paljon laskentaa ja sensitiivisen datan käsittelyä.
Loppuvuonna 2019 ilmaantunut COVID 19-virus aiheutti pandemian, joka järkytti koko maailmaa. Tauti oli hengenvaarallinen iäkkäille. Maaliskuussa 2021 mennessä tautiin oli kuollut 2,5 miljoonaa ihmistä noin 15 kuukauden aikana. Maailmanlaajuinen kriisi vaikutti niin talouteen kuin terveydenhuoltoon.
”Pandemioita tulee, koska väkiluku kasvaa ja asumme tiiviimmin ja lähempänä tuotantoeläimiä. Samalla luonnon monimuotoisuus vähenee ja syömme yksipuolisemmin. Maapallo on oikeastaan petrimalja, jossa kasvatetaan pandemioita,” sanoo Markus Perola.
Koska uusia muotoja viruksesta voi ilmetä, on tärkeää ymmärtää viruksen toimintaa ja miten sitä vastaan voidaan taistella. Esimerkiksi COVID-19 Host Genetics Initiative-projektissa tutkijat ympäri maailmaa yhdistivät voimansa kerätäkseen tietoa koronavirustartunnan piirteistä.
Tarkoituksena on tunnistaa yksilöt, joilla on suuri riski saada vakava tauti. Projektin tuloksena löytyi yli 50 perimän aluetta, joissa voi olla COVID-19 -taudille altistavia geenejä. Osa näistä altistaa myös erityisen vaikealle tautimuodolle.
”Näitä tietoja hyödynnetään THL:n omassa tutkimuksessa, jossa selvitetään, miksi jotkut koronaan sairastuneista joutuvat sairaalaan. Yksi syy voi löytyä geeneistä, ” sanoo Markus Perola.
Perolan johtamassa tutkimuksessa kerätään dataa yli 3 000 henkilöstä, jotka ovat joutuneet sairaalahoitoon tai lievemmissä taudin muodoissa hakeutuneet koronavirustestiin. Tutkimuksessa käytetään rekisteritietoja. Näytteiden keräys tehdään yhteistyössä biopankkien kanssa. Verinäytteistä tutkitaan muita samanaikaisia tartuntatauteja, tulehduksen vakavuusastetta sekä muita elimistön tasapainosta kertovia arvoja.
”Kun aina puhutaan eri riskiryhmistä, unohdetaan se, että iso osa koronaan sairastuneista riskiryhmäläisistä ei joudu teho-osastolle tai kuole siihen. Esimerkiksi kuolleisuus koronaan yli 80-vuotiaissa on kymmenen prosentin luokkaa, mutta kymmenet prosentit eivät myöskään kuole. Eli mikä on näiden ryhmien ero? Entä miksi jotkut hyvin ylipainoiset ihmiset joutuvat teho-osastolle, mutta toiset eivät? Toiveeni on, että löydettäisiin riskiryhmät, joita voitaisiin parhaiten suojata rokotuksin.”

Perolan mukaan genetiikan ja rekisteridatan yhdistäminen antaa lisävalaistusta asiaan. Isojen datamäärien analysoinnista Perolalla on poikkeuksellisen kiinnostavia tutkimustuloksia. Tero Hiekkalinnan ja Joseph Terwilligerin kanssa hän teki simulaation, jossa testattiin miljoonan ihmisen genomin data-aineiston hyödyntämistä. Aineistossa oli myös kliinistä fenotyyppidataa. CSC:n supertietokoneella analysoitiin anonymisoitua dataa, jossa oli genomidatan lisäksi tietoja terveydestä, sukulaisuussuhteista, iästä, sukupuolesta. Tämä testi tuotti arvokasta uutta tietoa, miten suuria datamääriä voitaisiin tulevaisuudessa hyödyntää julkisessa terveydenhoidossa.
Miksi kansallisten terveysvariaatioiden ymmärtäminen on tärkeää kansakunnan terveydenhuollolle?
”Jos emme tunne suomalaisia erityispiirteitä, ei kukaan muukaan niitä tutki. Hyvänä esimerkkinä on suomalaisen tautiperimän taudit, joita on nelisenkymmentä tänne konsentroitunutta harvinaista sairautta. Geenitutkimuksessa tehdään vankkaa kansainvälistä yhteistyötä geenien tunnistamisessa ja geenien toiminnan selvittämisessä. Mutta sen tuomisen kliiniseen todellisuuteen tekevät suomalaiset. ”
Suomi on geneettinen isolaatti, koska se on historiallisesti kasvanut vähän erillään muista Euroopan maista. Meillä on oma perimän muotomme, jota on tutkimuksellisesti helppo lähestyä eri tavalla. Täältä löytyy sellaista biologiaa, mitä ei muusta väestöstä löydy. Täältä on löytynyt toistasataa suomalaista tauteihin vaikuttavaa varianttia, joita ei muissa väestöissä näy.
Perolan mukaan suomalainen väestö on tavallaan maailman suurin isolaatti.
”Meillä on tilastollista voimaa enemmän löytää näitä variantteja verrattuna muihin eristyksissä oleviin populaatioihin, kuten Islantiin. Harvinaiset geenivariantit tuovat uutta tietoa tautien biologioista mitä ei muista populaatioista saada. Ne voivat avata ihan uusia syitä ja teitä tautien ymmärtämiselle. Olisiko tähän lääke vai pitääkö kehittää lääke?”

Suomi on rekisteridatassa Perolan mukaan maa, josta katsotaan mallia. Näin tapahtui esimerkiksi Euroopan terveysdata-avaruuden EHDS:n luomisessa. Rekisteridataa on kerätty vuosikymmeniä. Esimerkiksi syöpärekisteri pystytettiin jo 1950-luvulla.
”Meillä on laajasti dataa rekistereissä, esimerkiksi Kanta. Siinä ovat omat terveystiedot ja reseptit tallennettu. Vastaavanlaista ei ole monessa maassa. Esimerkiksi niin että kaikki laboratoriotiedot olisivat saatavissa niin kuin meillä nykyään on. Meillä on mahdollisuus saada tutkijoiden käyttöön koko populaation data eri tietojärjestelmistä tai hallintorakenteista huolimatta.”
Perola ottaa esimerkiksi yhden tutkimuksensa. Siinä selvitettiin rekisteridatan perusteella, mikä erotti Suomessa niitä ihmisiä, jotka ottivat ensimmäisen koronarokotteen niistä, jotka kieltäytyivät.
”Haluttiin löytää niitä ilmiöitä, jotka kuvaavat niitä vajaata 20% suomalaista, jotka eivät ottaneet ensimmäistä rokotetta. Tarkastelimme perhesuhteita ja sosioekonomisia muuttujia: onko palkkatyössä vai ei, asuinpaikan sijainti ja äidinkieli. Datasta pystyi tieteellisesti perustelemaan, että viesti rokotteista ei tavoittanut maahanmuuttajia ajoissa ja että oli sellaisia henkilöitä, joilla ei ollut resursseja hankkia itse tietoa rokotuksesta.”
Toinen asia, mitä tutkittiin oli RS-viruksen aiheuttamaa infektiota alle 1-vuotiailla. RS-virus (respiratory syncytial virus, RSV) on RNA-virus, joka aiheuttaa maailmanlaajuisesti miljoonia hengitystieinfektioita vuosittain. Se on erityisen merkittävä pienten lasten infektioiden aiheuttaja.
”Rekisteridatan perusteella seurattiin niitä perheitä, joiden lapsi oli RS-viruksen saatuaan joutunut sairaalaan. Tutkimuksessa löydettiin sosioekonomiseen statukseen, vanhempien päihteiden käyttöön ja lapsen synnynnäisiin ominaisuuksiin liittyvää dataa. ”
Perolan mukaan tämä oli arvokasta tietoa, joka saatiin tekoälyä käyttämällä. Koneelle syötettiin rekisteridata ja opetettiin tunnistamaan tietyt piirteet datajoukosta.
”Tätä ei voitu tehdä muilla kuin CSC:n sensitiivisen datan palveluilla ja superlaskentaympäristössä.”
Markus Perola käyttää tutkimuksissaan geeni-ja rekisteridataa.
”Infrastruktuurin merkitys on tärkeä. Tutkimus tarvitsee sellaisia organisaatioita, kuten CSC, joka mahdollistaa analyysien teon. On ihan sama onko tutkija astronomi tai geenitieteilijä: molemmat käyttävät samaa infraa. Infrastruktuurille on aina vaikea saada rahaa kun säätiöt eivät niitä rahoita vaan olettavat, että valtio maksaa. Valtio taas sanoo, että hankkikaa rahoitus ulkopuolelta. Infran tukeminen on välttämätöntä, jotta voidaan tehdä huipputiedettä Suomessa.”
Ari Turunen
25.6.2024
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). Why do some get the severe form of COVID-19?. https://doi.org/10.5281/zenodo.14810467
Lisätietoja:
CSC SD-connect
https://thl.fi/etusivuhttps://docs.csc.fi/data/sensitive-data/sd_connect/
Terveyden ja hyvinvoinnin laitos THL
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Yhdistämällä perimästä saatavaa tietoa eli genomitietoa kansallisissa terveydenhuollon rekistereissä olevaan dataan, voidaan kehittää tekoälymalli, jolle voidaan esittää kysymyksiä mahdollisista tulevaisuuden sairaalahoidoista. Tällaiset tilastolliset ja koneoppimisen mallit kykenevät ennustamaan sairauksien esiintymistä.
Apulaisprofessori Andrea Ganna Helsingin yliopiston Suomen molekyylilääketieteen instituutista (FIMM) on kiinnostunut geneettisen ja tilastollisen datan yhdistämisestä.
”Terveydenhuollossa voidaan hyödyntää koneoppimista, koska se oppii koko ajan valtavasta datamäärästä. Tekoälylle voidaan esittää kysymyksiä tulevaisuuden mahdollisiin sairaalahoitoihin liittyen. Tekoäly voi kertoa, mikä on elinajanennuste tai kuinka paljon reseptilääkkeet maksavat tietynlaisella elämäntyylillä ensi vuonna. ”
Ganna on hyödyntänyt suuria aineistoja tunnistaakseen demografisia ja geneettisiä tunnusmerkkejä, jotka ovat yleisten ja monitekijäisten tautien taustalla. Tekoäly voi tehdä jokaiselle henkilökohtaisen riskilaskelman, joka tehdään mallintamalla sairauksien ja lääkitysten pitkittäisseurannasta saatua dataa yhdessä geeni-, perhe- ja väestödatan kanssa.
Ganna käyttää tutkimuksissaan erityisesti FinRekisterit-aineistoa. FinRekisterit on Terveyden ja hyvinvoinnin laitoksen (THL) ja Suomen molekyylilääketieteen instituutin yhteinen tutkimusprojekti, jonka vastuututkijana toimii tutkimusprofessori Markus Perola. Se on yksi maailman laajimpia rekisteridatan toisiokäyttöön perustuvia tutkimuksia.
”Datakokoelmassa on 7,2 miljoonaa yksilöä eli kaikki Suomen kansalaiset sekä osa jo kuolleita sukulaisia. Siinä on paljon erilaista ja monipuolista tietoa. Saatavilla on terveystietoa, tietoja perhesuhteista, sosio-ekonomista tietoa, laboratoriotuloksia ja lääkereseptejä. Tämä on todella laaja datakokoelma.”
Aineistossa on 19 eri maanlaajuista rekisteriä, kuten Syöpärekisteri, Lääkeostorekisteri ja Kanta. Kanta on rekisteri, johon kerätään terveydenhuollossa ja apteekeista saatuja asiakas- ja potilastietoja. Kokoelmassa yksinomaan lääkeostoja on rekisteröity kokoelmaan yli miljardi. Ne ovat datapisteitä eli jokainen yksittäinen fakta on datapiste. Niitä datakokoelmassa on yhteensä yli 6,5 miljardia.
”Pidän hanketta ainutlaatuisena. Data on rikasta ja monipuolista”, sanoo Ganna.
”Terveystiedon yhdistäminen sosiaaliseen ja ekonomiseen informaatioon on minulle erittäin olennaista. Monesti näitä pidetään erillisinä, mutta tietojen yhdistäminen on erittäin tärkeää terveydelle. Meidän täytyy tarkastella sosio-ekonomista tietoa ymmärtääksemme kuinka ”reiluja” tekoälymallit ovat. Emme halua tekoälymallia, joka tekisi työnsä huonoimmin väestömme kaikkein haavoittuvimmissa osissa.”

Kun data on kerätty eri rekistereistä, yksilölliset tiedot salataan ja tallennetaan Suomen ELIXIR-keskuksen CSC:n sensitiivisen datan palveluihin. Ganna tutkimusryhmineen analysoi dataa tässä tietoturvallisessa ympäristössä.
”Olemme yhteistyössä CSC:n kanssa kehittäneet palveluja hyödyllisemmiksi tutkijoille. Olemme aloittaneet yksinkertaisista analyyseista kulkien kohti monimutkaisempia malleja.”
Andrea Gannan tutkimuksissa sensitiivistä dataa on valtava määrä.
”Luomme datamatriisin tekoälyä ja koneoppimisen malleja varten. Olemme myös hyvin tietoisia datan sensitiivisestä luonteesta. Emme pysty tunnistamaan yksilöitä ja käytämme erittäin kehittyneitä turvatoimia estääksemme luvattoman pääsyn dataan.”
Näitä tietoja voidaan käyttää eri tarkoituksiin.
”Saamme paremman ymmärryksen eri tautiryppäistä ja parempia ennusteita. Voimme laatia jopa digitaalista ikääntymistä kuvaavan kellon. Siinä käytetään koko väestön dataa, jotta voisimme antaa jokaiselle Suomen kansalaiselle eräänlaisen digitaalisen iän, joka perustuu terveystiedoista saadulle suuntaa-antavalle kehityskululle.”
Suunnitteilla on, että Ganna tutkimusryhmineen integroi rekisteridataa biopankeissa olevaan genomidataan. Kunnianhimoisena tavoitteena on tunnistaa yksilöissä kehittyviä sairauksia, joiden puhkeaminen voitaisiin estää. Tulevaisuudessa datan perusteella voitaisiin löytää riskiryhmään kuuluvia yksilöitä, jotka voisivat hyötyä ennaltaehkäisevistä lääkehoidoista. Andrea Gannan mukaan dataa on jo tarpeeksi, jotta tämä olisi mahdollista. Yhtenä hyvänä esimerkkinä tutkimusaineistosta Ganna mainitsee FinnGen-tutkimushankkeen, joka on tuottanut genomitietoa puolesta miljoonasta suomalaisesta. Hankkeessa on selvitetty suomalaisen väestön eri sairauksien geneettistä taustaa. Seuraavaksi on alettu selvittää, miten geenit vaikuttavat sairauksien etenemiseen.
”Biopankeissa oleviin, riskiryhmään kuuluviin ihmisiin voitaisiin olla yhteydessä. Tämä tietysti edellyttää että biopankeissa olevat ihmiset ovat antaneet kontaktointiin suostumuksensa.”

Gannan mielestä CSC:n sensitiivisen dataan liittyviä palveluita pitäisi pystyä kehittämään siihen suuntaan, että ne tukisivat erityisesti koneoppimisen malleja. Toistaiseksi tekoälymalleja on kokeiltu vain tutkimuksessa koska nykyisen lainsäädännön puitteissa ei voida automaattisesti käyttää rekisteridataa, jotta voitaisiin ottaa uudelleen yhteyttä riskiryhmään kuuluviin ihmisiin.
”Voimme laatia näitä kauniita malleja, mutta emme voi varoittaa riskiryhmäläisiä,” Ganna toteaa, mutta huomauttaa, että jos malleja yksinkertaistetaan tarpeeksi, niitä voidaan käyttää myös kliinisessä hoidossa.
Yhtenä esimerkkinä hän mainitsee RS-viruksen, jonka riskitekijöitä THL:n Markus Perola yhdessä FIMM:n Pekka Vartiaisen kanssa tutki FinRekisterit-hankkeessa. RS-virus (respiratory syncytial virus) on maailmanlaajuisesti yleisin pienten lasten hengitystieinfektioita aiheuttava virus. Tutkijat loivat yksinkertaistetun mallin, jota voitaisiin hyödyntää RSV:n kliinisessä hoidossa. Nyt Suomessa lääkärit voivat rekisteridatan perusteella tunnistaa, ketkä ovat vaarassa saada viruksen ja kenelle voisi antaa ajoissa hoitoa.
Andrea Ganna uskoo, että tulevaisuudessa terveydenhuolto hyötyy tekoälymalleista, joka ymmärtää terveysdataa.
”Tekoäly tukee päätöksentekoa auttamalla lääkäreitä paremmin tekemään yhteenvetoja heidän potilaidensa terveyden kehityskuluista. Tulevaisuus on valoisa.”
Ari Turunen
30.5.2024
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). An AI model that understands health data warns of future diseases. https://doi.org/10.5281/zenodo.13691998
Lisätietoja:
Suomen molekyylilääketieteen instituutti (FIMM)
FIMM on osa Helsingin yliopiston HiLIFE Helsinki Institute of Life Science -tutkimuskeskusta.
https://www.helsinki.fi/en/hilife-helsinki-institute-life-science/units/fimm
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Finnish Use Cases 2-julkaisuissa esitellään kattavasti suomalaista biolääketieteellistä tutkimusta, jossa on hyödynetty eurooppalaisen biolääketieteen infrastruktuurin ELIXIRin resursseja. ELIXIR-infrastruktuuriin on liittynyt lähes 200 tutkimusorganisaatiota ja vaikuttaa yli puolen miljoonan tutkijan työhön Euroopan maissa. Suomen toiminnoista vastaa CSC – Tieteen tietotekniikan keskus Oy.
Julkaisussa esitellään erilaisia tutkimuksia, joissa hyödynnetään uusia bioinformatiikan menetelmiä. Aiheet käsittelevät lääkeainesuunnittelua, tautien syntymekanismeja, solujen mallintamista, mikrobiomeja, tekoälymallien hyödyntämistä diagnostiikassa ja personoituja lääkehoitoja.
Biolääketieteellinen tutkimus on muuttunut data- ja laskentaintensiiviseksi. Datan analyysi tarvitsee koko ajan kehittyneempiä ohjelmistoja ja niiden yhdistelmiä. Lisäksi tutkijat tarvitsevat palveluita ja resursseja datan tallentamiseen ja sen kuvailuun jatkokäyttöä varten.
Esimerkiksi translationaalinen eli niveltävä lääketiede hyödyntää perustutkimusta kliinisessä tutkimuksessa ja toisaalta potilasnäytteitä ja tautimalleja tautimekanismien ja lääkevaikutuskohteiden selvittämisessä. Lähtökohtana on poikkitieteellisyys, joka auttaa tutkimuksen ohella myös potilaita. Monen eri datalähteen yhdistämisen lähtökohta on, että saataisiin enemmän tietoa esille. Yhdistäminen on hyvin paljon laskennallista ja siihen tarvitaan CSC:n resursseja ja ELIXIRin tapaisia infrastruktuureja.
CSC on kehittänyt erityisesti sensitiivisen datan palveluja infrastuktuuriin.
”Ihmisistä tuotetun tutkimusdatan hallinta pitää tehdä ammattitaitoisesti, ja tämä on ELIXIR Suomen yksi tärkeimmistä tavoitteista. Yhdistettynä laadukas sensitiivisen datan hallinta ja suurteholaskenta luovat ennennäkemättömiä mahdollisuuksia suomalaisille tieteentekijöille luoda malleja, jotka ennustavat ihmisten terveyttä, jolloin jokainen meistä hyötyy, ekosysteemi pitää vaan saada toimimaan yhteen”, korostaa Suomen ELIXIR-keskuksen johtaja Tommi Nyrönen.
Vuonna 2013 Euroopassa aloitettiin biotieteiden infrastruktuurin ELIXIRin rakentaminen. ELIXIR turvaa biolääketieteen tutkijoiden pääsyn biologisen datan tietokantoihin ja sen käsittelyyn tarvittaviin laskentaresursseihin, ohjelmistoihin ja niiden käytön koulutukseen. CSC:ssä oli huhtikuuhun 2024 mennessä 2386 biolääketieteen ja terveysalan tutkijaa asiakkaina.
Lue raportti täältä:

CSC oli mukana johtamassa eurooppalaista B1MG-projektia (Beyond One Million Genomes), joka keskittyi luomaan genomidatan käytölle turvallisen rajat ylittävään federoituun infrastruktuurin. Nyt hanketta seuraa genomidatan infrastruktuuri GDI, joka mahdollistaa tutkijoiden pääsyn eurooppalaiseen genomidataan ja kliiniseen dataan.
Tavoitteena on parantaa diagnostiikkaa ja farmakogenomiikkaa eli toisin sanoen perintötekijöiden yksilöerojen vaikutusta lääkevasteeseen. Toinen tavoite on tukea tutkimuksessa käytettävän datan toisiokäyttöä. Arvokasta dataa kerätään potilasaineiston perusteella syövistä, harvinaisista ja polygeenisistä (monitekijäisistä) sairauksista. Aineistoa on saatu myös sairautta aiheuttavista patogeeneistä sekä infektiotaudeista, kuten esimerkiksi COVID-19-viruksesta.
Tämä data voi luoda pohjan yksilöllisille lääkehoidoille, jossa hyödynnetään polygeenistä riskiarvioita. Geneettinen riski lasketaan henkilökohtaisen polygeenisen riskisumman (polygenic risk score, PRS) avulla, jossa on otettu huomioon miljoonia geneettisiä variaatioita.

Kolmivuotinen B1MG-projekti päättyi lokakuussa 2023. B1MG-hankkeessa Suomen ELIXIR-keskus CSC johti teknistä infrastruktuurityötä.
”B1MG oli koordinaatio- ja tukihanke, jonka tehtäväksi annettiin tiekartan ja parhaiden käytäntöjen määrittäminen vaadittavan infrastruktuurin käyttöönottamiseksi ja 1+Million Genomes -aloitteen tavoitteen tukemiseksi. CSC yhtenä teknisen infrastruktuurin työpaketin johtajana pystyi viemään sellaiset päätökset tiekarttaan, joilla varmistettiin, että ne olivat linjassa CSC:n nykyisen ja tulevien edellytysten, kuten sensitiivisen datan palvelujen, kanssa”, sanoo vanhempi koordinaattori tohtori Dylan Spalding CSC:stä.
Spalding työskenteli B1MG-projektissa yhden työpaketin toisena johtajana. Työpaketti keskittyi yksilölliseen lääkehoitoon.
”B1MG:n todellinen hyöty on siinä, että se on asetellut suunnan GDI-projektille, joka laittaa täytäntöön Euroopan laajuisen federoidun infrastruktuurin tukemaan rajat ylittävän pääsyn yli miljoonaan genomiin. Tässä on potentiaalia auttamaan tutkimuksen demokratisoitumista ja edistämään yksilöllistä lääkehoitoa EU:ssa.”
CSC:llä yhtenä infrastruktuuri-pilarin vetäjistä on johtava rooli tässä työssä. Myös Life Science AAI (Authentication and Authorization Infrastructure) ja REMS (Resource Entitlement Management System ) ovat sovelluksia, jotka ovat jo käytössä tukemassa dataan pääsemisen hallinnassa. Spaldingin mukaan tämän pitäisi olla hyvin linjassa jo olemassa olevan federoidun EGA-solmupisteen ja sensitiivisen datan palveluiden kanssa. Federoitu EGA (European Genome-phenome Archive) on hajautettu ratkaisu ihmisistä kerätyn omiikka-datan jakamiseen ja vaihtamiseen yli valtion rajojen.
”GDI on erittäin tärkeä harvinaisten sairauksien tutkimiselle ja yksilölliselle lääkehoidolle, mutta myös syövän, tartuntatautien ja yleisten ja monimutkaisten tautien tutkimiselle. Silti, infrastruktuuri ei ole erikoistunut millekään tietylle taudille vaan tukee kaikkien tautityyppien tutkimista, Kehitystä sysää eteenpäin 1+ Million Genomes -projektin käyttötapaukset, kuten myös Genome of Europe-hanke, jonka tavoitteena on rakentaa 500 000 kansalaisen viitekohortit Euroopassa.
Spaldingin mukaan B1MG näytti toteen konseptitodistetun version Starter Kit -palvelusta, joka liittyy harvinaisten sairauksien ja syövän käyttötapauksiin. Starter Kit on kokoelma ohjelmistoja, jotka 20 GDI:n solmua ovat kehittäneet.
GDI:n rakentamisen pohjaksi on luotu Starter Kit. B1MG määritteli viisi toiminnallisuutta joita tarvitsee tukea – datan vastaanottaminen, datan etsiminen, dataan pääsyn hallinta, tallentaminen sekä käyttöliittymät ja käsittely.

Starter Kit sisältää yli 2500 synteettistä genomia ja fenotyyppistä dataa syövästä ja harvinaisista sairauksista. Se on ensimmäinen askel kohti tuotanto-infrastruktuuria.
”Starter Kit mahdollistaa pääsyn sensitiivisen genomiikka-dataan ja fenotyyppisen dataan sekö datan etsimisen ja analyysin. Valikoima synteettistä dataa sisältyy siihen jolloin voidaan havainnollistaa näitä toiminnallisuuksia ilman riskiä siitä, että oikeaa genomiikka-dataa ja fenotyyppistä dataa vuotaisi muualle.”
Kehittynyt versio Starter Kit-palvelusta integroidaan GDI:n portaaliin.

Spalding uskoo, että GDI:n valtava datamäärä mahdollistaa yksilölliset hoidot entistä paremmin
”GDI:llä on potentiaalia tukea koneoppimista ja tekoäly-menetelmiä nopeuttaen siirtymistä yksilölliseen lääkehoitoon.”
Professori Arto Mannermaan ryhmässä Itä-Suomen yliopistossa kehitetään genomidatan ja kliinisen datan perusteella oppivia algoritmeja, jotka tunnistavat ja ennustavat rintasyövän riskitekijöitä. Genomidata ja kliininen data yhdistetään tekoälymalliksi, joka auttaa paitsi sairastumisriskin määrittämisessä, myös yksilöllisten hoitosuunnitelmien tekemisessä.
Mannermaan ryhmässä luodaan tekoälymalleja kuvadatasta. Mitä muuta dataa pitäisi yhdistää kuvadataan, jotta parannettaisiin terveydenhoitoa?
”Olemme liittäneet kuvantamisdataan nyt genomitietoa. Mitä enemmän data-modaliteetteja voidaan yhdistää, sitä paremmin pystymme tunnistamaan menestyksekkääseen syövän hoitoon liittyvät tekijät sekä todennäköisesti tunnistamaan tautiriskiin vaikuttavat tekijät.”
Tautiriskiin vaikuttavia tekijöitä ovat esimerkiksi tiedot hoitovasteesta tai muu hoitoon liittyvä kliininen tieto.
”Mitä enemmän dataa saamme käyttöömme, sitä isommaksi kasvavat laskentaympäristön vaatimukset. Liitännäisdataa voidaan saada esimerkiksi sähköisistä potilastietojärjestelmistä biopankkien kautta.”
Ari Turunen
29.4.2024
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). An infrastructure for genomic data. https://doi.org/10.5281/zenodo.13691595
Lisätietoja:
Genomic Data Infrastructure
https://gdi.onemilliongenomes.eu
Beyond One Million Genomes
https://b1mg-project.eu/1mg/genome-europe
Itä-Suomen yliopisto
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

BeYond-COVID-projektin (By-COVID) tavoitteena on saattaa eri Euroopan maista kerätty COVID-19 data tutkijoiden, sairaaloiden ja julkishallinnon saataville. Datan tunnistaminen, yhdistäminen eri lähteistä ja sen integroiminen analyysejä varten on iso urakka. Tähän haasteeseen on tarttunut 53 organisaatiota 19 eri maasta. Suomesta mukana on THL ja Tampereen yliopisto. Suomesta THL:ssä kerättyä dataa on käsitelty CSC:ssä.
THL:n tutkimusprofessori Markus Perolan mukaan By-COVID-projekti yksinkertaisesti valmistautuu seuraavaan pandemiaan analysoimalla COVID-19 dataa.
”Nyt pilotoidaan, miten tällaista yhteistyötä voidaan tehdä kun seuraava pandemia tulee. Tämä näyttää olleen tarpeen.”
Perolan mukaan datan harmonisaatiota todella tarvitaan Euroopan maiden kesken.
”Esimerkiksi eri maiden käsitykset, mitä pidetään COVID-tartuntaketjuissa olennaisina tekijöinä voivat poiketa paljonkin toisistaan.”
Perola käyttää lähes kaikissa tutkimuksissaan CSC:n laskentaa ja sensitiivisen datan tallennus- ja analyysipalveluja. Geneettisen aineiston lisäksi hän hyödyntää paljon rekisteriaineistoja. By-COVID-projektissa hänen tutkimusryhmänsä on hyödyntänyt suomalaisia tartuntatautirekistereitä sekä Tilastokeskuksesta saatua kuolinsyydataa. Dataa käytetään yhteisiin -analyyseihin By-COVID-projektissa. THL:n raakadata on käytettävissä CSC:n sensitiivisen datan palveluissa, mutta se ei poistu Suomen rajojen ulkopuolelle. Tämän lisäksi By-COVID-hanke kerää tietoa viruksesta itsestään. Tämä tieto on avointa tutkimusdataa.
”THL osallistuu hankkeessa yhteen työpakettiin, jossa federoidusti analysoidaan eri maista saatua rekisteridataa. Hankkeessa poimitaan tiettyjä asioita eri rekistereistä ja yhdistetään niitä ja edetään yhteiseen analyysin Euroopan laajuisesti.”
Suomesta kerätty rekisteridata pitää sisällään kaikki Suomen asukkaat, joilla on henkilötunnus.
Markus Perolan mukaan tällainen datan kerääminen ja analysoiminen on välttämätöntä tehdä. Hänen mielestään olisi jopa epäeettistä jättää käyttämättä tärkeä tieto, joka Euroopan kansalaisista kerätään.
”Miksi dataa kerätään, jos sitä ei käytetä? Tilastointi on tärkeää, mutta se ei riitä, että informaatio saadaan siirrettyä kliiniseen työhön tai yhteiskuntapoliittiseen päätöksentekoon. Tähän tarvitaan vertaisarvioitua tieteellistä tutkimusta ja sitä By-COVID tarjoaa.”
Projekti päättyy syksyllä 2024.

By-COVID-projektin sivuilla on saatavilla COVID-19-dataa sisältämä portaali. Hanketta koordinoi ELIXIR-infrastruktuuri, jonka jäsenorganisaatio EMBL-EBI on koonnut portaalin tärkeimmät koronaviruksen data-aineistot. Tutkijat pääsevät portaalin kautta analysoimaan COVID-19 viitedataa. Se sisältää yli 8 miljoonaa COVID-viruksen sekvenssiä.
Suomen Akatemia rahoitti Suomen ELIXIR-keskuksen CSC:n kokeilua, jossa portaalin sisältämää dataa analysoitiin ja testattiin Suomen LUMI-supertietokoneella. Työ tukee By-COVID-hanketta: CSC:n tärkeä tehtävä on edistää supertietokoneiden käyttöä dataintensiivisessä laskennassa.
Suomen ELIXIR-keskuksen johtajan Tommi Nyrösen mukaan projekti selviytyi monista teknisistä datan hallinnan haasteista
“Laskennan työvuot Euroopan bioinformattikan instituutista EMBL-EBI:stä mahdollistivat COVID-19 – virusdatan analysoimisen ja tämä työ tehtiin yhteistyössä CSC:n ja EMBL-EBI:n asiantuntijoiden kanssa.. Eurooppalaisessa superlaskennassa voimme nyt siirtää satoja tuhansia viruksen datapisteitä päivittäin laskentakeskusten välillä ja tässä apuna ovat eurooppalaiset tutkimusverkot.”
Tästä seuraa, että supertietokoneen kapasiteettia tarvitaan tulevaisuudessa analysoimaan koko dataa.
“Tätä vaaditaan nopean vastatoimen takia pandemian ollessa kyseessä ja myös COVID-19-portaalissa olevan datasta saadun tiedon päivittämiseksi.”
Ari Turunen
1.4.2024
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). European research community preparing for next pandemic. https://doi.org/10.5281/zenodo.13691578
FIRI
Suomen Akatemia on tukenut artikkelin tuotantoa apurahalla numerolla 345591, joka on myönnetty FIRI 2021-hankkeelle ”ELIXIR European Life-Sciences Infrastructure for Biological Information”.
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Oulun yliopiston evolutiivisen lääketieteen dosentti Ville Pimenoff käyttää paljon CSC:n superlaskentaympäristöä ja sensitiivisen datan palveluja tutkiessaan viruspopulaatioiden genetiikkaa ja ihmisen biologisia ympäristöaltisteita. Pimenoff on erikoistunut biopankkipohjaiseen ympäristöaltisteiden ja ihmisen eksposomin tutkimiseen. Eksposomi tarkoittaa sitä kokonaisuutta, mille ihminen elinaikanaan altistuu elinympäristössään. Eksposomitutkimus pyrkii ymmärtämään, mikä vaikutus ekposomin eri osa-alueilla on ihmisen terveyteen.
Yksi Pimenoffin viimeaikaisista tutkimuksista osoitti, että HPV-rokote suojaa tehokkaasti syöpää aiheuttavilta papilloomaviruksilta, mutta muuttaa samalla merkittävästi jäljelle jäävien vähemmän syöpää aiheuttavien papilloomavirusten ekologista dynamiikkaa.
Pimenoff teki väitöskirjansa suomalaisten ja suomensukuisten kansojen geneettisestä historiasta. Tällä hetkellä hänellä on kymmenen tutkimushanketta, joissa teemana on ihmisiä infektoivien mikrobien evolutiivis-ekologinen tarkastelu.
”Minun työni keskiö on laskennallinen genetiikka ja metagenomiikka, joka tarkoittaa sitä, että tutkimusnäytteestä pyritään DNA-sekvensoinnilla analysoimaan eri eliöistä ja mikrobeista lähtöisin oleva DNA. Käytännössä tämä tarkoittaa sitä, että tutkimusaineistot ovat datan määrältä usein kymmeniä, joskus jopa satoja teroja sekvenssidataa.”
Pimenoffin tutkimus virusten ja muiden mikrobien geneettisestä muuntelusta vaatiii paljon laskentaa ja datan käsittelyä.
Tiede tuntee jo yli 200 eri papilloomavirusta, jotka infektoivat ihmistä. Osa näistä HPV-viruksista on yleisimpiä seksin välityksellä tarttuvia viruksia, jotka aiheuttavat kohdunkaulan syöpää. Käytännössä suurin osa suomalaisista saa jossakin elämänsä vaiheessa tällaisen syöpää aiheuttavan HPV-tartunnan, yleensä nuorena. Jos infektio jää pysyväksi, se voi kehittyä syövän esiasteeksi ja lopulta muuttua syöväksi. Kohdunkaulan syöpä liittyy lähes aina pitkäkestoiseen HPV-tartuntaan.
Tämän vuoksi on kehitetty HPV-rokote, joka antaa suojaa erityisesti kohdunkaulan syöpää vastaan, mutta se tehoaa myös muiden genitaalialueiden sekä suun ja nielun alueiden HPV-infektioiden aiheuttamiin syöpiin. Pimenoffin mukaan HPV- virusten evolutiivinen tarkastelu osoittaa, että HPV-rokotteen antama laumasuoja on tehokas tapa suojata väestöä HPV:n aiheuttamilta syöviltä, etenkin kun sekä tytöt että pojat rokotetaan. Lisäksi väestön riittävä rokottaminen muuttaa jäljelle jäävien vähemmän syöpää aiheuttavien papilloomavirusten ekologista dynamiikkaa.
“Tämä johtaa siihen, että kohdunkaulan syövän seulonta HPV-infektioiden osalta tulee lähitulevaisuudessa keventää tai lopettaa rokotetuilta seulonnat kokonaan.”
Pimenoffin tutkimusala on evolutiivinen lääketiede ja genomiikka.
”Lääkäri tarkastelee papilloomavirusta infektiona, joka saattaa aiheuttaa potilaalle syövän. Epidemiologi tutkii infektion osalta, onko väestön elintavoista löydettävissä tekijöitä, jotka lisäisivät riskiä, että infektio johtaa syöpään.”
Pimenoff tarkastelee infektioita viruspopulaatioiden näkökulmasta.
“Minun näkökulma on, että väestössä kiertää aina suuri määrä viruksia. Yritän ymmärtää sitä dynamiikkaa, millä nämä miljoonat virukset väestössä leviävät ja aiheuttavat tauteja ja miten tämä viruspopulaation dynamiikka muuttuu, jos esimerkiksi iso osa väestöstä rokotetaan osaa viruksia vastaan. Eli tutkin virusten populaatiotason dynamiikkaa sekä lyhyellä että pitkällä evolutiivisella aikaskaalalla.”
Papilloomaviruksia tutkiessaan Pimenoffin aineistona oli 33 suomalaista kaupunkia, joista noin 22 000 nuorta monitoroitiin 16 vuotta sen jälkeen kun suurin osa heistä oli saanut HPV-rokotteen. Tutkimusaineisto on maailman suurin paikkakuntakohtaisesti satunnaistettu rokotus-kohortti, joka mahdollisti erinomaisen asetelman tarkastella papilloomavirusten evolutiivista dynamiikkaa siinä väestössä, joka oli rokotettu ja verrata siihen osaan väestöä, jota ei rokotettu.
”Tästä kohortti-aineistosta tietokoneavusteisesti simuloin puolen miljoonan suomalaisen nuoren naisen HPV-infektioiden prevalenssiaineiston. Tähän simulointiin ja siitä saadun synteettisen ja alkuperäisen aineiston muokkaamiseen ja tarkasteluun hyödynsin CSC:n laskentatehoa ja sensitiivisen datan virtuaalipilveä.”
Synteettistä dataa voi analysoida CSC:n kaikissa palveluissa. Sensitiivisen datan käsittelyyn on tarkoitettu oma palvelunsa.

Virusten genomiikkaan liittyvien projektien lisäksi erityisesti ympäristöaltisteiden tutkimuksessa Pimenoff käyttää paljon CSC:n palveluja.
”Olemme Suomessa rekrytoineet sata naista ympäristöaltisteiden eksposomi-tutkimukseen. Tutkimusaineistossa osa naisista on raskaana. Naiset kantavat neljän kuukauden ajan mukanaan pientä ilmapumppua, jota kutsumme eksposomi-mittariksi. Se kerää filtteriin pienhiukkasia, kuten bakteereja, sieniä ja kemiallisia hiukkasia. Eksposomi-mittareiden filtterit vaihdetaan kahden viikon välein, jolloin saadaan pitkä mahdollisten ympäristöaltisteiden näytesarja. Filttereistä eristetään mikrobien DNA, joka sekvensoidaan. Tästä saadaan ns. metagenominen seuranta-aineisto.”
Filttereistä saadaan myös massaspektrometrialla analysoituna selville erilaiset kemialliset yhdisteet, joille naiset ovat samana seuranta-aikana altistuneet. Näin, koska seurattavat on rekrytoitu eri paikkakunnilta, voimme arvioida ympäristöaltisteiden yhtäläisyyksiä ja erovuuksia Suomessa eri vuodenaikoina niin kaupungissa kuin maaseudulla.
“Käytännössä tällaisen aineiston käsittelyä ei voi tehdä muualla kuin suojatussa superlaskentaympäristössä ja CSC:n sensitiivisen datan palvelut mahdollistavat tämän. “

Pimenoff on rakentanut yhteistyössä CSC:n kanssa järjestelmän, jossa sensitiivisen datan analysointi voidaan jakaa myös yhteistyökumppaneille ulkomaille. Aineistoa siis käytetään saman CSC projektin sisällä yhteistyökumppanien kanssa eli tarvittaessa sitä voidaan jakaa vain tietyille tutkimusryhmille. Aineiston jakaminen tapahtuu SD Connect-palvelun kautta. SD Apply on työkalu, jolla voidaan myöntää lupia aineistoon.
”Voimme antaa luvan anonyymin datan analysointiin ulkomaalaisille yhteistyökumppaneillemme, mutta aineistot käsitellään vain CSC:n ympäristössä ja niitä ei voi siirtää ulkomaille. CSC:n työkalut sensitiivisen genomidatan analysoimiselle ovat nyt paremmat kuin aiemmin. CSC on tehnyt hyvää kehitystyötä,” Pimenoff kehuu.
Haasteita on kuitenkin edelleen CSC:n systeemin datan käsittelyssä ja käyttäjäystävällisyydessä. Miten käsitellä mahdollisimman jouhevasti isoja aineistoja ja miten käyttöoikeudet jaetaan eri aineistoille? Entä miten käyttöoikeuksia voi ketterästi hallinnoida, jos on CSC:n asiakkaana useissa eri projekteissa? Sensitiivisen datan palveluiden käyttöliittymää pitäisi Pimenoffin mielestä kehittää, jotta suurten data-aineistojen analysoiminen ulkomaalaisten yhteistyökumppanien kanssa tulisi joustavammaksi.
Ari Turunen
8.3.2024
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). Evolutionary dynamics of viruses and other microbes affect human health. https://doi.org/10.5281/zenodo.13691466
Lisätietoja:
FIRI
Suomen Akatemia on tukenut artikkelin tuotantoa apurahalla numerolla 345591, joka on myönnetty FIRI 2021-hankkeelle ”ELIXIR European Life-Sciences Infrastructure for Biological Information”.
Oulun yliopisto
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

THL yhteistyössä CSC:n kanssa on simuloinut miljoonan eurooppalaisen genomit. Simulointiin käytetty data oli aitoja julkisesti saatavissa olevia koko genomin sekvenssejä, mutta simuloinnissa niistä muodostettiin synteettisiä genomeja, jolloin ne eivät kerro oikeista ihmisistä. Simulointi tehtiin CSC:n LUMI-supertietokoneella. Tämä on yksi suurimpia ihmispopulaation perimän simulaatiota maailmassa. Simulaatio tehtiin EU:n 1+MG-aloitetta varten.
Vuonna 2018 EU julkisti 1+Million Genomes -aloitteen (1+MG), jonka kunnianhimoisena tavoitteena oli kerätä data, joka kattaa miljoonan eurooppalaisen ihmisen perimän. Projekti oli lajissaan yksi maailman suurimpia projekteja, johon osallistui 27 maata. Eurooppalaisen genomidatan tietoturvallinen käyttö mahdollistaa personoidun terveydenhoidon ja paremman diagnostiikan. Tämä parantaa erityisesti syöpien ja hermostollisten sairauksien hoitoennusteita.
Datakokoelma anonymisoidaan, joten yksiköllisiä ja tunnistettavia tietoja ei löydy. Tavoitteena on luoda kansalliset rajat ylittävä federoitu hallinto, jonka kautta on pääsy kansallisiin genomiarkistoihin.
”Minun näkökulmastani tämä 1+MG:n synteettisen datan projekti oli ainutlaatuinen haaste: miten imuloimme tehokkaasti populaation, jonka viimeisessä sukupolvessa on miljoona ihmistä ja joka vastaa kaikilta ominaisuuksiltaan, niin perimän, dataformaattien kuin kokonsa puolesta aitoa genomidataa, mutta on simuloituna täysin vapaasti jaettavissa ilman tietoturva-ongelmia? Loppujen lopuksi me simuloimme n. 25 miljoonan ihmisen populaation, joista vain hieman yli miljoonalle teimme synteettiset genomit. Tällainen datakokoelma mahdollistaa lukuisat erilaiset tutkimus-, harjoittelu- ja kehittämisprojektit, kuten 1+MG, ilman eettisjuridisia haasteita ja tietoturvaesteitä”, sanoo dosentti Tero Hiekkalinna THL.stä.
Nyt simuloitiin miljoonan ihmisen synteettinen aineisto kymmenine fenotyyppeineen. Mukana oli siis tietoja ympäristön aiheuttamista vaikutuksista yksilöiden fenotyyppeihin.
Miljoonan genomin simuloinnin rahoittivat Suomessa sosiaali- ja terveysministeriö sekä opetus-ja kulttuuriministeriö. Hiekkalinnan mukaan aineiston luomisessa ja hallinnassa oli valtavia haasteita.
”Aineistojen koko projektin aikana vaati kymmeniä teratavuja levytilaa.”
1+MG-aloitetta seurasi vuonna 2020 alkanut B1MG (Beyond 1 Million Genomes), joka päättyi tammikuussa 2024. B1MG-projektissa määritettiin suuntaviivat ja suositukset eri Euroopan maista saadun genomidatan federoidulle hallinnolle. Suomen ELIXIR-keskus CSC oli yksi hankkeen vetäjistä ja koordinaattoreista. Biopankkien toimintaa yritetään saada yhteensopivaksi valtakunnan rajat ylittävään datainfrastruktuuriin. B1MG-hankkeessa CSC johti teknistä infrastruktuurityötä.
THL:n ja CSC:n simuloima miljoonan genomin data laitetaan saataville eurooppalaiseen federoituun genomi-fenomi-arkistoon (FEGA). FEGA on on tarkoitettu biolääketieteellisten tietojen tallentamiseen ja jakamiseen tutkimusta varten, mutta dataa ei ole tarkoitus levittää täysin julkisesti. Suomen tietokantaa ylläpitää CSC. FEGA on yhteydessä Euroopan genomi-fenomi arkistoon (EGA). EGA on yksi maailman laajimmista julkisista datavarastoista.
Sama simuloitu data on tulevaisuudessa myös GDI-projektin käytössä. Vuonna 2022 käynnistettyä genomidatan infrastruktuuria (Genomic Data Infrastructure) koordinoi ELIXIR. GDI:n tarkoituksena on luoda lopullinen infrastruktuuri, joka mahdollistaa pääsyn eurooppalaisista kerättyyn genomidataan sekä kliiniseen dataan.
Tulevaisuudessa eurooppalaisia odottavat entistä nopeammat ja tarkemmat diagnoosit. Kerätty ja analysoitu genomidata mahdollistaa paremman lääkeainesuunnittelun ja ennaltaehkäisevät lääkehoidot. Kaikki tämä johtaa parempaan terveyteen ja elinajanodotteeseen. Tämän mahdollistamiseksi tarvitaan datan esikäsittelyä ja harmonisointia, kuten myös tietoturvallisia, skaalautuvia ja joustavia teknisiä ratkaisuja.

Nähin toisiinsa liittyvissä kolmessa hankkeessa hyödynnetään viittä käyttötapausta. Nämä käyttötapaukset ovat olennaisia lopullisen GDI-infrastruktuurin rakentamiselle. Euroopan genomi (Genome of Europe) luo viitedatakokoelman genomiikkaa hyödyntäville terveysohjelmille Euroopan maissa: kukin maa luovuttaa genomidataa suhteessa väkilukuun. Datamalli kehitetään syöpään liittyvästä kliinisestä informaatiosta ja genomiikasta saadusta metadatasta. Monigeeninen riskisumma (polygenic risk score, PRS) luodaan potilaan hoitoon liittyvää päätöksentekoa varten: yksilöllisessä riskisummassa otetaan huomioon miljoonia geneettisiä variaatioita. Harvinaisissa sairauksissa olennaista on geenivarianttien esiintyminen eri populaatioissa ja geenimutaation ja sairauden yhteyden selvittäminen. Lisäksi testataan Euroopan maiden välillä kunkin maan keräämän COVID-19-datan jakamista.
Ari Turunen
2.3.2024
Lue artikkeli PDF-muodossa
Sitaatti
Nyrönen, T., & Turunen, A. (2024). A million European genomes. https://doi.org/10.5281/zenodo.13691032
Lisätietoja:
Hiekkalinna, Tero; Heikkinen, Vilho; Perola, Markus; Terwilliger, Joseph (2023):
Simulated European Genome-phenome Dataset of 1,000,000 Individuals for 1+Million Genomes Initiative.
1+MG Framework
https://framework.onemilliongenomes.eu
Beyond 1 Million Genomes (B1MG)
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Tutkijat voivat siirtää laskentansa Googlen Colabista CSC:n ympäristöön uuden sovelluksen avulla. Samanlaista menettelytapaa voidaan soveltaa, jos halutaan vaihtaa yhdestä superlaskentaympäristöstä toiseen.
CSC – Tieteen tietotekniikan keskuksen sovellusasiantuntija Laxmana Yetukuri ja Turun biotiedekeskuksen erikoistutkija Michael Courtney ovat kustomoineet grafiikkaprosessoreilla varustettujen kannettavien tietokoneiden liittämisen CSC:n superlaskentaympäristöön, jotta niitä voidaan käyttää syväoppimisen mallien luomiseen biologisesta kuvantamisdatasta. Kannettavat laitteet on kehitetty Turun biotiedekeskuksen ryhmässä. Tarjolla on myös avoimen lähdekoodin työkalupakki ImageJ/Fiji syväoppimisen mallien luomiseen mikroskopiassa. Sen käyttöä tutkitaan CSC:ssä, ELIXIR-infrastruktuurin Suomen noodissa.
Turun biotiedekeskuksessa on käytetty Googlen Colab Notebook -pilvipalvelua, jonka kautta voi analysoida ja visualisoida dataa. Laajan skaalan data-intensiivinen tutkimus kohtaa kuitenkin rajoitteita, kun käytetään Googlen maksuttomia palveluja. Tutkijat tarvitsevat huomattavasti peruskäyttäjää enemmän tallennus- ja laskentakapasiteettia datankäsittelyyn. CSC:n superlaskentaympäristö tarjoaa akateemisille käyttäjille ylivertaisen maksuttoman tallennus- ja laskentakapasiteetin, ja nyt Google Colab-ympäristön voi vaihtaa CSC:n laskentapalveluun. Henkilökohtaisella tietokoneella pääsee helposti CSC:n laskentaympäristöön web-selaimen avulla, kiitos käyttäjäystävällisen käyttöliittymän.
Tutkijat voivat siirtää laskentansa Googlen Colabista CSC:n ympäristöön käyttämällä sisäisesti kehitettyä konttitekniikkaa. Sovellusten kontittamisen (container wrapper) avulla tutkijat saavat määrittää vakioidun ympäristön, jossa he voivat ajaa tieteellisiä ohjelmistojaan. Ohjelman koodi kirjastoineen ja asetuksineen asetetaan konttiin. Kun ohjelmistot ja data on paketoitu kontissa omaan wrapper-työkaluun, seuraavat käyttäjät voivat aloittaa sovelluksen käytön ilman esiasennuksia. Samanlaista menettelytapaa voidaan soveltaa, jos halutaan vaihtaa yhdestä superlaskentaympäristöstä toiseen.
”Teemme tutkijoiden työn helpommaksi. Meillä on helpot ohjeet sovelluksen asentamiseen kustomoituihin tietokoneisiin. Kun projektin jäsen asentaa sovelluksen, muiden tutkijoiden ei tarvitse asentaa mitään ohjelmistoja käyttääkseen näitä kustomoituja koneita, vaan he voivat heti aloittaa työskentelyn. CSC:n laskentaympäristöön pääsee käyttöliittymän (www.puhti.csc.fi) avulla muutamalla klikkauksella”, sanoo Yetukuri.
”Biologinen kuva-analyysi tarvitsee laajempaa levytilaa tallentamiseen. CSC:n ALLAS tarjoaa hyvän tallennusympäristön. Laskentaympäristöön pääsee, kun on saanut käyttäjätunnuksen CSC:ltä”, Yetukuri jatkaa.
Biologinen kuvantaminen ja kuvien data-analyysi hyödyntää algoritmeja, joiden avulla saadaan kuvista merkittävä määrä lisää informaatiota. Informaatiota voidaan käyttää hahmontunnistukseen ja kuvadatan luokitteluun, jolloin saadaan biologisesti merkittävää informaatiota. Tässä käyttötapauksessa Yetukurin ja Courtneyn tarkoitus on kehittää koneoppimisen malleja aivohäiriöitä aiheuttavien SynGAP1-geenivarianttien tunnistamiseen sekä tulevaisuudessa lääkeseulontaan.

Courtney, tutkijatohtori Li-li Li ja heidän kollegansa selvittävät Turun biotiedekeskuksessa SynGAP1-proteiinien tautia aiheuttavia variantteja. SynGAP1-geeni sijaitsee kuudennessa kromosomissa ja tuottaa SynGAP-proteiinia. Proteiini säätelee synapseja, joiden kautta hermosolut kommunikoivat toistensa kanssa. SynGAP1-geenin variantti aiheuttaa sen, ettei SynGAP-proteiinia muodostu riittävästi. Tämä johtaa siihen, että hermosolujen välinen viestintä vaikeutuu. Tämä puolestaan johtaa monin neurologisiin sairauksiin. Normaaliin aivojen kehittymiseen tarvitaan kaksi virheetöntä geeniä, jotka koodaavat SynGAP1-proteiinia. Mutaatiot voivat johtaa siihen, että toinen geeni ei ilmenny, jolloin tulee kehitysviiveitä.

SynGAP1-enkefalopatia on varhain ilmenevä älyllinen kehitysvamma. Sairaudenkuvalle ominainen kehitysviive havaitaan pääsääntöisesti ensimmäisen tai toisen ikävuoden aikana. Lisäksi noin kahdeksalla enkefalopatia-potilaalla kymmenestä todetaan epilepsia. Epilepsian oirekuva vaihtelee yksilöllisesti, ja se voi olla vaikeahoitoinen. Käyttäytymishäiriöitä ja autismia ilmenee puolella potilaista.
Turun biotiedetiedekeskuksen mikroskopian seulontayksikössä analysoidaan normaaleja SynGAP1-geenejä sekä pistemutaatioita, jotka voivat aiheuttaa proteiinin toiminnan heikentymistä, joissain tapauksissa lähes olemattomalle tasolle. Pistemutaatiot muuttavat vain yhden aminohapon proteiinissa, mutta se mitä tästä seuraa, vaatii lisäselvyyttä.
SynGAP1-proteiini esiintyy vain hermosoluissa. Korkean suoritustehon mikroskoopilla voidaan tarkastella samanaikaisesti 384 elävän hermosolun verkkoa ajan myötä. Hermosoluissa SynGAP1 merkitään fluoresentilla proteiinin tunnisteella, joka voidaan havaita virittyneellä valolla. Jokaisessa hermoverkossa normaali SynGAP1 tai erilainen sairautta aiheuttava muoto voidaan tutkia. Kuvien perusteella voidaan havainnoida poikkeavuuksia proteiinien toiminnassa.

Mikroskooppi tekee automaattisen kuvakaappauksen ja voi ottaa näytteitä hermoverkoista 20 sekunnin välein. Kun tutkitaan proteiinin eri variantteja, voidaan verrata, onko sen toiminta normaalia, tehostunutta tai kokonaan lakannut. Tehostunut tai lakannut toiminta voi johtaa sairauteen.
”Olemme pystyneet tekemään koe- ja analyysijärjestelyitä, jotka selvittävät tavallisuudesta poikkeavia vaurioituneen SynGAP1:n toimintoja. Tämä mahdollisesti tarjoaa tulevaisuudessa väylän lääkeaineseulontaan. On myös sairastuneista potilaista löydettyjä geenivariantteja, mutta ei tiedetä, miten tai ovatko ne ylipäätään aiheuttaneet sairauden. Menetelmämme avulla voimme havaita, onko näillä geenivarianteilla samanlainen puutteellinen toiminto kuin tiedetyillä sairautta aiheuttavilla varianteilla”, sanoo Michael Courtney.
Kun näytteiden valmisteluun liittyvät vaatimukset olivat täyttyneet, olennainen askel oli kehittää syväoppimisen malli, joka automatisoi SynGAP1-pisteiden (puncta) tunnistamisen. Ne ovat yleensä synapseissa. Pisteet ovat erillisiä kuva-alueita, joissa fluoresentti tunniste on näkyvissä.
”Kun nämä on tunnistettu, niiden lukumäärä ja noin 25 ominaisuutta jokaisesta alueesta voidaan poimia. Kun tämä on näytetty toteen, tämä lähestymistapa on tulevaisuudessa erittäin arvokas lääkeseulonnoissa. Seulonnoissa jokainen pistemutaatio altistetaan jokaiselle seulontakirjaston peräti 4000 erilliselle lääkeaineelle.”
Courtneyn mukaan vain lääkeaineita testaamalla on toivoa löytää yhdiste, joka on jo tunnettu kliinisestä turvallisuudesta ja siedettävyydestä. Tämä informaatio on korvaamaton kliinikoille ja potentiaalinen oikotie hyötyjen saamiseksi potilaille.
”Kun tutkimme harvinaisia sairauksia ja proteiinin erilaisia variantteja, on erittäin vaikeaa toteuttaa minkäänlaisia kliinisiä kokeita tehokkaiden lääkkeiden löytämiseksi puhumattakaan jopa eläinmallien tuottamisesta. Tämä tautia aiheuttavien varianttien moninaisuus on erittäin haastavaa. ”
Ari Turunen
20.2.2024
Lue artikkeli PDF-muodossa
Sitaatti
Nyrönen, T., & Turunen, A. (2023). Efficient transfer and analysis of biological image data through web interfaces. https://doi.org/10.5281/zenodo.13691023
Lisätietoja:
Tutkimusta on rahoittanut SynGAP Research Fund US,EU, ja Leon and friends e.V.
A free and open-source notebook for Deep-Learning in microscopy at CSC. Possibility to run Google Colab notebooks at CSC HPC environment via the web interface.
GitHub: https://github.com/yetulaxman/ZeroCostDL4Mic
The story behind ZeroCostDL4Mic, or How to get started with using Deep Learning for your microscopy data
Democratising deep learning for microscopy with ZeroCostDL4Mic
https://www.nature.com/articles/s41467-021-22518-0
Turun biotieteen keskus
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Rintasyöpäpotilaan verinäytteestä voidaan eristää syöpäsolun DNA:ta, jonka pilkkoutumisasteesta pystytään arvioimaan onko potilaalla huono tai hyvä hoitoennuste.
Rintasyöpä on naisten yleisin syöpä. Yli kaksi miljoonaa naista sairastui siihen vuonna 2020. Rintasyövän ennuste on onneksi parantunut, koska se on mahdollista havaita varhaisessa vaiheessa ja hoitomenetelmät ovat kehittyneet. Yksi tällainen on nestebiopsia, josta on tulossa yhä merkittävämpi syöpien diagnostiikan menetelmä.
Henkilökohtaisen lääketieteen ja biopankkitoiminnan professori Arto Mannermaan ryhmässä nestebiopsiaa on tutkittu vuodesta 2015 alkaen. Nestebiopsia perustuu siihen, että elimistön solut vapauttavat verenkiertoon ja ruumiinnesteisiin DNA:ta, jota kutsutaan solunulkoiseksi DNA:ksi (cell free DNA, cfDNA). Syöpäsoluista vapautuu siis potilaiden verenkiertoon DNA:ta, joka sisältää kullekin syövälle ominaisia mutaatioita. DNA sekvensoidaan, jolloin saadaan selville kasvaimessa olevat geneettiset muutokset.
”Solunulkoisesta DNA:sta olemme tutkineet sen pitoisuutta, pilkkoutumisastetta ja mutaatioita, jotka ovat yhteydessä rintasyöpäpotilaiden ennusteeseen. Vastaavanlaisia yhteyksiä löytyy myös useissa muissa syöpäsairauksissa”, sanoo tutkija Jouni Kujala. Hän työskentelee Mannermaan tutkimusryhmässä Itä-Suomen yliopistossa.
”Tämä on sellainen tutkimusaihe, jossa on ollut hyvinkin paljon laskennallista puolta, varsinkin sekvensointidatan työstämistä,” Kujala sanoo. Kujala aikoo keskittyä jatkossa solunulkoiseen mikro-RNA:han.
”Se on kokonaan toinen nukleiinihappotyyppi, mitä syöpäpotilaiden verinäytteistä voidaan eristää. Solunulkoinen mikro-RNA säätelee geenien toimintaa, eikä niiden ennusteellista arvoa vielä täysin ymmärretä.”
Mannermaan tutkimusryhmässä on tutkittu solunulkoisen DNA:n pilkkoutumista. Sen perusteella voidaan nyt arvioida rintasyöpäpotilaan hoitoennustetta. Tulos on merkittävä, sillä menetelmä auttaa tunnistamaan huonon hoitoennusteen rintasyöpäpotilaat aiempaa varhaisemmin ja tarkemmin. Varhainen tunnistus on keskeisimpiä keinoja vähentää rintasyövän kuolleisuutta.
Tutkijat ovat analysoineet solunulkoisen DNA:n eheyden syy-yhteyttä rintasyövän hoitoennusteeseen.
”Kun syöpäsolut vapauttavat solunulkoista DNA:ta verenkiertoon se alkaa pikkuhiljaa pilkkoutua pienemmäksi, kunnes se hajoaa kokonaan.”
Eheys kuvaa DNA:n pilkkoutumisastetta eli kuinka paljon DNA on veressä pilkkoutunut.
”Mitä eheämpää eli vähemmän pilkkoutunutta solunulkoinen DNA on, sitä enemmän se on yhteydessä huonoon rintasyövän ennusteeseen.”
Mannermaan ryhmän tutkimustuloksen mahdollisti mittava potilasaineisto, Kuopion rintasyöpäprojekti.
”Kuopion rintasyöpäprojekti kattaa yli 500 rintasyöpäpotilasta ja heistä on kerätty todella kattavat tiedot. Tiedämme heidän elintapansa ja heidän saamansa syöpähoidot. Meillä on seurantatiedot parhaimmillaan 25 vuoden ajalta, mikä on kansainvälisestikin poikkeuksellisen pitkä seuranta-aika.”
Tässä tutkimuksessa aineistoon oli valittu rintasyöpäpotilaita, joille ei oltu vielä aloitettu syöpähoitoja.
”Aineistossa oli varhaisen vaiheen rintasyöpäpotilaita, jotka olivat lähtökohtaisesti hyväennusteisia.”
Tällaisen aineiston valinnalle oli selkeä peruste, sillä rintasyöpä uusiutuu jopa kolmanneksella potilaista ja on naisten yleisin syöpäperäinen kuolinsyy. Mannermaan ryhmän tavoitteena on, että tulevaisuudessa aggressiivista rintasyöpää sairastavat potilaat voitaisiin tunnistaa nykyistä aikaisemmin eheysmittauksen avulla ja tarvittaessa ohjata tehostettuun hoitoon ja seurantaan.

Eheyden mittaus on menetelmänä yksinkertainen. Käytännössä eristetty näyte laitetaan mittauslaitteeseen, joka määrittää näytteessä olevien DNA-pätkien suhteellisen osuuden. Sitten voidaan laskea, mikä näytteessä olevan solunulkoisen DNA:n eheysaste on.
Kujalan mukaan näinkin yksinkertainen DNA-näytteen laatua kuvaava arvo voi olla käyttökelpoinen syövän ennusteen arvioinnissa. Tätä menetelmää voidaan jatkossa hyödyntää tekoälyn opettamiseen.

”Kun mitataan solunulkoisen DNA:n pitoisuutta ja eheyttä, nehän ovat puhtaasti laatumittareita. Niitä ei nykyisellään käytetä potilaan ennusteen arvioimisessa. Varsinainen diagnostinen puoli on pitkälti keskittynyt mutaatioihin ja muihin DNA:n piirteisiin. Koneoppiminen voisi hyödyntää tätäkin dataa nykyistä tehokkaammin. Tämä data joka tapauksessa kerätään kaikista näytteistä joita tutkitaan, mutta sitä ei juurikaan hyödynnetä.”
Mannermaan ryhmässä kehitetään genomidatan ja kliinisen datan perusteella oppivia algoritmeja, jotka tunnistavat ja ennustavat rintasyövän riskitekijöitä. Genomidata ja kliininen data yhdistetään tekoälymalliksi, joka auttaa paitsi sairastumisriskin määrittämisessä, myös yksilöllisten hoitosuunnitelmien tekemisessä.
Mannermaan ryhmän tutkimuksissa käyttämän datan määrä on niin iso, että siihen tarvitaan Suomen ELIXIR-keskuksen CSC:n superlaskentakapasiteettia.
”Meillä on CSC:n resursseja käytössä nimenomaan koneoppimisen takia. Toistaiseksi olemme kehittäneet syöpäriskin analytiikkaa, mutta samoja malleja hyödynnetään näiden nestebiopsiatulosten jatkotyössä. Vielä tätä dataa ole jatkotyöstetty”, sanoo professori Arto Mannermaa.
Ari Turunen
23.1.2024
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). Improving breast cancer treatment prognoses with liquid biopsy. https://doi.org/10.5281/zenodo.13691344
Lisätietoja:
Maria Lamminaho, Jouni Kujala, Hanna Peltonen, Maria Tengström, Veli-Matti Kosma ja Arto Mannermaa. High Cell-Free DNA Integrity Is Associated with Poor Breast Cancer Survival. Cancers. 2021.
https://doi.org/10.3390/cancers13184679.
Itä-Suomen yliopisto
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Rajat ylittävää terveysdataa ei ole päästy hyödyntämään kunnolla tutkimuksessa ja päätöksenteossa Euroopassa. Euroopan unionissa on vahva halu luoda infrastruktuuri terveystiedon ja sensitiivisen genomidatan toisiokäytölle. Tätä tarkoitusta varten syntyy Euroopan terveysdata-avaruus European Health Data Space (EHDS) ja sen HealthData@EU-ympäristö.
Koronaviruksen aiheuttama pandemia paljasti merkittäviä puutteita terveysdatan jakamisessa ja koordinaatiossa Euroopassa. Huomattiin, kuinka tärkeää on varmistaa suojattu pääsy terveysdataan yli jäsenvaltioiden rajojen, varsinkin kun ihmiset liikkuivat vapaasti EU:ssa pandemian aikana. Pandemian aikana päätöksentekijöillä oli hankaluuksia saada tarvitsemiaan sähköisiä terveystietoja. Myös yksilölliset lääkehoidot ovat mahdollisia vain, jos potilasdataa on tarjolla ja se on tallennettu, esikäsitelty ja luokiteltu yhdenmukaisella tavallakaikissa maissa.
Terveysdatan jakaminen yli rajojen on ollut yllättävän vaikeaa. Henkilökohtaisten terveystietojen ja geneettisten tietojen saatavuus digitaalisessa muodossa vaihtelee jäsenvaltioittain. Myös lainsäädäntö vaihtelee. EHDS varmistaa terveystietojen ensisijaisen ja toissijaisen käytön koordinoinnin ja yhdenmukaisuuden. Yhteistyölle luodaan nyt pysyvät rakenteet.
EHDS muuttaa terveydenhuoltoa merkittävästi seuraavien vuosikymmenten aikana. EHDS luo yhteisen alueen, jossa voidaan hallita ja siirtää sähköisiä terveystietoja, kuten potilaskertomuksia- ja rekistereitä ja genomidataa. Se antaa myös tutkijoille mahdollisuuden käyttää terveystietoja luotettavasti. Samalla yksityisyyden suoja säilyy.
”Samalla kun keskustellaan Euroopassa lainsäädännön puitteista, mennään kuitenkin eteenpäin rakentamalla infrastruktuuria. Myönteistä on, että asiantuntijoiden kuten tutkijoiden näkemyksiä on otettu huomioon lainsäädännössä. Isot pilotointihankeet aloitettiin jo ennen lainsäädäntötyötä,” sanoo THL:n ylilääkäri Persephone Doupi.
Hän työskentelee THL:n Aineistot- ja analytiikka-yksikössä kansainvälisten toisiokäytön tiedonhallinnan hankeiden koordinaattorina. Yksikkö edistää tietovarantojen monipuolista hyödyntämistä ja yhteentoimivuutta. Sen yhtenä tehtävänä on kehittää avoimen datan rajapintoja ja palveluita.
”Pitää miettiä datan koko elinkaarta, mallia ja toimintatapaa kokonaisuudessaan. Tämä näkyy erityisesti kun puhutaan tiedon laadusta ja standardoinnista eli miten tieto on eri tietojärjestelmissä semanttisesti yhteentoimivaa. Meidän pitäisi riittävän ajoissa tämä ymmärtää. Aivan olennaista on, miten terveydenhuollon ammattilaiset tekevät terveysaineistoista dokumentaatiot eri maissa”, sanoo Doupi.

THL ja Suomen ELIXIR-keskus CSC olivat mukana 25 maan TEHDAS-projektissa (Towards the European Health Data Space), joka päättyi heinäkuussa 2023. Tehdas oli yhteistoimintahanke, joka teki valmistelutyötä ja suosituksia EHDS:n toteutumisen edistämiseksi. Doupin mukaan terveysdatan hyödyntäminen asettaa uusia vaatimuksia erityisesti kun on kyse rajat ylittävästä toisiokäytöstä.
”TEHDAS-projektin tavoitteena oli selvittää millä tavalla rajat ylittävän/EU-tason datan toisiokäyttö voitaisiin organisoida ja millaista lainsäädäntöä tarvitaan. Mikä olisi tietolupaviranomaisten hallintomalli ja tehtävät ja miten organisoidaan pääsy dataan? Samalla selvitettiin, minkälainen tietojärjestelmäarkkitehtuuri ja tekniset ratkaisut olisivat sopivimmat ja miten varmistetaan tiedon laatu ja data-aineistojen yhteentoimivuus sekä minkälaisia standardeja on tarjolla.”
TEHDAS-projekti jatkuu TEHDAS-2-hankkeessa. Mukana on työpaketti, joka käsittelee tietoturvallisia ympäristöjä. Tavoitteena on luoda datan tietoturvalliselle hallinnolle kestävät ratkaisut.
”CSC on mukana tietoturvallisten ympäristöjen kehittämisessä. Isoin kysymys on tietoturvallisten ympäristöjen määrittelyt, hallintomallit ja ratkaisut. CSC on alusta lähtien ollut tässä keskeisessä roolissa, varsinkin kun ajatellaan genomiikkaan liittyviä aineistoja. Suomessa ei ole muita toimijoita, jotka voisivat siihen tarjota vastaavanlaista asiantuntemusta kuin CSC.”
Persephone Doupi muistuttaa, että vaikka lainsäädäntötyö edistyisi, kestää kuitenkin vielä vuosia, että nähdään datan toisiokäytön todelliset vaikutukset tutkimukselle. Kuitenkin jo tässä vaiheessa yhteistyö eri viranomaisten välillä on lisääntynyt ja tehty jopa pakolliseksi, mikä on Doupin mielestä hyvä asia.
”EHDS mahdollistaa monimutkaisten ja tärkeiden sairauksien tutkimisen aikaisempaa luotettavammalla tavalla tulevaisuudessa. Esimerkisi Pohjoismaissa on tiedostettu, että jokaiselle tutkimuskohteelle ei ole yksin riittävää aineistoa. Kun laitamme kaikki Pohjoismaiden aineistot yhteen, saamme luotettavampaa dataa tutkimusta varten. Tämä on tärkeää, kun tutkitaan esimerkiksi harvinaisia sairauksia tai lääkeiden turvallisuutta ja vaikuttavuutta. Yhden maan aineisto ei ole riittävä tällaisten aiheiden tutkimiseen.”

Yhtenä hyvänä esimerkkinä Persephone Doupi mainitsee EU:n 1+miljoonaa genomia -hankkeen (1+ MG). Aloitteella halutaan mahdollistaa tietoturvallinen pääsy genomiseen dataan ja siihen liittyviin kliinisiin aineistoihin paremman tutkimuksen ja päätöksenteon tueksi. Kansalliset kokoelmat, jotka on yhdistetty 1+MG-aloitteen kautta, muodostavat yhdessä valtavan eurooppalaisen tietokannan (The Genome of Europe). Vuoden 2022 loppuun mennessä sekvensoitiin yli miljoona genomia. 1+MG ja sen jatkoprojekti B1MG (Beyond 1 Million Genomes) ovat omassa lajissaan maailman isoimpia projekteja. Vuoteen 2026 mennessä 15 maassa on käytössä operatiivinen infrastruktuuri. 1+MG ja B1MG tekevät läheisesti yhteistyötä EHDS:n kanssa. Persephone Doupin mukaan tulevaisuus näyttää lupaavalta.
”Oletan että tietoisuus tiedon laadusta lisääntyy. Samalla monialainen yhteistyö rikkoo turhia siiloja. Toivottavasti käynnistyy myös yhteiskunnallinen keskustelu esimerkiksi tekoälyn käytöstä. Suurten aineistojen käsittely edellyttää tekoälyä ja siihen on suhtauduttava joustavasti. Meidän on oltava jatkuvasti valppaina sopeutumaan uusiin tietoihin ja ympäristöjen muutoksiin. Se tapahtuu EHDS:n myötä.”
Ari Turunen
15.12.2023
Lue artikkeli PDF-muodossa
Sitaatti
Nyrönen, T., & Turunen, A. (2023). The European Health Data Space: health data moves across borders for research purposes. https://doi.org/10.5281/zenodo.13691001
Terveyden ja hyvinvoinnin laitos THL
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Suolistomikrobistolla on vaikutus ihmisen terveyteen, mutta mikrobiston toimintaa ei tunneta tarpeeksi hyvin. Turun yliopistossa mikrobiston toimintaa proteiinien tasolla tutkitaan metaproteomiikan avulla.
Aiemmat tutkimukset ovat pääosin keskittyneet mikrobiston koostumuksen selvittämiseen, mutta ihmisen suoliston mikrobiston toiminnoista proteiinitasolla on edelleen varsin vähän tietoa. Proteiinit tekevät suurimman osan solujen toiminnoista ja niiden tutkimus auttaa ymmärtämään vuorovaikutuksia solujen ja ympäristön välillä. Metaproteomiikka on hyvä menetelmä tutkia ihmisen suolimikrobistoa, koska sen avulla voi luokitella ja tunnistaa mikrobiyhteisöissä toimivat proteiinit.
”Aiemmin on lähinnä vain profiloitu suoliston mikrobiston koostumusta. Se ei kuitenkaan kerro funktionaalisuudesta eli siitä, mitä suolistossa todella tapahtuu. Mukana voi olla kuollutta bakteerimassaa tai bakteerit eivät muuten ole aktiivisia. Toiminnallisuuden selvittämiseen tarvitaan metaproteomiikkaa. Tämä on käytännössä vasta viime aikoina muuttunut mahdolliseksi teknisesti mitata”, sanoo tutkija Tomi Suomi.

Suomi työskentelee Turun yliopistossa professori Laura Elon tutkimusryhmässä, jossa on kehitetty uusi menetelmä mikrobiston toiminnan tutkimiseen proteiinitasolla. Suomen mukaan olennainen kysymys on, että mitä prosesseja suolistomikrobistossa on havaittavissa. Vasta nyt saadaan tietoa bakteerien aineenvaihdunnallisesta aktiivisuudesta proteiinien tasolla. Näin voidaan analysoida monia ruokavalioon liittyviä tekijöitä kuten esimerkiksi sitä, miten äidinmaitokorvikkeet vaikuttavat suolistomikrobistoon.
”Nyt pystymme aivan uudella tasolla mittaamaan ja tutkimaan mitä suolistossa tapahtuu. Mikä on bakteerien välinen vuorovaikutus ja miten bakteerien aktiivisuus määräytyy? Kehittämämme menetelmä hyödyntää uusinta massaspektrometriteknologiaa ja laskennallisia menetelmiä. Menetelmän avulla on mahdollista mitata kattavasti monimutkaisten mikrobistonäytteiden proteiinitasoja.”
Suoliston mikrobien tärkeä rooli ihmisen terveydelle ja niiden merkitys eri sairauksissa on tunnistettu viimeaikaisissa tutkimuksissa. Potentiaalisia tauteja, joiden tutkimiseen metaproteomiikkaa voidaan soveltaa ovat esimerkiksi Crohnin tauti, haavainen paksunsuolen tulehdus, paksunsuolen syöpä tai diabetes.
”Mahdollisia muita sovellusalueita voisivat olla jopa allergiat. On olemassa runsaasti eri tautitiloja, joiden yhteyttä suoliston mikrobistoon on ainakin jollain tasolla ehdotettu. Kehittämämme menetelmät olisivat suoraan sovellettavissa näihin tutkimuksiin.”


Massaspektrometriaa käytetään eroteltujen proteiinien tunnistukseen. Näytteessä olevat proteiinit hajotetaan pienemmiksi aminohappoketjuiksi eli peptideiksi. Pilkotut peptidit analysoidaan massaspektrometrilla. Proteiinien tunnistus tapahtuu päättelemällä peptidien aminohappoketjut mitattujen massojen perusteella laskennallisia menetelmiä hyödyntäen. Mitattuja massoja verrataan esimerkiksi tietokantoihin, joihin on kerätty tunnettuja proteiinisekvenssejä, ja joihin saadut peptidimassat parhaiten sopivat.
Uusissa DIA-menetelmissä (data-independent acquisition) kaikki näytteen sisältämät peptidit pyritään mittaamaan ja fragmentoimaan tunnistusta varten. Tunnistaminen on kuitenkin tavallista hankalampaa, sillä yksittäiset spektrit saattavat samalla edustaa useampaakin peptidiä. Vastaavaa DIA-pohjaista massaspektrometriaa ei ole aiemmin hyödynnetty metaproteomiikan yhteydessä. Tutkimusryhmässä on kehitetty algoritmeja, joilla peptidisekvenssit tunnistetaan ja etsitään tietokannoista.
Suomen mukaan tämä on laskennallisesti haastavaa, koska uudessa menetelmässä yritetään mitata kokonaisvaltaisesti kaikkea, mitä näytteessä on: kaikki näytteiden sisältämät peptidit eri mikrobilajeista.
”Metaproteomiikkaan tarvitaan massiivinen laskentakapasiteetti, koska tunnistaminen on niin haastavaa. Meillä on referenssinä miljoonia eri proteiineja tuhansista bakteerilajeista, joita näytteistä yritetään tunnistaa. Lopputuloksena kuitenkin on, että näytteestä saadaan todella tarkka ja vertailukelpoinen mittaus.”
Tutkimusryhmä käyttää Suomen ELIXIR-keskuksen CSC:n laskentakapasiteettia. CSC:n virtuaalikoneet on liitetty Turun yliopiston paikallisen laskentaklusterin jatkeeksi.
Tomi Suomen mukaan tämä mittausmetelmä vaikuttaa toimivan kliinisissä näytteissä varsin hyvin. Tulevaisuudessa esimerkiksi biopankkeihin tallennettuja ulostenäytteitä voitaisiin mitata vertailukelpoisesti.
”Meillä saattaa olla satoja näytteitä eri yksilöistä. Tällä hetkellä ainoastaan tämän menetelmän avulla pystymme mittaamaan riittävän vertailukelpoisesti eri yksilöiden välisiä eroja vaikkapa osana sairauksien syntyprosessia. Uudella menetelmällä isojenkin kohorttien tutkiminen on mahdollista.”
Tomi Suomen mukaan uusi menetelmä tarjoaa laajan kirjon sovelluskohteita.
”Teoriassa menetelmät olisivat sovellettavissa laajemminkin metaproteomiikan sovelluksissa, kuten vaikka vesistöjen tai jätevesien tutkimuksessa, tai maaperästä kerättyjen näytteiden analysoinnissa, mutta näissä sovelluskohteissa emme ole menetelmiämme testanneet.”
Ari Turunen
16.11.2023
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2023). Artificial intelligence helps researchers find suitable drugs based on patient’s genetic data and cancer cell samples. https://doi.org/10.5281/zenodo.10796468
Lisätietoja:
Turun biokeskus
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Kaisa Lehosmaa tutkii arktisten mikrobien ja kasvien käyttöä teollisuuden valumavesien puhdistamisessa. Tämä voi auttaa kaivosteollisuuden aiheuttamien ympäristöhaittojen vähentämisessä. Typpi ja raskasmetallipitoista kuormitusta vesistöihin muodostuu kaivostoiminnan lisäksi jätevedenpuhdistamoilta, hulevesistä, maataloudesta ja turvetuotannosta. Mikrobien soveltuvuutta biopuhdistukseen analysoidaan pääasiassa sekvensointimenetelmillä, mutta myös eristäen mikrobeja sammalesta.
Ihmisen aiheuttamat teolliset prosessit, kuten kaivosteollisuus, ovat johtaneet siihen että maaperän ja vesistöjen typpi ja raskasmetallipitoisuudet ovat lisääntyneet. Tutkijatohtori Kaisa Lehosmaa Oulun yliopistosta tutkii professori Anna Maria Pirttilän tutkimusryhmässä sammalen sekä muiden kasvien sisällä eläviä mikrobeja ja niiden sovellettavuutta vesienpuhdistuksessa. Kasvien mikrobikumppaneiden käyttö biopuhdistuksessa on suhteellisen vähän tutkittu aihe. Joukko kasveja voi varastoida tai jopa haihduttaa haitta-aineita, kuten metalleja ja ravinteita ilmakehään. Kasvien mikrobikumppanit ovat merkittävässä roolissa ravinteiden ja metallien keräämisessä ja muunnostyössä kasvien sisällä.

Lehosmaa on tutkinut erityisesti nevasirppisammalta (Warnstorfia fluitans), joka kasvaa Suomessa vähäravinteisilla soilla ja pohjavesiriippuvaisissa lähde-ekosysteemeissä. Sammalta esiintyy Pyhäjärvellä Pyhäsalmen kaivosta ympäröivillä alueilla. Pyhäsalmi on Euroopan syvin perusmetalleja louhiva kaivos. Sieltä saadaan kuparia ja sinkkiä.
”Olemme löytäneet tämän sammalen kaivosalueelta ja se on luontaisesti sopeutunut poikkeaviin olosuhteisiin. Sammalesta löytyneitä mikrobeja voidaan yhdessä sammalen kanssa käyttää kaivosteollisuuden valumavesien puhdistajana kylmissä ilmasto-olosuhteissa, ” sanoo Lehosmaa.
Kaivostoiminta muodostaa hapanta ja metallipitoista ja painovoiman ansiosta liikkuvaa suotovettä. Suotovedet ovat erittäin happamia ja sisältävät runsaasti haitallisena pidettäviä metalleja (Zn, Al, Cu, Cd). Tällaista jätevettä on käsiteltävä ja puhdistettava huolellisesti, koska sillä on kielteisiä ympäristövaikutuksia.
Lehosmaan tutkimuksissa nevasirppisammal osoittautui tehokkaaksi metallien poistajaksi myös alhaisissa lämpötiloissa. Se pystyy poistamaan myös typpeä erityisen hyvin yhdistettäessä puuhakebioreaktori-puhdistusyksikköön. Lehosmaa ja hänen kollegansa tunnistivat nevasirppisammalen mikrobikumppanit sekvensointimenetelmillä.
”Sekvensoinnilla saadaan kokonaiskuva siitä, minkälainen sammalen mikrobien monimuotoisuus on eli kuinka paljon ja minkälaisia mikrobeja siellä on.”
Haluamme myös tietää, mitkä mikrobien geenit ovat aktiivisia eri olosuhteissa, jotta ymmärtäisimme, miten mikrobeja voidaan laajemmin hyödyntää.”

Lehosmaa on käyttänyt tutkimuksessa Suomen ELIXIR-keskuksen CSC:n laskentaresursseja ja Chipster-ohjelmistoa mikrobiomi-aineistojen analysoinnissa.
”Sammalen mikrobiomi on aika tuntematon. Kasvien mikrobikumppanit ovat yleisesti ottaen melko huonosti tunnettuja. Olemme alustavasti amplikonisekvensoinnilla tunnistaneet niitä.”
Amplikonisekvensointi kohdentaa analyysin tietyille geenialueille, tässä tapauksessa 16S- ja ITS-ribosomaalisen RNA:n (rRNA) geenialueelle. 16S- ja ITS-rRNA-geenialueet ovat säilyneet evoluutiossa muuttumattomana miljoonia vuosia bakteereilla ja sienillä, minkä vuoksi näiden geenialueiden perusteella voidaan tunnistaa eri lajeja. 16S- ja ITS-rRNA geenialueet sekvensoidaan ja tunnistetaan julkisten tietokantojen kautta.
”Seuraava askel mikrobien tunnistamisen jälkeen on selvittää mitä ne tekevät. Meillä on jo alustavaa näyttöä siitä, että sammalen solukossa tapahtuu mielenkiintoisia prosesseja.”
Lehosmaan mukaan on tärkeää tietää, mitä sammalen sisällä tapahtuu ja miten sammalen mikrobit pystyvät käsittelemään metalleja.
”Happamassa vedessä on yleensä metalleja liukoisessa muodossa. Mikrobien avulla ei voida välttämättä poistaa metalleja vedestä, koska ne ovat epäorgaanisia yhdisteitä. Voimme kuitenkin mikrobien avulla muuttaa metallien liukoisuutta. Usein biopuhdistuksessa käytetäänkin eläviä mikrobeja saostamaan metalleja partikkelimuotoon, jolloin ne ovat helpommin hallittavissa ja poistettavissa.”
Olennaista on, että löydettyjä mikrobeja pystyy kasvattamaan myös laboratoriossa.
”Mehän emme voi hyödyntää potentiaalisia mikrobeja, jos emme voi kasvattaa ja täten jatkojalostaa ja lisätä niitä saman tai eri kasvilajin edustajiin,” sanoo Lehosmaa ja tarkoittaa tällä, että potentiaalisilla mikrobikumppaneilla voi tehostaa biopuhdistusta. Mikrobikumppanit auttavat kasveja selviytymään haastavissa biologisissa olosuhteissa.
Sammalen lisäksi eräs tehokas biopuhdistukseen käytetty kasvi on järviruoko. Sammalen tavoin se sitoo tehokkaasti itseensä haitta-aineita. Järviruoko tuottaa paljon biomassaa ja lähtee helposti kasvamaan. Juurakossa elävät levät sitovat maaperän rakenteita ja estävät sinileväkukintoja. Järviruokoa hyödynnetäänkin metallien talteenotossa (phytomining). Yhdessä Lehosmaan tutkimuksessa kartoitettiin Pyhäsalmen kaivoksen kupari- ja sinkkipäästöjen kertymistä järviruokoon.
Seuraavaksi tavoitteena on tutkia ja optimoida pohjoisiin olosuhteisiin sopeutuneiden muiden luonnonkasvien, sienten ja bakteerien kykyä pidättää vedestä typpeä ja raskasmetalleja.
”Koska löydettyjä mikrobeja voidaan kasvattaa ja lisätä, niin nyt tarkoitus on laajentaa muihin sammaliin. On hyvä selvittää pystyvätkö mikrobit toimimaan yhtä hyvin muissa kasveissa kuin nevasirppisammalessa.”
Ari Turunen
31.10.2023
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2023). Purifying mining wastewater with plant-associated microbes. https://doi.org/10.5281/zenodo.13690962
Lisätietoja:
Oulun yliopisto
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

iCAN-PEDI on yksi laajan iCAN-tutkimushankkeen osa, jossa tutkitaan syöpään sairastuneiden lasten lääkehoitoja ja lääkevasteita. Tutkimuksessa yhdistetään potilaiden syövän geneettinen ja proteiinitason tieto heistä saatujen syöpäsolujen lääkeainevasteisiin. iCAN -hankkeissa on mahdollista hyödyntää datan tarkastelussa myös tekoälymalleja. Tavoitteena on myös toimittaa mahdollisesti hoitoon vaikuttavia löydöksiä takaisin lääkäreille. Näin voidaan tehostaa yksilöllistä syövän hoitoa.
Solu- ja molekyylibiologian dosentti FT Vilja Pietiäinen Suomen Molekyylilääketieteen instituutista (FIMM) johtaa iCAN-PEDI-projektia yhdessä HUS:n Uuden lastensairaalan dosentti Minna Koskenvuon kanssa. Projektiin osallistuu Uuden lastensairaalan lääkäreitä (HUS), Turun yliopistollisen sairaalan sekä Helsingin yliopiston tutkijoita. Pietiäinen haluaa kehittää entistä yksilöllisempiä lääkehoitoja.
”Lasten syöpähoito on jo lääketieteellisesti yksilön huomioivaa, mutta lasten kasvainten tutkiminen molekyylitasolla voi auttaa tehokkaampien lääkkeiden löytämistä juuri tietynlaiseen syöpään. Lasten kiinteät kasvaimet ovat heterogeenisiä, osaksi harvinaisia ja vaikeasti diagnosoitavia patologian perusteella. Lastensyövissä on vähemmän geneettisiä muutoksia, ja siksi ne vaativat enemmän erilaista molekyylitason dataa diagnoosiin. Diagnoosi puolestaan vaikuttaa siihen, minkälainen hoitolinja valitaan.”
Pietiäisen mukaan keräämällä runsaasti dataa yksittäisistä potilaista ymmärretään paljon paremmin tautien diagnostiikkaa ja löydetään uusia tapoja luokitella syöpäsairauksia. Aletaan myös hahmottaa, kuinka paljon vaihtelua on jopa hyvin tunnettujen syöpäsairauksien sisällä.
”Me haluamme paremmin ymmärtää, minkä takia tietyn potilaan syöpä reagoi tietyllä tavalla lääkkeisiin. Näin voidaan kehittää parempia ja yksilöllisempiä tapoja valita hoito tietyille potilaille.”
Hän yhdessä ryhmänsä yhdistää potilaan syövän molekyylitason dataa kunkin potilaan henkilökohtaisiin syöpäsolumalleihin. Eksomisekvensoinnilla tutkitaan yhdellä kertaa n. 20 000 geenin sisältämä tieto. Transkriptomiikassa tuhannet RNA-molekyylit analysoidaan samanaikaisesti. Tämä kertoo siitä, miten geenit ilmenevät. Kudoskuvantamisella tutkitaan syöpäkudosten ilmentämiä biomarkkereita. Datamassa tallennetaan iCAN-hankkeen tietoturvalliseen käyttöympäristöön (HUS Acamedic).
Pietiäisen mukaan geeneistä saatu data ei kuitenkaan usein yksinään riitä selvittämään yksittäisen potilaan syövän lääkeainevastetta.
”Tarvitaan potilaiden omia syöpäsolunäytteitä, jolloin voidaan mikroskooppikuvantamisen avulla katsoa yksittäisten solujen reagointia lääkeaineille. Syöpähän on hirveän heterogeeninen: kaikki solut eivät välttämättä reagoi samoihin lääkeaineisiin, ja meitä kiinnostavat myös ne solut, jotka eivät reagoi. Voidaan tarvita yhdistelmä eri lääkeaineita, jos halutaan tuhota kaikki syöpäsolut.”

Potilaan syöpäkudosnäyte tulee leikkaussalista patologille, ja sieltä heti tutkimukseen. Lääkeaineherkkyystestaus tehdään monikuoppaisella soluviljelylevyllä robotiikkaa käyttäen. Pieneen kuoppaan tarvitaan vain vähän arvokasta syöpäsolunäytettä, ja yhdellä levyllä voidaan kerralla testata kymmeniä lääkeaineita.
Levyn kuoppiin annostellaan syöpäsolunäytettä sekä eri lääkeaineita eri pitoisuuksissa. Mikroskooppikuvantamisella voidaan katsoa miten lääkeaineet vaikuttavat potilaan syöpäsoluihin, joita kuopissa on. Syöpäsolujen kuva-analyysissä hyödynnetään koneoppimismalleja. Tekoälyn opettamiseen on käytetty Suomen ELIXIR-keskuksen CSC:n laskentaklustereita.
”Kutsumme tätä fenotyyppiseksi kuvantamiseksi. Pystymme mikroskooppikuvantamisella määrittelemään soluista satoja erilaisia piirteitä. Tämä on tärkeää tietoa koneoppimisessa. Jos me selkeästi näemme tiettyjä fenotyyppejä, niin voimme opettaa tämän saman koneelle: tässä tämän näköinen solupopulaatio, joka on reagoinut lääkkeeseen näin. Tämän jälkeen voidaan antaa uusi data-aineisto koneelle, joka osaa sitten luokitella solut sen mukaan, miltä ne ovat näyttäneet. Toisaalta, tekoäly voi etsiä myös sellaisia piirteitä tai fenotyyppejä, joita emme pysty itse havaitsemaan tai luokittelemaan.”
Kun sadat analysoidut piirteet annetaan tekoälyn käyttöön, se pystyy erottelemaan erilaisia lääkeainevasteita. Tekoälyä voidaan käyttää myös luokittelemaan potilaita näiden lääkevasteiden perusteella.
Etsittäessä parasta lääkeainevastetta tarvitaan monia eri datalähteitä. Pietiäinen viittaa laajaan eurooppalaiseen tutkimukseen (ERA-PerMed), jossa he olivat mukana.
”Tiedetään, että jopa 90%:lle syövän geenimuutoksista ei ole kohdennettua lääkehoitoa. Lääkeaineiden toimivuutta ja lääkeainekohteita ei siis voitu selvittää tutkimuksessamme kuin osittain geenien perusteella. Kuitenkin lääkeainetestauksessa havaittiin, että näiden potilaiden solut reagoivat tietyille lääkeaineille.”
Pietiäisen mukaan on tärkeää, että syöpäsolujen lääkeainetestausdataa voidaan verrata esimerkiksi terveisiin soluihin.
”Näin nähdään onko esimerkiksi tietyn potilaan solujen vaste tietyille lääkeaineille erityisen hyvä. Tätä tietoa voidaan verrata eri potilaiden mutaatiodataan ja geenien ilmenemiseen. Voidaan esimerkiksi huomata, että tällä potilaalla on tietty altistava mutaatio, mihin lääkeaine voi kohdentua ja sen takia tämä potilas vastaa tälle lääkeaineelle. Toisaalta muu kuin mutaatiotieto, esimerkiksi geenin ilmeneminen, signaalireittien aktivaatio tai epigeneettiset muutokset, voivat auttaa ymmärtämään solujen lääkeainevastetta. Potilaita voidaan alkaa ryhmitellä yhdistämällä näitä eri datoja.”
Potilaan verinäytteestä tai vaikkapa aivoselkäydinnesteestä voidaan tehdä nestebiopsioita ja katsoa miten kasvaimen DNA ilmentyy, koska sitä voidaan käyttää mittarina siihen, miten lääkeaine on tehonnut tai onko tauti ylipäätään uusiutunut.

iCAN on useammat syövät kattava valtava Suomen Akatemian rahoittama tutkimushanke, johon osallistuu useita eri syöpiä tutkivia ja näiden tutkimusmenetelmiä samalla kehittäviä tutkimusryhmiä Helsingin yliopistosta. Syövän ominaisuuksia verrataan potilaan muihin terveystietoihin tietoturvallisessa käyttöympäristössä HUSin Acamedics palvelussa.
”Kaikki data, joka sinne kertyy, on meidän kaikkien iCAN-hankkeeseen osallistuvien tutkijoiden saatavilla. Meillä on iso materiaali mihin löydöksiä voidaan verrata. Löydetään potilasryhmä- ja potilasspesifisiä markkereita geneettisestä datasta.
Kaikki data (esimerkiksi lääkeainetestausdata, geneettinen data ja transkriptomiikka-data) yhdistetään tehokkaan työkalun (Integrated Molecular Tumor Board System) avulla. Lasten syöpien tutkimuksessa Pietiläinen kollegoineen pilotoi yhdessä HUS Lastensairaalaan kanssa tutkimustulosten nopeaa hyödynnettävyyttä.
”Tavoitteena on raportoida kliinisesti relevantteja löydöksiä lääkäreille ja toivottavasti parantaa potilaiden hoidon valintaa silloin, kun suositushoitoja ei enää ole.”

iCAN käyttää Suomen ELIXIR-keskuksen CSC:n palvelua (SD Connect) sekvensointidatan siirtämiseen tietoturvalliseen Academics-käyttöympäristöön.
Tiedot salataan Crypt4GH:lla, joka on Global Alliance for Genomics & Health -järjestön kehittämä suojattu standardimenetelmä ihmisen geneettisten tietojen jakamiseen.
”Tällä tavoin tiedot ovat yhteentoimivia koko CSC:n SD -palveluperheen sisällä ja mahdollisesti myös muiden palveluntarjoajien kanssa, joilla on samankaltaisia tietoja.”
iCAN-hankkeen koosta kertoo se, että datamäärän arvioidaan saavuttavan kolmen petatavua vuonna 2026.
”Kaikki tämä data on tarpeen syövän molekyyliperustan ja potilaan vasteen ymmärtämiseksi.”
Ari Turunen
29.9.2023
Sitaatti
Turunen, A., & Nyrönen, T. (2023). Artificial intelligence helps researchers find suitable drugs based on patient’s genetic data and cancer cell samples. https://doi.org/10.5281/zenodo.10796468
Suomen molekyylilääketieteen instituutti (FIMM)
FIMM on osa Helsingin yliopiston HiLIFE Helsinki Institute of Life Science -tutkimuskeskusta.
https://www.helsinki.fi/en/hilife-helsinki-institute-life-science/units/fimm
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Itä-Suomen yliopiston Bioinformatiikan keskuksessa kehitetään Virpi Aholan johdolla biolääketieteellisen ja multimodaalisen datan analysoimiseen uusia sovelluksia. Näitä voidaan hyödyntää syöpien, metabolisten, sydän- ja verisuonisairauksien sekä hermostoa rappeuttavien sairauksien tutkimisessa.
Aholalla on pitkä ura bioinformatiikasta. Hän oli mukana professori Ilkka Hanskin metapopulaatiobiologian tutkimusryhmässä, jossa sekvensointiin täpläverkkoperhosen koko genomi. Se oli ensimmäinen Suomessa tehty referenssigenomi. Karolinska Institutissa Hong Kongissa hän analysoi geenien toimintaa eri taudeilla yhden solun tasolla ja tutki sen avulla, miten kantasoluja käyttämällä voidaan kehittää uusia lääkkeitä ja hoitoja. Nyt hän johtaa Bioinformatiikkakeskusta.
Bioinformatiikakeskuksessa yhdistellään erilaisia omiikka-datoja (genomiiikka, proteomiikka, transkriptomiikka) kliiniseen dataan ja jatkossa mahdollisesti myös kuvantamisdataan.
”Tavallisten omiikka-analyysien lisäksi tehdään eri tutkimusryhmille multimodaalista data-analyysiä. Siinä yhdistetään erityyppisten datojen analyysi ja pyritään siihen, että saadaan enemmän tietoa kuin erikseen analysoimalla.”
Multimodaalisen datan analyysitapa vaihtelee sen mukaan, onko erityypiset datat kerätty samasta potilaasta vai ovat ne peräisin eri potilaista.
Omiikka on tutkimustapa, jolla pyritään analysoimaan tutkimuskohteen kaikkia geneettisesti määräytyviä muuttujia samanaikaisesti. Kun genomiikassa analysoidaan geneettistä muuntelua ja geenien toimintaa, proteomiikassa keskitytään proteiineihin ja epigenetiikassa geenien toiminnan säätelyyn ja perinnöllisen tiedon tallentumiseen ilman DNA-sekvenssin muutoksia. Metabolomiikassa analysoidaan sairauden, ruokavalion tai lääkityksen aiheuttamia muutoksia aineenvaihdunnassa.
”Kehitämme bioinformatiikkapalveluja yhteistyössä biolääketieteen asiantuntijoiden kanssa. Yksi painopiste Itä-Suomen yliopistossa on keskeisten kroonisten kansansairauksien molekulaarisen taustan selvittämisessä sekä niiden ehkäisyn ja hoidon kehittämisessä”, sanoo Ahola.
Translationaalinen eli niveltävä lääketiede hyödyntää perustutkimusta kliinisessä tutkimuksessa ja toisaalta potilasnäytteitä ja tautimalleja tautimekanismien ja lääkevaikutuskohteiden selvittämisessä. Lähtökohtana on poikkitieteellisyys, joka auttaa tutkimuksen ohella myös potilaita.
”Translationaalisen lääketieteen tulemista hidastaa se, että ei kerta kaikkiaan tiedetä tarpeeksi. Monen eri datalähteen yhdistämisen lähtökohta on, että saataisiin enemmän tietoa esille. Yhdistäminen on hyvin paljon laskennallista ja siihen tarvitaan CSC:n resursseja ja ELIXIRin tapaisia infrastruktuureja.”
Yhtenä esimerkkinä Ahola mainitsee yksisolutekniikat.
Transkriptiossa DNA:ssa olevaa geneettistä koodia kopioituu RNA:ksi. Transkriptio on proteiinisynteesin ensimmäinen vaihe. Transkriptomiikan avulla saadaan tarkkaa tietoa yksittäisen solun geenien ilmenemisestä juuri tietyllä hetkellä.
”Yksisolutranskriptomiikan käyttö on vielä kallista. Avoimen tieteen periaatteet ovat olemassa ja sen vuoksi kaikki data pitää jakaa, kun se julkaistaan. Tällöin dataa voi uudelleen käyttää ja eri datalähteitä yhdistellä.”
Haasteena on kuitenkin, että dataa on tuotettu erilaisilla teknologioilla.
”Eri datalähteissä voi solujen määrä vaihdella tai niissä voi olla eri solutyyppejä. Minkälaisia menetelmiä pitäisi tällöin käyttää erilaisten datojen yhdistämiseen? Jos tämä voitaisiin ratkaista, silloin voitaisiin tehokkaammin tutkia potilaan solujen kehitystä ja niiden erikoistumista.”

Aholan tavoitteena on avustaa enemmän laskennallisten menetelmien käytössä. Itä-Suomen yliopiston Bioinformatiikan keskus tarjoaa tutkijoille laskentakapasiteettia ja auttaa tutkijoita esikäsittelemään ja analysoimaan dataa sekä avustamaan erilaisten laskennallisten menetelmien ja ohjelmistojen käytössä ja asentamisessa.
”Jos samassa ryhmässä tai yhteistyökumppanina ei ole bioinformaatikkoja, tutkijoiden oletetaan hallitsevan myös laskennalliset menetelmät ja ison datan käsittelyn.”
Ahola myöntää, että vaatimukset ovat kovat esimerkiksi jatko-opiskelijoille.
Itä-Suomen yliopistossa on tähän haasteeseen on tartuttu perustamalla laskennallisen biolääketieteen suuntautumisvaihtoehto.
”Yksi esimerkki datan uudelleenkäsittelyn haasteista ovat suomalaiset biopankit, joihin on tallennettu yli puolen miljoonan suomalaisen genomit. Ei ole ihan yksinkertainen juttu käydä biopankeissa analysoimassa dataa, koska sitä on ihan järjetön määrä.”
Ahola viittaa FinnGen -tutkimushankkeeseen, joka käynnistyi syksyllä 2017. Sen päätavoitteena on lisätä ymmärrystä sairauksien syistä ja edistää niiden diagnosointia, ennaltaehkäisyä ja hoitojen kehittämistä. FinnGen -tutkimuksessa hyödynnetään suomalaisten biopankkien keräämiä näytteitä. Kesäkuuhun 2023 mennessä FinnGen -tutkimukselle saatiin kerättyä yli 553 000 näytettä. Tutkimushankkeen ensimmäisen vaiheen kesto oli kuusi vuotta. Vastaavan kokoluokan tutkimushankkeita on maailmassa vain muutama.
Tutkimushankkeissa genomidata yhdistetään kansallisissa terveydenhuollon rekistereissä oleviin aineistoihin. Suomessa onkin harvinaisen hyvät edellytykset koko väestön kattavalle geenitutkimukselle.
Kliininen data pitkittäistutkimuksista yhdistettynä geenidataan tarjoaa paljon mahdollisuuksia. Mutta dataa pitää olla paljon.
”Datakokoelmia tarvitaan, koska yksikään tutkija ei voi kerätä 10 tai 100 tuhannen yksilön aineistoa. Jos aineisto on pienempi sillä ei välttämättä saada luotettavaa tietoa geneettisesti kompleksisten tautien tutkimiseen ”
Itä-Suomen yliopistossa on monia eri datalähteitä hyödyntäviä tutkimushankkeita. Itä-Suomen yliopiston ja Kuopion yliopistollisen sairaalan Alzheimerin tautia käsittelevässä hankkeessa yhdistetään potilaskäynneillä kerätty kliininen data FinnGen -aineistoon. Näin tutkijat pyrkivät selvittämään Alzheimerin taudin puhkeamiseen johtavia biologisia mekanismeja.
”FinnGenin biopankki on ainutlaatuinen resurssi, jota voitaisiin kuitenkin hyödyntää tutkimuksessa mahdollisesti vielä paljon enemmän”, sanoo Ahola.
”Toinen esimerkki Alzheimerin taudin tutkimuksesta on Rappta Therapeutics:in ja Itä-Suomen yliopiston professoreiden Mikko Hiltusen ja Annakaisa Haapasalon projekti, jossa tutkitaan transgeenisten solulinjojen avulla eri Alzheimerin hoitojen vaikutusta proteiinien toimintaan.”
Yksi mielenkiintoinen yhteistyöprojekti on akatemiatutkija Kirsi Ketolan kanssa.
Siinä tutkitaan eturauhassyövän hoitoon käytettyä karboplatiini-resistenssiä. Karboplatiini tuottaa ”DNA-ristilinkkejä”, mikä johtaa DNA:n korjausmekanismin aktivoitumiseen ja resistenssiin, jolloin syöpäsolut kykenevät taas jakautumaan. Tutkimukseen käytetään yksisolutekniikoita, jossa yksittäisen solun tasolla pystytään mittaamaan sekä geenien ilmentymistä että kromatiinin muutoksia.”
Kromosomit sijaitsevat tumassa pitkinä kromatiini-rihmoina.
Virpi Aholan mukaan hyvä datankäsittely ja sen taitava yhdistäminen voisi mahdollistaa yksilöllisen hoidon.
”Potilaille voitaisiin räätälöidä paremmin olemassa olevilla lääkkeillä tehtyjä hoitosuunnitelmia”.

Ahola kannattaa vahvasti datan avoimuutta ja uudelleenkäyttöä sekä sellaisen menetelmien ja infrastruktuurien luomista, joka helpottaa ja kannustaa tähän. Yhtenä esimerkkinä hän mainitsee EGA:n. European Genome-phenome Archive (EGA) on data-arkisto, jossa voi jakaa ja lupaa vastaan on mahdollista saada käyttöönsä jo julkaistuja biolääketieteellisiä datoja.
”Arkisto sisältää ihmisen genomista dataa, joka on yhdistetty kliiniseen ja muuhun metadataan. Koska periaatteessa henkilö voi olla mahdollista genomisen ja fenotyypin perusteella identifioida, datan jakamien on tarkkaan säädeltyä.”
Aholan mukaan EGA:n avulla datan jakaminen on hoidettu asianmukaisella tavalla ja näin arvokasta biolääketeteen tutkimusaineistoa on mahdollista käyttää uudelleen, kuten uusien tutkimushypoteesien luomiseen tai testaamiseen.
”Olemassa olevia aineistoja voidaan myös katsoa eri näkökulmasta. Esimerkiksi potilaita voidaan valita eri kriteereillä kuin jo julkaistussa tutkimuksessa tai aineistoja voidaan käyttää osana laajempaa datakokoelmaa.”
Aholan mukaan yhdessä pitäisi tehdä enemmän ja viittaa Biokeskus Suomeen, joka yhdistää seitsemän eri Suomen yliopiston biokeskusta. Yhteistyötä pitäisi pystyä lisäämään eri biokeskusten välillä ja yli valtakunnan rajojen esimerkiksi Suomen ELIXIR-keskus CSC:n avulla.
”ELIXIR on meille väylä verkostoitua ja oppia muiden bioinformatiikkakeskuksien kokemuksista sekä olla mukana niissä pöydissä, jossa tutkimusinfrastruktuuriin liittyvistä asioista keskustellaan ja uusia aloitteita tehdään.”
Koska uudet teknologiat tuottavat isoja ja kompleksisia data-aineistoja, tutkimusinfrastruktuureilta edellytetään muutakin kuin vain tutkimuslaitteistoja.
”Jotta aineistoja voitaisiin tehokkaasti hyödyntää, pelkkä esimerkiksi CSC:n tarjoama laskentakapasiteetti ei riitä vaan datojen käsittelyyn ja uudelleenkäyttöön tarvitaan niihin perehtynyttä henkilökuntaa. Näen, että biokeskusten parempi resursointi ja systemaattinen yhteistyö voisi olennaisesti helpottaa ja parantaa isojen genomisten datojen käsittelyä, yhdistämistä ja uudelleenkäyttöä.”
Ari Turunen
1.9.2023
Lue artikkeli PDF-muodossa
Sitaatti
Turunen, A., & Nyrönen, T. (2024). Improving breast cancer treatment prognoses with liquid biopsy. https://doi.org/10.5281/zenodo.13691344
Lisätietoja:
Bioinformatiikkakeskus, Itä-Suomen yliopisto
https://uefconnect.uef.fi/tutkimusryhma/bioinformatiikkakeskus/
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org

Itä-Suomen yliopiston professori Merja Heinäniemi tutkimusryhmineen tulkitsee laskennallisten menetelmien avulla syöpänäytteistä, millaiset solun prosessit ovat viallisia ja miten solut käyttäytyvät lääkehoitojen aikana. Tarkoitus on löytää leukemiaan tehokkaita lääkehoitoja.
Leukemia eli verisyöpä johtuu kun luuytimen valkosolujen esiasteet muuttuvat syöpäsoluiksi. Toisin kuin muissa syövissä leukemiassa ei muodostu yksittäistä kasvainta, vaan syöpäsoluja on verenkierrossa ja luuytimessä. Kokonaisuudessaan lasten leukemiahoidot ovat niin tehokkaita, että ennusteet paranemisesta ovat jopa 90%. Heinäniemi kuitenkin muistuttaa, että tauti saattaa uusiutua.
”Vaikka leukemia olisi uusiutuessaan hoidettavissa, se kuitenkin tarkoittaa että kemoterapia, pitkä sytostaattilääkehoito, kestää useita vuosia. Siksi nykyistä tehokkaammat hoitomuodot ovat tärkeitä ja toisaalta joillakin potilaille hoitoja voisi keventää. On potilaita, joille on vaikea löytää hoitomuotoja, mutta toisaalta lasten leukemioiden hoidot kestävät pitkään.”
Laskennallisen biolääketieteen professori Merja Heinäniemi tutkii, miten geenit vaikuttavat syöpäsolujen syntyyn.
”Verisyöpiin kuuluu erilaisia leukemioita, akuutteja ja kroonisia leukemioita. Näistä leukemioista myeloidiset leukemiat ovat lähinnä aikuisten tauteja kun taas lymfoblastiset ovat lasten tauteja”, sanoo Heinäniemi.
Akuutissa leukemiassa luuytimessä veren kantasolun perimä muuttuu ja valkosolujen esiasteet alkavat jakaantua hallitsemattomasti. Lapsilla yleisin leukemia on immuunipuolustuksessa toimivien B- ja T-solujen esiasteesta lähtöisin, jolloin sitä kutsutaan akuutiksi lymfoblastileukemiaksi.
Heinäniemen tutkimusryhmässä on tehty syöpiin liittyviä geeniekspressioprofiilien analyyseja. Geeniekspressio tarkoittaa geenien ilmentymistä eli solun tapahtumasarjaa, jossa DNA:n sisältämä koodi kopioidaan RNA:ksi ja edelleen tämän viestimolekyylin ohjaamana proteiiniksi. Syövän kehittymistä edistävä geeni voi käynnistyä tai vastaavasti hiljentyä. Geenin toimintaan vaikuttavilla säätelyalueilla on vaikutus myös DNA-vaurioiden syntymisessä lasten leukemiassa ja kypsemmissä imukudossyövissä.
Vuonna 2019 Heinäniemi yhdessä muiden tutkijoiden kanssa keräsi ison datakokoelman, jossa on yli 10 000 potilasnäytettä. Tämä HEMAP-data (hematological malignancies) on edelleen jaettavissa tutkijoille Suomen ELIXIR-keskuksen CSC:n kautta. Tästä datajoukosta pystyttiin päättelemään laskennallisin menetelmin yli 30 syöpätyyppiä. Lisäksi löydettiin tauteja kuvaavia uusia biomarkkereita sekä uusia lääkeaihioita kun data yhdistettiin lääkekohdetietokantoihin.
Esimerkiksi lasten leukemiasta löytyi molekyylitasoltaan eri tyyppisesti käyttäytyviä alityyppejä.
”Pystymme huomaamaan jo dataryhmittelystä, että taudin alatyypitkin ovat geeniluennan profiileiltaan ainutlaatuisia ja ne voidaan tunnistaa datan perusteella. Yhteen koottu data paljasti meille molekyylitasolla taudin heterogeenisyyttä ja toisaalta yhteneväisyyksiä eri tautien välillä.”
Heinäniemi on etsinyt datan perusteella sellaisia potilaita, joille hoito voisi olla kevyempää. Solunsalpaajat eli sytostaatit ovat syöpäsolujen tuhoamiseen tarkoitettuja lääkkeitä. Ne kuitenkin voivat aiheuttaa paljon haittavaikutuksia. Huonon hoitovasteen saavilla potilailla on yleensä myös suurentunut riski taudin uusiutumisesta.

Yhdessä Tampereen yliopiston Olli Lohen kanssa Heinäniemen ryhmä kartoitti ihmisen koko perimästä, miten eri geenit voisivat toimia ennustavana tekijänä lasten leukemiassa.
”HEMAP-aineistosta on löydetty mahdollisia biomarkkerigeenejä lasten leukemioihin. Lähdimme aluksi kartoittamaan huonoa lääkevastetta, mutta genomitutkimuksessa löydettiinkin, millaisia piirteitä sellaisilla leukemiapotilailla on, jotka vastaavat hyvin lääkehoitoihin.”
Yksi tällainen hyvän vasteen merkki ovat solusyklissä olevat solut. Solujen elämä noudattaa yleensä tiettyä rytmiä eli solusykliä, jossa solunjakautuminen eli mitoosi ja välivaihe eli interfaasi vuorottelevat. Solusyklin päämääränä on useimmiten tuottaa solunjakautumisen avulla kaksi identtistä solua.
”Yksittäisten solujen kartoituksessa meille selvisi syklissä olevien solujen määrä. Me pystyimme erottamaan eri solut vaiheisiin ja syklissä olevien solujen määrä näytti olevan tärkeä hyvään vasteeseen liittyvä merkki. Yksisoluanalytiikka on hyvä keino tutkia miten syöpäsolu käyttäytyy. Sieltä paljastuu ne harvinaisemmat selviytyvät solut muun massan joukosta. Tärkeää on tutkia, miten lääkehoito vaikuttaa syöpäsolun käyttäytymiseen”, Heinäniemi toteaa.
Yksittäisten solujen RNA-sekvensointi (scRNA-seq) mittaa kaikkien geenien aktiivisuudet jokaisessa solussa erikseen, jolloin saadaan aiempaa tarkempi kuva solujen eroavaisuuksista. Tämä on tärkeää tietoa, koska syöpäsolut yrittävät karata immuunisoluilta muuttumalla.
”Syöpätutkimuksessa on tärkeää saada dataa yhden solun tarkkuudella. Syöpäsolut nimittäin muuttuvat koko ajan, jolloin jokainen solu alkaa olla erilainen.”
Nyt leukemiaa tutkittaessa yksisolutekniikalla saadaan yksittäisestä luuydinnäytteestä mitattua jopa 10 000 solun profiilia. Kun yksisolutekniikkaa käyttää muissa syövissä päästään helposti mittaamaan jopa miljoonia soluja.
Heinäniemen ryhmän tutkimuksissa havaittiin, että leukemiahoito käynnistää soluissa nopeasti eräänlaisia pakoreittejä muuttamalla geenien luentaa. Sen avulla syöpäsolu väistää annettua hoitoa. Nämä RNA- molekyylien profiilit, jotka luetaan vaikuttavat solun toiminnallisen osan rakentamiseen. Näin saadaan tavallaan sen hetkinen solun tila selville ja se, mitä solu pyrkii tekemään.
”Leukemiasolu on sellainen luuytimen kantasolumainen solu, jolla on vielä mahdollisuuksia vaihtaa ilmiasuaan. Se voi erilaisissa ilmiasuissa yrittää piileksiä hoidoilta. Esimerkiksi se, että solu ei jakaannukaan niin villisti, on yksi pakokeino. Solu voi alkuhoidoissa myös vaihtaa erilaistumistilojaan ja löytää lääkeresistentin tilan. ”
Heinäniemen ryhmässä laaja soluista mitattu molekyyliprofiili on laskennallisten menetelmien avulla mahdollista ryhmitellä. Siten voidaan erotella normaalit luuytimen solut leukemiasolujen profiileista ja tunnistaa erilaisia leukemiasolujen ilmiasuja mittausten perusteella. Malleja voi myös kouluttaa oppimaan samasta näytteestä kerättyjen eri mittausten yhteyden.
”Diagnoosivaihe ei täysin paljasta, minkälaisia pakokeinoja niillä syöpäsoluilla mahdollisesti on. Tässä yksisoluteknologia on auttanut, koska nyt pääsemme mittamaan niitä harvinaisia resistenttejä solumuotoja hoidon aikana. Eli uutta tietoa ja pystymme sitten miettimään, miten voimme ennaltaehkäistä solun pakoreittiä tai mihin se on piiloutumassa.”

Nyt Heinäniemen ryhmä on alkanut käyttää kehittämiään neuroverkkomalleja. Dataa kerätään eri tutkimuksista tähän malliin.
”Leukemia-hankkeemme keskittyy lasten syöpiin. Se on hyvin harvinainen syöpätyyppi: jos me emme saa yhdistettyä dataa niin ne aineistot jäävät todella pieniksi. Tavoitteena on näissä hankkeissa hyödyntää CSC:n infrastruktuuria. Näin pystyttäisiin prosessoimaan datat valmiiksi ja jakamaan ne tiedeyhteisön käyttöön.”
Tutkimusta ei pysty tekemään pelkästään suomalaisilla aineistoilla.
”Meillä on ollut pitkään pohjoismaista yhteistyötä. Nyt on tullut mukaan myös muita Euroopan maita. Tavoitteena olisi mahdollistaa datavaranto niille tutkijoille, jotka eivät itse pysty tekemään datan prosessointia. Tuomme yhteen jo kerättyjä ja mitattuja profiileja, koska niiden kerääminen julkisista datatietokannoista on työlästä. Tarkoitus on tuoda yksisoludata yhteen paikkaan ja helposti lähestyttävään muotoon. Kun pystymme tuomaan maailman eri tutkimusryhmien tuloksia samaan paikkaan, niin pääsemme nopeasti vertaamaan mitkä lääkeaihiot voisivat toimia. ”
Datan jakaminen vaatii luottamuksen luomista. Käytännössä se tarkoittaa yhteistyötä hankkeissa mukana olevien potilaiden kanssa.
”On todella tärkeää, että he osallistuvat ja että heidän datansa on tietoturvallisesti säilytetty ja että tutkijat pystyvät aineistojen kanssa tekemään työtään. Sitähän CSC on mahdollistamasssa kansallisesti ja EU-tasolla olemalla mukana ELIXIR-infrastruktuurissa.”
Ari Turunen
15.8.2023
Lue artikkeli PDF-muodossa
Sitaatti
Nyrönen, T., & Turunen, A. (2023). Better treatments for leukaemia. https://doi.org/10.5281/zenodo.10020637
Lisätietoja:
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
Pölönen P, Mehtonen J, Lin J, Liuksiala T, Häyrynen S, Teppo S, Mäkinen A, Kumar A, Malani D, Pohjolainen V, Porkka K, Heckman CA, May P, Hautamäki V, Granberg KJ, Lohi O, Nykter M, Heinäniemi M.Cancer Res. 2019 May 15;79(10):2466-2479. doi: 10.1158/0008-5472.CAN-18-2970. Epub 2019 Apr 2.PMID: 30940663
Data-driven characterization of molecular phenotypes across heterogeneous sample collections.
Mehtonen J, Pölönen P, Häyrynen S, Dufva O, Lin J, Liuksiala T, Granberg K, Lohi O, Hautamäki V, Nykter M, Heinäniemi M.Nucleic Acids Res. 2019 Jul 26;47(13):e76. doi: 10.1093/nar/gkz281.PMID: 31329928
Immunogenomic Landscape of Hematological Malignancies.
Dufva O, Pölönen P, Brück O, Keränen MAI, Klievink J, Mehtonen J, Huuhtanen J, Kumar A, Malani D, Siitonen S, Kankainen M, Ghimire B, Lahtela J, Mattila P, Vähä-Koskela M, Wennerberg K, Granberg K, Leivonen SK, Meriranta L, Heckman C, Leppä S, Nykter M, Lohi O, Heinäniemi M, Mustjoki S.Cancer Cell. 2020 Sep 14;38(3):380-399.e13. doi: 10.1016/j.ccell.2020.06.002. Epub 2020 Jul 9.PMID: 32649887
Laukkanen S, Veloso A, Yan C, Oksa L, Alpert EJ, Do D, Hyvärinen N, McCarthy K, Adhikari A, Yang Q, Iyer S, Garcia SP, Pello A, Ruokoranta T, Moisio S, Adhikari S, Yoder JA, Gallagher K, Whelton L, Allen JR, Jin AH, Loontiens S, Heinäniemi M, Kelliher M, Heckman CA, Lohi O, Langenau DM.Blood. 2022 Oct 27;140(17):1891-1906. doi: 10.1182/blood.2021015106.PMID: 35544598
Kuusanmäki H, Dufva O, Vähä-Koskela M, Leppä AM, Huuhtanen J, Vänttinen I, Nygren P, Klievink J, Bouhlal J, Pölönen P, Zhang Q, Adnan-Awad S, Mancebo-Pérez C, Saad J, Miettinen J, Javarappa KK, Aakko S, Ruokoranta T, Eldfors S, Heinäniemi M, Theilgaard-Mönch K, Wartiovaara-Kautto U, Keränen M, Porkka K, Konopleva M, Wennerberg K, Kontro M, Heckman CA, Mustjoki S.Blood. 2023 Mar 30;141(13):1610-1625. doi: 10.1182/blood.2021011094.PMID: 36508699
Mehtonen J, Teppo S, Lahnalampi M, Kokko A, Kaukonen R, Oksa L, Bouvy-Liivrand M, Malyukova A, Mäkinen A, Laukkanen S, Mäkinen PI, Rounioja S, Ruusuvuori P, Sangfelt O, Lund R, Lönnberg T, Lohi O, Heinäniemi M.Genome Med. 2020 Nov 20;12(1):99. doi: 10.1186/s13073-020-00799-2.PMID: 33218352
Semisupervised Generative Autoencoder for Single-Cell Data.
Trong TN, Mehtonen J, González G, Kramer R, Hautamäki V, Heinäniemi M.J Comput Biol. 2020 Aug;27(8):1190-1203. doi: 10.1089/cmb.2019.0337. Epub 2019 Dec 2.PMID: 31794242
Sequential drug treatment targeting cell cycle and cell fate regulatory programs blocks non-genetic cancer evolution in acute lymphoblastic leukemia. Malyokova A, Lahnalampi M, Falqués-Costa T, Pölönen P, Sipola M, Mehtonen J, Teppo S, Viiliainen J, Lohi O, Hagström-Andersson AK, Heinäniemi M*, Sangfelt O* co-senior, BioRxiv https://www.biorxiv.org/content/10.1101/2023.03.27.534308v2

Mikro-RNA:t ovat lyhyitä RNA-pätkiä, joita tunnetaan ihmisellä yli 2300. Niiden häiriintyneellä toiminnalla on merkitystä monien tautien synnyssä. Tällaisia ovat esimerkiksi sydän- ja verisuonisairaudet, immunologiset taudit ja syöpä. Turun yliopistossa löydettiin mikro-RNA, joka voi jo varhain ennustaa riskiä sairastua nuoruusiän diabetekseen.
Turun yliopiston professori Laura Elon laskennallisen biolääketieteellisen tutkimusryhmässä kehitetään työkaluja monimutkaisten sairauksien, kuten diabeteksen, syövän ja reuman diagnostiikkaan ja hoitoon. Ryhmä seuloo laskennallisilla menetelmillä potilasdatasta tietoa, joka auttaa löytämään merkkejä sairauksista ja niiden riskitekijöistä.
Elo, joka toimii tutkimusjohtajana Turun biotiedekeskuksessa, etsii potilasaineistosta erilaisia biomarkkereita, jotka voivat ennustaa sairauksien puhkeamisen tai kertoa jotakin hoitovasteesta. Biomarkkeri on tekijä tai ominaisuus, joka ilmentää biologisen tilan muutosta esimerkiksi geeneissä tai proteiineissa.
Suomessa on pitkään yritetty selvittää tyypin 1 diabeteksen syntymekanismeja. Ykköstyypin diabetes johtuu insuliinia tuottavien solujen tuhoutumisesta. Haima ei tuota elimistön tarvitsemaa insuliinihormonia, jolloin verensokeri kohoaa.
”Olemme pitkään tehneet tutkimusta, jonka avulla pystyisimme ennustamaan mahdollisimman varhain, ketkä lapset sairastuvat tyypin 1 diabetekseen. Suomi on luonteva maa tehdä tällaista tutkimusta, koska Suomessa tyypin 1 diabeteksen esiintyminen on korkeinta suhteessa väkilukuun maailmassa.”
Sekä geeniperimällä että ympäristötekijöillä on sairauden syntyyn jokin osuus. Elon ryhmässä etsitään diabetekseen sairastuneista biomarkkereita, jotka voisivat kertoa jotakin taudin kehittymisestä.
Dataa saadaan eri lähteistä. Yksi tärkeä data-aineisto on lapsista saadut seurantamittaukset. Jo vuonna 1994 Suomessa aloitettiin diabeteksen ennustamiseen ja ehkäisemiseen tähtäävä kunnianhimoinen ja laaja tutkimusprojekti DIPP (Diabetes Prediction and Prevention). Projektissa kerätyistä verinäytteistä etsitään tyypin 1 diabetekselle altistavia perintötekijöitä. Lapset, joilla todetaan geneettinen riski sairastua diabetekseen, kutsutaan seurantatutkimukseen.
”Lapsia on vauvasta asti on seurattu vanhempien suostumuksella sairastumiseen tai 15 ikävuoteen saakka.”
Näytteitä otetaan joka kolmas kuukausi ja 2-vuotiaasta eteenpäin puolen vuoden tai vuoden välein. Seulontaan osallistuvat Turun, Tampereen ja Oulun yliopistolliset keskussairaalat.

Näytteitä on kerätty muun muassa sellaisilta lapsilta, joille jossakin vaiheessa tapahtuu serokonversio. Serokonversio tarkoittaa kun autovasta-aineita alkaa ilmaantua vereen. Osa näistä lapsista sairastuu. Seurantatutkimuksessa on mukana sellaisia lapsia, joilla on geneettinen sairastumisriski.
”Suurin osa näistä ei koskaan sairastu eikä kehitä autovasta-aineita. Tavoitteemme on mahdollisimman varhain ennustaa, ketkä sairastuvat. Tätä varten tutkimme sekä niitä, jotka myöhemmin sairastuvat, että niitä, jotka pysyvät terveinä koko seurannan ajan.
Jossakin vaiheessa osalle lapsista tulee vereen autovasta-aineita, mikä indikoi sitä, että elimistö hyökkää itseään vastaan, jolloin haiman beeta-solut alkavat tuhoutua. Nämä pystytään mittaamaan seurantanäytteistä”, sanoo Elo, mutta huomauttaa, että iso osa lapsista, joita seurataan, eivät koskaan sairastu eivätkä kehitä autovasta-aineita.
Menetelmänä on verrata sairastuneiden lasten näytteitä näytteisiin, jotka on saatu mahdollisimman samankaltaisista terveistä lapsista.
Vertailun avulla Elon tutkimusryhmä löysi yhden lupaavan biomarkkerin, tietyn mikro-RNA:n.

”Mikro-RNA:t ovat hyvin lyhyitä RNA-pätkiä, jotka voidaan laskea kuuluvaksi epigeneettiseen säätelyyn – ne säätelevät siis solujen toimintaa koodaamatta proteiineja. Mikro-RNA:t voidaan tunnistaa verestä.”
Mikro-RNA:t on yhdistetty erilaisiin sairauksiin, kuten diabetekseen. Eri näyteryhmien vertailun perusteella löydettiin tutkimuksessa mikro-RNA (6868-3p), joka vaikuttaa varsin lupaavalta.
”Eri näyteryhmien väliltä etsittiin mikro-RNA:ta, joka assosioitiin sairastumiseen ja ei-sairastumiseen seuranta-ajan kuluessa. Tässä tapauksessa yksi mikro-RNA selvästi näytti liittyvän sairastumiseen.”
Tätä tulosta lähdettiin tutkimaan laboratoriokokein lisää.
”Meidän aineistosta pystyttiin erottamaan tämä markkeri hyvin varhaisessa vaiheessa – ja itse asiassa ennustamaan tällä hetkellä käytetyjä markkereita aikaisemmin kuka myöhemmin sairastuu ja kuka ei.”

Laura Elo korostaa, että hänen ryhmänsä kehittämät laskentamenetelmät sopivat toki muidenkin sairauksien tutkimiseen kuin diabetekseen. Koska näytteitä voidaan mitata verestä, ajatuksena on, että veri heijastelee tautiprosesseja myös muualla elimistössä. Esimerkiksi diabeteksen ollessa kyseessä haimasta on vaikeaa saada näytteitä.
”Olemme myös analysoineet esimerkiksi proteiinitasoja eri autoimmuunisairauksissa ja syövissä. Diagnoosi tapahtuu usein vasta jossakin vaiheessa kun alkaa olla kliinisiä oireita. Meitä motivoi laskentamenetelmien kehittämisessä se, että voimme pitkiä seurantamittauksia hyödyntämällä löytää sairauksille hyvin varhaisia markkereita.”
Elon mukaan enenevässä määrin onkin tajuttu, että ei kannata ottaa pelkästään yhtä mittausta.
”Seurantatutkimuksella saadaan ajan kuluessa ihmisestä ikään kuin oma referenssinsä, jolloin pystytään seuraamaan muutoksia elimistössä ja selvittämään paremmin tautiin liittyviä prosesseja. Markkerina voi olla molekyyli, joka assosioituu sairauteen. Mikro-RNA on yksi esimerkki tällaisesta lähestymistavasta.”
Elon mukaan tulevaisuudessa on otettava sairauksien tutkimisessa huomioon eri omiikat, kuten genomiikka (DNA), proteomiikka (valkuaisaineet), transkriptomiikka (RNA) tai metabolomiikka (aineenvaihdunta). Elon ryhmä onkin käyttänyt Suomen ELIXIR-keskuksen CSC:n laskentaresursseja laajojen mittausaineistojen prosessointiin.
”Julkaisimme hiljattain uuden pitkittäismallinnusmenetelmän Nature Communications -lehdessä.
Meidän menetelmämme tavoitteena on löytää mahdollisimman luotettavia markkereita pitkittäisaineistoista ja fokus oli erityisesti proteiinimittauksissa. Tärkeä kysymys on, miten pystyisimme luotettavasti analysoimaan kohinaista dataa. Vertailimme aikaisemmin käytettyjä menetelmiä ja saimme hyviä tuloksia sekä simuloiduissa ja oikeissa aineistoissa. Pystymme nyt entistä luotettavammin löytämään sellaisia proteiineja, jotka esimerkiksi assosioituvat sairauksiin.”
Kun laboratorioon lähdetään vahvistamaan löydöksiä niin se on pitkä ja kallis prosessi. Siksi luotettavien muutosten ja markkerien löytäminen on tärkeää.
Ari Turunen
10.6.2023
Lue artikkeli PDF-muodossa
Sitaatti
Nyrönen, T., & Turunen, A. (2023). MicroRNAs may reveal type 1 diabetes. https://doi.org/10.5281/zenodo.10017409
Turun biotiedekeskus
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org

Mullistava yksittäisten solujen RNA-sekvensointi (scRNA-seq) mittaa kaikkien geenien aktiivisuudet jokaisessa solussa erikseen, jolloin saadaan aiempaa tarkempi kuva solujen eroavaisuuksista. Tämä tekniikka tuo valtavasti uutta tietoa sairauksista, kuten syövästä. Syöpäsoluja on kasvaimessa miljoonia. Datan analysointi vaatii yhä enemmän laskentakapasiteettia ja tehokkaita algoritmeja, kun analysoitavien solujen ja yhdistettävien näytteiden määrät kasvavat.
RNA kuljettaa solussa valmistusohjeet DNA:sta proteiineihin. RNA vaikuttaa geenien ilmentymiseen, siis geeniä vastaavan proteiinin tuottamiseen. Yksisolutekniikalla pystytään mittaamaan kaikkien geenien RNA-tasot jokaisesta solusta erikseen. Yhdestä potilaan kudosnäytteestä voidaan nykytekniikoilla profiloida tuhansia, jopa kymmeniä tuhansia soluja. Näytteestä voidaan luotettavasti profiloida, minkä tyyppisiä soluja se sisältää.
”Vaikka solut näyttäisivät mikroskoopin alla samanlaisilta, niiden tehtävä voi tarkentua täysin erilaiseksi, kun päästään katsomaan geenien ilmentymistä yhden solun tarkkuudella”, sanoo tutkija Päivi Saavalainen.
Saavalainen työskentelee Folkhälsanin tutkimuskeskuksessa ja hän on myös yksisolutekniikkaan erikoistuneen yrityksen SCellexin toimitusjohtaja. Saavalainen, joka on yhdessä Suomen ELIXIR-keskus CSC:n kanssa järjestänyt yksisoluanalytiikan kursseja tutkijoille, pitää yksisolutekniikkaa yhtenä mullistavimmista menetelmistä biotieteissä viimeisten vuosien aikana.
”Esimerkiksi syöpätutkimuksessa on tärkeää saada dataa yhden solun tarkkuudella. Syöpäsolut nimittäin muuttuvat koko ajan, jolloin jokainen solu alkaa olla erilainen. On myös geenimutaatioita, joiden seurauksena tietyt geenit käynnistyvät ja tiettyjen toiminta lakkaa.”
Saavalaisen mielestä yksisoluresoluutio on tärkeä myös terveiden kudosten tutkimisessa, koska voidaan selvittää minkälaisia solutyyppejä kudoksista löytyy.
”Pelkästään perustutkimukseen yksisoluresoluutio on tuonut valtavasti uutta tietoa. Pitkään luultiin, että ihmisellä on noin 200 erilaista solutyyppiä, mutta yksisoluanalyysien avulla niitä on nyt tunnistettu jo yli 500.”
SCellexin kehittämän uuden tekniikan avulla kudosten rakenteesta voidaan määrittää, millaisia syöpäsoluja kasvaimessa on ja onko esimerkiksi mutaatio vaikuttanut vain tietyssä osassa kasvainta.
”Nyt saadaan tarkasti selville, onko kasvaimessa esimerkiksi jollekin lääkkeelle resistenttejä syöpäsoluja ja millaisia ne ovat”, sanoo Saavalainen.
Saavalaisen mukaan myös syövän immuuniterapiat ovat kehittyneet huimasti. Niissä autetaan elimistön omia immuunisoluja, T-soluja, tunnistamaan ja tappamaan syöpäsolut. T-solut ovat lymfosyyttien eli imusolujen toinen päätyyppi B-solujen kanssa. Ne tunnistavat vieraita rakenteita ja auttavat tuhoamaan viruksen infektoimia soluja sekä syöpäsoluja, joissa mutaatiot ovat muuttaneet omaa perimää ja siten proteiineja.
”Syöpäsolut yrittävät karata T-soluilta. Ne pitävät muuttuneita rakenteitansa piilossa tai erittävät sytokiinejä, jotka hiljentävät T-solut. Lääkkeillä yritetään saada aikaan, että T-solut pääsisivät tunkeutumaan kudokseen, tunnistaisivat aggressiivisesti syöpäsolut ja tappaisivat ne. Nyt voidaan esimerkiksi selvittää, mitä T-solun vieressä oleva syöpäsolu tekee. Tuottaako se jotakin T-solua hiljentävää geenituotetta ja miten T-solu käyttäytyy?”
Saavalaisen mukaan parhaimmassa tapauksessa ymmärretään eri potilaiden syöpäsolutyypit ja löydetään tehokas lääke, jolle potilas saa hyvän vasteen. Voidaan siis löytää keinoja yksilölliseen hoitoon.

Yksisoluanalytiikkaa tehdään yleensä niin, että solut hellävaroen erotellaan kudoksesta ja siirretään yksittäisinä soluina liuokseen, jonka jälkeen niiden sisältämä RNA sekvensoidaan kustakin erikseen. Tällöin kuitenkin solujen alkuperäinen sijainti ja järjestys kudoksessa vääjäämättä muuttuu eli ei tiedetä, mitkä solut olivat alun perin kudoksessa vierekkäin. Nyt ovat tulleet avuksi uudet ns. spatiaaliset tekniikat, joiden ansiosta soluja ei tarvitse enää erotella yksittäisiksi liuoksiksi vaan kudoksesta höylätään ohuita yhden solun paksuisia kerroksia ja kudosleikkeestä otetaan suoraan RNA:ta irti. Kun RNA:t sekvensoidaan, tiedetään, mistä solusta ja mistä kohtaa kudoksesta RNA on saatu.
”Kudosta voidaan siis sekvensoida siten, että solujen paikka tiedetään ja niiden alkuperäinen järjestys säilyy. Spatiaalinen sekvensointi on tämän hetken kuuma juttu”, sanoo Saavalainen.
SCellex kehittää patentoitua tekniikkaa, joissa solujen paikka selvitetään koneoppimisen malleilla ja mikroskooppisen pienillä värikuulilla. Kuulat ladataan analyysisirun 160 000 pieneen kuoppaan ja niiden sattumanvaraisista yhdistelmistä saadaan kuopille visuaalinen koordinaatti, joka voidaan mikroskooppikuvista laskea koneälymallin avulla. Mikrokuuliin kiinnitetyt synteettiset DNA-koodit yhdistetään sirulle asetetuista kudosleikkeistä vapautuviin RNA-molekyyleihin, jotka siten saavat kuopan koordinaatin.

”Meillä on käytössä koneälymalli, joka laskee automaattisesti kaikista sirussa olevista ”kuopista” mitä kuulia siellä on. Koneäly tuottaa siis kartan. Sen jälkeen siruun voidaan liittää varsinainen kudosleike, jonka jälkeen värikuuliin liimatut synteettiset DNA-pätkät nappaavat kudoksesta RNA:n. RNA-molekyylit tarttuvat näihin pätkiin ja saadaan tunniste.”
”Kun RNA:t sekvensoidaan isona joukkona, niin datasta voidaan analysoida mihin värikuulayhdistelmään RNA sopii ja verrata sitten alkuperäiseen mikroskooppikuvaan ja koneälylaskelmaan. Näin saadaan järjestettyä RNA-data oikealle paikalleen”, sanoo Saavalainen.
Datasetit ovat valtavan isoja ja laskentaan tarvitaan Suomen ELIXIR-keskuksen CSC:n palveluja. Saavalaisen mukaan koneoppimisen mallit ovat ensiarvoisen tärkeitä.
”Jos näytteessä on kymmeniä tuhansia soluja ja kaikista niistä on kymmenien tuhansien geenien mittaustulokset, niin mikrokuulien lisäksi itse biologinen RNA-data on valtavan monimutkaista. Sen analysoimiseen tarvitaan koneälyä. Koneäly voi löytää sellaista uutta informaatiota, mikä ei onnistu perinteisillä analyysityökaluilla. Luulen, että CSC:n laskentakapasiteetti riittää meidänkin haasteellisten koneälymallien ratkaisemiseen.”
Saavalaisen mukaan yksisolumenetelmä ei ole vielä tarpeeksi kypsä siihen, että sitä voitaisiin käyttää diagnostiikkaan tai lääkehoitojen määräämiseen. Tällä hetkellä se on kuitenkin hyvä työkalu tutkimukseen.
Ari Turunen
16.5.2023
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Päivi Saavalainen, & Tommi Nyrönen. (2023). Single-cell RNA sequencing enabling individual disease treatment. https://doi.org/10.5281/zenodo.8181234
Lisätietoja
SCellex
Folkhälsan
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org

Keliakia on sairaus, jossa viljatuotteiden – rukiin, vehnän ja ohran – gluteeni aiheuttaa ohutsuolen limakalvolla tulehduksen ja suolinukan vaurion. Vaurion takia ravintoaineet eivät imeydy elimistöön kunnolla. Potilaiden solujen RNA-sekvensoinnin ansiosta voidaan tutkia elimistön immuunijärjestelmää, jos se toimii virheellisesti.
Keliakiaa pidetään autoimmuunisairautena, jossa elimistön puolustusjärjestelmän torjunta kohdistuu virheellisesti omiin kudoksiin. Vaikka keliakian tarkkaa syntymekanismia ei tunneta, sen puhkeamiseen tarvitaan kuitenkin perinnöllinen alttius.
Immunologi Helka Kaunisto Tampereen yliopiston Keliakiatutkimuskeskuksesta tutkii ihokeliakiaa.
”Minua on aina kiinnostanut autoimmuunisairaudet. Niihin sairastuneilla on riski sairastua muihinkin autoimmuunitauteihin.”
Ihokeliakia on keliakian yleinen suoliston ulkopuolinen ilmenemismuoto. Se aiheuttavaa gluteenin syönnin yhteydessä kutiavaa, pienirakkulaista ihottumaa. Sekä keliakiaan että ihokeliakiaan liittyy vahva perinnöllinen taipumus.

”Puolet työstä on RNA-sekvensointia. Emme etsi mitään tiettyä geeniä tai proteiinia sekvensoinnissa, vaan haluamme tutkia minkälaisia muutoksia gluteenin syönti saa aikaan ihokeliaakikkojen RNA-profiilissa.”
Kauniston mukaan on mahdollista, että gluteenin syönti johtaa tiettyjen RNA-molekyylien ekspression muuttumiseen ihokeliaakikoissa. Se kertoo gluteenin vaikutuksesta immuunisysteemiin, kuten esimerkiksi solujen aineenvaihduntaan tai tulehdustilaan.
Samalla voidaan tutkia, miten keliakiassa immuunivaste voi levitä paikallisesta reaktiosta suolessa systeemiseksi reaktioksi, joka leviää iholle tai muihin elimiin. Tällä tarkoitetaan sairauden monimuotoisuutta, johon kuuluvat immunologiset poikkeavuudet.
Kaunisto tutkii immuunisoluja ja immuunipuolustusta selvittääkseen, miksi osalle keliaakikoista tulee ihokeliakia.
”On muistettava, että suolessa ja ihossa on eri kerroksia, jotka toimivat eri tavoin immunologisesti. Ihokeliakia on todella hyvä kohde tutkia keliakian suoliston ulkopuolisia oireita. Tätä tietoa voi hyödyntää myös muiden autoimmuunitautien tutkimiseen. Miten esimerkiksi reumassa tauti voi alun perin olla yhdessä paikassa ja sitten levitä muualle ja muuttua systeemiseksi?”
Noin 10% keliaakikoista sairastaa ihokeliakiaa. Keliakiaa ja ihokeliakiaa voidaan tutkia verestä mitattavien vasta-aineiden avulla. Keliaakikolla sekä ihokeliaakikoilla gluteeni saa aikaan kudosvasta-aineiden muodostumisen.

”Keliakia tunnetaan suolistotautina, mutta siihen kuuluu paljon muita oireita, jotka eivät liity suolistoon lainkaan. Voi olla neurologisia ja ihoon liittyviä ongelmia. Onko immuniteetissa ero keliaakikkojen ja ihokeliaakikkojen välillä? Entä miten immuunivaste voi levitä suolesta iholle? Ja miksi ihottuma syntyy? ”
Keliakian diagnoosissa analysoidaan vasta-ainemääriä. Transglutaminaasit ovat entsyymejä, jotka sitovat kudoksissa proteiineja yhteen. Jos transglutaminaasi 2:n vasta-ainepitoisuudet (S-tGAbA) ovat korkeita, ne viittaavat keliakiaan. Transglutaminaasi 2 muuntaa syödyn gluteenin rakennetta. Tällöin ohutsuolen limakalvo tulehtuu ja vaurioituu.
Keliakiatutkimuskeskuksessa on tehty tutkimus jossa gluteenittomalla ruokavaliohoidolla olleet ihokeliakiapotilaat altistettiin lyhytkestoisesti gluteenille. Ennen altistusta ja altistuksen aikana potilaista otettiin ohutsuoli ja verisolunäyte. Näitä näytteitä tutkimalla selvitetään miten gluteeni vaikuttaa verisolujen ja ohutsuolen RNA ekspressioon.
”Vaikka osalla keliaakikoista on seerumin perustella samat vasta-aineet kuin ihokeliaakikoilla, niin silti kaikki eivät saa ihokeliakiaa,” sanoo Kaunisto.
”Ihokeliakiassa potilailla on transglutaminaasi 2:n vasta-ainetta, mutta heillä on myös vasta-aineita sellaiseen sukulaisentsyymiin kuin transglutaminaasi 3. Transglutaminaasi 3 vasta-aineita löytyy myös iholta, sieltä ihottuman läheltä ja niiden on ajateltu osallistuvan ihottuman kehittymiseen. TG3 vasta-aineita löytyy myös ihokeliakiapotilaiden verenkierrosta. Vaikka myös osalla keliaakikoista on transglutaminaasi 3:n vasta-ainetta verenkierrossa, kaikki keliaakikot eivät kehitä ihokeliakiaa. Miksi näin on, sen haluamme ratkaista.”

Helka Kauniston mukaan tutkimuksesta on paljon hyötyä kliiniselle tieteelle.
”Jos keliakiaa ei esimerkiksi hoideta hyvin eli jos ei siis pysytä gluteenittomalla ruokavaliolla, onko sitten suurempi mahdollisuus, että kehittyy suoliston ulkopuolisia oireita?”

Tutkimuksessa analysoidaan sensitiivisen datan potilasnäytteitä, joihin on saatu potilailta lupa. Koska tämä on EU:n tietosuoja-asetuksen GDPR:n alaista informaatiota, dataa käsitellään CSC:n sensitiivisen datan palveluissa (SD Desktop ja SD Connect).
Sekvensointi on tehty yhteistyössä Helsingin yliopiston kanssa ja koodattu data on kryptattuna tallennettu CSC Connect-palveluun ja analysoitu SD Desktopissa.
Kaunistolla ei ollut aikaisempaa kokemusta suuren kapasiteetin laskentapalvelujen tai tallennuspalvelujen käytöstä.
”Aloin käyttää sensitiivisen datan palveluita, koska tarvitsin enemmän laskentakapasiteettia, mitä yliopisto pystyi tarjoamaan. Tarvitsin tälle tehokkaalle laskennalle tietoturvallisen ympäristön. Mielestäni palvelut ovat hyvin helppoja käyttää, koska verkko-ohjeet ovat erittäin perinpohjaiset. Jos minulla on ongelma, jota en pysty itse ratkaisemaan, helpdesk on aina avulias.”
Kun keliakia huomataan ajoissa, hoito voidaan aloittaa mahdollisimman pian, jotta gluteenin pitkäaikaishaitoilta voidaan välttyä. Gluteeniton ruokavaliohoito on kuitenkin haastavaa, koska gluteenia on monissa elintarvikkeissa.
”Tällä hetkellä ainoa hoito on tiukka gluteeniton ruokavalio. Mutta nykyään tutkitaan myös paljon lääkeaineita mahdollisina tulevaisuuden hoitoina. Keliakiatutkimuskeskuksessakin tehdään paljon yhteistyötä uusia lääkeaihioita kehittävien yritysten kanssa. Lääkkeillä pystyttäisiin tulevaisuudessa kenties ehkäisemään suolivaurioita ja muita vaurioita potilaissa, mutta näillä näkymin ne eivät tule korvaamaan ruokavaliohoitoa. Tampereen yliopiston alustavassa tutkimuksessa havaittiin, että ZED1227-lääkeaihio estää transglutaminaasi 2 toimintaa, ja sen käyttö vähensi gluteenin aiheuttamaa suolivaurioita potilaissa.”
Ari Turunen
12.4.2023
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Helka Kaunisto, Tommi Nyrönen, & Francesca Morello. (2023). Tissue samples analysed with Sensitive Data (SD) services provide new information on celiac disease and other autoimmune diseases. https://doi.org/10.5281/zenodo.8154655
Lue artikkeli:
Lisätietoja:
Keliakiatutkimuskeskus, Tampereen yliopisto
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Geneetikko Petri Auvinen tutkimusryhmänsä kanssa selvittää DNA-näytteiden avulla, mitä Itämeren ekosysteemissä on tapahtunut 10 000 vuoden aikana.
Kairattujen näytteiden avulla voidaan tutkia vanhoja ja nykyisiä eliöitä ja niiden elinympäristöjä. Tästä on hyötyä biodiversiteetin ja ilmastonmuutoksen tutkimisessa. Näytteitä saadaan sedimenteistä, kerrostuvasta maa-aineksesta, jotka ovat siirtyneet paikalle veden, tuulen tai jäätikön vaikutuksesta. Jos sedimenttinäytteistä saadaan eristettyä DNA:ta, siitä voidaan tutkia, millaisia eliöitä alueella on elänyt.
”Tarkoitus on kerätä mahdollisimman syviä sedimenttinäytteitä Itämerestä, jolloin pystyttäisiin tutkimaan Itämeren altaan historiaa. Lisäksi otamme syviä suonäytteitä, jotka kertovat maaperän historiasta”, kertoo Auvinen.
Sedimenttejä ei kerry joka paikkaan, mutta niitä on löydettävissä Itämerestä ja soista.
”Näitä sedimenttejä ei ole tutkittu aikaisemmin näin laajalla paletilla, kuten me. Parhaimmillaan voimme päästä jääkauden aikaisiin näytteisiin, aikaan kun sedimenttejä alkoi mereen kertyä.”
Petri Auvinen työskentelee Biotekniikan instituutin tutkimusjohtajana Helsingin yliopistossa. Hänen tutkimuksensa keskittyy genomiikkaan ja metagenomiikkaan. Kun genomiikassa tutkitaan eliön koko perimää, metagenomiikassa voidaan tutkia ja sekvensoida puolestaan samanaikaisesti lukuisia eliöitä, kuten mikrobeja, samasta näytteestä. Mikro-organismien tutkimus onkin tehostunut huomattavasti. Minkä tahansa ympäristöstä, maaperästä tai suolistosta otetun sekvenssinäytteen perusteella voidaan selvittää mikrobiyhteisön koostumus. Puhutaan mikrobiomista, joka viittaa tietyn elinympäristön mikrobistoon ja sen geenistöön eli metagenomiin.
”Me pystymme sedimentistä sanomaan, milloin se on syntynyt. Tutkimme sedimenteistä mitä mikrobeja, muita eliöitä ja kasveja on tiettynä ajanjaksona ollut.”
Auvisen tutkimusryhmässä on tutkittu jo pitkään ympäristönäytteitä, joita on kerätty maaperästä ja komposteista. Esimerkiksi komposteista on pystytty DNA-näytteiden eristämisen kautta tunnistamaan tuhansia eri bakteerilajeja.
Auvinen on tutkinut paljon mikrobien geneettistä alkuperää.
”Vuonna 2010 julkaisimme ensimmäisen Itämeren liittyvän mikrobiomi-tutkimuksen. Käytimme jo silloin rinnakkaissekvensointi-menetelmiä. Näillä menetelmillä voidaan jopa miljardeja DNA-sekvenssejä määrittää yhdestä näytteestä yhtä aikaa.”
Koska Itämeri on matala, pääsääntöisesti murtovettä sisältävä allas, se kärsii rehevöitymisestä, myrkyllisistä sinileväkukinnoista ja happivajeesta, mitkä kaikki vaikuttavat eliöyhteisöihin. Tutkimusryhmä määritteli pohjoisen Itämeren bakteeriyhteisöjen rakenteita perusteellisella sekvensoinnilla.
Aiemmin tutkittiin yhtä molekyyliä kerrallaan, mutta nyt puhutaan miljoona kertaa suuremmista sekvenssimääristä. Rinnakkaissekvensoinnilla voidaan selvittää sedimenttinäytteessä olevat mikrobit.

Mikrobit voivat tarjota yllättävän paljon uutta tietoa ilmastonmuutoksesta ja biodiversiteetistä.
”En yllättyisi, jos sedimenteistä huomattaisiin, että ympäristön muuttuessa myös mikrobit ovat muuttuneet. Kannattaa pitää mielessä, että melkeinpä kaikki muiden organismien käyttämät aineet ovat mikrobit liuottaneet sedimenteistä. Eli jos mikrobisto muuttuu ympäristössä kovasti niin voi olla, että myös jotkut ekologiset palvelut muuttuvat erilaisiksi.”
Auvinen tarkoittaa tällä luonnon tarjoamia ”palveluita”, kuten pölyttämistä, ravinteiden muuttamisesta ihmisille sopiviksi sekä puhdasta vettä.
”Jos ympäristö muuttuu niin esimerkiksi metsät saattavat hävitä tai vahingoittua pitkäksikin aikaa, jolloin näitä palveluita ei enää voi saada. Ihminen voi johonkin asti selvitä teknologian avulla, mutta jossain vaiheessa eläminen voi tulla hankalaksi tai mahdottomaksi. Toisaalta voidaan ajatella, että ekologisten palveluiden muuttuessa tai vähentyessä ympäristö ei enää pysty ylläpitämään yhtä suurta ihmisten määrää.”
Auvisen ryhmässä on tutkijoita monelta ei alalta. Eri alojen asiantuntijoita tarvitaan, jotta saadaan tarkka analyysi menneisyyden ympäristöistä.
”Tässä on nimenomaan tarkoitus tutkia rekonstruktiota eli miten DNA ja RNA-tietoa voidaan yhdistää näytteiden ajoitukseen, jolloin täsmälleen tiedettäisiin miltä ajalta näyte on.”
Auvinen mainitsee stabiilit isotoopit, joita voidaan käyttää ympäristön olosuhteiden ajalliseen rekonstruktioon. Sitten kasvitieteilijät voivat analysoida esimerkiksi siitepölyn DNA:ta, joka voidaan yhdistää isotooppi-ajotukseen, jolloin pystytään näkemään millainen ympäristö on ollut tuhansia vuosia sitten. Koska sedimenteissä on vanhaa ja uutta DNA:ta eikä vanhaa DNA:ta pystytä erottamaan uudesta, ajoitus on tärkeää.
”Jotta me tiedämme mihin ympäristö on menossa, meidän pitäisi tietää millainen se on ollut aikaisemmin. Pystymme kertomaan 10 000 vuoden ajalta, mitä ympäristössä on tapahtunut. Tätä voidaan käyttää vertailuaineistona mitä tulevaisuudessa tapahtuu.”
Tärkeitä tutkimisen aiheita ovat biodiversiteetin vähenemisen lisäksi kemikalisoituminen. Ne eivät vaikuta pelkästään meihin vaan tuleviin sukupolviin.
”Ihmisten tuottamat kemikaalit, jotka eivät ole luonnosta peräisin, jäävät kiertämään ympäristöön. Meillä on lääkeaineita ja pesuaineita, jotka eivät välttämättä häviä luonnosta enää koskaan. Me emme tiedä, miten nämä kemikaalit pitkällä aikavälillä vaikuttavat ympäristöön. Myös mikromuovin leviäimen luontoon on tätä kemikalisoitumista.”

Osa tutkimuksen sedimentti- ja datanäytteistä analysoidaan ja osa laitetaan säilytykseen, jotta niistä voidaan tutkia muita piirteitä myöhemmin. Mikrobiomien tutkimuksen ohella Biotekniikan instituutissa tehdään paljon tutkimusta ihmisten sekvenssinäytteillä. Kaikki tämä vaatii valtavasti tietoteknistä kapasiteettia.
”Pelkästään meidän instituuttimme tuottaa sekvenssidataa yhdellä laitteella 8 teratavua viikossa. Se on paljon enemmän mitä se oli 10 vuotta sitten. Kun kaikki tekevät tutkimusta tällä tavoin, näen datankäsittelyssä ison haasteen.”
Esimerkiksi koko genomin kattava DNA-sekvenssi on solussa erillisinä palasina, jotka pitää liittää yhteen oikeassa järjestyksessä eli assembloida. Sitten on tehtävä annotointi, jossa etsitään sekvenssistä geenit ja niiden tehtävä.
”Kun assembloidaan genomidataa, pitää olla paljon RAM-muistia, koska kaikki sekvenssit pitää analysoida yhdessä muistitilassa. Tarvitsemme myös lisää levytilaa datan tallentamiseen. Meillä on paljon korkeasti koulutettuja ihmisiä jotka käyttävät päivittäin suurimman osan ajastaan datan kopioimiseen paikasta toiseen.”
Suurin pullonkaula on sensitiivisen datan säilyttäminen.
”Se säilytystila, jota käytämme on liian pieni.”
Toinen haaste on laskentaan käytettävät ohjelmistot. Osa datasta analysoidaan CSC:n ePouta -laitteistolla, mutta osa täytyy tehdä omilla laitteilla.
”Ohjelmistot voivat olla niin hankalia, että niitä ei voida CSC:n isoon systeemiin tehdä. Meillä on virtuaalikoneita, joita me käytetään, mutta niissäkin on omat rajoituksensa. Meillä on myös sellaisia ajoja, jotka voivat kestää taukoamatta kuukausia. CSC:ssä on tuhansia käyttäjiä ja CSC:n ympäristössä on ymmärrettävästi huoltokatkoja.”
Kun esimerkiksi saimaannorpan genomia tehtiin tutkimusryhmässä niin ensimmäiset isot assembloinnit kestivät tuhat tuntia.
”Nyt jo pystymme tekemään isoja genomeja sata kertaa paremmin kuin muutama vuosi sitten. Mutta dataa tulee koko ajan enemmän ja se pitää pystyä tallentamaan tehokkaasti ja siten, että data on vertailukelpoista muun datan kanssa. Datan tallentamisessa, siirtämisessä ja laskemisessa jatkamme CSC:n kanssa yhteistyötä.”
Ari Turunen
20.3.2023
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Petri Auvinen, & Tommi Nyrönen. (2023). DNA isolated from Baltic Sea sediment shedding light on climate change and biodiversity. https://doi.org/10.5281/zenodo.8154641
Lisätietoja:
Biotekniikan instituutti, Helsingin yliopisto
https://researchportal.helsinki.fi/fi/organisations/institute-of-biotechnology
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Kantasoluista kasvatetut soluryppäät, organoidit, tarjoavat uuden tavan mallintaa erilaisia sairauksia, kuten syöpää. Oulun yliopistossa on hyödynnetty uutta alkiokudosten muuntelutekniikkaa syöpää aiheuttavien geenien löytämiseksi.
Kehitysbiologian professori Seppo Vainion tutkimusryhmässä tutkitaan munuaissyöpää aiheuttavia geenejä organoidien avulla. Kantasolut voidaan ohjata muodostamaan elimiä, kuten munuaisia muistuttavia kolmiulotteisia soluviljelmiä, joissa on lähes kaikkia oikeiden elinten solutyyppejä. Organoidit voivat olla myös soluryppäitä, jotka on kasvatettu tietyn potilaan syöpäkasvaimesta otetuista soluista. Organoidit ovat peräisin muutamasta kudoksesta saadusta solusta tai kantasoluista.
”Voimme mallintaa sisäelinten kuten munuaisen kehitystä. Tämän lisäksi työkalupakissamme on metodit luoda, eli toisintaa ihmisessä havaittuja eri sairauksiin liittyviä geenitason muutoksia ihmisen alkion kantasoluissa. Tämän perusta on ns. geenin kohdennustekniikoissa,” sanoo Seppo Vainio.

90% kaikista munuaissyövistä johtuu munuaissolukarsinoomasta. Tautia aiheuttavia tekijöitä ovat mm. tupakointi, ylipaino ja perinnöllisyys. Oulun yliopistossa tutkitaan erityisesti munuaisen kehittymisen ja syövän synnyn samankaltaisuuksia. Tutkimusryhmä tutki geenien ilmentymistä ja selvitti, ovatko jotkut munuaisen kehitykseen osallistuvat geenit myös merkityksellisiä syövän synnylle. Tutkimusryhmässä kokeiltiin erilaisia organoideja. Osassa oli hiiren munuaisen soluja ja syöpäsolujen ja joissakin oli yhdistetty hiiren munuaisen soluja ja ihmisestä saatuja kohdunkaulan syövän soluja.
”Kun yhdistimme alkioasteella olevat munuaisen solut ja munuaissyöpäsolut yhteen organoidiin, alkioasteella olevat munuaissolut eivät muodostaneet munuaiselle tyypillisiä putkimaisia rakenteita. Mutta kun estimme syöpäsoluissa tiettyjen munuaisen kasvuun liittyvien geenien ilmentymisen, syöpäsolujen kasvu hidastui ja huomasimme normaalin putkimaisten rakenteiden kehittymisen, ” sanoo tutkija Anatoliy Samoylenko.
Tutkimusryhmä löysi geenejä, joiden aktiivisuuden poistaminen syöpäsoluissa johti siihen, että alkio pystyi tuottamaan uusia rakenteita normaalisti. Oulussa kehitetty organoidimalli tarjoaa uuden keinon tarkastella haitallisia viestejä, joita syöpäsolut levittävät ympäristöönsä.
Alkioasteella olevat kantasolut ovat mullistaneet tautien tutkimuksen. Kantasoluista voidaan tehdä in vivo -malleja. Organoidien avulla voidaan tunnistaa kasvaimen kasvun ensivaiheet, solujen lisääntyminen ja erikoistuminen, kulkeutuminen ja kuolema.

Tutkija Ilya Skovorodkin pitää organoidien tutkimusta mullistavana.
”Oikea tiede alkaa kokeista. Tavallaan klassinen lääketiede ei voi olla oikeaa tiedettä siinä mielessä, koska ihmisillä ei voi tehdä kokeita.”
Skovorodkinin mukaan organoidit muuttavat tilanteen. Organoidit tarjoavat keinon tutkia ihmisen sairauksia kokeellisesti. Niiden kautta voidaan kehittää uusia lääkkeitä ja hoitoja.
”Olemme luonnollisesti vielä kaukana siitä, että voisimme tutkia kaikkia organismin vuorovaikutussuhteita. Voimme kuitenkin aloittaa solujen välisistä vuorovaikutussuhteista ja kuinka solut viestivät toisilleen.”
Organoidit voivat olla minimunuaisia, minisydämiä tai minisyöpiä.
”Parhaassa tapauksessa voimme saada potilaasta soluja ruumiinavauksen yhteydessä tai esimerkiksi ihosta. Solut voidaan istuttaa takaisin alkioasteelle ja sitten luoda minielimiä. Näin voidaan tehdä kokeita. Minkälainen lääke olisi sopiva potilaalle? Meidän tärkein kiinnostuksen kohteemme on elinten kehitys ja erityisen munuaisen kehitys alkiosta. Organoidi on erittäin vaikuttava työkalu. Oulu oli ensimmäisiä laboratorioita, jotka pystyivät rakentamaan munuaisen organoidin.”
Ilya Skovorodkinin mukaan seuraava askel biolääketieteessä on kasvattaa organoideja, joissa on verenkierto.
”Yksittäisen organoidin avulla voi tutkia solujen välistä vuorovaikutusta ja kuinka elimet toimivat, mutta oikeassa elämässä elimet ovat kytkeytyneet koko organismiin verenkierron avulla. Verenkierron avulla solut saavat kaikki tarpeelliset aineensa ja viestinvälitys tapahtuu solujen ja elinten avulla. Kanan alkion verisuonia voidaan jo kasvattaa organoideissa.”
Skovorodkinin tavoitteena on mallintaa solujen ja elinten välistä vuorovaikutusta. Mikrofluidistiikan eli mikroskooppisten neste- ja kaasuvirtausten hallinnan avulla voidaan rakentaa keinotekoisia verisuonia ja tutkia verenvirtausta elimissä.
Mallinnus edistäisi paljon syöpien tutkimusta.
”Syöpä ei kasva eristyksissä vaan se on aina jollakin tavalla yhteydessä koko organismiin verenkierron avulla.”
Professori Seppo Vainion mukaan organoideista toivotaan yhdessä 3D- biotulostustekniikoiden kautta keinoja myös solu- ja kudosterapioihin.
”Meillä on todella suuri tarve saada ei- hyljittäviä elimiä elinsiirtoihin. Tällaisia menestystarinoina on jo saatu aikaan, ” sanoo Vainio.
Ihmisperäisten näytteiden keräykseen iittyvästä laillisuudesta ja tietoturvasta vastaavat Suomessa biopankit. Biopankit koodavat jokaisen luovuttajan näytteen, joka turvaa henkilön anonymisoinnin.
”Lupien hakeminen on lisännyt kuitenkin byrokratiaa näytteiden ja niihin liittyvien kliinisten tietojen saamisessa tutkimuskäyttöön.”
Vainion mukaan lainsäädäntöä pyritään edistämään niin, että tutkimuksen tekeminen mukaan lukien ihmisorganoidien tuottaminen ja niihin liittyvät potilastiedot turvaavat yksilön anonymiteetin. Tällä hetkellä yliopistosairaalat ja Findata hallinnoivat operatiivisen potilastoiminnan kliinisiä mittaustuloksia.
”Tutkijat voivat uudelleenkäyttää ihmisten sairauksissa havaittuja geenitason muutoksia kantasoluissa ja niistä luoduissa organoideissa. Tämä edustaa perustutkimusta ja tuottaa kokeellista aineistoa, kuten kuva-analyysiä ja geenitason tietoa. Tällaisen digitaalisen aineiston säilyttämiseen CSC tarjoaa jo nyt oivat puitteet.”
Vainion mukaan kokeellisten solulinjojen tiedontuotanto ei ole samassa määrin anoinymisointiin liittyvää ja siksi sen hallinto esimerkiksi CSC:n kautta olisi mahdollista.
”Jos näitä tietoja halutaan linkittää myös potilasaineistoon tämä voisi tapahtua Findatan yhteistyön kautta. Jos organoideja tehdään Suomessa esimerkiksi potilaiden luovuttamista näytteistä, niin tämän prosessin voisi myös luvittaa.”
Ari Turunen
27.2.2023
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Seppo Vainio, Anatoliy Samoylenko, Ilya Skovorodkin, Susanna Kaisto, & Tommi Nyrönen. (2023). Organoids grown from stem cells boost cancer research. https://doi.org/10.5281/zenodo.8154628
Lisätietoja:
Oulun yliopisto
Kehitysbiologan laboratorio
Findata
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Francesca Morello työskentelee CSC:n sensitiivisen datan palveluiden yhteyshenkilönä. Morello ja hänen kollegansa kehittävät työkaluja ja palveluja sensitiivisen datan analysoimiseen, jakamiseen ja julkaisemiseen. CSC myös ylläpitää Suomen osuutta federoidusta EGA:sta (European Genome-phenome Archive), joka on hajautettu palvelu arkaluonteisten biolääketieteellisten tietojen tallentamista ja jakamista varten.
SD Connect on palvelu, jolla voi kerätä ja tallentaa sensitiivistä tutkimusdataa tutkimusprojektin aktiivivaiheessa. SD Desktopin käyttäjät pääsevät suoraan hallinnoimaan dataansa virtuaalikoneympäristössä. Palveluihin pääsee web-käyttöliittymän kautta käyttäjän omalta tietokoneelta.
”Kun käyttäjä on lähettänyt sensitiivisen datansa CSC:hen, data aina salataan, kun se tallennetaan, siirretään ja prosessoidaan palveluissamme. Salaus puretaan vain, kun data annetaan saataville valtuutetuille käyttäjille SD-palvelussa”, Morello sanoo.
Tätä pilvilaskentaympäristöä on helppo käyttää. Morello on hyvin innostunut siitä, että pääsy työympäristöön ei edellytä erityistä teknistä osaamista.
”Tutkijat pääsevät työtilaan muutamalla klikkauksella. Vaikka SD-palvelut sopivat minkä tahansa tutkimusalan sensitiivisen datan hallinnoimiseen, työskentelemme paraikaa mahdollistaaksemme palveluiden jatkokäytön alkaen täysin automatisoidusta datan salauksesta aina laskentaympäristön kustomoinnin virtaviivaistamiseen.”
Palvelut ovat käytettävissä tutkijoille ja opiskelijoille, jotka ovat kytköksissä suomalaisiin akateemisiin organisaatioihin, tutkimusinstituutteihin ja näiden kansainvälisille yhteistyökumppaneille. CSC:n palveluiden käyttäminen edellyttää rekisteröitymistä CSC:n asiakastilille. Vaikka SD Connect ja SD Desktop on suunniteltu mahdollistamaan yhteistyö eri organisaatioiden välillä, data on aina tallennettu CSC:n pilvipalveluihin Suomessa.
Oulun yliopiston kehitysbiologian professori Seppo Vainio tutkii organoideja. Organoidi on yksinkertainen ja pieni versio elimestä, jonka on kasvatettu kantasoluista. Organoidien tutkimukseen liittyy paljon sensitiivisen datan käsittelyä.
”Organoidit mallittavat joko normaalia tai sairauden elintoimintoihin liittyviä solu ja molekyylitason muutoksia. Oleellista on, että tutkijat ovat kehittäneet keinoja tuottaa myös ihmisistä monikykyisiä soluja, jota voidaan sitten kehitysbiologisin signaalein ohjata erilaisiin kehityssuuntiin. Meillä on siis keinot ja reseptit ohjata solut muodostamaan vaikka munuaisen normaalia syntyä mallintavia organoideja. Voimme mallintaa elinten kuten munuaisen kehitystä. Niin ikään meillä on keinot luoda samanlaisia geneettisiä muutoksia ihmisen alkion kantasoluissa, joita havaitaan ihmisen perimässä.”

Seppo Vainion mukaan organoiditutkimus on yksi tieteellinen megatrendi. Nyt on mahdollista mallintaa ihmisen sairauden prosesseja uudella tavalla. Kun useita organoideja yhdistetään, voidaan tutkia myös kudosten ja elinaiheiden vuorovaikutuksia kokeellisesti ihmisessä. Organoidien avulla voidaan tutkia ihmisen sairauksia ja kehittää uusia lääkkeitä ja hoitoja.
”Meillä on ihmisen kantasolukirjastoja Euroopassa. Voimme periaatteessa tehdä jokaisesta ihmisestä oman kantasoluvaraston biopankkiin. Tästä voisimme tuottaa tarpeen mukaan henkilöstä terveyden ja sairauden tutkimukseen henkilökohtaisen sairausmallin.”
Kun tavoite on pyrkiä henkilökohtaiseen terveysteknologiaan ja tietoon, niin kantasolu- tai solubiopankki tarjoaa Vainion mukaan realistiset keinot seurata miten sairaudet kehittyvät. Kaikki tämä edellyttää tutkimusinvestointeja. Vainio toivoo, että Suomen biopankkijärjestelmää voitaisiin kehittää tähän suuntaan.
Yksi kiinnostava kohde ovat iPS-solut. Ihmisen alkion kantasoluja opittiin kasvattamaan 1990-luvun lopulla ja niitä läheisesti muistuttavat indusoidut pluripotentit kantasolut eli iPS-solut kuvattiin vuonna 2007. Näitä iPS-solulinjoja voidaan tuottaa muun muassa potilaan iho- tai verisoluista ja ne voidaan ohjata erilaistumaan haluttuun suuntaan.
”Koska iPS-solut ovat peräisin yksilöistä, hankkeisiin liittyy myös paljon arkaluontoisen potilasaineiston käsittelyä. Tavoite on pyrkiä linkittämään organoideissa tehdyt havainnot yhä paremmin potilasrekisteritietoihin. Tässä kokonaisuudessa sosiaali- ja terveysalan tietolupaviranomainen Findata tarjoaa keinot Suomen runsaslukuisen rekisteritietojärjestelmän hyödyntämiseen. ”
Esimerkiksi FinnGen-tutkimuksen tavoitteena on sairausmekanismien parempi ymmärtäminen ja uusien hoitokeinojen kehittäminen yhdistämällä genomi- ja terveystietoa. Se tarjoaa yli 500 000 suomalaisen geneettisen tiedon. Tieto palautuu sopimuksen mukaan suomalaisiin biopankkeihin, josta geenitieto on vapaasti tutkijoiden käytössä. FinnGen on tunnistanut monia uusia sairauksiin liittyviä geenivariantteja.
”Tutkijat ovat mallintaneet kokeellisesti organoideissa identifioituja variantteja tutkiakseen tarkemmin sairauksiin assosioituneita geenitason muutoksia eli patogeneesiä. Kun tämä tutkimus liitetään sitten jatkossa erilaisten ns. kemikaalikirjastojen ja biomerkkien avulla tehtävään, automaatioon perustuvaan lääkeseulontaan, tämä prosessi luo perustan kiihdyttää organoidien avulla uusien hoitokeinojen kehittämistä.”
Sensitiivisen datan piiriin kuuluvat ihmisistä kerätty data, ekologinen data tai luottamuksellinen data. Henkilötietojen käsittelyä säätelee Euroopan yleinen tietosuoja-asetus GDPR (European General Data Protection Regulation).
”Rekisterinpitäjä on organisaatio tai laillinen edustaja, joka vastaa kaikista päätöksistä, miten dataa käytetään. SD-palvelujen avulla pyrimme tarjoamaan tutkijoille ja heidän organisaatioilleen kaikki työkalut, joilla dataa pääsee hallinnoimaan, kun sitä kerätään, analysoidaan ja käytetään uudelleen,” sanoo Francesca Morello.
Terveys- ja rekisteridatan käsittelyä toisiokäyttöön on tiukasti säädelty kansallisella lainsäädännöllä. SD Desktop on sertifioitu toisiokäytön ympäristö, jonka Suomen sosiaali- ja terveystietojen lupaviranomainen Findata on tarkastanut sääntelyään vastaavaksi. Tässä tapauksessa Findata ja CSC Helpdesk hallinnoivat pääsyä tietoihin ja tiedonsiirtoja.
Morellon mukaan nämä palvelut on suunniteltu siten, että ne tarjoavat tutkijoille ja rekisterinpitäjille kaikki välineet pitää datansa turvassa, mutta palvelut pysyvät joustavina ja helppokäyttöisinä.

Sekvensointi, tallentaminen ja geenisekvenssien käsittely on aikaa vievä prosessi. Ensimmäisessä vaiheessa DNA-sekvenssit voidaan lähettää sekvensointilaitteistolta SD Connect-palvelun kautta suoraan tutkijan työtilaan. Täällä salattu data voidaan helposti jakaa muille tutkijoille URL-osoitteen avulla. Kun datan keräämisen vaihe on ohi, tutkivat voivat luoda virtuaalikoneen SD Desktopilla ja analysoida SD Connect-palveluun tallennettua dataa striimauksen kautta. He voivat myös, jos esimerkiksi halutaan analysoida dataa yhdessä, myöntää pääsyn yhteistyökumppaneille muista organisaatoista vain lukuoikeuksilla.
Kun tutkijat ovat laatineet tulokset geenianalyyseistaan, he voivat julkaista datan valvottua pääsyä pitkin käyttämällä Suomen federoitua EGA-palvelua. Tällöin data-aineistolle myönnetään pysyvä tunniste ja datan uusiokäytön mahdollisuudesta ilmoitetaan kansainvälisesti EGA:ssa. Data pysyy Suomessa, kun taas luvan saaneet tutkijat pääsevät dataan SD Desktop-palvelun datastriimauksen kautta. Vain yksi kopio data-aineistosta lähetetään CSC:hen ja sitä käytetään tutkimuksen kaikissa eri vaiheissa. Federoitu EGA yhdessä täysin yhteensopivan amerikkalaisen virkaveljensä dbGAP:n kanssa ovat ensisijaiset globaalit resurssit, jotka mahdollistavat pääsyn sensitiivisen ihmisperäiseen biolääketieteelliseen dataan, joka on hyväksytty tutkimuskäyttöön.
Ari Turunen
19.12.2022
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Francesca Morello, & Tommi Nyrönen. (2022). Sensitive Data (SD) services for Research: with a few clicks a researcher can launch a personal secure computing environment. https://doi.org/10.5281/zenodo.8154610
Lisätietoja:
Oulun yliopisto
www.oulu.fi/
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
My CSC portal
SD Connect
SD Desktop
https://research.csc.fi/-/sd-desktop
Federoitu EGA

Luonnonvarakeskuksen erikoistutkija Jenni Hultman on kiinnostunut kylmän ilmaston mikrobiyhteisöistä, joilla voi olla myös vaikutusta maapallon ilmastoon. Tundralta löytyy esimerkiksi kasvihuonekaasu metaania syöviä bakteereja ja arkeoneja.
Nyt on saatu myös selville, että tundra on tärkeä kasvihuonekaasujen kuten dityppioksidin lähde. Mikro-organismit, jotka osallistuvat sen tuottamiseen, ovat kuitenkin suurilta osin entuudestaan tuntemattomia. Vaikka saataisiin selville, mitkä mikrobilajit ovat kyseessä, tärkeää on myös tietää, mitä niiden geenit tekevät.
Metagenomiikalla tarkoitetaan kokonaisen yhteisön geenien tutkimista. Termi yleensä viittaa näytteessä olevien bakteerien genomeihin, mutta se tarkoittaa myös muiden mikro-organismien, kuten arkeonien ja sienten ja myös näytteen eukaryoottien perimää. Metagenomiikan menetelmillä voidaan tutkia ja sekvensoida useita eliöitä samanaikaisesti samasta näytteestä. Hultman kollegoineen sekvensoi mikrobiyhteisöistä jopa miljoonia geenejä. Siihen tarvitaan Suomen ELIXIR-keskuksen CSC:n laskentatehoa, koska data-aineistoa on teratavuja.
”Olemme saaneet selville, millaisia mikrobeja subarktisella alueella on ja mitä ne tekevät. Data-aineiston käsittely on vienyt tolkuttoman määrän laskentaresursseja. Löysimme paljon tuntematonta mikrobistoa ja tuntemattomia geenejä.”
Näytteistä saatuja DNA-sekvenssejä on analysoitu ja pyritty tunnistamaan uusia lajeja ja sukulaisuussuhteita. RNA-sekvenssejä analysoimalla on puolestaan selvitetty, mitä mikrobiyhteisöt tekevät näytteenottohetkellä.
”Olen erityisen innoissani, että pääsin käymään talvella näillä samoilla paikoilla. Nyt pystytään selvittämään vuodenaikaisvaihtelua eli mitä mikrobiyhteisöissä tapahtuu kesällä ja talvella ja miten lämpimät syksyt vaikuttavat mikrobitoimintaan.”
Hultman vertaili mikrobiyhteisöistä löydettyjä uusia sekvenssinpätkiä tietokannoissa oleviin.
”Usein tietokannoissa ei samanlaisia sekvenssejä ollut löydettävissä. Suurin osa, yli 90% geeneistä oli tuntemattomia.”

Suomen Lapista, Kilpisjärveltä ja Pallakselta kerättyä mikrobidataa vertailtiin muihin datalähteisiin, kuten Alaskasta ja Ruotsista saatuun dataan. Suurin osa maapallon eliöistä on mikrobeja. Vaikka niitä tavataan kaikkialla ja kaikissa oloissa, on suurinta osaa niistä vaikea viljellä laboratorioissa. Niiden tutkimiseksi tarvitaan uusia tekniikoita, joista yksi on metagenomisekvenssin kokoaminen yhteen. Metagenomista koottu genomi eli MAG (metagenome-assembled genome) on rakennettu metagenomidatasta saadusta näytteestä. Toisin sanoen näytteestä, joka sisältää monia genomeja, yksittäisen lajin genomi palastellaan yhteen. Tämä MAG-data antaa uutta tietoa sellaisista mikrobilajeista, joita ei ole tallennettu ja annotoitu tietokantoihin.

Jenni Hultmanin tutkimuksissa kerättiin yli 800 erilaista MAGia ja vain muutama prosentti näistä oli aiemmin tunnettuja. Yksi mielenkiintoinen MAG oli tuntematon ammoniakkia hapettava arkeoni. Ammoniakkia hapettavat mikrobit ovat tärkeitä tekijöitä typen kierrossa.
”Tuntematonta arkeonia löydettiin ensin kahdesta data-aineistosta, Norjasta ja Suomen Kilpisjärveltä. Sitten kun aloimme selvittää mistä löytyisi vastaavia sekvenssejä metagenomeista, selvisi, että niitä löytyi Kanadasta ja Abiskossa Ruotsissa. Tarkemman tutkimuksen avulla tätä yhtä tiettyä arkeoni-sukua löydettiinkin maapallon molemmilta navoilta. Kiehtova ajatus, että tämä arkeoni-suku oli erikoistunut elämään navoilla ja on tärkeää mainita datan avoimuuden ja saatavissa olevien tietokantojen kautta päästiin tämän arkeoni-suvun jäljille. Arktisilta alueita voi löytyä paljon sellaisia mikrobeja, joista voi olla hyötyä aineiden kierrossa.”
Tällaisia ovat mikrobien tuottamat entsyymit eli proteiinit, jotka nopeuttavat kemiallisia reaktioita.
”Mikrobit pystyvät tuottamaan tehokkaasti paljon entsyymejä kylmissä olosuhteissa. Nämä ovat bioteknisesti kiinnostavia yhteisöjä. Tuotamme isoja avoimia tietokantoja näistä lajistoista, sekvensoimme kaikki ja olemme selvittäneet jo yli tuhat genomia. Entsyymiprosessit voivat olla kiinnostavia, koska kylmissä olosuhteissa on edullisempaa kasvattaa mikrobeja, jotka tuottavat entsyymejä.”
Yhtenä esimerkkinä Hultman mainitsee mikrobeista löytyviä, ligniinin hajottamiseen pystyviä geenejä. Yksi potentiaalinen käyttökohde on fossiilisten materiaalien korvaaminen. Muita kiinnostavia kohteita ovat sienet ja aktinobakteerit.
”Olemme löytäneet tieteelle uusia, mutta pohjoisissa näytteissämme hyvin yleisiä sienisukuja, joissa on hiilihydraattien hajotukseen liittyviä geenejä. Aktinobakteereja, tunnettuja hajottajia, on esimerkiksi komposteissa, mutta on myös hyvin paljon kylmässä eläviä ja erittäin aktiivisia aktinobakteereja.”

Metaani on yksi merkittävimmistä kasvihuonekaasuista. Tampereen yliopiston tutkimuksessa, jossa sekvensointidataa analysoitiin CSC:n laskentaresurssien avulla, todettiin, että metaania syöviä bakteereita, metanotrofeja, voi hyödyntää edullisten biotuotteiden valmistamiseen. Metanotrofit kuluttavat metaania erittäin tehokkaasti kasvuunsa.
Aiemmin mikrobeista tutkittiin vain yksittäisiä lajeja ja oletettiin, että tämä tietty laji toimii vain tietyllä tavalla. Nyt uudet löydökset ovat Hultmanin mukaan kumonneet tämän käsityksen. Esimerkiksi metaania syöviä mikrobeja löytyy monesta eri lajista, bakteerien ohella myös arkeoneista.
”Osa toimii sekä hapellisissa että hapettomissa olosuhteissa. Ennen ajateltiin, että metaania syntyy hapettomissa olosuhteissa ja että sitä syödään hapellisissa olosuhteissa. Syvemmissä maakerroksissa on metanogeenisiä arkeoneja, jotka tuottavat metaania, mutta pintakerroksissa oli metanotrofeja, jotka hapettavat metaania ja joille metaani on ruokaa. Miten löydetään ne olosuhteet, joissa nämä metaania syövät metanotrofit viihtyvät ja miten ne saadaan lisääntymään?”
Jenni Hultman teki opinnäytetyönsä komposteista ja siirtyi sitten näistä kuumista ympäristöistä ikiroutaan ja arktisiin alueisiin. Häntä kiinnostaa, kuinka paljon lämpenemistä arktisilla alueilla tapahtuu ja kuinka paljon hiiltä vapautuu ilmaan mutta myös miten mikrobit toimivat hiilen varastoinnissa. Mikrobeilla on tässä tärkeä rooli.
”Korkeilla leveyspiireillä ilmasto lämpenee aiemmin luultua neljä kertaa nopeammin. Kun päästään perille siitä minkälainen toiminto arktisilla mikrobiyhteisöillä on ja mitä ne tekevät, niin voidaan parantaa ilmastonmuutoksen ennustemalleja. Tämä data pitäisi saada ilmastomalleihin. Tällöin pystyään ennakoimaan tarkemmin mitä muutokset aiheuttavat. Metagenomiikka ja ilmatiede linkittyvät itse asiassa vahvasti yhteen. Mikrobit tuottavat kasvihuonekaasuja ja myös käyttävät niitä.”
Jenni Hultman on käyttänyt työssään SRA-tietokantaa. SRA (Sequence Read Archive) on avoin DNA-sekvensseistä koostuva tietokanta. Sitä ylläpitävät NCBI (National Center for Biotechnology Information), EBI (European Bioinformatics Institute) ja DDBJ (DNA Data Bank of Japan).
”Me tutkijat tuotamme koko ajan valtavasti dataa. Meille ensiarvoisen tärkeää on hyödyntää tietokantoja. Toivoisin, että ELIXIR pystyisi tarjoamaan ajantasaisia tietokantoja. Kun löydän uuden sekvenssipätkän ja haluan katsoa mikä se on, niin minun ei tarvitsisi ladata itselleni kaikkia uusia tietokantoja vaan ELIXIR tarjoaisi ne. ELIXIR mahdollistaa suuren verkoston, joka voisi auttaa tutkijoita datan avoimeen julkaisuun.”
Ari Turunen
30.11.2022
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Jenni Hultman, & Tommi Nyrönen. (2022). Microbiota in permafrost play an important role in climate change. https://doi.org/10.5281/zenodo.8154600
Lisätietoja
Luonnovarakeskus (Luke)
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Huolellinen datanhallinta mahdollistaa laadukkaan tutkimuksen nyt ja tulevaisuudessa. Sen hallinnalle on luotu ns. FAIR-periaatteet eli data on löydettävissä, se on saatavissa, se on yhdistettävissä muihin vastaaviin datakokonaisuuksiin ja sitä voidaan käyttää uudestaan. Näiden periaatteiden pohjalta ELIXIR-infrastruktuuri tarjoaa käyttöön hyviä datanhallintatyökaluja, jotka tukevat tutkijaa datanhallinnan eri vaiheissa.
“Hyvään tieteelliseen käytäntöön kuuluu varmistaa datan säilyminen käyttökuntoisena ja hyvin dokumentoituna koko tutkimusprosessin ajan ja siten, että tutkimustulokset ovat todennettavissa tutkimusprosessin jälkeenkin. On tärkeää, että tutkijat ja tietojärjestelmät voivat löytää ja saada käyttöönsä yhteentoimivia ja uudelleenkäytettäviä tutkimusaineistoja. Tämän edistämiseksi vuonna 2016 julkaistiin FAIR-periaatteet”, sanoo CSC:n datanhallinnan asiantuntija Minna Ahokas.
”ELIXIRin tarjoamien ohjeiden ja työkalujen avulla tutkijan on helpompi tehdä datansa löydettäväksi, saavutettavaksi, yhteentoimivaksi ja uudelleenkäytettäväksi ja samalla noudattaa datanhallinnassaan FAIR-periaatteita.”
Yhteistyössä eri jäsenmaiden ELIXIR-keskusten kanssa luotu RDMkit-sivusto pyrkii tukemaan ja yhtenäistämään datanhallinnan käytäntöjä Euroopassa.
RDMkit sisältää ohjeita ja vinkkejä aineiston koko elinkaaren ajalle: datanhallinnan suunnittelusta ja data-analyyseistä aina datan julkaisemiseen ja uudelleenkäyttöön.
”RDMkit on toteutettu niin, että jokainen joka on tekemisissä datan kanssa voi ottaa sen työkalupakikseen. Se tarjoaa ohjeistuksen lisäksi linkit palveluihin, joita tutkija tai tutkimuksen tukipalveluissa työskentelevä tarvitsee datanhallinnan eri vaiheissa”.
Suomen ELIXIR-keskus eli CSC on yksi niistä, joka tuottaa sisältöä ja ylläpitää työkalupakettia.
Ahokas korostaa, että sivustoa on suunniteltu alusta lähtien läpinäkyvästi yhteistyössä tutkijoiden ja datanhallinnan asiantuntijoiden kanssa. Kuka tahansa ELIXIR-infrastruktuuriin kuuluvista voi osallistua kehitystyöhön. Kaikki on dokumentoitu ohjelmakehitys-projekteille tarkoitettuun GitHub-portaaliin.
”RDMkitissä dataa tarkastellaan sen elinkaaren vaiheiden kautta. Datan keräämiseen, kuvailuun tai julkaisemiseen on tarjolla omat ohjeensa.”
RDMkit kehitettiin ELIXIR-CONVERGE –hankkeessa. Datanhallinnan yhtenäistämiseen oli tarvetta, koska tutkimushankkeet ovat pääasiassa kansainvälisiä ja dataa liikutellaan kansallisten rajojen yli.
”RDMkit on ensimmäinen iso kansainvälinen yritys yhtenäistää datanhallinnan käytäntöjä ja ohjeistuksia, jotta saadaan uudelleenkäytettävää, sekä riittävästi, yhtenäisillä standardeilla kuvailtua ja laadukasta dataa. Datanhallinnassa on kyse siitä, että datan keruu, käsittely ja kuvailu suunnitellaan ajoissa: miten ja missä dataa säilytetään ja miten eri versioita hallitaan. Sitten on vielä mietittävä, onko datassa jotakin sellaista, mikä pitäisi säilyttää pitkäaikaisesti. Toisaalta pitäisi myös päättää, mikä osa datasta voidaan hävittää.”
Minna Ahokkaan mielestä on tärkeää tarjota tutkijoille palveluja, jotka auttavat heitä noudattamaan datanhallinnan hyviä käytäntöjä.
”Yritämme välttää tilannetta, että tutkijoille esitetään esimerkiksi rahoitushakujen yhteydessä aina uusia listoja datanhallinnan vaatimuksista, mutta ei osoiteta niihin sopivia palveluita. Jos vaadimme, että tutkimushankkeiden datanhallinnassa noudatetaan FAIR-periaatteita, meidän pitää tarjota riittävästi tukea ja palveluita FAIR-datan tuottamiseen.”

CSC, suomalaiset tutkimusorganisaatiot ja yliopistot ovat luoneet kansallisen datatuki-verkoston. Verkosto toimii CSC:n ja organisaatioiden datatukihenkilöstön yhteistyön tukena. Se tarjoaa foorumin avoimelle keskustelulle, kysymysten esittämiselle ja vertaistuelle.
Esimerkiksi Aalto-yliopistossa on lanseerattu tieteenalakohtaiset ”data-agentit”, jotka ovat datanhallinnan asiantuntijoita ja heillä on tutkijatausta. He huolehtivat yhdessä tutkijoiden kanssa datasta.
RDMkitin julkaisuvaiheessa datanhallintaan kohdistui COVID 19 -pandemian vuoksi aivan uudenlaisia paineita.
”Kun RDMkit oli saatu lähes valmiiksi, maailmaan iski COVID. Silloin totesimme ELIXIR-CONVERGE -hankkeessa, että myös COVID-virukseen liittyvä data ja sen vaatimukset pitää huomioida. Siksi RDMkitiin toteutettiin nimenomaan COVID 19 -datan käsittelyyn liittyvää ohjeistusta sekä Euroopan COVID 19 -dataportaalia koskeva sivu.”
RDMkit ja ELIXIRin datanhallinnan ohjeistukset ovat päätyneet myös osaksi EU:n Horizon Europe rahoitusinstrumentin datanhallinnan ohjeita.
Biotietieteissä suositellaan RDMKit-työkalupakin hyödyntämistä. Se on herättänyt myös maailmanlaajuista kiinnostusta. Yhdysvaltalaisia käyttäjiä on huomattava määrä ja NIH (National Institutes of Health) on kiinnostunut yhteistyöstä ELIXIR-infrastruktuurin kanssa.
RDMkit on yleinen datanhallinnan ohjekokoelma, josta linkataan eteenpäin esimerkiksi IceBearin kaltaisiin työkaluihin.
”IceBear on tehty alun perin kristallografiaa ja rakennebiologian tiedonhallintaa varten”, sanoo professori Lari Lehtiö Oulun yliopiston biokemian ja molekyylilääketieteen tiedekunnasta.

Lehtiö on myös rakennebiologian tutkimusinfrastruktuurin Instructin Oulun yksikön johtaja. Biocenter Oulun rakennebiologian yksikössä suunniteltiin professori Rik Wierengan ja sovelluskehittäjä Ed Danielin avulla rakennebiologian datanhallintaohjelma IceBear. Sovelluksen kehitystyötä on tehty myös ELIXIRin koordinoimassa EOSC-Life verkostossa, johon myös Instruct kuuluu. EOSC-Life projektin tuella IceBear siirrettiin CSC:n ylläpitämään cPouta-pilvipalveluun.
Biocenter Oulussa kiteytetään proteiineja ja muita makromolekyylejä. Proteiinien aminohappoketju on laskostunut kolmiulotteiseksi rakenteeksi, joka on kullekin proteiinille tyypillinen. Koska mahdollisia erilaisia laskostumisen tapoja on valtavasti, proteiinirakenteita on jouduttu selvittämään laboratorioissa kokeellisesti, kiteyttämällä. Proteiinin kolmiulotteinen rakenne pystytään selvittämään sen perusteella miten röntgensäde siroaa proteiinikiteestä. Kerätystä sirontadatasta voidaan matemaattisella muunnoksella laskea proteiinin elektronitiheyskartta, joka kertoo atomien paikat proteiinissa. Nykyään käytetään rakennetutkimuksessa paljon myös kryoelektronimikroskopiaa, jossa proteiineista valmistettua jäädytettyä näytettä pommitetaan elektroneilla ja miljoonat yksittäiset proteiinien 2D-kuvat yhdistetään kolmiulotteiseksi rakenteeksi.
Apuna proteiinien kiteytyksessä on automaattisia kuvantamislaitteistoja. Proteiinit kiteytetään eri liuoksissa, jolloin joissakin olosuhteissa tapahtuu kiteiden muodostuminen.
”Proteiini kiteytetään pisaraan ja tätä seurataan kuvantamalla. Levyissä voi olla 300 pisaraa ja levyjä monta sataa. Kun niitä kuvataan joka päivä, kuvia tulee aika paljon. Kiteytys tehdään yleensä roboteilla,” sanoo Lehtiö.
Kidenäytteet poimitaan käsin mikroskoopista ja laitetaan nestetyppitankkeihin. Nyt IceBear-ohjelman avulla voidaan samalla sujuvasti pitää kirjaa automaattisesti näytteistä ja niihin liittyvästä tiedosta.
”Usein näytteet lähetetään toiseen infrastuktuuriin, eri synkrotroneihin Eurooppaan. IceBearin avulla tiedetään, mitä näytteelle tapahtui toisessa paikassa. Metadataa liikutellaan eurooppalaisten synkrotronien käyttämien tietokantojen ja IceBearin välillä. Näytteessä on metadataa aika paljon, kuten mikä proteiini oli kyseessä ja millainen rakenne sillä oli, miten se kiteytettiin ja minkälaiset olosuhteet kiteytyksessä olivat.”
Icebearin avulla päästään eroon käsin tehdystä kirjanpidosta. Dataa voidaan lähettää ilman kaavakkeiden täyttöä ja linkit ovat tietoturvallisesti luotu näytteiden viivakoodeihin.
“Kun tämän tekee kerran, se on siinä. Tämän sovelluksen arvo esimerkiksi tutkijoiden ajan säästämisessä näkyy myös vuosien kuluttua”, sanoo Lehtiö.
Sitaatti
Ari Turunen, Minna Ahokas, & Tommi Nyrönen. (2022). Reusable, accurately described and high-quality data – tools created by the research community for agile data management. https://doi.org/10.5281/zenodo.8154582
Lisätietoja:
RDMkit
https://rdmkit.elixir-europe.org/covid19_data_portal
ELIXIR CONVERGE
https://elixir-europe.org/about-us/how-funded/eu-projects/converge
COVID-19 dataportaali
https://www.covid19dataportal.org
EOSC-Life
https://elixir-europe.org/news/eosc-life-start
IceBear
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Suomen Akatemian tutkijatohtori Guilhem Sommeria-Klein kehittää matemaattisia malleja mikrobiyhteisöistä. Hänen tavoitteenaan on rakentaa tilastollinen kehikko mikrobiyhteisöjen rakenteen kuvaamiseen. Näitä malleja voidaan sitten soveltaa eri ympäristöihin, kuten merien tai ihmisen suoliston mikrobiomeihin. Tavoitteena on ymmärtää mikrobistojen rooli ekosysteemien toiminnassa tai ihmisten terveydessä. Turun yliopistossa tehtävän tutkimuksen tuloksena syntyy avoimen lähdekoodin laskentamenetelmiä, joita myös muut tutkijat voivat hyödyntää omassa työssään.
Mikro-organismien tutkimus on tehostunut huomattavasti suurta kapasiteettia hyödyntävän DNA-sekvensoinnin ansiosta (high-throughput DNA sequencing). Menetelmä mahdollistaa minkä tahansa ympäristöstä otetun sekvenssinäytteen perusteella mikrobiyhteisön koostumuksen selvittämisen, oli sitten kyse maaperästä, valtameristä tai suolistosta.
”Ensin katsomme, mitä näytteistä saaduista DNA-pätkistä eli sekvensseistä voidaan löytää tietokannoista. Jos samanlaista sekvenssiä ei löydy tietokannoissa, on vaikeaa tietää mikä se on. Esimerkiksi valtameristä löytyy paljon organismeja, joita emme tunne. Olemme siis loppujen lopuksi riippuvaisia tietokannoista.”
Somneria-Klein kuitenkin korostaa, että kaikkia plankton-lajeja ei voida mahdollisesti sisällyttää tietokantoihin.
”Kaikkia plankton-lajeja ei voida ikinä kuvailla ja sekvensoida. Valtava monimuotoisuus yksinkertaisesti tekee siitä mahdottoman tehtävän.”
Ongelma voidaan kuitenkin ohittaa. Eri mikrobiyhteisöjä voidaan luokitella laskennallisten menetelmien avulla ns. operationaalisiin taksonomisiin yksiköihin (OTU). Luokittelu perustuu DNA-sekvenssien samankaltaisuuksiin ja sitä käytetään paljon mikrobien tutkimuksessa. Samankaltaisuutta määrittää yleensä tietty mikrobeissa esiintyvä geenisekvenssi. Tämä sekvenssi on valittu perustuen sen laaja-alaiseen esiintymiseen ja stabiilisuuteen kohdennetuissa mikro-organismeissa.
”Kiehtovaa, että samanlaista dataa tulee hyvin erilaisista ekosysteemeistä DNA-sekvenssien analyysin perusteella. Organismit, varsinkin bakteerit, eivät ole välttämättä erilaisia, elivätpä ne ihmisen suolistossa tai valtamerissä.”
Ympäristöstä noukittuja ja sekvensoituja mikrobiston geenejä analysoidaan yhdessä ryppäässä samalla tavoin kuin yksittäisen lajin geenejä. Tämä lähestymistapa, metagenomiikka, on yleinen konsepti mikrobien tutkimuksessa.
”Metagenomiikan avulla voimme vertailla eri paikkojen mikrobiyhteisöistä kerättyjä näytteitä ja tutkia niiden spatiaalisia variaatioita esimerkiksi. Voimme myös selvittää, mitä tietyt geenit mikrobiyhteisöissä tekevät ja miten niiden toiminta muuttuu eri paikoissa ja olosuhteissa.”

Toisin kuin maalla, merissä mikrobit tuottavan suurimman osan biomassasta. Merissä on isoja mikrobiyhteisöjä eli mikrobiomeja. Kasviplanktonit ovat olennainen osa valtamerten mikrobiyhteisöjä. Nämä organismit voivat yhdistää vettä ja hiilidioksidia käyttämällä auringonvalosta saatua energiaa muodostaakseen orgaanisia molekyylejä, joista koostuvat kaikki elävät organismit. Ne tekevät samaa kuin kasvit maalla eli yhteyttävät.
”Koska avomerellä ei ole kasveja, kasviplankton muodostaa perustan koko valtamerien ravintoketjulle”, sanoo Sommeria-Klein.
Prosessi myös vapauttaa happia: kasviplankton vastaa 50% ilmakehän hapesta. Sillä on merkittävä vaikutus meriveden happipitoisuuteen ja siten myös mahdollistaa eläinten elämisen meressä.
”Vaikka kasviplankton tarvitsee valoa, sitä on usein itse asiassa kaikkein eniten noin sadan metrin syvyydessä, jossa ravinteita kuljettava kylmempi vesi merten syvyyksistä kohtaa auringonvalon. Valtameri on kolmiulotteinen ympäristö: jos tutkii vain pintaa, menettää paljon. Biomassaa on paljon enemmän valtameren syvyyksissä, tuhansiin metriin saaakka, kuin olemme aiemmin ajatelleet. Siellä on pimeää, joten yhteyttämistä ei tapahdu. Mutta koska paljon orgaanista ainetta vajoaa pohjaan, se myös ravitsee ekosysteemiä syvyyksissä.”
Guilhelm Sommeria-Klein hyödyntää valtavaa datamassaa, joka kattaa kaikki valtamerialueet eri syvyyksistä. Tara-tutkimusalus keräsi vuosina 2009-2013 DNA-aineistoa maailman meristä. 35 000 näytettä kerättiin 210 eri paikasta ympäri maailmaa. DNA-analyysissa havaittiin yli 40 miljoonaa geeniä, joista enemmistö oli tieteelle uusia. DNA-näytteistä voitiin erottaa noin 250 000 erilaista molekulaarista ”planktonlajia”. Analyysi perustui metaviivakoodi-menetelmään, jolla tarkoitetaan DNA-sekvenssien analysointia tietyltä genomin alueelta, jotta saataisiin tunnistettua eri lajeja tai yksilöitä.
”Valtameri antaa itse asiassa kasviplanktonin lisäksi suojapaikan hyvin suurelle valikoimalle mikrobeja. Tämä näkemys oli hyvin aliarvostettu ennen Taran tutkimusmatkaa. Mikrobiset eukaryootit erityisesti ovat hyvin monimuotoisia mutta kuitenkin huonosti tunnettuja. Tämän lisäksi planktonin maantieteelinen levinneisyys ei ole hyvin tiedossa, koska niiden elinympäristön tutkiminen on vaikeaa. Viimeaikaisessa tutkimuksessamme analysoimme eukaryoottisten plankton-ryhmien maantieteellistä levinneisyytä eri puolilla maailmaa ja tarkastelimme tätä niiden ratkaisevien erityispiirteiden valossa.”
Sommeria-Klein on kiinnostunut, mitä nämä mikrobiyhteisöt tekevät ja miten niiden toiminta vaihtelee eri puolilla maailman meriä.
”Planktonit liikkuvat alituisesti valtamerten virtausten mukana. Virtaukset muodostavat uudelleen yhteisöjä ja vievät mukanaan organismeja erilaisiin ympäristöoloihin. Minua kiehtoo se, miten nämä yhteisöt voivat edelleen vuorovaikuttaa ja erikoistua ja kehittyä haastavissa olosuhteissa.”

Valtameret ovat myös tärkeässä roolissa hiilinieluna. Plankton-yhteisöt vaikuttavat tähän suuresti sitomalla ilmakehän hiilidioksidiä yhteyttämisen avulla. Hiili sitten kierrätetään valltameren ravintoketjussa ja lopulta eristetään merenpohjaan, kun kuolleet organismit vajoavat pohjalle.
”Ilmaston lämpeneminen muuttaa veden lämpötilaa, mutta myös merivirtoja. Nämä muutokset yhdessä voivat aiheuttaa perusteellisia seuraamuksia ekosysteemissä, kuten vaikutukset kalakannoissa ja kuinka paljon meret voivat toimia hiilinieluna.”

Guilhelm Sommeria-Klein haluaa kehittää datan analysoimiseen ja tulkintaan entistä tehokkaampia menetelmiä. Tutkimuksessaan hän ei erikoistu puhtaasti matematiikkaan eikä biologiaan vaan yrittää kuroa umpeen katkoksia eri tutkimusalojen välillä.
”Tämä on tieteelliseen laskentaan keskittyneen tutkimusryhmämme ydinalaa, jota Sommeria-Kleinin työ erinomaisesti tukee”, sanoo Turun yliopiston apulaisprofessori Leo Lahti, jonka ryhmässä kehitetään koneoppimismalleja mikrobiryhmien seulomiseen.
”Mikrobiekologiassa on erityisen vahva tarve tällaiselle laskennalliselle perustutkimukselle. Näiden mallien avulla monimuotoinen mikrobien ekosysteemi voidaan palauttaa muutamiin yksinkertaisiin perusrakenteisiin. Merten mikrobiomin tutkimus on kiinnostavaa myös esimerkiksi Itämeren tilassa tapahtuvien muutosten seuraamiseksi. Tilastolliseen päättelyyn pohjautuvilla malleilla voidaan ottaa huomioon jo tunnettuja ennakkotietoja ja kuvata päättelyn varmuutta tuloksissa. Tässä tarvitaan CSC:n suurteholaskentaa, koska näiden mallien sovitus sisältää vaativaa laskentaa.”
Sommeria-Klein haluaa tutkia myös tulevaisuudessa erilaisia ekosysteemejä, jotka poikkeavat toisistaan.
”Haluamme tuoda yhdenmukaisen perspektiivin mikrobiekologiaan ekosysteemistä toiseen, koska sillä on merkittäviä seurauksia niinkin erilaisiin yhteiskunnallisiin asioihin, kuten ihmisen terveys, valtamerien ruokaketju ja globaali hiilen kierto.”

Ari Turunen
29,9.2022
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Guilhaume Sommeria-Klein, Leo Lahti, & Tommi Nyrönen. (2022). Gene sequencing used for study of structure and functioning of microbial communities in oceans. https://doi.org/10.5281/zenodo.8154571
Lisätietoja:
Turun yliopisto
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC –Tieteen tietotekniikan keskus Oy.

Antibiooteille vastustuskykyiset bakteerit kantavat resistenssigeenejä ja niistä tulee usein mikrobipopulaatioissa vallitsevia. Bakteerit voivat myös mutatoitua ja saada muilta mikrobeilta geenejä, jotka tekevät niistä antibiooteille vastustuskykyisiä. Suomen Akatemian tutkijatohtori Katariina Pärnänen etsii ja tunnistaa näitä geenejä, jotka on kerätty tietokantoihin eri ympäristöistä ympäri maailmaa.
Antibiootteja eli mikrobien tuottamaa ja toisia mikrobeja, erityisesti bakteereja tappavia lääkeaineita on käytetty infektioiden torjunnassa jo 1930-luvulta lähtien. Kun antibiootteja käytetään, alkaa syntyä näille lääkkeille vastustuskykyisiä bakteereja, varsinkin jos antibiootteja käytetään väärin tai liikaa. Tilanne pahenee koko ajan ja ihmisiä kuolee infektioihin, joihin antibiootit eivät tehoa. Katariina Pärnänen tutkii Turun yliopistossa antibioottiresistenssiä.
”Käytännössä tämä tarkoittaa sitä, että henkilöllä on joku antibiootille vastustuskykyinen bakteeri, joka aiheuttaa infektion. Kun tulehdusta yritetään hoitaa antibiooteilla, niin paranemista ei tapahdu. Nykyään on hyvin tavallista, että antibiootille vastustuskykyiset bakteerit eivät ole vastustuskykyisiä vain yhdelle vaan esimerkiksi 15 eri antibiootille.”

Bakteerien resistenssigeenit ovat kasvava maailmanlaajuinen ongelma. Niitä on maaperässä, jätevesissä, kalankasvattamoissa ja eläintiloilla, eikä vain ihmisen suolistossa. Lopulta ympäristönkin resistenssigeenit saatavat päätyä lopulta myös ihmisen suolistoon.
”Minua kiinnostaa kaikki mikrobeissa. Tutkimuksiani edistää, että ymmärrän myös jonkin verran mitä sikatiloilla, kalankasvattamoilla tai Indonesian suurkaupungin läpi virtaavassa joessa tapahtuu. Helsingin yliopistossa tutkin vauvojen suolistomikrobistoa ja miten vauvojen saama äidinmaitokorvike tai imetys ovat yhteydessä resistenssigeenien määrään. Tavallaan tutkimukseni edustaa ”yksi terveys”-suuntausta”, Pärnänen toteaa.

Kun 2000-luvun alussa havaittiin uusia virustauteja ja niiden uhkia, syntyi One Health and Global Health -tutkimussuuntaus: kokonaisvaltainen käsitys ihmisten ja eläinten terveyden ja ekosysteemin suojelemisen tärkeydestä. Lääkärien ja eläinlääkärien aloittama liike edustaa poikkitieteellistä lähestymiskulmaa, jossa on mukana paikallinen, alueellinen, kansallinen ja globaali taso.
”Haluan ymmärtää antibioottiresistenssiä sekä ihmisten terveyteen että eläin- ja ruoantuotantoon sekä ympäristöterveyteen liittyvänä ongelmana. Aiemmin olen tutkinut miten resistenssigeenit siirtyvät äidiltä lapselle ja miten imetyksen pituus vaikuttaa geenien määrään. Nyt olen keskittynyt siihen, minkälaiset tekijät ovat yhteydessä suolistomikrobiston antibioottiresistenssiin. Näitä ovat antibioottien liiallinen käyttö, asuinympäristö sekä terveyshistoria, joka voi paljastaa, kantaako todennäköisesti antibiooteille vastustuskykyisiä bakteereja.”

Ympäristössä olevien bakteereiden ja niiden geenien tutkimus otti suuren harppauksen eteenpäin, kun uuden sukupolven sekvensointimenetelmät tulivat käyttöön. NGS-sekvensointi (Next Generation Sequencing) perustuu massiiviseen rinnakkaissekvensointiin, jossa miljoonia lyhyitä DNA-fragmentteja monistetaan samanaikaisesti. Koska joukko ympäristöstä noukittuja ja sekvensoituja geenejä voidaan analysoida samalla tavoin kuin yksittäisen lajin perimää, tutkimussuuntausta alettiin kutsua metagenomiikaksi. Ensimmäinen metagenomiikkaa hyödyntävä tutkimusartikkeli antttiresistenssistä julkaistiin vuonna 2014.
”Antibioottiresistenssiä on tutkittu pitkään, mutta NGS mahdollisti – ei pelkästään yksittäisten geenien – vaan kaikkien vastustuskykyisen geenien analysoimisen yhdestä näytteestä”, Pärnänen huomauttaa.
Metagenomiikkaan liittyvät tutkimukset ovat osoittaneet, että antibioottien resistenssigeenit ovat yleisiä elinympäristössä. On suuri riski, että nämä geenit siirtyvät bakteereihin, jotka aiheuttavat tulehduksia ihmisissä.
Pärnänen hyödyntää metagenomien sekvenssidataa, jota on myös kerätty laajoihin avoimiin tietokantoihin. Dataa hän analysoi tieteen tietotekniikan keskuksen CSC:n supertietokoneiden avulla. Näin pystytään tunnistamaan eri bakteerilajeja ja niissä olevia resistenssigeenejä.
”Jostakin bakteerilajista voidaan tunnistaa sellaisia geenejä, mitkä esiintyvät sen perimässä vain kerran ja sitten vertailemalla niitä muiden lajien tietokannoissa oleviin geeneihin pystytään sanomaan, mikä bakteerilaji on kyseessä. Resistenssigeeneistä etsitään osumia: sopiiko se tietokannoissa olevaan resistenssigeeniin? Sitten voidaan todeta, että jollakin ihmisellä on ulostenäytteessään kymmenen resistenssigeeniä tai että hänellä on tietty määrä kolibakteereja.”
Yhdessä tutkimuksessa Pärnänen oli mukana analysoimassa resistenssigeenejä ihmisen ulosteista. Tutkimuksessa vertailtiin seitsemän maan jätevesien käsittelylaitosten bakteereja. Puolet maapallon väestöstä kantaa suolistossaan CrAssphage-faagia eli bakteerin loisena olevaa virusta. Tämän faagin geenisekvenssiä käytettiin tutkimuksessa markkerina osoittamaan ulostepohjaista tartuntaa.
”Samoja resistenssigeenejä löytyy kaikkialta maailmasta. Antibioottiresistenssistä puhutaan, että se olisi näkymätön pandemia, koska samat resistenssigeenit leviävät maan rajojen ulkopuolelle. Tietyt geenit ovat tosin yleisempiä jossakin päin maailmaa kuin toiset.”
Intiassa voi olla huomattavasti enemmän näitä geenejä kuin esimerkiksi Pohjois-Euroopassa. Etelä-Euroopan ja Pohjois-Euroopan välillä alkaa olla myös suuria eroja.
”Esimerkiksi virtsatieinfektioita aiheuttavat E. coli-kannat Etelä-Euroopassa voivat olla hyvin resistenttejä.”
Terveelle ihmiselle bakteerit eivät aiheuta vakavaa tautia, mutta aina välillä käy, että suolistoinfektion aiheuttajana on resistentti bakteeri.
”Resistentin bakteerin aiheuttamaa infektiota on vaikea hoitaa. Yleensä nämä ongelmallisimmat resistentit infektiot, joita tavataan Suomessa ovat usein tulleet sellaisille ihmisille, jotka asuvat Suomessa mutta jotka ovat matkustaneet ulkomaille.”
Vuonna 2002 Terveyden ja hyvinvoinnin laitoksen THL:n FINRISKI – väestöaineistoon kerättiin ulostenäytteitä ja määritettiin näytteissä olevien mikrobien sekvenssitiedot.
”Analysoimme yhdessä THL:n tutkijoiden kanssa suomalaisesta populaatiosta saaduista näytteistä, mihin resistenssi mahdollisesti vaikuttaa ja minkälaisia terveydellisiä seuraamuksia on, jos ihmisellä on paljon vastustuskykyisiä bakteereja. Ovatko korkeat antibioottiresistenssigeenien määrät yhteydessä riskiin kuolla seurantajakson aikana?
On ennustettu, että 2050 vuonna antibioottiresistentit infektiot tappaisivat enemmän kuin syöpä. Tuolloin infektiotaudit olisivat yleisin kuolinsyy. Antibiootteja käytetään jo nyt enemmän tuotantoeläimiin kuin ihmisiin ja samalla eläinproteiinin kulutus kasvaa. Pärnäsen mukaan resistenssikriisiä vastaan voidaan taistella siten, että antibiootteja käytetään vain bakteeri-infektioiden hoitamiseen ja vain silloin kun antibiooteista on tutkitusti apua. Myös ruokavalio tai elämäntapa voivat ehkä vähentää resistenssigeenejä suolistomikrobistossa.
”Esimerkiksi kuidun syönti on hiljattain yhdysvaltalaisissa tutkimuksissa yhdistetty resistenssigeenien pieneen määrään kun taas eläinproteiinin määrä ruokavaliossa oli yhteydessä geenien suureen määrään. Voidaan sanoa, että sinun suolistomikrobistosi on sitä mitä syöt.”
Katariina Pärnänen työskentelee apulaisprofessori Leo Lahden tutkimusryhmässä. Ryhmä kehittää koneoppimismalleja, jotka seulovat laajoista datakokoelmista mikrobiryhmiä.
”Antibioottiresistenssi on yksi esimerkki tutkimuksesta, jossa hyödynnetään uusia mittausmenetelmiä ja laskentakapasiteettia tavalla mitä ei ole aiemmin tehty. Tässä tutkimusaiheessa yhdistyvät luontevasti eri mittausympäristöt ihmiskehosta ympäristön mikrobistoon. Tällainen tutkimus mahdollistaa menetelmäkehitykseen ideoita, joista myös eri alojen tutkijat voivat hyötyä,” sanoo Leo Lahti.
Katariina Pärnäsen toiveena on tutkia kaikkien maailman ihmispopulaatioiden suolistomikrobinäytteet, joista on tehty metagenomisekvensoinnit ja jotka ovat tietokannoissa avoimesti saatavilla.
”Olisi kiinnostavaa keskustella CSC:n asiantuntijoiden kanssa, miten tämä olisi teknisesti mahdollista. Tämä myös edistäisi avointa tiedettä, koska tunnistetut resistenssigeenit ja mikrobiomeista löydetyt eliölajit voitaisiin tallettaa myös muiden tutkijoiden käyttöön.”
Ari Turunen
1.9.2022
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Katariina Pärnänen, Leo Lahti, & Tommi Nyrönen. (2022). Antibiotic-resistant bacteria are a global problem. https://doi.org/10.5281/zenodo.8154563
Lisätietoja
Turun yliopisto
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC –Tieteen tietotekniikan keskus Oy.
Solujen mallintaminen ja niiden toiminnan simuloiminen parantaa huomattavasti henkilökohtaisia hoitosuunnitelmia. PerMedCoE- hankkeessa yhdistetään kliinistä potilastietoa geenien ja proteiinien ja solujen toimintaan liittyvään tietoon. Tavoitteena on kehittää täsmälääketieteessä käytettäviä työkaluja. Solujen mallintaminen yksityiskohtaisesti on kuitenkin valtava urakka ja vaatii paljon supertietokoneiden laskentatehoa.
Yksilöity lääketiede avaa tulevaisuudessa suuria mahdollisuuksia. Tavoitteena on, että potilaan kliininen data voidaan yhdistää geneettiseen dataan ja näiden tietojen pohjalta voidaan laatia yksilöllisiä hoitosuunnitelmia. PerMedCoE– hankkeessa (HPC/Exascale Centre of Excellence in Personalised Medicine) pyritään parantamaan yksilöidyn lääketieteen mallinnusohjelmistojen yhteensopivuutta eksaskaalan supertietokonejärjestelmiin. Eksaskaalan supertietokoneet ovat seuraavan sukupolven järjestelmiä joiden teoreettinen laskentateho vastaa jopa 10^18 laskutoimitusta sekunnissa. Hankkeeseen osallistuu tutkijoita useasta eurooppalaisesta yliopistosta ja sairaalasta. Projekti keskittyy neljään avoimen lähdekoodiin perustuvaan solutason mallinnusohjelmistoon. Ohjelmistokehityksen lisäksi tutkimushankkeessa pyritään edistämään täsmälääketieteen työkalujen helppokäyttöisyyttä ja toimivuutta useissa eurooppalaisissa suurteholaskentakeskuksissa.
”Tavoitteena on että nämä neljä ohjelmistoa pystyisivät tulevaisuudessa toimimaan useassa supertietokoneessa”, sanoo CSC:n projektipäällikkö Sampo Sillanpää.
”Tällä hetkellä tämä on teknisesti hyvin haastavaa toteuttaa, koska jokainen suurteholaskentaympäristö on omanlaisensa johtuen järjestelmäarkkitehtuurista.”
Ohjelmistojen ja datamassojen saumaton toiminta on tarkoitus saavuttaa yhteisesti sovituilla teknologioilla. PerMedCoE-hankkeessa tämä toteutetaan ns. konttitekniikan ja työvuo-ohjelmistojen avulla. Työvuo on tutkimusprosessin automaatio, jonka aikana dokumentteja, tietoa ja tehtäviä siirretään suoritettaviksi tiettyjen sääntöjen mukaisesti. Konttitekniikan avulla voidaan määrittää vakioitu ympäristö, jossa tieteellisiä ohjelmistoja ajetaan jokaisessa hankkeeseen osallistuvassa suurteholaskentaympäristössä. Kun ohjelman koodi kirjastoineen ja asetuksineen asetetaan konttiin, sitä voidaan siirrellä koneelta ja konesalista toiseen.
”Ohjelmistot ja data on tavallaan paketoitu omaan laatikkoonsa, jotta niitä voidaan siirtää ympäristöstä toiseen. CSC:llä on useita konttitekniikan asiantuntijoita, joten työkaluja pystytään siirtämään alustalta toiselle”, Sillanpää sanoo.
”Kontteja hyödyntämällä asiantuntijat pystyvät rakentamaan käyttäjäystävällisiä työnkulkuja, eli työvoita. PerMedCoE-hankkeessa työvuot koostuvat useammasta rakennuspalikasta, joista jokainen toteuttaa tietyn täsmälääketieteen laskentatehtävän. Yhdessä rakennuspalikassa voidaan tehdään esikäsittelyä datalle, toisessa varsinainen analyysi ja viimeinen antaa tuloksen loppukäyttäjälle. Käyttäjän ei siis välttämättä tarvitse huolehtia miten useasta rakennuspalikasta rakennettu automatisointi toimii, vaan keskittyä tulosten tulkintaan.”

Hankkeessa rakennettujen teknologioiden hyödyllisyyttä arvioidaan erilaisten käyttötapausten avulla. Työvoiden avulla analysoidaan, mitä häiriöitä taudit voivat aiheuttaa solutasolla tai miten lääkeaineet toimivat. Mallien avulla voidaan tutkia solujen aineenvaihduntaa tai signaalinvälitystä.
”PerMedCoE-käyttötapauksissa hyödynnetään julkisesti saatavilla olevia genomidata-aineistoja. Nyt voimme tutkia koronaviruspotilaista otettuja näytteitä ja etsiä genomidatasta sellaisia markkereita, jotka ilmentävät, mitkä potilasryhmät ovat erityisen alttiita taudin vaaralliselle muodolle.”
Projektissa mallinnetaan ihon epiteelikudosta, joka reagoi koronavirustartuntaan kutsumalla erilaisia immuuneja soluja vaikuttamaan virukseen. Näin voidaan mahdollisesti paremmin tunnistaa sellaisia potilasryhmiä, jotka ovat alttiita koronan vakavalle tautimuodolle.
“Ajatuksena on, että pystytään rinnakkain ajamaan useita malleja yksittäisille potilaille. Näin voidaan tehokkaasti analysoida riittävän suuria datamääriä, jotta mallinnustuloksia voitaisiin käyttää yksilöidyn lääketieteen apuna”, sanoo vanhempi datatieteilijä Jesse Harrison CSC:stä.
COVID 19-käyttötapauksen mallinnuksessa käytetään solutason RNA-sekvenssidataa. RNA-sekvensointi yhden solun tarkkuudella (scRNA-seq) voi paljastaa geenien välisiä säännöllisiä vuorovaikutusyhteyksiä, solujen syntyperälinjat, solujen eroavaisuuksia sekä solun viitekehyksen ympäristössään.

Toinen tärkeä projektin käyttötapaus on syöpädiagnostiikka. Tavoitteena on luoda mallinnustyökaluja syöpäkasvainten kasvun ennustamiseen ja potilaskohtaisten hoitojen kehittämiseen. Aineistona käytetään Wellcome-instituutin ja Massachusettsin syöpäkeskuksen keräämää aineistoa. Tietokantaan on kerätty yli tuhat erilaista kasvainkudoksen solulinjaa.
”Projektissa pyritään esimerkiksi tunnistamaan uusia lääkeyhdistelmiä, jotka voisivat olla syöpähoidossa hyödyllisiä” Jesse Harrison sanoo.
Tämä johtaisi toivottavasti potilaskohtaisten syöpähoitojen tarkempaan kohdistamiseen ja diagnostiikan nopeutumiseen.
”Jotta nämä tavoitteet täyttyisivät läheisempää yhteistyötä tarvitaan suurteholaskentakeskusten ja lääketieteellisen organisaatioiden kanssa. Tämä siksi, koska nyt puhutaan isoista datamassoista ja suurten potilaskohtaisen datan analysointi ei ole omalla pöytäkoneella mahdollista.”
PerMedCoE:n tulokset ja työkalut on tarkoitettu kaikille tutkijoille.
“Kun projekti päättyy kesällä 2023, meillä on päivitettyjä versioita avoimen lähdekoodin pohjalta kehitetyistä mallinnustyökaluista ja ne saatetaan tutkijayhteisön saataville. Hankkeessa luodaan myös uutta osaamista tukemaan täsmälääketieteen työkalujen käyttöä CSC:n laskentaympäristöissä.”

EU rahoittaa monia projekteja, jotka tulevaisuudessa mahdollistavat yksilölliset potilashoidot. Syöpä on yksi esimerkki taudista, joka on erittäin yksilöllinen, oli kyse sitten rinta-, keuhko-, maksa-, tai eturauhassyövästä.
Esimerkiksi Horisontti Eurooppa -puiteohjelman Conquering Cancer: Mission Possible näyttää Suomen molekyylilääketieteen instituutin (FIMM) tutkijan Esa Pitkäsen mukaan suuntaa tulevaisuuden syöpätutkimukselle ja -hoidoille. Kunnianhimoinen ohjelma tavoittelee syöpien syntyyn johtavien mekanismien ymmärtämistä, uusia menetelmiä syöpien aikaiseen havaitsemiseen, sekä henkilökohtaisen eli yksilöidyn syöpälääketieteen läpimurtoja.
”Kaikille näille tavoitteille yhteistä on monipuolisen ja laajan terveysdatan hyödyntäminen uusien laskennallisten menetelmien avulla. Koneoppimiseen perustuvien tekoälyalgoritmien avulla onkin jo saavutettu rohkaisevia tuloksia esimerkiksi digitaalisen patologian alalla. Seuraavat harppaukset tehdään yhdistelemällä useita eri tietolähteitä yksilöllisten syöpäseulonta- ja hoitosuositusten antamiseksi”, Pitkänen uskoo.
Ohjelmassa syöpäpotilaat halutaan mukaan syöpähoitojen kehitykseen esimerkiksi antamalla potilaille mahdollisuuksia lähettää tietoturvallisesti omaa terveysdataansa tutkijoiden käyttöön. Samalla potilaat saavat myös uutta tutkimustietoa omasta sairaudestaan.
”On tärkeää, että hoitomuotojen kehittyessä pidetään huolta siitä, että ihmisille taataan tasa-arvoinen mahdollisuus hyötyä uusista hoidoista taustasta riippumatta. Olen iloinen siitä, että tämä on huomioitu ohjelman suosituksissa. Lisäksi lasten ja nuorten syöpiin kiinnitetään erityistä huomiota.”
Ari Turunen
23.8.2022
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Sampo Sillanpää, Esa Pitkänen, & Tommi Nyrönen. (2023). Personalised medicine against cancer and viruses. https://doi.org/10.5281/zenodo.8154548
Lisätietoja:
HPC/Exascale Centre of Excellence in Personalised Medicine
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC –Tieteen tietotekniikan keskus Oy.

Mikrobien ja niiden vuorovaikutusta isännän kanssa kutsutaan mikrobiomiksi. Mikrobiomin koostumus on jokaisella yksilöllinen. Mikrobiomi auttaa esimerkiksi elimistön puolustusjärjestelmää torjumaan infektioita. Jos mikrobiomi häiriintyy, elimistö voi altistua sairauksille, kuten diabetekselle.
Datatieteen apulaisprofessori Leo Lahti Turun yliopistosta kehittää tutkimusryhmänsä ja yhteistyökumppaneidensa kanssa koneoppimismalleja, jotka seulovat laajoista datakokoelmista mikrobiryhmiä.
”Sairauksien synnyssä mikrobiomi on vain yksi osanen, mutta se on sellainen osanen, jota ei ole aikaisemmin pystytty tutkimaan näin kattavasti koska vasta nyt meillä on käytössämme tehokkaat mittausmenetelmät,” sanoo Lahti.

Lahden tutkimusryhmä on kartoittanut mikrobeja erilaisista elinympäristöistä ja ekosysteemeistä yhdessä kokeellisten tutkijoiden kanssa.
”Tutkijoilla alkaa olla aika hyvä käsitys mikälaisia bakteerilajeja ja ryhmiä löytyy eri ympäristöistä. Aika paljon on saatu tietoa niiden toiminnasta, tehtävistä ja roolista aineenvaihdunnassa sekä siitä, minkälaisia kemiallisia yhdisteitä ne tuottavat.”
Kaikki bakteerit ja yksisoluiset arkeonit ovat mikrobeja. Mikrobeihin kuuluvat myös levät, alkueläimet, hiivat ja homeet. Mikrobitutkimus on Leo Lahden mukaan kasvanut kovaa vauhtia, kun sekvensointitekniikoiden hinnat ovat tulleet alas. Mikrobinäytteistä sekvensoidaan DNA:ta ja päätellään mitä mikrobilajeja on näytteessä, jos näytteet on kartoitettu aiemmin.
”Nämä näytteet voivat tulla ympäristöstä, ihmisen kehon osista tai ties mistä. Me mittaamme DNA:n pätkiä ja yritämme laittaa palapeliä kasaan. Sitä kautta voimme saada selville minkälainen bakteerikoostumus annetulla näytteellä on. Voimme jopa jäljittää kokonaisia uusia bakteerigenomeja ja löytää aiemmin tuntemattomia lajeja,” sanoo Leo Lahti.

Kaikkein monipuolisin mikrobien ekosysteemi kukoistaa suolistossa. Nykyisen käsityksen mukaan keskikokoisessa ihmisessä on keskimäärin 1-2 kg bakteereita, lukumäärällisesti hieman enemmän kuin ihmissoluja. Ihmisen mikrobistossa on monia eri tasoja, ja ne muodostavat monimuotoisia ekosysteemejä. Mikrobiston koostumukseen vaikuttavat yksilön geeniperimä ja asuinympäristö. Myös elintavoilla kuten ruokavaliolla ja ulkoilulla on osoitettu olevan vaikutusta mikrobien kirjoon. Mikrobien perusteella voidaan nähdä viitteitä esimerkiksi siitä, onko ihminen kasvis- tai lihansyöjä. Leo Lahden tutkimusryhmä on ollut mukana tutkimassa mikrobikirjoa myös eri väestöissä.
”Iso työ on ollut kartoittaa, että mitä lajeja ylipäätään ihmisen mikrobistosta löytyy. Tämä voi vaihdella maantieteellisesti eli missä päin maailmaa yksilö asuu ja kuuluuko hän alkuperäisväestöön tai asuuko hän kaupungissa tai maaseudulla ja minkälainen elintaso hänellä on.”
Kartoitus auttaa hahmottamaan, miten mikrobit kytkeytyvät yksilön terveyteen.
”Tällöin tulee tärkeäksi miten mikrobikirjo pystytään yhdistämään ihmisen tämänhetkiseen ja tulevaan terveydentilaan. Pystytäänkö mikrobiston avulla päättelemään jotakin ihmisen terveydentilasta tai jopa ennakoimaan terveydentilan kehitystä? Ja jos pystytään, niin onko mahdollista muokata mikrobikantoja, jotta ne vaikuttaisivat terveyteen, ja minkälaisia riskejä tai eettisiä näkökulmia tähän liittyy? Laskennalliset ja koneoppimisen menetelmät ovat avainasemassa kun nyt tuotetusta monimutkaisesta datasta kaivetaan tietoa.”
Suomalaiseen THL:n FINRISKI-väestöaineistoon kerättiin vuonna 2002 myös ulostenäytteitä. Nyt voidaan pitkäaikaisseurannan ansiosta tarkastella ihmisten terveydentilan kehitystä kun heidän mikrobistonsa on mitattu. Lahden mukaan tällainen THL:n kokoama väestökohortti on maailmanlaajuisesti ainutlaatuinen.
”Nämä aineistot ovat erittäin arvokkaita koska tällainen tutkimus on hankala tehdä monissa muissa maissa koska niissä ei ole saatavissa vastaavia kattavia väestöaineistorekistereitä. Nyt meillä on valtava määrä näytteitä ja niihin liittyvää terveystietoa, joissa mikrobikoostumus voidaan kytkeä terveydentilan kehitykseen väestötasolla.”
Leo Lahden mukaan joitakin mikrobimittauksia voitaisiin käyttää diagnostiikassa. Niiden perusteella voidaan tunnistaa jokin tietty tauti tai tunnistaa mikrobeja, jotka ennustavat tiettyjen syöpien riskiä. Esimerkiksi mahalaukussa elävä helikobakteeri voi lisätä mahasyövän riskiä.
”Suolistossa on tiettyjä bakteeriryhmiä, jotka ovat tilastollisesti yhteydessä myöhempään sairastumisriskiin. Olemme äskettäin havainneet, että ne voivat ennakoida esimerkiksi kohonnutta kuolleisuusriskiä, maksasairauksia ja tyypin 2 diabetesta. Me emme vielä tunne näiden havaintojen syy-seuraussuhteita, mutta voimme nähdä jo signaaleja vuosia aikaisemmin ennen kuin henkilö sairastuu.”
Tutkimustuloksia on julkaistu kokonaiskuolleisuudesta, maksasairauksista ja tyypin 2 diabeteksesta.

”Nämä ovat isoja sairausryhmiä, joita tutkitaan tosi paljon muutenkin. Vaikka niihin liittyvät pitkät tutkimusperineet, mikrobiomi on tuonut uuden kulman näiden sairauksien ymmärtämiseksi. Mikrobeilla on rooli aineenvaihdunnassa. Mikrobien kehoon tuottamilla yhdisteillä voi olla merkittävä rooli näissä sairauksissa ja immuunijärjestelmissä.”
”Kun olemme saaneet lisää tietoa siitä mitä nämä mikrobit tekevät ja mitä mikrobeja elimistössä on, meillä on paremmat mahdollisuudet ymmärtää niitä mekanismeja jotka vaikuttavat sairauksien syntyyn. Tämä voi auttaa kehittämään uusia tapoja hillitä sairauksien vaikutuksia tai ehkäistä riskiä niiden syntymiseen.”
Lahden mukaan valtava lääketieteellinen kiinnostus kohdistuu tällä hetkellä mikrobiomeihin, koska elintapojen muutosten ja monien yleistyneiden tautien on havaittu kytkeytyvän mikrobitasapainon vaihteluun. Tämän lisäksi esimerkiksi antimikrobiresistenssi on yksi kasvava terveysongelma. Se tarkoittaa bakteerien lisääntynyttä vastustuskykyä antibiootteja kohtaan. Se on johtava kuolinsyy lähivuosikymmeninä.
Leo Lahden tutkimusryhmä seuloo suurista datamassoista tietoa ja yhdistää eri lähteistä saatavaa tietoa. Koska datamassojen koko kasvaa jatkuvasti, ne pitää järjestää ja organisoida, jotta niistä saataisiin ymmärrettäviä. Tällaisella analyysilla on monta laskennallista vaihetta. Ensin data pitää esikäsitellä ja DNA-pätkät yhdistää, jotta nähdään mistä lajeista ne ovat peräisin ja missä suhteissa niitä esiintyy eri näytteissä. Tämän jälkeen voidaan alkaa selvittää tarkemmin mikrobikoostumuksen yhteyksiä esimerkiksi elinympäristöön ja terveydentilaan.
”Data voi olla monimutkaista. Se voi olla hierarkista ja siinä voi olla ajallinen tai paikallinen rakenne. Siksi tarvitaan uusia laskennallisia menetelmiä. Esimerkiksi koneoppimisen menetelmät ovat hyviä, koska ne vähentävät ihmisen intervention tarvetta eli voimme merkittävän osan siitä päättelystä automatisoida ja siirtää koneiden suoritettavaksi.”
Leo Lahden mukaan menetelmillä, joilla voidaan avustaa ihmisiä kvantitatiivisten päätelmien tekemisessä, on iso rooli biolääketieteen tutkimuksessa.
”Tietoa on koottu tietokantoihin. Ja kun me analysoimme uusia näytteitä me haluamme yhdistää tämän mittausten tiedon tietokannoissa jo oleviin tietoihin. Tätä uutta tietoa pitää tulkita tämän aiemmin kerätyn ja karttuneen tiedon kontekstissa.”
Kun mikrobilajeja tutkitaan, on Lahden mukaan tärkeää ymmärtää, miten ne toimivat yhdessä kokonaisena ekosysteeminä ja vuorovaikuttavat ihmiskehon kanssa. Mikrobiryhmien perimän sekvensointi ja tietojen yhdistäminen vaativat massiivisia laskenta- ja tallennusresursseja.
”Jotta saisimme sekvenssitietomassasta ymmärrettävää aineistoa, jota voidaan oikeasti lähteä tilastollisesti analysoimaan, se edellyttää CSC:n tarjoamia resursseja. Kasvavassa määrin käytämme näitä palveluja yhteistyöalustana. Voimme rakentaa yhdessä muiden tutkimusryhmien kanssa työvirtoja, jolloin data on CSC:n kautta saatavissa ja analyysiympäristö yhdessä paikassa eli CSC:n palvelimilla. Tärkeä on myös päästä CSC:n kautta ELIXIRin tarjoamiin bioinformatiikan dataresursseihin. Me myös kasvavassa määrin käytämme näitä palveluja laskennallisten menetelmien koulutuksessa.”
Ari Turunen
30.6.2022
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Leo Lahti, & Tommi Nyrönen. (2022). Studying the human microbiome is a key towards holistic understanding of our health. https://doi.org/10.5281/zenodo.8154534
Turun yliopisto
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC –Tieteen tietotekniikan keskus Oy.

Mittavassa FINRISKI -tutkimusprojektissa on vuodesta 1972 lähtien kerätty viiden vuoden välein terveystietoa suomalaisista. Aineistoa voidaan käyttää kroonisten tautien riskitekijöiden selvittämiseen. Yhä enemmän kerätään myös geenidataa, jonka yhdistäminen rekisteritietoihin mahdollistaa sairauksien ennaltaehkäisemisen ja entistä tehokkaampien hoitomenetelmien kehittämisen.
Suomalaisia tutkimusaineistoja on paljon, mutta THL:n johtavan tutkijan Kati Kristianssonin mukaan FINRISKI sisältää poikkeuksellisen paljon monipuolista dataa suomalaisen väestön terveydestä. Tutkittavat on valittu satunnaisotoksella eri alueiden väestöistä. Terveystarkastuksiin osallistuneilta kysellään myös elintavoista, sairauksien perhehistoriasta, mielialasta sekä muista terveyteen ja hyvinvointiin liittyvistä asioista. Rekisteri- ja kyselytiedot voidaan yhdistää geeninäytteisiin.
”Kun kaikki nämä laboratoriomittaukset ja kyselyaineistot saadaan yhdistettyä terveysrekisteritietoihin, saadaan selville sairaushistoria, minkälaisia lääkityksiä henkilöillä on ollut ja kaikki kuolinsyyt.”
FINRISKI-kokoelmia siirrettiin vuonna 2015 THL Biopankkiin. Kaksi vuotta myöhemmin FINRISKI- ja Terveys 2000 -tutkimukset yhdistettiin uudeksi FinTerveys -väestötutkimukseksi. Biopankkiaineistoja, joihin on tallennettu genomidataa ja terveystarkastuksissa saatua dataa on toki muuallakin. FINRISKI –aineistosta tekee poikkeuksellisen laadukkaan sen aikajänne.
”Henkilöstä mitataan ensimmäisessä terveystarkastuksessa erilaisia arvoja. Tämän lähtötilanteen jälkeen samaa henkilöä voidaan seurata edelleen rekistereistä vaikka 30 vuotta eteenpäin ja nähdä mitä henkilölle on tapahtunut. Voidaan nähdä, minkälaisia riskitekijöitä on jo alussa, minkälaisia sairauksia tulee tai mihin henkilö mahdollisesti kuolee. ”
Kristianssonin mukaan FINRISKI -väestöaineistossa erityisen arvokasta on ajassa seuraaminen alkumittausten jälkeen.
”Tällainen analyysi edesauttaa arvioimaan minkälaiset tekijät nostavat tulevan sairastumisen riskiä. Sitä pystyään hyvin arvioimaan perinnöllisten ja elintapatekijöiden avulla.”
FINRISKI -aineistot on tallennettu THL Biopankkiin. Lisää dataa tallennetaan koko ajan eri tutkimusprojekteista. Kristianssonin tutkimus nojaa vahvasti biopankkiaineistoihin. Hän vetää THL:ssä Väestönterveysyksikössä Kansantautien tutkimus -tiimiä ja on mukana keräämässä dataa vuonna 2022 alkaneessa Terve Suomi -tutkimusprojektissa, joka tuottaa ajankohtaista tietoa Suomessa asuvien aikuisten terveydestä ja hyvinvoinnista.
Kati Kristiansson on käyttänyt FINRISKI -aineistoa koko tutkijanuransa ajan.
”Kun aloitin tutkijan urani, tutkin kansantautien perinnöllisyystekijöitä keskittyen erityisesti sydän- ja verisuonisairauksien riskitekijöihin. Tätä olen tehnyt siitä lähtien. Kansansairauksien riskitekijöiden selvittäminen ja mahdollisten ennaltaehkäisevien toimenpiteiden arviointi on ollut sydäntäni lähellä koko työurani.”
FINRISKI -tutkimukseen on kutsuttu 10 000 ihmistä terveystarkastuksiin viiden vuoden välein. Uusimmissa terveystarkastuksissa on otettu myös ulostenäyte ja siitä on tutkittu bakteeristo eli mikrobiomi ja verinäytteistä metabolomi, eli satoja aineenvaihduntatuotteita.
”Saamme myös tietoa väestön lihomisesta. Eli saadaan painoindeksit ja paljon sellaista tietoa, mitä ei ole rekistereissä.”

Kristiansson on tutkinut tyypin 2 diabeteksen ja sepelvaltimotaudin riskitekijöitä. Erityisesti häntä kiinnostaa genomitiedon hyödyntäminen kansantautien ehkäisyssä.
”Suomessa on hienot rekisterit ja niitä eri aineistoihin yhdistämällä saadaan hienoa tutkimusta aikaan. Kyselyt, terveystarkastukset tai rekisterit yksinään eivät kuitenkaan riitä. Jos halutaan selvittää kansansairauksien perinnöllisiä riskitekijöitä, tarvitaan rekistereiden lisäksi genomitieto.”
Kattavien mittausten lisäksi terveystarkastuksissa on otettu verinäyte. Näin saadaan talteen DNA sekä selville erilaiset rasva-arvot, lipidien kolesteroli ja verensokeri.
Vuodesta 1992 alettiin eristää DNA:ta terveystarkastuksista saaduista näytteistä. Nyt näytteille on tehty koko perimän kattava genotyypitys. jossa DNA:n sisältämä geneettinen tieto määritetään mikrosirutekniikalla. Genotyypityksessä luetaan satoja tuhansia kohtia kromosomeista, ja sen jälkeen tieto vielä laajennetaan käsittämään miljoonia muita kohtia tilastollisilla menetelmillä. Näissä kohdissa esiintyy paljon erilaisiin tauteihin liittyviä geenivariantteja.

FINRISKI- aineistoa on yhdistetty myös muista maista kerättyihin aineistoihin. Kansainvälisissä tutkimusprojekteissa kerätään usein mahdollisimman iso määrä näytteitä, jotta voitaisiin tehdä kattavia koko perimän assosiaatioanalyyseja (GWAS). Näissä tutkimuksissa selvitetään eri sydän- ja verisuonitauteihin liittyviä geenialueita. FINRISKI -aineistosta löytyy paljon tutkimusdataa sydän- ja verisuonitaudeista ja niiden riskitekijöistä, joita ovat muun muassa lihavuus, diabetes, veren kolesteroli, verensokeri ja perimä.
Kristianssonia kiinnostavat aineistosta löytyvät biomarkkerit, jotka kertova biologisen tilan muutoksista. Yksi tutkimuskohde FINRISKI-aineistoissa on ollut peptidit, alle 50 aminohapon ”pienet proteiinit”. Natriureettiset peptidit saavat aikaan munuaisissa natriumionien ja veden eritystä ja vähentävät verenpainetta.
ANP (eteispeptidi) ja BNP (B-tyypin natriureettinen peptidi) erittyvät sydämestä verenkiertoon ja toimivat hormonien tavoin.
Näiden peptidien eritystä säätelee sydänlihaksen painekuormitus. Sydämen vajaatoiminnassa peptidien pitoisuudet plasmassa suurenevat. Ne ovat hyviä kliinisiä biomarkkereita ilmaisemaan sydänrasitusta.
Tutkimuksessa, jossa Kristiansson oli mukana, havaittiin mielenkiintoisia eroja peptidien määrässä eri ihmisissä. Tutkimusryhmä selvitti geenivarianttien vaikutusta peptidien määrään ja vertasivat varianttien vaikutusta verenpaineeseen. Tutkimuksissa otettiin huomioon asuinpaikka, ikä, sukupuoli, tupakointi, verenpaine sekä hiussuonikerästen suodatusnopeus munuaisissa. Huononeva munuaistoiminta ilmenee suodatusnopeuden (GFR) laskuna. Geenitutkimus voisi tuoda lisävalaistusta siihen, mitkä tekijät ja geenialueet erityisesti vaikuttavat peptidien määrään ja verenpaineen vaihteluun.
Kristianssonin mukaan tällaiset tutkimustulokset FINRISKI -aineistosta antavat osviittaa, minkälaisiin geenialueisiin jatkotutkimuksen ja lääkekehityksen voisi suunnata.
”Kun tiedetään näitä genomin alueita, jotka vaikuttavat sairauksien biomarkkereihin, niin jatkotutkimuksessa voidaan yrittää etsiä hyvä lääkeproteiini.”
Kristianssonin mukaan hyviä esimerkkejä tällaisesta ovat tällaiset kolesterolia alentavat lääkkeet. Lääkekehitystä tehdään muun muassa Helsingin yliopiston koordinoimassa FinnGen -tutkimuksessa. Sen tuottama aineisto on jatkossa muidenkin kansallisten ja kansainvälisten tutkijoiden ja yritysten hyödynnettävissä.
FINRISKI -aineistot hyödyttävät Kristianssonin mukaan erityisesti sairauksien ennaltaehkäisyssä.
”Tässähän tarkoituksena on elintapojen muutos.”
Ari Turunen
23.5.2022
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Kati Kristiansson, & Tommi Nyrönen. (2022). FINRISK: one of the world’s longest-running population survey time series. https://doi.org/10.5281/zenodo.8154515
Terveyden ja hyvinvoinnin laitos THL
FINRISKI-laskuri
https://thl.fi/fi/web/kansantaudit/sydan-ja-verisuonitaudit/finriski-laskuri
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

THL Biopankki sisältää valtavasti suomalaisen väestön elintapoihin liittyviä aineistoja, joiden kerääminen aloitettiin jo 1960-luvulla. Kun tähän lisätään pankkiin tallennettu geenitieto, voidaan tehokkaasti tunnistaa ja ennustaa sairauksien riskitekijöitä.
”Biopankissa olevaa tietoa voi käyttää lähes mihin tahansa terveystutkimukseen”, sanoo tutkimuspäällikkö Kaisa Silander, joka on ollut mukana kuvailemassa ja luokittelemassa THL Biopankin väestöaineistoja.
”Meillä on paljon dataa erilaisista väestötutkimuksista ja kun nämä tiedot yhdistetään, niin tutkijoilla on käytössä todella iso aineisto.”
Silander pitää aineistoa merkittävänä myös kansainvälisesti.
”Aineistokokonaisuus on mielestäni yhtä arvokas kuin UK Biobank tai Estonia Biobank, joistakin henkilöistä on terveystietoa 40 vuoden ajalta kun tiedot yhdistää terveysrekistereihin. Voimme tietää esimerkiksi tarkasti mihin tauteihin kyseinen henkilö on sairastunut.”
Silander on tehnyt kohorttiaineistojen kanssa pitkään töitä. EU:n Health-ohjelmien rahoitetuissa projekteissa rakennettiin infrastruktuuria. Sen jälkeen hän oli yhdistämässä THL:n tutkimusryhmien hallinnoimat kohortit yhdeksi metatietokannaksi.
”Rakensimme datan tallentamiselle yhteisen infrastruktuurin, sillä kaikista näistä kohorteista löytyy samanlaista tietoa. Laadimme ensin katalogin, jossa näitä aineistoja kuvattiin samalla tavalla. Sitten aloimme tallentaa muuttujia samaan tietokantaan, jotta ne olisivat haettavissa ja helposti löydettävissä. Muuttujien metadataluokittelu tehtiin suomeksi ja englanniksi. Samaa luokittelua käytetään myös tuleviin kohorttiaineistoihin”, Silander sanoo.
Vuonna 2014 THL:n Biopankki aloitti toimintansa. THL:n kerätyissä väestöaineistoissa oli kaksi perinteistä tutkimuslinjaa. Vuosina 1965-1980 väestöstä tehtiin terveystarkastuksia ja kerättiin tietoja ajamalla laboratoriolla varustettuja busseja paikan päälle. Autoklinikka tutki yli 50 000 suomalaista ympäri Suomea. Väestöaineistot muodostuvat tutkittavien terveystarkastuksessa antamista tiedoista, näytepankista ja jopa yli 40 vuoden ajalta terveyttä koskevista rekisteriseurantatiedoista. Autoklinikan jatkona toteutettiin vuosina 2000−2001 kansallinen Terveys 2000 -tutkimus ja vuosina 2011−2012 sen seurantavaihe. Tutkimuskohteita ovat olleet mm. keuhkosairaudet, sydänviat, anemia ja raudanpuute, diabetes, munuaisten ja virtsateiden taudit, kilpirauhasen sairaudet, kalkkiaineenvaihdunnan sairaudet ja sepelvaltimotauti. Myöhemmin tutkittavien sairauksien valikoima on monipuolistunut ja nykyään biopankissa tutkimuksen kohteena voi olla mikä tahansa sairaus.

FINRISKI-linjassa on kerätty tietoa sydän -ja verisuonitaudeista ja diabeteksesta alun perin lähinnä Itä- ja Keski-Suomesta. Myöhempinä vuosina tutkimus laajeni kattamaan useita alueita Suomessa ja lisää sairauksia. Vuonna 2017 nämä kaksi tutkimuslinjaa yhdistyivät FinTerveys -tutkimuksessa.
”Aineistossa on paljon elämäntapatietoa, jota on saatu kyselylomakkeilla”, sanoo Silander.
Lomakkeissa on kysytty tupakointitottumuksista, alkoholinkäytöstä ja miten syödään, nukutaan ja liikutaan. Terveystarkastuksissa on mitattu pituus, paino, verenpaine ja muita mitattavia asioita. Lisäksi on otettu verinäytteitä, ulostenäytteitä ja virstanäytteitä
”Otetuista näytteistä määritellään hyvin paljon erilaisia biomarkkereita, esimerkiksi lipidejä eli veren rasva-arvoja sekä tulehdusarvoja (CRP). CRP on maksan tuottama valkuaisaine, jonka määrä elimistössä kohoaa nopeasti erilaisissa tulehdustiloissa.”
Kaisa Silander toivoo, että tulevaisuudessa saataisiin enemmän hyvää biomarkkeridataa, joka kuvaa henkilön elimistössä tapahtuvia muutoksia, jotka voivat viitata sairauteen.
”Nyt on olemassa biomarkkereiden tuottamiseen ja analysoimiseen hyviä työkaluja. Tällä hetkellä meillä on NMR -spektroskopiasta saatua tietoa kahdesta sadasta biomarkkerista. On kuitenkin firmoja, jotka voivat tuottaa tuhansia biomarkkereita yhdestä seeruminäytteestä. Tällainen tieto olisi esimerkiksi FINRISKI -aineistoon yhdistettynä arvokasta. Aineistosta löytyy edelleen sopivia seeruminäytteitä.”

FinnGen -tutkimusprojektin ansiosta THL Biopankin aineistoihin kertyy myös geneettistä materiaalia.
Joulukuussa 2017 käynnistyneen Helsingin yliopiston vetämän FinnGen -projektin tavoitteena on taltioida puolen miljoonan suomalaisen genomit. Hankkeessa hyödynnetään kaikkien suomalaisten biopankkien keräämiä näytteitä. Perimästä saatava tieto yhdistetään kansallisissa terveydenhuollon rekistereissä olevaan tietoon. Näin pystytään ymmärtämään sairauksien syntymekanismeja paremmin ja laatimaan uusia hoitokeinoja. Toistaiseksi FinnGenin fenotyyppitiedot ovat ikä, sukupuoli, pituus, paino ja tupakointi. FinnGen-projektissa tuotettu genomidata palautuu vuoden välein biopankeille.
”Jos pystyy yhdistämään rekisteridataa, kyselylomakkeiden datat ja geenidatan niin kyllähän se mahdollistaa tosi laajan tutkimuksen eri aihealueista”, sanoo erikoistutkija Heidi Marjonen. Marjonen on genomiasiantuntijana THL Biopankissa. Hän käsittelee kaikkien THL Biopankin kohorttien genomidataa.
THL Biopankin kohorttiaineistoissa on geneettistä sirudataa, jossa on määritetty tihea kartta yksittäisiä variantteja DNA:sta sekä sekvenssidataa koko genomin laajuisesti ja proteiinien rakennusohjeita sisältävää eksomisekvenssidataa.
FINRISK ja Terveys 2000 -tutkimusten koko genomin ja eksomi -sekvenssidata eli perimän sekvenssijärjestys, on tuotettu Washingtonin yliopistossa ja Broad/MIT (Massachusettsin teknillinen korkeakoulu) -instituuteissa Yhdysvalloissa. FINRISKI- kohorttiaineistossa on 10 000 eksomisekvenssiä ja 4000 koko genomin sekvenssiä. Nämä tiedot yhdistetään suomalaisiin terveystietoihin, mikä mahdollistaa tautien paremman tutkimisen.
”Yksilöllisten hoitomenetelmien laatiminen on nyt mahdollista. Kun yhdistetään elintapatieto geenitietoon, voidaan kehittää parempia lääkehoitoja”, Marjonen sanoo.
DNA-näytteistä voidaan Marjosen mukaan tuottaa myös epigeneettistä dataa.
Epigeneettinen periytyminen tarkoittaa perinnöllisen tiedon siirtoa solun tai eliön jälkeläiselle ilman, että perinnöllinen tieto on koodattuna DNA:n tai RNA:n sekvenssiin. Epigeneettisiin tekijöihin vaikuttavat monet ulkoiset tekijät, kuten ravintotottumukset.
Toinen mielenkiintoinen aineisto liittyy mikrobiomiin eli ihmisen suolessa oleviin mikrobeihin. Vuonna 2002 FINRISK kohortissa kerätyistä ulostenäytteistä on määritetty kaikkien näytteissä olevien mikrobien sekvenssitiedot. Nyt voidaan hyödyntää biomarkkeridataa ja tutkia miten mikrobiomi vaikuttaa ihmisten terveyteen.
Heidi Marjonen oli mukana tutkimuksessa, jossa yli 3000 tutkittavaa sai tietoa sairastumisriskistään kansantauteihin. Kun geenidatan yhdistää kliiniseen dataan voidaan ennustaa yksilöllinen sairastumisriski. Kokonaisriskin arviointi pohjautuu perimään ja muihin tekijöihin kuten sukupuoleen, ikään, painoindeksiin, verenpaineeseen ja kolesteroliin. Geneettinen riski lasketaan henkilökohtaisen monigeenisen riskisumman (engl. polygenic risk score, PRS) avulla, jossa on otettu huomioon miljoonia perimän kohtia eli geneettisiä variaatioita.
Data on tallennettu Suomen ELIXIR –keskuksen CSC:n sensitiivisen datan ePouta -alustalle, joka mahdollistaa tietoturvallisen datan siirron portaalin käyttöliittymän ja tietokannan välillä.
Monigeeninen riskisumma on Heidi Marjosen mielestä yksi merkittävä tutkimustrendi. Riskisumma lasketaan niin, että miljoonista eri geneettisistä muodoista perimässämme muodostetaan yksi luku.
”Tutkija saa koko genomista infoa kätevästi yhteen lukuarvoon. Nyt voidaan tutkia vaikka genomin vaikutusta sairauksiin tai yksilön muihin ominaisuuksiin.”
Ari Turunen
8.4.2022
Lue artikkeli PDF-muodossa
Lisätietoja:
THL Biopankki
https://thl.fi/fi/web/thl-biopankki
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Diabetes on iso kansansairaus, mutta suuri haaste on myös tautiin liittyvät muut sairaudet. Diabeteksen liitännäissairauksia ovat mm. diabeettinen munuaistauti, diabeettinen retinopatia, sekä sepelvaltimotauti ja aivohalvaukset. Nyt Suomessa sekvensoidaan diabetes-potilaiden koko perimä ja etsitään geneettisiä riskitekijöitä.
Diabeetikoilla sydänsairauksien riski on paljon suurempi muuhun väestöön verrattuna. Kolmannes tyypin yksi eli nuoruustyypin diabeetikoista saa munuaissairauden, joka vaikuttaa suuresti kuolleisuuteen ja osaltaan myös sydänsairauksien riskiin. Retinopatia on ollut puolestaan merkittävin sokeuden aiheuttajista työikäisessä väestössä.
Suomalaisilla on maailman korkein ykköstyypin diabeteksen riski lapsilla ja nuorilla aikuisilla. Tyypin II diabetes mielletään usein enemmän länsimaiden elintasosairaudeksi, mutta suurimmat potilasmäärät löytyvät keskituloisista maista, ja yksittäisistä maista tilaston kärjessä on Kiina ja Intia.

”Diabeteksen yhteydessä puhutaan isoista ja vakavista komplikaatioista. Nämä muut sairaudet vaikuttavat vahvasti sekä diabeetikon elämänlaatuun että elinajan odotteeseen,” sanoo geneettisen epidemiologian tutkija Niina Sandholm Folkhälsan-tutkimuskeskuksesta. Sandholm työskentelee FinnDiane-tutkimusprojektissa, jonka tavoitteena on löytää diabeteksen liitännäissairauksille altistavia perinnöllisiä ja ympäristöön liittyviä riskitekijöitä. FinnDiane-tutkimus on Helsingin yliopiston, HUS:n ja Folkhälsanin tutkimuskeskuksen yhteistyöprojekti.
Sandholmin mukaan geenitiedosta on hyötyä erityisesti nuorille potilaille jo varhaisessa vaiheessa ennen kuin riskitekijät ilmenevät.
”Tällä hetkellä geenitietoa hyödynnetään klinikassa lähinnä harvinaisten sairauksien tapauksessa, mutta ryhmämme tekemät ja aiemmin tehdyt tutkimukset tukevat kattavan geenitiedon hyödyntämistä myös yleisten sairauksien varhaisessa ennaltaehkäisyssä.”

Vuonna 1997 professori Per-Henrik Groopin perustama FinnDiane on seurantatutkimus, johon osallistuu jo lähes 8000 diabetekseen sairastunutta. Potilasaineisto on saatu 80 sairaalasta ja terveyskeskuksesta eri puolilta Suomea. Se on yksi maailman laajimmista tyypin 1 diabeteksen ja sen liitännäissairauksien tutkimusaineistoista. Nyt tästä aineistosta sekvensoidaan 1700 potilaan koko perimä eli genomi.
Sandholm on aiemmin osallistunut tutkimusprojekteihin, joissa menetelmänä oli genominlaajuinen assosiaatiotutkimus (GWAS). Sitä käytetään erityisesti silloin, kun sairauden geneettinen tausta on monitekijäinen. Menetelmän avulla voidaan löytää sairastumisriskiä lisääviä tai sairaudelta suojaavia geenivariantteja. GWAS-menetelmässä osallistujien verinäytteistä mitataan geenivariantteja, joiden määrä vaihtelee sadoista tuhansista miljooniin. Potilaita on tuhansista satoihin tuhansiin.

Yli 5600 FinnDiane-potilaista tehty, toistaiseksi laajin sydänsairauksia ykköstyypin diabeetikoilla käsittelevä GWAS- tutkimus paljasti esimerkiksi uuden sydänsairauksiin liittyvän geneettisen lokuksen lähellä DEFB127-geeniä. Lokus on DNA-jakson sijaintipaikka kromosomissa. Jakson vaihtelua kutsutaan alleeliksi.
Samassa tutkimuksessa, jossa löydettiin DEFB127-geeni, löydettiin myös muita sydänsairauksille altistavia perintötekijöitä.
”Sydänsairauksille, kuten muillekin yleisille sairauksille on löydetty paljon altistavia perintötekijöitä, joista yksi vahvimmista sijaitsee geenien CDKN2A ja CDKN2B alueella. Diabeetikoilla sydänsairauksien riski on paljon suurempi kuin muussa väestössä eikä niiden perintötekijöistä tiedetä paljoa, mutta näytimme tässä tutkimuksessa, että tuo sama CDKN2A/B geenialue vaikuttaa sydänsairauksien riskiin myös ykköstyypin diabetesta sairastavilla.”
Kolmanneksella tyypin yksi diabeetikoista saa munuaistaudin. Joillekin voi kehittyä munuaisen vajaatoiminta, joka pahimmillaan voi johtaa keinomunuaishoitoon tai munuaisen siirtoon.
Toisessa tutkimuksessa analysoitiin eri datalähteitä yhdistäen 27 000 diabetekseen sairastuneen yhteyksiä munuaistautiin. GWAS on nopea ja taloudellinen menetelmä, mutta kaikkia variantteja ei sen avulla löydetä. Tätä yritetään nyt potilaan koko genomin sekvensoinnilla.
”GWAS-menetelmällä löydetyt variantit ovat useimmiten yleisiä, ja yksittäisten varianttien vaikutus sairastumisriskiin on varsin maltillinen. Sekvensoinnin tavoitteena on löytää harvinaisia variantteja, joilla voi olla yksilön kohdalla huomattavan suuri vaikutus sairauden puhkeamiselle. Pahimmillaan tällainen variantti voi estää koko proteiinin toiminnan.”
Sandholmin mukaan tutkimustulokset voivat auttaa sairastumisriskin ennakoimisessa tai viitoittaa tietä uusien lääkeaineiden kehittämiseksi.
”Laajempana tavoitteena geenitutkimuksessa on löytää sairastumisriskiin vaikuttavia tai sairauden aiheuttavia variantteja, jotta ymmärtäisimme paremmin diabeteksen liitännäissairauksien syntymekanismeja. ”
Pohjimmaisena tavoitteena on oppia ehkäisemään ja parantamaan diabeteksen liitännäissairaudet.
”Nyt luetaan koko DNA-sekvenssi kaikilta potilailta. Dataa tulee hirmuinen määrä,” Sandholm korostaa.
”DNA-dataa saadaan sekvensointilaitteesta 150 emäsparin pätkinä kerrallaan. Tavoitteena on lukea jokainen DNA:n kolmesta miljardista emäsparista keskimäärin 30 kertaa tiedon varmistamiseksi, joten näitä 150 emäsparin pätkiä tulee yli 600 000 kullekin henkilölle.”
Sekvensoidut pätkät täytyy järjestää ihmisen referenssigenomin avulla oikeaan järjestykseen, jotta koko sekvenssi saadaan selvitettyä. Tämä vaatii valtavasti laskentakapasiteettia, jota saadaan Suomen ELIXIR-keskuksesta CSC:stä.
”Tarkoitus olisi saada aineisto sellaiseen muotoon, että pystyttäisiin tietämään kulloisellakin potilaalla, mitkä emäsparien muutokset eli variantit liittyvät mihinkin sairauksiin. Tavoitteena on se, että pystytään tunnistamaan harvinaisia variantteja, joita ei löydy GWAS-menetelmällä. Harvinaisia variantteja löytyy aineistosta vain muutamalta potilaalta.”
Variantit DNA:n emäsparijaksoissa eli snipit ovat tavallaan lopputulos datan käsittelystä.
”DNA-juoste on siis muutettu snippimuotoon eli kullakin potilaalla voi olla alleeleja nolla, yksi tai kaksi varianttia. Nämä toimivat markkereina jotka selittävät mitä sairauksia variantti voi aiheuttaa.”
Tutkimusryhmä on jo saanut sekvensoitua 600 potilaan koko genomin.
”Alustavia tulosten perusteella esimerkiksi aivohalvauksille löydettiin yksittäisiä variantteja, jotka selvästi liittyvät aivohalvauksien riskiin. Muutoksia löytyy myös geeneissä, jotka on aiemmin liitetty synnynnäisiin munuaissairauksiin. Näiden ei ole ajateltu siis aiemmin liittyneen diabetekseen mutta jotka aiheuttavat erilaisia munuaisvaurioita. Nyt näyttää, että samoissa geeneissä olevat variantit myös vaikuttavat diabeettisen munuaistaudin syntyyn.”
Niina Sandholm ja hänen kollegansa tutkivat myös geenin proteiinia koodaavia osia sekä geenien säätelyalueita, jotka voivat liittyä sairauden riskitekijöihin.
”Geenien välissä oleva alue – 95% genomista – sisältää paljon säätelyalueita mikä kertoo, mikä geeni ilmentyy missäkin kudoksessa. DNA sinällään on sama ihmisen jokaisessa solussa, mutta geenien säätely aiheuttaa sen, että silmistä tulee silmät ja munuaisista munuaiset. Tässä nämä geenien säätelyalueet ja niiden muutokset ovat avainasemassa. ”
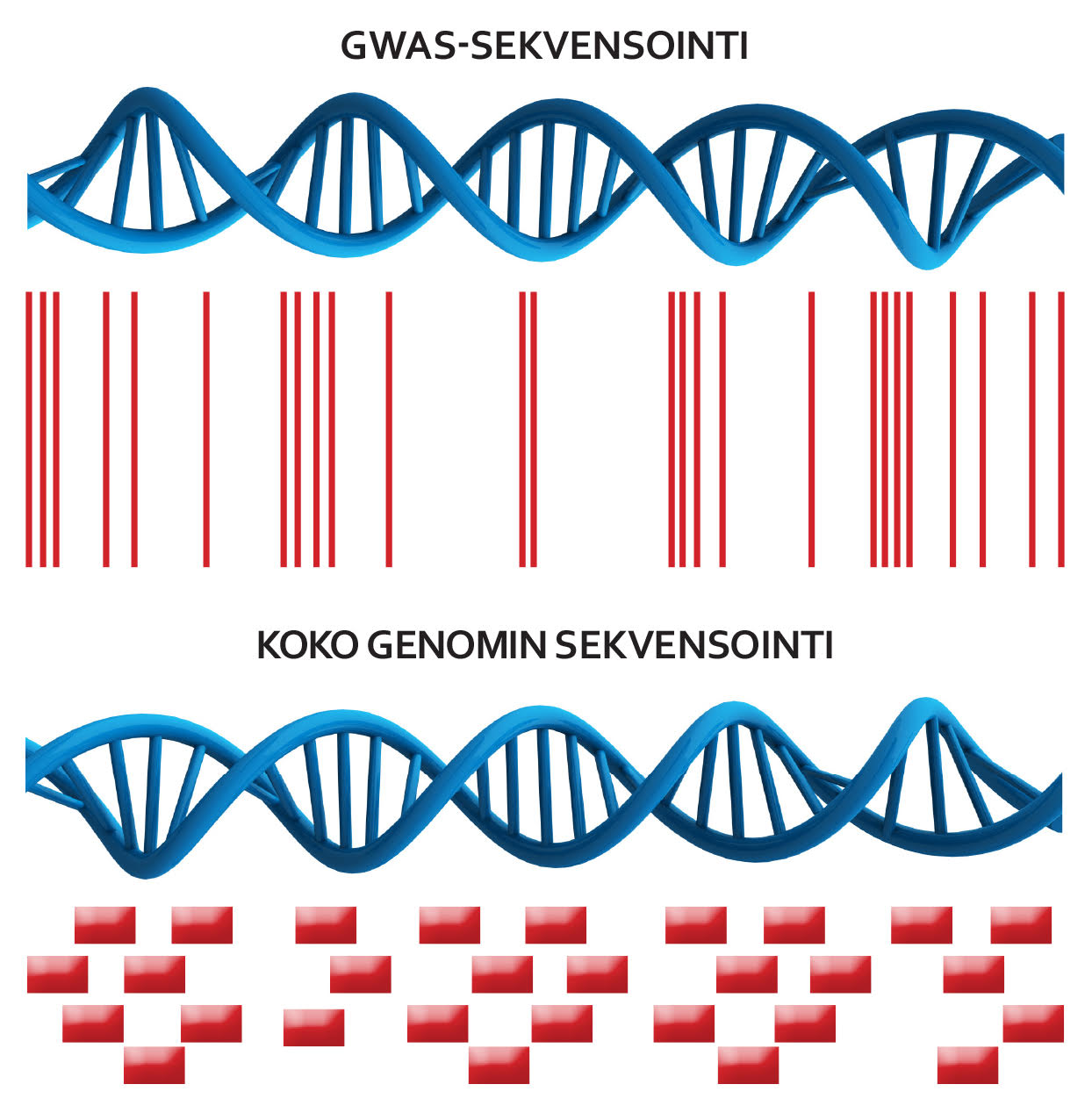
Tämä on maailmanlaajuisesti ensimmäisiä ja poikkeuksellisen laaja genomin sekvensointiprosessi. Toistaiseksi hyvin vähän on tehty koko genomin sekvensointia.
”Nyt trendinä on koko eksomin sekvensointi, jossa keskitytään proteiinia koodaavin osiin. On vain ajan kysymys milloin kuitenkin näitä koko genomin sekvensointeja aletaan tehdä lisää. Myös ELIXIR panostaa ja kehittää koko genomin käsittelymenetelmiin ja genomidatan työstämismenetelmiä.”
CSC tarjoaa ePouta-palvelua sensitiivisen datan käsittelyyn. Virtuaalipalvelimet toimivat CSC:n laskenta-alustalla korotetun tietoturvan ePouta-pilvipalvelussa. Käyttäjän tarvitsemat pilviresurssit on yksilöity ja varattu asianomaiselle käyttäjälle, eriytettynä CSC:n muusta laskentaympäristöstä. FinnDianen tutkimusryhmä käyttää Suomen molekyylilääketieteen instituutin FIMM:n laskentaklusteria, joka on yhdistetty CSC:n sensitiivisen datan laskenta-alustaan ePoutaan valopolun kautta. Valopolku mahdollistaa projektin käyttämän datan nopeamman käsittelyn, koska laskentaresurssit skaalautuvat. Tutkijoille on lisäksi allokoitu merkittävä tallennustila, jossa genomitiedot ovat.
Ari Turunen
3.2.2022
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Niina Sandholm, & Tommi Nyrönen. (2022). Finnish research team sequences the genomes of thousands of individuals with diabetes to look for genetic risk factors. https://doi.org/10.5281/zenodo.8154493
Lisätietoja
Folkhälsan
FinnDiane
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC –Tieteen tietotekniikan keskus Oy.

Ihmisistä kerätyn biolääketieteellisen datan jakaminen on nykyaikana edellytys sairauksien ennaltaehkäisylle ja hoitamiselle. Suomen ELIXIR-keskus CSC rakentaa infrastruktuuria, jossa Suomen biopankeista ja tutkimusorganisaatioista saatu suostumukseen perustuva ihmisperäinen data on esikäsitelty ja kuvailtu sekä tietoturvallisesti tallennettu. Datan jakamisesta päättävät tahot voivat automatisoida lupaprosessiaan CSC:n alustan avulla. Siten datan luvanvarainen saatavuus tutkimukseen ja terveydenhuoltoon kohentuu.
Yksilölliset lääkehoidot ovat mahdollisia vain, jos potilasdataa on tarjolla ja se on tallennettu ja esikäsitelty oikein. Suomen Akatemian rahoittamassa hankkeessa luodaan infrastruktuuri, joka täyttää sensitiivisen datan tallentamiseen ja käyttöön liittyvät vaatimukset. Data on kliinistä rekisteridataa, genomitietoa ja biokuvantamiseen liittyvää aineistoa. Hankkeeseen osallistuvat CSC:n lisäksi biokuvantamisen infrastruktuuri Euro-Bioimaging, THL Biopankki sekä Suomen molekyylilääketieteen instituutti FIMM.
Hankkeessa luodaan ratkaisuja, jotta erilaisen datan saaminen tutkijoiden käyttöön olisi nopeaa ja helppoa. Data voidaan tallentaa CSC:n sensitiivisen datan infrastruktuuriin. Tutkijat saavat käyttöönsä tilan, jossa data ja laskentakapasiteetti ovat samassa paikassa. Tutkija pääsee vain sellaiseen dataan, johon on saatu datan omistajalta lupa. Hankkeessa hyödynnetään CSC:n kehittämää federoitua tietohallintoa. ELIXIR AAI ja REMS ovat CSC:n kehittämiä sovelluksia ELIXIR-infrastruktuurin käyttäjähallintoon.
Datan tietoturvallinen siirtäminen muuttaa terveydenhuoltoa merkittävästi seuraavien vuosikymmenten aikana. Hankkeessa tuetaan tekoälyalgoritmeja kehittäviä tutkijoita tarjoamalla heille laskentapalveluita, terveystiedon tehokkaampaa tutkimuskäyttöä sekä datan hallintaan liittyviä teknologioita. Samalla data-aineistojen yhteensopivuus kansainvälisten standardien kanssa varmistetaan.


Suomen molekyylilääketieteen instituutin ja Helsingin yliopistollisen keskussairaalan HUS:n sekvensointikapasiteettia tehostetaan niin, että se on suoraan yhteydessä CSC:n laskenta ja datapalveluihin. Genomidata siirretään CSC:lle huippunopean ja turvallisen valopolkuyhteyden ansiosta. Datan esikäsittely ja laadunvarmistus on nopeaa, koska data sijaitsee CSC:llä.
Kun sekvenssidata on fyysisesti lähellä laskentapalveluja, tutkija saa esikäsitellyn datan nopeammin. Kapasiteetilla voidaan sekvensoida tehokkaasti eksomeja, genomeja ja transkriptomeja.
Geenidatan ja kliinisen datan yhdistäminen vaatii vielä paljon datan tallennus- ja laskentakapasiteettia. CSC:n ja Barcelonan superlaskentakeskuksen (BSC) yhteinen projekti European HPC Center of Excellence for Personalised Medicine (PerMedCoE) toi henkilökohtaisen lääketieteen data-analyysimenetelmiä supertietokoneympäristöön. Hankkeessa kehitetyillä algoritmeilla pystytään merkittävästi lyhentämään analyysin vaatimaa laskenta-aikaa. Geeni- ja proteiinidatan analysointi nopeutuu, mikä helpottaa ja nopeuttaa sairauksien tunnistamista ja oikeiden hoitojen löytämistä. Sairauksien diagnosointi molekyylibiologian tietoa hyödyntämällä onnistuu jatkossa jopa tuntien tai päivien sisällä.

CSC yhdessä Suomen biopankkien, Terveyden ja hyvinvoinnin laitoksen sekä Turussa toimivan Euro-BioImaginin kanssa kehittävät tekoälyalgoritmia lääketieteellisen datan louhimiseen.
Euro-BioImaging Finland tarjoaa kuvan tallentamiseen ja dataan liittyviä palveluja, kuten kuvakokoelmia. Kokoelmiin on tallennettu teratavujen verran kuvia, joita voidaan käyttää mm. referenssidatana. Materiaalia on planktonin kuvantamisesta syöpäsoluihin.
Euro-BioImaging Finland tarjoaa myös lääketieteellisen kuvantamisen aineistoja. Vapaan pääsyn kuvantamispalvelut kattavat Suomessa kuusi yliopistoa ja kolme yliopistosairaalaa. Käytössä ovat OMERO-palvelimet (Open Microscopy Environment), joiden ansiosta tutkijat voivat katsoa, organisoida, analysoida ja jakaa kuvia mistä paikaista tahansa, jossa on pääsy internetiin.
“Turussa on jo tuotantokäytössä kaksi uutta OMERO-serveriä kuvadatalle, toinen tutkimukseen ja toinen opetukseen. Molemmat palvelevat rajoitetusti myös koko maata. Nyt olisi tärkeää suunnitella, miten nämä voisi linkittää CSC:n palveluihin”, sanoo Euro-BioImagingin johtaja Pasi Kankaanpää.
Kankaanpää on kirjoittanut Nature Methods-julkaisusarjaan, jossa määritellään suosituksia kuvadatan hallinnointiin ja sen metadataan.
”Tämä lisää yhteistyötä ja korostaa samalla myös sensitiivisen datan hallinnan tärkeyttä. Datan hallinnointi ja sen käsittely on Euro-BioImaging Finlandissa yksi keskeisiä kehityssuuntia – sitähän heijastaa myös tämä Suomen Akatemian rahoittama hanke”, sanoo Kankaanpää.
Tällä hetkellä genomidatan siirtäminen ja hyödyntäminen ei toimi yli rajojen. CSC kehittää genomidatan teknologioiden standardeja (mm. GA4GH.org Passport, Cloud, Beacon), joilla on myös merkitystä Euroopan ulkopuolella, kuten Pohjois-Amerikassa, Japanissa ja Australiassa. ELIXIR-infrastruktuurin tavoitteena on ottaa käyttöön globaalit genomidatan vastuullisen jakamisen standardit. Euroopassa on myös vahva halu luoda federoitu tietoturvainfrastruktuuri sensitiiviselle genomidatalle. Tarkoituksena on luoda Euroopan terveysdata-avaruus European Health Data Space (EHDS).
”ELIXIR on kehittänyt jo pitkään hyviä työkaluja tutkijoille – parantamaan käytettävyyttä luomalla uusia työkaluja. ELIXIRin yhteistyö Global Alliance for Genomic Health-konsortion kanssa on luonut hienon vision siitä, miten tämä globaali yhteistyö toimisi sekä konkreettisia työkaluja ja malleja”, sanoo THL Biopankin johtaja Sirpa Soini.
Biopankkien toimintaa yritetään saada yhteensopivaksi valtakunnan rajat ylittävään federoituun datainfrastruktuuriin. Tässä on yhteys EU:n jäsenmaiden ja komission rahoittamiin ”miljoonan genomin”-projekteihin (1+million genomes ja Beyond million genomes). Beyond million genomes-hankkeessa CSC johtaa teknistä infrastruktuurityötä.
THL Biopankki suunnittelee hankkeessa kansallisen terveysdatan hallinnointiprosesseja tutkimukseen. Tavoitteena on luoda tutkijoille ja opiskelijoille nopeampi pääsy Suomen eri biopankkien aineistoihin. Samalla dataa voidaan turvallisesti siirtää biopankeista CSC:n sensitiivisen datan ympäristöön ja jakaa aineistoja niille, jotka ovat saaneet käyttöluvan.
Sirpa Soini on hyvin perillä sensitiivisen datan käyttöön liittyvistä huolenaiheista ja sääntelystä. Hänestä tuntuu kuitenkin, että liian helposti syytetään EU:n yleistä tietosuoja-asetusta GDPR:ää kaikista vaikeuksista, vaikka moni jäsenmaa itse rajoittaa lainsäädännössään tai omissa tulkinnoissaan arkaluonteisen datan liikkumista. Soini on koulutukseltaan myös juristi ja hänen mielestään asiat ovat ratkaistavissa, jos poliittista tahtoa löytyy.
”Nyt tuntuu siltä, että monessa maassa sanotaan, että ei voida tehdä sitä tai tätä GDPR:n takia. Mutta se ei ole oikeasti se syy. Se ei ole syy Suomessa eikä muuallakaan ja tilanteeseen on olemassa ratkaisuja.”
Soinin mukaan GDPR ei rajoita datan käyttöä, vaan nimenomaan itse asiassa mahdollistaa sen, mutta vastuullisesti ja riskilähtöisesti. Kansallista lainsäädäntöä tarvitaan tukemaan joitakin käyttötapauksia.
Soinin mukaan datan toisiokäytössä on vaikeaa ennakoida tulevia käyttötarkoituksia. Mutta silloin pitäisi lähteä siitä, että lääketieteellinen ja soveltava tutkimus sekä tuotekehitys on mahdollista GDPR:n mukaan nimenomaan lakiperusteisesti.
”Silloin ei välttämättä suostumusta tarvita. Meillä voi olla laissa säädelty käyttötarkoitus yleisen edun nimissä ja asianmukaiset tietosuoja- ja tietoturvatoimenpiteet. Joka ikiseen asiaan ei tarvita täysimittaista yksityiskohtaista suostumusta sellaisenaan, vaikka läpinäkyvää informaatiota pitääkin edistää.”
Myöskään datan siirtoon ulkomaille ei ole Soinin mukaan absoluuttisia juridisia esteitä. THL Biopankissa sopimuksia datansiirrosta on tehty esimerkiksi Yhdysvaltoihin ja Australiaan.
”Ehdotin amerikkalaisille ja australialaisille juristeille yhteistyösopimusta, jossa korostetaan, mitä vastuita kullakin partnerilla on riskienhallintanäkökulmasta. Tärkeää, että sopimuksissa on tarkat rajoitukset ja että aineistot on pseudonymisoitu. Lisäksi aina mainitaan mihin data voidaan tallentaa. ”
Yksi säilöntäpaikka voi olla esimerkiksi Euroopan genomitiedon tietokanta EGA. Datan luovuttajien yksityisyyden suojaamiseksi tutkimukseen luvitettu tieto on pseudonymisoitu. Vain valtuutettu taho kuten THL voi purkaa pseudonymisoinnin.
Soini puhuu unelmapilvestä, jossa data ei itse asiassa liikkuisi.
”Dataa voitaisiin tallentaa tietoturvallisesti kansainväliseen tietokantaan. Haku ja tunnistautuminen olisi suoraan mahdollista ja saatavilla luottamusverkoston puitteissa edellyttäen, että datasetit olisivat valmiina. Tällöin jokainen rekisterinpitäjä kontrolloisi dataansa ja arvioisi pyyntöjä käyttää rekisteriä. Ideaalitapauksessa lupa voi kohdistua useisiin datasetteihin ympäri maailmaa, jolloin meillä olisi jonkinlainen federoitu ratkaisu: data itsessään ei liikkuisi vaan tutkija saisi käyttöönsä ”unelmapilven.” Siihen olisi tutkijoilla pääsy eri paikoista.”
Ari Turunen
30.12.2021
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Pasi Kankaanpää, Sirpa Soini, & Tommi Nyrönen. (2021). Sensitive data infrastructure. https://doi.org/10.5281/zenodo.8135532
Lisätietoja:
Suomen molekyylilääketieteen instituutti (FIMM), Helsingin yliopisto
THL Biopankki
Euro-BioImaging
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Glaukooma eli vanhalta nimeltään silmänpainetauti on näköhermon etenevä sairaus, joka aiheuttaa vaurioita näköhermonpäähän ja hermosäiekerrokseen. Riski sairastua glaukoomaan suurenee iän myötä. Glaukoomaa esiintyy yli 50-vuotiailla noin 2%:lla ja yli 75-vuotiailla yli 5 %:lla. Maailmassa on arviolta yli 60 miljoonaa glaukoomaa sairastavaa potilasta, heistä noin 6 miljoonan arvioidaan olevan näkövammaisia.
Haasteena taudissa on, että glaukooma on usein alkuvaiheessa täysin oireeton tai vähäoireinen. Koska vaurioita ei voida korjata, tauti tulisi löytää mahdollisimman varhain. Hoidon tavoitteena on ehkäistä glaukoomasta johtuvaa näkövammaisuutta. Suurimmalla osalla potilaista tautimuutokset etenevät hitaasti vuosien aikana. Pienellä osalla potilaista tauti voi johtaa vaurioihin jo lyhyessä ajassa.
Glaukooman havaitsemisen ja etenemisnopeuden tunnistamiselle olisi tärkeää, että terveydenhuollon järjestelmien avulla löydettäisiin mahdollisimman varhain suuren riskin tapaukset. Glaukooman varhaisen havaitsemisen avuksi on nyt kehitteillä tekoälymalleja.
Tutkija ja projektipäällikkö Ara Taalas on erikoistunut datatieteeseen, tekoälyyn ja koneoppimisen algoritmeihin lääketieteessä. Yksi hänen tutkimuskohteistaan on kehittää tehokkaita oppivia algoritmeja glaukooman havaitsemiseen Suomen molekyylilääketieteen instituutin (FIMM) ja Terveystalon yhteisessä projektissa. Aiemmin Taalas on mallintanut kantasolujen erilaistumisprosesseja ja tehnyt lääkeainesuunnittelua.
Terveystalon erikoisalajohtajan ja ylilääärin Matti Seppäsen mukaan glaukooman diagnoosi ja luokittelu perustuvat näköhermon pään, hermosäiekerroksen ja kammiokulman tutkimiseen, silmänpaineen mittaamiseen sekä näkökenttätutkimukseen.
”Glaukooman tarkkaa syntymekanismia ei tunneta, mutta todennäköisesti glaukoomavaurioiden taustalla ovat vauriot hermosolujen rakenteissa.”
Todennäköisesti noin 30-50 prosentilla potilaista silmänpaine on niin sanotulla normaalialueella (10-21 mmHg). Potilailla on yksilöllinen alttius glaukoomavaurioiden kehittymiseen eri painetasoilla. Osalla potilaista syntyy glaukoomavaurioita alhaisemmalla painetasolla, osalla potilaista muutokset voivat olla vähäisiä vaikka painetaso olisi suurempi.
”Nykyisin glaukoomadiagnoosiin tarvitaan silmälääkärin tutkimus ja useita lisätutkimuksia. Näköhermon päätä voidaan tutkia mm. biomikroskopian ja stereopapillakuvauksen avulla. Hermosäiekerrosta voidaan arvioida esim. värisuodatetun silmänpohjakuvauksen tai hermosäiekerroksen valokerroskuvauksen (ns. OCT-tutkimus) avulla. ”
Tutkimuksissa glaukoomaepäily voi herätä esimerkiksi näköhermonpään muodon perusteella. Näköhermonpään rakennetta voidaan arvioida ns. cup/disc –suhteen mittauksella, jossa näköhermon keskuskuopan suuruutta verrataan näköhermonpään ulkoreunan suuruuteen.
”Hermosäiekerroksen vauriot voivat tulla esiin hermosäiekerroksen valokerroskuvauksessa ohentuneena hermosäiekerroksena. Silmänpohjan värisuodatetussa valokuvauksessa voidaan myös saada esiin hermosäiekerroksen puutoksia. Glaukoomadiagnoosi perustuu usein useaan eri tutkimukseen ja tällä hetkellä ei ole saatavilla yksittäistä tutkimusmenetelmää, jonka avulla glaukooman seulontaa väestötasolla olisi päästy toteuttamaan. Tekoälysovellukset voivat tulevaisuudessa tuoda seulontaan ja diagnostiikkaan merkittävää apua.”
Esa Pitkänen Molekyylibiologian instituutista FIMM:stä (Helsingin yliopisto) kertoo glaukooman tutkimisesta algoritmien avulla.
Ara Taalaksen mielenkiinnon kohteena tekoälymallia kehitettäessä on mm. silmänpohjan hermokerrosten kuvautuminen kuvantamistutkimuksissa. Algoritmin avulla pyritään havaitsemaan silmänpohjakuvista niitä muutoksia, jotka voivat viitata hermosäiekerroksen vaurioon. Mallin avulla pyritään selvittämään, voivatko silmänpohjan hienosyiset verkottuneet muutokset muuttuessaan tummemmiksi ja monotonisiksi olla yhteydessä hermosäiekerroksen vaurioon.
”Tämä on yksi tekijöistä, joihin malli on kohdennettu. Jatkossa mallille opetetaan lisää silmänpohjan hermosäikeiden kuvioita. Tällaisten algoritmien tavoitteena on pyrkiä löytämään keinoja, jotka auttavat kehittämään päätöksentukijärjestelmiä lääkärin työhön. Pitkälle kehittynyt keinoäly voi löytää muutoksia, joita kokenutkaan kliinikon silmä ei välttämättä havaitse.”

Silmän rakennetta ja toimintaa mittaavissa tutkimuksissa esiintyy vaihtelua, joka johtuu käytössä olevasta tutkimusmenetelmästä, arvioijan kokemuksesta, tutkittavasta sekä taudin vaikeusasteesta. Näköhermon pään arvioimisella ei saavuteta aina riittävää tarkkuutta nykyisillä menetelmillä. Näkökenttätutkimus voi olla normaali, vaikka näköhermossa ja hermosäiekerroksessa esiintyisi vaurioita. Tämä johtuu siitä, että rakennevauriot tulevat yleensä ennen kuin näkökenttäpuutokset esiintyvät. Mikäli jatkossa pystytään kehittämään sovelluksia, jotka arvioivat aiempaa tarkemmin ja tehokkaammin rakenteellisia muutoksia, voidaan sillä varhaistaa glaukooman diagnostiikka.

Taalaksen mukaan eräänä sovelluskohteena mallille olisi, että tekoälymalli olisi käytettävissä aina kun tehdään näöntarkastus.
”Väestötutkimuksissa on todettu, että jopa puolet glaukoomaa sairastavista on tällä hetkellä diagnosoimatta. Nykyisillä seulontamenetelmillä ei ole päästy riittävän kustannusvaikuttavaan tulokseen ja yleisen väestöseulonnan esteenä on riittävän hyvien menetelmien puuttuminen.Jos keinoälysovellusten avulla pystytään riittävällä tarkkuudella tunnistamaan ne potilaat, joilla on keskimääräistä suurempi alttius sairastua glaukoomaan, voitaisiin oireettomasta väestöstä löytää sairaus helpommin jo niin varhaisessa vaiheessa että sen hoito olisi mahdollisimman tehokasta.”
Yhtenä tulevaisuuden visiona on, että esimerkiksi optikkokäynnin tai terveydenhoitajan tutkimuksen yhteydessä voitaisiin ottaa silmänpohjakuvaus ja samassa yhteydessä keinoäly analysoisi potilaan silmänpohjakuvan. Jos keinoäly ilmaisisi potilaalla olevan tavallista suuremman riskin glaukoomaan sairastumiseen, voitaisiin potilas ohjata jo varhaisessa vaiheessa jatkotutkimuksiin.
Tekoälysovellusten avulla työnjako tullee merkittävästi muuttumaan optisella alalla ja silmäsairauksien diagnostiikassa. Tämä tarjoaa myös avaimia merkittävästi lisääntyvän potilasmäärän hoitoon. Väestön ikärakenteen muuttumisen myötä glaukoomaa sairastavien potilaiden määrä Suomessa kaksinkertaistuu nykytasosta vuoteen 2030 mennessä.
Taalas on Suomen ELIXIR-keskuksen CSC:n laskentapalvelujen käyttäjä. Hän kehittää malleja yhteistyössä FIMM:in Machine Learning in Biomedicine-ryhmän tutkijoiden kanssa, ja samaa lähdekoodia pystytään käyttämään ristiin CSC:n ja Terveystalon laskentapalvelimilla.
”Suomessa ollaan datanhallinnassa nyt korkealla tasolla, mutta potilaista ei ole yksittäisillä terveydenalan toimijoilla tyypillisesti kaikenkattavaa kuvaa – potilasdataa on usein hajautuneena useille eri toimijoille. Kun asiakas vaihtaa organisaatiota, data ei aina liiku perässä, mikä voi vaikeuttaa hoidonohjausta. Tutkijan kannalta olisi ihanteellista, mikäli meillä olisi valtakunnallisesti keskitetty paikka, josta kansalaisen potilashistoria löytyisi kokonaisuudessaan.”
Myös datan kuvaaminen pitäisi saada standardoiduksi.
”Potilastietojärjestelmien rakenne vaikuttaa vahvasti syntyvän datan käytettävyyteen. Vapaatekstikentät ovat usein järjestelmän käyttäjälle miellyttäviä, mutta tuottavat tiedon hyödynnyksessä runsaasti päänvaivaa data-analyytikolle. Analyytikko joutuu usein tekemään runsaasti työtä tiedon standardoimiseksi, ja virheellisten kirjausten tunnistamiseksi. Modernit potilastietojärjestelmät ovat tässä mielessä menneet eteenpäin aiemmasta maailmasta, ja rakenteisuus korostuu niiden tietorakenteissa.”
Ari Turunen
23.11.2021
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Lila Kallio, Arho Virkki, & Tommi Nyrönen. (2021). Patient data creating better artificial intelligence models. https://doi.org/10.5281/zenodo.8135413
Lisätietoja:
Suomen molekyylilääketieteen instituutti (FIMM), Helsingin yliopisto
Terveystalo
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Ilman dataa ja sen uusiokäyttöä lääketieteellinen tutkimus ei edisty. Kerätyn datan ansiosta voidaan luoda hoitopäätösten tueksi tekoälymalleja, jotka nopeuttavat diagnooseja. Uusia datan analyysitekniikoita tulee koko ajan lisää, mutta miten data saataisiin kaikkien tutkijoiden käyttöön?
Suomeen perustettavan Genomikeskuksen yksi vahvuuksista on biopankkien tietokannat. Keskus vastaisi kansallisen genomitietorekisterin kehittämisestä eli keskitetystä geneettisen tiedon tallennuksesta ja hallinnoinnista. Tarkoituksena olisi saada aikaan laadukas suomalaisten geneettistä variaatiota kuvaava tietokanta. Auria Biopankin johtaja Lila Kallio uskoo, että biopankkien ja Genomikeskuksen hyvä yhteistyö voi johtaa merkittäviin tuloksiin geenivarianttien seulonnassa.
”Kun Genomikeskus on perustettu ja se aloittaa toimintansa, voitaneen tutkimuksessa tuotettu genomitieto tallentaa myös genomikeskukseen. Genomikeskus voisi sitten analysoida uudelleen sinne talletettua genomidataa vasten kaiken aikaa karttuvaa referenssigenomitietoa. Näin esimerkiksi uusien tunnistettujen kliinisesti merkittävien varianttien seulonta olisi mahdollista jo aiemmin tuotetusta ja tallennetusta datasta,” sanoo Lila Kallio.
Vuonna 2013 Suomessa säädettiin laki biopankeista. Laki mahdollisti biopankkien perustamisen. Suomessa on tällä hetkellä 11 biopankkia. Vuonna 2020 biopankkien verkostoon liittyi Arctic Biopankki, joka säilyttää Oulun yliopiston Pohjois-Suomen alueelta keräämiä laajoja väestöaineistoja. Tutkijat voivat Suomessa hyödyntää kaikkien biopankkien aineistoja Fingenious-verkkopalvelun kautta. Fingenious on digitaalinen työkalu, jonka kautta tutkija voi jättää aineiston luovutuspyynnön. Palvelusta vastaa Suomen biopankkien osuuskunta FINBB.
”Biopankit säilyttävät näytteisiin liittyvää dataa tietoturvallisesti. Biopankkien näytteisiin liittyvä tieto on kaikkien tutkijoiden käytettävissä. Tutkijalla tulee olla tutkimussuunnitelma, jonka biopankkien ohjausryhmät tai eettinen toimikunta hyväksyy. Näytteiden ja niihin liittyvän datan saamiseksi tutkimuskäyttöön biopankeilla on valmis prosessi olemassa.”
Suomessa on poikkeuksellisen kattavat ja laadukkaat terveysalan tietovarannot. Vuonna 2019 Suomessa tuli voimaan laki terveystietojen toissijaisesta käytöstä. Datan toisiokäyttö tarkoittaa sitä, että sosiaali- ja terveydenhuollon asiakas- ja rekisteritietoja käytetään muussa kuin siinä ensisijaisessa tarkoituksessa, jonka vuoksi ne on alun perin tallennettu. Laki toisiokäytöstä on luonut paineita myös vuonna 2013 säädetyn biopankkilain uudistamiselle. Datan merkitys biolääketieteen tutkimuksessa kasvaa ja lainsäädännön olisi luotava edellytykset sekä tutkimukselle että tarkoituksenmukaiselle tietoturvalle.
Toisiokäyttö luonnollisesti edellyttää, että ihmisistä kerättyjen tietojen hallinnointi on tietoturvallista. Biopankkeihin saatu ja ihmisistä kerättyjen näytteiden tunnistedata suojataan tarkasti.
”Biopankissa näytteistä poistetaan henkilötunnisteet, jotka korvataan pseudonyymikoodilla. Kun näytteitä luovutetaan edelleen tutkimuksiin, korvataan pseudonyymi vielä uudella, tutkimuskohtaisella koodilla. Koodiavain säilytetään biopankissa. Jos alkuperäiseen näytteeseen pitää palata esimerkiksi siitä löytyneen kliinisesti merkittävän tiedon vuoksi, voidaan se tehdä koodiavaimen avulla,” Kallio sanoo.
Koodiavain mahdollistaa datan uusiokäytön ja tutkimuksen tulevaisuudessa.
”Mikäli näyte anonymisoitaisiin eli tehtäisiin täysin tunnisteettomaksi, siihen palaaminen mahdollisten biopankkitutkimuksessa tehtyjen löydösten vuoksi ei olisi mahdollista, eikä siihen jälkeenpäin myöskään voisi liittää enää lisää näytekohtaista tietoa.”
Lila Kallion mukaan näytteen todellinen arvo muodostuu siitä tuotetusta datasta.
”Dataa syntyy diagnostiikan ja hoidon yhteydessä. Myös tutkimuksissa syntyy näytteestä analysoitua tietoa, mikä tulee palauttaa näytteen omistavalle biopankille liitettäväksi näytteeseen. Biopankki hallinnoi tunnistedatan lisäksi näytteeseen liittyvää kliinistä sekä tutkimuksessa tuotettua dataa.”

Datan toisiokäyttöä koskeva laki keskitti lupaprosessin hallinnoinnin uudelle viranomaiselle Findatalle. Ongelmaksi on tullut lupahakemusten ruuhkautuminen. Hakijat ovat kaikki samalla viivalla riippumatta siitä, koskeeko pyyntö pieniä tai äärimmäisen suuria aineistoja.
Aurian tietopalvelujohtaja ja lääketieteellisen matematiikan dosentti Arho Virkki tähdentää, että aineistolle on moninaista käyttöä ja siksi käyttötarkoituksen pitäisi myös määrittää datan suojaamisen tason. Datan toisiokäytön tietoturvaharppaus Suomessa oli Virkin mielestä liian iso askel yhdellä kertaa.
”Äärimmäinen suojaaminen huonontaa datan saatavuutta, jolloin tietoturva ei ole optimaalisella tasolle. Minulle optimaalinen tietoturva tarkoittaa, että aineisto on saatavilla ja sitä voidaan hyödyntää lääketieteen kehitykseen, uusien hoitojen suunnitteluun ja hoidollisten prosessien ohjaamiseen. Optimaalista on, että tieto on käytettävissä mutta samalla riittävästi suojattu. Suojaamisen tason pitäisi tulla riskiperusteisuudesta.”
Koska datanhallinta on kiinteä osa lääkärien ja hoitajien ammattia, datan hyödyntämiseen pitäisi Virkin mielestä löytää tasapaino aineiston saatavuuden ja suojaamisen välillä. Nyt se on heilahtanut toiseen ääripäähän.
”Aineiston käsittely on esimerkiksi osa lääketieteen opiskelijoiden opintoja. Yksi osahan kouluttautumista on, että opiskelijat käyvät läpi operatiiviset järjestelmät ja poimivat itse tietoja oppiakseen.”
Virkin mielestä ongelma on pitkän aikaan ollut tietoarkkitehtuuri. Lääketieteen ja terveydenhuollon defensiivisyyden ja sääntely takia tietoarkkitehtuuri on perinteistä verrattuna esimerkiksi logistiikkaan tai finanssialaan. Sen takia erilaisten tietojärjestelmien integraatio ei ole hyvä.
Virkki toki myöntää, että sairaalat ovat monimutkaisempia paikkoja kuin esimerkiksi logistiikkakeskukset. Logistiikassa paketti menee linjalle ja se kirjataan järjestelmiin, mutta kun potilas tulee sairaalaan, erilaisia kirjauksia ja järjestelmiä on valtava määrä.
Laki datan toisiokäytöstä määrittelee Virkin mukaan kuitenkin liian tarkasti sen, että yksi järjestelmä sopisi kaikille. Virkin mielestä luvan antaja voisi määrittää erilaisia käyttöympäristöjä tutkijoiden tarpeista riippuen.
”Luvanantaja voisi antaa perustasoisen ympäristön, mikä kelpaa yksinkertainen taulukkolaskenta-tyyppiseen data-analyysiin ja jossa olisi käytettävissä tavallisia tilastotieteen ohjelmointikieliä.”
Jos tutkijat taas tarvitsevat oman ympäristön, tutkijoille pitäisi antaa tarkat ohjeet tietoturvasta jaedellyttäätutkijoiden vakuutukset ohjeiden noudattamisesta.
”Tällöin viranomaiset vastaisit tietoturvan varmistamisesta ja tutkijat vastaisivat toiminnastaan tutkimusrekisterin pitäjälle, eli tutkimusta johtavalle kokeneelle tutkijalle, kuten tähänkin asti. Loppupeleissä on tutkijoiden vastuulla varmistaa, että tutkimustulokset ovat oikein, rehellisiä, tieteellisiä ja anonyymejä.”
Suomessa lääketieteen alan ihmisillä on Virkin mukaan korkea ammattiylpeys ja lääketieteellisen aineiston käsittely on ollut tähänkin asti alan tutkijoilla asianmukaisesti hoidettu. Virkin mielestä tietoturvasta voidaan huolehtia luvanvaraisuuden lisäksi koulutuksella. Tietoturva pitäisikin ottaa osaksi lääketieteen opetusta. Virkki käy säännöllisesti puhumassa Turun yliopistossa kliiniset tutkimuksen perusteet -kurssilla tietoalustoista ja tietoturvasta.

Virkin mukaan lakia datan toisiokäytöstä on alettu korjata. Jos säädökset datan toisiokäytöstä saadaan joustavimmiksi ja lupaprosessit nopeutuvat, tarjoaa se monia mahdollisuuksia tekoälytutkimukseen.
”Nyt kun Suomessa sosiaali- ja terveydenhuollon uudistus meni läpi, on hyvät edellytykset yhdistää perusterveydenhoidon ja erikoissairaanhoidon potilastiedot eli potilasdataa voidaan tarkastella kokonaisuutena. Se puolestaan antaa mahdollisuuksia kehittää uusia tekoälysovelluksia kliiniselle puolelle. ”
Tekoälymallien algoritmit voivat tehdä tekstipohjaisia analyyseja potilaskertomuksia tai oppia tunnistamaan kuvista piirteitä, joita voidaan hyödyntää diagnooseissa.
”Tekoälyhän on itse asiassa modernia tilastotiedettä, tilastomatematiikan hienostunut sovellus. Tekoälymalleissa hyödynnetään monimutkaisia tilastollisia menetelmiä. Kun puhutaan koneoppimisesta tarkoitetaan tilastollista oppimista. Nykyään voidaan laskea niin tarkkoja tilastomalleja, että se suorastaan tuntuu taikuudelta.”
Tekoälymallit ovat kiinnostaneet Virkkiä pitkään. Omassa väitöskirjatutkimuksessaan hän laati tekoälymallin ihmisen nukkumisen aikaiseen aineenvaihduntaan. Viime aikoina hän on ollut kehittämässä keuhkoveritulpan ennustemallia tutkijoiden kanssa. Mallia käytetään päätöksenteon työkaluna. Keuhkoveritulppa syntyy, kun muualta elimistössä liikkeelle lähtenyt verihyytymä tukkii keuhkoihin johtavan valtimon. Yleisin oire on äkillinen hengenahdistus. Isoissa keuhkoveritulpissa käytetään verihyytymien liuotushoitoa, jolloin laskimoon annetaan pistokselle veren hyytymistä estävää ainetta.
”Jos on epäilys, että päivystykseen tullut potilas on saanut keuhkoveritulpan, on toimittava nopeasti. Kone pystyy nopeasti vilkaisemaan kuvapakan läpi ja neuvomaan radiologia, mitä kohtaa kuvasta kannattaisi katsoa tarkemmin. Sitten päätetään, pitääkö aloittaa liuotus. Jos ei, niin hoitolinja on toinen. Kaikki pitäisi pystyä tekemään alle 10 minuutissa: keuhkojen kuvaus, diagnoosi ja hoidon aloittaminen.”
Virkin mukaan malli keuhkoveritulpasta oli ensimmäinen tieteellinen testi, jossa yritettiin ratkaista vaikeaa ongelmaa hyvin pienellä määrällä dataa. Laajempi ja tarkempi tekoälymalli on kuitenkin kehitteillä. Tulossa on tieteellisten julkaisujen lisäksi väitöskirjoja.
”Toteutuessaan malli nopeuttaa päätöksentekoa hoitotilanteessa, mutta se auttaa myös laaduntarkkailussa. Voimme esimerkiksi seuloa jälkikäteen tuliko havaittua kaikki pienetkin keuhkoveritulpat.”
Tekoälymallien kehittäminen edellyttää paljon dataa, joilla algoritmeja opetetaan sekä laskentatehoa.
Varsinais-Suomen sairaanhoitopiiri käyttää Suomen ELIXIR-keskuksen CSC:n ePouta -pilvipalvelua ja sairaanhoitopiiriin on saatu CSC:n laskentaympäristöön dedikoitu 10 gigabitin yhteys. Virkki toivoo tutkijoille parempaa pääsyä ELIXIR-verkostoon.
”Olisi hienoa, jos tutkijoilla olisi mahdollisuus saada kapasiteettia suoraan ELIXIR-infrastruktuurilta käyttöönsä. Tietoaineisto tulisi suoraan ELIXIRin ympäristöön ja ELIXIR pitäisi huolen riittävästä laskentakapasiteetista.”
ELIXIR-infrastuktuurin Suomen toiminnasta vastaa CSC – Tieteen tietotekniikan keskus. CSC hallinnoi resursseja ja palveluja, jotka ovat osa ELIXIRiä, kuten tunnistautumis- ja auktorisointipalvelut (ELIXIR AAI). ELIXIRissä tavoitteena on muodostaa yksi yhteinen, eurooppalainen tutkimusinfrastruktuuri, jonka ansiosta bio- ja terveystieteiden tutkijat voivat aiempaa helpommin löytää, analysoida ja jakaa aineistojaan. Tutkija voi käyttää ELIXIRin tunnistautumis- ja auktorisointipalveluja luodakseen turvallisen analyysiympäristön ja päästäkseen käsiksi pilveen tallennettuihin tutkimusaineistoihin.
Lääkärin kirjoittamaa tai sanelemaa tekstiä voidaan hyödyntää tekoälymalleissa, jotka ovat hoitosuositusten ja diagnoosien apuvälineinä. Lausunnoista ja lauseista voidaan rakenteistaa dataa ja opettaa alogoritmi tekemään päätelmiä. Auria biopankin ja Turun yliopistollisen keskussairaalan ja Turun yliopiston hankkeessa tekoäly opetettiin lukemaan lähes 30 000 potilaskertomuksista tupakointia käsitteleviä teitoja. Tutkija Antti Karlssonin vetämässä hankkeessa hyödynnettiin kielimallia nimeltä ULMFiT. Malli koulutettiin VSSHP:n analyysikoneilla suomenkielisen Wikipedian tekstimassaa hyödyntäen. Tämän jälkeen mallista koulutettiin luokittelija käyttäen noin 5000 tupakointiin liittyvän, käsin annotoidun lauseen aineistoa. Nykyään saatavilla on myös kehittyneempiä, valmiiksi esikoulutettuja suomenkielisiä kielimalleja, joista kuuluisin lienee Googlen BERT-malliin perustuva FinBERT. Sen on tuottanut Filip Ginterin vetämä Turun yliopiston tutkimusryhmä käyttäen Suomen ELIXIR-keskus CSC:n laskentatehoa.
Tekoälymallin keräämää dataa hyödyntämällä tutkimus osoitti, että tupakoinnin lopettaminen vaikka vasta syövän diagnoosihetkeen saattaa pidentää elinikää huomattavasti.
”Olen varma, että tulevaisuuden potilastietojärjestelmät eivät ole kaavakemaisia alasvetolaatikoineen, vaan nimenomaan proosallista potilaskertomusta tukevia ja siitä tiedot automaattisesti rakenteistavia versioita,” Karlsson sanoo.
”Tämä on työn tehokkuuttakin ajatellen tärkeää. En halua edes ajatella, millaista monimutkaisien asioiden kirjaaminen mahtaa olla kiireisessä lääkärin arjessa.”
Kun louhitaan isoa massaa dataa, säästetään tavattomasti aikaa ja rahaa. Antti Karlssonin kouluttama tekoälymalli analysoi potilastietoa tupakointiin liittyen. Em. tutkimuksessa malli analysoi 30 000 potilaan sairaskertomuksista saatua tekstidataa. Karlssonin mukaan tällaisia malleja käyttämällä saadaan yli 90% tarkkoja analyyseja jopa tunneissa tai minuuteissa. Se on eri asia kuin että manuaalisesti luettaisiin 30 000 potilaan tekstit ja kerättäisiin muuttujat taulukkoon.
”Parhaassa tapauksessa nämä mallit voisivat olla valmiina saatavilla tietoaltaassa ja voisivat rakenteistaa esimerkiksi tätä tupakkatietoa automaattisesti juuri tutkimuskäyttöä varten,” sanoo Karlsson.
Malli ei anna yksittäiselle potilaalle hoito-ohjetta, mutta luo hyvän kokonaiskuvan.
”Uskon, että ainakin aluksi tulevaisuuden automaattiset järjestelmät keräävät pikemminkin raportointiin ja tutkimukseen tärkeää dataa, kun taas todella tärkeät asiat, kuten esimeriksi lääkeannokset tai allergiat täytyy vielä asiantuntijoiden tarkistaa ja syöttää tiedot manuaalisesti.”
Ari Turunen
26.10.2021
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Pasi Kankaanpää, Sirpa Soini, & Tommi Nyrönen. (2021). Sensitive data infrastructure. https://doi.org/10.5281/zenodo.8135532
Lisätietoja:
Karlsson et al. (2021): Impact of deep learning-determined smoking status on mortality of cancer patients: never too late to quit. Esmo Open Cancer Horizons. Vol 3. Issue 3.
https://www.esmoopen.com/article/S2059-7029(21)00135-6/fulltext
Auria Biopankki
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Syväoppiminen on mullistanut syöpäsairauksien tutkimisen. Syvillä neuroverkoilla voidaan automaattisesti löytää potilaan näytedatasta piirteitä, joiden perusteella voidaan tunnistaa syöpiä. Oppivat algoritmit voivat tunnistaa jatkossa verinäytteestä mahdollisia syövän esiasteita. Esa Pitkänen ja hänen tutkimusryhmänsä Suomen molekyylilääketieteen instituutista kehittävät uuden sukupolven syväoppimisen algoritmeja.
Algoritmeja on hyödynnetty kudosnäytteiden leikekuvien solujen tunnistamisessa. Esimerkiksi jos kudoksen solut näyttävät epätyypillisiltä, algoritmi tunnistaa sen ja päättelee onko kyseessä syöpä. Nyt kuvantamisdatan rinnalla käytetään syöpien tunnistamisessa kasvaimista saatua DNA-sekvenssidataa.
”Aikaisemmin on ollut vaikea sanoa DNA-sekvenssin perusteella, minkälaisesta kasvaimesta sekvenssi on tullut. Nyt on luotu uusia tekniikoita ja syväoppimisen algoritmeja”, sanoo tutkija Esa Pitkänen.
Pitkänen ryhmineen kehittää algoritmeja, jotka tunnistavat DNA-sekvensseistä lyhyitä, toisteisia pätkiä. Algoritmien avulla voidaan löytää pätkiä, jotka mutatoituvat tietyssä syöpätyypissä usein tai joihin tietyt geenien säätelyyn osallistuvat proteiinit sitoutuvat. Näitä pätkiä analysoimalla voidaan saada tietoa esimerkiksi syöpäsairauksien syiden kartoittamiseen ja lääkkeiden kehittämiseen.
”DNA:n kopioituminen solun jakautumisen yhteydessä ei ole täydellistä. Kun solu jakautuu niin on mahdollista, että mutaatioita syntyy. Kun solu jakautuu, kopioitavaa DNA:ta on kuuden miljardin merkin verran eli virheitä tapahtuu. Pienikin todennäköisyys riittää että mutaatioita tulee”, sanoo Pitkänen.
”Jos riittävästi mutaatioita tapahtuu esimerkiksi kasvaimen syntyä ehkäisevissä geeneissä, syöpä voi alkaa kehittyä.”
Esimerkiksi pistemutaatiossa yksi emäs vaihtuu toiseksi DNA-ketjussa. Virhe voi syntyä, kun solun jakautuessa DNA kopioidaan ja kopioinnista vastaavat entsyymit korjaavat esimerkiksi auringonvalon ultraviolettisäteilystä vaurioituneen kohdan väärin. Ihosyöpää aiheuttavan ultraviolettisäteilyn aikaansaama tyypillinen mutaatio on se, että ihmisen DNA:n emäspareissa kaksi peräkkäistä sytosiinia (C) muuttuvat kahdeksi tymiiniksi (T). Kun tällaisia, ihosyövälle tyypillisiä mutaatioita havaitaan riittävästi, oppivat algoritmit yhdistämään mutaatiot tiettyyn syöpätyyppiin.
”Yritämme ennustaa mutaatioiden perusteella mikä syöpätyyppi ja kasvain on kyseessä. Samalla saadaan tietoa, joka voi vaikuttaa hoitoon.”
Pitkänen ryhmineen analysoi sekvenssijaksoja ja algoritmeja opetetaan tunnistamaan sekvenssijaksojen poikkeavuuksia. Näistä poikkeavuuksista algoritmi pystyy tunnistamaan, että kyseessä on kasvain ja luokittelemaan kasvaimet eri syöpätyyppeihin.
“Ennen siirtymistäni Suomen molekyylilääketieteen instituuttiin olin Euroopan molekyylibiologian laboratoriossa EMBL Heidelbergissä, jossa osallistuin PCAWG-syöpägenomiprojektiin. Projektissa analysoitiin yli 2600 syövän kokogenomia. PCAWG-data toimii aineistona useassa ryhmäni syöpägenomiikkaa käsittelevissä projekteissa.”
Esa Pitkäsen ryhmän kehittämälle algoritmille on opetettu näiden 2600 syöpäpotilaan kasvainnäytteistä löydetyt löytyneet mutaatiot, joita on yhteensä 47 miljoonaa.
“Algoritmi on koulutettu siten, että se yrittää näistä sekvenssien muutoksista päätellä syöpätyypin. Kun algoritmille on annettu eri kasvainten kaikki mutaatiot sekvensseineen, se pystyy jatkossa päättelemään minkälainen kasvain on kyseessä. Päättely perustuu siihen, että algoritmi oppii nämä yhteydet.”
Algoritmi oppii kasvaimissa olevan sekvenssidatan poikkeamien kautta tunnistamaan, että kyseessä on tietylle syövälle olennainen mutaatio. Algoritmi pystyy ryhmittelemään kasvaimet pelkän sekvenssidatan perusteella.
”Ryhmässäni tutkija Prima Sanjaya on kehittänyt neuroverkkomalleja sekvenssidatan analysoimiseen. Silloin tällöin törmätään metastaattisiin eli levinneisiin syöpiin, josta ei tiedetä mistä se on levinnyt. Tulevaisuudessa voidaan hyödyntää myös ns. nestebiopsiaa. Tällöin pystytään toivottavasti verinäytteestä sanomaan, onko potilaalla syöpä ja jos on niin minkälainen.”

Nestebiopsia perustuu siihen, että elimistön solut vapauttavat verenkiertoon ja ruumiinnesteisiin DNA:ta, jota kutsutaan solunulkoiseksi tai soluvapaaksi DNA:ksi (cell free DNA, cfDNA). Myös syöpäsoluista vapautuu DNA:ta, joka mahdollistaa syöpämutaatioiden etsimisen veren plasmasta.
“Jos nestebiopsiassa näkyy jälkiä syövästä, emme tiedä suoraan mikä syöpä on kyseessä, koska se voi tulla verenkiertoon mistä vain kehosta. Jos meillä on keinoja katsoa tarkemmin, kuten syväoppimisen algoritmit, saamme arvokasta tietoa, mihin kohtaan potilaan kehossa tutkimus pitää suunnata. Algoritmi voi kehottaa katsomaan esimerkiksi paksusuoleen. Uskon, että tulevaisuudessa tällaisilla algoritmeilla on suuri merkitys. Nestebiopsian ja algoritmien ansiosta voidaan tehdä tutkimusta ilman potilasleikkauksia”
Syövän syntyyn vaikuttavat perintötekijöiden lisäksi elintavat. Helsingin yliopistossa on tutkittu paljon esimerkiksi suolistosyöpiä.
”Se tiedetään, että punaisen lihan syömisellä on yhteys paksunsuolen syövän syntyyn. Syntymekanismit vaativat vielä lisätutkimuksia mutta esimerkiksi punaisen lihan aiheuttamien DNA:n alkylaatioreaktioiden merkitystä on selvitetty viime vuosina paljon.”
Paksunsuolen syöpä (CRC) on yksi vaarallisimpia syöpiä länsimaissa ja johtaa 30% tapauksissa esimerkiksi Suomessa kuolemaan. Noin 15% paksunsuolen syövistä kuuluvat joukkoon, jossa esintyy ns. mikrosatelliiti-instabiliteettia (MSI). Mikrosatelliitit ovat DNA:n toistojaksoja, joiden pituus vaihtelee yksilöstä toiseen ja ovat siten yksilöllisiä “sormenjälkiä”. Mikrosatelliiti-instabiliteetissa solun DNA:n replikaation jälkeinen korjausmekanismi ei toimi, jolloin mutaatioita alkaa kertyä erityisesti mikrosatelliitteihin.
”MSI-kasvaimessa mikrosatelliitteihin tulee helposti yhden emäksen lisäyksiä tai poistoja. Esimerkiksi kahdeksan peräkkäisen adeniinin mikrosatelliitista häviää yksi adeniini. Osuessaan geeniin tällainen muutos aiheuttaa geenin koodaaman proteiinin aminohappoketjun sisällön muuttumisen täysin. Jos riittävästi muutoksia tapahtuu hallitsematonta solujakautumista estävissä geeneissä, saattaa syövän kehittyminen alkaa.”
MSI liittyy usein paksunsuolensyövän lisäksi muihin syöpiin, kuten vatsasyöpiin, kohdunrungon ja munasarjan syöpään tai aivosyöpään. Syövän ennusteen arvioinnissa voidaan käyttää apuna MSI-analyysiä. Analyysin perusteella on joskus mahdollista määrittää sopiva hoito.
”Mielenkiintoista on, että syvä neuroverkko oppii myös luokittelemaan eri syöpien alalajeja. Se tunnisti esimerkiksi suolisyöpien MSI-alatyypin”, Pitkänen sanoo.
Suomen ELIXIR-keskus CSC on yksi pääpartnereita PerMedCoE-hankkeessa. Kolmevuotisen HPC/Exascale Centre of Excellence in Personalised Medicine -hankkeen (PerMedCoE) avulla esimerkiksi syöpään liittyvä data saadaan tehokkaasti terveydenhoidon käyttöön ja diagnoosit nopeutuvat.
”Tulevaisuuden yksilöidyt hoidot kuten syöpähoidot rakentuvat täsmälliseen käsitykseen potilaasta ja hänen sairaudestaan. Tämä käsitys muodostetaan keräämällä suuri määrä erilaista tietoa, kuten syöpää hoidettaessa kasvaimen genomi- ja kuvantamistietoa. Monet tiedonkeruumenetelmät tuottavat valtavan määrän tietoa, joiden analysoimiseksi kehitetyt uudet laskennalliset menetelmät puolestaan vaativat suuria laskentaresursseja”, Pitkänen toteaa.
”Uuden laskennallisen menetelmän kehittäminen ideasta toimivaksi, terveydenhoidossa käytettäväksi työkaluksi on tällaisessa toimintaympäristössä valtava haaste. Erityisesti syöpähoidoissa on tärkeää, että potilaan hoitoon vaikuttava tieto saadaan lääkärin käyttöön mahdollisimman nopeasti. Uskon, että PerMedCoE:n tuloksilla luodaan pohjaa sille, että valtavasta terveystietomäärästä voidaan lääkärin avuksi jalostaa merkityksellistä tietoa ja näin parantaa hoitotulosta merkittävästi.”
Ari Turunen
16.9.2021
Lue artikkeli PDF-muodossa
Citation
Ari Turunen, Esa Pitkänen, & Tommi Nyrönen. (2023). Teaching an algorithm to identify cancer from sequence data. https://doi.org/10.5281/zenodo.8135303

Mutaatioiden lähteinä ovat 1.ulkoiset tekijät: esimerkiksi auringon UV-säteily. 2.sisäiset tekijät: spontaani deaminaatioreaktio eli emäksen amiiniryhmän muutos, jolloin alkuperäinen emäs muuttuu joksikin toiseksi, esimerkiksi adeniini urasiiliksi 3. DNA:n kopioinnissa aiheutuneet virheet.
Mutaatio tarkoittaa muutosta DNA:n tai RNA:n nukleotidijärjestyksessä. Nukleotidiin kuuluu emäs, sokeri ja fosfaatti. DNA:n sokeri on D-deoksiriboosi ja RNA:n D-riboosi. DNA:n emäksiä ovat guaniini (G), adeniini (A), sytosiini (C) ja tymiini (T). RNA:n emäsosassa tymiinin tilalla on urasiili (U). Mutaatio voi olla vain yhden nukleotidin muutos eli pistemutaatio, tai se voi käsittää useita nukleotideja. Pistemutaatiossa yksi emäs vaihtuu toiseksi RNA- tai DNA-ketjussa. Iso mutaatioita, jotka voivat käsittää tuhansia nukleotideja, kutsutaan rakennemuutoksiksi.
Rakennemuutos voi vaikuttaa yhtä aikaa useaan geeniin. Syövät ovat yleensä useiden somaattisten mutaatioiden aiheuttamia; somaattiset mutaatiot eivät periydy, ja niitä voi syntyä milloin tahansa alkionkehityksen aikana ja sen jälkeen. Mutaatioiden seurauksena normaalin solun toiminta voi muuttua siten, että solu alkaa jakautua hallitsemattomasti. rilaisia mutaatiotyyppejä mutaatioiden jakautuminen kromosomeihin epigeneettinen tieto. Epigeneettiseen periytymiseen vaikuttavat monet ulkoiset tekijät, kuten esimerkiksi ravinto. Esimerkiksi identtiset kaksoset, voivat kehittyä ulkoisilta olemuksiltaan erilaisiksi. Mutaatioiden mallintaminen lineaariset mallit syvät neuroverkot transformer-mallit. Transformerit ovat syväoppimismalliperhe, jotka toimivat erityisen hyvin esim. tekstimuotoiseen dataan, sovelluksena vaikkapa konekääntäminen. Syöpätutkimuksessa transformer-mallit voivat kiinnittää huomiota mutaatiotyyppeihin, jotka ovat tärkeitä tietyn syöpätyypin tunnistamiseksi. Esimerkiksi ihosyövissä, joissa on paljon auringonvalon aiheuttamia mutaatioita (C>T, CC>TT), huomio kohdistuu juuri näihin mutaatioihin.
Kuvassa keskellä erilaisia mutaatiotyyppejä ja miten mutaatiot jakautuvat kromosomeihin. Mutaatioihin liittyy epigeneettinen tieto. Epigeneettiseen periytymiseen vaikuttavat monet ulkoiset tekijät, kuten esimerkiksi ravinto. Esimerkiksi identtiset kaksoset, voivat kehittyä ulkoisilta olemuksiltaan erilaisiksi.
Mutaatioiden mallintaminen:
lineaariset mallit
syvät neuroverkot
transformer-mallit. Transformerit ovat syväoppimismalliperhe, jotka toimivat erityisen hyvin esim. tekstimuotoiseen dataan, sovelluksena vaikkapa konekääntäminen. Syöpätutkimuksessa transformer-mallit voivat kiinnittää huomiota mutaatiotyyppeihin, jotka ovat tärkeitä tietyn syöpätyypin tunnistamiseksi. Esimerkiksi ihosyövissä, joissa on paljon auringonvalon aiheuttamia mutaatioita (C>T, CC>TT), huomio kohdistuu juuri näihin mutaatioihin.
Lisätietoja:
HPC/Exascale Centre of Excellence in Personalised Medicine (PerMedCoE)
Suomen molekyylilääketieteen instituutti FIMM
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Uuden sukupolven geenien ja RNA-molekyylien analyysimenetelmät mahdollistavat entistä nopeammat ja vaivattomammat analyysit. Data saadaan myös hyvin talteen ja jaettavaksi tutkimusryhmille Suomen ELIXIR -keskuksen CSC:n Allas-käyttöliittymän kautta.
Uuden sukupolven sekvensointimenetelmien (NGS) avulla tutkitaan perimässämme olevia virheitä ja variaatiota sekä geenien ilmentymisen (ekspressio) muutoksia. Menetelmien tuottamien miljardien sekvenssipätkien analysointi on mahdollista kerralla yhdessä tietokoneajossa.
Uusien menetelmien avulla pystytään tutkimaan lukuisia geenejä ja kohteita useista eri näytteistä samanaikaisesti. Menetelmien avulla voidaan tehdä nopeasti yksittäisten solujen, kuten syöpäsolujen, analysointi. Nyt voidaan myös analysoida veren plasmasta eroteltu soluvapaa DNA, joka kertoo nopeasti ja luotettavasti valittujen hoitojen tehokkuudesta ja erityisesti siitä, onko etäispesäkkeitä jäljellä.
Suomen molekyylilääketieteen instituutin (FIMM) ja CSC:n alustoilla on käytössä erilaisia algoritmeja sekvensointiin perustuvien menetelmien, (eksomit, genomit ja trasnkriptomitn) tuottaman datan analysoimiseen. Yksi keskeisimpiä on Broad Instituten GATK -työkalupakki (Genome Analysis Toolkit). Sen avulla etsitään geenivariantteja ja tunnistetaan DNA- tai RNA-sekvenssin muutoksia solulinjassa. GATK -analyysiohjelmistosta on tullut bioinformatiikan standardi tiedeyhteisössä. GATK-ohjelmistot ajetaan huippunopean Dragen-alustan (Dynamic Read Analysis for GENomics) kautta. Suomen ELIXIR-keskus CSC ylläpitää Dragenia yhdessä FIMM:n kanssa. Dragen esiprosessoi datan eli kun ensimmäiset tulkinnat datasta on tehty, tehdään usein lisää analyysejä. Tällöin myös CSC:n tallennuskapasiteetista on hyötyä, koska analysoitu data ei mahdu tavanomaiseen tietokoneeseen vaan saadaan suoraan jaettua käyttäjille Allas-palvelun kautta. CSC:n ja FIMM:n yhteistyö on olennainen osa analyysien nopeaa läpimenoa.
”Kun käytössä ovat korkean kapasiteetin sekvensointitekniikan alustat, algoritmit ja laskentateho, saadaan erittäin nopeita tuloksia. Yksi genomi voidaan nyt analysoida jopa vuorokaudessa kun aikaisemmin siihen meni useita viikkoja”, sanoo Pekka Ellonen.
Ellonen on Suomen molekyylilääketieteen instituutin (FIMM) sekvensointiyksikön laboratoriopäällikkö. Yksikkö tuottaa tutkimusyhteisölle genomiikan (DNA) ja transkriptomiikan (RNA) analyysejä moderneilla menetelmillä. Yksikkö saa analysoitavakseen erilaisten tutkimusprojektien tuottamia näytteitä.
”Yhdessä tutkijoiden kanssa päätetään tarvittavista menetelmistä ja räätälöidään paras työkalupakki, jolla testataan tutkijoiden hypoteesia. Sellaisia menetelmiä voivat olla eksomisekvensointi, genomisekvensointi, erilaisten RNA-molekyylien (transkriptomi) sekvensointi sekä geeniekspressio,” sanoo Ellonen.
Näiden menetelmien avulla kudoksesta voidaan selvittää perimä (genomiikka) tai tunnistaa esimerkiksi kaikki kudoksessa ilmentyvät geenit (transkriptomiikka) ja proteiinit (proteomiikka). Genomin proteiinia koodaavan alueen eli eksomin sekvensointi auttaa esimerkiksi periytyvien tautien, synnynnäisten kehityshäiriöiden ja syövän tutkimisessa. Geenien ilmentymistä säädellään tarkasti soluissa ja muutokset voivat johtaa sairauksiin. Tutkimuksissa voidaan verrata esimerkiksi syöpäkudoksen ja terveen kudoksen geenien ilmentymisen eroja.

Uuden sukupolven sekvensointimenetelmät mahdollistavat monimutkaisten biologisten järjestelmien tutkimisen. Ellosen mukaan ylivoimaisesti suurin muutos bioinformatiikassa viime vuosina on ollut yksittäisten solujen analysointi. Yksittäisten solujen analyysi tapahtuu Suomen molekyylilääketieteen instituutin yksittäisten solujen analyyseihin erikoistuneen yksikön (SCA) sekä sekvensointiyksikön yhteistyönä.
Jokainen solu sisältää yksilön jokaisen geenin, mutta tietyt geenit ilmentyvät vain tietyissä soluissa sekä usein vain tietyissä olosuhteissa. Geenien ilmentyminen ja proteiinien tuotanto soluissa vaihtelee eri kehitysvaiheissa ja sairauksien vaikutuksesta. Se aiheuttaa muutoksia solujen ja kudosten toiminnassa. Yksittäisen solun analytiikka ei oikeastaan tarkoita yhtä solua.
”Nyt voidaan tutkia esimerkiksi syöpäsoluja yksittäisinä kohteina. Luotettavaan tulokseen ei riitä yhden solun DNA:n emäsjärjestyksen tai geeniekspression selvittäminen, vaan pitää tutkia tuhansien tai kymmenien tuhansien solujen otoksia”, sanoo Ellonen.
RNA-sekvensointi yhden solun tarkkuudella (scRNA-seq) voi paljastaa geenien välisiä säännöllisiä vuorovaikutusyhteyksiä, solujen syntyperälinjat, solujen eroavaisuuksia sekä solun viitekehyksen ympäristössään.
Sekvensointi yksittäisistä soluista paljastaa myös erilaisia ja jopa uusia solutyyppejä sekä geenien ilmentymiseen perustuvaa tietoa niiden toiminnallisuudesta. Yksittäisen solujen DNA-sekvensointi antaa puolestaan tietoja mutaatioista, jotka tapahtuvat pienissä solupopulaatioissa normaalien solujen seassa. Yksittäisen solun tarkkuus antaa tietoja kasvainten geneettisestä erilaisuudesta, mistä on apua hoidoissa.
”Elävien solujen määrä tutkittavassa näytteessä todennetaan laboratoriossa, jonka jälkeen kukin solu erotellaan omaan nestepisaraansa eli droplettiin mikä mahdollistaa yksittäisen solun DNA- tai RNA –molekyylien merkitsemisen molekyylikohtaisilla ja solukohtaisilla DNA-viivakoodeilla. Molekyylikohtaiset, solukohtaiset ja lopulta näytekohtaiset DNA-viivakoodit mahdollistavat sekä solunäytteen kuhunkin soluun kuuluvien molekyylien tunnistamisen sekä taloudellisesti tehokkaan sekvensoinnin,” kertoo FIMM Teknologiakeskuksen yksittäisten solujen analytiikan yksikön (SCA) johtaja Pirkko Mattila.
”Yhdessä sekvensointiajossa profiloidaan useista näytteistä kustakin tuhansia soluja kerrallaan. Näin saavutetaan tuhansien solujen tai jopa satojen tuhansien solujen analyysistä yhden solun resoluutio ja päästään tutkimaan yksittäisen solun ominaisuuksia.”
Nestemäinen biopsia tarkoittaa soluja tai solunosia sisältävän nestemäisen näytteen ottamista elävästä kudoksesta, kuten verestä. Nestemäinen biopsia on lupaava seurantatyökalu syövän hoitamiseen ilman kirurgisia toimenpiteitä.
”Luomme sekvenssikirjastoja genomialueista, joista ollaan kiinnostuneita eri syövissä,” Pekka Ellonen sanoo.
Nestemäistä biopsiaa voidaan käyttää syövän tunnistamiseen varhaisessa vaiheessa. Verinäytteestä saadaan tietoja kasvaimen syöpäsoluista tai niiden erittämistä DNA-fragmenteista, joita on mahdollisesti verenkierrossa.
”Kasvain on yleensä hankalassa paikassa, jolloin kasvaimen poistamiseksi ja näytteen pitää tehdä kirurginen operaatio. Kun kasvaimet kasvavat hallitsemattomasti, solukuolemia tapahtuu normaalia enemmän. Kuolevat syöpäsolut vapauttavat DNA-fragmentteja verenkiertoon. Verinäytteen soluvapaasta osasta, plasmasta ja seerumista, kerätään nämä DNA-fragmentit talteen sekvensointia varten. Sekvensointituloksia analysoimalla voidaan havaita, onko verenkierrossa DNA-fragmentteja, joissa on nähdään syöville ominaisia muutoksia,” Ellonen toteaa.

Ellosen mukaan nestemäistä biopsiaa käytetään paljon ja siihen liittyy monia uusia tutkimushankkeita. Nestemäistä biopsiaa voidaan käyttää perustutkimuksen lisäksi myös hoitosuunnitelman teossa, hoidon vaikutusten seurannassa tai syövän uusiutumisen monitoroinnissa. Se, että pystyy ottamaan useita verinäytteitä eri aikoina, auttaa lääkäreitä ymmärtämään minkälaisia molekyylitason muutoksia on tapahtunut elimistössä.
”Voidaan tunnistaa uusia geenimerkkejä ja parhaassa tapauksessa valita mutaatioiden perusteella toimiva täsmähoito. Vaihtoehtoisesti tiedetään mitä etsitään eli tutkitaan näkyykö verenkierrossa enää merkkejä jäännöstaudista ja saatiinko syöpä kirurgisen operaation jälkeen kokonaan leikattua pois.”
Pekka Ellonen on innostunut CSC:n Allas-tallennuspalvelun käyttöliittymästä, jota kautta laboratoriot ja tutkimuslaitokset voivat jakaa esikäsitellyt sekvensointitulokset ja molekyylien datan tutkijoiden, tutkimusryhmien ja konsortioiden käyttöön. Allas tarjoaa 12 petatavun tallennustilan. Data on saatavilla tietoturvallisesti suoraan www:n kautta. Datankäsittely voidaan tehdä tavanomaisia ohjelmointirajapintoja käyttäen mistä tahansa.
”Julkinen raha tuottaa dataa, joten se pitää jakaa aikanaan tiedeyhteisön käyttöön laajemminkin, asianmukaisesti pseudonymisoituna. Käyttöliittymä mahdollistaa isojen aineistojen, kuten hyödyllisen genomitiedon kohorttiaineistot, jakamisen.”
Ari Turunen
3.12.2020
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Esa Pitkänen, & Tommi Nyrönen. (2020). Efficient processing and sharing of data improving disease diagnosis and treatment. https://doi.org/10.5281/zenodo.8135239
Lisätietoja:
Suomen molekyylilääketieteen instituutti FIMM
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Ihmisen geeneistä ja proteiineista saatu data mahdollistaa sairauksien nopean diagnoosin sekä hyvät ja yksilölliset potilashoidot. Riskiryhmään kuuluvat voidaan seuloa paremmin ja lääkityksen tehoa voidaan parantaa kun tiedetään potilaan geeniperimä. Haasteena on, miten data käsitellään ja minne se tallennetaan.
Uusien datan analyysimenetelmien ja tietokoneiden lisääntyneen laskentatehon ansiosta geeni- ja proteiinidatan käsittely saadaan nopeutettua useista päivistä jopa alle puoleen tuntiin. Tämä edellyttää, että data on esikäsiteltyä eli siitä on poistettu toisteisuus ja että se on nopeasti ja tietoturvallisesti saatavissa.
Bioinformatiikan mittausmenetelmät ovat kehittyneet huimasti ja ne tuottavat valtavasti dataa. Nyt voidaan ymmärtää kokonaisen biologisen järjestelmän toiminta. Tällöin kaikkia geenejä tai niiden tuottamia proteiineja tutkitaan samanaikaisesti. Näitä ns. omiikkoja ovat DNA-sekvenssin selvittäminen (genomiikka) ja proteiinien rakenteiden tietokonemallinnus (proteomiikka), solukudoksessa ilmentyvät geenit (transkriptomiikka)sekä aineenvaihduntatuotteet (metabolomiikka). Näiden menetelmien avulla voidaan tutkia molekyylien vuorovaikutuksia ja löytää elimistön tilan muutoksista merkkejä tautien tunnistamiseksi.
”Nyt pystytään tekemään todella paljon, mutta geenidatan ja kliinisen datan yhdistäminen vaatii vielä paljon datan tallennus- ja laskentakapasiteettia ja kaiken tiedon käsittelyä tietoturvallisesti,” sanoo Suomen molekyylilääketieteen instituutin (FIMM) teknologiakeskuksen johtaja Katja Kivinen.

Datan oikeaoppinen esikäsittely ja mallintaminen ovat edellytys tulevaisuuden tutkimukselle, joka lupaa entistä tehokkaampia ennusteita taudeista ja jopa yksilöllistä täsmälääkitystä. Kivinen antaa kaksi esimerkkiä: tautien riskitekijöiden esiseulonnan ja lääkehoidot.
Nature Medicine -lehdessä julkaistiin keväällä 2020 artikkeli, joka perustui Finngen -hankkeessa tehtyihin data-analyyseihin. Professori Samuli Ripatin tutkimusryhmä Suomen molekyylilääketieteen instituutista pystyi genomitiedon perusteella tunnistamaan suomalaisen väestöryhmän, jolla oli 60% todennäköisyys sairastua elämänsä jossakin vaiheessa sydän- ja verisuonisairauksiin tai diabetekseen. Tutkimusaineistossa oli 135 000 suomalaista näytteenantajaa. Yksittäisistä riskitekijöistä saatu tieto yhdistettiin ns. perimänlaajuiseksi riskipistemääräksi.
”Kun geneettinen tausta selvitetään, lääkärit voivat kohdentaa sekä ennaltaehkäiseviä toimenpiteitä että hoitoja tarpeen mukaan ja yhteiskunta säästää aikaa ja rahaa”, sanoo Kivinen.
”Tulevaisuudessa väestölle tehtävät seulonnat voidaan kohdentaa nykyistä paremmin. Osalle väestöstä esimerkiksi kutsu rintasyöpäseulontaan tulee perinnöllisen riskin puolesta aivan liian aikaisin, toisille puolestaan aivan liian myöhään. Kun perinnölliset riskitekijät otetaan huomioon, voidaan seulontoihin kutsua optimaaliseen aikaan syövän varhaisen havaitsemisen kannalta ja samalla minimoida toistuvista mammografioista aiheutuvaa tarpeetonta säteilyannosta.”

Ihmiset reagoivat lääkkeisiin eri tavoin, osalla lääkehoidon teho jää puutteelliseksi ja osalle se aiheuttaa haittavaikutuksia. Syynä poikkeavaan vasteeseen voivat olla fyysiset ominaisuutemme, muu lääkitys ja geneettinen perimämme. HUS e-care for me –projektin pilottivaiheessa kehitetään parempia hoitomenetelmiä leukemiaan ja muihin verisyöpiin. Kesällä 2019 aloitetussa projektissa yhdistetään Suomen molekyylilääketieteen instituutissa tuotetusta potilaskohtaisesta biologisesta datasta kliinisiin tietoihin syövän tyypistä ja leviämisasteesta ja etsitään tekoälyn avulla kullekin potilaalle sopivin lääkitys syövän leviämisen pysäyttämiseksi.
”Joskus voi käydä niin, että lääke ei tehoa tai se on lakannut tehoamasta. Leukemiapotilaiden verinäytteistä otetaan soluviljelmät ja sitten analysoidaan, mitkä lääkeaineiden yhdistelmät toimivat.”
Samasta verinäytteestä tehdään genomi- ja transkriptomi -sekvensointi. Transkriptomi antaa tietoa mahdollisten geenimuutosten aiheuttamista muutoksista geenien toiminnassa.
”Jos lääkeaine ei enää toimi, voidaan selvittää minkälaisia geneettisiä muutoksia eli mutaatioita on tullut. Toimivatko jotkut geenit tai eivät mutaation seurauksena? Entä miten mutaatio vaikuttaa aineenvaihduntareitteihin? Nyt voidaan suoraan verikokeista katsoa, mikä lääke sopii parhaiten eri verisyöpäpotilaille.”
Yksikölliset lääkehoidot ovat mahdollisia, jos dataa on potilaasta tarjolla ja se on tallennettu ja esikäsitelty oikein. Suomen ELIXIR -keskus CSC ja Barcelonan supertietokonekeskus (BSC) yhdessä yhdentoista muun akateemisen ja kaupallisen toimijan kanssa, aloittivat lokakuussa 2020 European HPC Center of Excellence for Personalised Medicine (PerMedCoE) -hankkeen. Hankkeessa kehitetään algoritmeja, joilla pystytään merkittävästi lyhentämään analyysin vaatimaa laskenta-aikaa. Geeni- ja proteiinidatan analysointi nopeutuu, mikä helpottaa ja nopeuttaa sairauksien tunnistamista ja oikeiden hoitojen löytämistä. Nykyisin genomianalyysi voi kestää viikkoja tai jopa kuukausia. Superlaskennan ja oikeiden ohjelmistojen myötä esimerkiksi sairauksien diagnosointi onnistuu jatkossa tuntien tai päivien sisällä.
Tällaiset projektit ovat tärkeitä Suomen molekyylilääketieteen instituutin tutkimusryhmille, jotka ovat koko ajan tekemisissä valtavien datamäärien kanssa.
”Datan määrä kasvaa kiihtyvällä tahdilla entistä tehokkaampien laitteiden ja menetelmien myötä, sanoo Katja Kivinen. ”Tällä hetkellä datan tallennustilasta on jatkuva pula ja datan esikäsittely kestää liian kauan, jotta pääsisimme purkamaan muodostuvaa sumaa ja lähettämään valmiit datat eteenpäin tutkimusryhmille. Tietoturvallinen datan tallennus- ja käsittely-ympäristö on elintärkeä ihmisdataa käsitellessä. Kaupalliset pilvipalvelut tarjoavat turvallisia käyttöympäristöjä, mutta ovat liian kalliita useimmille tutkijoille. Lisäksi osa datoista vaatii tarkasti räätälöidyn esikäsittely- ja analyysiympäristön ja soveltuu huonosti kaupallisten pilvipalveluiden tarjoamiin vaihtoehtoihin.”
Datan käsittelyyn saadaan apua CSC:n ja FIMM:n työnjaolla. Pilottivaiheessa genomidata siirretään FIMM:istä CSC:lle huippunopean ja turvallisen valopolkuyhteyden ansiosta. Datan esikäsittely ja laadunvarmistus analyysia varten on nopeaa, koska data sijaitsee CSC:llä. CSC toimii jatkossa myös datan valtakunnallisena jakajana takaisin tutkimusryhmille.
”Aiemmin sen selvittäminen, minkälaisia genomisia muutoksia ihmisen genomissa on, on vienyt meiltä 2-3 päivää per genomi. Yhteistyön ansiosta olemme saaneet käyttöön sekventointilaitteemme valmistajalta optimoidun laskentapalvelimen, joka tiivistää yhden genomin prosessoinnin 20 minuuttiin. Tämä auttaa meitä purkamaan genomidatan käsittelyyn kertyneen jonon FIMM:issä ja vapauttamaan bioinformaatikoidemme aikaa muihin töihin – esimerkiksi erilaisten datojen integraation suunnitteluun ja mahdollistamiseen.”
CSC on kehittänyt FIMM:istä tulevan genomidatan jakamiseen suomalaisten tutkimusryhmien käyttöön yhteisen käyttöliittymän CSC:n Allas-palveluun. Tutkimusryhmät saavat viestin, kun heidän genomidatansa on valmis ja siirtävät sen omalle projektialueelleen CSC:n ePouta -ympäristössä. Pilottivaiheen jälkeen portaalin toimintaperiaatetta on tarkoitus tarjota laajemmin kaikille omiikka -dataa tuottaville tutkimusryhmille suomalaisissa yliopistoissa.
”Käyttöliittymä on meille elintärkeä mm. siksi, että datamäärän kasvun ja toisaalta tietoturvavaatimusten kiristymisen myötä meidän on yhä vaikeampi ylläpitää FIMMissä datan tallennus- ja prosessointiympäristöä.. Meidän on pakko alkaa siirtää enenevässä määrin raakadataa tai käsiteltyä dataa CSC:lle, josta tutkimusryhmät voivat ottaa sen käyttöönsä.”
Toinen tärkeä kehityskohde Kivisen mukaan ovat mikroskooppien tuottaman datan talllentamisen ja siihen liittyvät kuvantamispalvelut.
”Kuvien prosessointi tapahtuu yleensä itse instrumenttiin liitetyllä palvelimella, jossa on prosessointiin tarvittavat ohjelmistot. Prosessoinnin siirtäminen pilvipalveluun ei aina ole varteenotettava vaihtoehto varsinkaan koko maassa liian hitaan siirtonopeuden vuoksi. Kuvien prosessointi saattaa siis jatkossakin tapahtua ”paikan päällä”, mutta prosessoidun datan jakamisen tulisi mielestäni siirtyä genomidatan tapaan CSC:n jaettavaksi.”
Ari Turunen
10.11.2020
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Katja Kivinen, & Tommi Nyrönen. (2020). Bioinformatics to revolutionise healthcare: Efficient data processing speeds up diagnoses and enables personalised drug treatments. https://doi.org/10.5281/zenodo.8135131
Lisätietoja:
Suomen molekyylilääketieteen instituutti FIMM
Cleverhealth
https://www.cleverhealth.fi/fi/ecare-for-me
+1 million genomes
https://ec.europa.eu/digital-single-market/en/european-1-million-genomes-initiative
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Turun yliopistollisen keskussairaalan ja Auria biopankin tavoitteena on saada kaikki kudosleikenäytteet digitaaliseen muotoon. Näytteet skannattaisiin lasilevyiltä ja jokapäiväisessä patologian työssä diagnostiikka siirtyisi tietokoneelle. Samalla kehitetään tekoälymalleja eli luokittelijoita, jotka tunnistavat digitoiduista näytteistä esimerkiksi syövän.
Pelkästään Turun yliopistollisessa keskussairaalassa (TYKS) otetaan potilailta 200 000 kudosnäytettä vuosittain. Kudosnäyte käsitellään formaliinissa ja valetaan parafiiniblokkiin, jonka jälkeen siitä voidaan höylätä leikkeitä mikroskoopilla tarkasteltavaksi. Lopulta parafiiniblokit varastoidaan. Näytteiden hallinnoiminen on työlästä ja vie paljon aikaa. Näytteiden järjestelmällinen digitoiminen tuo tähän apua.
”Koska näytteitä on paljon, metadatatiedon avulla löydetään halutut ja oikeat näytteet nopeasti”, sanoo Auria biopankin data-analyytikko Antti Karlsson.
Tietokantaan voi siis tehdä esimerkiksi haun, joka etsii kaikki ne näytteet, joissa on rintasyöpäkasvainta. Hakua voi metatiedon avulla tarkentaa, jolloin voidaan etsiä esimerkiksi 60-vuotiaiden rintasyöpäpotilaiden näytteet, joissa on tietty reseptoristatus.
Digitaalisen patologian hankkeessa mikroskooppilaseilla olevat näytteet skannataan. Sitten patologi voi katsoa tietokoneella näytteet ja kuvailla ja luokitella ne. Nämä ns. annotaatiotiedot ovat olennaisia, jotta voidaan opettaa tekoälyä automaattisesti tunnistamaan näytteistä esimerkiksi syöpäsolut. Tämä nopeuttaisi huomattavasti patologin työtä jatkossa. Auria biopankissa on panostettu data-analytiikkaan, algoritmien kehitykseen ja koneoppimismalleihin.
Turun yliopistollisessa keskussairaalassa (Tyks) on valtavasti mikroskooppilaseille säilöttyjä kudosleikkeitä. Ongelma on, että lasiin ei saa tallennettua metadataa, joka saataisiin siirrettyä tietokantoihin automaattisesti. Nyt tarkoituksena on, että uusiin näytteisiin patologit merkitsevät metadatan kuvankäsittelyohjelman avulla.
Karlssonin mukaan työ on ensin mekaanista. Patologi käyttää kuvankäsittelyohjelmaa, jonka avulla piirtää skannattuihin näytteisiin ne kohdat, joissa on esimerkiksi syöpää.
Tämän lisäksi tarvitaan kuvailutietoja. Tässä apuna olisivat neuroverkko-kielimallit. Patologi voisi kuvailla suoraan tietokoneelle näytteen tietoja. Aihetta on tutkittu Turun yliopiston tulevaisuuden teknologioiden laitoksen Filip Ginterin tutkimusryhmän kanssa,. Tutkimusryhmä on keskittynyt siihen, miten tietokoneohjelmia voidaan käyttää luonnollisen tekstin ja puheen analysointiin. Kielimalli oppii isosta määrästä luokittelematonta tekstiä, miten jokin puhuttu kieli näyttää tilastollisesti toimivan. Auria biopankki ja Tyks ovat kiinnostuneita siitä, miten lääkärinlausuntojen teksteistä saataisiin muodostettua luokiteltua ja rakenteistettua tietoa kielimallien avulla
”Digipatologiassa yksi sovellus voisi olla se, että jälkikäteen louhitaan lausuntoteksteistä erilaisia tietoja, kuten vaikka missä näytteen osassa on mitäkin kiinnostavaa kudosta, jolloin näytteiden valinta tutkimusten tarpeisiin helpottuu. Lisäksi voitaisiin kehittää vapaata lausuntotekstiä automaattisesti rakenteistavaa mallia. Patologi voisi lausua ’proosaa’, jonka tekoäly sitten keräisi ja koostaisi rakenteiseksi taulukoksi. ”
Karlssonin mukaan tällaisia taulukoita käytetään jo nyt aika paljon esimerkiksi silloin, kun patologit ovat sopineet, mitkä kaikki asiat kustakin kasvaimesta pitää raportoida.
”Tällä hetkellä kokeilemme jo näitä malleja esimerkiksi tupakointitiedon löytämiseen ja luokitteluun satojentuhansien lausuntotekstien sisältä, sekä syövän metastasointitietojen, sairaalainfektioihin liittyvien oireiden ja erilaisten diagnoosien löytämiseen.”
Haasteena on vielä monimuotoinen data. Esimerkiksi eri laitevalmistajien skannerit tuottavat erilaista dataa, joka pitäisi luotettavasti yhteensovittaa.

Metadatan ja digitoidun näytemateriaalin avulla kehitetään esimerkiksi tekoälysovelluksia, jotka opetetaan luokittelemaan automaattisesti, missä kohtaa kuvassa on syöpäsoluja. Tekoälyn opettamiseen tarvitaan patologien luokittelemaa materiaalia. Antti Karlssonin mukaan kuvia ei tarvita itse asiassa kovinkaan paljon, jotta algoritmi oppisi.
”Kymmenillä kuvilla päästään jo alkuun. Yksi iso leikekuva voi tuottaa tuhat pientä kuvaa, joilla voi kouluttaa malleja.”
Tällöin 20 potilaasta saadaan jopa 10 000 pientä kuvaa.
”Isoa kuvaa ei sellaisenaan pysty vielä lykkäämään algoritmeille, koska minkään tietokoneen grafiikkaprosessorin muisti ei riitä siihen.”
Karlsson haluaa tähdentää sitä, että kuvia katsovat tekoälymallit ovat eri asia kuin tekstiä katsovat mallit.
”Ne ovat toki kaikki tekoälyä ja vieläpä neuroverkkoja, mutta rakenteeltaan ja toimintaperiaatteeltaan erilaisia. Tekoäly on ennemminkin kokoelma työkaluja, joista jokainen on sitten käyttökelpoinen omaan tiettyyn sovellukseensa.”

Auria biopankin johtaja Lila Kallio toteaa, että genomidatan tutkimuskäytön lisäksi digipatologiaa hyödyntävä data-analytiikka on yksi keskeisiä Aurian painopisteitä.
”Entistä enemmän ollaan kiinnostuneita siitä, miten digitoidusta syöpäkudosleikkeestä voidaan tunnistaa eri asioita. Olemme mukana tutkimuksissa, joissa pyritään algoritmin avulla ennustamaan primäärisyöpäkasvaimen näytteen kuvasta esimerkiksi taudin hoitovastetta tai sitä, tuleeko primäärisyöpäkasvain levittämään etäispesäkkeitä. On viitteitä siitä, että algoritmi pystyisi ennustamaan histologisesta kuvasta sellaista, mikä ei silmämääräisesti ole nähtävissä.”
Suomessa on Lila Kallion mielestä oltu datan hallinnoimisessa ja jakamisessa hyvin edistyksellisiä. Suomen biopankkilaki on mahdollistanut tutkimuksen ja tiedon yhdistelemisen eri rekistereistä. Erityisen tärkeää on, että kliininen tieto voidaan yhdistää näytteisiin.
”Palvelua tutkijoille on voitu toteuttaa yhden luukun periaatteella. Biopankki hoitaa luvat, kerää näytteet ja yhdistää niihin tutkimukselle oleellisen kliinisen tiedon. Tämä kaikki voidaan sitten yhdistää muuhun dataan, esimerkiksi geenitietoihin. ”
Biopankin kautta tutkija saa tarvitsemansa näytteet.
”Biopankit tekevät Suomessa yhteistyötä. Tutkija voi pyytää näytteitä kaikista Suomen biopankeista Suomen biopankkien osuuskunnan kautta yhdellä pyynnöllä.”
Haasteena nyt ja tulevaisuudessa on Lila Kallion mielestä datan tallentaminen ja hallinnoiminen.
”Dataa tallennetaan sairaanhoitopiirin palomuurien sisälle. Jos patologian diagnostisia näytteitä ruvetaan rutiininomaisesti digitoimaan, tulee myös tallennuskapasiteetti ratkaista. Lisäksi kuvien koko on niin valtava, etteivät ne helposti siirry tavallisten tietoverkkojen kautta.
Laskentateho ja tietoturvalliset tallennus- ja käyttöympäristöt Suomen ELIXIR-keskuksen CSC:n kanssa tulevat tässä tärkeään rooliin.
Ari Turunen
28.8.2020
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Antti Karlsson, Lila Kallio, & Tommi Nyrönen. (2020). Tissue samples into digital images, interpreted by artificial intelligence. https://doi.org/10.5281/zenodo.8134949
Lisätietoja:
Auria Biopankki
https://www.auria.fi/biopankki/
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Digitalisaatio on mullistamassa patologiaa. Mikroskooppinäyte voidaan muuttaa digitaaliseen muotoon skannereiden avulla. Skanneri kuvaa näytteen näkymä kerrallaan ja tietokone yhdistää näkymät virtuaalimikroskopiakuvaksi.
Turun yliopistollisessa keskussairaalassa patologian näytteet digitoidaan ja näytteiden tutkiminen siirtyy tietokoneen ruudulle. Tämä antaa mahdollisuuksia erilaisiin mittauksiin ja tekoälysovelluksiin. Yhteistyössä Auria Biopankin kanssa kehitetyillä tekoälysovelluksilla vähennetään patologin rutiinityötä ja nopeutetaan näytteiden analyysia.
Turun yliopistollisen keskussairaalan patologian vastuualuejohtaja Markku Kallajoki on tehnyt syöpään liittyvää perustutkimusta ja tutkinut solumalleja ja soluviljelmiä. Hän on toiminut patologian erikoislääkärinä sekä solu – ja molekyylipatologian professorina. Yksi Kallajoen kiinnostuksen kohteista on eturauhassyöpä.
Perinteisesti patologit arvioivat eturauhassyövän ärhäkkyyttä kudosnäytteestä mikroskoopilla. Syöpäkasvaimesta annetaan ns. Gleasonin luokitus asteikolla 6-10. Tauti on sitä ärhäkämpi, mitä korkeammat pisteet ovat. Gleasonin luokituksen arvoa 7 pidetään rajana hyvän ja huonon ennusteen välillä. Korkeat Gleason -pisteet (8–10) tarkoittavat ärhäkästi käyttäytyvää kasvainta ja matalat (alle 7 pistettä) rauhallista tautia.
”Mitä suurempi pistesumma, sen aggressiivisempi syöpä. Tekoäly voi tehdä erottelua ja löytää kudosnäytteestä syöpäalueet ennen kuin patologi alkaa tutkia näytettä. Se voi myös ehdottaa Gleason-luokitusta. Patologi voi kohdentaa huomionsa tekoälyn näytteestä löytämiin kohtiin ja olla sen kanssa samaa tai eri mieltä. Joka tapauksessa tekoäly helpottaa ja nopeuttaa patologin työtä, ” sanoo Kallajoki.

Tampereen yliopiston ja Tukholman Karoliinisen instituutin tutkijat ovat kehittäneet tekoälyyn perustuvaa menetelmää eturauhassyövän mikroskooppidiagnostiikkaan ja luokitteluun. 6600 eturauhasen koepalaa käytettiin materiaalina, jolla opetettiin tekoälyä erottamaan hyvänlaatuiset ja pahanlaatuiset koepalat. Näytteistä pystyttiin luomaan malli, joka osaa katsoa kudosnäytteistä onko siinä syöpää, kuinka paljon ja kuinka pahanlaatuinen se on.
Tutkimusten mukaan patologien työajasta menee 15 % muuhun kuin itse diagnostiseen työhön. Aikaa kuluu näytteiden ja lähetteiden etsimiseen, käsittelyyn ja vastaanottamiseen sekä niiden kuittaamiseen. Näytteiden analysointi vaatii usein myös keskusteluja muiden patologien kanssa. Digitalisaation myötä näihin konsultaatioihin kuluva aika vähenee, koska näytelasien lähettämisen sijaan patologit voivat siirtää verkossa kuvia ja keskustella katsomalla vaikka eri sairaaloissa samaa näytettä tietokoneiltaan.
”Digipatologia helpottaa meidän työtämme ja tekee siitä laadultaan parempaa. Se nopeuttaa työtä ja säästää rahaa”, sanoo Kallajoki.
Patologi pystyy analysoimaan pelkästään digitoinnin myötä n. 15% enemmän näytteitä nykyiseen verrattuna. Kun mukaan tulee tekoälymalli, työ voisi nopeutua jopa 30%.
Eturauhassyöpä on miesten yleisin pahanlaatuinen syöpä, joka syntyy eturauhasen solujen muuttuessa pahanlaatuisiksi. Eturauhasesta otettujen kudospalojen perusteella patologi pystyy arvioimaan, kuinka pahanlaatuinen syöpä on kasvaimen erilaistumisen perusteella. Mitä huonommin kasvain on erilaistunut, sitä aggressiivisemmin se käyttäytyy.
”Mikroskooppinäyte otetaan, jos kliinisten esitietojen ja löydösten, laboratoriotutkimusten ja radiologisten kuvantamistutkimusten perusteella herää vahva epäily syövästä”, Kallajoki sanoo.
”Syöpähän ei ole syöpä, ennen kuin patologi on vahvistanut sen solu- tai kudosnäytteestä. Eturauhassyöpää epäiltäessä näyte otetaan neulalla peräsuolen kautta eturauhasesta. Senttimetrin – kahden pituisia ja n. millimetrin paksuisia kudospaloja otetaan yleensä kuusi kappaletta eturauhasen molemmilta puolilta. Kudoslieriöt lähetetään patologian laboratorioon, jossa niistä valmistetaan histologiset näyteet.”
Histologisen eli kudosopillisen näytteen perusteella arvioidaan tarvitseeko potilas hoitoa. Näytteet fiksoidaan eli kiinnitetään formaliinissa, jolloin kudos kiinteytetään ja säilötään solujen omien entsyymien hajottavaa vaikutusta vastaan. Sitten parafiinilla imeytetyt näytteet valetaan parafiiniblokkeihin, josta leikataan ohuita kolmen – neljän mikrometrin siivuja. Näytteet värjätään histologisin väreillä ja laitetaan kahden lasilevyn väliin. Nyt näytteitä voidaan tarkastella mikroskoopilla ja tarvittaessa skannata ja digitoida.
Suuriresoluutioisista digitoiduista kudosnäytteistä on löydettävissä samat yksityiskohdat kuin mikroskooppinäkymää tarkasteltaessa. Digitoitu kuva antaa mahdollisuuden mittauksiin ja erilaisten solutyyppien automaattiseen laskentaan. Näytteisiin on myös helppo palata, koska kuvat voidaan kuva-arkistosta helposti hakea uudelleen tarkasteltaviksi esimerkiksi kokouksissa, joissa päätetään potilaiden hoidosta.
Patologi saa huomattavan määrän apua myös muusta datasta. Kallajoen mukaan Aurian tapaisen biopankkien merkitys on suuri. Dataa saadaan nyt monesta lähteestä, mikä helpottaa patologien käytännön työtä. Sairaskertomuksista saadaan potilastiedot, mitä on tutkittu sekä laboratoriotestien tulokset. Lisäksi käytössä on radiologian tuottama kuvantamisdata.
Datan hyödyntämisen ja uusien menetelmien myötä kehitetään Kallajoen mukaan uusia hoitomuotoja.
”Elämme poikkeuksellisia aikoja, sillä syöpähoidot ovat kovan kehityksen alla ja tulossa on lisää molekyylimuutoksiin perustuvia täsmähoitoja.”
Datan tallennus on kuitenkin edelleen haasteellista.
”Digikuvat ovat valtavan suuria. Kuvan koko on 2-3 gigaa. Kun yhdestä potilaasta otetaan 12 kuvaa yhdellä tutkimuskerralla, saadaan aikamoinen datamäärä. Turun yliopistollisessa keskussairaalassa tehdään vuodessa 200 000 näytelasia. Koska kyseessä on lääketieteellinen informaatio, siitä pitää ottaa kahdet tai kolmet varmuuskopiot. Kun 200 000 mikrosooppinäytteen tallennusmäärä kerrotaan kolmella, saadaan tallennukselle kovat vaatimukset.”
Markku Kallajoen mukaan suuri haaste on se, että eri paikoissa suunnitellaan digipatologiaan tarvittavien laitteistojen, ohjelmistojen ja tallennussysteemien hankintaa, mutta järjestelmien pitäisi olla keskenään yhteensopivia.
”Optimaalinen olisi Suomen laajuinen, yhteensopiva järjestelmä. Digipatologiassa suurin yksittäinen kustannuserä on tallennuskapasiteetti.”
Ari Turunen
9.6.2020
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Markus Kallajoki, & Tommi Nyrönen. (2020). Digital pathology speeds up diagnosis. https://doi.org/10.5281/zenodo.8131372
Lisätietoja:
Auria Biopankki
https://www.auria.fi/biopankki/
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Geenivarianttien lisäksi on genomisia variantteja yksittäisissä DNA:n emäsparijaksoissa. Nämä variaatiot aiheuttavat yksilöiden väliset erot, mutta ne voivat myös auttaa paikallistamaan tautia aiheuttavia geenejä. Nämä yhden emäsparin vaihtelut eli snipit (single nucleotide popymorphism, SNP) voivat toimia markkereina, jotka viittaavat sairauteen. Itä-Suomen yliopistossa kehitetty tekoälymalli etsii rintasyöpään viittaavia snippejä.
Genomidatan valtava määrä on mahdollistanut sen, että tutkijat voivat laskea, mitä geenimuunnoksia on niissä ryhmissä, jotka ovat sairastuneet syöpään. Yhteen tautiin voi vaikuttaa satoja tai tuhansia geenimuunnoksia.
Tilastollisten menetelmien ansiosta tutkijat voivat arvioida, miten yhden ihmisen geenimuunnokset lisäävät riskiä sairastua tautiin eli näin saadaan monitekijäisten geenien riskiarvo. Mutta variaatioita on myös DNA:n emäspareissa eli nukleotideissä. Ne tunnetaan genomisina variantteina eli snippeinä. DNA:n sekvenssivariaatiot tapahtuvat, kun yhdessä emäsparissa genomisekvenssi (adeniini-tymiini, sytosiini-guaniini) muuttuu. Jokainen SNP edustaa muutosta yhdessä emäsparissa. Esimerkiksi yksi SNP voi vaihtaa jossakin DNA-ketjun emäsparissa sytosiinin tymiiniksi. Se tarkoittaa, että sytosiini-guaniini -emäspari voi muuttua DNA-ketjusssa esimerkiksi tymiini-adeniini -pariksi. Toisin kuin geenimuunnokset, snipit eivät välttämättä sijaitse geeneissä. Snippejä sijaitsee myös ei-koodaavissa geeneissä tai geenien välissä. Ihmisen genomissa on paljon snippejä. Niitä on keskimäärin melkein joka tuhannen emäsparin jälkeen, mikä tarkoittaa, että ihmisen genomissa on arviolta 4-5 miljoonaa snippiä.
Snipit voivat olla hyödyllisiä, kun etsitään syövän geneettisiä riskitekijöitä. Biolääketieteellisessä tutkimuksessa snippejä käytetään tutkimusaineistossa vertailemalla genomialueita sairastuneiden ja terveiden välillä.
“Kun snipit ilmaantuvat geenissä tai regulatiivisella alueella lähellä geeniä, niillä voi olla suora rooli taudin syntymiseen, koska ne vaikuttavat geenin toimintaan. Meillä on uudenlainen koneoppimisen lähestymistapa, jolla voidaan tunnistaa joukko vuorovaikuttavia snippejä, jotka ovat eniten osallisina rintasyövän riskitekijöissä”, sanoo tutkija Hamid Behravan Itä-Suomen yliopistosta. Hän työskentelee Kuopiossa Kliinisen lääketieteen yksikössä.
”Olemme julkaisseet useita tuloksia siitä, miten geneettinen osatekijä rintasyövän riskissä tunnistetaan, jolloin erotettaisiin luotettavasti sairastapaukset terveiden vertailuryhmästä. Rintasyöpään liittyvien snippien tunnistaminen on erityisen hyödyllistä, koska rintasyövän ennustettavuutta voidaan parantaa ja kehittää yksilöllisiä hoitosuunnitelmia”, sanoo Behravan.
Standardeilla hypoteesien testausmenetelmillä on mitattu ainoastaan yhden snipin yhteyttä tautiin. Kuitenkin Itä-Suomen yliopiston tutkimukset ovat osoittaneet, että rintasyövän riskitekijät voidaan ennustaa paremmin kun snippejä tarkastellaan ryhminä, jotka itse asiassa vuorovaikuttavat toistensa kanssa.
Genominlaajuisten assosiaatiotutkimusten (GWAS) idea on tunnistaa snipit DNA:ssa. Se auttaa selvittämään geneettiset osatekijät tutkittavassa fenotyypissä joukossa genotyypitettyjä ihmisiä. Genotyypityksessä luetaan vain ne tiedossa olevat kohdat kromosomeissa, joissa esiintyy tutkittavaan tautiin liittyviä geenivariantteja.
”Genominlaajuiset assosiaatiotutkimukset mittaavat yksittäisen snipin yhteyttä sairauteen, mutta jättävät huomioimatta mahdollisen korrelaation snippien välillä”, sanoo Behravan.
”Tähän päivään asti koko populaation kattavat GWAS-tutkimukset ovat usein käyttäneet ns. PRS- pisteytystä (polygenic risk scoring, PRS), joka kerää yhteen riskialleelien (geenien vaihtoehtoiset muodot) vaikutukset tautiin. Kuitenkin PRS olettaa, että tauteihin liittyvät snipit ovat riippumattomia toisistaan ja että riskivaikutukset ovat lineaarisia ja yhteenlaskettavissa. Olemme osoittaneet, että sen sijaan, että arvioisimme yksittäisiä osatekijöitä (snipit) yksi kerrallaan, olisi erityisen hyödyllistä parantaa rintasyöpäriskin ennustettavuutta tutkimalla vuorovaikuttavien snippien ryhmää käyttäen koneoppimista.”

Itä-Suomen yliopistossa kehitetty koneoppimisen menetelmä on osoittautunut tehokkaaksi.
“Löysimme ryhmän vuorovaikuttavia snippejä, joilla on todellista biologista merkitystä. Tunnistettujen snippien biologinen analyysi paljasti geenejä, jotka liittyivät tärkeisiin rintasyöpään viittaaviin mekanismeihin, kuten estrogeeniaineenvaihduntaan ja ohjelmoituun solukuolemaan, apoptosikseen.”
Kohonneet estrogeenitasot liittyvät vaihdevuosien jälkeen kasvaneeseen rintasyövän riskiin. On myös vahva näyttö, että kasvaimen kasvu ei johdu pelkästään rajoittamattomasta leviämisestä vaan myös pienentyneestä solukuolemasta.
”Löysimme siis menetelmämme avulla geenit noiden tunnistettujen snippien taustalta. Laadimme näistä geeneistä interaktiivisia karttoja. Sitten tarkkailimme useita erilaisia rintasyöpään liittyviä geenien vuorovaikutusverkostoja, kuten estrogeeniaineenvaihduntaa ja ohjelmoidun solukuoleman verkostoja. Meidän systeemimme ei ainoastaan löytänyt mahdollisimman hyvin vuorovaikuttavia rintasyövän riskejä ennustavia snippejä, vaan se myös tunnisti ne snipit, jotka muodostivat merkittävän määrän tärkeitä biologisia rintasyövän osa-alueita. Näin ollen, vuorovaikuttavat snipit ilmaisevat myös ne snipit, jotka ovat mukana syöpään liittyvissä biologisissa verkostoissa.”

Kuopiossa kehitetty koneoppimisen lähestymistapa perustuu gradienttipuun tehostamismenetelmälle, jossa on iteratiivinen hakualgoritmi. Tehostaminen on ensimmäinen moduuli ja haku toinen.
Tehostaminen (boosting) on algoritmi ja metodi, jolla heikot oppijat muutetaan vahvoiksi. Heikolla luokittelijalla tarkoitetaan sellaista luokittelijaa, joka on vähintään puolessa tapauksista oikeassa. Algoritmi käynnistyy opettamalla päätöspuuta. Heikot luokittelijat lisätään peräkkäisesti korjaamaan olemassaolevien luokittelijoiden virheet, jotta rakennetaan vahvaa luokittelija.
”Ensimmäinen moduuli arvioi tunnusmerkkien tarkkuutta, tässä tapauksessa snippejä, rintasyövän ennustettavuudessa. Ensimmäinen moduuli antaa alustavan kandidaattilistan snipeistä, jotka voivat ennustaa rintasyöpäriskistä.”
Toinen moduuli sitten käyttää kandidaattisnippejä adaptiivisessä ja iteratiivisessa haussa, jotta se voisi kaapata nuo vuorovaikuttavat piirteet. Parhaimmat tunnistetut vuorovaikuttavat snipit käytetään ennustamaan tuntemattoman yksilön rintasyövän riskiä testivaiheessa käyttäen koneluokittelijaa. Luokittelija opetettiin erottamaan rintasyöpätapaukset (positiiviset näytteet) terveistä kontrolleista (negatiiviset näytteet).
Koska syöpä on monitekijäinen tauti, jonka aiheuttavat elintavat sekä geneettiset ja ympäristötekijät, geneettisiin variantteihin perustuva ykslöllinen analyysi ei ehkä ole riittävä, jotta saataisiin kokonaisvaltainen kuva tautiriskistä. Behravanin mukaan myös muita datalähteitä tarvitaan.
“Kehitämme integroivia koneoppimisen lähestymistapoja, jossa yhdistetään eri datalähteitä, kuten väestötieteellistä dataa.”
Ari Turunen
18.5.2020
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Hamid Behravan, & Tommi Nyrönen. (2020). Searching markers for breast cancer by machine learning. https://doi.org/10.5281/zenodo.8131311
Lisätietoja:
Lääketieteen laitos, Itä-Suomen yliopisto
https://www.uef.fi/fi/web/laake
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Aineenvaihdunnan eli metabolian aikana syntyy ja hajoaa molekyylejä, joilla osalla on vaikutus myös terveyteen. Niiden pitoisuuksia mitataan verestä, virtsasta ja kudosnäytteistä. Metabolomiikan avulla saadaan selville biomarkkereita, jotka voivat kertoa elintavoista, ruokavaliosta, sairauksista sekä lääkityksen ja muiden vierasaineiden vaikutuksista.
Yhdellä mittauksella saadaan tietoa sadoista, jopa tuhansista aineenvaihduntatuotteista eli metaboliiteista. Lisäksi samassa mittauksessa näkyvät myös elimistön ulkopuolelta tulleet yhdisteet kuten lääkkeet, ympäristömyrkyt ja nautintoaineet.
”Metabolomiikka mahdollistaa aineenvaihdunnallisten ilmiöiden laaja-alaisen tarkastelun. Näin saadaan erittäin laaja kuva esimerkiksi elimistön biokemiallisesta tilasta,” sanoo professori Seppo Auriola Itä-Suomen yliopiston farmasian laitokselta. Auriola on myös Kuopion LC-MS Metabolomiikkakeskuksen johtaja. Keskus on osa Suomen Biokeskuksen infrastruktuuriverkostoa.
Yksi metabolomiikassa käytetty analyyttinen työkalu on nestekromatografia yhdistettynä korkean erotuskyvyn massaspektrometriaan. Nestekromatografia-massaspektrometriaa (LC-MS) käytetään näytteistä löytyvien yhdisteiden seulomiseen ja tunnistamiseen. Nestekromatografi erottelee yhdisteet niiden rasvaliukoisuuden mukaan ja massaspektrometrilla mitataan eroteltujen yhdisteiden tarkat molekyylipainot. Metabolomiikassa käytetään termiä ”molekyyliluonne”, joka tarkoittaa ionisaatiossa ja mittauksessa yhdisteestä syntyvää signaalia.
”Metabolomiikassa pyrimme löytämään tilastollisesti eroavat molekyyliluonteet eri tutkimusryhmien välillä. Näitä voivat olla esimerkiksi sairaat versus terveet. Metabolomiikka pyrkii myös tunnistamaan nämä molekyyliluonteet molekyyleiksi erilaisten spektroskopiaan perustuvien tekniikoiden avulla. Meidän laboratoriomme hyödyntää tähän massaspektrometriaa,” sanoo laboratorionjohtaja Marko Lehtonen.
Metabolomiikkamittaukset voidaan jakaa kohdentamattomiin ja kohdennettuihin menetelmiin. Lähtökohta kohdentamattomassa analyysissä on se, että tutkittavasta näytteestä pyritään löytämään mahdollisimman laaja joukko metaboliitteja. Kohdennetussa analyysissä puolestaan seurataan rajattua joukkoa tunnettuja metaboliitteja.
Kohdentamattomat mittaukset voivat toimia hyvänä lähtökohtana hypoteesin luomiseen.
”Ensimmäisellä seulonnalla nähdään niitä aineenvaihduntatuotteita, jotka ovat muuttuneet esimerkiksi tietyn altistuksen jälkeen. Sitten mietitään teoriaa eli miksi näin on käynyt”, sanoo Auriola, joka on keskittynyt työssään analyyttiseen kemiaan ja tutkittavien näytteiden mittaustekniikkaan.

Koska metabolomiikan mittausmenetelmät tehostuvat, saadaan parempaa mittausdataa esimerkiksi ihmisten elintapojen ja ympäristön vaikutuksesta terveyteen. Ruokavalio on yksi merkittävimmistä ulkoisista tekijöistä, jotka vaikuttavat aineenvaihduntaan.
”Metabolomiikka soveltuu erinomaisesti juuri ravitsemustutkimuksiin.
Analyyseissa löytyy selviä markkereita, mitä joku on syönyt ja miten ne vaikuttavat ihmisten endogeenisiin yhdisteisiin,” Auriola sanoo.
Endogeeniset aineita ovat kaikki kehon tuottamat yhdisteet, kuten hormonit ja välittäjäaineet. Niitä ovat esimerkiksi endokannabinoidit, steroidit sekä endorfiinit.
”Voimme tutkia, vaikuttaako elintapojen muuttaminen terveellisemmäksi myös metaboliittien tasoihin. Tämä olisi osoitus siitä, että elimistö voi paremmin. Metabolomiikan avulla voidaan myös etsiä sairauksien biomarkkereita varhaisessa vaiheessa ennen sairauksien puhkeamista. ”

Toinen merkittävä metabolomiikan analyysikohde ovat eksogeeniset eli elimistön ulkopuoliset yhdisteet, kuten lääkkeet ja ympäristömyrkyt. Tällöin etsitään biomarkkereita esimerkiksi siitä, miten lääke vaikuttaa elimistössä.
Tärkeä kysymys on Auriolan mielestä myös se, miksi joku aine vaikuttaa meihin negatiivisesti. Silloin voidaan etsiä aineenvaihduntatuotteista sellaisia biomarkkereita, jotka osoittavat ihmisen altistumista vierasaineelle tai vierasaineen vaikutusta ihmiseen. Sellaisia on esimerkiksi torjunta-aineiden vaikutus ihmisten terveyteen.
”Torjunta-aineiden kaikkia vaikutusmekanismeja ei tiedetä.
Kun menetelmät kehittyvät, nähdään paremmin minkälaisia vaikutuksia on elimistössä tiettyjen altistusten yhteydessä. Voidaan mitata ihmispopulaatioista, mikä on ympäristömyrkkyjen taso ja vastaavasti endogeenisten metaboliittien taso. ”
Itä-Suomen yliopiston ja Karolinska Instituten tutkimuksessa selvitettiin polykloorattujen bifenyylien eli PCB-yhdisteiden vaikutusta hiirten jälkeläisiin. Pitkään on tiedetty, että suurin näiden aineiden vaikutus kohdistuu kehittyvään elimistöön. Eläinkokeissa on todettu eri elinten kehityshäiriöitä. Kun jälkeläisten metabolomiikkaprofiileja tutkittiin, huomattiin, että tiettyjä muutoksia havaittiin koirailla. Nämä muutokset kuitenkin puuttuivat naarailla. PCB -yhdisteiden aiheuttamat metaboliittien muutokset koirailla vaikuttivat maksan ja hermoston toimintaan.
”Voidaan seurata minkälaisia muutoksia seuraavassa sukupolvessa on, tietämättä etukäteen, mitä sieltä pitäisi etsiä, sanoo Auriola.
”LC-MS -laitteistojen ja kohdentamattoman metabolomiikka -menetelmän avulla löydetään tuhansien mitattavien molekyylien joukosta ne molekyylit, jotka ovat muuttuneet.”
Molekyyliluonteita etsitään algoritmien avulla. Helsingin ja Itä-Suomen yliopiston tutkimuksessa analysoitiin vastasyntyneiden napanuorista löytyneitä yhdisteitä. Raskausmyrkytys (pre-eklampsia) on yksi yleisimmistä äitiyskuoleman ja ennenaikaisen synnytyksen syistä. Sen kehittymisen syitä ei tunneta tarkasti. Sen tiedetään lisäävän äidin ja lapsen riskiä sairastua myöhemmin sydän- ja verisuonitauteihin. Ei kuitenkaan tiedetä miten myrkytyksen saaneiden äitien muuttunut aineenvaihdunta vaikuttaa vastasyntyneiden aineenvaihduntaan. Vastasyntyneiden napanuoran kudoksen metaboliitit analysoitiin LC-MS -laitteistolla Kuopiossa raskausmyrkytyksen saaneiden ja terveiden välillä. Tutkimuksessa käytettiin myös suomalaisia FINNPEC (Finnish Genetics of Pre-eclampsia Consortium) -aineistoja. FINNPEC -kohortin keräämiseen ovat osallistuneet kaikki Suomen yliopistosairaalat.
”Useat eri tutkimusprojektit käyttävät laboratoriomme palveluja”, sanoo Marko Lehtonen. Laboratoriossa on mitattu esimerkiksi diabeteksen ja Alzheimerin tautiin liittyvien tutkimuksen näytteitä. Lehtosen mukaan metabolomiikka tuo paljon lisätietoa myös harvinaisten ja perinnöllisten sairauksien tutkimukseen.
”Vastasyntyneiden seulontaa tehdään kohdennetuilla mittauksilla. Se on myös erinomainen esimerkki, jossa metabolomiikalla voi olla suuri merkitys. Siinä yhteiskunta säästää rahaa. Tietyillä elimistössä esiintyvillä biomarkkereilla voidaan löytää vastasyntyneillä perinnöllisiä sairauksia,” sanoo Lehtonen.
Nykyisillä laitteilla ei kaikkia metaboliitteja voi vielä mitata.
”Yhdisteet ovat näytteessä niin pieninä pitoisuuksina, että nykyisin tarvitaan myös kohdennettuja menetelmiä. Laitetekniikoiden kehittyessä voidaan tulevaisuudessa toivoa, että yhä useamman aiemmin näkemättä jääneet yhdisteet näkyvät myös kohdentamattomilla menetelmillä. Tällöin emme hävitä muuta tietoa näytteestä. Kohdennetut menetelmät nimittäin seuraavat vain ennalta rajattua joukkoa yhdisteitä ja ovat sokeita kaikelle muulle tiedolle”, sanoo Lehtonen ja korostaa, että kohdentamattoman menetelmän data sisältää paljon tietoa, josta voidaan aina etsiä uusi asioita.
Kun laitteiden herkkyydet parantuvat, päästään havainnoimaan todella pieniä molekyylejä. Silloin puhutaan pikogrammoista ja nanogrammoista litraa kohden. Yksi pikogramma on gramman triljoonasosa ja yksi nanogramma on gramman miljardisosa.
”Nyt näemme tuhansia molekyylejä, mutta monia tärkeitä molekyylejä on vielä havaintorajan alapuolella, sanoo Seppo Auriola.
”Esimerkiksi steroideja löydetään näytteistä entistä enemmän mittaustekniikan kehittyessä. Näin voidaan tutkia endogeenisia steroideja ja niiden muutoksia.”
Näitä ovat esimerkiksi sukupuolihormonit, kuten testosteroni ja progesteroni sekä kortikosteroidit (mm. kortisoni ja kortisoli).
”Olemme mukana muun muassa projektissa, jossa tutkitaan lasten ja nuorten liikunnan ja elintapojen vaikutusta steroideihin ja muuhun metaboliaan. Toisissa tutkimuksissa etsitään steroidimetaboliaan valikoivasti vaikuttavia yhdisteitä, joita voitaisiin käyttää lääkkeenä.”

Massaspektrometriassa tutkittavat aineenvaihduntatuotteet ensin ionisoidaan. Ionisoituneet molekyylit erotellaan toisistaan niiden massan ja varauksen suhdeluvun avulla. Molekyyliluonteiden tunnistaminen on Lehtosen mukaan metabolomiikan viimeinen vaihe, jossa pyritään aukottomasti tunnistamaan tilastollisesti merkittävästi eroava metaboliitti kahden tai useamman tutkittavan ryhmän välillä.
Lehtonen haluaisi mallin, jossa laboratorion ja tutkimusten data olisi koneoppimisen pohjana.
”Vaikka näitä spektrejä voidaan vertailla massakirjastoissa oleviin pilkkoutumisspektreihin (tuoteionipyyhkäisyihin), niin ongelma tunnistamisessa on, että se on hyvin pitkälle manuaalista työtä. Jos siihen saisi oppivan algoritmin, joka etsii automaattisesti pilkkoutumisspektrejä ja vertaa niitä kirjaston muistissa olevaan eli malli voisi aukottomasti tunnistaa laboratorion aiempien mittausten tunnistamat yhdisteet. Se auttaisi tutkimustyössä paljonkin,” sanoo Marko Lehtonen.

Seppo Auriolan mielestä mittausdataa pitäisi pystyä hyödyntämään entistä enemmän. Ongelmana on datan saatavuus ja yhdenmukaisuus.
”ELIXIRissä on menossa useita toimintoja joissa pyritään yhdenmukaistamaan eri työkalujen käyttöä metabolomiikassa, jotta ne toimisivat hyvin yhteen keskenään. Myös mittausdata pyritään saamaan arkistoihin.”
Auriolan mielestä tieteellisen julkaisun lisäksi suuri osa alkuperäisestä mittausdatasta pitäisi olla muiden tutkijoiden käytössä jatkoanalyyseihin.
”Sen toinen vaihe on, mitä metadataa lisätään, minkälaista tietoa näytteistä pitää olla, kuinka ne on mitattu, kuinka valmistettu, minkälaiset tutkimusryhmät ovat olleet kyseessä. Kuinka tämä tieto kulkee mittausdatan mukana? Olennaista olisi, että kerralla suurella työllä mitattu data olisi vielä käytössä myöhempiin analyyseihin ja vertailuihin.”
Toinen haaste on käytössä olevat työkalut: kuinka poimitaan yhdisteitä ja kuinka niitä tunnistetaan, mitä ohjelmistoja tarvitaan kun lasketaan tuloksia, etsitään molekyylejä ja vertaillaan niiden määriä eri näytteissä. Kuinka asiat esitetään? Kuinka muutokset eri metaboliittien tasossa saadaan, kuinka ne löydetään metaboliittikartalta, missä metaboliareiteillä yhdisteet ovat ja mitenkä niiden pitoisuudet keskenään vaihtuvat? Miten tämä kuvataan selkeästi ja miten se tulos esitetään? Kaiken tämän yhdenmukaistamiseen tarvitaan työtä. Nyt tämä kaikki data ja työkalut on pieninä palasina eri ihmisten ohjelmistoissa.” sanoo Auriola.
Ari Turunen
8.4.2020
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Seppo Auriola, Marko Lehtonen, & Tommi Nyrönen. (2020). Metabolomics measures and analyses metabolic changes caused by illness, diet or medication. https://doi.org/10.5281/zenodo.8131264
Lisätietoja
LC-MS Metabolomiikkakeskus
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Tutkija Raju Gudhe on keskittynyt yhdistämään tietojenkäsittelytieteen älykkäisiin järjestelmiin. Hän kehittää syväoppimisalgoritmeja rintasyövän riskien analysoimiseen käyttämällä radiologista ja kliinistä dataa. Näitä algoritmeja on opetettu hyödyntämään massiivisia datajoukkoja, joita on saatu Kuopion yliopistollisesta sairaalasta, jotta ne ennustaisivat rintojen tiheyden mammografiakuvista.
”Yritämme paikallistaa kiinnostavia alueita mammografiakuvista ja luokitella kasvaintyypin saatujen tunnusmerkkien perusteella käyttämällä syväoppismisalgoritmeja, sanoo Gudhe, joka työskentelee data-analyytikkona Itä-Suomen yliopiston kliinisen lääketieteen yksikössä Kuopiossa.
Mammografia eli rintojen röntgenkuvantamistekniikka, on yksi yleisimmin käytettyjä menetelmiä varhaisen asteen rintasyövän havaitsemiseksi. Varhainen rintasyövän havaitseminen alentaa merkittäväsi kuolleisuuslukuja. Vuonna 1987 Suomi aloitti ensimmäisenä maana maailmassa maanlaajuisen syöpäseulontaohjelman. Silti mammografia ei ole täydellinen. Mammografiakuvat eivät ole erityisen tarkkoja eivätkä aina havaitse syöpätapauksia ja kuvat voivat näyttäytyä normaaleina, vaikka syöpä olisikin kyseessä.
Rinnoissa on vaihtelevia määriä rasvakudosta ja tiivistä kudosta. Tiiviimpi kudos näyttää mammogrammeissa vaaleana röntgensäteiden vaimentumisen takia. Suurin osa rintasyövistä esiintyy tiiviissä kudoksessa, jonka vaaleus peittää alleen noin 25% mammogrammeista havaituista syöpätapauksista.
“Vaaleus voi naamioida syöpien läsnäolon: se on kuin löytäisi lumimiehen sakeassa lumipilvessä”, sanoo Gudhe.
Tiiviin kudoksen kuvioiden ja jakautumisen perusteella radiologit luokittelevat rinnat joko “tiheisiin” tai “rasvaisiin”. Naisilla, joilla on erittäin tiheää rintakudosta, on suurempi riski saada rintasyöpä.

Tutkijat Itä-Suomen yliopistossa ja Kuopion yliopistollisessa sairaalassa ovat kiinnostuneita kehittämään täysin automaattisen mallin arvioimaan rinnan tiheyttä. Rinnan tiiviys, yksi vahvimpia riskitekijöitä rintasyövässä, on mittaustulos tiiviin kudoksen suhteellisesta osuudesta. Tarkka tiiviin kudoksen segmentointi mammografiakuvassa voi vähentää väärien diagnoosien todennäköisyyttä.
Itä-Suomen yliopistossa kehitetyt algoritmit voivat auttaa radiologisteja arvioimaan rinnantiheyden tarkasti. Merkittävin haaste syväoppimisen malleja käytettäessä on massiivinen datan määrä, jota ne tarvitsevat. Lisäksi lääketieteessä hankittuihin kuviin liittyvät tarkat kuvailutiedot, annotaatiot, lisäävät datan kompleksisuutta.
“Käytämme tuhansia mammografiakuvia, jotka kokeneet radiologit ovat manuaalisesti annotoineet, jotta saataisiin luotua tarkat opetusjoukon luokittelut (ns. ground truth label) syväoppimisen malleihimme. Olemme kehittäneet uudenlaisen arkkitehtuurin, joka perustuu U-Net -malliin, huippuluokan ratkaisuun lääketieteellisten tiiviin kudoksen kuvien segmentoimiseen,” sanoo Gudhe.

Koska mammografiakuvat ovat korkearesoluutioisia, suurta laskentatehoa tarvitaan niihin yhdistettyjen syväoppimisen mallien opettamiseen. Suomen ELIXIR -keskuksen CSC:n palveluja käytetään sensitiivisen datan tehokkaaseen käsittelyyn ja mallien opettamiseen CSC:n grafiikkaprosessoreja.

Raju Gudhe korostaa, että kestävän mallin tekemiseksi kliinisille toimenpiteille tutkijoiden täytyy integroida erilaisia kuvantamismuotoja ja muita kliinisiä yksityiskohtia algoritmeihinsa. Näitä ovat – mammografiakuvien lisäksi – ultraääni ja magneettiresonanssikuvantaminen. Seuraava askel on integroida kuvantamisdata ja genomidata syöpäriskin analysoimiseen.
“Mammografiakuvia käyttämällä voimme tunnistaa rinnan tiheyden ja tiheysarvojen perusteella voimme saada aikaan seuraavan kuvantamistavan. Emme voi nojata yhteen kuvien kuvantamistapaan, mikä on syynä, että tietoa ei voi käyttää suoraan kliinisessä työssä. Jotta saisimme päästä-päähän mallin, joka pystyy tekemään hyvän luokittelun ja ennusteen, tarvitsemme myös genomidataa.”
Ari Turunen
1.3.2020
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Tommi Nyrönen, & Raju Gudhe. (2020). Deep learning algorithms help in breast cancer screening. https://doi.org/10.5281/zenodo.8131233
Lisätietoja:
Lääketieteen laitos, Itä-Suomen yliopisto
https://www.uef.fi/fi/web/laake
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Metabolomiikka tutkii elimistön aineenvaihduntatuotteita, niiden rakennetta ja toimintaa soluissa, veressä ja eritteissä. Olennaista on selvittää aineenvaihduntatuotteiden eli metaboliittien merkitystä ja vaikutusta ihmisen hyvinvointiin ja terveyteen. Soile Rummukainen tutkii koirien ja ihmisten syöpiä metabolomiikan avulla. Tavoitteena on tunnistaa syövän hajun molekyylit.
Koirien hajuerottelukoulutukseen erikoistuneen Wise Nosen eli Suomen hajuerottelu ry:n toiminnanjohtaja Susanna Paavilainen huomasi, että hänen Kössi-koiransa haisteli toisesta koirasta tiettyä kohtaa sen iholla. Paavilainen huomasi, että jotain on vialla. Lopulta paljastui, että toisella koiralla oli iensyöpä. Paavilainen päätteli, että koulutettu koira voisi hajuaistinsa avulla havaita lajitovereiltaan syövän.
Monitieteinen tutkimushanke käynnistyi Helsingin yliopiston eläinlääketieteellisen tiedekunnan, Wise Nosen, Aqsens Health Oy:n ja Itä-Suomen yliopiston välillä. Ensin koirat koulutettiin tunnistamaan koirien nisäsyövän merkkiaineita virtsanäytteistä. Testien mukaan hajukoirien tulokset olivat hyviä ja syöpäsairauksien havaitsemisaste oli lähes 100 prosenttia Nyt tätä menetelmää aletaan laajentaa miesten eturauhassyövän ja naisten rintasyövän havaitsemiseen.
Koirien hajuaisti on erinomainen. Keskikokoisella koiralla on jopa 220 miljoonaa hajureseptoria nenässään, kun ihmisellä on vain 5 miljoonaa. Koirat haistavat tuhansia kertoja paremmin kuin ihmiset. Orgaanisten aineiden tunnistamiseen käytettävä massaspektrometri tarvitsee yleensä noin kymmenen miljardia molekyyliä, ennen kuin mitään näkyy mittauksissa. Koira voi haistaa sairauden huomattavasti pienemmästä määrästä. Itä-Suomen yliopiston mittauksissa Kössi-koiralle riitti näyte, jossa oli vain kymmenen molekyyliä.

Aineenvaihduntatuotteet eli metaboliitit ovat yhdisteitä, joilla on pieni molekyylipaino ja jotka osallistuvat erilaisiin toimintoihin solujen aineenvaihdunnassa. Näitä pieniä molekyylejä ei voi nähdä eikä havaita suoraan, vaan tarvitaan mittalaitteita, kuten massaspektrometrejä, joiden tuottamia signaaleja analysoidaan.
Itä-Suomen yliopiston farmasian laitoksen nuorempi tutkija Soile Rummukainen tutkii Kuopiossa koirien haistamia ja löytämiä syöpänäytteitä massaspektrometrilla.
“Tarkastelemme näitä syöpänäytteitä ja kontrolliryhmän näytteitä käyttämällä ensin kohdentamattoman metabolomiikan menetelmää. Massaspektrometrin avulla näemme virtsanäytteiden aineenvaihduntatuotteista kymmeniä tuhansia molekyylipiirteitä. Tilastotieteen avulla vertailemme ryhmien välisiä eroja ja pyrimme tunnistamaan mielenkiintoisimmat metaboliitit eli ne, jotka eroavat ryhmien välillä.”
Massaspektrometrin ja nestekromatografian avulla näytteestä voidaan erottaa siinä olevat yhdisteet ja muodostaa niille kullekin massaspektri. Massaspektrin piikkien sijainnista (x-akseli) käy ilmi molekyyleistä muodostuneiden ionien massa ja piikkien korkeudesta (y-akseli) niiden suhteellinen runsaus. Molekyylin pilkkoutumistuotteista voidaan puolestaan päätellä molekyylin rakenne. Nestekromatografia (LC) yhdistettynä massaspektrometriaan (MS) on tehokas analyysitekniikka metaboliittien määritykseen. LC-MS -menetelmiä käytetään paljon lääketutkimuksessa sekä kliinisessä diagnostiikassa.
Rummukaisen mukaan metabolomiikassa molekyylien tunnistaminen on haastava osa-alue. On pystyttävä tunnistamaan pilkkoutumisspektriä vastaava molekyylirakenne. Pilkeioneja verrataan maailmanlaajuisiin tietokantoihin ja niiden spektrikirjastojen kokoelmiin sekä omiin standardeihin.
”Oma standardi-kirjastomme on täällä yliopiston laitteilla analysoitujen standardien kokoelma. Niiden avulla saamme tarkimman tunnistuksen metaboliiteille, koska ne on analysoitu samalla menetelmällä ja antavat myös tunnistukselle tärkeän retentioaikatiedon. Oma kirjastomme on kuitenkin kooltaan rajallinen, joten työssä on käytettävä myös muita tietokantoja.”
Retentioaika tarkoittaa aikaa, joka yhdisteeltä kuluu kulkiessa kromatografialaitteiston läpi detektorille.
”Biologisessa näytteessä voi olla on tuhansia aineenvaihduntatuotteita. Kun näyte analysoidaan massaspektrometrilla, saadaan dataa, joka antaa kymmeniä tuhansia molekyylipiirteitä. Nämä piirteet täytyy sitten yhdistää molekyyleiksi. Tarkan massan, pilkkoutumisspektrien ja retentioajan avulla näytteestä saadaan tunnistettua keskimäärin sadasta kahteensataan metaboliittia, mikä on aika pieni määrä.”

Koirat tulevat nyt taas avuksi. Seuraavaksi tehdään fraktiointeja eli näytteistä otetaan osanäytteitä. Sitten käydään uudestaan testaamassa koirilla, onko haju vieläkin osanäytteissä.
Suurin työ on Rummukaisen mukaan fraktioiden tekemisessä ja analysoinnissa.
”Jatkossa tutkimme näitä osanäytteitä ja analysoimme tarkemmin niiden sisältämiä yhdisteitä käyttäen massaspektrometrisiä menetelmiä ja ydinmagneettista resonanssispektroskopiaa (NMR). Tavoitteenamme on hajukoirien ja koirien nisäsyöpänäytteiden avulla kehittää menetelmä, jota hyödynnetään myös ihmisten syöpään liittyvien metaboliittien määrittämiseen.”
Koiria koulutetaan tällä hetkellä haistamaan eturauhassyöpää ja rintasyöpää. Myös datan käsittely on tärkeää. Massaspektrometrin raakadatan käsittely tarvitsee paljon laskentakapasiteettia ja levytilaa.
”Yksittäinen metaboliitti voi liittyä kymmeniin solunsisäisiin signaalireitteihin. Tässä tarvittaisiin avuksi tietokonesimulointia, jotta löydettyjen muutosten biologinen merkitys avautuisi paremmin. Myös genomiikan ja proteomiikan antaman tiedon yhdistäminen metabolomiikkaan olisi mielenkiintoista, kunhan tarvittavat ohjelmistot ja työkalut tulevaisuudessa kehittyvät. ”
Ari Turunen
6.2.2020
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Soile Rummukainen, & Tommi Nyrönen. (2020). A dog can smell diseases. https://doi.org/10.5281/zenodo.8131208
Lisätietoja:
LC-MS Metabolomiikkakeskus, Itä-Suomen yliopisto
http://www.uef.fi/fi/web/metabolomics-center
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

ELIXIR on rakentanut tutkijoille monipuolisen laskenta-alustan, jossa on useita tutkijoille tärkeitä palveluja. Käyttöluvan saatuaan tutkija voi alustalla hyödyntää laskennan lisäksi useita datalähteitä sekä tallentaa, siirtää ja analysoida dataa. Kaikki palvelut yhdistyvät saumattomaksi työnkuluksi.
ELIXIR Compute Platform (ECP) rakennettiin vuosien 2015-2019 aikana biolääketieteiden tarpeisiin. ECP on maantieteellisesti hajautettu alusta, jossa ELIXIR keskukset toimivat yhdessä biologisen tiedon hallinnan palveluiden tuottamiseksi. Keskukset toimivat itsenäisesti, mutta niitä yhdistää käyttäjien tunnistaminen ja valtuutus (AAI), jolla pilvipalvelut ja laskenta sekä tallennus- ja tiedostonsiirtopalvelut voidaan koordinoida. Tutkija kirjautuu järjestelmään, joka tunnistaa tutkijan sähköisen identiteetin ja samalla antaa eri tasoisia käyttöoikeuksia biolääketieteelliseen dataan. Tutkijat voivat tämän jälkeen luoda tietoturvallisen analyysiympäristön käyttämilleen ohjelmistoille. Data on eurooppalaisella pilvilaskenta-alustalla. Käyttöympäristö myös auttaa tutkijaryhmiä luomaan skaalautuvia palveluja.
Tuhannet tutkimuslaboratoriot tuottavat massiivisia määriä dataa. Datan monimutkaisuus myös kasvaa, mikä on suuri haaste. Dataa pitää hallinnoida siten, että kaikki käyttäjät ymmärtävät ja käsittelevät sen samalla tavalla. Tehokas datanhallinta edellyttää federaatiota, jolla on hallussaan infrastruktuuri, jossa käyttäjä pääsee siirtämään, vaihtamaan, käsittelemään ja analysoimaan dataa. Siksi ECP kehitettiin yhteistyössä eri ELIXIR-keskusten ja eurooppalaisten tutkimusinfrastruktuurien kanssa. ECP:n tutkijoille tarkoitetut palvelut rakennettiin yhteistyössä neljän eri tieteellisen käyttäjäyhteisön kanssa. Näitä olivat merien mikrobien, viljely- ja metsäkasvien, ihmisten geenien ja harvinaisten sairauksien tutkijat.
ECP:ssä olevia palveluja tarjoavat eri ELIXIR-keskukset. ELIXIRin AAI-palvelu (Authentication and Authorisation Infrastructure) mahdollistaa sen, että käyttäjien tunnistaminen ja käyttöoikeuksien myöntäminen on sähköistä. Pääsystä dataan päättää aina datan tai laskentapalvelun omistaja, mutta AAI:n avulla pääsy dataan nopeutuu ja datan käyttöpolitiikka ja analysointi on selkeää ja suoraviivaista käyttäjälle.

Datan siirtoon käytetään suuritehoista verkkoa ja ohjelmistojen avulla sen päälle rakennettuja rajapintoja, eräänlaisia dataputkilinjoja (data pipeline). Niillä hoidetaan datan siirto paikasta toiseen sekä datan prosessointi ja analysointi. Datavirrat jaetaan pienempiin osiin ja niitä prosessoidaan rinnakkain, jolloin saadaan lisää laskentatehoa ja siirto tapahtuu ilman pullonkauloja ja viiveitä. Analyysejä voidaan suorittaa hajautetusti. Jos data on sensitiivistä tarvitaan tietoturvafederaatiota.
ECP:ssä oli vuonna 2019 käytössä 50 000 teratavua tallennuskapasiteettia. Se tarjosi 80 000 erillistä laskentaydintä, prosessointia tekevää yksikköä. Vuodesta 2017 vuoteen 2019 tallennuskapasiteetti kaksinkertaistui ja hajautetun laskennan resurssit lisääntyivät 33%. Vuonna 2019 ECP:llä oli 3100 käyttäjää.

Mikrobiyhteisöt vaikuttavat ihmisten ja eläinten elämään ja ovat tärkeitä eri ekosysteemeille. Kuitenkin vain pieni osa mikrobeista on luokiteltu ja analysoitu. Mikrobiyhteisöjen genetiikan tutkiminen on synnyttänyt uuden biotieteen alan, metagenomiikan. Joukko ympäristöstä noukittuja ja sekvensoituja geenejä voidaan analysoida samalla tavoin kuin yksittäisen lajin genomia eli perimää.
Valtameret ovat maailman suurin yhtenäinen ekosysteemi. Planktonin merkitys maailman ilmastolle on vähintään yhtä merkittävä kuin sademetsien. Kuitenkin vain pieni osa niistä organismeista, jotka luovat tämän ekosysteemin, on luokiteltu ja analysoitu. Planktoneiden muodostamat ekosysteemit sisältävät valtavasti elämää: yli 10 miljardia organismia on jokaisessa litrassa valtameren vettä sisältäen viruksia, prokaryootteja, yksisoluisia eukaryootteja ja polttiaiseläimiä. Nämä ainutlaatuiset organismit sisältävät bioaktiivisia yhdisteitä, joille on käyttöä lääketeollisuudessa, elintarvikkeina, kosmetiikassa, bioenergiassa ja nanoteknologiassa. Vuosina 2009-2013 kansainvälinen tutkimusmatka Tara Oceans keräsi 210 mittauspaikasta maailman valtameristä 35 000 biologista näytettä. Se on laajin planktonista kerätty kokoelma.
ELIXIR rakensi pysyvän julkisen datavarannon, jotta voitaisiin parantaa merestä saatujen metagenomiikkanäytteiden tunnustamista ja kartoitusta. Tunnistamiseen tarvittavat työkalut ja datan prosessoinnin dataputket tehtiin mahdollisiksi siirtää eri alustoille. Näin voidaan saada käyttöön uusia biokemiallisia materiaaleja, kuten entsyymejä ja lääkeainemolekyylejä. Työkaluja ja dataputkia voidaan käyttää eri ELIXIR-keskusten (Norja, EMBL-EBI, Suomi, Tsekki, Ranska) kautta.

Euroopan genomiarkisto EGA on yksi maailman laajimmista julkisista datavarastoista, joihin on tallennettu potilasdataa biolääketieteellisistä projekteista. Arkistoon on tallennettu erilaisia tietoaineistoja eri datan tuottajilta. EGA tallentaa ihmisistä kerättyä geno- ja fenotyyppidataa erikseen kysyttävällä suostumuksella. ELIXIR Compute Platform mahdollistaa EGA:ssa olevan luottamuksellisen ihmisdatan siirtämisen luvan saaneille yksittäisille käyttäjille.
ECP:n kautta tutkijat voivat hakea pääsyoikeutta EGA:n sensitiivisiin datakokoelmiin. Ensin käyttäjä tunnistetetaan sähköisesti, ja pääsyoikeus joko hyväksytään tai hylätään hakulomakkeen tietojen perusteella. Jos palvelu edellyttää monivaiheista tunnistautumista, käyttäjä uudelleenohjataan tunnistuspalveluun, joka suorittaa ylimääräisen tunnistuksen käyttämällä toista turvatekijää.
Tutkijoilla on sen jälkeen pääsy EGA:n datavarastoihin ja he voivat prosessoida sensitiivistä dataa. ECP:n kautta tutkijat voivat myös tallentaa dataa EGA:n arkistoon. ECP:n ansiosta voidaan varmistaa datan kuvailu, pääsy dataan ja yhteentoimivuus. Jotta data siirtyy turvallisesti, luotiin arkkitehtuuri, jossa on käytössä kaksi protokollaa. Oauth.2.0 ja OpenID Connect (OIDC) ovat teollisuuden käyttämiä käyttäjäntunnistusprotokollia.

FAO:n mukaan kasvitaudit aiheuttavat vuosittain maailman ravinnontuotantoon noin 20-40% leikkauksen. Massiivinen viljely- ja metsäkasvien sekvensointi mahdollistaa kasvitautien aiheuttajien tutkimisen. Kasvien sekvensointi ja genotyypitys mukaan lukien patogeenit ja taudit tuottavat laajoja määriä perinnöllistä vaihteludataa. EURISCO (European Search Catalogue for Plant Genetic Resources ) sisältää informaatiota 1,9 miljoonasta viljelykasvista ja sen villeistä sukulaisista. Näytteet on kerätty lähes 400 eri organisaatioon.
ECP mahdollistaa genotyyppi-fenotyyppi-analyysin viljelykasveille perustuen laajimpiin saatavilla oleviin julkisiin datavarantoihin. Tämä data on tuotu yhteen maantieteellisesti eri paikoissa sijaitsevista tutkimuslaitoksista. Keskeinen toiminnallisuus on hakurobotti, joka vastaanottaa hakuja käyttäjiltä ja siirtää integroidut, eri datalähteistä kerätyt hakutulokset takaisin käyttäjälle. Käyttäjät voivat siirtää valitun datan pilvi-infrastruktuuriin analyyseja varten.

Noin 30 miljoonaa ihmistä 25 EU-maassa sairastaa jotakin harvinaista tautia, arvioi EURORDIS (European Organisation of Rare Diseases). Se tarkoittaa 6-8% koko EU:n asukkaista. Kansainvälinen harvinaisten tautien tutkimuskonsortio on asettanut tavoitteeksi kehittää 200 uutta hoitomuotoa harvinaisille taudeille vuoteen 2020 mennessä.
ELIXIR julkaisi kustomoidun kokoelman työkaluja ja palveluja, joiden tarkoitus on auttaa uusien hoitomuotojen kehittämisessä. Kokoelma on saatavilla ELIXIR biotools-palvelun kautta (bio.tools). Harvinaisten tautien tutkijat voivat jättää sisään raakadatan, ajaa geenikartoituksen ja noukkia gvcf-tiedostot (genomic variant call format) analyysiä varten. Se määrittelee bioinformatiikassa käytetyn tekstitiedoston, kun geenisekvenssivariaatioita tallennetaan.
Potilaaseen liittyvä metadata (sairauden, hoidot, hoitotulokset), potilasnäytteet biopankeissa ja kaikki EGA:n data on haettavissa ECP:n kautta.
Ari Turunen
2.12.2019
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, & Tommi Nyrönen. (2019). ELIXIR Compute Platform for life and health sciences. https://doi.org/10.5281/zenodo.8131182
Lisätietoja:
Kataja, Teemu (2018): Designing and developing a data processing pipeline for archiving sensitive human data.
https://www.theseus.fi/handle/10024/142007
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Jotta tutkija pääsisi eri tutkimusinfrastuktuurien digitaalisiin palveluihin, hänen henkilöllisyytensä ja suhteensa tutkimusorganisaatioonsa tulee todentaa. Tähän asti todentaminen on edellyttänyt henkilökohtaista käyntiä rekisteröintipisteessä, jossa hänen henkilöllisyystodistuksensa tarkistetaan. Suomessa on testattu uutta ratkaisua vahvalle sähköiselle tunnistamiselle, joka ei edellytä pistäytymistä rekisteröintipisteessä.
Todentamisella ja ensitunnistuksella varmistetaan, että henkilö on se, joka väittää olevansa. Tällä hetkellä tutkijat voivat käyttää kotiorganisaationsa käyttäjätunnuksia kirjautuessaan infrastruktuurien palveluihin. Kirjautuminen esimerkiksi sensitiivistä dataa sisältäviin palveluihin edellyttää kuitenkin luotettavampaa ensitunnistamista, jollaista ei ole käytössä kaikissa kotiorganisaatioissa.
”Perinteisesti ensitunnistamista pidetään luotettavana, jos henkilö joutuu käymään kasvotusten rekisteröintipisteessä, jossa koulutettu henkilökunta tarkistaa hänen passinsa tai muun viranomaisen myöntämän tunnistamisasiakirjan.”, sanoo vanhempi sovellusasiantuntija Mikael Linden CSC:stä.
ELIXIRin Suomen keskus CSC, yhdessä n kanssa, on jo pitkään kehittänyt infrastruktuurille autentikointipalveluja. ELIXIRin AAI-palvelu (Authentication and Authorisation Infrastructure) mahdollistaa sen, että käyttäjien tunnistaminen ja käyttöoikeuksien antaminen on sähköistä. Pääsystä esimerkiksi geenidataan päättää aina datan omistaja, mutta AAI:n avulla pääsy dataan nopeutuu.
AAI-palvelu on tehokas, mutta edellyttää tutkijan luotettavaa tunnistamista. Yleensä yksinkertainen ja hallinnollisesti ketterä ratkaisu on federoitu käyttäjäidentiteetin hallinta. Tällöin yhdellä tunnistautumisella ja oman kotiorganisaation käyttäjätunnuksella tutkijat saavat pääsyn organisaationsa ulkopuolella oleviin palveluihin, myös tarkoin suojeltuihin datakokoelmiin. Entä jos kotiorganisaatio ei pysty varmistamaan riittävän luotettavaa tunnistamista?
CSC on tehnyt yhteistyötä suomalaisen Sandbox of Trust -hankkeen kanssa, jossa on mukana muun muassa tietoturvayhtiö Nixu. Hankkeessa on kehitetty SisuID -tunnistusratkaisu, jonka tarkoituksena on tuoda käyttäjäystävällisempi vaihtoehto salasanoille sekä vahvaan kaksivaiheiseen tunnistamiseen. Tunnistusvälineenä käytetään ensi vaiheessa mobiilitunnistussovellusta, jonka myöntövaiheessa henkilölle luodaan myös yksilöivä sähköinen identiteetti. Näiden yhdistelmä mahdollistaa myös henkilötiedon luotettavan siirtämisen palveluiden välillä, henkilön omalla suostumuksella.
”ELIXIR:n tyyppisessä tutkimusinfrastruktuurissa ensitunnistamisen rekisteröintipisteiden verkostosta tulisi kallis ja loppukäyttäjälle kömpelö. SisuID -konseptissa ensitunnistus nojaakin siihen, että käyttäjä itse skannaa passinsa ja ottaa itsestään valokuvan SisuID -matkapuhelinsovelluksella, joka tarkistaa, että ne täsmäävät,” sanoo Mikael Linden.

SisuID on avoimen lähdekoodin tunnistustapa, jota on kokeiltu viidessä eri pilottihankkeessa. Nixun digitaalisen liiketoiminnan johtaja Joonatan Henrikssonin mukaan nyt on kokeiltu eri tapoja todentaa ja tunnistaa luotettavasti suomalainen sekä ulkomainen henkilö.
”Suomessa vahva sähköinen tunnistaminen on mahdollista toteuttaa tällä hetkellä esimerkiksi pankkitunnuksilla, mutta ulkomaalaisten tutkijoiden osalta niitä ei voida hyödyntää eikä kaikissa maissa ole kansallista vahvaa tunnistautumistapaa,” sanoo Nixun digitaalisen liiiketoiminnan johtaja Joonatan Henriksson.
Henrikssonin mukaan testatussa rajat ylittävässä ratkaisussa ensin tunnistettava henkilö ottaa mobiililaitteellaan passistaan tai henkilökortistaan kuvan sekä itsestään kasvokuvan. Näitä vertaillaan algoritmisesti keskenään.
”Lisäksi vertailussa voidaan käyttää henkilöllisyystodistuksen myöntäjämaan rekistereitä sekä mm. Interpolin väärennettyjen henkilöllisyystodistusten kantoja.”
Mutta tiukempiakin kriteerejä tunnistamiseen on.
”Jos palveluntarjoajan mielestä luottamus etätunnistamisen osalta ei ole riittävä, meillä on mahdollista korottaa identiteetin luottamustasoa käyttämällä henkilö kerran fyysisessä asiointipisteessä ensitunnistettavana, jonka jälkeen luotettavampi identiteetti on kaikkien SisuID:tä käyttävien palveluntarjoajien käytettävissä.”
Henrikssonin mukaan tunnistamisen kriteerit noudattavat EU:n eIDAS -asetusta. eIDAS -asetus tarjoaa tunnistuspalveluiden tarjoajille raamit, joihin esimerkiksi Suomen laki vahvasta sähköisestä tunnistamisesta perustuu. eIDAS -asetuksen avulla tunnistus- ja luottamuspalveluiden tarjoajat voivat halutessaan hakea palvelulleen viranomaishyväksyntää, jolloin tunnistusväline käy esimerkiksi rajat ylittävään valtionhallinnon asiointiin.
”Jatkossa voimme myös lukea NFC -sirulta passin myöntäjän allekirjoittaman kasvokuvan, sekä ottaa liveness -videon kasvoista, joka parantaa entisestään rekisteröidyn identiteetin sähköistä luottamustasoa.”
SisuID -ratkaisun tuottamista varten ollaan perustamassa voittoa tavoittelematonta tunnistusosuuskuntaa, joka jakaa kaikkia sektoreita palvelevan tunnistuspalvelun hyödyt, kustannukset ja riskit sitä käyttävien organisaatioiden välillä.
Kun henkilön todentaminen ja tunnistaminen pystytään hoitamaan tehokkaasti ja luotettavasti, Henrikssonin mielestä jäljelle jäävä ongelma on, että henkilöön liitetty data elää siiloissa. Tällä hetkellä pääsy esimerkiksi ELIXIRin tuottamiin palveluihin voitaisiin antaa yhdistämällä kaksi tietoa: luotettavalla tavalla rekisteröity digitaalinen identiteetti ja henkilöön liittyvät todistukset. Tutkija voi muuttaa yliopistolta saadun tutkintotodistuksen tai EU:lta saadun apurahapäätöksen sähköiseen muotoon, joka virallistaa tutkijan väitteen tutkijastatuksestaan.
”Tämä tunnistetun henkilön digitaaliseen identiteettiin liitettävä sähköinen tieto voitaisiin jatkossa välittää toimijoiden välillä esimerkiksi hajautettua luottamusta tuottavien rajat ylittävien lohkoketjuverkostojen avulla.”
Lohkoketjussa lohkoihin tallennetaan dataa. Lohkot liitetään edelliseen algoritmilla, joka luo datasta merkkijonon. Yhteen lohkoon kirjattuja tietoja ei voi muuttaa jälkikäteen, koska lohkoketju on hajautettu usealle tietokoneelle. Tämä menetelmä mahdollistaa digitaalisen luottamuksen hajauttamisen, ilman että esimerkiksi kansallisten rekisterien rajapintoja tarvitsee avata koko maailmalle. Lohkoketjun muuttumattomuus takaa luotettavan datan siirron käyttäjän itsensä toimesta, jolloin suoria integraatioita rajapintojen välillä ei tarvita. Esimerkkinä tästä on tehty EU tasolla kokeiluja European Blockchain Services Infrastructure (EBSI) -hankkeessa, muun muassa sähköisten koulutustodistusten siirrossa.
Ari Turunen
30.10.2019
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Mikael Linden, Joonatan Henriksson, & Tommi Nyrönen. (2019). No need to turn up personally: SisuID improves electronic authentication. https://doi.org/10.5281/zenodo.8131086
Lisätietoja:
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Sydän- ja verisuonitaudit ovat yleisin kuolinsyy maailmassa. Suomessa yli kolmannes kuolemista johtuu sydän- ja verisuonitaudeista. Nyt tavoitteena on saada terveysdatan perusteella arvio jokaisen sairastumisriskistä Suomessa ennen lääkärillä käyntiä.
Andrea Ganna, Suomen molekyylilääketieteen instituutin (FIMM) ryhmän vetäjän ja Harvardin lääketieteellisen koulun opettaja, haluaa perustaa maanlaajuisen yksilöllisen riskiarvioinnin, joka olisi perustana, joilla voisi suunnitella julkisen terveydenhallinnon toimenpiteitä. Arviointi perustuu kansalaisten terveys, väestö- ja geenitietoon. Arviointi, joka hyödyntää teköälyä, parantaa ehkäisevien hoitojen kohdentamista nykyistä halvemmalla kustannustasolla.
“Pohjoismailla ja erityisesti Suomella on tähän ainutlaatuinen mahdollisuus ja miljöö, sillä nämä maat ovat keränneet terveys- ja väestödataa vuosia. Mutta tapa, jolla dataa on aiemmin kerätty, on jossain määrin vanhentunut. Datasta on katsottu vain tiettyjä riippuvuussuhteita ja yhteyksiä. Kuitenkin uudet menetelmät, kuten tekoäly, ovat tulossa ja antavat mahdollisuuden suurempaan ja kunnianhimoisempaan visioon.”
Andrea Ganna ja hänen tutkimusryhmänsä kehittävät tekoälyyn (AI) perustuvia lähestymistapoja yksittäisen ihmisen terveyshistorian mallintamiseksi.
“Jokaisella henkilöllä on tietynlainen terveys- ja lääkintähistoria. Haluamme tietää, onko muilla samantyyppisiä seurantatietoja. Heitä voi olla tuhansia. Me hyödynnämme näiden ihmisten terveystietoja ja selvitämme, mitä heille tapahtui. Näin autamme alentamaan sairastumisriskiä. Voimme käyttää kaikkea tätä dataa aiempaa paljon kokonaisvaltaisemmalla tavalla auttaaksemme julkista terveyshallintoa ja antaaksemme potilaille ja lääkäreille enemmän tietoa päätöksenteon tueksi.”
Andrea Ganna on kiinnostunut epidemiologiasta, genetiikasta ja tilastotieteestä. Hän on keskittynyt hyödyntämään suuria epidemiologisia aineistoja tunnistaakseen yhteiskunnallis-väestötieteellisiä, metabolisia ja geneettisiä tunnusmerkkejä, jotka ovat yleisten ja monimutkaisten tautien taustalla. Bostonissa ollessaan hän työskenteli laajojen eksomi- ja genomisekvenssidata-aineistojen parissa.
Gannan mukaan sydän- ja verisuonitaudit sopivat täydellisesti tekoälyn tekemiin analyyseihin, koska näiden tautien hoito on ennaltaehkäisevää.
“Tarkka korkean riskin yksilöiden tunnistaminen on yksi kulmakiviä kardiometabolisten sairauksien ennaltaehkäisyssä”, hän sanoo.
”Kuitenkin tällä hetkellä kardiometabolisten sairauksien riskitekijöiden arviointi edellyttää potilailta käyntiä lääkärillä lipidimittauksessa.”
Lipidi on yleisnimitys kaikille veressä kiertäville rasvoille ja rasvan kaltaisille aineille. Keho varastoi ravinnosta saatua rasvaa tulevaan käyttöön. Runsasrasvainen ruokavalio saa rasvan kiinnittymään valtimoiden seinämiin, mistä aiheutuu sydän- ja verisuonitauteja sekä valtimotauteja. Lipidimittauksessa saadaan selville, millaisia rasvoja testattavalla on elimistössään. Lipidimittaus on tehokas, mutta ongelma on, että osa väestöstä ei tiedä kuuluvansa riskiryhmään.
Ganna haluaa mullistaa sairausten ennaltaehkäisyn tarjoamalla riskiarvioinnin potilaalle ennen kuin hän menee lääkärin vastaanotolle.
“Jotkut eivät yksinkertaisesti mene lääkärille ja paljon ihmisiä puuttuu. Mutta koska kaikki lääkitykseen ja diagnooseihin liittyvä data on jo kerätty, voimme tunnistaa korkean riskin potilaat ennen kuin he menevät lääkärille. Voimme tehdä sydän- ja verisuonitautien riskikartan koko maasta mukaanlukien kaikki yksittäiset henkilöt.”
Riskilaskelma tehdään mallintamalla sairauksien ja lääkitysten pitkittäisseurannasta saatua dataa yhdessä geeni-, perhe- ja väestödatan kanssa.
“Yritämme ymmärtää, kuinka genetiikka vuorovaikuttaa sellaisen datan kanssa, joka saadaan lääkityksistä, diagnooseista, väestöstä ja perheestä. Tämä voi antaa ennennäkemättömän kokonaisvaltaisen näkökulman yksilön terveydentilaan.”
Ganna antaa esimerkin.
“Kun katkaiset jalkasi, menet lääkärille. Kuitenkin tänä päivänä lääkäri katsoo vain jalkaasi, vaikka samalla käynnillä voisit saada hyötyä myös muusta tiedosta. Me voimme informoida lääkäriä muista riskeistä, joita potilaalla on perustuen kerättyyn dataan. Voimme laskea ennalta potilaan muut riskit, kuten esimerkiksi, jos hänellä on korkea riski sydän- ja verisuonisairauksiin. Siten, samalla käynnillä, lääkäri voi myös antaa neuvoja tai ohjata potilaan asiantuntijalle.”

Ganna päätti tulla Suomeen laajan geeniprojektin, FinnGenin takia.
Elokuussa 2017 alkaneessa projektissa taltioidaan puolen miljoonan suomalaisen genomit. Hankkeessa hyödynnetään kaikkien suomalaisten biopankkien keräämiä näytteitä. Perimästä saatava data yhdistetään kansallisissa terveydenhuollon rekistereissä olevaan tietoon. FinnGen on yksi ensimmäisiä näin laajassa mittakaavassa tehtyjä erittäin yksilöllistettyjä lääketieteen projekteja. Julkisten ja yksityisten organisaatioiden yhteistyö on poikkeuksellista.
“Suomessa on sopiva lainsäädäntö, joka antaa pääsyn maanlaajuiseen populaatiodataan. Minulle tämä on ainutlaatuinen kattaus.”
Ganna ja hänen tutkimusryhmänsä integroivat rekistereissä olevan tiedon ja biopankkeihin tallennetun laajan tutkimustiedon auttaakseen tunnistamaan yksilöryhmiä, jotka voisivat eniten hyötyä olemassaolevista farmakologisista toimenpiteistä.
“Ehkä tärkein ryhmä on nuoret yksilöt jotka eivät käy lääkärissä kovinkaan usein. Nykyiset riskitekijät eivät toimi hyvin tässä ryhmässä. Genetiikka on erityisesti arvokasta, koska sen avulla voidaan löytää sairastumisen riskitekijät aikaisemmalla iällä verrattuna muihin riskitekijöihin. Ensimmäinen askel on ymmärtää, miten ihmiset hahmottavat tämän tiedon. Meidän täytyy varmistaa että lääkärit käyttävät dataa oikealla tavoin ja mitä sillä voidaan tehdä.”

Gannan tavoitteena on integroida kansalliset ja alueelliset rekisterit syvä- ja koneoppimiseen.
“Perinteisillä menetelmillä on etunsa, sillä ne ovat suhteellisen yksinkertaisia ja helppoja tulkita, mutta ne eivät skaalaudu. Viimeisten 20 vuoden aikana yli 500 miljoonaa lääketieteellistä diagnoosia on tehty suomalaisista. Puhumme valtavista datajoukoista. Joka vuosi tehdään miljoonia uusia lääkemääräyksiä ja diagnooseja. Tämän skaalaamiseksi ja hyödyntämiseksi tarvitaan syväoppimisen menetelmiä.
Keinotekoiset neuroverkot ovat tehokkaita koneoppimisen algoritmeja, joita voidaan hyödyntää hahmontunnistamisessa. Takaisinkytkeytävät neuroverkot (recurrent neural network) voivat hyödyntää niiden sisäistä muistia syötejonojen käsittelyssä. Tämä tekee niiistä soveltuvia sellaisiin tehtäviin, kuten segmentoitumattomaan tunnistamiseen. Ganna haluaa laajentaa nämä neuroverkot käyttämäänsä dataan.
”Voidaan ajatella, että terveydentilaa kuvaavien tapahtumien muutosjono, jota yritämme mallintaa, on ”tekstiä”, jossa jokainen sana on erilainen koko elämän aikana ollut tauti, lääkitys, väestötieteellinen tapahtuma jne. Nämä ovat luonnollisesti sovitettu mallintamaan muutosta kuvaavaa tapahtumaketjua, esimerkiksi niitä käytetään ennustamaan seuraavaa todennäköisintä sanaa tekstiviestissä.”
Syväoppimisen menetelmät edellyttävät suurta supertietokoneinfrastruktuuria.
”CSC on luonut turvallisen ympäristön laskentaan. Ilman turvallista superlaskennan ympäristöä, emme voisi toteuttaa tätä projektia. Onnistuaksemme me tarvitsemme yhtäältä tutkimusta ja kehitystyötä ja toisaalta tehokasta laskentaympäristöä.”
Potilasdata on tärkeää tutkimukselle, mutta henkilökohtainen data on myös suojeltua. Esimerkiksi Suomen molekyylilääketieteen instituutissa kehitetty VEIL.AI anonymisoi potilasdatan perinteisiä menetelmiä tehokkaammin, nopeammin ja informaatiota paremmin säilyttäen. Tarvittaessa sovelluksen avulla voidaan tuottaa myös synteettistä, täysin anonyymia eli siis yksittäisestä henkilöstä erillään olevaa tilastollista dataa.
“Meillä on tarve taata yksilöiden yksityisyys, mutta samalla meidän täytyy integroida paljon henkilökohtaista dataa, jotta voisimme todella hyötyä tekoälystä ja syväoppimisen lähestymistavoista ja jotta voisimme kohdentaa tulokset parempiin julkisen terveydenhuollon toimenpiteisiin. Luomalla synteettisiä terveystiedon historioita autetaan kunnioittamaan yksityisyyttä, mutta samaan aikaan pystytään yhdistämään paljon persoonakohtaista tietoa ei pelkästään Suomessa vaan Pohjoismaiden välillä.”
“Toivon, että rutiininomaisesta terveydenhuollossa kerätty persoonakohtainen data voi auttaa ja hyödyntää kaikkia. Toivon, että tämä tieto voi auttaa lääkäreitä tekemään parempia päätöksiä ja myös motivoimaan potilaita elämäntapamuutoksiin. Siten kaikki auttavat kaikkia.”
Ari Turunen
30.9.2019
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Andrea Ganna, & Tommi Nyrönen. (2019). Risk assessment of cardiovascular diseases for all citizens. https://doi.org/10.5281/zenodo.8131074
Lisätietoja:
FIMM
Suomen molekyylilääketieteen instituutti (FIMM) on kansainvälinen tutkimuslaitos, jonka toiminta keskittyy sairauksien molekyylitason mekanismien selvittämiseen genetiikan ja lääketieteellisen systeemibiologian menetelmin. Tavoitteena on tutkimustiedon siirtäminen terveydenhuollon käyttöön mm. henkilökohtaista lääketiedettä edistämällä.
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Life Science AAI pyrkii tekemään sisäänkirjautumisen ja pääsyn tarjolla oleviin palveluihin mahdollisimman yksinkertaiseksi.
ELIXIR on luonut helppokäyttöisen ja tietoturvallisen käyttäjäidentiteetin hallinnan, jonka avulla pääsee nopeasti lukuisiin datakokoelmiin ja palveluihin. Palvelua kehitetään ja laajennetaan muiden tutkimusinfrastruktuurien kanssa, jotta tutkijat saisivat käyttöönsä myös biopankkien tarjoamia tai koe-eläimistä kerättyjä aineistopalveluita.
Tutkijoiden tarvitsemat tietoaineistot ja tutkimusinstrumentit ovat saatavilla lukuisissa tutkimusinfrastruktuureissa. Vaikka kansainvälinen yhteistyö tutkimuksessa on tehostunut ja nopeutunut huomattavasti viimeisen vuosikymmenen aikana, tutkija joutuu kuitenkin käytännön työssä selvittämään erilaisia byrokraattisia prosesseja. Pääsy tutkimuksen tuottamiin aineistoihin edellyttää usein käyttäjän tunnistamisen sekä käyttöluvan myöntämistä. Jos jokainen datakokoelma vaatii oman salasanansa ja käyttäjätunnuksensa, niiden hallinnoiminen alkaa olla yksittäiselle käyttäjälle liian hankalaa. Salasanaviidakosta täytyy löytyä tie ulos vaarantamatta palvelun tietoturvaa tai käyttäjän omia oikeuksia, jotka ovat osa EU:n tietoturva-asetusta (GDPR). ELIXIR-tutkimusinfrastruktuurissa lähtökohtana on mahdollistaa datakokoelmien helppo käyttö tinkimättä kuitenkaan tietoturvasta.
ELIXIRin AAI-palvelu (Authentication and Authorisation Infrastructure) mahdollistaa sen, että käyttäjien tunnistaminen ja käyttöoikeuksien kommunikointi on sähköistä. Pääsystä dataan päättää aina datan omistaja, mutta AAI:n avulla pääsy dataan nopeutuu ja datan käyttöpolitiikka tehdään selkeäksi ja suoraviivaiseksi.
Yksinkertainen ja hallinnollisesti ketterä ratkaisu on federoitu käyttäjäidentiteetin hallinta. Tällöin yhdellä tunnistautumisella ja oman kotiorganisaation käyttäjätunnuksella tutkijat saavat tietoturvallisen ja luotettavan pääsyn myös tarkoin suojeltuihin datakokoelmiin.
Federaatiot antavat tutkijoille mahdollisuuden käyttää kotiorganisaatioidensa käyttäjätunnuksia. Niillä pääsee palveluihin, jotka ovat heidän organisaatioidensa ulkopuolella. Federoinnin ideana on hallinnoida, miten käyttäjien identiteettejä välitetään organisaatiorajan ylittävässä tunnistuksessa. Tähän identiteettiin voidaan liittää erilaisia ja eri tasoisia käyttöoikeuksia, jolloin varmistetaan, että oikea käyttäjä pääsee oikeisiin resursseihin oikeasta syystä.
Federoitu käyttäjähallinta ei ole uusi keksintö. Sitä on käytetty menestyksekkäästi esimerkiksi Suomen korkeakoulujen Haka-luottamusverkostossa. Haka-luottamusverkostossa on yli 300 erilaista palvelua ja sillä on yli 300 000 käyttäjää.
Vuonna 2004 eri federaatiot yhdistävä eduGAIN-projekti alkoi EU:n rahoittamana. Huhtikuussa 2011 siitä tuli pysyvä palvelu, joka yhdistää tutkimuksen identiteettifederaatiot ympäri maailmaa. eduGAIN liittää yhteen yli 50 federaatiota, jossa on 5000 organisaatiota. Se on avoinna kaikille akateemisille federaatioille maailmassa ja mahdollistaa luotettavan käyttäjän tunnistamisen luottamusverkostojen jäsenten välillä.

ELIXIR AAI -palvelu otettiin käyttöön marraskuussa 2016. Se kuuluu osana ELIXIRin laskenta-alustaan (Compute Platform) yhdessä pilvi- ja datan siirtopalveluiden kanssa. Vuoden 2018 lopussa ELIXIR AAI-palvelussa oli 2174 käyttäjää ja keskimäärin 3200 sisäänkirjautumista kuukaudessa.
ELIXIR AAI -palvelussa tunnistautuneet tutkijat pääsivät vuoden 2018 lopussa kirjautumaan 50 muuhun ELIXIR-infrastuktuuriin liittyvään palveluun. Lisäksi testattiin 44 muuta palvelua, joista osaa tarjosivat muut merkittävät eurooppalaiset tutkimusinfrastruktuurit. Sellainen on esimerkiksi EGI (European Grid Infrastructure), jonka fedCloud-laskentapalveluun pääsyä testattiin. Palvelujen määrä on koko ajan kasvussa.
ELIXIR AAI -palvelua ovat kehittäneet ELIXIR-infrastruktuurin Suomen ja Tsekin keskukset. Tunnistautumisen lisäksi palvelu välittää myös käyttölupia aineiston omistajalta. Suomessa Terveyden ja hyvinvoinnin laitos (THL) testasi ensimmäisenä ELIXIR AAI:n federoitun tunnistautumiseen ja käyttöluvan hallintaan perustuvaa prosessia biopankin näytteistä kerätyille sensitiivisille aineistoille. THL:n biopankki on osa BBMRI-infrastruktuuria ja aineistojen pääsynhallinta on esimerkki kahden eurooppalaisen tutkimusinfrastruktuurin yhteistyöstä tutkijan elämän helpottamiseksi.
Tarkoituksena on, että henkilö rekisteröi yhden ELIXIR-identiteetin ja käyttää tätä identiteettiä koko uransa ajan. Ainoa asia, mikä pitää tehdä, on päivittää yhteys- ja henkilötiedot, jos ne muuttuvat. Ei ole tarkoituksenmukaista ylläpitää useita ELIXIR-identiteettejä. ELIXIR-identiteettiin ei liity salasanaa. Rekisteröitymisen yhteydessä vaaditaan vain yhteys yhteen akateemiseen tai kaupalliseen käyttäjätiliin, joita käytetään sisäänkirjautumisessa.
Jo nyt ELIXIR AAI hyväksyy osana tunnistautumista myös Googlen, LinkedInin tai Orcidin tilin. Orcidin kautta tutkija saa digitaalisen identiteetin, jolla hän pystyy erottautumaan saman nimisistä kollegoistaan. ELIXIR AAI tukee myös 721 instituution sisäänkirjautumisia eduGAIN-palvelun kautta.
Federaatioiden haaste on se, että tällä hetkellä ei ole laajasti käytössä määritystä, jossa voisi määritellä erilaisia identiteettien ja tunnistautumisen varmuuden tasoja. Dataturvalait saavat jotkut instituutiot epäröimään tutkijoidensa henkilökohtaisen datan jakamista muille toimivalta-alueille.
Kun kyse on suojatuista ja sensitiivisistä datakokoelmista, käyttäjän tunnistamiselle ja käyttövaltuuksien hallinnalle tulee lisää vaatimuksia. Käyttäjien pääsyoikeuksia joudutaan esimerkiksi luokittelemaan. ELIXIRin asiantuntijat ovat työskennelleet yhdessä muiden tutkimusinfrastruktuurien kanssa EOSC LIFE-projektissa, joka kartoittaa bioalan eri käyttötapauksia luodakseen yhteisen ja laajan federoidun tunnistautumispalvelun. Tätä palvelua kutsutaan nimellä Life Science AAI ja se hyödyntää tunnistautumisessa eduGAIN-federaatiota.
Koska on lisääntynyt tarve federoituun pääsyyn myös eri tutkimusinfrastruktuurien välillä, monet projektit auttavat luomaan yhteisen käyttäjähallinnan. AARC-projekti (Authentication and Authorisation for Research and Collaboration) aloitettiin toukokuussa 2015. Projektin toinen vaihe (AARC2) käynnistyi toukokuussa 2017 ja päättyi huhtikuussa 2019. Projektissa pilotoitiin integroitua eri alojen välistä tunnistautumista ja valtuuttamista.
Tavoitteena on, että jokainen uusi käyttäjä rekisteröisi vain yhden käyttäjätunnuksen, joka seuraisi heitä läpi uran, vaikka hän vaihtaisi työpaikkaansa ja kytköksiään. Koska yliopistoilla ja tutkimuslaitoksilla on kytköksiä useampaan tutkimusinfrastruktuuriin, tutkijalla olisi niihin automaattinen pääsy oman organisaationsa tunnuksilla. Tavoitteena on rakentaa tutkijan sähköinen viitekehys niin, että voidaan hallinnoida niin identiteettiä (rekisteröityminen, ensitunnistus), tunnistautumista (sisäänkirjautuminen) kuin muita lisämääreitä, kuten tutkijastatusta.
Yhteistyö sellaisten tahojen kanssa kuin Federated Identity Management for Research Collaboration (FIM4R) tähtää puolestaan yhteisten standardien luomiseen, jotta voitaisiin vastata eri tutkimusyhteisöjen tarpeisiin. Toinen merkittävä yhteistyökumppani on GA4GH.
GA4GH (Global Alliance for Genomics and Health) on kansainvälinen vuonna 2013 perustettu allianssi, jossa on mukana yli 500 bioalan, terveydenhuollon ja IT-alan organisaatiota tavoitteenaan luoda standardeja tutkimuskäyttöön jaettavalle datalle. ELIXIR ja GA4GH päättivät aloittaa marraskuussa 2017 yhteistyön. Sopimus antaa ELIXIR-infrastruktuurille mahdollisuuden vaikuttaa kansainvälisten standardien luomisessa. Sopimus liittyy projektiin, jonka tarkoituksena on saada datastandardit käyttöön kliinisessä potilastyössä vuoteen 2022 mennessä. Nyt päästään luomaan yli 1000 organisaation kanssa standardien ohella yhteisiä periaatteita, miten dataa käsitellään ja jaetaan.
Haaste on miten määritellä ne vaatimukset, jotka organisaation täytyy täyttää jotta se voisi tulla luotettavaksi partneriksi globaaliin allianssiin.
Rekisteröity pääsy mahdollistaa eri käyttäjien luokittelun. Se myös mahdollistaa datan uudelleenkäytön, mutta luonnollisesti vain, jos suostumus on saatu ja käyttäjä noudattaa eettisiä sitoumuksia.
The Global Alliance for Genomics and Health on jaotellut kolme erilaista mahdollisuutta päästä käsiksi ihmisdataan. Sellaisia ovat:
1.Ei tarvetta pääsyn kontrolloimiseen.
2.Rekisteröity pääsy, joka perustuu käyttäjän rooliin tutkijana.
3. Kontrolloitu pääsy, joka perustuu käyttäjän saamaan yksilöityyn käyttölupaan.
”Koska data on yksityistä, federaatiot ovat tarkan tietosuojan ja säätelyn, kuten GDPR:n, alaisia. ELIXIRin jäsenorganisaatiot noudattavat eurooppalaista politiikka datan suojaamisessa. Koska tutkimus on globaalia, EU haluaa kuitenkin jakaa tutkimusdataa Kanadan ja Yhdysvaltojen kanssa,” sanoo Suomen ELIXIR-keskuksen johtaja Tommi Nyrönen. Suomen ELIXIR-keskus CSC on yhdessä Tsekin ELIXIR-keskuksen kanssa rakentanut ELIXIR AAI -palvelua.
”Siksi meidän tulee hallinnoida käyttäjäinformaatiota sekä eurooppalaisten että esimerkiksi pohjoisamerikkalaisten organisaatioiden välillä. Meillä tulee olla yhteiset sopimukset, miten dataa voidaan siirtää tutkimuksen käyttöön säädösten mukaisesti. Datasta vastuullistet tahot tarvitsevat riittävästi informaatiota käyttäjistä, jotka pyytävät pääsyä. Vasta, kun käyttäjä identiteetistä, ja mahdollisesti kotiorganisaatiosta ja statuksesta tutkijana on varmuus, lupahakemus voidaan käsitellä ja myöntää. Meillä pitää olla myös mekanismi lopettaa tai kumota pääsy dataan nopeasti, jos sitä käytetään vääriin tarkoituksiin. Asian voi hoitaa esimerkiksi ELIXIR AAI:n määrittelemällä politiikalla ja tekniikalla.”
ELIXIR AAI:ssa on palvelu, jota tutkijat voivat käyttää hakeakseen pääsyoikeutta sensitiivisiin datakokoelmiin. Käyttäjä voi osoittaa tutkijastatuksensa. ELIXIR-infrastruktuurissa tutkijastatuksen rekisteröimiseksi ja henkilön identiteetin varmentamiseksi tutkijan pitää ensin kirjautua sisään kotiorganisaatioonsa, joka sitten toimittaa edelleen ajantasaiset käyttäjätiedot sisäänkirjautumisprosessissa. Rekisteröimisessä voi olla lisätietoja, kuten kategoria ”bioalan tutkija”.
Tutkimusprojektin vastuuhenkilö täyttää hakemuskaavakkeen muiden projektiin osallistuvien tutkijoiden puolesta ja hyväksyy datakokoelman lisenssiehdot. Sähköinen hakemuskaavake lähetetään sitten datan pääsyoikeuksia valvovalle elimelle, jonka datanhallinnoija on nimennyt (Data Access Committee). Pääsyoikeus joko hyväksytään tai hylätään hakulomakkeen tietojen perusteella.
Jos palvelu edellyttää monivaiheista tunnistautumista, käyttäjä uudelleenohjataan nopeutettuun ja tehostettuun tunnistuspalveluun joka suorittaa ylimääräisen peräkkäisen tunnistuksen käyttämällä toista turvatekijää. Peräkkäinen tunnistus nojautuu aikariippuvaiseen ja kertakäyttöiseen salasanastandardiin (Time-based One-Time Password (TOTP) sekä älypuhelinsovellukseen, joka rekisteröidään ELIXIR AAI -palveluun. Kun käyttäjä on rekisteröitynyt, TOTP-sovellus antaa 6-merkkisen kertakäyttöisen salasanan, joka käyttäjän tulee kirjoittaa www-selaimeensa.
Älypuhelinsovellus kytketään oikeaan ELIXIR-identiteettiin puhelimeen lähetettävän tekstiviestin avulla. Datan omistajat voivat perua tai katselmoida käyttäjän pääsyoikeuksia.ELIXIRiin luottavat organisaatiot voivat rekisteröidä omat datakokoelmansa valtuutuspalveluun ja määritellä hakukaavakkeet ja hakemiseen liittyvät prosessit.
Tehokas tietoturva perustuu riskianalyysiin aineistojen sekä palvelun luonteen asettamista vaatimuksista. Esimerkiksi tutkijoiden pääsy datakokoelmien, joiden vaikutus yksityisyyteen on rajallinen, on mahdollista toteuttaa kevyemmän hakuprosessin avulla. Tällöin tutkijan ei tarvitse tehdä muuta kuin osoittaa olevansa varteenotettava tutkija ja sitoutua yleisiin rekisteröidyn pääsyn sitoumuksiin.
Hakemuksen kertaalleen tehtyään tutkijat voisivat saada pääsyn kaikkiin rekisteröitymistä edellyttäviin datakokoelmiin ja palveluihin ilman lisätyötä. Esimerkki tällaisesta pääsyprosessista on ELIXIR Beacon -palvelu. Beacon-protokolla määrittelee avoimen standardin. Sivustoa, joka tarjoaa tällaista palvelua kutsutaan ”majakaksi” (beacon). Beacon on hakukone tiedolle, mistä päin maailmaa löytyy genomiaineistoja, joissa esimerkiksi on kiinnostuksen alla olevan nukleotidin muutos, esimerkiksi proteiinia koodaavassa geenisekvenssissä muutos, jossa sytosiini (C) muuttuu guaniiniksi (G).
”Tämä muutos voi muuttaa geenistä syntyvän proteiinin rakennetta. Joskus nämä muutokset ovat vaarattomia, mutta joskus voivat myös johtaa sairauteen. Geneettisten muutosten ja harvinaisten tautien yhteyttä tutkitaan aktiivisesti, ja tuloksia voidaan saavuttaa nopeammin tekemällä aineistot löydettäväksi Beacon palvelun avulla,” sanoo Tommi Nyrönen.
Standardin ja teknologian ovat kehittäneet GA4GH:n jäsenorganisaatiot. Dataa voidaan etsiä samanlaisilla periaatteilla ELIXIRin ja Beacon-organisaatioiden verkostoista (Beacon Network). Haku on federoitu ja datakokoelmien määrä kasvaa koko ajan.
Ari Turunen
20.8.2019
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, & Tommi Nyrönen. (2019). Federated user ID management: a single identity giving access to numerous bioinformatics services. https://doi.org/10.5281/zenodo.8176724
Lisätietoja:
Registered access: authorizing data access
European Journal of Human Genetics (26,2018)
https://www.nature.com/articles/s41431-018-0219-y
Common ELIXIR Service for Researcher Authentication and Authorisation
F1000Reserarch (7, 2018)
https://f1000research.com/articles/7-1199/v1
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Potilasdata on tärkeää tutkimukselle. Henkilön tietosuojasta huolehditaan piilottamalla tai muokkaamalla tunnistetietoja, mutta samalle tutkijalle jää tutkimukselle merkittävä tilastollinen data. Uusi tekoälyä käyttävä palvelu mahdollistaa tämän.
VEIL.AI anonymisoi potilasdatan perinteisiä menetelmiä tehokkaammin, nopeammin ja informaatiota paremmin säilyttäen. Tarvittaessa sovelluksen avulla voidaan tuottaa myös synteettistä, täysin anonyymia eli siis yksittäisestä henkilöstä erillään olevaa tilastollista dataa.
Suomen molekyylilääketieteen instituutissa (FIMM) kehitetty sovellus on nyt tarjolla ELIXIR -infrastruktuuriin, jonka kanssa kehitetään yhteistä palvelua. Dataa hallinnoiva organisaatio voi suojata datansa syöttämällä metadatatiedot skaalautuvaan pilvipalveluun. Palvelu verhoaa yksilökohtaiset tunnisteet, jolloin tutkijat saavat käyttöönsä anonymisoitua ja tarvittaessa synteettistä dataa.

VEIL.AI –sovellus hyödyntää tekoälyyn perustuvaa mallintamista. Sovelluksessa luodaan huntu, joka suojelee potilaan tunnistetietoja mutta se osaa tunnistaa relevantin datan, jolloin se ei hävitä sitä.
“Toisinaan, esimerkiksi koneoppivia malleja kehitettäessä, tarvitaan dataa laajemmin ja nopeammin kuin mitä tutkimuseettiset lautakunnat mielellään antavat. He edellyttävät jokaisen muuttujan tarkkaa perustelua, mikä taas on koneoppivissa malleissa vaikeaa siinä vaiheessa, kun parasta mallia vasta haetaan,“ sanoo kaupallistamisasiantuntija Tuomo Pentikäinen.
Siksi varsinkin mallintamisen alkuvaiheessa onkin Pentikäisen mukaan järkevää käyttää synteettistä dataa, jota VEIL.AI -menetelmällä voidaan luoda.
“Tällä tarkoitetaan taustalla olevista ihmisistä kokonaan irrallaan olevaa dataa, joka kuitenkin käyttäytyy haluttujen muuttujien suhteen samoin kuin alkuperäinen data.”
VEIL.AI löytää henkilön tunnistamiselle herkät muuttujat ja pystyy nämä muuttujat anonymisoimaan automaattisesti.
”Sovelluksessa voidaan tehdä suunnitelmallisemmin ja järkevämmin laskennallisesti raskaita ja operatiivisesti työläitä datan osittamiseen ja anonymisointimetriikoiden laskemiseen liittyviä toimenpiteitä.”
Arkaluontoista potilasdataa pitää pystyä suojelemaan, mutta monet perinteiset anonymisointimallit hävittävät samalla tärkeääkin dataa. Perinteisesti potilastietoja on suojattu osittamalla ja karkeistamalla datassa olevia tunnistetietoja. Anonymisoinnissa tutkitaan sitä, miten muuttujat jakavat/osittavat tiedon erilaisiin ryhmiin. Sitten kutakin ryhmää tarkastellaan erikseen ja jos sieltä löytyy liian tunnistettavia muuttujia, niitä karkeistetaan. Karkeistuksessa esimerkiksi ikää voidaan pyöristää muutamalla vuodella ja ammattinimike vaihtaa sairaanhoitajasta ”terveydenalan ammattilaiseksi”.
”Liian tunnistettavat muuttujat karkeistetaan siis riittävän yleiselle tasolle tai jopa poistetaan. Terveysdatassa poistamisia joudutaan aika usein tekemään, kun jokin muuttuja on liian ainutlaatuinen ja tunnistettava”, sanoo Pentikäinen.
Karkeistaminen voi siis hukata tärkeää potilasdataa.

”Tyypillisesti tätä tapahtuu silloin, kun kiinnostava ilmiö (vaikkapa sairaus) on kohtalaisen harvinainen ja jakaantuu melko tasaisesti koko tietomassaan. Kun tietomassa sitten jaetaan ositteisiin anonymisointia varten, on tavallista että kiinnostuksen kohteena oleva ilmiö jakautuu entistäkin harvinaisempana kuhunkin uuteen ositteeseen. Tällöin on tavallista, että perinteiset menetelmät tulkitsevat kyseessä olevan kiinnostavan datan ”outlieriksi” kussakin uudessa ositteessa ja se siivotaan pois. Tämä on typerää, koska fiksummin valitulla strategialla kiinnostava ilmiö olisi saatu kerätyksi ositteisiin siten, että tärkeä informaatio voidaan säilyttää paremmin. ”
Suomen molekyylilääketieteen instituutin IT-päällikkö Timo Miettinen ottaa esimerkiksi potilaan, jolla on harvinainen versio rintasyövästä. Liian raju karkeistus voi kokonaan hävittää tiedot harvinaisesta versiosta, koska tällaisia potilaita on datajoukossa vähän.
”Rintasyöpäpotilaalla on yksi diagnoosi, mutta hänen geneettinen profiiliinsa kertoo, että hänellä on rintasyövästä harvinainen versio. Näitä potilastapauksia voi olla yhdessä sairaalassa muutamia, jolloin se voidaan luokitella outlieriksi ja deletoidaan. Mutta koko populaatiota ajatellen näin ei ole ole. Jos kokonaisuutta pystyttäisiin tarkastelemaan paremmin, tämä outlier, poikkeava havainto, ei olisi deletoitu.”
Timo Miettinen on pitkään ollut mukana suunnittelemassa tietojärjestelmiä, joissa hyödynnetään ja suojataan kliinistä dataa. Miettinen ryhmineen on kehittänyt VEIL.AI-sovelluksen, jota ollaan kaupallistamassa. Tällainen mikropalvelu on luotu EU:n tietosuoja-asetuksen GDPR:n takia.
Suomessa on jokaisella biopankilla käytössään oma koodirekisteri. Koodirekisterissä on henkilötunnus sekä synonyymitaulukko, jolloin luodaan tutkittavalle tunniste, joka on pseudonyymi eli peitetunniste.
”Joitakin asioita on vaikea muuttaa, kuten pituus, silmien väri ja syntymäpaikka. Ne ovat tilastollisilla menetelmillä tunnistettavissa. Samoin terveyteen liittyvä tapahtumasarja eli hoitohistoria”, sanoo Miettinen.
”Meillä on kaksi lupausta. Ensinnäkin lupaamme skaalautuvuutta ja enemmän suorityskykyä. Pystymme hyödyntämään jatkuvasti päivittyvää dataa monesta lähteestä. Ne voimme anonymisoida tehokkaasti ja tietoturvallisesti. Toinen lupauksemme on, että yritämme minimoida tietohävikkiä. Sovelluksella huomioidaan datan sisältö ja täytetään samalla anonymisointikriteerit”, sanoo Miettinen.

VEIL.AI -sovelluksessa käytetään neuroverkkoa, jopa on jopa tuhansia kertoja nopeampi kuin perinteiset menetelmät.
”Menetelmämme mahdollistaa aikaisempaa turvallisemman tiedon jakamisen, sillä neuroverkon opettamisen jälkeen kukin luottamuksellisen tiedon haltija voi suorittaa anonymisoinnin ennen kuin luovuttaa luottamuksellista tietoa partnereilleen. Usein menetelmämme tuottaa myös parempaa dataa, sillä voimme kokeilla valtavan määrän erilaisia datan osittamisstrategioita ja valita niistä sen, joka tuottaa pienimmän informaatiohävikin ja silti saavuttaa tavoitellun anonymiteettitason, ” sanoo Pentikäinen.
Tietoturvalle tärkeää on myös VEIL.AI -sovelluksen käytössä se, että potilasdata ei siirry minnekään.
”Me emme halua hallinnoida dataa. Meidän palvelumme läpi striimataaan dataa, joka anonymisoidaan ja palautetaan sitten välittömästi asiakkaan hallintaan,” sanoo Tuomo Pentikäinen.
”Tarjolla on skaalautuva pilvipalvelu. Käyttöliittymän kautta voidaan syöttää tarvittavat metadatatiedot (data dictionary) ja opettaa algoritmi tekemään datan anonymisointimallin jollakin esimerkkiaineistiolla. Algoritmi oppii käsittelemään dataa ja jos tulee lisädataa, se striimataan pilvipalvelun kautta ja anonymisoidaan,” Timo Miettinen korostaa.
Organisaatioiden ei siis tarvitse jakaa sensitiivistä dataa enää kenellekään. Data tulee anonymisoituna pilvipalvelun kautta tutkimuksen käyttöön.
Eri pseudotunnisteiden analysoimiseen tarvitaan paljon laskentaa, jota on saatu ELIXIR -infrastruktuurista.
Ari Turunen
3.6.2019
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Tuomo Pentikäinen, Timo Miettinen, & Tommi Nyrönen. (2019). VEIL.AI: patient data in a veil. https://doi.org/10.5281/zenodo.8119016
VEIL.AI
FIMM
Suomen molekyylilääketieteen instituutti (FIMM) on kansainvälinen tutkimuslaitos, jonka toiminta keskittyy sairauksien molekyylitason mekanismien selvittämiseen genetiikan ja lääketieteellisen systeemibiologian menetelmin. Tavoitteena on tutkimustiedon siirtäminen terveydenhuollon käyttöön mm. henkilökohtaista lääketiedettä edistämällä.
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Biocenter Oulu tarjoaa palveluja proteiinien, solujen ja geenien tutkimisessa sekä transgeenisten eläinten luomisessa. Yksi vahvuusalueista on valo- ja elektronimikroskooppinen kudosten ja solujen kuvantaminen.
Biocenter Oulun infrastruktuuri-yksikön johtajan, professori Lauri Eklundin mukaan geneettisesti muokatut mallieläimet ja erityisesti muuntogeeniset hiiret ovat auttaneet tutkijoita ymmärtämään nisäkkäiden normaaliin kehitykseen ja kudosten toimintaan liittyviä ilmiöitä enemmän kuin mikään muu eliö. Ne sopivat myös ihmisellä esiintyvien tautien malliorganismeiksi.
”Useat kuvantamisprojektit Oulussa liittyvät geneettisesti muokattujen hiirten tutkimukseen. Oulussa kuvannetaan hiiren alkioita ja elimiä kokonaisina tai kudosleikkeistä yksittäisten solujen tarkkuudella. Olemme ottaneet käyttöön myös menetelmiä, joilla kuvataan soluja ja makromolekulaarisia rakenteita elävissä hiirissä, joissa kudoksia voidaan kuvata tarkalla resoluutiolla mikroskopiaikkunoiden kautta.”
Tätä tarkoitusta varten on rakennettu intravitaalikuvantamislaboratorio, joka mahdollistaa solujen tutkimisen nukutetussa eläimessä. Laboratoriossa voidaan tehdä myös pieniä kirurgisia toimenpiteitä.
”Täällä myös tehdään tuotetusta kuvadatasta 3D-mallinnusta optisten leikkeiden avulla. Motorisoitujen mikroskooppien avulla voidaan myös muodostaa pinta-alaltaan suuria kudosleikekuvia, jotka ovat mosaiikkimaisia kuvakoosteita kudoksista.”
Biocenter Oulun valomikroskopian ydinpalvelussa on erikoistuttu ns. mesoskooppiseen kuvantamiseen. Mesoskooppinen kuvantaminen auttaa ymmärtämään solujen välisiä vuorovaikutuksia monimutkaisessa kudosympäristössä tai jopa kokonaisissa eliöissä. Mesoskoppisen mittakaavan näytteet ovat tilavuudeltaan ja pinta-alaltaan tavallista suurempia: kokoluokka on muutamasta millimetristä pariin senttimetriin. Sellaisia ovat esimerkiksi hiirten alkiot, kolmiulotteiset elimiä muistuttavat organoidit ja kokonaiset pienet malliorganismit, kuten kärpäset ja kalat.
”Teknisesti mesoskooppinen kuvantaminen edellyttää mikroskopiaan sopivaa kudosviljely-ympäristöä, tarkoitukseen kehitettyä 3D -kuvantamislaitteistoa, kudosten kirkastusmenetelmiä sekä edistynyttä kuva-analyysi- ja prosessointikapasiteettia, sanoo Eklund.

Biocenter Oulussa on käytössä erilaisia mikroskooppeja, joiden ansiosta saadaan monipuolisesti kuvannettua ja paikannettuja useita erilaisia tapahtumia soluissa ja kudoksissa. Kolmiulotteisiin malleihin saadaan myös liitettyä ajallinen ulottuvuus (4D kuvantaminen) elävissä näytteissä. Voidaan laatia kuvasarjoja, joista voidaan seurata, miten solut erikoistuvat ja kasvavat esimerkiksi alkioiksi tai elimiä muistuttaviksi organoideiksi.
”Professori Seppo Vainion tutkimusryhmän työn ansiosta voimme esimerkiksi kasvattaa elintä muistuttavan organoidin muutaman päivän aikana munuaisen eri solutyypeistä. Tämä osaaminen on kiinnostanut myös kansainvälisesti. Moni tutkija on tullut hakemaan oppia Oulusta.”
Konfokaali- ja valolevyfluoresenssimikroskoopit soveltuvat kolmiulotteisten ja elävien näytteiden kuvantamiseen. Ne skannaavat näytteet nopeasti niitä vahingoittamatta. Elektronimikroskoopeilla voidaan puolestaan löytää muutoksia solun ja soluvälitilan rakenteista, jotka ovat valomikroskopian resoluution ulottumattomissa. Tämä teknologia vaati kuitenkin näytteiden paikalleen kiinnittämistä (fiksaamista).
Vaikka valoaaltojen avulla ei saada sellaisia suurennoksia kuin elektronimikroskoopilla, laserherätevalon ja fluoresoivien leimamolekyylien kekseliäällä käytöllä ja kuvadatan käsittelyllä päästään valomikroskopiassa sellaiseen tarkkuuteen, jolla voidaan tutkia yksittäisiä soluja, soluelimiä ja makromolekyylirakenteita.
Jotta muutoin näkymättömät kohteet saataisiin 3D mikroskopiassa näkyviksi ne usein värjätään fluoresoivaksi. Fluoresoiva proteiini kiinnitetään tutkittavaan molekyyliin elävissä solussa tavallisesti geneettisesti. Fluoresoivat yhdisteet (fluoroforit) absorboivat eli ottavat vastaan herätevalon energiaa ja vapauttavat osan tästä energiasta pidempinä valon aallonpituuksina. Tätä kvanttimekaanista ihmisenkin silmällä havaittavaa ilmiötä kutsutaan fluoresenssiksi.
Haluttuja proteiineja voidaan myös etsiä soluista ja kudoksista käyttämällä vasta-aineita, joihin on liitetty fluoresoiva merkkiaine. Vasta-aine tunnistaa tietyn proteiinin ja kiinnittyy siihen. Kiinnittymisen jälkeen merkkiaine havaitaan mikroskoopilla. Käytettävä merkkiaine valitaan sen mukaan millaisella mikroskoopilla näytettä aiotaan tutkia.
”Käytössämme on mm. spektraarisilla detektoreilla ja jatkuvalla laservalolla varustettuja mikroskooppeja, jotka mahdollistavat usean fluoresoivan leiman tutkimisen samanaikaisesti. Näin voidaan tutkia monimutkaisia vuorovaikutuksia.”
Fluoresenssimikroskopiassa merkkiaineena käytetään fluoresoivia molekyylejä ja elektronimikroskopiassa esimerkiksi kultaa.
”Oulussa on myös käytössä ns. label free– kuvantamismenetelmiä, jotka eivät edellytä erityisiä leimoja tai varjoaineita. Tällaisia ovat mm. multifotoni- teknologialla näkyvä sidekudoksen kollageeni tai fotoakustisen mikroskopian avulla kuvattavat elimistön omat molekyylit, kuten hemoglobiini. Jälkimmäisessä teknologiassa yhdistämällä erilaisia herätelasereita voidaan kudoksista saada rakenteellista ja toiminnallista tietoa, esimerkiksi verisuonten rakenteesta ja veren hapetusasteesta. Nämä teknologiat ovat suureksi avuksi kuvattaessa eläviä kudoksia, jonne merkkiaineita on vaikea saada.”
Elektronimikroskopiassa Oulussa on erikoistuttu kudosten ultrastruktuuripatologiaan ja immunoelektronimikroskopiaan, joilla tutkitaan esimerkiksi geenimuokattujen hiirikudosten rakenteita tai viljeltyjä soluja. Näillä tekniikoilla saadaan tietoa hyvin pienistä yksityiskohdista sekä tutkittavien proteiinien täsmällisestä sijoittumista solu- ja kudosrakenteisiin.
Immunoelektronimikroskopiassa metallileimattu vasta-aine liittyy tutkittavaan proteiiniin, jolloin voidaan määrittää proteiinin paikka erittäin tarkasti. Näin voidaan saada uutta tietoa esimerkiksi solujen rakenteista ja proteiinien välisistä yhteyksistä.
”Hienorakenteen tutkiminen elektronimikroskooppisten menetelmien avulla on ollut erityisen hedelmällistä soluväliaineen molekyylien tutkimuksessa, joita ei valomikroskoppisessa tutkimuksessa voida nähdä. Uutena tutkimuskohteena ovat myös solunulkoiset vesikkelit, ”eksomit”, joita voidaan kuvantaa elektronimikroskopian avulla.”
Perinteisen kuvantamisen ongelmia ovat olleet huono erotuskyky, pieni kuvantamissyvyys ja kuvadatan tehokkaan analytiikan puute. Elektronimikroskopiassa näytteiden valmistaminen vaatii erikoisosaamista ja biologisen tiedon esiin saaminen kuvista vaatii tutkijoilta harjaantumista.
Oulussa on kehitetty kuvia automaattisesti tulkitsevaa ja oppivaa konenäköä. Tässä Biocenter Oulu on tehnyt yhteistyötä professori Janne Heikkilän, Oulun yliopiston konenäön ja signaalianalyysin tutkimuskeskuksesta. kanssa.
”Suurten näytteiden kolmi- ja neliulotteisessa kuvantamisessa datan tallennus, siirto ja analyysit ovat haasteellisia. Kun data siirtyy mikroskoopista käyttäjälle, sitä pitäisi pystyä analysoida. Analyysit voivat vaatia paljon laskentatehoa. Jos alkuperäinen data säilytetään kaukana, ongelmana sujuvalle kuva-aineistojen käsittelylle voi olla tiedonsiirtonopeudet.”
Lauri Eklundin mielestä Suomen ELIXIR -keskus CSC:n tarjoama infrastruktuuri on kansallisesti toimivin ratkaisu raakadatan varastointipaikaksi ja avoimen datan uudelleenkäytölle.
Vaikka metadataa liitetään kuvadataan, datanhallintaan liittyy vielä paljon ongelmia.
”Jotta kuvadata olisi uudelleen käytettävissä, sen pitäisi olla tiettyjen standardien mukaista, kuratoitua ja annotoitua. Tutkimuksen infrastruktuurit tarvitsevat kuvadatalle ”kirjastonhoitajia” ja kuvainformaatikkoja.”
Ari Turunen
20.5.2019
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Lauri Eklund, & Tommi Nyrönen. (2019). Biocenter Oulu: technology services for biomedical research. https://doi.org/10.5281/zenodo.8176718

Tavanomaisessa valo- ja fluoresenssimikroskoopissa valo valaisee koko näytteen läpi, valoaalto himmenee ja diffraktion vuoksi valo siroaa kudoksissa ja aiheuttaa kuvannettavan kohteen sumentumisen, ja huonon syvyysterävyyden paksuissa näytteissä
Konfokaalimikroskooppi puolestaan skannaa kapean lasersäteen avulla yhtä pientä osaa optista näytekerrosta kerrallaan, poistaa ei-fokustasossa olevaa valoa, ja saavuttaa paremman tarkkuuden näytteistä jotka ovat liian paksuja perinteiselle fluoresenssimikroskopialle.
Konfokaalimikroskoopissa lopullinen kuva muodostetaan pienistä kohdistetuista alueista. Kolmiulotteisia kuvia saadaan rekonstruoimalla kaksiulotteiset kuvat näytteen eri syvyyksistä. Kolmiulotteisella mallinnuksella yhdistämällä useita optisia leiketasoja voidaan visualisoida rakenteita, joita ei voi nähdä perinteisellä valomikroskopialla.
”Uusien teknologioiden käyttöönotossa on hyödynnetty Oulun yliopiston monitieteisyyttä. Esimerkiksi valolevymikroskopiassa ja fotoakustisessa mikroskopiassa kehitystyötä on tehty Oulun yliopiston optoelektroniikan ja mittaustekniikan laboratorion dosenttien Matti Kinnusen ja Teemu Myllylän kanssa, ennen kuin teknologiat ovat olleet kaupallisesti saatavilla. Tämä tuo tutkijoille kilpailuetua ”, sanoo Lauri Eklund.

Valolevyfluoresenssimikroskopian (light sheet) avulla voidaan kuvantaa valolle herkkiä näytteitä tai nopeita biologisia prosesseja mikroskooppisesti suuressa elävässä organismissa. Näyte valaistaan herätevalolla vain yhdessä tasossa kerrallaan ja näytteestä syntyvä signaali kerätään toisella objektiivilla. Mikroskoopissa on jatkuva optinen jaksotus: kun näytettä siirretään valotasolla, yksittäiset optiset tasot voidaan taltioida 3D-kuviksi. Isoja 3D-näytteitä voidaan skannata nopeammin mutta hieman huonommalla resoluutiolla kuin konfokaalimikroskoopilla.
”Biocenter Oulu oli Suomessa ensimmäinen laboratorio, joka otti käyttöön tämän teknologian. Oulussa valolevymikroskopialla voidaan kuvata mesoskooppisia kudoskirkastettuja, mutta myös eläviä kolmiulotteisia näytteitä, jolloin kuviin saadaan aikaulottuvuus. Näin voidaan kuvata esimerkiksi geneettisesti leimattujen yksittäisten solujen kasvaminen kokonaisiksi alkioiksi tai organoideiksi tietyssä ajassa”, sanoo Eklund.
Heidelbergissä kehitetyn uuden valolevyfluoresenssimikroskoopin ansiosta, vuonna 2015 EMBL:n laboratoriossa Heidelbergissa tutkijat ensimmäistä kertaa pystyivät tarkkailemaan hiiren alkion kehittymistä muutaman ensimmäisen päivän aikana kun se alkoi kehittyä hedelmöityneestä munasolusta alkioksi.
Yhdysvalloissa (Howard Hughes Medical Institute) julkistettiin vuonna 2018 monia kuvakulmia hyödyntävä mikroskooppi, jossa voidaan tarkastella alkion kasvua yksittäisen solun tasolla. Tutkijat seurasivat solualkioita ja tarkastelivat, mitkä geenit kytkeytyivät päälle ja mitkä solut liittyivät toisiinsa.
Kaksi valotasoa valaisivat alkiota ja kaksi kameraa tallensivat varhaista elinten kehittymistä. Algoritmit jäljittivät alkion paikan ja koon. Algoritmit kartoittivat kuin valolevy liikkuu näytteessä ja sitten ratkaisee, miten saada parhaimmat kuvat, mutta samalla huolehtii kuitenkin siitä, että alkio on kiintopisteessä. Koska alkio muuttuu koko ajan, mikroskoopin pitää alituisesti mukautua ja tehdä ratkaisuja hyvin nopeasti, mitä sadoista kuvista ja aikaikkunoista otetaan huomioon.
”Tulevaisuuden kehittyneet mesoskooppiset menetelmät voivat hyödyntää ei-diffraktoituvaa herätevaloa (Bessel Beam ja Airy Beam). Poiketen tavallisesta valosta, näissä herätevaloissa intensiteetti pysyy vakiona paksuissa kudosnäytteissä. Lisäksi herätevalon asymmetrinen muoto ja uudelleen muotoutumisominaisuus parantavat kuvantamisresoluutiota ei-homogeenisissä ja valoa paljon sirottavissa kudosnäytteissä.”
Uudelleenmuotoutumisessa tarkoitaan sitä, että vaikka herätevalon säde osuu osittain esteeseen se palautuu ennalleen, toisin kuin tavallinen valo.
Lauri Eklundin mukaan elävien näytteiden nopean kolmiuloitteisen kuvantamistekniikoiden kehittymisen myötä tallennetun kuvatiedon määrä on kasvanut valtavasti. Samoin tarve kuvadatan kvantitatiivisille analyysiohjelmistoille on suuri.
”Uusista tekniikoista saadaan kaikki hyöty irti, jos osataan myös kuvankäsittely. Erityisesti mesoskooppisessa kuvantamisessa näytteiden suuri koko edellyttää tehokkaita kuva-analytiikan ja prosessoinnin työkaluja jotka esimerkiksi voivat poistaa kuvista taustahälyä ja mahdollistavat tarkkojen 3D-mallennusten tekemisen. Älykkäillä tietokoneohjelmistoilla voidaan lisäksi analysoida solujen käyttäytymistä ja tunnistaa solujen ominaisuuksia. Voidaan esimerkiksi erottaa solytyyppejä, määrittää solujen jakautumisen aktiivisuutta ja analysoida solujen liikkumis- tai elinkykyä.”
Lisätietoja:
Biocenter Oulu
Biocenter Oulu kuuluu osana suomalaisten biokeskusten muodostamaan Biocenter Finlandin, joka kordinoi merkittävien kansallisten tutkimuksen infrastruktuurien toimintaa. Se on myös jäsenenä eurooppalaisissa tutkimusinfrastruktuureissa. Näitä ovat transgeenisten hiirten (Infrafrontier), biologisen kuvantamisen (Euro-BioImaging), ja proteiinirakennetutkimuksen (Instruct) infrastruktuurit.
https://www.oulu.fi/biocenter/
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Pienet erot perimässämme tekevät meistä erilaisia. Monimuotoisuus on hyvä asia, mutta toisinaan geenimuutokset aiheuttavat sairauksia. Hiiret ovat ihmisen sairauksien tutkimiselle hyvä apu, sillä hiiren ja ihmisen genomi on noin 80 prosenttisesti samankaltainen. Hiirikannoista voidaan siksi luoda ihmisen geneettisten tautien malleja, ja näitä malleja voidaan käyttää tautien syntymekanismien tutkimuksessa ja lääkeainesuunnittelussa.
Eurooppalainen INFRAFRONTIER-tutkimusinfrastruktuuri tarjoaa yli 6800 erilaista hiirikannan mutaatiota eli käytännössä tuhansien eri sairauksien hiirikantoja. Infrastruktuurissa on 23 jäsenorganisaatiota. Suomea edustaa Oulun yliopistossa toimiva Biocenter Oulu.
Vuonna 2007 lääketieteen ja fysiologian Nobelin palkinnot myönnettiin Mario Capecchille, Olivier Smithiesille ja Martin Evansille tutkimuksesta, jonka ansiosta kantasolujen avulla voidaan luoda muutoksia ja lisäyksiä hiiren omaan, nk. ituradan eli perimän kautta tulevaan genomiin. Evans kehitti menetelmän kasvattaa hiiren alkion kantasoluja. Hän lisäsi kantasoluja hiiren alkioon ja kehittyi hiiriä, joiden soluista osa oli viljeltyjä kantasoluja. Toisin sanoen hiiren perimään saatiin liitettyä kantasolujen avulla toisen hiiren geneettistä materiaalia. Solutasolla hybridit hiiret kehittyivät normaalisti.
Capecchi ja Smithies kehittivät puolestaan menetelmän häiritä tai kokonaan sammuttaa hiiren tietyn geenin ilmentyminen siirtämällä vierasta DNA:ta hiiren kromosomistoon tarkasti määriteltyihin kohtiin. Vieras DNA lopettaa tai merkittäviltä osin sammuttaa geenin toiminnan, jolloin voidaan tutkia mikä geeni vaikuttaa mihinkin hiiren ominaisuuteen. Kohdennettua geenin toiminnan estämistä käytettiin hiiren alkion kantasoluihin. Niiden avulla voitiin kasvattaa hiiri, jonka jälkeläiset olivat kokonaan ns. poistogeenisiä eli niiden perimästä oli poistettu toiminnasta jokin geeni. Tämän tekniikan on nykyään korvannut suurelta osin CRISPR-Cas9- menetelmä.
Koska hiiren yksittäisen geenin toiminta voidaan sammuttaa, pystytään nyt tutkimaan, minkä vaikutuksen kyseisen geenin poiskytkeminen aiheuttaa. Näin on voitu esimerkiksi määrittää geenejä , jotka ohjaavat nisäkkäiden luuston ja tiettyjen sisäelinten kehitystä.

Geenien toiminnan säätelymenetelmien ansiosta on voitu tehdä hiirimalleja useista ihmisten sairauksista. Näitä hiirimalleja voidaan käyttää tutkittaessa tautien syntymekanismeja, niiden etenemistä ja luonnollisesti myös hoitoa.
”Jos potilaalta löydetään uusi mutaatio ja tauti, me näemme vain taudin lääketieteellisesti luokitellun ilmentymän. On vaikea erottaa, mikä on ensisijainen syy taudin syntyyn tai mikä on toissijainen seuraus, jos kyseessä on pitkälle edennyt tai monielinoireinen tauti,” sanoo dosentti Reetta Hinttala Biocenter Oulusta.
Hinttala on Biocenter Oulun Transgeeniyksikön koordinaattori. Yksikkö on osa eurooppalaista INFRAFRONTIER-infrastruktuuria. IINFAFRONTIER tarjoaa tutkijoille maailmanlaajuisesti pääsyn hiirimalleihin, jotka liittyvät geeniperimän ja sairauksiin tutkimiseen.
Reetta Hinttala tutkii Oulun yliopiston lääketieteellisen tiedekunnan PEDEGO-tutkimusyksikössä hiirimallien avulla mm. harvinaisia perinnöllisiä sairauksia. Hiirimallit auttavat tunnistamaan tautia aiheuttavat geenit.
”Hiirimallit ovat olennainen osa geenitutkimusta. Niiden avulla pystytään selvittämään organismin tasolla tautigeeniä ja tautimekanismeja. Malli tuo perustietoa siitä, miten tauti etenee. Tutkimalla eri ikäisiä hiiriä saadaan tietoa, mitä eri kudoksissa tapahtuu taudin eri vaiheissa.”
Hinttalan mukaan vastaavanlaista kudostason analyysiä olisi vaikea toteuttaa potilasaineistosta, varsinkin jos kyseessä ovat keskushermostoon vaikuttavat taudit.
”Eläinmalli tuo arvokasta tietoa tapahtumista kudostasolla aivan taudin alkuvaiheessa. Ne voivat olla sellaisia tapahtumia, joita ei välttämättä ihmisellä ole huomattukaan. Kohdentamalla tutkimukset juuri niihin alkuvaiheen muutoksiin on mahdollista löytää taudin varhaiseen vaiheeseen kohdentuvia hoitokeinoja, joita voidaan hyödyntää jatkossa lääkeainekehittelyssä.”
Hiirimallin merkitys tautigenetiikan tutkimukselle on Hinttalan mielestä erityisen arvokasta silloin, kun tutkitaan tuntematonta proteiinia ja taudin mekanismia. Sen avulla päästään tutkimaan oikeassa ympäristössä, mitä kudoksissa taudin edetessä tapahtuu. Koska hiiren ja ihmisen perimä on hyvin samankaltainen, voidaan samoja fundamentaalisia tautia aiheuttavia mekanismeja havaita sekä hiiressä että ihmisessä.
Kudokset rakentuvat soluista ja niitä ympäröivästä soluväliaineesta. Oulussa tutkitaan kudosten rakennetta sekä sitä, miten kudokset järjestyvät muodostaakseen elimiä. Keskeinen apuväline kudosdatan keräämisessä on mikroskooppi, jolla voidaan kuvantaa kudosten rakennetta. Kudosnäytteistä saadaan lisäinformaatiota käyttämällä erilaisia värjäystekniikoita haluttujen rakenteiden osoittamiseksi. Värjäyksissä voidaan käyttää väriaineita, jotka sitoutuvat vain tiettyihin rakenteisiin ja molekyyleihin.
Kuvannetut digitaaliset kudosnäytteet varustetaan metadatalla ja arkistoidaan. Haasteena on kuitenkin kuvannetun datan säilyttäminen ja jakaminen. Slide Scanner- laitteen skannaaman kudosleikkeen kuvatiedoston koko voi jopa nousta kymmeniin gigatavuihin. Haasteena on, miten näitä tiedostoja hallinnoidaan tulevaisuudessa.
Tutkijoilla on suuri tarve säilyttää kuvamateriaali. Data pitää kuitenkin osata kuvailla, jotta se voidaan jakaa tiedeyhteisölle.
”Sekä INFRAFONTIER että ELIXIR-infrastruktuurit tekevät töitä avoimen tutkimustiedon saatavuuden eteen. Jotta esimerkiksi hiiristä tuotettu data olisi maksimaalisesti hyödynnettävissä, se pitää saada käsiteltyä ja analysoitua tutkimusta hyödyntävällä tavalla. Tärkeänä työsarkana pidän myös kuvailua kansainvälisiä standardeja käyttäen, mikä tekee jatkokäytön mahdolliseksi, esimerkkinä tiedon yhdistely täydentäviin tietolähteisiin,” sanoo Tommi Nyrönen, Suomen ELIXIR-keskukseen johtaja CSC:stä.
Tieteellisesti merkittävät hiirikannat ovat Euroopassa INFRAFRONTIERin EMMA-arkistossa, joka on yksi maailman johtavista hiirikantojen arkistoista. EMMA (The European Mutant Mouse Archive) arkistoi geenimuunneltuja hiirikantoja eri puolilta maailmaa ilmaiseksi. EMMA:ssa on tällä hetkellä 6800 mutatoitua hiirikantaa eli hiirimallia ja moni näistä hiirimalleista on voitu yhdistää sairauksiin. Münchenissa olevan keskuksen kautta organisoidaan INFRAFRONTIERin eri yksiköiden toimintaa. 12 eri maassa olevien yksiköiden tehtävänä on hiirikantojen pakastaminen, säilytys ja jakelu. Osa tekee myös fenotyypitystä.
”Tutkija voi halutessaan säilöä oman hiirikantansa, hiirimallinsa arkistoon, jos hiirikanta on tarpeeksi hyvin karakterisoitu ja tietty mutaatio hiiressä on luotettavasti todennettu. Kun uusi hiirikanta otetaan EMMA-arkistoon, tutkija lähettää hiiret valittuun yksikköön. INFRAFRONTIERin www-sivuilla on hakupalvelu, josta selviää, mitä hiirikantoja on tällä hetkellä säilytettynä. Pakastettu kanta voidaan myöhemmin elvyttää eläviksi hiiriksi.”
Suomen EMMA-yksikössä Oulussa on arkistoituna 226 eri hiirikantaa. Yksi näistä on Reetta Hinttalan ja lastenneurologian professori Johanna Uusimaan löytämän harvinaisen FINCA-taudin hiirimalli. Siinä tautia aiheuttava NHLRC2- geenin toiminta on sammutettu. Aiemmin toiminnaltaan tuntemattoman NHLRC2-proteiinin on havaittu olevan elintärkeä normaalille sikiönkehitykselle sekä useiden elinten toiminnoille.

Hiiren oireiden ja muiden ominaisuuksien perusteella tehdään hiiren ilmiasun eli fenotyypin luokitus. Geenimuuntelun vaikutukset hiiren ilmiasuun selvitetään systemaattisten analyysien avulla. Näin ne kuvaavat kyseisen hiirimallin.
”Näitä analyysejä tehdään ns. hiiriklinikoissa, joissa genotyypin ja fenotyypin välisiä vuorovaikutuksia selvitetään käyttämällä kehittyneitä analyysi- ja diagnostiikkatekniikoita,” Hinttala kertoo.
Tutkijoilla on INFRAFRONTIERin kautta pääsy niin Saksan hiiriklinikkaan (German Mouse Clinic) kuin myös mahdollisuus hyödyntää maailmanlaajuisen hiiren fenotyypitystä tekevän konsortiumin IMPC:n palveluja. IMPC (International Mouse Phenotyping Consortium) selvittää tautimekanismia malleissa, joissa yksi hiiren noin 20 000 geenistä on poistettu.
Fenotyypitys tarvitsee myös kansallisen tason toimintaa. Reetta Hinttala on Biokeskus Suomen FinGMice-verkoston puheenjohtaja. Biokeskus Suomen neljä paikkakuntaa (Helsinki, Turku, Kuopio ja Oulu) rakentavat yhdessä kattavaa ja monipuolista hiiren fenotyypitysverkostoa.
”Tavoitteena on taata tutkijoille palvelua, laitteistoa sekä analysointiapua perustason sekä myös erityistason osaamista vaativiin fenotyypityksiin. Erityisen tärkeää on myös siirtää esimerkiksi isoja kuvatiedostoja kudosleikkeistä eri yliopistojen välillä, jolloin saamme tarvittaessa konsultointiapua eri puolilla Suomea olevilta asiantuntijoilta.”
Ari Turunen
23.4.2019
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Reetta Hintala, & Tommi Nyrönen. (2019). Mouse models provide insights into the causal mechanisms of diseases. https://doi.org/10.5281/zenodo.8118927
Lisätietoja:
Biocenter Oulu
https://www.oulu.fi/fi/yliopisto/tiedekunnat-ja-yksikot/biocenter-oulu
INFRAFRONTIER
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Bioinformatiikan avulla on selvitetty ihmisen perimä. Nyt uusien kuvantamistekniikoiden avulla päästään katsomaan suoraan, miten geenit vuorovaikuttavat toistensa ja ympäristön kanssa.
Nykyaikaisilla kuvantamismenetelmillä saadaan tarkkoja rakennekuvia elimistöstä. Niiden perusteella voidaan diagnosoida sairauksia, suunnitella hoitoa ja seurata hoidon tehokkuutta. Kuvantaminen on kehittynyt huimasti. Nykyisin voidaan tutkia ja analysoida myös eläviä soluja jopa yksittäisen molekyylien tarkkuudella.
Turun yliopiston ja Åbo Akademin yhteinen Turku BioImaging (TBI) tarjoaa huippuluokan kuvantamisteknologiaa tutkijoiden käyttöön. TBI myös kouluttaa tutkijoita moderneihin biolääketieteen kuvantamistekniikoihin sekä kehittää alan kansainvälisiä infrastruktuureja. Tietokonemallinnusta ja ohjelmistokehitystä tarvitaan kuvallisen datan käsittelemiseksi ja sen analysoimiseksi.
”Osa menetelmistä keksittiin jo 1950-luvulla, mutta tekninen valmius ei vielä pitkään riittänyt siihen, että tutkijat olisivat voineet niitä käyttää. Nyt tilanne on toinen. Menetelmien käyttö on ollut räjähdysmäisessä kasvussa. Tämän on mahdollistanut lasereiden ja tietokoneiden kehittyminen ja tiettyjen itsevalaisevien molekyylien löytyminen sekä superresoluutiotekniikat. Näiden kehittyneiden menetelmien ja tekniikoiden ansiosta voimme nähdä sellaisia asioita, jotka aiemmin olivat lähinnä tieteiskirjallisuutta”, sanoo TBI:n hallintojohtaja Pasi Kankaanpää.
Kuvantamisessa hyödynnetään eri tekniikoita. Turussa tarjotaan kuvantamispalveluja mm. valomikroskopiasta, elektromikroskopiasta ja atomivoimamikroskopiasta positroniemissiotomografiaan (PET) ja magneettiresonanssikuvantamiseen (MRI). Turussa voidaan analysoida myös tuhansia soluja ja niiden ominaisuuksia virtaussytometrialla.Kerätyn datan analysointiin on tarjolla useita vapaan lähdekoodin ohjelmistoja.
”Kuvantamisen merkitys on tutkimukselle suuri. Liioittelematta voi sanoa, että se on nykyään yksi tärkeimpiä osa-alueita kaikessa biologisessa ja lääketieteellisessä tutkimuksessa,” sanoo Kankaanpää.
Kankaanpää viittaa mm. Suomessa tehtyihin kyselyihin, jossa on selvitetty tärkeimpiä biolääketieteen tutkimusmenetelmiä ja niiden käyttöä. Vaikka bioinformatiikan ansiosta ihmisen ja monien muiden lajien geeniperimä on selvitetty ja biolääketieteellinen tutkimus on edistynyt huomattavasti, se ei vielä Kankaanpään mukaan riitä. Tutkimus edellyttää myös kuvantamista.
”Nyt täytyy saada tietää, mitä geenit tekevät ja miten ne vuorovaikuttavat kaikkien muiden geenien ja ympäristön kanssa. Ja mikä olisikaan parempi keino tähän kuin yksinkertaisesti katsoa, mitä tapahtuu.”
Kuvamateriaali ei Kankaanpään mukaan itsessään kuitenkaan vielä riitä tulosten saamiseksi. Viime vuosina on kehittynyt uusi tieteenala, jota kutsutaan biokuvien informatiikaksi (bioimage informatics). Se tarkoittaa menetelmiä, joilla kuvia hallitaan ja ennen kaikkea analysoidaan kvantitatiivisesti. Pelkästään yhden kolmiulotteisen solun mallin koko voi olla useita gigatavuja. Valtavaa määrää kuvadataa käsitellään siten, että siitä saadaan irti todellista informaatiota ja ymmärretään, mitä kuvissa tapahtuu. Analysointia voidaan myös automatisoida mm. koneoppimisen avulla.
”Biokuvainformatiikalle on ennustettu vastaavaa mullistavaa potentiaalia kuin mitä geenitekniikalla oli muutamia vuosikymmeniä sitten. Nyt voidaan myös kuvantamisen perusteella analysoida sairauksien syntyä ja solujen toimintaa.”
TBI tarjoaa esimerkiksi solukuvantamispalveluja, joissa hyödynnetään huippuluokan valomikroskopiaa. Laitteilla voidaan kuvantaa yksittäisiä molekyylejä tai vaikka kokonaisia pieniä, eläviä eliöitä.

Mikroskopia perustuu valon tai elektronien aaltoliikkeeseen. Nimensä mukaisesti elektronimikroskooppien valonlähteenä on elektronipartikkeleista koostuva säde, jolla näytettä pommitetaan. Elektronimikroskoopissa on valomikroskooppia huomattavasti parempi erotuskyky. Jopa tuhansia kertoja parempi erotuskyky yltää 0.2 nanometriin. Vaikka elektronimikroskoopin ansiosta saadaan kuvannettua solun sisäisiä rakenteita ja soluelimiä, sitä ei voi käyttää eläviin soluihin, sillä näytevalmistus käytännössä tuhoaa näytteen.
Turun yksiköllä on ansiokas historia mikroskopiassa. Turun biofysiikan laboratoriossa työskennellyt tukija Stefan Hell sai kemian Nobelin vuonna 2014 yhdessä Eric Betzigin ja William Moernerin kanssa erittäin tarkan valomikroskopian kehittämisessä. Hell teki Turussa ratkaisevat kokeet vuosina 1993-1996.
Valoaaltojen avulla ei saada niin tarkkaa resoluutiota kuin elektronimikroskoopilla, mutta lasereiden ja fluoresoivien molekyylien nerokkaalla käytöllä tämä rajoitus voidaan kiertää. Menetelmissä hyödynnetään fluoresenssia eli molekyylin kykyä imeä valoa tietyllä aallonpituudella ja lähettää valoa takaisin korkeammalla aallonpituudella. Fluoresoiva proteiini eli fluorofori kiinnitetään tutkittavaan molekyyliin solussa esimerkiksi geenitekniikan tai vasta-aineiden avulla. Fluoroforilla tavallaan ”värjätään” tutkittava kohde.
Käyttämällä fluoresoivia merkkiaineita niin, että niiden valoa esimerkiksi ”sytytetään” ja ”sammutetaan” eri tavoilla, voidaan uusilla valomikroskoopeilla päästä näkemään rakenteita, jotka olivat ennen nähtävissä vain elektronimikroskoopilla. Yksi tällainen menetelmä on Turussa kehitetty STED-mikroskopia (stimulated emission depletion). Sen avulla päästään jopa muutaman nanometrin, eli millimetrin miljoonasosan tarkkuuteen. Näkyvän valon aallonpituudet ovat useita satoja nanometrejä.
STED-mikroskoopilla voidaan nähdä soluelinten rakenteet ja jopa yksittäisiä molekyylejä ja niiden toimintoja kudoksessa. STED-mikroskoopilla saadaan myös kolmiulotteista kuvadataa ja sitä voidaan käyttää elävillä näytteillä.
”Olemme kuvanneet kehittyneillä valomikroskoopeilla esimerkiksi flunssaa aiheuttavia viruksia ja sitä, miten ne tunkeutuvat soluun. Kehittämillämme analyysiohjelmistoilla olemme voineet laskea, kuinka monta prosenttia viruksista on mennyt isäntäsolun sisälle ja kuin monta jäänyt ulkopuolelle. Voimme seurata, mihin virukset solussa menevät, miten nopeasti ne liikkuvat ja milloin ne hajoavat.”
Kuvantamista on käytetty mallina kehittämään nanopartikkeleita, jotka voivat kuljettaa lääkeaineita täsmäohjatusti solun sisään matkimalla näiden virusten toimintamekanismia. Esimerkiksi syövän hoitamisessa on voitu etäpesäkkeeseen laittaa katetrilla pieniä partikkeleita, joiden avulla sädehoito on kohdisteettu täsmällisesti kasvaimeen.
”Nyt saadaan kolmiulotteista kuvadataa elävästä syöpäsolusta ja nähdään, miten partikkelit liikkuvat. Samalla tavoin kuin flunssaviruksia, olemme kuvanneet, kuinka partikkelit pääsevät soluun sisälle ja miten ne hajoavat. ”
Tavoitteena on kohdistaa lääkkeen vaikutus siten, että se ei vaikuta terveisiin soluihin.
”Päämääränä on ohjata lääkeainetta suoraan syöpäsoluun, joka halutaan tappaa, eikä muihin soluihin. Näin syöpälääkkeen haittavaikutukset radikaalisti vähentyisivät. Kuvantaminen mahdollistaa tällaisen kehitystyön. Olisi hyvin vaikea kuvitella, miten tällaista työtä voitaisiin tehdä ilman modernia kuvantamista. ” sanoo Pasi Kankaanpää.
Ari Turunen
26.2.2019
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Pasi Kankaanpää, & Tommi Nyrönen. (2019). Imaging helps to highlight significance of data. https://doi.org/10.5281/zenodo.8118822
Lisätietoja:
Turku BioImaging
Euro BioImaging
https://www.eurobioimaging-interim.eu
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Mittausinstrumenteista saatua geenidataa sekä kliinistä dataa tuotetaan paljon ja helposti. Tärkeää on kuitenkin päättää hyvissä ajoin, miten ja missä muodossa raakadata tallennetaan ja miten jälkikäsitelty data luokitellaan ja kuvaillaan mittaustapahtuma mukaan lukien.
Metadata eli kuvailutieto datasta on tärkeää määritellä täsmälleen samalla tavalla kaikissa tutkimuslaitoksissa ja laboratorioissa ympäri maailmaa. Muutoin datasta ei saada maksimaalista hyötyä tutkimuksessa, koska sitä ei voida yhdistää muualla tuotettuun dataan.
”Jo omassa tutkimusryhmässä voi olla sekasotkua, jos ei ole käytetty esimerkiksi samoja tiedostoja, jolloin ne eivät ole vertailukelpoisia”, professori Aarno Palotie Helsingin yliopiston Suomen molekyylilääketieteen instituutista (FIMM) sanoo.
Kansainvälisen yhteistyön ansiosta on jo saatu muutamia standardeja aikaan. VCF (Variant Call Format) määrittelee bioinformatiikassa käytetyn tekstitiedoston, kun geenisekvenssivariaatioita tallennetaan. BAM (Binary Alignment/Map) on puolestaan formaatti, joka voidaan muuttaa luettavaan tekstimuotoon.

GA4GH (Global Alliance for Genomics and Health) on kansainvälinen vuonna 2013 perustettu allianssi, jossa on mukana yli 500 bioalan, terveydenhuollon ja IT-alan organisaatiota tavoitteenaan luoda standardeja tutkimuskäyttöön jaettavalle datalle. ELIXIR ja GA4GH päättivät aloittaa marraskuussa 2017 yhteistyön. Sopimus antaa ELIXIR -infrastruktuurille mahdollisuuden vaikuttaa kansainvälisten standardien luomisessa. Sopimus liittyy -projektiin, jonka tarkoituksena on saada datastandardit käyttöön kliinisessä potilastyössä vuoteen 2022 mennessä.
Aarno Palotie pitää ELIXIR -keskusten ja GA4GH:n yhteistyötä merkittävänä, koska nyt päästään luomaan yli 1000 organisaation kanssa standardien ohella yhteisiä periaatteita, miten dataa käsitellään ja jaetaan.
”ELIXIR -keskukset ovat hyvin verkostoituneita omissa maissaan ja voivat vaikuttaa paikallisiin käytäntöihin.”
Datan käsittely ja analysoiminen samalla tavalla ja samoin periaattein vaatii vielä työtä. Suomessa on tavoitteena mahdollistaa genomitiedon hyödyntäminen potilasterveydenhuollossa. Tarkoitus on saada aikaan kansallinen genomitietovaranto, jonka ylläpidosta vastaa Suomen Genomikeskus.
”Suomessa yritetään luoda edistyksellisiä lakeja väestön kliinisen tiedon ja genomitiedon yhdistämiseen ja hyödyntämiseen.”
Kliinisen datan ja tutkimuksessa käytettävän genomidatan yhdistämisessä pitää Palotien mielestä ottaa kuitenkin huomioon datan erilaiset käyttötarkoitukset.
”Potilaslähtöinen analyysi pitää olla juuri oikein. Siinä ei siedetä näytesekaannuksia. Datan pitää olla samassa muodossa ja helposti saatavissa, jos sitä käytetään kliiniseen päätöksentekoon. Tieteellisen genomidatan pitää puolestaan olla joustavaa, nopeasti saatavissa sekä erilaisissa tiedostomuodoissa. Vain joustavalla tavoin tutkimus etenee.”
FinnGen -hankkeessa tutkijat ovat joutuneet käsittelemään huomattavan paljon erilaisia sopimuksia. Tietosuojasäädökset edellyttävät äärimmäisen tiukasti ennalta sovittuja protokollia, mikä on Palotien mielestä ristiriidassa tutkimusideologian kanssa.
”Perustutkimus ei vain etene tällä tavalla, siis ulkoa annettujen protokollien mukaan. Tutkimuksessa prosesseja muunnellaan ja sovelletaan sitä mukaan, miten dataa tuotetaan. Kyseessä ovat toisenlaiset tavoitteet kuin kliinisen genomitiedon hyödyntämisessä.”
Koska vaateet ovat erilaisia, Palotien mukaan tarvitaan rinnakkaiset etenemisreitit kahden näin erityyppisen tiedon hyödyntämiseen. Lainsäädännössä pitäisi tarkentaa, miten kliiniseen tarkoitukseen luotua genomidataa voidaan käyttää myös tutkimuksessa.
”Sinänsä pitäisi päästä yksimielisyyteen myös siitä, miten tutkimuksessa syntynyttä tietoa voidaan joissakin tilanteissa käyttää järkevällä tavalla kliiniseen päätöksentekoon. Nyt tilanne Suomen nykyisessä biopankkilaissa on epäselvä.”
On luonnollisesti tärkeää huolehtia tarvittavasta tietosuojasta, mutta datankäytön liika tai sekava säätely aiheuttaa ongelmia tutkimukseen. Euroopassa säädösympäristö on osittain rikki. Palotie mainitsee esimerkkinä metadatan louhimiseen.
”Tutkija haluaa esimerkiksi tietää, kuinka monta sellaista yksilöä on suomalaisissa biopankeissa, joilla on tietynlainen genotyyppi ja tietty sairaus ja ikä. Ideaalitapauksessa meillä olisi käytössämme portaali, joka antaisi tämän tiedon reaaliajassa. Tutkija ei näe eikä pääse käsiksi yksilökohtaiseen dataan, jonka tietokone käsittelee konepellin alla. Silloin kun hyödynnetään henkilötietoja, jotka EU-alueella on määritelty tiukaksi, lähtökohtana on, että dataa ei saa käsitellä. Poikkeus on tutkimus, mutta tiukasti tulkittuna se voi jopa vaatia joka kerta erillisen lupaprosessin. ”
Datasta käyttö on haastavaa, koska säädösympäristöä on tulkittu lähinnä tietosuojan, ei yksiköille saadun terveyshyödyn näkökulmasta.
”Säädösympäristöä tulisi kehittää niin, että eri viranomaiset tulkitsevat lainsäädäntöä samalla tavalla, jolloin ehdottamaani portaalia voi käyttää. Tällaisen portaalin käyttö ei millään tavalla ole mikään tietosuojauhka, kun sen on asianmukaisesti rakennettu”, Palotie sanoo ja huomauttaa, että metadataan liittyvät säädökset ovat esimerkiksi Yhdysvalloissa Eurooppaa väljempiä.
”Lupaprosesseja Euroopassa on luonnehdittu byrokraattiseksi farssiksi. Lupia voidaan joutua odottamaan jopa vuosia”, Palotie huokaa.
Palotie toivoo, että Suomeen syntyvä uusi genomidataan ja rekisteritiedon toisiokäyttöön liittyvä lainsäädäntö nopeuttaa lupaprosesseja ja selkeyttää datankäyttöön liittyviä säädöksiä.
”Datapolitiikka pitää olla selkeää ja data kaikkien käytössä. Tällä hetkellä eri viranomaiset tulkitsevat lakia eri tavoin, mikä on tutkijan oikeusturvalle heikoin asia. Uudet lait toivottavasti korjaavat tämän tilanteen. Toivottavasti myös Suomen biopankkilain päivittäminen EU:n uuden tietosuoja-asetuksen (GDPR) takia on samassa linjassa muiden uusien lakien kanssa. ”
Ari Turunen
14.1.2019
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Aarno Palotie, & Tommi Nyrönen. (2019). Data harmony and standards: data must be processed, described and stored by uniform means. https://doi.org/10.5281/zenodo.8118815
Lisätietoja:
FIMM
Suomen molekyylilääketieteen instituutti (FIMM) on kansainvälinen tutkimuslaitos, jonka toiminta keskittyy sairauksien molekyylitason mekanismien selvittämiseen genetiikan ja lääketieteellisen systeemibiologian menetelmin. Tavoitteena on tutkimustiedon siirtäminen terveydenhuollon käyttöön mm. henkilökohtaista lääketiedettä edistämällä.
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Professori Aarno Palotie Helsingin yliopiston Suomen molekyylilääketieteen instituutista (FIMM) keskittyy sairauksien geneettiseen analyysiin hyödyntämällä ihmisistä kerättyä suuria datamääriä. Data-analyysien perusteella hän on tutkimusryhmineen pystynyt osoittamaan, että monien neurologisten sairauksien taustalla on lukuisia geenejä, ei yksittäinen tautia aiheuttava geeni. Esimerkiksi migreeniin, epilepsiaan tai Parkinsonin ja Alzheimerin tauteihin sairastumisen alttiuteen voi vaikuttaa satoja eri geenejä.
Aarno Palotien tutkimukset tarvitsevat valtavasti näytemääriä. Vuonna 1998 ollessaan professorina Kalifornian yliopistossa (UCLA) hänellä oli käytössään siihen asti maailman suurin migreenitutkimusaineisto: dataa oli kerätty 400 suomalaisesta migreeniperheestä. Määrä on vuosien saatossa kasvanut 1600 perheeseen. Vuosina 2007-2013 hän teki suurilla aineistoilla Cambridgessa Britanniassa migreeniin, skitsofreniaan ja epilepsiaan liittyvää tutkimusta.
Ihmisistä kerättyä kliinistä ja tutkimuksellista dataa tuotetaan ja tallennetaan jatkuvasti lisää. Mitä enemmän dataa saadaan tutkimuskäyttöön, sen tarkemmin voidaan löytää tilastollisia muuttujia. Suurista datamääristä voi löytyä paljon uutta tietoa, jos data osataan louhia ja analysoida hyvin.
”Tutkimuksissa pitää päästä hyödyntämään näytemääriä, joita ei enää mitata tuhansissa vaan jopa miljoonissa, ” Aarno Palotie huomauttaa.
”Suuret näytemäärät on kerätty eri biopankkeihin kirjavasta luovuttajakunnasta. Jotta saadaan numerot oikein isoiksi, dataa yhdistetään eri lähteistä. Näin saadaan signaali isoksi ja kohina pieneksi.”
Isolla signaalilla Palotie tarkoittaa, että datasta tulee tilastollisesti merkittävää. Esimerkiksi harvinaisten tautien louhiminen aineistosta esiin edellyttää suuria datamääriä.
Tutkijoille on arvokasta, jos data on kerätty samalla tavoin. Eri laboratorioissa ja tutkimuslaitoksissa voi olla erilaisia käytäntöjä mittausinstrumenteista saadun raakadatan keräämiseen, jälkikäsittelyyn ja luokitteluun. Mitä yhtenäisempää data on, sen helpompaa on analysointi.
”Oikeassa elämässä, esimerkiksi sairauksien tutkimisessa ehdoton harmonisointi on kuitenkin hyvin haasteellista. Siksi datan harmonisointi on tärkeää tehdä niiltä osin kun se on mahdollista, jotta valtavista datamääristä saadaan tehtyä oikeita löytöjä ja tulkintoja.”
Perinteisesti genomidataa on kerätty sekvensointitekniikoilla, joilla selvitetään koeputkissa geenien emäsjärjestys. Sekvensoinnin kustannukset ovat kuitenkin suuret, kun aineistoa tarvitaan paljon, kuten tutkittaessa tavallisia ja kroonisia tauteja. Kustannustehokkaaksi ja luotettavaksi menetelmäksi on vakiintunut genotyypitys. Genotyypityksessä DNA:n sisältämä geneettinen tieto määritetään näytteistä DNA-mikrosirutekniikalla. Näytteet luetaan mikrosiruskannerilla, jonka tuottama raakadata käsitellään. Genotyypityksessä luetaan vain ne tiedossa olevat kohdat kromosomeissa, joissa esiintyy tutkittavaan tautiin liittyviä geenivariantteja. Tämän jälkeen otetaan avuksi laskennalliset menetelmät. Referenssigenomin (useiden eri luovuttajien DNA-sekvenssien avulla luotu vertailugenomi) avulla voidaan sitten ennustaa ne variantit, joita ei ole luettu.
Genominlaajuisissa assosiaatiotutkimuksissa (GWAS) tutkittavat geenivariantit mitataan näytteistä, joiden määrä vaihtelee sadoista tuhansista miljooniin. GWAS- menetelmää käytetään erityisesti silloin, kun sairauden geneettinen tausta on monitekijäinen, polygeeninen, eli sadat tai tuhannet geenivariantit vaikuttavat sairausriskiin. Monitekijäisiä sairauksista ovat esimerkiksi sydän- ja verisuonitaudit, allergiat, diabetes ja mielenterveyden häiriöt. Luotettava GWAS analyysi edellyttää suurta tutkimusaineistoa. Aineiston analysoimiseen tarvitaan supertietokoneiden laskentatehoa.
”Sekvensointiin tarvitaan vieläkin isompia datamääriä kuin GWAS -tekniikoissa. Sekvensointi on myös GWAS -menetelmään verrattuna kallista. Datan tuottaminen GWAS -menetelmällä maksaa muutaman kympin. Menetelmää voidaan soveltaa riittävän suuriin näytemateriaaleihin. Data on standardoitua ja se säilyy hyvin. Eri paikoissa genotyypitettyjä aineistoja voidaan hyvin helposti yhdistää.”

Migreeni on päänsärkykohtauksia aiheuttava sairaus, jonka ajatellaan saavan alkunsa useimmiten ulkoisten tekijöiden aiheuttamasta häiriöstä aivorungossa. Sitä esiintyy yhdellä kymmenestä aikuisesta, naisilla kolme kertaa miehiä yleisemmin. Palotie on tutkinut migreeniä pitkään. Yhdessä tutkimuksessa hyödynnettiin näytteitä, joita oli kerätty 375 000 ihmisestä ympäri maailmaa. Näistä 60 000 oli migreenipotilaita. Vuonna 2016 hänen tutkimusryhmänsä tunnisti 30 uutta migreenin perinnöllistä riskitekijää. Moni sijaitsee verisuonien toimintaa säätelevissä geeneissä.
Vuonna 2018 julkaistiin Neuron-tiedelehdessä Palotien ja muiden tutkijoiden artikkeli, joka antoi merkittävästi uutta tietoa migreenin synnystä. Tärkeä havainto oli, että migreeniin eivät vaikuta edes migreeniperheissä vain tietyt geenit vaan suuri joukko geenejä. Palotie puhuu geenikuormasta (gene load).
”Vuosikymmeniä on ajateltu sairauksien genetiikkaa niin kuin Mendel sen kuvasi. Asia on paljon monimutkaisempi”, Palotie toteaa.
Genetiikan isäksi kutsuttu Gregor Mendel osoitti, että yksilön tietyt ominaisuudet ovat periytyviä sukupolvesta toiseen. Geenit voivat olla vallitsevia tai peittyviä. Palotien mukaan uudet tutkimustulokset ovat osoittaneet, että asia ei ole näin yksinkertainen. Esimerkiksi sairauteen voi vaikuttaa joukko geenimuunnoksia, ei välttämättä yksi geenivariantti.
”Oletuksena on ollut, että jos suvussa on ollut migreeniä, sydäninfarkteja, syöpää tai jotain muita tavallisia sairauksia, nämä sairautta aiheuttavat geenivariantit ovat vahvoja ja kulkeutuvat vanhemmilta lapsille. Migreenitutkimus yhdessä muiden tutkimusten kanssa osoittavat itse asiassa sen, että tiettyjen sairauksien taustalla on todennäköisesti hyvin tavallisten geenivarianttien kasautumista. Kyse on samoista varianteista, joita koko väestössä ilmenee. Joskus sattuu vain niin, että henkilöllä ja hänen puolisollaan on molemmilla iso geenivarianttien kuorma. Kun nämä kaksi tuhansien geenivarianttien sisältämät kuormat liittyvät yhteen, se lisää jälkeläisissä riskiä sairastua.”
Palotie ryhmineen etsii vastaavanlaisia kuormia muista neurologisista sairauksia. Nyt Palotietä työllistää suuri kansainvälinen tutkimus psykoosisairauksien geneettisestä taustasta. Aineistoa kerätään maailmanlaajuisesti yhteensä yli 100 000 ihmisestä. Geenilöydöillä uskotaan olevan suuri merkitys sairauksien ymmärtämisessä, mikä on perusta uusien hoitojen kehittämisessä.
”Kun potilaasta saadaan tarvittava määrä dataa, voidaan potilaiden hoitoa täsmentää, puhutaan täsmähoidosta ja yksilöllisemmästä hoidosta. ”

Palotie tekee tutkimusta kahdesta suunnasta: hän etsii tavallisten geenimuunnosten kasautumia, mutta myös harvinaisia geenivariantteja.
”Harvinaiset variantit voivat olla oikotie biologiaan”, hän sanoo.
Palotie mainitsee esimerkiksi skitsofreenipotilaan, jolta löytyy muutama geeni, jossa on sairauteen liittyvä vahva muunnos. Tämä on skitsofrenian tapauksessa ollessa hyvin harvinaista, koska yleensä kyseessä on tuhansien geenien yhteisvaikutuksesta syntyvä sairausalttius.
”Tällainen harvinainen poikkeus voi kuitenkin valottaa sairausmekanismeja laajemminkin. Harvinaiset, muutamat muunnokset skitsofreenipotilaassa voivat helpommin osoittaa biologisen signalointireitin solussa kuin yleisten varianttien kasautumat.”
Signalointireitin tutkiminen eli ymmärtäminen, miten solu reagoi siihen kohdistuvaa viestintään, on keskeistä sairausmekanismien ymmärtämiseksi. Solut muuttavat toimintaansa ympäristöstä saapuvien viestien mukaisesti. Usein signaali ulottuu tumaan asti, jolloin se alkaa säädellä geenien toimintaa. Joskus solussa on erityisiä proteiineja, joiden tehtävänä on katkaista signaalin kulku. Esimerkiksi syöpäsolut eivät reagoi moniin niille tarkoitettuihin viesteihin. Sen sijaan syöpäsolut vahvistavat signalointireittiä, joka saa solun jakautumaan ja täten kasvaimen kasvamaan.
Suomalaisilla on joukko geenivariantteja, jotka ovat muualla maailmassa harvinaisia, mutta meillä väestöhistoriamme vuoksi rikastuneita. Kun suomalaisten dataa yhdistetään muusta populaatiosta kerättyyn dataan, voidaan saada lisää tietoa signalointireiteistä. Japanilainen potilas voi siis hyötyä suomalaisista kerätystä datasta ja päinvastoin.
”Vaikka Suomesta löydettyä varianttia ei tunnetakaan Japanissa, ihmisen fysiologia ja biologia ovat kuitenkin hyvin samanlaisia. Löydetty variantti ohjaa toivottavasti kohti oikeaa solun signalointireittiä. Kun me tunnistamme uuden solunsignalointireitin, niin toisessa populaatiosta voidaan löytää toinen geenivariantti, joka itse asiassa liittyykin samaan signalointireittiin. Tällöin löydös vahvistaa, että signalointireitti onkin tässä taudissa merkityksellinen.”
Geenivariantin sijainnilla on merkitystä. Palotie kertoo esimerkin. Vieraillessaan Islannissa Palotie kertoi Leif Groopin tutkimuksesta, jonka tuloksena löydettiin Suomen länsirannikon populaatiosta harvinainen geenivariantti, joka suojaa kakkostyypin diabetekselta. Leif Groopin kollega tiedusteli islantilaisilta tutkijoilta, onko samanlaista varianttia löydetty islantilaisesta populaatioista. Islantilaiset tarkistivat asian omista tietokannoistaan. Samanlaista geenivarianttia ei oltu löydetty, mutta samasta geenistä islantilaiset olivat löytäneet toisen variantin.
”Tämä islantilaisten löytö vahvisti kyseessä olevan geenin suojaavan merkityksen tyypin 2 diabeteksessa. Tällainen suojaava geenivariantti on tietenkin hyvin mielenkiintoinen molekyyli lääkeainesuunnittelussa.”
Syksyllä 2017 alkoi FinnGen -projekti, jonka tavoitteena on taltioida puolen miljoonan suomalaisen genomit. Hankkeessa hyödynnetään kaikkien suomalaisten biopankkien keräämiä näytteitä. Suomalaisten perimästä saatava data on tarkoitus yhdistää kansallisissa terveydenhuollon rekistereissä olevaan kliiniseen tietoon. Tavoitteena on sairauksien parempi ymmärtäminen yhdistämällä genomi- ja terveystietoa. Vain suuria näytemääriä analysoimalla voidaan merkittävästi tehostaa potilasterveydenhuoltoa.
FinnGenin keskiössä on terveysrekistereistä saatava suomalaisten fenotyyppidata. Palotien mielestä FinnGen voidaan ottaa malliesimerkiksi siitä, miten biopankkien aineistoa ja terveysrekisteridataa voidaan yhdistää genomidataan analyyseja varten.
Hankkeessa on partnereita ympäri maailmaa. Tarkoituksena on yhdistää suomalaisten biopankkien näytteistä saatua tietoa muiden maiden biopankkien tulosten kanssa meta-analyysia varten.
”Datojen yhdistäminen on iso haaste, siksi tulosten meta-analyysi on usein toimivampi ratkaisu. FinnGenin meta-analyysia on harjoiteltu Britannian ja Japanin biopankkien kanssa. Tavoitteena on saada myös muita maita mukaan.”
Palotien mukaan on ensiarvoisen tärkeää, että suomalaisista kerätyn datan lisäksi tutkimusaineistoon pitää pystyä yhdistämään muista maista ja populaatioista tuotettua dataa. Koko ajan kehitetään uusia menetelmiä, joilla dataa käsitellään ja siitä saadaan jalostettua uutta tietoa. Uusista menetelmistä ei ole mitään hyötyä, jos tutkijoilla ei ole käytössä riittävää määrää dataa, jota analysoida ja vertailla.
”Myös tekoälyn on vaikeaa toimia ilman riittävän suurta datamäärää.”
Ari Turunen
10.12.2018
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Aarno Palotie, & Tommi Nyrönen. (2018). Hundreds of genes could lie behind a single disease. https://doi.org/10.5281/zenodo.8118783
Lue myös:
Suomalaisen väestön perimästä apua sydän- ja verisuonisairauksien hoitoon
Massiivinen datanhallintaprojekti: suomalaisten perimä kerätään talteen
Lisätietoja:
FIMM
Suomen molekyylilääketieteen instituutti (FIMM) on kansainvälinen tutkimuslaitos, jonka toiminta keskittyy sairauksien molekyylitason mekanismien selvittämiseen genetiikan ja lääketieteellisen systeemibiologian menetelmin. Tavoitteena on tutkimustiedon siirtäminen terveydenhuollon käyttöön mm. henkilökohtaista lääketiedettä edistämällä.
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org
Professori Samuli Ripatin ryhmä Suomen molekyylilääketieteen instituutissa ja Helsingin yliopiston lääketieteellisessä tiedekunnassa tutkii sydän- ja verisuonitautien syntymekanismeja geenitekniikan avulla. Suomalaisen populaation geeniperimä tarjoaa tähän hyvät mahdollisuudet.
Suomessa on noin 40 perinnöllistä tautia, jotka ovat tunnusomaisia suomalaiselle populaatiolle. Tautiperimään kuuluvat taudit johtuvat tietyistä mutaatioista, jotka ovat Suomessa muuta maailmaa yleisempiä ns. pullonkaulaefektin takia. Viimeisten 10 000 vuoden kuluessa Suomen alueelle on muuttanut suhteellisen pieni määrä uudisasukkaita. Tämän uuden populaation yksilöt edustivat pientä ja kapeaa geeniainesta, mikä sai aikaan joidenkin tautigeenien alueellisen rikastumisen.
Pullonkaulaefektistä on nyt hyötyä kun tautien geneettistä perimää selvitetään.
”Suomi on Euroopan skaalassa suurin pullonkaulaväestö. Tänne on tullut vähän ihmisiä vuosituhansien aikana. Sellaiset geenimuunnokset, jotka ovat muuttajien mukana Suomeen tulleet, voivat olla Suomessa sata kertaa yleisempiä, kuin muualla. Näin ei ole sellaisilla populaatioissa, joissa väestö on päässyt sekoittumaan. Pysyvää asutusta tuli ensin rannikkoseudulle. Ja vasta paljon myöhemmin sisämaahan ja pohjoiseen”, sanoo Samuli Ripatti.
Ripatin mukaan 1500-luvun aikana tapahtunut sisäinen muuttoliike oli toinen pullonkaula, jonka ansiosta nähdään isoja eroja Suomen väestössä idän ja lännen välillä. Vaikka populaatioisolaatteja on muuallakin, suomalaisen tautiperimän tutkimuksen tekee ainutlaatuiseksi se, että monen harvinaisen taudin geneettinen tausta on selvitetty. Tätä tietoa voidaan hyödyntää myös muita tauteja tutkittaessa.
”Nyt pystymme ymmärtämään monen geneettisesti periytyvän taudin syntyperiaatteet, jolloin tutkimustietoa voidaan soveltaa muualla. Vaikka taudit ovat erilaisia, niissä on samalla tavalla toimivia geneettisiä mekanismeja. Tämän dynamiikan ymmärtäminen on iso asia ja tarjoaa mahdollisuuksia uusien hoitojen kehittämiseen.”
Esimerkiksi Parkinsonin tautia tutkittaessa voidaan selvittää, olisiko tauti yleisempää jossakin osassa Suomea. Jos näin on, voi tämän osan maata tutkiminen tuottaa uutta geneettistä tietoa.
Ripatti on kiinnostunut populaatiogenetiikasta ja suomalaisten geneettisestä vaihtelusta. Vuodesta 2013 hän on toiminut biometrian professorina Helsingin yliopiston lääketieteellisessä tiedekunnassa. Biometria on tilastotieteen ala, joka on keskittynyt biologisten aineistojen analysointiin. Ripatin tutkimusryhmä yhdistää tilastolliset menetelmät ihmisen perimän sekvenssitason mittauksiin.
”Sekvensoinnilla saadaan tietoa geneettisestä vaihtelusta, joka voi olla pienessä populaatiossa harvinaista. Vaihtelun perusteella voidaan nähdä tiettyjen tautiriskiä muokkaavien geneettisten muutosten yleisyys jollakin Suomen alueella tai osoittaa altistuminen tiettyyn tautiin.”
Näin populaation geenidatasta voidaan yrittää seuloa arvokasta tietoa terveysvaikutuksista. Voidaan löytää henkilöt, joilla on korkea riski sairastua ja samalla etsiä keinoja tautien ehkäisemiseen.
”Me katsomme asiaa kansantautien näkökulmasta. Tutkimme Suomessa yleisiä tauteja, joita ovat esimerkiksi sydän- ja verisuonitaudit ja diabetes.”
Vaikka näihin tauteihin vaikuttavat esimerkiksi ruokavalio ja muut elämäntavat, myös perinnölliset tekijät ovat merkittäviä. Siksi tauteja kutsutaankin Suomessa kansantaudeiksi. Ripatin ryhmä on Suomen pullonkaulaefektin ansiosta tunnistanut geenimuunnoksia, erityisesti sydän- ja verisuonitaudeille altistavia geenejä sekä verestä mitattuja sairautta ennakoivia ja merkkiaineita sääteleviä geenejä. Ripatti ottaa esimerkiksi korkean kolesterolitason.
”Ne joilla on korkeat kolesterolitasot, voidaan ottaa tutkimuksiin ja heidän perimänsä sekvensoida tehokkaasti ja helposti. ”
Sydän- ja verisuonisairaudet aiheuttavat kolmanneksen kuolinsyistä maailmassa. Eniten siihen sairastuneita on Keski-Aasiassa ja Itä-Euroopassa. Suomi oli 1960-luvulla maailman kärkisijalla keski-ikäisten miesten sepelvaltimotautikuolleisuudessa. 2000-luvulle tultaessa miesten kuolleisuus oli vähentynyt noin viidennekseen korkeimmasta tasosta.
Alueelliset erot sydän- ja verisuonitautien sairastavuudessa ja kuolleisuudessa ovat kuitenkin Suomessa suuret. Tautien esiintyminen on Länsi- ja Etelä-Suomessa muuta maata selvästi vähäisempää. Tämä suuri alueellinen ero kiinnostaa tutkijoita. Länsi-Suomen väestöstä on löytynyt ns. sammuneita geenejä, jotka suojaavat diabetekselta ja sydän- ja verisuonitaudeilta.
Yksi kiinnostavia tutkimuskohteita on geenin muuttaminen tai muuttuminen toimintakyvyttömäksi. Tällaisia geenejä kutsutaan sammuneiksi geeneiksi. Professori Aarno Palotien johtamassa tutkimuksessa analysoitiin yli 80 harvinaista, mutta Suomessa muuta maailmaa yleisempää muutosta, joka hiljentää koko geenin. Aineisto saatiin yli 30 000 suomalaisen geeniperimästä.
Suomalaisilla on itse asiassa muita kansoja enemmän geenejä, jotka sammuttavat yksittäisen geenin toiminnan.
”Proteiinituotannon katkaisevat geenivariantit ovat ihmispopulaatioissa aika harvinaisia. Kuitenkin Suomeen uudisasukkaiden mukana tulleet proteiinituotannon katkaisevat geenivariantit ovat meillä muuta Eurooppaa yleisempiä ja siksi niiden tänne aikanaan saapuneiden varianttien terveysvaikutusten tutkiminen on Suomessa paljon helpompaa kuin muualla.”
Länsi-Suomen väestöstä on löydetty sellaisia poistogeenejä, joiden toimintakyvyttömyys ei aiheuta terveydellisiä ongelmia. Päinvastoin, ne suojaavat kantajaansa diabetekselta tai sydän- ja verisuonitaudeilta.
”Suomesta on löytynyt geenimuunnos, joka suojaa diabetekselta. Variantin kantajilla oli vähemmän diabetestä muihin verrattuna. Geenimuunnoksen kantajia on Pohjanmaalla enemmän kuin muualla maailmassa. Tästä voi olla hyötyä lääketeollisuudelle, jos pystytään matkimaan molekyylivalmisteilla tällaisen geenin toimintaa.”
Toinen esimerkki on lipoproteiini (a)n toimintaa ehkäisevä geeni. Sydäntautiriskiä voidaan arvioida mittaamalla verestä lipoproteiini (a). Lipoproteiini (a) eli LPA on LDL-kolesterolia kuljettavan lipoproteiiniperheen jäsen. Aineistosta löytyi esimerkiksi geenimuutoksia, joiden kantajilta puuttuu lähes kokonaan LPA-geenin tuottama lipoproteiini (a). Ihmiset, joilta lipoproteiini a puuttuu, sairastuvat muita harvemmin sydän- ja verisuonitauteihin.
”LPA-geenistä löytyy pari varianttia, jotka sulkevat pois sen toimintaa. LPA-proteiinia on tällöin veressä vähemmän, jolloin matalan tiheyden kolesteroli kiertää verenkierrossa vähemmän. Tällöin syntyy vähemmän verisuonitauteja. Proteiinitason alentaminen farmakologisin keinoin olisi mahdollista.”
Suomessa on tutkittu myös USF-1-geenin toimintaa. Ihmisillä geeni vaikuttaa veren rasva-arvoihn ja kolesteroliin. Kun geenin toiminta poistettiin hiirellä, veren hyvä HDL-kolesterolipitoisuus nousi.

SISu-hankkeen (Sequencing Initiative Suomi) ansiosta tiedot suomalaisten geneettisestä vaihtelusta on koottu yhteen tietokantaan.
”Sekvensoitu näyteaineisto on kerätty suomalaisista potilaista ja vapaaehtoisista. Aineistosta on laskettu tilastotietoa siitä, kuinka yleinen kunkin geneettisen variantin yleisyys on Suomessa. Kun on kerätty tarpeeksi iso tietokanta, niin saadaan selville minkälainen on ylipäätään suomalainen genominen variaatio.”
SISu-tietokannassa on tällä hetkellä perimän proteiineja koodaavat variantit reilulta 10000 suomalaiselta ja kaikkiaan koko perimäkin on sekvensoitu jo monelta tuhannelta suomalaiselta.
”SISu-tietokannan sekvenssidata antaa meillä mahdollisuuden täydentää meidän muita edullisemmilla genomisiruilla mitattuja aineistoja tilastollisilla imputaatioalgoritmeilla. Nyt pystymme aika tarkasti sanomaan minkälaisia geenivariantteja suomalaisilla on. Esimerkiksi jos yksi tuhannesta kantaa Suomessa tiettyä geenivarianttia, niin tällöin keskimäärin ainakin 20 henkilöltä pitäisi löytyä variantti nykyisestä tietokannasta.”
Tietokannasta on jo nyt apua potilaiden diagnostiikassa.
”Variaatiodata on tietokannassa ja dataa hyödynnetään koko ajan, erityisesti kliinisessä genetiikassa. Lähtökohta on, että sairaalan potilaan hoitoon saadaan lisäselvitystä tietokannasta. Jos siis epäillään, että geenissä oleva variantti saattaa olla taudin syynä, niin lääkäri tarkistaa tietokannasta kuinka usein suomalaisissa tätä varianttia esiintyy. Jos se on yleinen, ei ole todennäköistä, että se olisi harvinaisen taudin syynä. Jos se on harvinainen ja sen vaikutus geenin toiminnalle on merkittävä, niin todennäköisyys variantin merkitykselle myös taudin puhkeamisessa kasvaa. Tämä on hyvin konkreettinen kliininen käyttö tietokannalle.”

SISu-projektin dataa on kerätty tutkimusprojekteista ja potilaista. Projekti on kuitenkin keskittynyt pelkästään genomidataan, jolloin datan hyödyntämismahdollisuudet terveystutkimuksessa ovat rajalliset.
”Kaikista meistä pitäisi saada kerättyä talteen biopankkinäyte”, sanoo Ripatti. ”Ne, joilla on alttius sairastumiseen, pitäisi seuloa tarkemmin.”
Samuli Ripatin mielestä on suuri puute, että genomitietoa ei vielä ole saatavissa terveystarkastusten yhteydessä. Se pitäisi olla osana jokaisen rutiinitarkastusta, jotta voitaisiin tehdä konkreettisia päätöksiä hoidolle.
”Suomessa olisi tähän hyvät edellytykset. Meillä on hyvin toimiva työterveyshuolto ja perusterveydenhuolto sekä hyvä osaaminen geenitutkimuksessa.”
SISu:n jatkoksi alkoi elokuussa 2017 FinnGen-projekti, jossa taltioidaan puolen miljoonan suomalaisen genomit. Hankkeessa hyödynnetään kaikkien suomalaisten biopankkien keräämiä näytteitä. Perimästä saatava data yhdistetään kansallisissa terveydenhuollon rekistereissä olevaan tietoon.
”Työkalut riskiarviontien tekemiseen ovat olemassa ja tilastollisia malleja on kehitetty usealle taudille. Perimästä saadun datan tulkitseminen osana rutiiniterveydenhoitoa on lähivuosien tavoite. FinnGen osaltaan mahdollistaa tämän.”
Ripatti ryhmineen osallistuu tilastollisten algoritmien kehittämiseen, implementoimiseen ja testaamiseen.
”Kehitämme ennustealgoritmeja, jossa arvioidaan esimerkiksi sydän- ja verisuonitautien riskiä potilaalla. Yhdistämme genomidatan ja elintapatekijät, jonka perusteella tehdään ennuste. Haemme siis keinoja, jotka motivoivat potilasta muuttamaan elintapojaan.”
Ripatin ryhmä täydentää tilastollisilla algoritmeilla myös genomista tietoa. Suomen populaatiohistoriasta johtuen täällä pystytään ennustamaan paremmin ja tarkemmin kuin juuri missään muualla maailmassa puuttuvat genotyypit sirudatoihin. Algoritmi toimii hyvin suomalaisessa datassa, koska suomalaisten genomit ovat keskimäärin enemmän samankaltaisia kuin muualla. Laskennallisesti täydennetään sekvenssidatalla geenisiruilla kerättyä dataa.
”Jos oleelliset variaatiokohdat skannaavalla geenisirulla on 500 000 geenimerkkiä ja meillä on näiden mittausten lisäksi tiedossa geenisekvensseistä 30 miljoonaa genomivarianttia, me voimme täydentää geenisirulla tehdyn mittauksen kokonaiseksi genomisekvenssiksi hyvillä tilastollisilla laatumittareilla. Näin saadaan luotua riittävän luotettavia kokonaisia genomeja lisää huokeammin. Koko genomin sekvensointi on toistaiseksi huomattavasti kalliimpaa.”
Genomidatan säilyminen tulevaisuudessa ja sen analysointiympäristön suunnittelu on iso asia, jossa ELIXIR-infrastruktuurilla on keskeinen rooli.
”Meillä on olemassa tietovaranto, jota luvan saanut tutkija voi hyödyntää. Tietovarannon ollessa suuri, täytyy tutkijalle tarjota tietoturvallinen ja tehokas data-analyysiympäristö, jossa dataa voi tutkija analysoida.”
Tietosuojan takia parhain ratkaisu olisi esimerkiksi etätyöpöytä. Eri maiden populaatiodatasta tällä hetkellä on satoja kopioita eri tutkimusryhmien levypalvelimilla ympäri maailmaa. Se on suunnaton määrä dataa.
”Toisaalta meillä täytyy tulevaisuudessa olla genomidatan analysointiin soveltuvia ratkaisuja, jotka mahdollistavat valtavien aineistojen tehokkaan ja hajautetun tallennuksen ja analysoinnin. Tätä haastetta eivät nykyiset paljon vaatimattomampien datamäärien aikanaan kehitetyt suljetut etätyöpöytäratkaisut ratkaise vaan tarvitaan avoimia, tehokkaasti pilvipalveluita ja kansainvälistä yhteistyötä hyödyntäviä laskentaympäristöjä. Tämän miettiminen on ihan keskeistä.”
Ari Turunen
5.11.2018
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Samuli Ripatti, & Tommi Nyrönen. (2018). Help from the Finnish genome for the prevention of cardiovascular diseases. https://doi.org/10.5281/zenodo.8118771
Lue myös:
Massiivinen datanhallintaprojekti: suomalaisten perimä kerätään talteen
Lisätietoja:
FIMM
Suomen molekyylilääketieteen instituutti (FIMM) on kansainvälinen tutkimuslaitos, jonka toiminta keskittyy sairauksien molekyylitason mekanismien selvittämiseen genetiikan ja lääketieteellisen systeemibiologian menetelmin. Tavoitteena on tutkimustiedon siirtäminen terveydenhuollon käyttöön mm. henkilökohtaista lääketiedettä edistämällä.
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Laskennallisilla menetelmillä voidaan data-aineistosta nykyään päätellä keillä on riski sairastua esimerkiksi diabetekseen tai syöpään. Laura Elo tutkimusryhmineen kehittää menetelmiä, joiden avulla etsitään erilaisia sairauksien ennustemerkkejä. Yhdistämällä kliinistä dataa geeniperimästä saatuihin tietoihin saadaan myös arvokasta tietoa sopivasta lääkehoidosta.
Ihmisen biologian tutkimus tuottaa paljon uudenlaista dataa tutkijoiden tulkittavaksi. DNA:n sekvensointi tuottaa yksilön geneettisen profiilin. RNA:n sekvensointi puolestaan antaa mittausdataa geenien aktiivisuudesta. Se kertoo, mitkä geenit milloinkin ilmenevät ja muun muassa tuottavat proteiineja soluissa.
Kudosnäytteestä voidaan mitata tuhansia eri molekyylejä ja niiden välisiä vuorovaikutuksia. Voidaan esimerkiksi tutkia geenin erilaisia aktiivisia muotoja, transkripteja. Kun pyritään selvittämään proteiinien toimintaa tai niiden poikkeamia tautien yhteydessä, puhutaan proteomiikasta. Apuna käytetään massaspektrometreja, joilla mitataan molekyylimassa.
Turun biotekniikan keskuksen bioinformatiikan tutkimusjohtaja Laura Elo ja hänen tutkimusryhmänsä kehittävät mallinnusmenetelmiä, joiden avulla seurantatutkimuksissa kerättyä mittausdataa voidaan hyödyntää sairastumisriskin määrittämiseen yksilökohtaisesti.
”Aloitin urani matemaatikkona aikana, jolloin bioinformatiikka oli vielä marginaalista. Sitten innostuin laskennallisesta biologiasta ja lääketieteestä”, Elo kertoo.

Yksi tärkeä tutkijoiden aineisto on eri populaatioista kerätty data. Tutkimuksissa käytetään Turun alueen Auria-biopankkiin tallennettua dataa sekä muualta Suomesta ja muista maista saatua dataa. Lisäksi sairaaloiden sähköisissä järjestelmissä on paljon potilaiden hoidosta kerättyä dataa, jota voidaan luvanvaraisesti käyttää tutkimuksessa. Näytteistä kerätty data ei kuitenkaan yksin riitä selvittämään tautien syntyä ja kehittymistä. Tarvitaan laskennallisia menetelmiä ja malleja, jotta datamassoista voidaan saada ymmärrettäviä tulkintoja. Tarkoituksena on kehittää toimivia malleja lääkäreiden käyttöön.
”Lähes kaikki tutkimuksemme liittyy lääketieteeseen ja lääkäreiden tarpeisiin. Tarkoituksenamme on tarjota toimivia työkaluja lääkäreille. Kaikesta tästä datamäärästä ei saada tarpeeksi hyötyä, jos sitä ei pystytä mallintamaan ja tulkitsemaan. Työmme avulla potilaille pystytään toivottavasti tulevaisuudessa tarjoamaan hoitomenetelmiä, jotka ovat yhä enemmän yksilöllisesti kohdennettuja.”
Tehokas hoito on aina yksilöllistä, koska lääkkeet ja hoitomenetelmät tehoavat eri yksilöihin eri tavoin. Potilaan hoitovasteeseen vaikuttaa joukko tekijöitä, joista saadaan tietoa mm. laboratoriomittauksista. Kliinisten, potilaan terveydentilaan liittyvien muuttujien lisäksi on paljon esimerkiksi geeni- ja proteiinitason tekijöitä, jotka vaikuttavat hoitomenetelmien tehoon. Yksilöstä saadun datan analysoimisessa matematiikka tulee apuun.

”Biologia on monimutkaista. Näennäisesti yksi sairaus voi molekyylitasolla ilmetä eri ihmisissä monin eri tavoin, ja eri potilaille tehoaa erilainen hoito. Toisille tietty lääkehoito voi aiheuttaa pahoja haittavaikutuksia, toisille lääke ei tehoa. Laskennallisilla menetelmillä pystymme ennustamaan lääkkeiden haittavaikutuksia ja näkemään kenelle lääke sopii. Me matemaatikot voimme auttaa lääketieteilijöitä tunnistamaan näitä tekijöitä”, Elo sanoo.
Toimivat matemaattiset mallit edellyttävät raaka-aineekseen suuria datamääriä. Esimerkiksi osa malleista on kehitetty Yhdysvalloista saadusta kliinisestä potilasdatasta, mutta ne sopivat myös Turun yliopistollisen sairaalaan potilasdataan.
”Kun saadaan riittävän iso määrä genomidataa ja kliinistä dataa, ne voidaan yhdistää ja päästään mallinnusvaiheeseen. Yhdistely on mahdollista vain, jos datan kuvaus, metadata, on kunnossa.”
Mallien kehittämisessä pitää ottaa huomioon monia asioita. On tärkeää arvioida mallin ennustuskykyä etukäteen. Mallit yleensä ylisovittuvat (over-fitting) dataan, jolla ne luodaan. Tällä tarkoitetaan sitä, että malli sopii dataan liian hyvin. Ennustemalli siis toimii yhdellä datalla, mutta ennuste ei olekaan enää hyvä uudella datalla. Mallin todentamiseksi tarvitaan validointia. Se onnistuu esimerkiksi käyttämällä potilasaineistoa toisesta sairaalasta tai maasta. Mallin tarkistaminen käyttämällä muuta potilasdataa on tärkeää, jotta malli voidaan ottaa yleisesti käyttöön. Tässä apuna ovat eri biopankkien data.
”Jos mallin tekee samasta datasta, sen voi saada toimimaan lähes täydellisesti, mutta uusiin yksilöihin se ei välttämättä toimi. Pyrimme siis löytämään datasta sellaisen kombinaation, päätössäännön, joka ennustaa lopputulosta mahdollisimman tarkkaan mutta kuitenkin niin, että se yleistyy uusiin datoihin.”
Laura Elon ja hänen tutkimusryhmänsä työ mallintamisen parissa on jatkuvaa kokeilua ja muutosta.
”Kehitämme malleja ja pyrimme näyttämään ensin tietyissä aineistoissa, että malli toimii. Sen jälkeen validointia jatketaan ja etsitään mahdollisimman monia uusia aineistoja, joissa mallin tuottamia ennusteita voi testata. Aina voi kehittää mallin joka toimii yhdessä aineistossa. Mutta vasta kun monessa aineistossa on todettu, että ennustemalli toimii luotettavasti, se voidaan antaa lääkäreiden päätöksenteon tueksi. Mitä laajemmin mallia pystytään testaamaan sen paremmin voimme arvioida, toimiiko se vain tietylle populaatiolle vai onko se yleispätevä.”
Malleihin lisätään uusia tekijöitä ja analysoidaan, miten ne vaikuttavat ennusteisiin. Esimerkiksi lineaarisia, yksinkertaistavia malleja on helppo hahmottaa ja tulkita sairaaloissa. Välillä molekyylien vuorovaikutukset ovat kuitenkin niin monimutkaisia, että lineaariset mallit eivät toimi ja tarvitaan muita ratkaisuja.
”Mitä enemmän uusia muuttujia lisätään malliin, sitä kriittisemmäksi tulee mallin validointi. Tärkeä kysymys on ymmärtää, mitkä muuttujat yksinään ovat merkittävimpiä ennustamiselle ja miten niiden kombinaatiot erilaisilla painoarvoilla ennustavat parhaiten. Pitää löytää tasapaino malliin: sen pitää olla riittävän kompleksinen pystyäkseen ennustamaan, mutta mallia ei saa ylisovittaa dataan.”

Laura Elo on ryhmineen ollut mukana munuaissyövän ennustemalleja kehittämässä. Munuaissyöpä saa alkunsa munuaisen kuorikerroksen epiteelisoluista. Munuaissyövän ennuste on huono, sillä 40% potilaista kuolee siihen viiden vuoden kuluessa.
Uuden laskennallisen menetelmän avulla voidaan löytää ennustemerkkejä potilasnäytteistä. Tutkimuksessa havaittiin, että 152 geenin ilmentymä pystyy ennustamaan munuaissyöpää sairastavien potilaiden elinaikaa leikkauksen jälkeen.
”Munuaissyövän ennuste on yleensä hyvä, jos syöpäpesäke on paikallinen. Keskimäärin puolelle potilaista kehittyy kuitenkin etäspesäkkeitä leikkauksen jälkeen. Tavoitteena on, että pystyttäisiin mahdollisimman aikaisin näkemään onko potilaan ennuste hyvä vai huono, jotta voidaan valita paras hoitostrategia.”
Ennustemallin kehittämisessä hyödynnettiin kahta eri aineistoja. Yli 400 munuaissyöpäpotilaan geeni-ilmentymätiedot saatiin kansainvälisestä Cancer Genome Atlas (TCGA) -tietokannasta. Tutkimusryhmä vahvisti mallin toimivuuden käyttämällä riippumatonta japanilaista 100 potilaan aineistoa.

Laura Elo etsii potilasaineistosta erilaisia biomarkkereita, jotka voivat ennustaa sairauksien puhkeamisen tai kertoa jotakin hoitovasteesta. Biomarkkeri on tekijä tai ominaisuus, joka ilmentää biologisen tilan muutosta esimerkiksi geeneissä tai proteiineissa. Suomessa on pitkään yritetty selvittää tyypin 1 diabeteksen syntymekanismeja. Ykköstyypin diabetes johtuu insuliinia tuottavien solujen tuhoutumisesta. Haima ei tuota elimistön tarvitsemaa insuliinihormonia, jolloin verensokeri kohoaa.
”Suomessa ykköstyypin diabetesta sairastetaan suhteessa väkilukuun eniten maailmassa. Sekä geeniperimällä että ympäristötekijöillä on sairauden syntyyn jokin osuus. Etsimme diabetekseen sairastuneista biomarkkereita, jotka voisivat kertoa jotakin taudin kehittymisestä.”
Koska Suomessa on maailmassa eniten suhteessa asukaslukuun ykköstyypin diabetesta, on myös diabeteksen tutkimus täällä merkittävää. Jo vuonna 1994 Suomessa aloitettiin DIPP (Diabetes Prediction and Prevention) eli diabeteksen ennustamiseen ja ehkäisemiseen tähtäävä kunnianhimoinen ja laaja tutkimusprojekti. Vastasyntyneiltä etsitään verinäytteistä tyypin 1 diabetekselle altistavia perintötekijöitä. Lapset, joilla todetaan geneettinen riski sairastua diabetekseen, kutsutaan seurantatutkimukseen. Näytteitä otetaan joka kolmas kuukausi ja 2-vuotiaasta eteenpäin puolen vuoden tai vuoden välein. Seulontaan osallistuvat Turun, Tampereen ja Oulun yliopistolliset keskussairaalat.
”Niitä lapsia, joilla on geneettinen riski sairastua, on seurattu 15 ikävuoteen saakka. Tavoitteena on, että pystyttäisiin tunnistamaan sairauden syntyyn vaikuttavia tekijöitä solutasolla jo ennen kuin se pystytään nykykeinoin diagnosoimaan. ”
Laura Elo tekee yhteistyötä professori Riitta Lahesmaan kanssa. Lahesmaan ryhmässä tutkitaan valkosoluja ja yritetään ymmärtää, mitkä asiat tekevät soluista diabetesta aiheuttavia. Näin voitaisiin tulevaisuudessa estää diabeteksen syntyminen sekä parantaa siihen sairastuneet.

Laura Elo haluaa jatkossa keskittyä tautien syntymekanismeihin ja sairastumisen riskitekijöihin. Eri tekijöiden monimutkaisten vuorovaikutusten tilastollinen mallintaminen edellyttää monia uusia menetelmiä ja mittausteknologioita, joita tutkijat kehittävät ja kokeilevat.
Tilastollisen mallinnuksen lisäksi Elo ryhmineen soveltaa koneoppimisen eri tekniikoita ennustavien mallien tekemiseen. Kone opetetaan seulomaan datasta olennaisia tekijöitä. Kone voi esimerkiksi oppia ennustamaan binäärisesti taudin lääkehoidon seuraamukset: hyvä vaste/huono vaste.
”Uudet työkalut ja menetelmät on tuotava mahdollisimmat lähelle potilasta. Pohdimme koko ajan sitä, mitä pitää tehdä, jotta mallia voidaan hyödyntää potilaiden hoidossa. Mitä ja miten pitäisi mitata? Onko jotain, joka voitaisiin tehdä paremmin? Mallin on oltava riittävän yksinkertainen ja helppokäyttöinen, että se päätyy klinikalle lääkärin päivittäiseen työhön. Tärkeää on tietää, miten lääkärit niitä käyttävät.”
”Olennaista tässä työssä on, että tämä on tieteiden välistä. Miten paljon enemmän laskennan avulla voidaankaan saada informaatiota kuin että samaa aineistoa käytäisiin vain käsin läpi. Laskennasta on tullut osa lääketiedettä.”
Turun biotekniikan keskuksella on oma tietokoneklusteri, jonka laskentakapasiteettia täydentää yhteys Suomen ELIXIR-keskuksen CSC:n ePouta-pilvipalveluun.
”ELIXIRin tarjoama laskentakapasiteetti ja työkalut helpottavat muiden organisaatioiden tuottaman datan hyödyntämistä. Eurooppalaisen datan hyödyntäminen on tärkeää, mutta datan pitäisi olla standardoitua. Datan saaminen yhteensopivaksi on ison infrastruktuurin tehtävä.”
Ari Turunen
8.10.2018
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Laura Elo, & Tommi Nyrönen. (2018). Disease prediction models are becoming more accurate thanks to the computational methods. https://doi.org/10.5281/zenodo.8118762
Lisätietoja:
Turun yliopiston Lääketieteellisen Bioinformatiikan keskus:
Suomen ELIXIR-keskuksen CSC:n tarjoamat bioinformatiikan palvelut:
https://research.csc.fi/biosciences
Biotools, ELIXIRin tarjoama valikoima bioinformatiikan työkaluja:
https://www.elixir-europe.org/services/tools/biotools
ELIXIR tekee yhteistyötä genomitiedon hyödyntämiseksi yhdysvaltalaisen GA4GH:n (Global Alliance for Genomics and Health) kanssa.
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Bioalan tutkimus tuottaa hurjan määrän dataa ja määrä kaksinkertaistuu muutaman kuukauden välein. Siksi datan hallinnointi edellyttää kehittyneitä työkaluja. Nämä on mahdollista toteuttaa julkisten biologisen tiedon infrastruktuurien ja yritysten, kuten ELIXIRin ja BC Platformsin yhteistyössä.
BC Platforms tarjoaa tietojärjestelmiä genomidatan hallintaan. Sen kehittämät kaksi järeää tietokantaa ovat käytössä myös ELIXIR-infrastruktuurissa Suomen ELIXIR-keskuksen CSC:n kautta. BC Platforms on nyt luomassa ekosysteemiä, jossa eri maiden biopankkien data-aineistoihin voidaan tehdä hakuja yhteisen käyttöliittymän avulla.
BC Platformsilla on yli 20-vuotinen historia suurten datamassojen käsittelystä. Yrityksen tiedonhallintajärjestelmät voidaan laittaa paikalliseen laskentaympäristöön tai pilveen. Taustalla toimii virtuaalinen tiedostojärjestelmä. Käyttäjät kirjautuvat tietokantaan ja hakevat aineiston palvelimelta. Käyttäjien tekemät muutokset tallennetaan sitten takaisin tietokantaan eli tiedostoja viedään ja tuodaan valtavia määriä käyttäen suojattua tietoverkkoa. Tämä ns. objektipohjainen tallennus sopii erityisesti silloin, kun dataa on säilytettävä pitkään ja samalla otettava huomioon tietoturva.
BC Platformsin asiakkaiden analysointien kohteet vaihtelevat yksittäisen ihmisen tai eläimen datasta jopa miljoonien yksilöiden kohortteihin. Asiakkaina on myös tutkimusorganisaatioita, jotka tuottavat jopa 10 000 genomia päivässä.
BC Platforms haluaa luoda avoimen ekosysteemin tutkijoiden, lääkeyhtiöiden ja biopankkien välille. BC RQUEST-palvelu välittää tietoja eri biopankkien sisältämästä datasta. Palvelun käyttöliittymän kautta tutkijat ja lääkeaineiden kehittäjät pääsevät näkemään keskitetysti yhteistyöverkostoon kuuluvien biopankkien aineiston.
Jokaiseen ekosysteemiin liittyneessä biopankissa on BC Platformsin kehittämä moduuli, joka välittää biopankkien dataa palveluun. BC Platformsin pääarkkitehti Timo Kannisen mukaan yhteinen biopankkien käyttöliittymä hyödyttää kaikkia.
”Autamme lääkeyhtiöitä löytämään oikeat biopankit, joihin on tallennettu niille merkittävää dataa. Esimerkiksi hakusanalla ”astma” pääsee näkemään kuinka monen astmapotilaan aineistoja on tallennettu eri maiden biopankkeihin. Aiemmin on täytynyt lähettää yksittäisen biopankin ylläpitäjälle sähköpostia ja kysellä kuinka monta astmapotilasta siellä on ja odottaa vastausta.”
Ohjelmisto tuottaa automaattisesti aggregaattidataa eli dataa, joka kerätään useasta lähteestä. Koska se ei sisällä henkilökohtaista tietoa, dataa voidaan siirtää maiden rajojen ulkopuolelle. Tunnistetut biopankkien datat voidaan yhdistää järjestelmässä, kun siihen on saatu lupa.
”Hakuja voi tehdä olemassa olevaan dataan älykkäästi. Palvelu ja ekosysteemi saattavat yhteen datanhaltijat, tarjoajat ja käyttäjät. Koska käyttäjät ovat lääkkeitä kehittäviä yhtiöitä, ne haluavat usein määritellä tarvitsemansa datan. Analyysityökalumme soveltuvat hyvin tähän käyttötarkoitukseen.”
Timo Kannisen mukaan tavoite on saada viiden miljoonan potilaan kliininen ja genominen data yhteisen käyttöliittymän hakutoimintojen alle vuoteen 2020 mennessä.
”Nyt pystytään laajasti näkemään minkälaista dataa on saatavilla. Rekrytoimme koko ajan ekosysteemiin lisää biopankkeja, joilla on kliinisen tiedon lisäksi genomidataa. Lääkeainesuunnittelijat hyötyvät tästä, sillä löydökset voidaan todentaa toisessa populaatiossa.”
BC Platformsin sovellus tuottaa metadataa automaattisesti, mikä parantaa mahdollisuuksia tehdä hakuja biopankkien aineistoihin. BC Platforms luokittelee metadataa olemassa olevien standardien pohjalta. Metadatan harmonisointi on kuitenkin edelleen haaste tehokkaalle tietojenkäsittelylle. Kirjaamiskäytännöt vaihtelevat maasta ja sairaalasta riippuen.
”Yleensä ikä, sukupuoli ja diagnoosi tiedetään, mutta leikkaukset, operaatiot ja laboratorioarvot on usein kirjattu epäyhteneväisellä tavalla. Haasteita lisäävät vielä eri tietojärjestelmät”, sanoo Kanninen.
Bioalan yritykset eivät jää odottamaan standardoinnin tuloksia, jos siihen menee vuosia. On pakko miettiä omia ratkaisuja. Metadatan harmonisointi ja standardointi sekä julkisten tietokantojen tarjoaminen standardimuodossa olisi kuitenkin erittäin iso helpotus ja resurssi. Tähän pyrkii ELIXIR.
Geenidataa käytetään entistä enemmän potilaiden hoidossa ja teollisuudessa. BC Platformsin asiakkaana on yksi maailman suurimpia geenitestejä tuottavia yrityksiä, jolle BC Platforms tuottaa geenidatan. Suomalaiset tutkimusryhmät hyödyntävät BC Platformsin järjestelmiä kasvien, eläinten ja ihmisten genomien analysoimisessa. Helsingin yliopistossa tehdään mm. eläinjalostukseen liittyvää tutkimusta ja tutkijat tarvitsevat työkaluja genomidatan hallintaan. BC Platformsin järjestelmällä analysoidun datan avulla haetaan myös uusia lääkkeiden vaikutuskohteita ja tutkitaan lääkeaineiden tehoa ja turvallisuutta.
”Digitoimme geenidatan sellaiseen muotoon, mitä tutkijat tarvitsevat analyyseissaan. Sen voi sitten yhdistää muuhun dataan, esimerkiksi kliiniseen dataan tai potilasdataan”, sanoo BC Platformsin kehitysjohtaja Anita Eliasson.
Syöpätutkimuksessa voidaan hyödyntää genomidataa, kun selvitetään potilaan syöpätyyppiä. Genomidatan perusteella voidaan tietää, minkälainen on lääkevaste ja minkälaista hoitomuotoa kannattaa suositella.
”Käytämme julkisia tietokantoja, joissa on tietoa minkä tyyppisellä genomilöydöksellä on tyypillisesti tiettyjä hoitovasteita tai mistä syöpätyypistä on kyse kun henkilöllä on tietty perimä. Tämä yhdistetään muuhun tietoon. Potilasta osataan hoitaa alusta lähtien oikein, mikä säästää aikaa ja rahaa. Pelastetaan henkiä, kun osataan valita oikea lääke.”
Vaikka päätietokantajärjestelmä on BC Platformsin kehittämä, Eliasson painottaa, että BC Platforms on ekosysteemiyritys, jolle tärkeää on kumppaniverkosto.
”Olemme kehittäneet pitkään tietojärjestelmiämme yhdessä tutkijoiden kanssa. Nyt on edessä uusi vaihe geenitutkimuksessa, sillä tietoa tarvitaan myös muuhun kuin tutkimuskäyttöön. Emme pyri tarjoamaan analyysipalvelua jokaiseen tarkoitukseen. Tietojärjestelmässämme on siksi avoimet rajapinnat. Siihen voi sitten kytkeä helposti muita analyysimenetelmiä, kuten tekoälymenetelmiä.”

BC Platformsin kaksi tietojärjestelmää BC I Genome ja BC I Insight, ovat käytössä ELIXIR-infrastuktuurissa Suomen ELIXIR-keskuksen CSC:n kautta. Tutkijaryhmillä on oma virtuaalipalvelin, jossa ovat BC Platformsin tietokannat ja työkalut. Virtuaalipalvelimet toimivat CSC:n laskenta-alustalla ja tarvittaessa korotetun tietoturvan ePouta-pilvipalvelussa.
”Tutkijat pystyvät tallentamaan näihin genomisen datan ja muun tutkimusdatan. Samalla he pystyvät tekemään hyvin laajan skaalan erilaisia genomianalyyseja samassa ympäristössä datoja eri tavoin yhdistellen.”
Tutkimusympäristöä käyttävät tällä hetkellä Helsingin yliopiston ryhmät, jotka tutkivat eläinten geenejä.
”Tähän ympäristöön voi kytkeä lisää sovelluksia, koska BC I Genomessa ja BC I Insightissa ovat avoimet rajapinnat. Ihmisdatan analysoimisessa data voitaisiin tarvittaessa tallentaa kovennetun tietoturvan ympäristöön, kuten CSC:hen.”

Koska datan käsittely ja yhdistely on automatisoitu, tutkijaryhmän ei tarvitse tehdä datakonversioita tai huolehtia dataformaateista.
”Ylläpito on tehokasta, koska ympäristö on yhteneväinen. Vain harvoilla tutkimusorganisaatioilla on varaa hankkia yksittäiselle tutkimusryhmälle näin järeää ratkaisua ja sen ylläpitoa. ELIXIR-infrastruktuurin kautta tämä on nyt mahdollista biotieteilijöille.”
Anita Eliassonin mukaan BC Platformsin tapaislla yrityksillä on suuri tarve hyödyntää replikoituja julkisia tietokantoja, jolloin automaattisesti otettaisiin tietokannasta paikallisia kopioita. Bitit eivät liiku riittävän nopeasti EMBL:n tietokannoista. Fyysinen etäisyys vaikuttaa, kun on kyse todella suurten datamassojen siirtämisestä.
”Kaiken datan siirtäminen ei ole mielekästä. Siksi Suomen ELIXIR-keskuksen solmupisteisiin pitäisi replikoida tietokantoja. Yritykset, jotka haluavat analysoida isoja datamassoja tekoälyllä hakeutuvat fyysisesti lähelle tietokantoja tiedonsiirtokustannusten takia.”
Ari Turunen
11.9.2018
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Timo Kanninen, Anita Eliasson, & Tommi Nyrönen. (2018). Genetic data under control and in the desired format. https://doi.org/10.5281/zenodo.8113213
Lisätietoja:
BC Platforms
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org
Kolmen vuoden aikana Yhdysvalloista siirrettiin 500 teratavun verran valokuitua pitkin Suomeen sekvenssidataa, joka oli saatu suomalaisista tutkimusnäytteistä. Luvanvarainen ja tietosuojattu data siirretään suomalaisiin biopankkeihin ja edistää merkittävästi perinnöllisten sairauksien tutkimista.
Suomessa ei ole ollut vuoteen 2015 asti valmiutta palauttaa kansainvälisissä tutkimushankkeissa luotua ja suomalaista kerättyä genomidataa takaisin kotimaahan. Tämän vuoksi Suomen Akatemia rahoitti projektin, jossa Helsingin yliopiston Aarno Palotien ja Samuli Ripatin tutkimusryhmät Suomen molekyylilääketieteen instituutista (FIMM) ja tieteen tietotekniikan keskus CSC aloittivat datan siirtämisen takaisin Suomeen genomisekvenointikeskuksista St. Louisista, Missourista ja Bostonista.
”Saimme luotua hyvän prosessin, johon kuuluivat lupakäytännöt, aineiston siirtäminen, luotettavuus ja tietoturva. Näin suurta aineistoa ei ole monikaan siirtänyt Yhdysvalloista Eurooppaan. Suomen yliopistojen runkoverkon FUNETin ansiosta tiedonsiirtonopeus oli riittävä. Lisäksi CSC:llä oli aiempaa kokemusta massiivisten data-aineistojen, kuten koko suomalaisen tv- ja elokuvatuotannon taltioimisesta nauhalle,” kertoo CSC:n terveys- ja biotieteiden palvelukehityksen vetäjä Ilkka Lappalainen.
eSISu-projekti (e-Infrastructure for Sequencing Initiative Suomi) taltioi tietoturvallisesti suomalaisen geneettisen perimän yksityiskohdat eli geenivariaatiot. Variaatioita analysoimalla saadaan selville uutta tietoa perinnöllisistä sairauksista. SISu-hankkeen (Sequencing Initiative Suomi) tavoite on kasata genomitieto muotoon, jossa se on parhaiten suomalaisten lääkäreiden ja tutkijoiden hyödynnettävissä. Tähän mennessä on selvitetty jo tuhansien suomalaisten koko genomi ja lähes 30 000 suomalaisen genomin proteiineja koodaavat osat.

Suomalaisista kerätyn datan perusteella perimä on pitkälti samanlainen kuin muissakin eurooppalaisissa maissa, mutta tietyt osat suomalaisten genomista ovat joko jalostuneet pohjoisia oloja varten tai ne esiintyivät vain muutamissa suvuissa, jotka asuttivat pieniä kyliä pohjoisessa.
”Tästä syystä tietyt geneettiset variaatiot esiintyvät suomalaisissa vaikuttaen esimerkiksi sydän- ja verisuonitautien syntyyn. Jos meillä ei ole dataa omasta geeniperimästämme, miten voisimme tutkia perimän vaikutusta erilaisten sairauksien syntymiseessä?”, Ilkka Lappalainen kysyy.
Genomidata on osa integroitavaa kokonaisuutta, johon liittyvät elintavat, lääkitykset, hoidot ja yksilöistä kerätyt terveysdatat. Näin geneettisten lähtökohtien ja lääkityksen vaikutuksesta tapahtuvien terveydentilan muutosten yhteyksien tilastollinen tulkinta tulee mahdolliseksi.
”Tietyissä tapauksissa, esimerkiksi Helsingin yliopistollisen keskussairaalan (HUS) syöpähoidoissa tämä on jo käytössä. Siellä tutkitaan syöpää aiheuttavien geenien tiettyjä osia, jotka vaikuttavat hoitomuotoihin ja suosituksiin ja hyödynnetään valtavaa määrää tilastollista dataa. Jos saadaan stardardoitua dataa koko Suomen populaatiosta, voidaan kutsua ihmiset tarvittaessa syöpäseulontaan ja päättää sopivasta lääkityksestä. Tulevaisuuden hoitomuodot eivät ole mahdollista vain suomalaisista kerätyn datan turvin. Syövän hoitomuodot kehittyvät osana kansainvälistä yhteistyötä.”
Toiveena on, että tieto saadaan terveydenhuoltoon ja näytteenantaja saa myös tiedon itselleen analysoituna. Näin hän voi halutessaan saada tiedon, onko hän riskiryhmässä tai ei.
Yksi tärkeimpiä bioinformatiikan tutkimuskohteita on tautien syntymekanismien ymmärtäminen. Yksi aineisto, joka projektissa kerättiin, liittyi migreenipotilaista saatuun dataan. Kesällä 2016 hanke saavutti merkittävän virstanpylvään, kun ensimmäiset datasetit migreenin geeniperimään siirrettiin Suomeen. Datansiirto pystyttiin toteuttamaan teknisesti ja tietoturvallisesti ilman ongelmia.
FIMMin tutkijat ovat SISu:n datan avulla todentaneet, että periytyvä alttius migreeniin on tosiasia, ja geneettisten lähtökohdat migreenialttiuteen voidaan jäljittää 38 alueelle genomissa. Löydöksellä on merkitystä migreenin mekanismien ymmärtämiselle ja siten tulevaisuudessa diagnostiikan täsmentämiselle ja parhaiden hoitovaihtoehtojen valitsemiselle.
Genomitiedon ansiosta suomalaiset tutkijat ovat saaneet myös uutta tietoa alttiudesta sairastua sepelvaltimotautiin. Sepelvaltimotaudin riskiryhmään kuuluvat voivat aloittaa ehkäisytoimet varhain, mikä tarkoittaa elintapojen muutosta tai ennaltaehkäisevää lääkitystä.
Saadun datan analysoimisessa on vielä töitä. Samasta henkilöstä on voitu ottaa useampia näytteitä eri tarkoitukseen, joten dataa on kerätty eri käyttötarkoituksiin. Nyt selvitetään, mistä näytteistä mikäkin tiedosto on saatu.
”Me työskentelemme juuri metadatan kanssa, jolla selvitetään aikaisemmin kerätyt aineistot ja lisätään niiden arvoa tulevia tutkimusprojekteja varten.”
Lappalaisen mukaan projektissa saatiin arvokkaita kokemuksia datanhallintaan. Siitä on hyötyä uudessa FinnGen-projektissa.
Joulukuussa 2017 käynnistyneen FinnGen-projektin tavoitteena on taltioida puolen miljoonan suomalaisen genomit. Hankkeessa hyödynnetään kaikkien suomalaisten biopankkien keräämiä näytteitä. Perimästä saatava data yhdistetään kansallisissa terveydenhuollon rekistereissä olevaan tietoon. Näin pystytään ymmärtämään sairauksien syntymekanismeja paremmin ja laatia uusia hoitokeinoja.

SISu on jo tunnistettu merkittäväksi dataresurssiksi ELIXIR– ja BBMRI -infrastruktuureissa. Seuraavaksi datan organisoiminen ja hallinta tehdään mahdolliseksi skaalautuvalla ja tietoturvallisella alustalla (ePouta-pilvipalvelu) prosessointia varten. Data siis tehdään laskennallisesti saataville. Suomen biopankit, kuten THL:n biopankki, hallinnoivat jatkossa aineistoa ja myöntävät lupia aineistojen käyttöön.
”Nyt datansiirtoa kokeillaan ja jatkossa se toimii, kun metadata saadaan ajantaiseksi.”
eSISU luo Suomeen ne valmiudet, jotka tarvitaan, että luvanvarainen genomidatan siirto Suomen ELIXIR-keskuksen ja muiden ELIXIR-keskusten välillä toimii. CSC:llä dataa voidaan alkuperäisten datan haltioiden luvalla integroida muihin Suomessa oleviin rekistereiden ja tietokantojen datoihin.
”Näin voidaan yhdistää suomalainen data eurooppalaisen EGA:n (European Genome-phenome Archive) dataan.”
Euroopan genomiarkisto EGA on yksi maailman laajimmista julkisista datavarastosta, joihin on tallennettu potilasdataa biolääketieteellisistä projekteista. EGA jakaa ihmisistä kerättyä geno- ja fenotyyppidataa erikseen kysyttävällä suostumuksella näytteen ja datan tutkimuskäyttöön. EGA:n ansiosta moni ELIXIRin tutkimusprojekti on mahdollinen.
www.sisuproject.fi on hakupalvelu, josta voi etsiä suomalaisen väestön geenivariantteja. KITE-hakumoottori etsii puolestaan aineistoja metadatan perusteella. Nämä ovat esimerkkejä palveluista, joita kehitetään myös kansainväliseen käyttöön. Datan hallinnointi ja lupakäytännöt hoidetaan REMS-ohjelmiston avulla.
”Datan hallinnointi toimii nyt teknisesti hyvin. SiSun aineistosta merkittävä osa saadaan käyttöön vuoden 2018 aikana.”
Ari Turunen
23.8.2018
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Ilkka Lappalainen, & Tommi Nyrönen. (2018). Massive data management project. Finns’ heredity is collected and safeguarded. https://doi.org/10.5281/zenodo.8113203
Lisätietoja:
Tommi Nyrönen
Suomen ELIXIR-keskuksen johtaja
tommi.nyronen@csc.fi
+358-50-3819511
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Jopa 50% hyväksytyistä lääkeaineista vaikuttaa kolmeen proteiiniperheeseen, tumareseptoreihin, G-proteiinireseptoreihin ja ionikanaviin.
Lääkeaineet vaikuttavat tavallisesti solujen reseptoreihin tai elimistön entsyymeihin, jotka ovat molemmat proteiineja. Monet lääkeaineet sitoutuvat myös entsyymireseptoreihin ja solukalvolla oleviin kantajaproteiineihin. Lääke voi esimerkiksi sitoutua entsyymin aktiiviseen kohtaan, jolloin se estää entsyymin säätelemän kemiallisen reaktion. Useimmiten entsyymeinä, jotka katalysoivat lääkkeen aiheuttavan kemikaalisen reaktion, ovat sytokromi P450-entsyymit.
Suurin osa lääkkeiden kohdeproteiineista kuuluu vain kymmeneen proteiiniperheeseen, jopa puolet vain kolmeen perheeseen. Tiettyyn perheeseen kuuluvilla proteiineilla on samalla tavalla laskostunut kolmiulotteinen rakenne, toiminta ja merkittävä samankaltaisuus aminohapposekvensseissä, mikä kertoo yleensä yhteisestä muinaisesta historiasta. Saman perheen proteiinit ovat peräisin yhdestä alkuperäisestä kantamuodosta, joka on evoluution myötä muokkaantunut ja erikoistunut ympäristön paineessa myös alkuperäisestä roolistaan poikkeaviin toiminnallisiin rooleihin solujen prosesseissa.

Proteiiniperheet keksittiin, kun alettiin tuntea muutaman proteiinin rakenne ja aminohapposekvenssit. Silloin havaittiin että, proteiinit muodostuvat useita itsenäisiä rakenteellisesti erottuvia alueita, jolla on jokin erikoistehtävä. Näitä alettiin kutsua domeeneiksi.
Uusia proteiiniperheitä on löydetty eri sairauksien syntymekanismeja tutkittaessa. Esimerkiksi tumareseptorit löydettiin rintasyöpää tutkittaessa. Pitkään oli tiedetty, että kolmannekselta rintasyöpään sairastuneilta naisista, joilta oli poistettu munasarjat tai lisämunuaiset, kasvaimen kasvu loppui. Rintasyövän molekylaarinen perusta oli kuitenkin vielä mysteeri. Vuonna 1947 lääketieteen tutkija Elwood Jensen alkoi selvittää tätä. Jensen löysi estrogeeni-reseptorin ja havaitsi, että kun estrogeenireseptori aktivoituu, kun siihen sitoutuu sen luontainen estrogeeni, estradioli. Tämän jälkeen aktivoitunut estrogeenireseptori matkustaa solun tumaan, missä se osallistuu geenien toiminnan säätelyyn.
Tumareseptorien perheeseen kuuluva proteiinimolekyyli, estrogeenireseptori, on erittäin tärkeä ihmiselle. Jos sen toiminnassa tapahtuu muutoksia, niillä on suuri merkitys solujen terveyteen. Estrogeenireseptorilla on diagnosoitu olevan tärkeä rooli rintasyövän synnyssä. Normaalisti estrogeenit säätelevät estrogeenireseptorin aktiivisuutta solussa. Estrogeenireseptorin muuttunut muoto on koko ajan aktiivinen, eivätkä solun normaalit estrogeenipitoisuuteen perustuvat säätelymekanismit siten toimi oikein. Tämä voi johtaa syövän, eli säätelemättä kasvavien normalista poikkeavien solukkojen syntyyn.
Elwood Jensen osoitti, että rintasyöpäpotilaat, joilla oli alhainen estrogeenireseptoripitoisuus syöpäsoluissaan eivät hyötyneet munasarjojen poistosta. Munasarjat tuottavat suuren osan naisten aktiivisesta estrogeenista. Reseptoripitoisuus osoittaa, kenen kannattaa mennä leikkaukseen ja kenen kannattaa jättää se väliin. 1970-luvun puolivälissä Jensen ja hänen kollegansa Craig Jordan havaitsivat, että syöpäpotilaat, joiden kasvaimien muuttuneissa soluissa oli suuri määrä estrogeenireseptoreja ovat myös todennäköisesti niitä, jotka hyötyvät tamoksifeenista. Se on antiestrogeeni eli se kumoaa estrogeenin vaikutusta soluissa. Ne potilaat, joilla oli vähäisiä määriä reseptoreja, voitiin puolestaan heti siirtää muihin hoitoihin. Vuoteen 1980 mennessä Jensenin kehittämästä testistä, jolla mitataan reseptorien määrää rintasyöpänäytteistä, oli tullut standarditesti rintasyöpäpotilailla.


Löydöt paljastivat soluissa toimivan proteiinien superperheen, tumareseptorit, joihin estrogeenireseptori kuuluu. Tumareseptoriperheeseen kuuluvat mm. estroneegireseptorit alfa ja beta, androgeenireseptori, keltarauhashormonireseptori ja D-vitamiinireseptori. Tumareseptoreille on yhteistä, että ne aktivoituvat solukalvon läpäisevän viestimolekyylin eli ligandin, tumareseptorihormonin, sitouduttua niihin ja matkustavat tämän jälkeen tumaan vaikuttamaan solun prosesseihin. Hormonit, jotka aktivoivat tumareseptorien suurperheeseen kuuluvia jäseniä ovat mm. testosteroni, estradioli, progesteroni eli keltarauhshormoni, glukokortikoidit, mineralokortikoidit ja D-vitamiini ja lääkeainesuunnittelun avulla luodut luonnollisten ligandien rakennetta matkivat molekyylit. Esimerkiksi Norjan vuoden 2016 hiihtomaajoukkueen Therese Johaugin huulivoiteessa saattoi olla klostebolia, joka on androgeenireseptorin ligandi. Klosteboli toimii anabolisena eli lihassolujen proteiinien kasvua edistävänä tekijänä.
Ihmisen elimistöön lääkeiden tai muun reitin kautta tulevat pienet molekyylit voivat siten vaikuttaaa tumareseptoreihin niitä aktivoimalla tai sammuttamalla, ja siten vaikuttavat solun geenien toimintaan. Tumareseptorien löytäminen on muuttanut vallankumouksellisesti biokemiallisen endokrinologian tutkimuksen. Endokrinologia on erikoisala, joka tutkii ja hoitaa hormoneja tuottavien elinten sairauksia. Sairaudet voivat johtua hormonien liikatuotannosta tai niiden puutteesta, lisäksi hormoneja tuottavissa kudoksissa voi ilmetä sekä hyvän- että pahanlaatuisia kasvaimia. Ennen tumareseptoreiden keksimistä ihmiskehon hormoonien toiminta oli täysi mysteeri, nyt toimintaa osataan jo hieman muokata.
Jotta organismi voisi toimia, signaalien pitää välittyä kehon soluissa ja niistä muodostuneissä elimissä. Elimistö kokonaisuutena lähettää ja vastaanottaa signaaleita sähkövirtojen ja tiettyjen molekyylien avulla. Martin Rodbell ja Alfred Gilman selvittivät , miten signaalinvälitys tapahtuu solukalvon läpi molekyylien yhteistoiminnan kautta. Vuonna 1970 Martin Rodbell osoitti, että signaalinsiirto tapahtuu kolmessa vaiheessa: signaalin vastaanotto, siirto ja vahvistus. Siirto tapahtuu siten, että solun pinnan proteiinista välitetään käsky vaihtaa solukalvon toisella puolella sijaitsevaan proteiiniin sitoutunut guanisiinidifosfaatti (GDP) guanosiinitrifosfaattiin (GTP). Tämä ilmiö on tiedonsiirtoa molekyylitasolla.
Vuonna 1980 Alfred Gilman tutki leukemiasoluja ja havaitsi, että ne eivät vastanneet hormonien välittämään ulkoiseen signaaliin. Syynä oli reseptoriproteiinin mutaatio, joka aiheutti sen, että hormonien signaalinvälitys estyi. Gilman eristi proteiinin normaaleista soluista ja näillä proteiineilla hän pystyi korjaamaan vaurioituneen solun. Molekyylit, jotka ovat mukana signaalinvälityksessä ovat suuri perhe proteiineja, jotka sitoutuvat guanosiinitrifosfaattiin. Kun ne ovat sidoksissa GTP:hen, ne ovat ”päällä” ja kun ne ovat sidoksissa GDO:hen, ne ovat ”pois päältä.” Gilman kutsui niitä G-proteiineiksi (guanine nucleotide-binding proteins).
G-proteiinit ovat kenties tärkeimpiä signaalinvälitykseen osallistuvia molekyylejä. Ne liittyvät joidenkin syöpämuotojen lisäksi diabetekseen, alkoholismiin sekä monien muiden sairauksien molekyylaarisiin syntymekanismeihin.
Solukalvossa olevien G-proteiineihin kytkeytyneiden reseptorien proteiiniperhe kuljettaa signaalit solun G-proteiineille solukalvon sisäpuolella. G-proteiinit puolestaan ottavat vasteen vaihtamalla GDP:n GTP:ksi. Seuraus tästä aktivoitumisesta on esimerkiksi solun sisäpuolella solulimassa pilkkomistyöhön vapautuva entsyymi, solukalvossa sijaitsevan ionikanavan avautuminen tai sulkeutuminen.
Tällä mekanismilla toimii esimerkiksi silmässä rodopsiini, joka on avulla havaitsemme silmillämme valon eli näemme. Kolmasosa tunnetuista lääkeaineista vaikuttaa G-proteiineihin kytkeytyneisiin reseptoreihin. Katekoliamiinit (mm. adrenaliini, noradrenaliini ja dopamiini), peptidit, glykoproteiinihormonit sekä rodopsiini ovat esimerkkejä ligandeista, jotka sitoutuvat näihin reseptoreihin. Alfred Gilman ja Martin Rodbell saivat 1994 Nobelin lääketieteen palkinnon G-proteiinien keksimisestä. Kemian Nobel myönnettiin vuonna 2012 Robert Lefkowitzille and Brian Kobilkalle G-proteiineihin kytkeytyneiden proteiinien toiminnan selittämisestä.

Proteiinit suorittavat työtään syklisesti ja tarkasti vaihtamalla muotoja ja molekyylejä signaalien perusteella. G-proteiinin ja G-proteiinikytkettyjen reseptorien muodot ovat jatkuvassa dynaamisesti muuttuvassa biokemiallisessa tasapainoreaktiossa keskenään. G-proteiinien herkässä tasapainossa tapahtuvat muutokset voivat aiheuttaa sairauksia. Esimerkiksi kolerabakteerin myrkky lukitsee G-proteiinit yhteen muotoon ja vaikuttaa hermoihin, jotka ohjaavat suolan ja nesteen imeytymistä suolistossa.

Ionikanavat kuuluvat integraalisiin solukalvon proteiineihin eli proteiineihin, jotka ovat osa solukalvon rakennetta. Ne voivat olla ligandivälitteisiä, reseptoriohjattuja ja jänniteohjattuja.
Jotkin ionikanavat ovat monimutkaisia moniosaisia ja molekyylikooltaan valtavia rakennelmia. Valtavat ionikanavien toimintaan kytkeytyneet reseptorit reagoivat suoraan pienen pieniin ligandimolekyyleihin, kuten aivoissa sijaitseva ionotrooppinen glutamaatti-aminohappoon reagoiva reseptori. Neljästä domeenista muodostuva proteiini muuttaa auliisti muotoaan tuhansia kertoja pienemmän glutamaatin sitoutuessa signaalinvälitykseen tarkoitettuun domeeniin ja avaa solukalvon läpisevä ionikanavan. Memantiinia käytetään Alzheimerin tautiin. Se suojaa aivojen hermosoluja tuhoutumiselta estämällä liiallisen glutamaatti-välittäjäaineen vaikutuksen.
Reseptoriohjatut ionikanavat aukeavat, kun niihen kiinnittyy tietty kemiallinen yhdiste. Kemiallinen yhdiste voi olla solun ulkoinen molekyyli kuten hormoni, hermoston välittäjäaine, lääkeaine tai myrkky tai solun sisäinen molekyyli. Ymmärtämällä ionikanavareseptorien toimintaa tutkijat voivat kehittää esimerkiksi addiktion hoitomuotoja muuttamalla reseptorien aktiivisuutta.
Ari Turunen
Tommi Nyrönen
14.6.2018
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, & Tommi Nyrönen. (2018). Half of all drug ingredients affect only three protein families. https://doi.org/10.5281/zenodo.8113184
Lisätietoja:
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Hyvää lääkeainemolekyyliä ei synny, ellei tiedetä, mihin proteiineihin se elimistössämme vaikuttaa. Siksi lääkeainesuunnittelussa on tärkeää hyödyntää massiivisia tietokantoja, joihin on tallennettu löydettyjä proteiinirakenteita ja proteiiniperheitä sekä tietoja, miten ne toimivat soluissa.
Suurin osa käytössä olevista lääkkeistä on suunniteltu niin, että niiden kohdemolekyyleinä ovat elimistön biomolekyylit eli proteiinit. Useimmat lääkeaineet vaikuttavat elimistössä sitoutumalla viestimolekyylien, kuten hermoston välittäjäaineiden ja hormonien, reseptoreihin. Reseptorit ovat solun erikoistuneita proteiineja, jotka käynnistävät siihen kytkeytyvät solun signaalinvälitysmekanismit.
Lääkeaineiden suunnittelun lähtökohtana on rakentaa pieniä synteettisiä molekyylejä, jotka vaikuttavat valikoivasti juuri haluttuihin proteiineihin. Suurin osa lääkkeiden kohdeproteiineista kuuluu vain kymmeneen proteiiniperheeseen, jopa puolet vain kolmeen perheeseen. Pienet molekyylit pystyvät imeytymään hyvin verenkiertoon, jolloin lääke alkaa vaikuttaa. Proteiinin sijainnista riippuen lääkeainemolekyylin täytyy tunkeutua soluihin tai välittää solun ulkopuolelta signaali, joka vaikuttaa solun sisällä tapahtuviin prosesseihin. Molekyylit pyritään suunnittelemaan esimerkiksi siten, että ne hidastavat tai kiihdyttävät jonkin tietyn proteiinin toimintaa.
Aiemmin ei tiedetty paljonkaan siitä, missä kohdassa solua lääkeaine vaikuttaa. Vuonna 1980 näitä vaikutuskohteita tunnettiin 150. Määrä on eri eliöiden genomien selvittämisen myötä kuitenkin kasvanut huimasti, sillä nyt on tiedossa jo yli 5 000 mahdollista vaikutuskohdetta. Lääketieteen käytettävissä on noin 2500 lääkeainemolekyyliä. Ihmisen genomin toimintaa selvitetään yhä tarkemmin, ja mahdollisia lääkeaineiden vaikutuskohteita tunnetaan lähivuosina ehkä jo 10 000.
Viimeisten arvioiden mukaan elimistössämme on 2000 – 3000 proteiinia, jotka ovat mahdollisia kohdeproteiineja lääkeaineelle. Nykyisten lääkkeiden on osoitettu toimivan vasta noin 450 lääkeaineen kohteen kautta rajalliseen määrään tauteja. Siten lääkeaineiden suunnittelijoilla on kaksi merkittävää tavoitetta – rakentaa uusia turvallisia molekyylejä, joilla tunnettuihin kohteisiin voidaan turvallisesti vaikuttaa ja toisaalta tutkia tunnettujen turvallisten lääkeaineiden käyttöä uusiin sairauksiin, joihin ei tällä hetkellä ole viranomaisten hyväksymää lääkettä. Tutkijoiden tavoitteena on muun muassa ymmärtää, mitkä lääkeaineen rakenteelliset ja kemialliset ominaisuudet ovat avainasemassa, kun ne muokkaavat proteiinien toimintaa solutasolla.
Toimiva lääke voidaan kehittää, kun löydetään sellainen kohdeproteiinin kolmiulotteinen rakenne, joka mahdollistaa vuorovaikutuksen lääkeainemolekyylin kanssa. Lääkemolekyyliin rakennetaan kemialliset vastakappaleet, jotka tunnistavat proteiinin sitoutumiskohdassa olevat aminohapot. Kun tällainen molekyyli törmää elimistössä kohdeproteiiniin, se hakeutuu automaattisesti proteiinin sitoutumiskohtaan, koska siihen kiinnittyminen on sille energeettisesti edullista.
Hyvin suunnitellun lääkeainemolekyylin sitoutumista kohdeproteiiniin voisi verrata villakäsineen pukemiseen. Se istuu napakasti nimenomaan viisisormiseen käteen: kuusi- tai seitsemänsormiselle se olisi erittäin epämukava. Vasemman käden käsine myös istuu huonosti oikeaan käteen.
Proteiinien muoto kertoo molekyylin toiminnasta enemmän kuin aminohappojärjestys. Muodoltaan samanlaiset proteiinit voivat biokemiallisesti toimia samankaltaisesti, vaikka niiden aminohappojärjestykset poikkeaisivat toisistaan yli 80 prosenttia.
Kun proteiiniperheen yhden jäsenen rakenne on selvitetty, voidaan muiden samaan perheeseen kuuluvien proteiinien rakenne ennustaa mallintamalla. Tietokoneen avulla tehtävä mallintaminen nopeuttaa tutkimusta, sillä proteiinien aminohappojärjestyksiä tunnetaan satoja kertoja enemmän kuin sellaisia proteiinirakenteita, jotka on jo ehditty määrittää kokein. Karkeasti voidaan sanoa, että genomiikan tehtävänä on selvittää nukleotidien järjestys. Tämä järjestys muuttuu solussa aminohappopolymeeriksi, mutta vasta kun proteiini laskostuu kolmiulotteiseen muotoonsa, se alkaa toimia. Tätä toimintaa selvittää proteomiikka. Siten genomiikan, proteomiikan ja lääkemolekyylimallituksen asiantuntijoiden yhteistyö tukee toisiaan.

Vaikka tietoa on paljon, uusien lääkkeiden kehitys on varsin haasteellista. Vain viisi prosenttia lääkeaine-ehdokkaista etenee laboratoriotestauksen kautta edes eläimillä tehtäviin hoitokokeisiin asti. Niistäkin vain pari prosenttia sopii lopulta lääkkeiksi. On arvioitu, että jopa 75 prosenttia lääkkeiden hinnasta johtuu epäonnistuneiden lääkekehityshankkeiden kustannuksista.
Yksi suuri haaste on sivuvaikutusten minimointi. Genomiikan kehityksen myötä lääkeaineiden on todettu vaikuttavan yksilöllisesti. Historiallisesti lääkeaineet on kehitetty olettaen, että ihmiset ovat samanlaisia biokemialtaan, mutta todellisuudessa olemme solutasolla yksilöllisiä samalla tavalla kuin ihmiset ovat fyysisesti hieman erilaisia. Kun pienillä lääkeainemolekkyleillä pyritään vaikuttamaan sairastuneen elimistön tilanteeseen parantavasti, nämä yksilölliset molekyylitason erot voivat vaikuttaa lääkeaineen toimivuuteen.
Keräämällä ja tallentamalla ihmisen biologista tietoa, voidaan tulevaisuudessa kohdistaa hoitotarkoituksiin lääkemolekyylejä, jotka tekevät juuri sen mitä niiden pitääkin ja juuri siinä tilanteessa ja räätälöitynä sille ihmiselle, joka lääkehoitoa tarvitsee. Tätä kutsutaan yksilöllistetyksi lääketieteeksi.
Tietty geeni tuottaa tiettyä proteiinia, joihin lääkeaineet vaikutavat. Kun tunnetaan ihmisen perimän DNA:n emäsjärjestys, voidaan päätellä myös vastaavan proteiinin perusrakenne tällä ihmisellä. Kuten DNA, proteiinikin on rihma, joka koostuu peräkkäisistä rakennuspalikoista. Geenin tiettyä palikkaa vastaa aina proteiinin tietty palikka.
Yhdellä ihmisellä voi olla perittynä tai ympäristön aiheuttaman muutoksena yhden DNA:n nukleotidin muutos, joka tämän ketjun kautta heijastuu proteiiniin. Tuo muutos voi olla juuri siinä kohdassa proteiinia, jolla sen pitäisi ottaa vastaan signaaleita muualta elimistöstä tai vuorovaikuttaa lääkeaineen kanssa. Proteiinin rakenteet tallentamalla ja jakamalla ne tutkijoiden käyttöön voidaan tämä ilmiö hallita ja ymmärtää. Lääkemolekyylin ja proteiinimolekyylin muodot osataan sovitella toisiinsa niin, että lääkettä muokataan sopeuttaen se tilanteeseen, jolloin lääke tarttuu ja vaikuttaa mahdollisimman tehokkaasti. Monet syöpähoidot perustuvat tähän. Kasvaimen perimä muuttuu ajan kuluessa. Eri vaiheessa oleviin kasvaimiin voi vaikuttaa lääkeaineilla, mutta lääkeaineiden muodon on otettava huomioon kasvua kiihdyttävien proteiinin muodon muutokset.
Lääkeainesuunnittelussa tutkitaan siksi erityisesti proteiineja, joiden kolmiulotteinen rakenne voidaan selvittää kokein tai ennustaa mallintamalla. Lääkemolekyylin tarttumista voi tutkia tietokoneen moderneilla mallinnusohjelmilla, joissa kolmiulotteista proteiinin ja lääkkeen mallia sovitellaan toisiinsa. Näin voidaan myös räätälöidä ihanteellinen lääkkeen muoto.
Tavallisesti lääke vaikuttaa tarttumalla elimistön vialliseen proteiiniin ja muuttamalla sen toimintaa. Ihanteellinen lääke tekee vain tämän; se ei häiritse terveitä proteiineja eikä aiheuta muita sivuvaikutuksia. Tähän asti on oltu onnellisia, jos on löydetty yksi sairauteen vaikuttava proteiini ja jokin siihen kohtuullisesti tehoava lääkeaine.
Nyt proteiinien ja lääkemolekyylien koko arsenaalia pystytään seulomaan ja valitsemaan parhaat ehdokkaat. Tämä johtuu molekyylibiologian, tietokoneiden laskentatehon ja tietokantojen edistymisestä. Nyt voidaan seuloa elimistön koko proteiinivalikoimaa.

Protein Data Bankissa eli PDB-proteiinitietokannassa on yli 100 000 proteiinirakennetta, jotka jakautuvat proteiiniperheisiin. Proteiiniperheen jäsenet ovat yleensä kolmiulotteiselta rakenteeltaan samankaltaisia, ja siksi ne myös toimivat samantapaisesti.
PDB-tietokantaa ylläpitää kansainvälinen konsortio Worldwide Protein Data Bank (wwPDB). Sen tehtävänä on ylläpitää yksittäistä makromolekyylien rakennedataa, joka on tutkijoille vapaasti käytettävissä.
Human Protein Atlas on vuonna 2003 Ruotsista alkanut ohjelma, jonka tarkoituksena on kartoittaa kaikki ihmisen proteiinit soluissa, kudoksissa ja elimissä. Kartoituksessa käytetään erilaisia omiikka-tekniikoita eli tekniikoita, joissa kaikkia geenejä tai niiden tuottamia proteiineja tutkitaan samanaikaisesti. Näitä ovat vasta-aineiden kuvantaminen, massaspektromiikkaan perustuva proteomiikka, transkriptiomiikka ja systeemibiologia. Kaikki kerätty data on avoinna tutkijoille.
Tammikuussa vuonna 2015 Human Protein Atlas julkaisi kartan, joka näytti 17 000 eri proteiinin paikat ihmisen kehossa antaen näin arvokasta tietoa lääkeainesuunnitteluun. Kartassa olivat proteiinien sijainnit, jotka olivat hyväksyttyjen lääkkeiden kohdeproteiineja. Tutkijat voivat katsoa proteiineja 32 erilaisessa kudoksessa edustaen kaikki merkittävimpiä kehon kudoksia ja elimiä.
Joulukuussa 2017 Human Protein Atlas julkaisi version 18. Tietokannassa oli tuolloin 26 000 vasta-ainetta, jotka kohdistuivat proteiineihin, joita lähes 17 000 geeniä koodaa. Se vastasi 87% ihmisen proteiineja koodaavista geeneiistä.
Tommi Nyrönen
Ari Turunen
12.6.2018
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, & Tommi Nyrönen. (2018). Looking for a good drug. https://doi.org/10.5281/zenodo.8113165
Lisätietoja:
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org
Ihmisen perimä sisältää miljoonia geneettisiä muunnelmia, variantteja, jotka tekevät jokaisesta yksilöstä ainutlaatuisen. Jotkut variantit vaikuttavat silmien väriin tai verityyppiin, toiset perinnöllisiin sairauksiin. DNA-sekvenssistä voi löytyä myös patogeeninen sekvenssivariantti, joka aiheuttaa geenin toiminnassa erilaisia häiriötä. Häiriöt ilmenevät perinnöllisinä sairauksina. Suomalainen Blueprint Genetics luokittelee potilasnäytteistä perimästä havaittuja geneettisiä variaatioita ja analysoi niiden yhteyden potilaista kuvattuihin oireisiin.
Blueprint Genetics aloitti toimintansa keskittymällä sydän- ja verisuonitautien diagnostiikkaan. Nyt yritys pystyy analysoimaan saamistaan potilasnäytteistä valtaosan perinnöllisistä sairauksista. Ihmisistä tunnetaan yli 6000 yhden geenin virheestä syntynyttä sairautta. Keskimäärin yksi kahdesta sadasta perii geenivirheen vanhemmiltaan. On myös paljon monitekijäisiä sairauksia, joissa useamman geenivariaation yhdistelmä aiheuttaa sairauden tai nostaa sairastumisriskiä. Sellaisia ovat esimerkiksi Alzheimer, diabetes, nivelreuma tai syöpäsairaudet.
Blueprint Geneticsin datatieteen johtaja ja Itä-Suomen yliopiston tutkija Jussi Paananen on taustaltaan tietojenkäsittelytieteilijä, joka on erikoistunut data-analytiikkaan. Paananen kiinnostui jo varhain biolääketieteestä, koska siinä hyödynnetään teknologioita, jotka tuottavat paljon dataa. Viime vuosina häntä on kiinnostanut koneoppiminen ja tekoäly, jotka ovat tulossa bioinformatiikan tutkimusmenetelmiksi kasvavan laskentatehon myötä.
”Minua kiinnostaa, miten tekoälyllä voidaan auttaa geneetikkoja päätöksenteossa ja isojen datamäärien käsittelyssä. ”
Tekoälyn tutkimus on kovassa kasvussa ja menetelmät muuttuvat. Koneoppimisessa tietokone oppii itsenäisesti päätymään tiettyyn lopputulokseen. Koneoppimisen algoritmit löytävät sellaisia säännönmukaisuuksia isoista aineistojoukoista, joita ihminen ei havaitse. Koneoppimisessa hyödynnetään neuroverkkotutkimusta, jossa Suomessa on pitkä perinne. Neuroverkko oppii muuttujien epälineaariset riippuvuussuhteet suoraan havaintoaineistosta. Se osaa esimerkiksi luokitella eläinaiheisista kuvista korvat.
”Kaikkein parhaimpia neuroverkot ovat juuri luokitteluongelmien ratkaisuissa”, sanoo Paananen.
”Kuva-analytiikassa kuvia tunnistetaan tai kuvista tunnistetaan osia ja niitä luokitellaan. Kone pystyy tunnistamaan esineitä ja asioita: tässä on ihminen, tässä auto, tässä syöpäkasvain. Se, mitä me teemme, on DNA-varianttien luokittelu. Yritämme löytää potilasnäytteistä, mitkä DNA-variantit aiheuttavat sairauksia ja mitkä geneettiset variaatiot ovat osa normaalia perimäämme.”

Blueprint Geneticsin asiakkaina ovat potilaita hoitavat lääkärit. Lääkärit haluavat selvittää, johtuvatko heidän potilaidensa sairaudet perinnöllistä tekijöistä vai eivät. Lääkärit eri puolilta maailmaa lähettävät Blueprint Geneticsille potilaidensa veri- tai sylkinäytteen, josta eristetty DNA sekvensoidaan. Sekvensointi tuottaa valtavan määrän dataa, joista poimitaan kiinnostavat variantit. Käytännössä se tarkoittaa, että potilaan geenimuunnoksia verrataan keskimääräiseen ihmisen referenssi-DNA:han.
Blueprint Geneticsin palveluksessa on huippuammattilaisia, geneetikkoja ja lääkäreitä, jotka luokittelevat variantteja. He käyvät läpi datamassaa, jota on jo käsitelty ja pilkottu pienempiin osiin. Asiantuntijat käyvät käytännössä läpi olemassa olevaa tieteellistä kirjallisuutta ja tietokantoja.
”Yritämme selvittää, mitkä näistä varianteista selittäisivät sairauden tai sen oireet”.
Koska vastaavaa informaatiota on kerätty ympäri maailmaa, usein tieteellisistä artikkeleista ja tietokannoista löytyy yksittäinen DNA-variantti, joka selittää sairauden.
”Teemme aineistosta kliinisen lausunnon joka lähetetään asiakaslääkärille. Lääkäri käyttää lausuntoa apuna diagnoosissa ja hoidon suunnittelussa.”
Blueprint Genetics hyödyntää erilaisia datalähteitä. Mahdollisuuksien mukaan data-aineiston analysointi automatisoidaan. Ohjelmistot analysoivat dataa ja tekevät monimutkaista datankäsittelyä. Ala on jatkuvassa kehityksessä. Ohjelmistoja päivitetään useita kertoja vuodessa, datamäärät ja laskentatehot kasvavat. Menetelmät kehittyvät ja muuttuvat nopeasti.
”Meillä on omaa ohjelmistotuotantoa, joka yhdistää eri datalähteitä ja helpottaa kirjallisuushakuja. Lopullisen tulkinnan tekee kuitenkin aina geneetikko. ”
Potilasdatan analysointi ja tulkitseminen on vaativaa työtä, koska siihen liittyy paljon lainsäädäntöä ja säätelyä. Blueprint Genetics tarjoaa lääkäreille käsiteltyä tietoa, mutta lääkärit tekevät aina varsinaisen päätöksen.
Blueprint Genetics on myös kiinnostunut myös julkisen- ja yksityissektorin välisestä yhteistyöstä.
”Geneettisen tiedon hyödyntämisessä on kyse koko ihmiskuntaa koskevasta valtavasta haasteesta. Ratkaisu vaatii yhteistoimintaa niin yrityksiltä, akateemisilta tutkimusryhmiltä kuin julkisrahoitteisilta järjestöiltä. Blueprint Genetics pyrkii osallistumaan avoimen tieteen ratkaisujen kehittämiseen ja etsii jatkuvasti uusia yhteistyötahoja.”
Alun perin Blueprint Genetics keskittyi potilaan oireiden perusteella tiettyihin kiinnostaviin geeneihin eli geenipaneeleihin. Paneelissa on tyypillisesti noin sata kappaletta tiettyyn tautiin liittyviä tunnettuja geenejä. Geneetikoista koostuva tiimi käy paneelin avulla tutkitut noin 2000 varianttia läpi. Nyt yritys on siirtynyt eksomisekvensointiin eli se sekvensoi kaikki proteiineja koodaavat geenit, joita meidän perimässämme on noin 21 000.
Ihmisen eksomi on se osa DNA:sta, jonka avulla tuotetaan kaikki ihmisen proteiinit. Sitä geenin osaa, joka koodaa ja suoraan ohjaa proteiinien tuotantoa kutsutaan eksoniksi. Kaikkia ihmisen eksoneita perimässämme kutsutaan kokonaisuudessa eksomiksi. Ihmisen eksomi noin 1,5% koko genomista.
”Kun analyysimme kohdistui geenipaneeleihin, saimme esimerkiksi 2000 varianttia, jota geneetikkojen tiimi kävi läpi. Nyt variantteja voi tulla 200 000. Kun olemme menossa koko genomin sekvensoitiin, variantteja saadaan 5 miljoonaa. Tätä datamäärää ei voida käsipelillä käydä läpi.”
Potilasnäytteistä kerätyn datan tulkinnassa ulkopuoliset tietokannat ovat tärkeitä. Genomin variaatioita on luetteloitu erilaisiin kansainvälisiin tietokantoihin, näistä tärkeimmät sijaitsevat eurooppalaisessa EMBL-EBI:ssä sekä yhdysvaltalaisessa NCBI (The National Center for Biotechnology Information) organisaatioissa. Lisäksi ELIXIR koordinoi Euroopassa julkisen biolääketieteen infrastruktuuria mahdollistaen geneettisten variaatioiden louhimisen näistä kansainvälisistä tietokannoista.
Varianttitietokannat tarjoavat hyödyllisiä luetteloita, joilla voidaan löytää korrelaatioita geenimuunnosten ja fenotyyppidatan välillä. EMBL-EBI luokittelee, tallentaa ja jakaa tietoa geenimuunnoksista. Tärkeimpiä tietokantoja ovat European Genome-phenome Archive (EGA), johon säilötään biolääketieteen tutkimuksen aineistot potilaista, European Variation Archive (EVA), joka sisältää geneettiset variaatiot, Ensembl tarjoaa näille variaatioille tulkinnan, gnomAD palvelu väestötasoiselle varianttien esiintymistiedolle sekä kliinisesti merkittävien varianttien varasto ClinVar. Lääkäri tarvitsee siis usein tiedon useammasta palvelusta, jotta oikea tulkinta genomivariaatiosta voidaan tuottaa potilasta varten. Tästä syystä eurooppalaiset ja amerikkalaiset palvelut vaihtavat säännöllisesti tietoa viimeisimmistä tutkimustuloksista, jotta palvelut tarjoaisivat aina viimeisimmän tiedon perimästämme tutkimuksen ja lääketieteen käyttöön.
”Geenivarianttitietokannat ovat tärkeitä, koska sieltä löytyy tietoa varianttien yleisyydestä terveessä ihmisessä. Tätä tietoa voidaan käyttää hyödyksi esimerkiksi silloin, kun tiedetään, että tietty periytyvä harvinainen sairaus on vain yhdellä prosentilla ihmisistä. Kun nähdään, että siellä on variantti, joka on viidellä prosentilla ihmisistä, voidaan todeta, että tämä ei voi olla se tautia aiheuttava variantti. Voidaan siis suodattaa pois isoja yleisiä DNA-variantteja, jotka eivät voi liittyä tähän sairauteen.”
ELIXIRin tarjoamat julkisen sektorin datapalvelut ovat tärkeitä.
”Me hyödynnämme omia paikallisia kopioita eri datalähteistä. Fyysinen etäisyys ja tietoliikenneyhteydet vaativat, että lähteet ovat samassa paikassa. Julkisilla palveluilta toivoisin lisää toimenpiteitä tietokantojen versioimiseen liittyen. Vanhoja versioita ei pitäisi hävittää pois. Eri versioihin pitäisi tarjota pitkäaikaissäilytystä.”

Iso haaste niin julkisissa tutkimusorganisaatioissa kuin yksityissektorillakin on tulkintaan käytetyn datan standardointi. Datan merkintätavat voivat vaihdella suuresti. Blueprint Geneticsin iso haaste on ns. fenotyyppidata.
”Se on tavallaan metadata itsessään eli potilasnäytteen mukana tuleva informaatio: oireet, diagnoosi ja muut taustatiedot. Voi olla, että näytteen mukana saadaan paljon metadataa tai sitten sitä ei saada ollenkaan.”
Fenotyyppidatan standardoinnissa on sama ongelma kuin terveydenhuollon potilasdatassa, jossa haasteena ovat erilaiset merkintätavat.
”Meille tulee eri maista erilaisilla käytänteillä varustettua tietoa. Taustatieto vaihtelee.”
Blueprint Geneticsin tapaisten firmojen on Jussi Paanasen mielestä hankalaa hyödyntää julkisrahoitteisten ja tutkimuskeskeisten organisaatioiden tuottamaa ja hallinnoimaa dataa.
”Tutkimusorganisaatiot ja yhteiset infrastruktuurit ovat kiinnostuneita isoista väestökohorteista, jolloin kyse on valtavista datamäärästä, joita koetetaan harmonisoida. Me käsittelemme tietoa eri tavoin kuin kohorteissa, jossa vaikkapa kootaan kymmenien tuhansien samalla alueella asuvien ihmisten tietoa. Meillä on kyse kuitenkin aina yksilöistä.”
Blueprint Genetics pyrkii käyttämään kansainvälisesti yhdenmukaista luokittelua, terminologiaa ja standardeja toiminnassaan.
”Tuotamme itse DNA-datan ja voimme päättää missä muodossa ja missä standardeissa se on. Me kuitenkin hyödynnämme muiden tekemää ohjeistusta kun tulkitsemme tuloksia.”
Muutama vuosi sitten tuli ensimmäinen yritelmä tällaisesta standardista. Yhdysvaltalainen American College of Medical Genetics and Genomics (ACMG) on laatinut ohjeistuksen, miten sekvenssivariantteja voisi luokitella. ACMG on ehdottanut seuraavanlaista yhteistä terminologiaa yksittäisen geenin aiheuttamille sairauksille: patogeeninen, todennäköisesti patogeeninen (likely pathogenic), epävarma merkitys (uncertain significance), todennäköisesti hyvälaatuinen (likely benign) ja hyvälaatuinen (benign).
”Meillä on ACMG:n luokittelusta oma muokattu versio. ”
Blueprint Geneticsin tapaisten yritysten haasteena on tiedon hyödynnettävyys. Tietoa on paljon referoiduissa julkaisuissa ja tavoitteena on kehittää hyviä tekstilouhintatyökaluja, jolloin artikkelien seulominen voitaisiin automatisoida.
”Pitäisi saada keskitetty pääsy kaikkiin julkaisuihin. Nyt on pitkään neuvoteltu akateemisten kustantajien kanssa lisenssimaksuista, jotka ovat korkeat.”
Ari Turunen
29.5.2018
Lue artikkeli PDF-muodossa
Lisätietoja:
https://www.elixir-europe.org/platforms/data/core-data-resources
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Professori Mikko Niemen tavoitteena on laatia tulkinta-algoritmi, joka auttaa lääkäreitä määrittämään potilaalle sopivan lääkkeen ja oikean annostuksen. Hoidot tehostuvat ja haittavaikutukset vähenevät, jolloin myös kustannukset pienenevät.
Ihmiset reagoivat lääkkeisiin eri tavoin, osalla lääkehoidon teho jää puutteelliseksi ja osalle se aiheuttaa haittavaikutuksia. Syynä poikkeavaan vasteeseen voivat olla fyysiset ominaisuutemme, muu lääkitys ja geneettinen perimämme. Lääkkeen annostarpeen tai haittavaikutusten ennakoimiseen saataisiin apua algoritmilta, kun käytössä on potilaasta saatujen fysiologisten tietojen lisäksi tietoa potilaan perimästä. Geenitesti voidaan tehdä yksinkertaisen verinäytteen perusteella.
Ihmisten geeniperimästä saadaan koko ajan uutta tietoa. Samalla geenitutkimusten ja bioinformatiikan kustannukset ovat laskeneet tuntuvasti. Dataa kertyy ja sen hyödyntämiselle on paljon uusia mahdollisuuksia. Farmakogenetiikka tutkii perintötekijöiden vaikutusta lääkeaineiden tehoon ja turvallisuuteen. Jos potilaiden perimästä saatu tieto olisi lääkäreiden saatavilla, lääkekulut ja merkittävät haittavaikutukset usein vähentyisivät. Myös sairaalahoitopäivien määrä vähenisi.
”Jos potilaiden perimä testattaisiin systemaattisesti, lääkehoidot voitaisiin paremmin räätälöidä ja annostella yksilöllisemmin”, sanoo farmakogenetikan professori, ylilääkäri Mikko Niemi.
Niemi johtaa Helsingin yliopistossa tutkimusryhmää, joka tutkii miten perintötekijät vaikuttavat lääkeaineiden pitoisuuksiin, turvallisuuteen ja tehoon. Lisäksi hän selvittää, milloin kannattaa lääkeaineen valinnassa harkita geenitestejä.
”Tieto geenitestin tuloksista tulisi olla käytettävissä silloin kun lääkettä määrätään, mutta yleensä tulosta joudutaan odottamaan viikko-pari. Voisi siis olla järkevää tutkia tärkeimmät lääkehoitoihin vaikuttavat geenimuunnokset ennakoivasti. Pyrimme tutkimustemme avulla tunnistamaan ne potilaat, jotka eniten hyötyisivät tällaisesta ennakoivasta testaamisesta.”
Niemen tutkimusryhmä kehittää myös farmakogenetiikkaan liittyviä päätöksenteon tukijärjestelmiä. Tavoitteena on laatia sydän- ja verisuonitautipotilaita hoitaville lääkäreille tulkinta-algoritmi, joka auttaisi löytämään kullekin potilaalle mahdollisimman tehokkaan ja turvallisen kolesterolilääkityksen. Algoritmi hyödyntää tietoja potilaan ominaisuuksista, sairauksista, muista lääkityksistä ja perimästä.
Sydän- ja verisuonitauteihin tarkoitetut statiinilääkkeet vähentävät veren LDL-kolesterolin ja lisäävät hyvän HDL-kolesterolin pitoisuutta. Ne aiheuttavat kuitenkin joillakin potilailla lihaskipua. Alttius lihasoireille on osittain perinnöllinen.

Yksittäisten lääkeaineiden annostarve saattaa vaihdella eri yksilöillä jopa yli 10-kertaisesti. Se voi johtua siitä, miten nopeasti tai hitaasti lääkeaine poistuu elimistöstä. Sytokromi-entsyymit (CYP) ovat keskeisiä monien elimistölle vieraiden aineiden, kuten lääkkeiden, pilkkomisessa ja poistamisessa elimistöstä. CYP-entsyymejä on erityisesti maksassa.
Kun Mikko Niemi teki väitöskirjaansa diabeteslääkkeiden yhteisvaikutuksista, hän epäili, että lääkeaineiden aineenvaihdunnan vaihtelu eri yksilöillä oli perinnöllistä. Erityisen kiinnostavia ovat kolme CYP-entsyymiä (CYP2D6, CYP2C9 ja CYP2C19), sillä ne vaikuttavat jopa kolmannekseen kaikista kliinisesti käytetyistä lääkeaineista. CYP-entsyymien aktiivisuuden geneettinen vaihtelu on suurta. Vaihtelu voi johtaa eri lääkeaineen pitoisuuksien ja vasteiden moninkertaisiin eroihin eri yksilöissä.

Geenitestien avulla ihmiset voidaan lääkeaineesta riippuen luokitella jopa neljään eri ryhmään sillä perusteella, miten nopeasti elimistö poistaa tiettyjä lääkeaineita: erittäin nopea, normaali, hidastunut ja hidas. Tämä ns. metabolianopeus voi vaikuttaa lääkkeen annostarpeeseen, tehoon ja haittavaikutusriskiin.
Erittäin nopeilla metaboloijilla lääkeaine poistuu elimistöstä tavallista nopeammin ja sen teho voi jäädä puutteelliseksi. Hitailla metaboloijilla lääke poistuu tavallista hitaammin ja sen vaikutukset voivat korostua. Sama lääkeannos siis voi olla toisilla liian pieni ja toisilla liian suuri.
Jotkut lääkkeet muuttuvat aktiiviseen muotoon CYP-entsyymien välityksellä. Tällaisiin lääkkeisiin perinnöllisen metabolianopeuden vaikutus on päinvastainen. Esimerkiksi kolmanneksella väestöstä veren hyytymistä estävä klopidogreeli-lääke tehoaa tavallista heikommin, mikä johtuu perinnöllisesti hidastuneesta CYP2C19-metaboliasta. Tällaisille potilaille kannattaa siksi yleensä valita vaihtoehtoinen lääkitys.
CYP2D6-entsyymin vaihtelu vaikuttaa puolestaan hyvin merkittävästi mm. kodeiiniin. Kodeiini on yleinen resepti-kipulääke, josta tavallisesti osa muuttuu maksassa CYP2D6-entsyymin välityksellä morfiiniksi. Hitailla metaboloijilla kodeiinin teho voi jäädä riittämättömäksi. Erittäin nopeilla metaboloijilla morfiinin määrä elimistössä voi nousta liian suureksi.
”Jos lääkäri tietäisi jo hoidon alussa, että potilaan CYP2D6-aineenvaihdunta on hidasta, potilaan ei tarvitsisi kärsiä riittämättömästä kivunhoidosta.”
Myös muilla kuin CYP-entsyymeillä on merkitystä. Esimerkiksi TPMT on entsyymi, joka vaikuttaa tiopuriinilääkkeiden aineenvaihduntaan. Tiopuriineja käytetään mm. autoimmuunitautien, tulehduksellisten suolistosairauksien sekä leukemioiden hoidossa.
”TPMT:n perinnöllinen puutos altistaa tiopuriinilääkkeiden vakaville verisoluihin kohdistuville haittavaikutuksille. Perinnöllisen puutoksen tunnistava eenitesti on ollut kliinisessä käytössä Suomessa jo vuodesta 2005”, sanoo Mikko Niemi.
Suomessa on tällä hetkellä saatavilla kymmenkunta lääkehoitoihin liittyvää geenitestiä.
Lääkeaineen sopivuus kullekin yksilölle riippuu hyvin monista tekijöistä. Siihen eivät vaikuta pelkästään lääkkeitä hajottavat entsyymit. Solukalvon kuljetusproteiinit vaikuttavat lääkeaineiden kulkeutumiseen vaikutuspaikkaansa. Kohdekudoksessa lääkeaine vuorovaikuttaa vaikutuskohteensa kanssa.
”Tästä seuraa tapahtumaketju, joka aikaansaa toivotun lääkevaikutuksen. Kaikissa näissä tekijöissä on yksilöiden välisiä, osin perinnöllisiä eroja.
Olisi tärkeää, että kaikki nämä yksilötekijät, perimä mukaan lukien, otettaisiin huomioon lääkehoitoa valittaessa.”
Mikko Niemi sai vuonna 2017 mittavan rahoituksen Euroopan tutkimusneuvostolta hankkeeseen, jossa kehitetään kolesterolilääkityksen valintaa helpottava algoritmi. Tätä varten Niemen tutkimusryhmä rakentaa niin kutsutun systeemifarmakologisen mallin.
”Se on tavallaan virtuaalinen potilas, jonka avulla voidaan yksilöllisesti ennakoida kunkin vaihtoehtoisen kolesterolilääkityksen vaikutukset.”
Vastaavanlaista algoritmia ei ole toistaiseksi yritetty kehittää.
”Mikäli algoritmi toimii kolesterolilääkityksen valinnassa, voisi samanlaista ajattelutapaa laajentaa myös muihin lääkehoitoihin.”
Alogoritmia ei luonnollisesti voida rakentaa, jos käytettävissä ei ole riittävästi luotettavaa tutkimustietoa. Tätä Niemen tutkimusryhmä on kerännyt jo vuosien ajan tutkimushankkeissaan. Suomeen perustetut biopankit ja tuleva genomikeskus nopeuttavat myös tällaisessa tutkimuksessa tarvittavan tiedon keräämistä.
Geenitiedon parempaa hyödyntämistä haluaa myös Suomen valtio. Suomen poikkeuksellisen asutushistorian vuoksi väestön geneettinen rakenne antaa erityisiä mahdollisuuksia yhdistää genomi- ja terveystietoja. Farmakogenetiikka on yksi kansallisen genomistrategian neljästä kärkihankkeesta. Strategian tavoitteena on, että geenitieto on tehokkaassa, terveyttä edistävässä käytössä jo vuonna 2020.

Tällä hetkellä merkittävästi lääkehoidon tehoon ja turvallisuuteen vaikuttavia geenejä on suhteellisen pieni joukko: alle 20 ihmisen kaikkiaan noin 20 000 geenistä. Koska kyseessä on näin pieni määrä geenejä, laajojenkin potilasmäärien testaus olisi Mikko Niemen mukaan teknisesti mahdollista.
”Seuraava askel on, että ennakoivasti testattaisiin kaikki lääkehoitoihin vaikuttavat geenimuunnokset.”
Terveyden ja hyvinvoinnin laitos (THL), HUSLABin Kliinisen farmakologian yksikkö ja CSC:n ovat aloittaneet pilottiprojektin, joka toteutetaan THL Biopankin geenitietoja ja HUS:n potilasasiakirjatietoja yhdistämällä. Aineistoista kartoitetaan lääkehoitoihin vaikuttavien geenimuunnosten yleisyyksiä suomalaisilla. Lisäksi tutkitaan, kuinka moni potilasotoksesta sai hoitojakson aikana tai sen jälkeen lääkehoitoa, jonka valintaan tai annosteluun geenitiedolla olisi voinut olla vaikutusta.
Tutkimusta varten HUS ja THL saavat omat yksityiset ja tietoturvalliset verkkoyhteytensä CSC:n datakeskukseen. Näin HUS ja THL voivat prosessoida dataa nopeasti ja tehokkaasti.
Projektissa varaudutaan riittävään pitkäaikaistallennustilaan, tiedonsiirtoon vähintään 10 Gbit/s nopeudella HUS:n ja THL:n järjestelmiin, sekä tarjotaan farmakogenetiikan ohjelmistoympäristölle tiedon prosessointiin tarvittava määrä virtuaalipalvelimia.
Ari Turunen
4.4.2018
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Mikko Niemi, & Tommi Nyrönen. (2018). Algorithm determines the appropriate drug. https://doi.org/10.5281/zenodo.8082229
Lisätietoja:
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Suomen ensimmäiseen sairaalabiopankkiin Auriaan on tallennettu yli miljoona kudosnäytettä sekä kymmeniä tuhansia verinäytteitä. Biopankki pystyy yhdistämään kokoelmiin myös luovuttajaan liittyviä tietoja, mikä auttaa merkittävästi tutkimusta. Tietoja voidaan pyytää näytteen luovuttajalta itseltään, potilasasiakirjoista tai valtakunnallisista rekistereistä.
Suomessa on ollut pitkään käytössä henkilötunnuksen kautta käytettävä sähköinen potilaskertomus. Henkilötunnusta edellyttävät rekisterit luovat hyvät edellytykset ihmisistä saatujen näytekokoelmien ja niihin liitetyn tiedon tehokkaalle hyödyntämiselle tulevaisuudessa. Tämä on suuri etu moniin maihin verrattuna.
Turun yliopistollisen keskussairaalan ja Turun yliopiston yhteydessä toimivan Auria Biopankin näytekokoelmat sijaitsevat fyysisesti lounaisen ja läntisen Suomen sairaaloissa. Näytteitä kerätään ja niihin liitetään tarpeellinen metadata, josta ilmenee kliininen tieto näytteen antajasta, määrästä, ajankohdasta ja miten näytettä on käsitelty. Auria Biopankin näytteet ovat muun muassa kudosta, verta ja soluista eristettyä DNA:ta.

Suomen biopankkeihin liittyvä lainsäädäntö on edistyksellinen. Näytteiden luovuttajan yksi suostumus riittää siihen, että tallennettuja näytteitä voidaan hyödyntää eri tutkimuksissa myös tulevaisuudessa. Laki sallii biopankille yhteydenoton luvan antaneisiin näytteiden luovuttajiin esim. tiedustellakseen näytteenantajan halukkuutta osallistua tutkimukseen, jota suostumus ei kata tai lisänäytteiden luovuttamiseen.
”Useimmiten yhteydenotto liittyy lääketutkimukseen. Mikäli potilas on kiinnostunut, hän ottaa suoraan yhteyttä tutkimuksen tekijään ja tekee tutkimusorganisaation kanssa erillisen sopimuksen, jonka jälkeen asia ei liity enää biopankkiin”, kertoo Auria Biopankin varajohtaja Perttu Terho.
Tietojen siirrossa noudatetaan henkilötieto- ja biopankkilakia, jotka turvaavat potilastietojen yksityisyyden ja luottamuksellisuuden. Suostumuksen näytteiden antamiseen voi antaa sairaaloissa tai verkossa sähköisen kaavakkeen kautta.

Uusia näytteitä kerätään normaalin diagnostiikan ja hoidon yhteydessä potilailta, jotka ovat antaneet suostumuksen. Sairaaloihin arkistoituja kudosnäytteitä skannataan, digitoidaan ja siirretään tietokantoihin. Ennen biopankkiin siirtoa näytteistä poistetaan henkilötiedot ja ne korvataan koodilla. Näin henkilösuoja on tehokkaasti turvattu.
Auria kerää leikkausten yhteydessä otettuja diagnostiikan yli jääviä kudosnäytteitä kuten syöpäkudosta, sekä laboratoriokäyntien yhteydessä otettavia biopankkiverinäytteitä.
”Kudosnäyte menee leikkauksen jälkeen patologille tutkittavaksi. Tyypillisesti näyte valetaan parafiiniin, ja siitä leikataan muutaman mikrometrin paksuisia siivuja, jotka värjätään diagnostiikan kannalta tarpeellisilla väreillä. Patologi tutkii värjätyistä kudosleikkeistä, onko näytteessä esimerkiksi kasvainta. Mikäli näytettä jää jäljelle, voidaan sitä hyödyntää biopankkitutkimuksissa. Näyte ei saa loppua eli sitä pitää olla riittävästi sairaalan käyttöön. Kun tämä on varmistettu, kudosnäytettä voidaan käyttää muihin tutkimuksiin”, kertoo Terho.
Auria Biopankki digitoi sellaiset näytteet, joita tarvitaan tutkimusprojekteissa.
”Digitoinnin idea on se, että pystymme esim. pyytämään patologia arvioimaan näytteet ja merkitsemään paikat, mistä löytyy syöpäkudosta ja mistä tervettä kudosta. Tämän patologi voi tehdä omalta tietokoneeltaan mistä tahansa, eikä itse näytteitä ole tarvetta siirtää mihinkään. Digitoituja kuvia voidaan myös analysoida automatisoidusti hahmontunnistus-algoritmeilla ja tekoälyyn perustuvilla menetelmillä.”
Auria on aikaisemmin eristänyt DNA:ta verinäytteistä ja kudoksista ainoastaan niistä näytteistä, joita on tarvittu projekteissa. Nyt DNA-eristys on tarkoitus tehdä jokaisesta talletetusta verinäytteestä.
“DNA:n eristäminen jokaisesta näytteestä tehostaa tutkimuksen tekemistä. Näytteet vastaanotetaan ja tallennetaan, mutta vielä ei tutkita sinänsä mitään. Näytteet jäävät odottamaan tulevaisuuden tutkimusta, koska ei vielä tiedetä mihin näytteitä voidaan tarvita.”
Tänä vuonna eristetään DNA 16 000 verinäytteestä. Jatkossa näytteitä otetaan vuosittain yli 20 000. Verinäyte otetaan normaalin diagnostisen tai kliinisen verinäytteen oton yhteydessä.
”Kyseessä on yksi ylimääräinen 10 ml verinäyte biopankkia varten. Näytteestä veriplasma ja valkosolut laitetaan eriputkiin ennen pakastamista.”
Perttu Terho korostaa, että annettu näyte on arvokas, kun se voidaan yhdistää potilastietoihin.
”Tutkijat voivat tarvita dataa potilaista, joille on tehty tietty diagnoosi ja joilla on tietty lääkitys ja veriarvo. Tällöin biopankista voidaan nopeasti katsoa, onko näillä kriteereillä näytteitä ja niihin liittyvää tietoa olemassa.”
Biopankin aineiston avulla voidaan saada selville tautien ja lääkeaineiden erityispiirteitä. Voidaan esimerkiksi saada lisätietoa, miksi joillekin potilaille tulee lääkehoidoista sivuvaikutuksia ja toisille ei.
”Tärkeää on, että kerätään järkevä määrä relevanttia potilasdataa mahdollisimman suuresta massasta. Näin biopankkiin saadaan näytteitä tutkimuksellisesti kiinnostavista potilaista.”
Tutkijoilta tulee näytteisiin liittyviä pyyntöjä joka viikko.
”Kyselyn perusteella teemme kartoituksen siitä, millaisia määriä biopankista löytyy kiinnostuksen kohteena olevia näytteitä ja tietoja. Mikäli tutkija on tyytyväinen esiselvityksen tulokseen, hän tekee luovutuspyynnön, jossa kuvataan tutkimus ja määritellään tarvittavat näytteet ja tiedot.”
Luovutuspyynnöt käsitellään biopankin tieteellisessä ohjausryhmässä, joka kokoontuu kerran kuukaudessa. Ohjausryhmä arvioi pyynnöt. Mikäli ohjausryhmä puoltaa tutkimusta, voidaan hakijan kanssa edetä luovutussopimuksen valmisteluun.
Suomen sairaaloiden yhteydessä toimivien biopankkien toiminta on periaatteessa samanlainen. Ne keräävät näytteitä omista sairaanhoitopiireistä ja tallentavat niihin liittyvää tietoa. Olisi luonnollisesti houkuttelevaa päästä tekemään hakuja kaikista saatavilla olevista näytekokoelmista yhdellä kertaa. Haasteena on, että eri sairaalat ovat vuosien saatossa tallentaneet ja luokitelleet näytteet eri tavoin. Eri järjestelmissä ovat erilaisen kirjaamistiedot, jolloin potilasnäytteistä annetuissa tiedoissa on vaihtelua. Tietojen pitäisi kulkea eri biopankkien välillä sujuvasti.
“Sairaaladataa on hankala analysoida. Tarvitaan kliinikon asiantuntemusta tulkitsemaan mitä on kirjattu. Saatavilla oleva data ei ole suoraan yhteismitallista. Tärkeää olisi saada aikaan saatavuuspalvelu, joka voisi yhdistää eri biopankkien tietoja, jolloin ainakin perustiedot olisivat saatavissa.”
Vuonna 2017 perustettiin Suomen biopankkiosuuskunta, jonka jäseninä ovat sairaanhoitopiirit ja yliopistot, joissa on lääketieteellinen tiedekunta. Biopankkiosuuskunnan tarkoituksena on tarjota Suomen biopankkien näyte- ja tietokokoelmien aineisto tutkijoiden käyttöön yhden luukun periaatteella. Se välittäisi asiakkaille yhtenäisen näkymän ja keskitetyn kanavan suomalaisten biopankkien aineistoihin. Biopankkiosuuskunta vastaa mm. tietojärjestelmien kehittämisestä.
Terhon mukaan näytteisiin voidaan yhdistää niihin liittyvä tutkimukselle merkittävä kliininen tieto. Biopankit hyödyntävät CSC – Tieteen tietotekniikan keskus Oy:n sensitiiviselle datalle rakentamia alustoja, kun ne suunnittelevat omiaa tietopalvelujaan.

Auria Biopankki on mukana tulevan genomikeskuksen perustamisessa. Auria Biopankin vt. johtajan Lila Kallion mukaan on vasta mietinnän asteella miten tutkimus- ja diagnostiikkasekvenssien kulku ja säilytys järjestetään.
”Genomilainsäädäntö on valmisteilla ja biopankkilakia uudistetaan. Näiden lisäksi mm. uusi EU:n tietosuoja-asetus selkeyttää myös biopankkien toimintaa..”
Alustavien suunnitelmien mukaan Suomen Genomikeskus aloittaa toimintansa vuonna 2019.
Ari Turunen
19.3.2018
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Tommi Nyrönen, Perttu Terho, & Lila Kallio. (2018). Bank of million patient samples. https://doi.org/10.5281/zenodo.8081169
Lisätietoja:
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Bioinformatiikan menetelmien kehittyessä myös kustannukset ovat laskeneet. Eri eliöiden perimä saadaan selvill entistä nopeammin ja halvemmin. Edessä oleva urakka eri eliöiden ja ihmisten genomien sisältämän tiedon ymmärtämisessä on kuitenkin valtava. Se edellyttää eri tutkimusorganisaatioiden yhteistyötä ja hyvin järjestettyjä tietokantoja.
Ihmisen koko perimä selvitettiin vuonna 2003. Human Genome Project-hanke saatiin valmiiksi ennakoitua aiemmin internetin ansiosta. Se mahdollisti eri laboratorioiden tehokkaan yhteistyön. Ihmisen koko DNA saatiin sekventoitua. Ihmisen geenit on pakattu kolmeen miljardiin emäspariin. Nyt seuraavana on selvittää miten nämä geenit toimivat. Genomin emäsparien selvittämisen kautta aletaan ymmärtää eri sairauksien syntymekanismeja ja tehokkaita hoitomuotoja.
Nykyään tutkimus tuottaa genomitietoa varsin monipuolisesti. Tavoitteena on esimerkiksi arvioida tiedon avulla ympäristön tilaa ja terveysvaikutuksia tarkastelemalla mikrobeja, jalostaa ruokakasveja paremmin kuivuutta sietäviksi viljelykasveiksi ilmastonmuutoksen kriisien lievittämiseksi, tai kehittää lääkeaineita tauteihin, joihin ei tällä hetkellä tunneta hoitokeinoja. Näihin tarkoituksiin tarvitaan tietolähteiden uudenlaista yhdistämistä ja analysointia.

Eri eliöiden genomien selvittäminen on entistä helpompaa ja halvempaa. Nyt EBP-projektin (Earth Bio-Genome Project) tavoitteena on selvittää kaikkien aitotumaisten eliöiden eli eukaryoottien genomit. Esitumalliset arkit ja eubakteerit eli prokaryootit ovat soluja, joiden DNA muodostuu vain yhdestä kromosomista. Eukaryootteihin kuuluvat yksisoluiset alkueläimet ja kolme monisoluisten elöiden ryhmät: kasvit, sienet ja eläimet.
Bioinformatiikan avulla voidaan selvittää loput 80-90% niistä eliöistä, joiden genomia ei vielä tiedetä. Vuonna 2011 Census of Marine Life arvioi eläinlajien määräksi noin 8,7 miljoonaa, joista 6,5 miljoonaa on maaeläimiä ja 2,2 miljoonaa merieläimiä. Korkean suoritustehon sekvensointimenetelmiin perustuvan arvion mukaan sienilajeja voi olla jopa 5,1 miljoonaa. Kasvilajeja on arviolta 400 000.
Ensimmäistä kertaa ihmiskunnan historiassa on mahdollisuus tehokkaasti sekvensoida kaikkien tunnettujen aitotumaisten eliöiden genomi. EPB:n tavoitteena on sekvensoida kaikki 1,5 miljoonaa tunnettua eukaryoottia. Näytteitä kerätään ympäri maailmaa. Osa, ehkä noin puoli miljoonaa, saadaan kasvitieteellisistä puutarhoista. Loput joudutaan keräämään suoraan luonnosta. Yksi merkittävä keräyspaikka on Amazon. EPB aloitti tammikuussa 2018 yhteistyön brasiliaisen geenipankki-projektin kanssa, joka keskittyy Amazonin alueen eliöihin.
Amazonin alueella on eniten kasvi- ja eläinlajeja kuin missään muussa paikassa maailmassa. Ehkä kolmannes lajeista löytyy sieltä. Sademetsiin kätkeytyy valtavasti esimerkiksi potentiaalisia lääkeaineita.
Amazonin jararaca-kyykäärmeen myrkystä löydettiin ACE- estäjä eli angiotensiinikonvertaasi-niminen entsyymi, jonka vaikutuksesta syntyy verenpainetta alentavaa ja sydämen pumppaustyötä keventävää angiotensiiniä. 1970-luvulla tutkijat kehittivät synteettisen version käärmeen myrkystä.

Valtameret ovat maailman suurin yhtenäinen ekosysteemi. Planktonin merkitys maailman ilmastolla on vähintään yhtä merkittävä kuin sademetsien. Kuitenkin vain pieni osa niistä organismeista, jotka luovat tämän ekosysteemin, on luokiteltu ja analysoitu. Planktoneiden muodostamat ekosysteemit sisältävät valtavasti elämää: yli 10 miljardia organismia on jokaisessa litrassa valtameren vettä sisältäen viruksia, prokaryootteja, yksisoluisia eukaryootteja ja polttiaiseläimiä. Nämä ainutlaatuiset organismit sisältävät bioaktiivisia yhdisteitä, joille on käyttöä lääketeollisuudessa, elintarvikkeina, kosmetiikassa, bioenergiassa ja nanoteknologiassa. Vuosina 2009-2013 kansainvälinen tutkimusmatka Tara Oceans keräsi 210 mittauspaikasta maailman valtameristä 35 000 biologista näytettä. Se on laajin planktonista kerätty kokoelma. Ocean Sampling Day oli kampanja jossa myös kerättiin näyttetä merestä. Tutkimusasemia pyydettiin ottamaan näytteitä ja tuottamaan dataa. BioSamples kerää kuvauksia ja metadataa biologisista näytteistä, joita on käytetty tutkimuksessa. Näytteet ovat referenssejä tai niitä on käytetty eri tietokannoissa.

Genomien ja niiden toimintaa määrittävien proteiinien selvittäminen on valtava urakka, joka ei onnistu ilman yhteistyötä. Eurooppalainen biotieteiden tutkimusinfrastuktuuri ELIXIR tarjoaa tehokkaan alustan yhteistyölle. Siihen on liittynyt lähes 200 tutkimusorganisaatiota ja infrastruktuuria käyttää yli puoli miljoonaa tutkijaa. ELIXIR mahdollistaa pääsyn eri data-arkistoihin.
Massiivinen viljely- ja metsäkasvien sekvensointi mahdollistaa kasvitautien aiheuttajien tutkimisen. EURISCO (European Search Catalogue for Plant Genetic Resources ) sisältää informaatiota 1,9 miljoonasta viljelykasvista ja sen villeistä sukulaisista. Näytteet on kerätty lähes 400 eri organisaatioon. Mukana on 43 jäsenmaata ja tarkoituksena on säilyttää maailman agrobiologinen moninaisuus.
UniProt (Universal Protein Resource) kerää proteeinisekvenssit ja annotaatiodataa. Annotaatio tarkoittaa proteiinin toiminnan määrittelyä sekvenssin perusteella. Uniprotin datan ansiosa voidaan tietää enemmän proteiinien toiminnasta ja niiden vuorovaikutuksesta muiden molekyylien kanssa, niiden sijainnista soluissa ja organismeissa. Tavoitteena on kerätä kaikki julkisesti saatavulla oleva proteiinisekvenssidata. Uniprot on laajin julkisesti avoin olema proteenisekvenssitietokanta.
Euroopan nukleotidiarkisto ENA on kokoelma joka tarjoaa vapaan pääsyn kaikkiin julkaistuihin nukleotidisekvensseihin ja annotoituihin (geenin ja proteiinin toiminnan määrittely) DNA- ja RNA-sekvensseihin. The International Nucleotide Sequence Database on yhteistyöfoorumi, jossa ovat mukana DNA Data Bank of Japan (Japani), GenBank (Yhdysvallat) ja ENA. Uusi data synkronoidaan joka päivä kolmen tietokannan välillä. Jo vuonna 2012 näissä tietokannoissa oli 5682 organismin kokonaiset genomit. Data kaksinkertaistuu joka kymmenes kuukausi.
Euroopan genomiarkisto EGA on yksi maailman laajimmista julkisista datavarastosta, joihin on tallennettu potilasdataa biolääketieteellisistä projekteista. EGA säilöö ihmisistä kerättyä geno- ja fenotyyppidataa erikseen kysyttävällä suostumuksella näytteen ja datan tutkimuskäyttöön. EGA:n ansiosta moni ELIXIRin tutkimusprojekti on mahdollinen.

ELIXIR-infrastruktuurissa on yli 20 jäsenmaata Euroopasta. Jäsenmaiden keskusten kautta tarjotaan erilaista biolääketieteellistä dataa tutkijoiden käyttöön. Hyödyt ovat kiistattomia. Ihmisten harvinaisten sairauksien selvittämisessä on ollut hyötyä esimerkiksi koirien ja kissojen geeneistä. Suomen keskuksen kautta tutkijoilla on pääsy koirien ja kissojen DNA-pankkeihin, joiden aineistojen ansioista on onnistuttu löytämään esimerkiksi hermorappeumasairauden geeni. Tavoitteena on kehittää tähän sairauteen lääke. Koirien geeneistä on hyötyä ihmisten sairauksien tutkimisessa, sillä koiran ja ihmisen geeniperimä on 95-prosenttisesti samanlainen. Koirien geenipankissa on yli 70 000 näytettä 60 000 koirasta yli 300 rodusta. Se on tiettävästi lajissaan maailman suurin.
Arvioiden mukaan vuoteen 2025 mennessä voidaan sekvensoida 100 miljoonasta kahteen miljardiin ihmisen genomia. Jos datasta halutaan saada hyödyt, genotyyppinen data pitää linkittää muihin terveystietoihin. ELIXIR pystyy tähän. Tutkimusinfrastruktuuriin kuuluu lähes 200 organisaatiota, joiden muodostama federaatio, luottamusverkosto, mahdollistaa ihmisdatan käsittelyn tietoturvallisesti. Vuoteen 2016 mennessä ELIXIR-infrastruktuurin avulla oli laadittu 21000 tieteellistä artikkelia ja saatu 8500 patenttia. Patentteja oli haettu rokotteisiin, biomarkkereihin, entsyymeihin ja ebola-viruksen torjuntaan.
Elämän biologisten molekyylien yksittäisen atomin mittakaava on nanometrin kymmenesosa. Jos tuon biomolekyylin yksi hiiliatomi olisi ihmisen kokoinen kappale, se tarkoittaisi, että sen toiminnalla voisi olla ratkaiseva vaikutusta tapahtumiin, jotka tapahtuvat kymmenien miljoonien kilometrin päässä. Aurinkokuntamme halkaisija on samaa luokkaa.
Jos yksikin hiili vaihdetaan biologisessa molekyylissä toiseen atomiin, vaikka typpeen, se voi olla ratkaiseva piirre sille, tepsiikö esimerkiksi otettu lääke. Juuri tuon atomin avulla lääkemolekyyli voi olla tarttumassa proteiiniin, mutta ei onnistukaan muutoksen seurauksena saamaan riittävän pitävää otetta.
Proteiini, johon lääkkeen oli tarkoitus vaikuttaa puolestaan jakaa käskyjä eteenpäin toisille proteiineille soluissamme. Jos käskyyn vaikuttaminen jää tekemättä, biologiseen viestiketjun vaikuttaminen jää tekemättä.
Kysymys on myös siitä, ovatko solussa sijaitsevan viestiketjun kaikki osat virheettömiä? Kaikki nämä tekijät vaikuttava siihen voivatko tutkijat suunnitella lääkemolekyylin oikein, että se voi auttaa soluja parantumaan. Solussa ei ole tyhjiötä toisin kuin avaruudessa. Solut ovat täynnä toistensa kanssa koko ajan vuorovaikuttavia biomolekyylejä. Ihmisen vaikutusmahdollisuuden esimerkiksi auringon fuusioreaktioon ovat paljon rajallisempia kuin elämän molekyyleihin tallentuneen atomitason digitaalisen informaation vaikutus ihmisen sairastumiseen, vaikka mittakaavaero on sama.
Tommi Nyrönen
Ari Turunen
20.2.2018
Artikkeli PDF-muodossa
Sitaatti
Ari Turunen, & Tommi Nyrönen. (2018). Mapping the genomes of all organisms enables the development of new vaccines and medicines. https://doi.org/10.5281/zenodo.8070219
Lisätietoja:
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
Lähtökohtaisesti jokaisesta kerätty lääketieteellinen data on yksityistä ja tarkoin suojattua. Ilman ihmisistä kerättyä dataa, lääketiede ei kuitenkaan edisty. Ratkaisuna on datan hallintaohjelmisto, joka on tietoturvallinen ja jakaa pääsyä vain sellaiseen aineistoon, johon on annettu lupa.
Ihmisen perimästä saatua dataa on syytä käsitellä huolellisesti ja tietoturvaa noudattaen. Jotta kenenkään tietoturvallisuus ei vaarannu, ELIXIR tarjoaa palvelun, jossa tutkija kirjautuu järjestelmään, joka tunnistaa tutkijan sähköisen identiteetin ja samalla jakaa käyttöoikeuksia biolääketieteelliseen dataan, joka on varastoitu pilveen. Näin tutkija luo käyttämälleen datalle tietoturvallisen analyysiympäristönsä. Tämän mahdollistaa REMS-työkalu.
ELIXIR noudattaa tiukasti EU:n lainsäädäntöä tietoturvasta. Kun tutkijat hyödyntävät dataa, REMS-työkalun avulla voidaan varmistaa, että jaettu data on luvanvaraista.
Suomen ELIXIR-keskus CSC kehittää ja ylläpitää avoimen lähdekoodin REMS-työkalua, jolla voidaan hallinnoida pääsyä sellaisiin tietoaineistoihin, jotka sisältävät luottamuksellista materiaalia. REMS (Resource Entitlement Management System) on käyttöoikeuksien hallintatyökalu, joka tarvittaessa estää datan laittoman käytön. REMS-työkalun avulla voidaan tilata suuresta datamäärästä vain tietty aineisto, joka toimitetaan tilaajalle tietoturvallisesti lukittuna.
”Organisaation sisällä saattaa olla montakin erilaista työkalua, jotka hoitavat vastaavanlaisia asioita. Vaikka identiteetin ja roolin hallintaan löytyy paljon valmiita työkaluja ja palveluita, en kuitenkaan ole kuullut muista REMSin kaltaisista yleisistä resurssin luvitusohjelmista,” sanoo REMS-työkalun tuoteomistaja Tommi Jalkanen CSC:stä.
REMS on osa federoitua järjestelmää, jonka on muodostanut lähes 200 organisaation ELIXIR-yhteisö. Federointi on edellyttänyt sopimista eri organisaatioiden välillä tietoturvasta, henkilötietolaista, oikeuksista ja velvollisuuksista. Näin on muodostunut ELIXIRin oma luottamusverkosto, ELIXIR-AAI, jonka sääntöjä jokainen jäsenorganisaatio on sitoutunut noudattamaan.
ELIXIR-AAI on käytännössä yhteisö, jolla on käytössä federoitu autentikaatio ja identiteetinhallinta. Tätä federaatiota on kehitetty Suomen korkeakoulujen ja tutkimuslaitosten luottamusverkoston (HAKA) pohjalta. ELIXIR-federaation mahdollistaa kertakirjautumisen (Single Sign On, SSO) yhteisiin palveluihin.
ELIXIRin jäsenorganisaatiot ylläpitävät käyttäjän perustietoja, josta käy ilmi käyttäjän nimen ja yhteystietojen ohella käyttäjän rooli. Roolin määrittäminen on tärkeää, koska sen pohjalta REMS-työkalu jakaa käyttöoikeuksia. REMS siis päättää henkilötietojen perusteella, millainen näkymä käyttäjälle avautuu palvelussa. Tämä on ns. lupaperusteinen REMS.
Vaikka tietoturvataso on korkea, REMS on kuitenkin helppokäyttöinen. Työkalun käyttöön ei tarvita erillistä kirjautumista. Kirjautuminen palveluun tapahtuu ELIXIRin kotiorganisaation tunnuksella ja salasanalla. Eli ei tarvita palvelukohtaista käyttäjätunnus/salasana-paria. Juuri tämä federoitu hallinta takaa sen, että tietoaineistojen käyttöä voidaan valvoa. Samalla pystytään varmistamaan, että aineistoa ei käytetä vääriin tarkoituksiin. Palvelun käyttöä voidaan seurata ja siitä voidaan raportoida. (audit)
Käytännössä palvelu toimii niin, että tutkija hakee datan hyödyntämiselle lupaa REMS-työkalulla. Hän kirjautuu REMSiin federoidulla identiteetillään. Sitten hän täyttää hakemuksen datankäytölle ja sitoutuu noudattamaan käyttöoikeuksia. ELIXIRin datahallinto DAC (Data Access Committee) saa REMSin kautta hakemuksen ja hyväksyy tai kieltää datan käytön. Tämä ilmoitetaan hakijalla sähköpostilla. Jos hyväksyntä saadaan, hakijalle lähetetään ohjeet mitä seuraavaksi tapahtuu. REMS ohjaa datapyynnön CSC:n Data Access Service-palveluun. Se tarjoaa tutkjalle näkymän ePouta-pilvipalvelussa luvitettuun tietoaineistoon.
Federoitu käyttäjätunnus on helppo sulkea vastuussa olevasta organisaatiosta, jos käyttäjä esimerkiksi vaihtaa työpaikkaa. Koska käytetään vahvaa tunnistusta, jäljitettävyys ja raportointi helpottuu. Samalla sähläys tunnus/salasana-parien kanssa vähenee, kuten myös salasanojen resetointi. Kertakirjautuminen vähentää erillisten käyttäjätunnusten tarvetta sekä säästää aikaa, vaivaa ja rahaa. Päällekkäinen tietojen ylläpito vähenee ja tiedon laatu paranee. Palvelunomistaja voi keskittyä palveluunsa, koska ELIXIR-organisaation tietohallinto hoitaa tunnukset. Nämä uudet toimintatavat tukevat esim. ELIXIRin monien ohjelmistopalveluiden käyttöä.

REMS-ohjelmiston uutena piirteenä on rajapintatuki apuohjelmille. Nyt tutkijoille on tarjolla moderni ja laajasti käytössä oleva web-teknologia, joka mahdollistaa palveluiden, kuten tietokantojen, yhteiskäytön. Näin voidaan rakentaa ekosysteemejä helposti ja turvallisesti sekä antaa kolmansille osapuolille pääsy palveluun. REST (Representational State Transfer) on tunnettu ja paljon käytetty sovellusarkkitehtuuri hajautetuille järjestelmille. REST-rajapinnan avulla eri ohjelmat eri alustoilta voivat käyttää samaa resurssia.
”Työn alla on tällä hetkellä kaiken kattavan rajapinnan luonti, mikä antaa laajat mahdollisuudet kolmannen osapuolien apuohjelmien rakentamiselle.”, sanoo Tommi Jalkanen.

Tilastotieteen menetelmiä käyttäen on mahdollista tunnistaa henkilö riittävällä todennäköisyydellä anonymisoidusta aineistosta, mikäli kohteesta on käytettävissä genomi-informaatiota. Tätä asiaa täytyy siis lähestyä tietoturvan, genomitietoa tarjoavan palvelun käyttösopimusten sekä kansallisen ja kansainvälisen lainsäädännön kautta.
Mikäli anonymisoituun aineistoon liitetään lisätietoa, kuten syntymävuosi tai sairauden nimi – tulee tutkijan autentikoitua palveluun luotettavasti ja hyväksyä palvelun käyttöehdot, jotka kieltävät aineistojen sisältämien henkilöiden tunnistamisen. Lisäksi on mahdollista profiloida käyttäjät, jolloin jokaiselle profiilille voidaan tarjota aineistosta tarkoituksenmukainen näkymä. Käyttölupa ja lainsäädäntö määrittelevät miten aineistoja tulee mm. säilyttää ja analysoida.
Ari Turunen
7.2.2018
Artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Tommi Jalkanen, & Tommi Nyrönen. (2018). Ordered and secured. https://doi.org/10.5281/zenodo.8070212
Lisätietoja:
REMS
https://www.elixir-finland.org/aai-rems/
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Ihmisen perimästä eli genomista saatu tieto tulee osaksi terveydenhuollon päätöksentekoa. Potilaan genomidatan yhdistäminen hänen nykyisestä terveydentilastaan saatuun tietoon mahdollistaa uusien algoritmien kehittämisen, jolloin lääkäri voi nopeasti valita potilaalle parhaimman mahdollisen hoidon ja lääkityksen.
Ihmisen yksilöllisestä perimästä johtuen lääkkeet vaikuttavat eri tavoin. Esimerkiksi jotkut antibiootit aiheuttavat lääkeaineallergioita. Elimistö voi myös pilkkoa lääkkeen nopeammin kuin se ehtii vaikuttaa
tai potilas voi saada haitallisia sivuvaikutuksia. Siksi genomitiedon hyödyntäminen lääkehoidoissa vähentää väärien lääkemääräysten määrää. Toisaalta, jos henkilöllä on tiedossa, että hänellä on ruoansulatukseen liittyvä geeniominaisuus, joka lisää tai heikentää vaikkapa kofeiinin pilkkoutumista energiaksi ja rakennusaineiksi, tiedolla voi olla myönteisiä vaikutuksia hänen elintapoihinsa. Tulevaisuudessa sähköisiin potilaskertomusjärjestelmiin liitettyjen geenitietokantojen algoritmit voisivat varoittaa automaattisesti mahdollisista lääkehaitoista ja neuvoa tehokkaimmasta vaihtoehdosta.
Suomessa tieteen tietotekniikan keskuksen CSC:n, Terveyden ja hyvinvoinnin laitoksen THL:n ja Helsingin yliopiston molekyylilääketieteen instituutin suunnitelmissa on luoda tietoturvalliset puitteet suomalaisista tuotetun genomitiedon tallentamiselle ja tiedon tulkitsemiselle terveydenhuollon tarkoituksiin. Yhteistyössä mukana olevan Helsingin yliopistollisen keskussairaalan (HUS) tavoitteena on selvittää ihmisistä tuotetun digitaalisen terveysdatan hyötyjä tutkimukselle ja hoidolle. Puoli vuotta kestävä pilottiprojekti kuuluu Suomeen perustettavan Genomi-keskuksen saamaan toimeksiantoon, jota koordinoi Sosiaali- ja terveysministeriö.

Vuosi vuodelta datan tallennus halpenee ja kapasiteetti kasvaa. Esimerkillinen aineisto suomalaisten terveydestä kerätystä datasta on THL:n FINRISKI-kohortti. Suomalaisista vuosikymmeniä kerätyn data-aineiston analyyseja on jatkokehitetty GeneRISK-hankkeessa, jossa tutkitaan sydän- ja verisuonitautien perinnöllisiä riskitekijöitä. Samalla testataan algoritmia, joka laskee riskipisteet ihmisen sairastumiselle sydän-ja verisuonitauteihin. Kardiokompassi-niminen työkalu kertoo ihmiselle nykyisen riskitason ja riskin kehittymisen lähivuosikymmeninä.
Kardiokompassia kokeillaan käytännössä rekrytoimalla ja testaamalla 10 000 ihmistä Kotkan seudulla, Mehiläisen asiakaskunnasta ja Helsingin verenluovuttajista. Hankkeeseen osallistuvat henkilöt saavat
genomitiedon yhdistämisen avulla tärkeää palautetta omasta terveydentilastaan ja tarkemmin kuin koskaan aikaisemmin. Tiedot kerätään Kardiokompassiin. Henkilöt voivat myös keskustella suoraan
asiantuntijoiden kanssa datasta tehtävistä tulkinnoista.

Suomen hallitus päätti huhtikuussa 2106, että Suomeen perustetaan Genomikeskus, jonka tavoite on tuoda perimästä saatu tieto osaksi terveydenhoitoa. Genomikeskuksen toimintojen rakentamiseksi suomalaisista jo kerättyä ja tallennettua dataa pyritään hyödyntämään ja yhdistelemään tutkimuksessa, joka onnistuessaan parantaa lääkemääräyksien tarkkuutta. Potilaan genomidatan perusteella voitaisiin määrittää sopivat tai sulkea ulos huonot lääkitykset. Algoritmeja voidaan kehittää valitsemaan sopiva lääkeaine ja optimoimaan lääkityksen määrää standardisoiduilla ohjelmistomenetelmillä. Tätä kutsutaan farmakogenetiikaksi.
Professori Mikko Niemi Helsingin Biomedicumista sai vuonna 2016 mittavan rahoituksen Euroopan tutkimusneuvostolta hankkeeseen, jossa kehitetään algoritmi, jolla etsitään potilaalle sopiva kolesterolilääke. Matemaattinen malli ottaa huomioon potilaan perimän, muun lääkityksen, sukupuolen, iän ja painon.
Algoritmien tehokas hyödyntäminen edellyttää kuitenkin, että potilaista on saatavilla tarpeeksi erilaista dataa. On tärkeää tietää datan laatu ja käyttötarkoitus. Riittävä metadata kuvaa datan laadun, jonka pohjalta voidaan tehdä päätökset datan hyödyntämisestä. Kun referenssidatalle saadaan toimiva tekninen jakelualusta, datan tulkitseminen helpottuu. Tällöin voidaan suunnitella parempia tulkinta-algoritmeja datalle.
Geneettisen datan tulkinta-algoritmien laatiminen kliiniseen käyttöön on pitkän aikavälin tavoite. Sen lisäksi, että algoritmit auttavat lääkäreitä esimerkiksi määrittämään sopivaa lääkitystä, ne voivat soveltua jopa proteiinien toiminnan muutosten ennustamiseen. Tavoitteena on, että kun tulkinta-algoritmit ovat valmiita kliiniseen käyttöön, ne olisivat käytettävissä potilastietojärjestelmissä automaattisesti, ei erikseen tilattavana tietopyyntönä.
Suuri osa teknologioista on olemassa, mutta ne pitää vain osata liittää yhteen. Osaamista
Suomeen saadaan muun muassa osana eurooppalaista yhteistyötä. CSC:n yhteydessä toimii ELIXIR-infrastruktuurin Suomen keskus, joka rakentaa genomitiedon hallinnalle ja tallentamiselle tarvittavan tietoturvallisen infrastruktuurin.
Hankkeessa tietoteknologiaa sovelletaan THL:n biopankin näyte- ja dataaineistoihin. Hankkeen tavoite on muokata genomitieto siten, että se on parhaiten suomalaisten lääkäreiden ja tutkijoiden hyödynnettävissä. Tähän THL:n ja muiden tärkeiden suomalaisten näytekokoelmien digitalisoinnin avulla on selvitetty jo noin 9000 suomalaisen koko genomi (www.sisuproject.fi), mutta jopa puolen miljoonan suomalaisen genomiaineistosta on keskusteltu.
Hanke yhdistää THL:n, HUS:n ja CSC:n teknologisen osaamisen Suomessa. Tulevaisuudessa
tavoite on, että tämäntyypistä dataa analysoisi suuri joukko suomalaisia bioalojen asiantuntijoita yliopistoista, julkiselta sektorilta ja bioalan yrityksistä. Pelkkä datan tallentaminen ei riitä, vaan pitää syntyä kaiken biologisen datan hyödyntämisen kattava palvelu. Tällä hetkellä datan tallettajien ja datan tarjoajien asiantuntemus ei riitä kaikkiin mahdollisiin terveyden sovelluksiin. Pilotin toteuttamisella saadaan siten tärkeitä suuntaviivoja, miten genomitiedon tehokas tallentaminen
ja tietoturvallinen jakelu voidaan toteuttaa organisaatioiden välisessä yhteistyössä, jotta dataa voidaan hyödyntää täysimittaisesti terveydenhoidossa, tutkimuksessa sekä tulevaisuuden innovaatioissa.
Kyse on pitkälti siitä, halutaanko Suomeen pienen tehtaan kokoinen erikoistunut yhteisen genomitiedon hallinnan ja jatkojalostamisen infrastruktuuri ja osaaminen, jonka varaan datan tulkintaekosystemi rakentuu, vai halutaanko datan infrastruktuurin palveluita ulkoistaa muualle.
Monessa maassa koko maan kattava genomitieto on haastava tavoite. Suomen Genomikeskuksen palvelut ovat hahmottumassa, ja ne luodaan yhteistyössä datan hallinnoijien kuten biopankkien ja lupaviranomaisten kanssa. Genomikeskuksen koordinoimat datavarannot ovat tietoturvallisesti saatavilla hyödyntämiselle. Tulevaisuudessa jokaisella suomalaisella voisi siten olla oma terveys- ja hyvinvointiprofiili, jossa olisi mukana omaan perimään liittyvä tieto.
Tommi Nyrönen
Ari Turunen
2.11.2017
Tommi Nyrönen on biokemisti ja Suomen ELIXIR-keskuksen johtaja.
Ari Turunen on tietokirjailija ja Le monde Diplomatiquen Suomen edition päätoimittaja.
Artikkeli PDF-muodossa
Sitaatti
Ari Turunen, & Tommi Nyrönen. (2017). Striving for a national service to utilise genomic data in health care. https://doi.org/10.5281/zenodo.8070200
Lisätietoja:
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 20 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

Kasvien kasvua ja fysiologiaa analysoidaan kuvantamismenetelmillä, mikä tuottaa valtavasti dataa kasvien genomi- ja ympäristövasteista. Tällä pyritään kasvien satoisuuden parantamiseen, jolloin voidaan tuottaa ekologisesti kestävällä tavalla ruokaa ja raaka-aineita kasvavalle ihmiskunnalle.
Helsingin ja Itä-Suomen yliopistojen yhteisessä NaPPI- infrastuktuurissa kasvit mitataan ja analysoidaan automaattisesti. Infrastruktuurin toiminta ja sen tuottama data voidaan järjestää alusta lähtien niin, että se on yhteensopivaa myös muiden eurooppalaisten tutkimusorganisaatioiden käyttöön. Tavoite on hyvä, sillä näihin päiviin asti jokainen laboratorio ympäri maailmaa on kerännyt kasvien perimästä, ilmiasuista eli fenotyypeistä ja ympäristötekijöistä saatua dataa omalla tavallaan.
Helsingin yliopiston Viikki Plant Science Center (ViPS) on tutkimuskeskittymä, jossa 36 ryhmää tutkii kasveja. Tutkimusaiheet vaihtelevat tiettyyn elinympäristöön ja ilmastonmuutokseen sopeutumisesta, kasvien stressinsietoon ja kasvinjalostukseen.
NaPPI-infrastruktuurin (National Plant Phenotyping Infrastructure) toiminta keskittyy kasvitutkimukseen, ja -jalostukseen. Tavoitteena on kattavan fenotyyppitiedon tuottaminen suuresta määrästä kasveja. NaPPI antaa tekniset mahdollisuudet yhdistää kasvien perimästä saatu tieto fenotyyppidataan.
Kasvin fenotyyppi on geenien ja ympäristön yhteisesti tuottama ilmiasu. Fenotyyppi voi muokkautua hyvinkin erilaiseksi ympäristön vaikutuksesta. Kasveilla onkin paljon laajempi kyky periytymättömään muunteluun kuin eläimillä. Esimerkiksi kasvin kasvuun voidaan vaikuttaa tehokkaasti eri tavoin, kuten ravinteilla ja valolla.
Ihmiset ovat jalostaneet kasveja tuhansia vuosia, koska on haluttu parempaa ruokaa. Tätä on tehty paikallisesti eikä kasveista kerättyä tietoa ole systemaattisesti tallennettu. Hyvänä esimerkkinä on viinirypäleen lukuisat lajikkeet, joita pelkästään Euroopassa on yli tuhat. Kaikkien lajikkeiden alkuperää ei enää tiedetä ja siksi alkuperää selvitetään geenitekniiikan avulla.
”Kasvien fenotyypeistä saatua dataa ei ole vielä standardisoitu. Eri tutkimusryhmät ovat tuottaneet ja luokitelleet sitä omissa laboratorioissaan”, sanoo NaPPI-infrastruktuurin tutkimuskoordinattori Kristiina Himanen Helsingin yliopistosta.

NaPPi-infrastruktuurin tavoitteena on tehostaa ja tarkentaa kasveista saadun tiedon keruuta ja analysointia uusien kuvantamistekniikoiden avulla. Infrastruktuurilla on käytössä kuvantamislaitteita, jotka analysoivat kasvien kasvua ja fysiologiaa. Kasvit mitataan ja kuvataan automaattisesti, jonka jälkeen tietokone laskee kuvien perusteella kasvien korkeuden, leveyden ja esimerkiksi lehtiruusukkeen pinta-alan ja muodon.
”Kasvin koko, kasvu, ja muoto eli kasvin arkkitehtuuri ovat tärkeitä maataloustuotannossa”, Himanen korostaa.
”Kasvin arkkitehtuuri voi vaikuttaa sadon määrään tai viljelyominaisuuksiin. Kun riisistä on tehty kääpiölajikkeita ne eivät lakoonnu enää helposti, ja tämä vaikuttaa satoon. Geenit voivat vaikuttaa kasvin arkkitehtuuriin ja sitä kautta sadon määrään ja laatuun.”
Viikissä tutkitaan, mitä tapahtuu kun rypsin perimään eli genomiin syötetään kääpiögeeni. MMT Tarja Niemelä ja yhteistyökumppanit selvittävät, voiko kääpiögeeni lisätä rypsin satoisuutta vähentämällä varren biomassaa suhteessa kasvin tuottamaan siemensatoon.
”Genomidataa on hurjasti saatavilla, mutta se pitää pystyä yhdistämään muuhun dataan. Haluamme liittää kuvantamislaitteilla tuottamaamme fenotyyppidatan genomidataan. Lopulta, meitä tietenkin kiinnostaa, miten genomeista ja fenotyypeistä saatu tieto saadaan siirrettyä kasvinjalostukseen.”
Himasen mukaan uusien kuvantamismenetelmien ansiosta kasvintutkimuksen volyymi kasvaa.

NaPPI-infrastruktuurin laitteilla analysoidaan kasvin muotojen lisäksi kasvien fysiologista tilaa. Itä-Suomen yliopiston Joensuun kampuksella oleva spektromiikkalaboratorio on Suomen ensimmäinen kasvien ja muiden biologisten näytteiden spektrikuvantamiseen keskittynyt tutkimusympäristö. Spektrikuvantaminen koostuu useista valon eri aallonpituuksilla otetuista kuvista, joilla on oma värikanavansa. Spektromiikkalaboratoriossa kehitetään optisia menetelmiä erityisesti kasvien stressivasteiden tutkimukseen.
Ihmissilmä tai tavanomainen kamera näkee värit kolmen aallonpituuskaistan (punainen, vihreä ja sininen) yhdistelminä. Spektrikameralla voidaan kuitenkin havaita jopa satoja eri aallonpituuskaistoja. Se ei ole myöskään rajoittunut vain näkyvään valoon, vaan kykenee kuvaamaan ultravioletti- ja infrapunasäteilyn alueilla. Kustakin kaistasta voidaan muodostaa erillinen kuva ja kukin pikseli sisältää täydellisen spektrin.
”Spektrikuvaus mahdollistaa värien erittäin tarkan erottelun, mutta samalla moninkertaistaa tuotetun datan määrän”, toteaa professori Markku Keinänen Itä-Suomen yliopistosta.
”Tämä taas edellyttää monimutkaisia laskennallisia lähestymistapoja kuva-analyysissä. Spektrikuvaus onkin suurelta osalta laskentaa ja tuloksia havainnollistavat kuvat tuotetaan vasta analyysin loppuvaiheissa.”.
Kun kasveja lisäksi analysoidaan lämpö- ja fluoresenssikameroilla, päästään näkemään asioita, joita ei tavallisessa valossa näe. Fluoresenssi on näkyvää, tietyn väristä valoa, joka syntyy kasvin atomien virittyessä esimerkiksi näkymättömän ultraviolettisäteilyn johdosta. Lämpö- ja fluoresenssikameroilla voidaan laskea pikseli kerrallaan kasvissa olevan erivärisen alueen koko ja tutkia esimerkiksi infektioita kasvissa.
Suomen ELIXIR-keskus tarjoaa datan käsittelyyn ja tallentamiseen tehokasta kapasiteettia. Koska fenotyyppien datankeruu on automatisoitu ja digitalisoitu, nyt on Kristiina Himasen mukaan mahdollista aloittaa myös datan standardointi.
”Datalla pitää olla sama formaatti. Excelerate-hanke kehittää standardit fenotyyppidatalle ja metadatalle. Mukana on 22 maata. Vaikka kaikilla on omat infrastruktuurit, niin nyt niiden toimintaa yhdenmukaistetaan.”
Käytännössä tutkijoilla on käytössään tieto kasvin perimästä sekä fenotyyppidataa kasvuolosuhteista ja muista ympäristötekijöistä. Kun molemmat datalähteet on yhdistetty saadaan luotua kattavia tietokantoja ja laboratoriot eri puolilla Eurooppaa voivat välttää päällekkäisen työn tekemistä ja jakaa datankeruuta järkevästi.
”Yksittäisen geenin käyttöönotto kasvijalostuksessa helpottuu, koska yksittäisen kasvin analyysiin liittyvän työn määrä kohtuullistuu.”
Jatkossa Viikin tutkimusryhmät siis tuottavat kuvapohjaista dataa, johon liitetään genomidata. Suomen Elixir-keskuksessa puolestaan mietitetään, miten data analyoidaan ja standardisoidaan ja miten metadatat luovutetaan ELIXIRrille pilvitietokantaa varten. NaPPI-infrastruktuurin ja Suomen ELIXIR-keskuksen CSC:n työnjako on hyvä esimerkki siitä, miten kasvien geno- ja fenotyyppidataa kannattaa tuottaa tutkimukseen.
Ari Turunen
11.8.2017
Sitaatti
Ari Turunen, Kristiina Himanen, Markku Keinänen, & Tommi Nyrönen. (2017). Better harvests on the horizon? Data will also be harvested. https://doi.org/10.5281/zenodo.8070177
Lisätietoja:
NaPPI
NaPPI on osa yhteistyöverkostoa Itä-Suomen yliopiston Spektromiikan yksikön (www.spectromics.org) sekä useiden muiden suomalaisten kasvitutkimuslaitosten kanssa. Mukana on yhteistyökumppaneita lisäksi Turun ja Oulun yliopistoista sekä Luonnonvarakeskuksesta.
Viikki Plant Science Center
https://www.helsinki.fi/en/researchgroups/viikki-plant-science-centre/about-vips
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Geenitutkimus on paljastanut, että mikrobeja on huomattavan paljon enemmän ja niiden yhteisöt ovat monimuotoisempia kuin tiedämmekään. Mikrobiyhteisöjen genetiikan tutkiminen synnytti uuden biotieteen alan, metagenomiikan. Jenni Hultman tutkii, mikä merkitys arktisten alueiden mikrobistolla on ilmastonmuutoksessa.
Mikrobit tai mikro-organismit ovat yksisoluisten tai muutamasta solusta muodostuneiden eliöiden yleisnimitys. Niitä ovat bakteerit, alkueläimet, virukset ja yksisoluiset levät. Vaikka mikrobeja esiintyy kaikkialla elinympäristössämme ja myös ääriolosuhteissa, niiden geneettistä alkuperää ja toimintaa tunnetaan edelleenkin huonosti. Suurinta osaa mikrobeista ei tunneta.
Termillä metagenomi tarkoitetaan sitä, että joukko ympäristöstä noukittuja ja sekvensoituja geenejä voidaan analysoida samalla tavoin kuin yksittäisen lajin genomia eli perimää. Metagenomiikan avulla voidaan selvittää mikrobiston muutoksia eri sairauksien aikana ja hoidon jälkeen, löytää uusia taudinaiheuttajia ja saada tietoa niiden toiminnasta esimerkiksi lääkityksen aikana. Metagenomiikan avulla voidaan tutkia myös, miten mikrobit vaikuttavat elinympäristöömme.

Metagenomiikassa DNA eristetään mikrobiyhteisöstä. Tämä on ollut suhteellisen helppoa, kun mikrobeja on tutkittu esimerkiksi suolistossa ja vesistöissä.
Maaperän tutkiminen on huomattavasti haasteellisempaa johtuen mikrobien suuresta määrästä yksittäisessä näytteessä. Yhdessä näytteessä voi olla jopa 10 000 eri lajia. Koska eri mikrobien DNA:ta voidaan uusien tekniikoiden avulla eristää maaperästä, mikrobien tutkimus elää jatkuvaa murrosta. Koko ajan saadaan uutta tietoa eliöistä ja myös itse elämän synnystä Maapallolla. Mikrobiyhteisöt ovat kuitenkin haasteellisia tutkittavia. Mikrobien monimuotoisuus on valtava ja ne myös vaikuttavat toisiinsa tavalla, joita ei kunnolla vielä tunneta.
”Perinteisesti mikrobeja on kasvatetty petrimaljoissa. Mutta nyt kyseessä on valtava määrä tutkittavaa, koska kohteena ovat mikrobiyhteisöt, joissa eri mikrobit ovat riippuvaisia muista mikrobeista tai ravinteista. Tällaisia yhteisöjä ei voida kasvattaa maljoilla. Nyt tarkoitus on sekvensoida valtaosa maaperänäytteessä olevat geenit. Vaikka saataisiin selville, mikä laji on kyseessä, tärkeää on myös tietää, mitä sen geenit tekevät. Koska mikrobiyhteisöstä sekvensoidaan jopa miljoonia geenejä, tähän tarvitaan laskentatehoa”, sanoo akatemiatutkija Jenni Hultman.
Hultman on kiinnostunut erityisesti arktisten alueiden mikrobistosta. Koska mikrobit toimivat hajottajina luonnossa, niillä voi olla merkittävä rooli kasvihuonekaasujen, kuten hiilidioksidin ja metaanin muodostumisessa. Metaanin vaikutus kasvihuoneilmiöön on lyhyellä aikavälillä monikymmenkertainen hiilidioksidiin verrattuna.
”Arktisten ympäristön mikrobeja ei tunneta hyvin. Ne voivat vaikuttaa siihen miten ilmasto ja olosuhteet muuttuvat. Kysymyksiä on paljon. Miten luonto sopeutuu ilmastonmuutokseen? Mitä lajit tekevät kun ilmasto muuttuu?”
Kun ikiroudan alla olevat turvesuot alkavat sulaa, syntyy erityisesti metaanipäästöjä. Mutta minkälainen merkitys mikrobeilla on tässä prosessissa? Tämän Hultman haluaa selvittää.
Helsingin yliopiston Elintarvike- ja ympäristötieteiden laitoksella työskentelevä Hultman kerää tutkimusaineistoa mikrobeista eri puolilla pohjoista pallonpuoliskoa. Tutkimuksessaan Hultman analysoi maaperänäytteitä Kilpisjärvellä, Alaskassa ja Grönlannissa. Nyt hän etsii mittauspaikkaa Siperiasta, jolloin hänen keräämänsä näytteet edustaisivat hyvin koko pohjoista pallonpuoliskoa.
”20% Maapallon maapinta-alasta on ikiroudan peitossa. Ikiroudan sisällä ovat valtavat hiilivarastot. Ikiroudan sulaessa voi ilmakehään voi vapautua suurimmat hiiidioksidimäärät, mitä on ikinä mitattu.
Tämä prosessi on riippuvainen mikrobisesta vasteesta, mutta tällä hetkellä tiedämme vähän mikrobien aktiivisuudesta ikiroudan alla.”

Hultman on kiinnostunut mikrobiyhteisöjen aktiivisuudesta ja erityisesti siitä, mitä mikrobiyhteisöjen geenit tekevät (metagenomiikka) ja kuinka aktiivisia yhteisöjen geenit tietyllä hetkellä ovat (metatranskriptomiikka).
Hultman eristää Kilpisjärven kenttäalan maaperänäytteistä kokonais-DNA:n ja RNA:n, pilkkoo ne pienemmiksi paloiksi ja sekvensoi ne. Hän eristää DNA:n ja RNA:n 0,5 gramman näytteistä. Näytepisteiden määrä on yli sata. Alueella on mikroilmasto, jolloin Hultman voi ottaa huomioon eri tekijöitä, kuten kosteuden, pH-arvon ja lämpötilan. Näin voidaan tutkia mikrobiyhteisöjen aktiivisuuden merkitystä ilmastonmuutoksessa ”mini-ilmastonmuutos”-skaalalla.
”Rinnakkaisia puolen gramman näytteitä tarvitaan paljon koska maaperän mikrobisto on monimuotoista ja koska maaperä itsessään vaihtelee paljon. Mikrobit voivat esiintyä kivessä, kuolleessa madossa, kasvin juuressa tai vain kosteammassa paikassa kuin joku toinen. Eli paljon on kaivettavaa ja eristettävää.”
Olennaista on tietää, mitä mikrobien geenit aktiivisesti tekevät ja miten ne vaikuttavat
ilmastonmuutokseen.
”Tutkin mitä maanäytteessä tapahtuu tällä hetkellä. Mitkä ovat aktiivisia geenejä? Kiihdyttääkö osa mikrobeista ilmastonmuutosta ja osa jarruttaa? Tuottavatko mikrobit pelkästään metaania vai hyödyntävätkö ne sitä?”
Hultmanin tutkimuksen yhtenä tärkeänä tavoitteena on tuottaa metagenomiikasta saatua dataa myös ilmastomalleihin. Näin voidaan mahdollisesti parantaa ilmastomallien luotettavuutta.

Yhdessä grammassa maaperää voi olla jopa kymmenen miljardia erilaista mikrobia. Kun mikrobiekologian tutkimus kunnolla alkoi 1970-luvun lopulla ja ympäristöstä otettuja mikrobinäytteitä verrattiin viljeltyihin mikrobinäytteisiin, havaittiin, että ympäristöstä saaduissa näytteissä oli jopa 99% enemmän uusia ja tuntemattomia mikrobeja kuin viljelynäytteessä.
Perinteisesti geenien sekvensointi alkaa kasvattamalla soluja petrimaljassa. Kun DNA-sekvensseriin laitetaan soluista saatua DNA:ta, sekvensseri selvittää DNA-emäsparien eli adeniinin, guaniinin, sytosiinin ja tymiinin järjestyksen. Varhaiset metagenomiset tutkimukset paljastivat kuitenkin, että on isoja mikro-organismien ryhmiä, joita ei voi kasvattaa laboratorioissa ja niitä ei voida siten sekvensoida.
Varhaiset tutkimukset keskittyivät 16S rRNA-geenin tuottamiin sekvensseihin. Kaikissa elollisissa olennoissa tavatun 16S rRNA:n tehtävänä on tuottaa ribosomeja, jossa proteiinisynteesi tapahtuu. Vuonna 1977 mikrobiologi Carl Woese aloitti tämän geenin sekvensoinnin tutkiessaan mikrobeja. Koska geeni on aina hieman erilainen eri mikrobeilla, Woese huomasi, että sitä voi käyttää näytteiden mikrobiston kehityshistorian tutkimisessa. Woese ja hänen kollegansa George E. Fox kuitenkin yllättyivät, kun monet eristetyt 16S rRNA-sekvensseistä eivät kuuluneet mihinkään tunnettuun eliölajiin. 16S rRNA-geenin avulla tehdyt löydöt mullistivat mikrobien tutkimuksen.
Woese ja Fox havaitsivat että näytteistä löytyi myös yksisoluisia, mutta tumattomia mikro-organismeja, jotka muistuttivat ulkoisesti bakteereja, mutta eivät olleet niitä. He kutsuivat tätä ryhmää arkeoneiksi.
Arkeonit osallistuvat aineenvaihduntaan ja vaikuttavat entsyymien toimintaan. Aluksi arkeoneja havaittiin vain äärimmäisissä olosuhteissa, kuten kuumissa lähteissä ja suolajärvissä, mutta sittemmin niitä on löydetty esimerkiksi myös eri maalajeista, marskimailta, valtameristä ja jopa ihmisen suolistosta.
Näin eliöt voitiin jakaa kolmeen luokkaan. Eukaryootit eli monisoluiset kasvit, sienet ja eläimet kuuluvat aitotumaisiin. Bakteerit ja arkeonit taas ovat tumattomia mikrobeja, joista suurin osa maailman biodiversiteetistä koostuu.
”Koska DNA:n sekvensoiminen halpenee koko ajan, metagenomiikka mahdollistaa mikrobeiden tutkimuksen paljon suuremmalla skaalalla ja yksityiskohtaisemmin kuin aiemmin”, Jenni Hultman toteaa.
Salaperäisillä arkeoneilla voi olla suurempi rooli metaanin muodostumisessa kuin aiemmin on tiedetty. Osa arkeoneista hajottaa orgaanisen hiilen metaaniksi. Mutta kuinka paljon tällaisia arkeoneja on ja kuinka tehokkaita hajottajia ne ovat?
Jenni Hultmanin ja muiden tutkijoiden keräämä data mikrobiomin salaisuuksista tallennetaan julkisiin tietoresursseihin, joita ylläpitää ELIXIR, Euroopan bioinformatiikan infrastruktuuri.
Ari Turunen
19.6.2017
Sitaatti
Ari Turunen, Tommi Nyrönen, & Jenni Hultman. (2017). Microbes and climate change. https://doi.org/10.5281/zenodo.8070142
Lisätietoja:
Elintarvike- ja ympäristötieteiden laitos, Helsingin yliopisto
http://www.helsinki.fi/elintarvike-ja-ymparisto/
CSC – Tieteen tietotekniikan keskus Oy
CSC on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Suomalaisten geeniperimästä tehdään laajoja tutkimusprojekteja ja genomidataa tuotetaan ja analysoidaan koko ajan. Kansallinen tavoite on kuitenkin tallentaa suomalaisista tuotettu data Suomeen, jolloin analyytikot voivat yhdistää datan muihin terveystietoihin. Genomidatan hyödyntäminen terveydenhoidossa on vasta alussa. Data-analyysi tarjoaa paljon mahdollisuuksia bioalan yrityksille myös Suomessa.
Tutkimuskäyttöön soveltuvaa geenidataa suomalaisista on sirpaleina eri puolilla maailmaa eri tietokannoissa ja datavarastoissa ja vaihtelevasti järjestettynä. Tarve olisi siis luoda suomalaisen datan hallintaan kotimainen tietoturvallinen palvelu, joka ylittäisi organisaatiorajat, on verkostomainen ja hyvin koordinoitu. Kun eri paikoissa sijaitseva data koordinoitaisiin yhteen paikkaan, data voitaisiin omistajan luvalla luovuttaa laillisiin käyttötarkoituksiin, kuten tutkimukseen, tuotekehitykseen ja lääkehoitoihin.
Ihmisen biologia on hyvin monimutkaista, monimutkaisempaa kuin aiemmin on luultu. Geenin ja elimistön rakennusaineiden eli proteiinien ilmeneminen, rakenne ja niiden toiminta edellyttävät kehittyneitä matematiikan, tietojenkäsittelytieteen sekä tilastotieteen menetelmiä eli bioinformatiikkaa.
Bioinformatiikan menetelmien, kuten geenien sekvensoinnin, avulla löydetään koko ajan uusia tapoja tutkia ja ehkäistä sairauksia. DNA:n sekvensointi on lähtökohta, jossa määritetään DNA-molekyylin neljän eri emäksen, adeniiniin, guaniini, sytosiini ja tymiini (A, G, C,T) järjestys geneettisen digitaalisen koodin selvittämisessä. Jokainen ACGT-emäs on vastaava tiedonjyvä kuin tietokoneen bitti, nolla tai ykkönen, jotka pitkänä ketjuna sisältävät ohjeet ohjelmaan.
Sekvensointimenetelmien parantuminen ja halpeneminen ovat lisänneet merkittävästi biologian ja lääketieteen mahdollisuuksia tuottaa tämänkaltaista dataa. Nyt datan avulla saadaan selville mitä digitaalisia viestejä elämän molekyyleihin on kirjoitettu eliöiden selviämistä varten.
Data on kuitenkin vasta ensimmäinen askel kohti tulkintaa. Digitaalisen genomidatan tulkinta, eli miten genomiin tallennettu tieto ilmenee elimistössä, on vielä kehittymässä. Esimerkiksi viimeisen kymmenen vuoden aikana on Ruotsissa luotu karttaa (HPA Human Protein Atlas) siitä, miten geenit ilmenevät proteiineina eri soluissa ja yhdistetty tämä tieto mikroskooppikuviin soluista. Näin siis voidaan nähdä, mikä geeni ilmenee missäkin solussa ja osallistuu proteiinien ja sitä kautta suurempien rakenteiden esimerkiksi hermosäikeiden, hiustuppien tai silmänpohjan valoa aistivien rakenteiden syntymiseen. Ei ole kuitenkaan vielä selvää syvemmän tason karttaa siitä, miten nanometrien skaalassa toimivat molekyylit tuottavat nämä toiminnalliset mikroskooppiset rakenteet. Jokaiseen solun rakenteeseen tarvitaan miljoonia molekyylejä yhteistyössä. Genomeihin tallennettu rakennusohje ja sen tuottamat molekyylit muodostavat itsestään organisoituvan verkon, jota pyritään nykytutkimuksella ymmärtämään.
Suomella on melko hyvät lähtökohdat olla kansainvälinen toimija genomitiedon hallinnassa, mutta osaajia on yksittäisissä organisaatioissa liian vähän. Genomitiedon ymmärtämiseen vaadittavat tietomassat ovat suuria ja analysointi vaatii erikoistunutta osaamista toimijoita, jota ei vielä löydy riittävästi Suomesta. Tarvitaan yhteistyötä genomidatan hallintaan ja lisää dataan erikoistuneita tulkitsijoita. Osaamista saadaan Suomeen lisää, kun päästään luomaan puitteet suomalaisten genomien tallentamiselle. Tämä tarkoittaisi aluksi kymmenien tuhansien ihmisten datasta luotua kansallista viitetietokantaa. Siitä olisi hyötyä diagnostiikassa, esimerkiksi lääkehoitojen parantamisessa, sillä jo nyt voidaan potilaan genomitiedon perusteella määrittää esimerkiksi sopiva ja turvallinen lääkitys.

Molekyyleistä, soluista tai kokonaisista organismeista saadun datan analysointi edellyttää, että data on järjestetty hyvin. Sekvensoinnilla, mikroskoopeilla, massaspektrometrialla tai tietokonesimulaatioilla tuotetuilla data-aineistoilla pitää olla yhteiset tiedostostandardit ja riittävästi koneluettavia rajapintoja, joita noudatetaan kun dataa varastoidaan. Hyvä mittari datan järjestämisen asteelle on, jos toinen tutkimusryhmä pystyy hyödyntämään dataa yhtä hyvin kuin sen alkuperäiset tuottajat.
Kun data on hyvin järjestetty ja kuvailtua, sitä voidaan yhdistellä. Täydentävien tietojen, esimerkiksi lääkemääräyksen, genomin ja pitkäaikaisten hoitotulosten liittäminen yhteen on edellytys syvemmän ymmärryksen kehittymiselle.
Taitavien analyytikoiden käsissä järjestetty data auttaa saavuttamaan läpimurtoja tutkimuksessa. Esimerkiksi yhdysvaltalainen GRAIL-yritys pyrkii ymmärtämään syövän syntymekanismeja. Mitä varhaisemmassa vaiheessa syöpä havaitaan, parantaa se huomattavasti taudin hoitoennustetta. GRAIL-hankkeessa on kerätty 10 000 potilaan näytteet ja suostumus niistä luodun monipuolisen datan analysointiin. Ideana on, että tämän potilasjoukon syöpäkasvaimista luodaan tietokanta, jota vastaan voidaan tehdä verinäytteiden seulontaa.
Syöpäkasvaimet ovat yleensä seurausta siitä, että sairautta kantavan ihmisen solun genomiin on tullut muutos, joka on tekee solusta epänormaalin. Jokainen syöpä on solutasolla kantajansa näköinen melko yksilöllinen sairaus, joita yhdistää epänormaalien solujen holtiton kasvu. Syöpä hyödyntää elimistön normaaleja uusiutumisen ja parantumista mekanismeja omien geneettisten ohjeidensa itsekkääseen levittämiseen. Kahden ihmisen väliset genomit ja niiden sisältämä digitaalinen informaatio ovat keskimäärin 99,5% samanlaiset. Siksi monien syöpien etenemisprosessi on syöpien yksilöllisyydestä huolimatta hyvin tunnettu. Siksi onkin perusteltua tutkia, miten yksittäisten tai useampien nukleotidien (ACGT) muutokset genomissa vaikuttavat solun molekyyliverkoston tasapainoon siten, että solusta tulee syöpäsolu.
GRAIL-hankkeessa potilaiden genomeista ja heidän syöpäkasvaimistaan sekvensoidaan miljoonia ainutlaatuisia genomitiedon muutoksia, jotka voivat aiheuttaa syöpää. Hanke luo tietokannan, jonka avulla terveydenhuollossa pystytään havaitsemaan syövän varhaiset vaiheet, jopa suoraan verenkierrosta. Innovaation onnistuessa syöpäseulontaa voidaan alkaa tehdä entistä varhaisemmassa, jolloin kasvaimet ovat vasta mikroskooppisen pieniä ja helpommin hallittavissa esimerkiksi lääkeaineilla.
Samanlaisen tutkimuksen tekeminenon mahdollista Suomessa yhdistämällä terveys- ja genomitiedot. Esimerkiksi Suomen ELIXIR-keskus on jo alkanut rakentaa genomitiedon hallinnalle ja tallentamiselle tarvittavaa tietoturvallista infrastruktuuria.

Tieteen käyttöön on saatavissa satoja kertoja enemmän dataa DNA:n sisältämästä tiedosta kuin kymmenen vuotta sitten. Ymmärrys siitä, miten genomiin tallentunut tieto välittyy molekyylitasolla esimerkiksi proteiineiksi, ja edelleen solujen kolmiulotteisiksi toiminnallisiksi yksiköiksi kasvaa kovaa vauhtia. Kun ihmisen biologiaa ymmärretään solutasolta molekyylien tasolle, se parantaa elämänlaatua ja sairauksien hoitoa.
Yksi tärkeimpiä bioinformatiikan tutkimuskohteita on tautien pohjimmaisten syntymekanismien ymmärtäminen. Geenin koodaama toiminnallinen yksikkö on proteiini. Se on satojen yksiköiden, aminohappojen, ketju. Aminohappoja on 20 erilaista. Geenien ohjeistama proteiiniketju tulee solun toiminnalliseksi yksiköksi, vaikkapa entsyymiksi vasta sen jälkeen, kun se on laskostunut kolmiulotteiseen muotoonsa ja voi aloittaa vuorovaikutuksen toisten solun molekyylien kanssa. Väärin laskostunut proteiini voi johtaa sairauteen, koska se ei toimi odotetulla tavalla elämälle tärkeiden molekyylien muodostamassa verkostossa.
Joskus esimerkiksi geneettisessä koodissa on muutos tämän kriittisen toiminnallisen yksikön eli proteiinin laskostumiselle kriittisessä kohdassa. Solut muokkaavat itseohjautuvasti syntyvien proteiinin koostumusta ja sitä kautta niiden rakennetta ja toimintaa. Tämä voi korjata geneettiseen koodiin syntyneen virheen. Toisaalta voi myös käydä niin, että proteiini menee rikki solun omassa prosessissa. Useimmat sairaudet voidaan jäljittää tilanteisiin, jossa solun molekyylien verkoston
dynamiikkaan on tullut tärkeään kohtaan biokemiallinen lukuvirhe. Toisaalta kyseessä voi olla vain muunnelma jonka seuraus ihmiselle on vain suositus, miten kannattaa valita ruokavalionsa. Molekyylitason muutosten vaikutus genomiin talletettuun dataan riippuu monesta asiasta, sillä DNA:ssa on jokaisesta geenistä ”varmuuskopio” molemmilta vanhemmilta. Joistakin geeneistä on jopa useita versioita.
Vaikka logiikka ja tieto siitä mitkä ovat biologisten prosessien verkoston tärkeimmät pelurit alkavat olla selvillä, dynaamista kokonaisuutta ei vielä osata hahmottaa saati ennustaa tai muokata lääketieteellisesti niin hyvin kuin haluttaisiin. Esimerkiksi sepelvaltimotautiin sairastumisen riskien ennakointi on genomista saadun datan ansiosta tarkentunut, mutta molekyylitason tapahtumien ymmärrys on siinä vaiheessa, että komponentit tunnetaan, mutta ponnistellaan niiden välisen toiminnan tai molekyylitasolla esiintyvien vikojen ymmärryksessä. Tautien molekyylitason ymmärrys kuitenkin merkitsee tarkempia ja varhaisempia diagnooseja, ja että
ehkäisytoimet voidaan aloittaa varhain ja esimerkiksi riskiryhmässä olevat voivat halutessaan muuttaa elintapojaan.
Tommi Nyrönen
Ari Turunen
21.5.2017
Tommi Nyrönen on biokemisti ja Suomen ELIXIR-keskuksen johtaja.
Ari Turunen on tietokirjailija ja Le Monde Diplomatiquen Suomen edition
päätoimittaja.
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, & Tommi Nyrönen. (2017). Storing the whole genome of the Finnish population? The data will benefit disease research. https://doi.org/10.5281/zenodo.8070146
Lisätietoja:
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keski- tettyä tietotekniikkainfrastruktuuria.
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Kun dataa kerätään entistä enemmän ihmisen perimästä ja elintavoista, on pidettävä huoli omasta tietosuojasta. Ketkä ovat tarpeeksi päteviä tulkitsemaan ja käyttämään tätä dataa?
Biologisen informaation räjähdysmäinen lisääntyminen vaikuttaa sekä yksilöihin että yhteisöihin. Ihmisen koko elinkaaren ennustaminen tietyillä geneettisillä lähtökohdilla ja elintavoilla tulee mahdolliseksi. Samaan aikaan kun tieto lisääntyy, lisääntyvät myös mahdollisuudet käyttää dataa muihin tarkoituksiin kuin alunperin on tarkoitettu. Uskaltaako tulevaisuudessa enää nauttia epäterveellisiä ruokia, jos siitä kerätään tietoa, joka voi vaikuttaa esimerkiksi vakuutusehtoihin?
Taloudelliset ja yhteiskunnalliset vaikutukset seuraavat viiden–kymmenen vuoden aikana, kun bioinformatiikkaa aletaan soveltaa ennaltaehkäisevässä terveydenhuollossa. Esimerkiksi, jos henkilöllä on tunnettu geneettinen alttius sairastua maksasairauksiin, jonka voi hoitaa elintapoja suunnittelemalla, asian kertominen varhaisessa vaiheessa luultavasti vaikuttaa elintapojen valintaan. Terveydenhuollon ammattilaiset voivat perustella suosituksiaan esittämällä esimerkkeinä tunnettuja koko elämän kattavia
hoitohistorioita sairaanhoitojärjestelmästä tai biopankista.
Avoimia kysymyksiä yhä riittää: miten ja missä laajuudessa modernia biologista informaatiota tulkitaan ja käytetään julkisessa terveydenhuollossa? Miten lainsäädäntö kehittyy? Tilaus parempaan ikääntyvien terveydenhuoltoon kasvaa ja siksi asiaan olisi saatava nopeasti selvyyttä. Monet vakuutusyhtiöt ja datan käsittelyn jätit, kuten Google, ovat kiinnostuneita avautuvista mahdollisuuksista.
Yhdysvaltalainen 23 & me tarjoaa kenelle vain testejä, joilla saa tiedon sadoista lääketieteellisistä riskeistä, jotka liittyvät oman perimän piirteisiin. Sairauksia, joiden synty voidaan analysoida molekyylitasolle saakka on jo paljon. On mahdollista diagnosoida sairauksia, esimerkiksi syöpiä, entistä tarkemmin. Se muun muassa vähentää rankoista hoidoista johtuvia sivuvaikutuksia. Uusilla tekniikoilla voidaan myös ennustaa yksilön terveydentilan muutoksia.
Ketkä pystyvät, saavat tai osaavat osallistua terveyden jatkuvaan tarkkailuun, jolla voidaan esimerkiksi ennustaa tulevia muutoksia? Kuka tulkitsee, onko henkilö ajautumassa vakavaan sairauteen ja voiko diagnoosiin luottaa? Kenen harvinainen sairaus saadaan parannettua ja tehdäänkö se julkisin varoin? Millä eettisillä reunaehdoilla pääsy viimeisimpiin hoitoihin koordinoidaan?
Teknologia tarjoaa koko ajan enemmän mahdollisuuksia tarkkailla reaaliaikaisesti terveyttä ja elintapoja yksilötasolla. Erilaiset teknologiset apuvälineet terveydentilan monitorointiin tulevat koko ajan halvemmiksi ja sulautuvat kaikkien jo nyt mukana oleviin laitteisiin, kuten kännykkään, vaatteisiin tai rannekelloon. Esimerkiksi vakuutusyhtiö Lähitapiolalla on Suomessa meneillään uusi kokeilu, jossa yhtiö tarjoaa ”älyhenkivakuutusta.” Vakuutusyhtiö tekee yhteistyötä biomonitoreita tekevän Polarin kanssa ja kerää mm. syke- ja elintapatietoja sovellukseen, joka auttaa lääkäreitä tekemään ennusteita henkilön terveydentilasta. Asiakkaan on mahdollista alentaa vakuutusmaksuja, jos tietyt terveelliset elämäntavan
ehdot toteutuvat vakuutusyhtiölle luovutetussa datassa. Yksilöt siis hyötyvät alentuneista vakuutusmaksuista, jotka kannustavat terveempiin elintapoihin. Vastapalveluksena vakuutusyhtiö hyväksyy ”maksuvälineeksi” dataa, jota se hyödyntää.
Tämä data on arvokasta. Luotettavat ja hyvin järjestetyt datalähteet, joita käytetään yksilöiden terveyden tulkinnassa, ovat valuuttaa kansainvälisessä kaupankäynnissä. Britanniassa National Health Service NHS on päättänyt avata yli miljoonan lontoolaisen hoitohistorian Googlelle. Toiveena on, että Google asiantuntijoiden pääsy dataan auttaa ehkäisemään suuria kustannuksia julkisessa terveydenhuollossa aiheuttaviin munuaissairauksiin. Arvioidaan, että jopa neljännes sairaustapauksista voitaisiin estää, jos riskitilanteet havaittaisiin aikaisemmin ja henkilöt muuttaisivat elintapojaan. Tämä toisi merkittäviä säästöjä julkiselle sektorille ja parantaisi kansanterveyttä.

Ihmisten itse itsestään kerryttämä elämäntapaan liittyvä data esimerkiksi lenkeistä, syödystä ruuasta ja nautitusta alkoholista päätyy tällä hetkellä internetiin hyvin erilaisiin palveluihin, tai häviää muutaman vuoden sisällä keruusta. Dataa keräävien palveluiden tarkoitus on useimmiten voiton tavoittelu esimerkiksi sitouttamalla ihmiset teknologisten laitteiden ekosysteemiinsä. Siksi kerrytetyn datan liittäminen kolmansien osapuolten tietolähteisiin ei useinkaan onnistu. Datan käyttö luotettavan diagnosoinnin tukena vaatii pääsyä laajoihin ja tutkimuksiin, joiden valossa esimerkiksi yksittäinen näytteestä saatu data voidaan tulkita oikein. Tällainen datan integraatio on vielä alkutekijöissä.
Kehitysvauhti on kuitenkin valtava. Esimerkiksi koirista kerätyn datan tarkastelua rajoitetaan lainsäädännöllisesti vähemmän kuin ikuin ihmisistä, ja niille on jo saatavissa monenlaisia genetiikkaa ja elintapoja yhdistäviä terveyttä edistäviä palveluita (MyDogDNA). Ihmisen parhaan ystävän seuraava suuri palvelus voikin olla auttaa osoittamaan, millä tavalla geneettistä biologista informaatiota kannattaa käyttää terveydenhoidossa.
Terveydenhuollon organisaatiot keräävät dataa ja näytteitä ihmisistä hoitojen ohella tutkimustarkoituksiin. Datan ja näytteiden luottamuksellisesta keruusta on aina vastuussa lääketieteen ammattilainen. Kerääjän lupa kysytään, jos näitä käytetään uusiin tarkoituksiin.
Vallitseva käytäntö helpottaa ratkaisevasti terveyttä parantavien tutkimusten tekemistä. Pohjoismaissa on ollut vuosikymmeniä toiminnassa keskitetty terveydenhuolto, joka on kyennyt myös organisoimaan ja tarjoamaan laadukasta dataa tutkimustyötä varten. Esimerkiksi norjalaisista yli 30 prosentin osalta on näyte biopankissa. Suomessa on koottu yli 150 miljoonaa sairaskertomusta 4,3 miljoonasta kansalaisesta arkistoon.
Suomessa on yhteensä noin 5,4 miljoonaa asukasta ja vuonna 2016 lähes kaikkien lääkereseptit
päätyvät samaan arkistoon. Biopankkilaki Suomessa takaa myös sen, että datan vastuullinen tutkimuskäyttö voi tapahtua informoimatta jokaista kansalaista erikseen asiasta. Kokonaisuus antaa erinomaiset lähtökohdat tulkita geneettisten lähtökohtien ja elämän aikana tapahtuvien asioiden yhteyksiä, jos voidaan luoda pääsy dataan turvallisesti ja riittävän avoimesti suurelle kansainväliselle joukolle taitavia analyytikoita.
Mutta mitä datasta voi lukea nyt ja ennen kaikkea mitä tulevaisuudessa? Britanniassa Googlelle on annettu pääsy kaikkeen potilasdataan, koska ennalta ei voi tietää, mitkä tekijät ovat ennustavia ja selittäviä munuaissairauden kehittymiseen. Mutta entä jos tätä ennustettaessa käy ilmi, että henkilöllä on akuutti riski saada sydänkohtaus? Pitäisikö asiasta kertoa henkilölle? Pohjoismaiset biopankit ovat tutkineet, että noin 60 prosenttia ihmisistä haluaa tietää satunnaisista löydöistä. Loput 40 prosenttia ei halua tietää. Kuka omistaa ihmisestä kerätyn datan ja näytteet ja kenellä on oikeus hallinnoida niitä esimerkiksi tutkimustarkoituksiin?
Lainsäädännön on luotava linjauksia, jotka eivät jarruta kehitystä biologisen informaation ymmärryksestä. Lakien pitäisi suojella riittävästi datan luovuttajia ja lähteitä väärinkäytöksiltä ja ylläpitää datan infrastruktuuria ja sen palveluita, joiden varaan voidaan rakentaa uusia palveluita. Terveydenhoidon päätöksenteon tukijärjestelmät nojautuvat rakennettuihin ja ylläpidettyihin tietolähteisiin.
Kansainvälisessä yhteistyössä pystytään rakentamaan ihmisen geneettisten lähtökohtien ja elintapojen
ja hoitohistorian valossa luotettavampia tietolähteitä kuin yksikään maa pystyy yksin rakentamaan. Tämän vuoksi olisi pyrittävä kohti globaalisti saatavilla olevia datan lähteitä myös ihmiseen liittyvän biologisen informaation käsittelyssä ja tulkinnassa.
Kansainvälinen pääsy dataan lisää demokratiaa, koska ihmisistä kerätyn tutkimusdatan käytön tulkintoihin tarvittavat kustannukset voidaan jakaa. Samalla voidaan tukea maita, jotka eivät yksinään kykenisi luomaan tietopalveluita. Ihmisistä saadaan tehtyä nykyään mittauksia kaikkialla, mihin internet yltää – haaste on, että mittaustulosten tulkinta voidaan suorittaa luotettavasti. Tähän kansainvälisesti avoimet ja tietoturvalliset tietopalvelut olisivat yksi ratkaisu.
Esimerkiksi ihmisen perimässä on noin 20 000 sellaista geeniä, jotka ohjeistavat elimistön kaikkia toimintoja. Joskus geneettinen informaatio kuitenkin korruptoituu, mikä voi johtaa esimerkiksi rintasyövän syntyyn. Kansainvälinen tutkimusryhmä on osoittanut, että perimässä on täsmälleen 93 geeniä, jotka mutatoituessaan muuttavat terveen solun rintasyöpäsoluksi. Tämänkaltainen informaatio on erittäin tärkeää suunniteltaessa uusia lääkkeitä, koska mutatoituneesta geenistä syntyvät proteiinit ovat kohteita lääkemolekyylien suunnittelulle. Sairastunut henkilö voidaan myös entistä tarkemmin diagnosoida tiedon avulla.
Tämän tyyppisen biodatan sulkeminen rajoitetun joukon saataville olisi väärin. Siksi tarvitaan avoimia palveluita biologiselle informaatiolle, jotta tutkimustulokset ovat yliopistojen, tutkimuslaitosten ja lääketeollisuuden saatavilla silloin, kun niitä tarvitaan. Yksi tällainen tietopalvelu on European Genome-Phenome Archive EGA, joka on osa eurooppalaista ELIXIR-tutkimusinfrastruktuuria. EGA suojelee biologista informaatiota vanhalla mantereella. EGA varastoi suuria ihmisperäisiä biolääketieteellisiä data-aineistoja ja jakaa dataa luvanvaraisesti. Tähän eurooppalaiseen globaaliin palveluun voivat laittaa dataa niin yliopistot, tutkimuslaitokset, yritykset kuin julkishallintokin. Palvelua on käytetty esimerkiksi pohjoismaisessa julkisessa terveydenhuollossa pitkien aikasarjojen ja koko populaation (geenipoolin) kattavien tutkimusten datan julkaisuun.
Seuraavien vuosikymmenien aikana ihmisistä kerätyn data hyödyntäminen on osa yhteiskuntaa. Valistuneet kansalaiset osaavat vaatia uudenlaisia terveyspalveluita. Alan yksityisten palveluiden sektori voi kasvaa nopeasti. Tarvitaan kuitenkin kansainvälisesti luotuja tietolähteitä ja standardeja, joiden varaan pieni- ja keskisuuri sektori voi rakentaa ja jotka tuovat takuita mittausdatan tulkinnan laadulle. Geneettisen, molekyylibiologisen ja elintapoja keräävien tietolähteiden korrelointi on vasta aloitettu.
Tommi Nyrönen
6.4.2017
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, & Tommi Nyrönen. (2017). ”Smart life insurances” offered: human biological data is only useful when interpreted correctly. https://doi.org/10.5281/zenodo.8070130
Lisätietoja:
CSC – Tieteen tietotekniikan keskus Oy
CSC – Tieteen tietotekniikan keskus Oy on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 20 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.
https://www.elixir-finland.org
http://www.elixir-europe.org

BioCity Turun bioinformatiikan yksikkö on keskittynyt geeni- ja proteiinidatan analysoimiseen. Data-analyyseista on hyötyä erilaisten tautimekanismien ymmärtämisessä. Yksikössä on tutkittu erityisesti syöpäsairauksia ja aikuisiän 1-tyypin diabetesta. Yksikön tavoitteena on parantaa monimutkaisten tautien diagnostiikkaa, hoitoa ja ennustettavuutta yhdistämällä laskennallista, kokeellista ja kliinistä tutkimusta.
Bioinformatiikan menetelmien avulla analysoidaan proteiinien kolmiulotteisia rakenteita. Näin voidaan selvittää, millaiset lääkeaihiot, tyypillisesti pienet molekyylit, todennäköisesti vaikuttavat proteiiniin. Hyödyntämällä näitä tietoja tutkijat voivat ymmärtää solun normaalia toimintaa ja miten proteiinien toimintaan kannattaa vaikuttaa. Lopputuloksena voi olla uusi lääkeainemolekyyli, joka vaikuttaa kohdeproteiiniin halutulla tavalla.
”Kahden molekyylin kohdatessa tapahtuu aina vuorovaikutusta. Yhteensopiva muoto ja kemia lisäävät tätä vuorovaikutusta merkittävästi. Jos kohtaaminen on voimakas, se voi muuttaa molekyylin mahdollisuutta vaikuttaa kolmanteen molekyyliin. Siten signaali välittyy ketjussa, jossa on eri molekyylien kohtaamisia”, kertoo bioalan tietotekniikkaan erikoistunut Åbo Akademin tutkija Jukka Lehtonen.
Lehtonen korostaa, että viestiä välittävät molekyyliparit eivät kuitenkaan ole täydellisen täsmällisiä, jolloin kyseessä ei ole suoraviivainen viestinvälitysketju. Pikemminkin voidaan puhua molekyylien vuorovaikutusten verkosta.
”Solujen ns. normaali toiminta on herkkä tasapainotila. Lääkkeillä yritetään ylläpitää tätä normaalia tilaa. Esimerkiksi diabeteksessä solujen oma insuliinitoiminta on häiriintynyt, joten lääkityksellä ja ruokavaliolla korvataan vähentyneitä vuorovaikutuksia.”
”Myös haitallisesti toimivia signaaliketjuja yritetään hillitä lääkityksellä.”
Lääkeainemolekyylien suunnittelussa on tärkeää, että ketju tapahtumia toimii halutulla tavalla kaikissa molekyyleissä. Jos esimerkiksi signaaliketjussa oleva kolmas molekyyli aktivoituu liikaa, lääkkeellä ei välttämättä ole haluttuja vaikutuksia.
”Lääke on tehokas ja sivuvaikutuksia on vähän, jos lääkemolekyylin ja proteiinin sitoutumiskohdan rakenteet ovat riittävän ainutlaatuisia ja yhteensopivia.” Lehtonen toteaa.
”Samantyyppisiä proteiineja on kuitenkin ihmiskehossa paljon ja epätäsmällisemmätkin vuorovaikutukset voivat muuttaa annosteltuja lääkemolekyylejä kemiallisesti.”
Lääkesuunnittelussa on siten kaksi osaa: optimaalisten molekyylien suunnittelu kohdeproteiinille ja sellaisten yhdisteiden etsiminen, jotka elimistössä matkatessaan muuttuvat lääkemolekyyleiksi ilman sivuvaikutuksia.
Proteiinin kolmiulotteinen rakenne voidaan määrittää röntgenkristallografian avulla. Elektronit säännöllisessä proteiinikiteessä taivuttavat röntgensäteitä ja taipumisesta eli diffraktiosta voidaan laskea elektronitiheyskartta. Rakennemalli syntyy sovittamalla proteiinin atomit elektronien tiheyteen laskennallisten algoritmien ja tietokonegrafiikan avulla.
“Proteiinin kiteytys on vaikea vaihe. Oikeiden kiteytymisolosuhteiden löytäminen on haastavaa. Jotkut proteiinit eivät kiteydy kokonaisina”, kertoo Lehtonen.
Proteiinirakenteiden määrä on kuitenkin lisääntynyt valtavasti. Vuonna 1994 rakenteita oli määritetty noin tuhat, nyt niitä on jo sata tuhatta. Jo ratkaistut proteiinirakenteet löytyvät PDB- tietokannasta (http://www.rcsb.org/).
”Proteiineja on olemassa huomattavasti enemmän ja muiden tutkimushavaintojen perusteella on useita mahdollisia lääkekohteita, joiden rakennetta ei vielä ole määritetty.”
Jos kohdeproteiinin sukulaisten rakenteita tunnetaan, voidaan yrittää laatia homologiamalli.
“Sukulaiset muistuttavat yleensä toisiaan. Teoreettinen malli kohteen rakenteesta voidaan laatia tunnetun sukulaisen perusteella. Malli muistuttaa väistämättä esikuvaansa”, Lehtonen kertoo, mutta muistuttaa, että malli ei ole tulos vaan työkalu.
Rakennemallin avulla selitetään proteiinin toiminnasta kerättyä kokeellista dataa ja ennustetaan, mitä poikkeavassa tilanteessa saattaa tapahtua. Mallin avulla voidaan esimerkiksi ennustaa, millaisiin vuorovaikutuksiin erilaiset pienmolekyylit proteiinin kanssa kykenevät.
”Mallia täytyy kuitenkin arvioida kriittisesti. Se ei ole kaikilta osiltaan yhtä luotettava. Rakennemalli saattaa kuvata lääkemolekyylin sitoutumiskohdan uskottavasti vaikka olisikin muilta osin epävarma.”
Lehtonen korostaa, että mallintaminen edellyttää yhteistyötä kokeita tekevien tutkimusryhmien kanssa.
”Mallin perusteella ehdotetaan koejärjestelyjä, jotka kertovat tutkimuskohteesta enemmän ja samalla paljastavat onko malli luotettava. Mallintajan täytyy datan perusteella päättää, voiko mallia käyttää. Mallia korjataan ja tarkennetaan saadun kokeellisen datan avulla. Sykli jatkuu kunnes kohde tunnetaan hyvin,” Lehtonen korostaa.

Rakenteeseen perustuvassa lääkeainesuunnittelussa hyödynnetään tietoa proteiinin sitoutumiskohdan rakenteesta ja tunnetuista proteiiniin sitoutuvista molekyyleistä, joita kutsutaan ligandeiksi. Lääkemolekyylit suunnitellaan usein ligandin kaltaiseksi. Parhaimmillaan tutkijoilla on käytettävissä määritetty proteiinirakenne, joka sisältää ligandin. Proteiinia voidaan myös mutatoida valikoivasti, jolloin sitoutumisen voimakkuuden muutosten perusteella päätellään, mitkä proteiinin aminohappotähteet osallistuvat sitoutumiseen. Sitoutumiskohta on yleensä onkalo proteiinirakenteessa. Rakennemallin onkalot voi hahmottaa myös laskennallisesti, mutta aidon sitoutumiskohdan tunnistaminen ei ole automaattista.
”Ligandin vaikutustapa, eli proteiinin normaali toiminta, on itsessään arvokas tutkimustulos. Jos tiedetään sukulaisrakenteita, joukko niihin sitoutuvia ligandeja ja erot sitoutumisen voimakkuudessa, voidaan rakenneanalyysillä tunnistaa sitoutumiselle merkittävimmät atomitason erot. Näin selviää, mikä ligandin rakenteessa on tärkeää.”
Mahdollisella lääkemolekyylillä tulisi siis olla samankaltaiset osaset. Jos lääkeaineen sitoutumispaikasta kohdeproteiinissa on saatavilla riittävästi kokeellista tietoa, voidaan tietokannoilla ja tehokkailla tietokoneilla tehdyllä virtuaaliseulonnalla rajata nopeasti ja luotettavasti suuresta määrästä molekyylejä mahdolliset lääkeainekandidaatit. Näin voidaan minimoida myös lääkkeen mahdolliset sivureaktiot.
”Virtuaalisia molekyylikirjastoja voidaan seuloa luoduilla hakukriteereillä, eli suorittaa tietokonehaku joka rajaa pois täysin sopimattomat molekyylit. Jäljelle jääneillä yhdisteillä tehdään tarkempaa mallinnusta, jotta kokeellisesti testattavien yhdisteiden joukko supistuu kohtuulliseksi.”
Mallinnuksen avulla etsitään todennäköisesti proteiinin kanssa oikein reagoivia molekyylejä ja laboratoriotuloksilla testataan paikkansapitävyys. Näin saadaan vastaus siihen, mitkä ovat mahdollisia lääkeainekandidaatteja, miksi tämä toimii ja toinen ei.
”Jos asetetaan kaksi molekyylirakennetta vierekkäin virtuaalisesti, voidaan kysyä miten vahva vuorovaikutus niillä on. Voimien vahvuuteen vaikuttavat atomien väliset etäisyydet ja muiden molekyylien eli veden läsnäolo. Fysiikka ja kemia ovat tuottaneet havaintodatan ja teoriat voimien
arvioimiseksi. Molekyylien siirtyessä tai muuttaessa muotoaan myös lasketut voimat muuttuvat. Molekyylit voidaan siis asetella lukemattomilla tavoilla.”
Telakointi (docking) on hakualgoritmi, joka laskee voiman proteiinin ja toisen molekyylin välillä.
”Kukin telakointialgoritmi käyttää erilaista strategiaa joukon valinnalle. Tavoitteena on löytää optimaalinen asettelu, joka toivottavasti kuvaa miten rakenteet todellisuudessa vuorovaikuttavat. Haku rajataan melko tarkasti oletettuun sitoutumiskohtaan ja molekyylien sallitut muodonmuutokset ovat pieniä. Muuten hakuavaruus on liian suuri, eli laskennan määrä kasvaa suhteettomaksi.”
Bioinformatiikassa telakoinnilla selvitetään se, mikä ligandi sitoutuu vahvimmin. Kun jokaisen ligandin sitoutumiskohdalle, sitoutumistavalle ja sitoutumisen voimakkuudelle on malli, voidaan laatia ehdotus, miltä uusien lääkemolekyylien pitää näyttää, jotta ne sitoutuvat toivottuun kohdeproteiiniin. Telakointiin on käytössä useita eri laskentateknologioita. Esimerkiksi, molekyylidynamiikkasimulaatiossa sallitaan molekyyliparien vapaa liikkuminen, eikä työ saa kestää viikkoja. Siksi tarvitaan tehokkaita laskentaresursseja. Molekyylidynamiikka on siis laskennallisesti raskas menetelmä telakointiin, mutta palkintona on tarkempi ymmärrys molekyylien välisestä dynaamisesta vuorovaikutuksesta. Molekyylidynamiikan simulaatioita käytetäänkin vuorovaikutusten yksityiskohtaisempaan mallintamiseen ja proteiinin ja lääkeaihion välisen vuorovaikutuksen ja pysyvyyden arvioimiseen.
“Suurin virhe mallinnuksessa on uskoa sokeasti ohjelmien antamia vastauksia. Olennaista on kyky arvioida tuloksia kriittisesti ja mallinnuksen hyödyntäminen ongelmissa, joihin se soveltuu,” Lehtonen korostaa.
Turun bioinformatiikan yksikkö hyödyntää tutkimuksessaan Suomen ELIXIR-keskuksen pilvilaskentaresurssia ePoutaa. Se luo läpinäkyvän paikallisen resurssin, jonka tietoturvataso on erittäin korkea. Käyttäjä ei näe, että laskenta tapahtuu pilvessä eikä dataa tarvitse siirtää levyasemalta toiselle, varsinkaan julkisen verkon kautta. Esimerkiksi sellaisille tutkimusaineistoille, joihin liittyy yrityssalaisuuksia, ePoudan korkeampi tietoturvataso on
välttämätön.
“Saamme ePoudan ansiosta lisää laskentakapasiteettia paikalliseen verkkoon, mikä on sopinut meille erittäin hyvin. Käytännössä meidän laskentakapasiteettimme on tuplaantunut. CSC:n pilvi on kansallisella tasolla edullisin tapa luoda paikallisia laskentaresursseja.”
Lehtosen mukaan ePouta luo läpinäkyvän paikallisen resurssin. Käyttäjä ei näe, että laskenta tapahtuu pilvessä eikä dataa tarvitse siirtää levyasemalta toiselle, varsinkaan julkisen verkon kautta. Joillekin tutkimusaineistoille ePoudan korkeampi tietoturvataso on välttämätön.
“Koska CSC vastaa laskentaresursseista ja pilvipalvelusta, asiakaspäähän voidaan rakentaa sellainen ympäristö, joissa tutkija viihtyy. Tällä tavoin on myös helpompi ylläpitää sellaisia ohjelmistokokonaisuuksia, joita CSC:llä ei ole.”
Ari Turunen
15.1.2016
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Tommi Nyrönen, & Jukka Lehtonen. (2016). New drug molecules through determining the structure of proteins. https://doi.org/10.5281/zenodo.8068984
Lisätietoja:
Biokeskus Suomi
Biokeskus Suomi on bioalan kansallisia tutkimusinfrastruktuureja kehittävä ja tarjoava organisaatio, joka toimii yhteistyössä ESFRI-hankkeiden kanssa.
http://www.biocenter.fi/
BioCity
BioCity Turku on turkulaista bioalan tutkimusta yhdistävä kattojärjestö.
http://www.biocity.turku.fi/
Turun Biotekniikan keskus
Turun Biotekniikan keskus on Turun yliopiston ja Åbo Akademin erillislaitos, joka tuottaa palveluja eri bioalan tutkimusryhmille.
http://www.btk.fi
Rakennebioinformatiikan laboratorio
Rakennebioinformatiikan laboratorio toimii Åbo Akademin Luonnontieteiden ja tekniikan tiedekunnan tiloissa Bio-Cityssä.
http://www.abo.fi/fakultet/biokemisbl
CSC – Tieteen tietotekniikan keskus Oy
CSC on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon
osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

BBMRI (Biobanking and Biomolecular Resources Research Infrastructure) on 16 eurooppalaisen valtion perustama infrastruktuuri, jonka tavoitteena on edistää eurooppalaisten biopankkien näytekokoelmien ja niihin liittyvien tietojen korkeatasoista tutkimuskäyttöä. Kokoelmien hyödyntäminen auttaa diagnostiikan ja hoitojen kehittämistä sekä terveyden edistämistä ja sairauksien ehkäisyä. Suomessa on toiminnassa jo useita biopankkeja, joille luodaan BBMRI:n ja ELIXIRin yhteistyönä yhteinen tietotekninen infrastruktuuri.
BBMRI toimii kansallisten keskusten kautta, jotka koordinoivat jäsenmaiden biopankkeja. Jäsenmaihin ja BBMRI:n alaisuuteen perustetaan myös palvelukeskuksia, jotka palvelevat biopankkien asiakkaita. BBMRI. fi on BBMRI-verkoston kansallinen yhteistyöelin, jonka jäseniä ovat suomalaiset biopankit.
Suomessa oli vuonna 2015 toiminnassa viisi biopankkia. Uusia perustetaan lähitulevaisuudessa. Terveyden ja hyvinvoinnin laitoksen THL Biopankkiin siirrettiin kesäkuussa 2015 yli 100 000 suomalaisen näytekokoelmat. Kokoelmien avulla voidaan selvittää sairauksien syitä ja perimän, ympäristön ja elintapojen vaikutusta niihin. Auria Biopankin näytteistä 50 prosenttia on syöpänäytteitä. Auria Biopankki keskittyy erityisesti verenkierto-, aineenvaihdunta-, syöpä- sekä neurologisten sairauksien tutkimukseen. Auria Biopankin ovat perustaneet Turun yliopisto sekä
Varsinais-Suomen, Satakunnan ja Vaasan sairaanhoitopiirit.
FHRB eli Suomen hematologinen rekisteri ja biopankki toimii koko maassa ja kerää veritautipotilaiden veri- ja luuydinnäytteitä. Näytteitä tarvitaan tutkimuksiin, joissa etsitään keinoja vaikeiden veritautien, erityisesti leukemian hoitoon. FHRB-biopankin omistavat Suomen Hematologiyhdistys, Suomen molekyylilääketieteen instituutti (FIMM) ja Suomen Punaisen Ristin Veripalvelu. Toiminnassa on mukana myös Suomen Syöpäpotilaat ry.
Helsingissä toimivan Akateemisen lääketiedeyhdistyksen AMCH:n tehtävänä on tukea tutkimusta, jonka tavoitteena on terveyden edistäminen, tautimekanismien ymmärtäminen tai terveyden- ja sairaanhoidossa käytettävien tuotteiden, diagnostisten menetelmien tai hoitokäytäntöjen kehittäminen.
HUB-biopankki keskittyy urologisiin sairauksiin ja se palvelee tämän tutkimusalueen biopankkinäytteistä hyötyvää tutkimusta. Biopankki aloitti näytekeräyksen vuoden 2015 alusta. Näytteitä ja tietoja hyödyntävien tutkimushankkeiden pyrkimyksenä on parantaa urologisten
tautien ennaltaehkäisyä, diagnostiikkaa ja hoitoa. HUB-biopankin perustivat FIMM ja Helsingin ja Uudenmaan sairaanhoitopiirin kuntayhtymä (HUS).
Biopankit hallinnoivat erittäin suuria ja tärkeitä tietoaineistoja. Esimerkiksi genomitiedon ja kuvantamisen tietoaineistojen yhdenmukaistaminen ja hallinta on vaativa tehtävä. Tarkoituksena on tuottaa kansallinen web-pohjainen biopankkitietojen saatavuuspalvelu, josta voi etsiä sopivia aineistoja
tutkimus- ja tuotekehityskäyttöön.
THL:n erikoissuunnittelija Juha Knuuttila koordinoi biopankkien IT-yhteistyötä Suomessa. Juha Knuuttilan mielestä BBMRI.fi -verkoston keskeistä kansallista yhteistyötä on biopankkien IT-infrastruktuuri.
“Suomessa tietotekninen infrastruktuuri on suhteessa moneen muuhun eurooppalaiseen maahan kehittyneessä vaiheessa. Suomen BBMRI.fi ja Suomen ELIXIR-keskus ovat tästä hyviä esimerkkejä. Molemmilla on selkeä roolinsa. ELIXIR toteuttaa hyvän pilvipalvelun ja biopankkitoimintaa tukevat
erikoistuneet tietokonejärjestelmät tulevat BBMRI:ltä. Pilvipalvelussa ovat käytössä FIMM:n ja CSC – Tieteen tietotekniikan keskus Oy:n virtualisoidut laskentaklusterit. Euroopan tasolla näin toimiva yhteistyö on vielä harvinaista,” Knuuttila toteaa.
Biopankkien yhteistyöverkoston tavoitteena on sopia yhtenäisistä toimintatavoista, jotka liittyvät laatuvaatimuksiin järjestää kansallisesti yhtenäiset aineistojen luovutuskäytännöt. Yhtenäiset eettiset periaatteet ja tutkimuksiin osallistuneiden henkilöiden luottamuksen säilyttäminen ovat myös tärkeä osa kansallista biopankkitoimintaa.
IT-puolella yhteistyö on käynnistetty tietokantapiloteilla. Esimerkiksi patologian arkistot ovat useimpien suomalaisten sairaalabiopankkien tai biopankkihankkeiden tärkeimpiä näyteaineistoja. Biopankkien yhteistyönä on aloitettu kansallinen digitaalisen patologian infrastruktuuri digitalisoimalla yliopistosairaaloiden patologian arkistojen näytteet.
Digitalisointi edesauttaa uusien sovellusten kuten kudos-mikrosiruteknologian hyödyntämistä sekä työkalujen kehittämistä suurten tietoaineistojen analysointiin, mikä edistää yksilöllistettyä terveydenhoitoa. Palvelut ovat osa eurooppalaista BBMRI-infrastruktuuria.
”Tavoitteena on luoda yhtenäinen suomalainen rajapinta eurooppalaiseen infrastruktuuriin.”
Työtä kuitenkin riittää. Käytössä on monia erilaisia terveydenhuollon järjestelmiä ja tieto on hajanaista. Knuuttilan mielestä suurin työ on tiedon harmonisoinnissa.
”Tutkimusyhteistyön mahdollistamiseksi kliininen data, väestödata ja näytedata pitäisi saada yhteen paikkaan ja helposti haettavaan muotoon. Siksi biopankkien pitää sopia, mitä muuttujia yhdistetään realistisella ja hyödyllisellä tavalla tietokantoihin.”
Knuuttilan mielestä tämä pakottaa biopankit toimimaan yhdessä, jolloin siitä on hyötyä myös tutkijoille ja lääkefirmoille. Knuuttila johtaa biopankkien yhteistä IT-ryhmää.
”Sekä biopankeille että sairaaloille on hyödyllistä, että potilastieto saadaan strukturoituun muotoon.”
THL, FIMM ja CSC loivat Biomedinfra-yhteistyön, koska tunnistettiin tarve luoda yhteinen kokonaisuus biopankeista saadun geenitiedon hyödyntämiseksi. Se edellytti myös yhteisiä IT- ratkaisuja. Suomen Akatemia ja Opetus- ja kulttuuriministeriö asettuivat tukemaan hanketta. Tällä hetkellä neljää eri palvelua voidaan hyödyntää yhteisten rajapintojen avulla. Ne ovat näyte- ja tietorekisteri (THL), koodi- suostumus- ja tapahtumarekisteri (FIMM), luovutuspyyntöjen hallinta
eli REMS-palvelu (CSC) sekä saatavuustietokanta (FIMM).
”Kaikissa on ohjelmointirajapinta, jonka avulla ne voivat vaihtaa tietoa keskenään.”
Knuuttilan mukaan tällaista THL:n, CSC:n ja FIMM:n luomaa ohjelmistokokonaisuutta ei ole kukaan muu vielä tehnyt.
”Tällaiset avoimen lähdekoodin ratkaisut voivat olla houkuttelevia myös biopankeille.”
Knuuttilan mielestä seuraavia tärkeimpiä tehtäviä on luoda yhteinen verkkopohjainen saatavuuspalvelu, josta voidaan tehdä hakuja eri biopankkien näytteiden ja tietojen saatavuudesta.
Ari Turunen
26.10.2015
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Juha Knuuttila, & Tommi Nyrönen. (2015). BBMRI.fi: an IT Infrastructure for shared biobanks. https://doi.org/10.5281/zenodo.8068915
Terveyden ja hyvinvoinnin laitos THL
Terveyden ja hyvinvoinnin laitos THL
THL on kansallinen asiantuntijalaitos, joka tarjoaa luotettavaa tietoa terveys- ja hyvinvointialan
päätöksenteon ja toiminnan tueksi.
https://www.thl.fi
http://www.bbmri.fi
CSC – Tieteen tietotekniikan keskus Oy
CSC on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon
osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing

Biotekniikan instituutissa Jukka Jernvallin ja Petri Auvisen tutkimusryhmissä selvitetään eri lajien perimää ja populaatioiden rakenteita. Tavoitteena on ymmärtää, milloin lajit syntyivät ja eriytyivät toisistaan. Erityisen kiinnostuksen kohteena on saimaannorppa, jonka koko perimä eli genomi selvitetään.
Saimaannorppa on erinomainen tutkimuskohde, kun halutaan tutkia perimän monimuotoisuutta,
eristäytymistä ja sisäsiittoisuutta. Saimaannorpalla ei ole ollut yli kymmeneentuhanteen vuoteen kosketusta muihin hyljelajeihin. Sen silmät, aivot ja kallo ovat erilaiset muihin norppalajeihin verrattuna. Saimaannorppa kehittyi hyljekannasta, joka todennnäköisesti tuli Itämerestä Laatokkaan ja siirtyi sieltä Saimaan saaristoon.
”Jos laatokannorppa siirrettäisiin Saimaaseen, se ei välttämättä pärjäisi. Saimaannorppa on sopeutunut humuspitoiseen sameaan veteen ja sokkeloiseen saaristoon,” Biotekniikan instituutin laboratorion johtaja Petri Auvinen kertoo.
Biotekniikan instituutin DNA-sekvensointi ja genomikka -laboratorio on erikoistunut geenien sekvensointiin eli DNA:n emäsjärjestyksen selvittämiseen. Laboratoriossa on sekvensoitu useiden eliöiden kokonainen genomi kylmäruokaa pilaavasta Lactococcus piscium-bakteerista alkaen. Lisäksi laboratoriossa tutkitaan sekvensoimalla myös geenien ilmentymistä. Keskeisinä tapahtumina eliöiden kehityksessä ovat solujen jakautuminen ja erilaistuminen, mikä on ajallisesti ja paikallisesti tarkasti säädeltyä.
Solujen erilaistuminen tapahtuu vaiheittain. Joskus geeni kytkeytyy päälle ja joskus lakkaa toimimasta. Tätä aktiivista toimintaa kutsutaan geenin ilmentymiseksi. Kun geenien ilmentyminen saadaan mitattua, voidaan esimerkiksi voidaan seurata sitä, mitkä geenit alkavat toimia vaikkapa puun valmistautuessa talveen. EST (expressed sequence tag)-tekniikka antaa tietoa geenin sijainnista ja toiminnasta. Selvittämällä geenien emäsjärjestys saadaan kullekin ilmenevälle geenille tunnistin (tag). Nykyisin geenien toiminnan tutkimiseen käytetään lähinnä RNA-seq menetelmää.

Helsingin yliopistossa toimivan Biotekniikan instituutin tutkijoiden tavoitteena on saada mahdollisimman korkealaatuinen referenssigenomi saimaannorpasta. Referenssigenomi on digitaalinen sekvenssitietokanta yhden lajin koko emäsjärjestyksestä, joka on saimaannorpan tapauksessa koottu yhdestä yksilöstä ja ihmisen tapauksessa lukuisista genomeista. Hyvän referenssigenomin kerääminen edellyttää erilaisten, kehittyneiden tekniikoiden käyttöä.
Populaatiota voidaan tutkia tehokkaasti referenssigenomin ja yksilöiden genomeissa esiintyvien poikkeamien avulla. STR-menetelmässä (short tandem repeat) verrataan DNA:n yhtä tiettyä kohtaa, jossa toistuu aina muutaman emäsparin toisto, kahteen tai useampaan DNA-näytteeseen. STR:n avulla yksilöiden DNA:t erottuvat selvästi. Mitokondrio-DNA:n avulla voidaan puolestaan selvittää yksilöiden äiti-linjaa tuhansien vuosien taakse. DNA- sekvensointitekniikoiden nopea kehittyminen on mahdollistanut yhden nukleotidin polymorfismien (SNP) selvittämisen, joka antaa hyvin tarkan arvion yksilöiden välisistä eroista. Tätä menetelmää käytetään myös saimaanorpan genomiprojektissa. Datan kerääminen edellyttää paljon tallennustilaa ja laskentatehoa, jota tieteen tietotekniikan keskus CSC tarjoaa ELIXIR-infrastruktuurin kautta.
Saimaannorpan genomi on 2,5 miljardin emäsparin pituinen, saman kokoinen kuin koiran genomi. Saimaannorpan perimän selvittämisessä akatemiaprofessori Jukka Jernvallin ryhmä keskittyy hylkeiden hampaiden tutkimiseen, Petri Auvisen ryhmä populaatiohistoriaan ja genomin rakenteeseen. Kun genomi on selvitetty, saimaannorpan genomia verrataan Laatokan,
Itämeren ja Jäämeren norppien perimään.
Tutkijat yhdessä Oulun ja Itä-Suomen yliopistojen tutkijoiden kanssa keräävät dataa genotyypin (geneettiset tekijät) ja fenotyypin (ympäristötekijät) yhteyksistä. Paljon kehitysbiologista tietoa saadaan analysoimalla hampaita. Kun hammas puhkeaa, se ei enää kehity eikä se muutu ympäristön vaikutuksesta. Hampaissa on kuitenkin valtava variaatio. Siksi tutkitaan, mitkä geenit ovat vaikuttaneet erikoisiin hampaisiin. Esimerkiksi grillihylkeen hampaat ovat evoluution myötä tulleet hyvin monimuotoisiksi ja toimivat valaiden hetuloiden tapaan, koska hylkeet syövät grilliä.
”Meillä on tietokonemallit kaikista norpan kalloista. Voimme laatia tarkkoja fenotyyppejä ja etsiä todennäköisiä geenejä, jotka aiheuttivat tietyn hampaan. Geenin toimintaa voidaan mallintaa tietokoneella ja analysoida, mitkä alueet genomista voisivat vaikuttaa hampaaseen.”
Erilainen kallo ja hampaat kertovat adaptaatiosta tai lajiutumisesta, sopeutumisesta erilaisiin olosuhteisiin. Koska saimaannorpan silmäkuopat ovat erilaiset muihin läheisiinkin norppiin verrattuna, voidaan esimerkiksi päätellä, että se on sopeutunut sameisiin ja sokkeloisiin vesiin.
Auvisen ja Jernvallin ryhmillä on käytössä maailman ainoa tunnettu norpan ja harmaahylkeen risteymän DNA. Vuonna 1929 Skansenin eläintarhassa syntyi poikanen, jonka hampaasta Auvisen onnistui eristämään DNA:n. Valtavan harmaahylkeen ja pienen norpan jälkeläinen eli vain lyhyen aikaa. Risteymän hampaat ja kallo kertovat välimuodosta. Auvisen mukaan se vastaisi ehkä simpanssin ja ihmisen risteymää. Nyt pystytään vertaamaan, miksi tietynlainen hammas tai kallo kehittyy.
Auvisen mielestä tämä on myös ihmisen evoluutiolle merkittävää tutkimusta, koska ei tiedetä, milloin nykyihmisen eriytyi omaksi lajikseen. Risteytymiä on tapahtunut myös ihmisen evoluutiossa. On löydetty ihmisen kallonpalasia, jotka ovat Cro-Magnonin ihmisen ja Neanderthalin ihmisen väliltä. Eurooppalaisista 2-5% kantaa Neanderthalin ihmisiltä periytyviä
geenejä. Denisovan luolasta Siperiasta puolestaan löytyi ihmislajin luuranko, joka nimettiin Denisovan ihmiseksi. Se kuoli sukupuuttoon 40 000 vuotta sitten, aiemmin kuin serkkunsa Neanderthalin ihminen. Kun Denisovan ihmisen luurangon sormesta eristettiin DNA, havaittiin, että tiibetiläisillä on Denisovan ihmisen geenejä. Yksi periytyvä geeni auttaa tiibetiläisiä selviytymään korkeassa ilmanalassa.

Biotekniikan instituutin tutkijat haluavat selvittää onko saimaannorppa oma lajinsa vai alalaji. Tutkijat tietävät tarkasti, kuinka monta sukupolvea norppa on ollut eristyksissä Saimaalla. Saimaannorpan populaatio on pieni. 1980-luvulla jäljellä oli vain 140 yksilöä, nyt 320. Kun vanhoja näytteitä Saimaalta, Itämerestä ja Laatokasta verrataan saimaannorpan referenssigenomiin, voidaan tutkia minkälainen populaatio on mennyt ns. pullonkaulan läpi.
Nykyisin on olemassa myös laskennallisia menetelmiä joilla voidaa jopa yhdestä genomista kohtuullisen tarkasti päätellä millaisessa populaatiossa sen esiisät ja -äidit ovat eläneet. Populaation kohtaama pullonkaulailmiö tarkoittaa tapahtumaa, jossa suurikin osa populaatiosta tuhoutuu tai vain pieni joukko yksilöitä perustaa uuden joukon kuten esimerkiksi Suomeen aikanaan saapuneet ihmiset. Tuhoutumisen syynä voivat olla ympäristön muutokset tai siirtyminen uuteen ympäristöön, joka voi estää lisääntymisen.
Saimaannorpan geneettisen historian tutkimisesta on apua myös ihmisen perimän tutkimiseen. Pullonkaulat voivat lisätä sisäsiittoisuutta ja siten vaikuttaa myös tautiperimään. Suomessa pullonkaulat ovat synnyttäneet väestöön noin neljäkymmentä perinnöllistä sairautta, jotka ovat täällä huomattavasti yleisempiä kuin muualla. Suomalaisia geneettisiä pullonkauloja ovat olleet maanviljelyn omaksuminen 4000 vuotta sitten ja asutuksen leviäminen pohjoiseen ja itäiseen Suomeen 1500-luvulla.
”Nyt pystytään tutkimaan tautigeenien vaikutusta populaation rakenteeseen ja luonnon ja ihmisten aiheuttamia pullonkauloja. Suomalainen tautiperimä on tässä suhteessa mielenkiintoinen. Voidaan saada selville, minkälainen on ollut suomalaisten kantama tautiperimä, kun on menty pullonkaulan läpi,” Auvinen toteaa.
Referenssigenomin luomisesta on paljon hyötyä. Referenssigenomin dataa voidaan käyttää aina uudestaan. Mitä parempi referenssigenomi, sitä helpompi on analysoida uutta dataa, jota voidaan verrata referenssigenomin dataan.
Esimerkiksi koivun referenssigenomin analysoiminen nopeuttaa ja tehostaa puun tutkimusta teollisuuden ja lääketieteen tarpeisiin. Koivun genomista voidaan etsiä uusia ominaisuuksia, jotka vaikuttavat puun laatuun ja määrään. Lisäksi tätä dataa voidaan hyödyntää muiden puulajien tutkimisessa.
”Toisin kuin koivulla, esimerkiksi poppelilla ja eukalyptuksella kestää ominaisuuksien selvittäminen 10 vuotta. Koivua voidaan geneettisesti modifioida. Koska koivu saadaan jopa kolme kertaa vuodessa kukkimaan, uusia ominaisuuksia saadaan koivulle yhdessä, kahdessa vuodessa. Näitä tekniikoita voidaan soveltaa myös muihin puulajeihin. Koivun geneettistä mallia voidaan käyttää hyväksi esimerkiksi eukalyptuksen tutkimisessa,” toteaa Petri Auvinen.
Koivun referenssigenomin projektia oli seuraamassa myös teollisuuden edustajia. Geenitiedon ansiosta koivun ominaisuuksia voidaan jalostaa ja metsäteollisuus voi käyttää puuta muuhun kuin laudan tekemiseen.
Uusia sovelluskohteita ovat nanomateriaalit, puunjalostusteollisuuden sivuvirrat sekä esimerkiksi hemiselluloosa. Auvinen mainitsee myös koivun kaarnassa olevan betuliinin, jolla on raportoitu olevan syöpää torjuvia ja antiviraalisiakin vaikutuksia. Betuliinista on jo tehty emulsiolääkevoiteita. Voidaan myös pyrkiä tavanomaisin jalostusmenetelmin aikaan saada sellaisia koivuja, joissa on enemmän betuliinihappoa.
Ari Turunen
10.8.2015
Artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Petri Auvinen, & Tommi Nyrönen. (2015). Saimaa ringed seal aids the study of population genomes. https://doi.org/10.5281/zenodo.8068837
Lisätietoja:
Biotekniikan instituutti
Biotekniikan instituutti on Helsingin yliopiston erillinen tutkimus- ja koulutuslaitos,
joka edistää korkeatasoista tutkimusta ja koulutusta biotekniikassa ja molekyylibiologiassa.
http://www.biocenter.helsinki.fi/bi/dnagen/index.htm
CSC – Tieteen tietotekniikan keskus Oy
CSC on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon
osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing
ELIXIR
ELIXIR rakentaa Eurooppaan biologisen informaation infrastruktuurin bioalan tutkimuksen tueksi. Sen Suomen keskus on CSC.
http://www.elixir-europe.org

Suomalaisten lääkärien Johan ja Mikael Lundinin keksintö tarjoaa tehokkaan ratkaisun kudosleikekuvien analysoimiseen ja tallentamiseen.
Tutkimusdata lisääntyy valtavasti vuosi vuodelta, mikä edellyttää ohjelmistonkehittäjiltä jatkuvaa aktiivisuutta. Isoja datamääriä on pystyttävä analysoimaan ohjelmistoilla, jotka eivät pistä työasemaa jumiin. Suomen molekyylilääketieteen instituutin (FIMM) tutkimusjohtaja Johan Lundin tutkii ja kehittää kuvaperustaista diagnostiikkaa konenäköratkaisujen avulla. Tulevaisuudessa eri datalähteitä, geneettistä dataa, kudosdataa ja kliinistä potilasdataa, yhdistämällä voidaan laatia persoonakohtaisia tautiennusteita ja hoitomuotoja. Tätä on sovellettu erityisesti rinta- ja eturauhassyövän sekä paksunsuolen syövän hoitamisessa.
Helsingin yliopistollisessa keskussairaalassa 2000-luvun alussa työskennellessään Lundin turhautui siihen, miten hankalaa isojen kudosleikekuvien käsittely oli työasemilla. Kudosleikekuvat ovat 1-2 gigatavun kokoisia, joten niiden tallentaminen omalle kovalevylle ei ole järkevää. Kuvien pyörittely on myös hidasta. Johan Lundin alkoi miettiä veljensä Mikaelin kanssa toimivaa ohjelmistoratkaisua ongelmaan.
Veljekset kehittivät täysin web-pohjaisen ohjelmiston, jonka olennaisia osia ovat tehokas kuvapalvelin sekä web-käyttöliittymä joka toimii kaikilla selaimilla. Heidän käyttämänsä kompressioalgoritmin avulla kuvat vievät vähemmän tilaa ja latautuvat nopeasti. Kahden gigatavun näytekuva voidaan kompressoida puolen gigan kokoiseksi. Kudosnäyte tallennetaan pilveen ja isoa datamäärää
voidaan käsitellä omalta työasemalta helposti ja nopeasti.
Verkossa toimivaa mikroskooppipalvelua voi käyttää kaikilla selaimilla ja tableteilla, myös älypuhelimilla. Web-Microscope® on myös yhteensopiva eri mikroskooppivalmistajien kuvaformaattien kanssa. Web-mikroskoopilla on mahdollista tutkia erittäin laajoja aineistoja ja
se sopii hyvin myös yhteistyöprojektien yhteiseksi digitoitujen kuvien hallinta- ja analysointipaikaksi.
”Palveluun on ollut todella kasvavaa kiinnostusta. Lääkärit, tutkijat ja opettajat ovat siirtymässä digitaaliseen mikroskopiaan. Verkossa toimiva pilvipohjainen palvelu on edistyksellinen ratkaisu digitaalisen mikroskopian käyttäjille kaikkialla maailmassa,” toteaa palvelua tarjoavan Fimmicin toimitusjohtaja Kaisa Helminen. Helminen on koulutukseltaan biokemisti ja työskennellyt aiemmin useissa bioalan firmoissa.
Fimmic perustettiin vuonna 2013 ja seuraavana vuonna palvelua alettiin kaupallistaa. Fimmicin asiakkaita ovat mm. yliopistot, tutkimuslaitokset, lääkeyritykset sekä ulkoista laadunvalvontaa tekevät yritykset. Ulkoinen laadunvalvonta tehostuu kun näytteitä voidaan lähettää virtuaalisesti analysoitavaksi sen sijaan, että lasilevyillä olevia näytteitä postitettaisiin laboratorioihin.
Näiden palvelujen tuottamisen kumppanina Fimmic käyttää Tieteen tietotekniikan keskuksen CSC:n cPouta-pilvipalvelua. Se tarjoaa web-mikroskoopin käyttäjille oman palvelimen, nopean kaistanleveyden ja valtavasti tallennustilaa. Näin taataan, että palvelu toimii mahdollisimman tehokkaasti. Web-mikroskooppi soveltuu myös biopankeille kudosnäytteiden hallinnoimiseen. Palvelu voidaan räätälöidä yksittäiselle biopankille sopivaksi.
Mikroskooppiskannerit ovat kalliita laitteita – hinta vaihtelee tyypillisesti 150 000 – 300 000 euron välillä. Skannereiden määrä kuitenkin lisääntyy ja kun kuvia skannataan, monelle käyttäjälle kätevin ja edullisin ratkaisu on tallentaa ne suoraan pilveen.
”Mikäli asiakkaalla ei ole mahdollisuutta käyttää skanneria, hän voi lähettää näytteet meille skannattavaksi. Me tallennamme digitoidut näytteet suoraan asiakkaan Web-Microscope-tilille,” Helminen kertoo.
WebMicroscope-portaalin kautta käyttäjä voi jakaa omia mikroskooppikuviaan eri tutkimusryhmille ja yhteistyökumppaneille ympäri maailmaa. Tämä on tärkeä ominaisuus, koska esimerkiksi lääkeainesuunnittelussa testitulosten jakaminen nopeasti tutkimusryhmien ja lääkeyhtiöiden kesken
on edellytys läpimurroille. Lääkekehitykseen liittyvä tutkimus on yksi Fimmicin
painotuksista.
Perinteisellä mikroskoopilla voidaan tarkastella vain pientä osaa näytteestä kerrallaan. Mikroskooppiskanneri kuvaa näytteen suurella objektiivilla, jolloin koko näyte on yksityiskohtineen digitoitu. Syntynyttä kuvaa voidaan web-mikroskoopin avulla katsella helposti ja nopeasti, paikasta
riippumatta.
”Tarkasteltavaksi voidaan ottaa osa kudosnäytteestä Google Mapsin tavoin ja katsoa siitä vain osa ja siirtyä nopeasti toiseen kohtaan. Kuvaa ei tallenneta työasemille, vaan se latautuu verkon yli suoraan kuvapalvelimesta.”
Kaikissa Suomen lääketiedettä opettavissa yliopistoissa käytetään web-mikroskooppia opetustarkoituksiin anatomian ja patologian kursseilla. Webmikroskoopin avulla digitoituja näytteitä
voidaan helposti jakaa opiskelijoille ja liittää oheen muita dokumentteja ja videoita.
Omat sivut voidaan suojata salasanalla ja ohjelmiston avulla voidaan suorittaa myös tenttejä. Virtuaalisia näytteitä voidaan katsoa etäopetuksessa vaikkapa tableteilta tai älypuhelimilta ja luokkahuoneessa isolta näytöltä. Sovellus sopii erinomaisesti monipistetunnistusta hyödyntäviin Multitouch–näyttöihin. Massiivisia kudosleikekuvia voidaan tällöin tarkastella helposti ja nopeasti
suurella kosketusnäytöllä isommankin ryhmän kesken.
Mikroskooppiskanneri tuottaa paljon dataa. Tarkasteltavana voi olla miljoonia havaintopisteitä, joiden käsittelyyn tarvitaan laskentatehoa ja hyviä algoritmeja. Fimmicin suunnitelmissa on kehittää ohjelmistoa eteenpäin ja tuoda siihen kvantitatiivisen kuva-analyysin työkaluja, algoritmeja.
Kaisa Helmisen mukaan mahdollisia tutkimuskohteita, joihin algoritmeja voidaan käyttää, on valtavasti.
”Konenäköalgoritmit perustuvat signaalin käsittelyyn. Konetta opetetaan kymmenillä ellei sadoilla kuvilla tunnistamaan tietty signaali taustasta, esim. värjätyt solut muusta kudoksesta. Seulonta on tapauskohtaista ja vaihtelee, miten eri näytteitä on käsitelty. Algoritmi on juuri niin hyvä kuin se
on opetettu.”
Tähän kaikkeen tarvitaan laskentatehoa, jota saadaan mm. CSC – Tieteen tietotekniikan
keskuksen supertietokoneista.
”Laskentatehoa vaaditaan paljon, koska tutkittavat kuvat ovat ns. suurkuvia (whole slide images). Toki näistä saatetaan rajata pienempiä alueita analyysiä varten, mutta silti laskentatehoa vaaditaan paljon, jotta analyysi ei veisi liikaa aikaa,” Kaisa Helminen huomauttaa.
Ari Turunen
1.8.2015
Lue artikkeli PDF-muodossa
Sitaatti
Ari Turunen, Kaisa Helminen, & Tommi Nyrönen. (2015). Webmicroscope stores tissue samples in the cloud. https://doi.org/10.5281/zenodo.8068745
Lisätietoja:
Fimmic Oy
Fimmic kehittää teknologiaa ja palveluja liittyen digitaaliseen mikroskooppikuvantamisen, kuva-analyysin ja informatiikan teknologiaa ja palveluja.
http://www.fimmic.com
CSC – Tieteen tietotekniikan keskus Oy
CSC on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon
osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
http://www.csc.fi
https://research.csc.fi/cloud-computing

Olisitko uskonut, että sohvallasi lepäävä rakas karvaturrisi voisi toimia ihmisen geenilöytöjen lähteenä? Harva tietää tai tulisi edes ajatelleeksi, että koirilla on 95 prosenttisesti sama perimä ja sairaudet kuin ihmisillä. Professori Hannes Lohen tekemä geenitutkimus Helsingin yliopistossa tuo merkittävää tietoa niin koirien kuin ihmisten silmä-, luusto- ja neurologisiin sairauksiin. Lohen edustamaa tutkimusalaa edistetään Euroopan laajuisella bio- ja lääketieteen tutkimusinfrastruktuurilla (ELIXIR), jota Suomi on mukana perustamassa.
Ahaa-elämys tapahtui noin kymmenen vuotta sitten tutkijatohtori Hannes Lohen paikannettua tutkimusryhmässään Torontossa kääpiomäyräkoirien epilepsiageenin. Samaan aikoihin toisaalla geeni löydettiin myös ihmisestä. Tästä yhteensattumasta alkoi professorin johtama poikkitieteellinen koirageenitutkimus Helsingin yliopiston eläinlääketieteellisessä ja lääketieteellisessä tiedekunnassa sekä Folkhälsanin tutkimuskeskuksessa. Lohen perustamaan DNA-pankkiin on kerätty vuodesta 2006 lähtien jo liki 50 000 suomalaiskoiran DNA-näytettä.
”Koirarodut antavat geneettisesti loistavan rakenteen erityisesti käyttäytymistutkimuksiin ja koirien ja ihmisten sairauksien tutkimiseen yleisesti. Mikä muu eläinlaji on sosiaalisesti lahjakas, jakaa saman ympäristön ja altistuu samoille taudinaiheuttajille kuin ihmisen paras ystävä”, Lohi tajusi tuolloin.
Lohi totesi erityisesti koirarotujen sisäsiittoisuuden auttavan sairausgeenien tunnistamista.
”Sukulinjoista on helpompi tunnistaa geenejä pienemmillä otannoilla. Verrattuna tutkimuksissa tyypillisesti käytettäviin hiiriin ja rottiin, koirat ovat kokonsa puolesta myös elintoiminnoiltaan lähempänä ihmistä”, Lohi sanoo.

Lohen johtaman koirien geenitutkimuksen kirjo on laaja. Kohteina ovat niin silmäsairaudet, autoimmuunisairaudet, neurologiset sairaudet kuin luusto- lihassairaudet. Ryhmä on tunnistanut koirista useita uusia tautigeenejä mm. epilepsiaa, kääpiökasvuisuutta ja ahdistuneisuushäiriöitä aiheuttavista tekijöistä. Löydettyjen geenialueiden myötä esimerkiksi ahdistuneisuushäiriöt, joista noin
viisi prosenttia ihmisväestöstä kärsii jossain vaiheessa elämänsä aikana, saavat uuden tutkimuspohjan mm. pakko-oireisuuden geenitaustan ja ympäristötekijöiden tutkimiseen.
”Koirarodusta etsitään sairautta aiheuttavaa geeniä, ja samalla rodusta saadaan koiramalli ihmisen sairauksien tautimekanismin selvittämiseen”, Lohi kuvaa tutkimuksen hyötyjä.
Ryhmä tunnisti CNGB1-geenin, joka aiheuttaa verkkokalvon rappeumaa ja pahimmillaan sokeutta perhoskoirissa. Sama geeni on löydetty ihmispotilaissa. Joka kymmenes yli 65-vuotiaista kärsii eläkevuosinaan kyseisestä sairaudesta, jossa sokeat pisteet rajoittavat tarkan näön aluetta estäen esimerkiksi ajokortin uusimisen.
”Lääkeaihioiden jatkokehityksen myötä ihmisen verkkokalvon rappeumaa voisi hoitaa geeniterapian avulla ulkoisesti esimerkiksi levittämällä verkkokalvolle rasvan mukana normaalia geenikopiota kantavia viruksia, jotka korjaisivat solujen toimintaa ja saattaisivat korjata näkökykyä”, Lohi kuvaa
mahdollisuuksia.
”Geenin tunnistamisen jälkeen päästään tutkimaan tautimekanismia ja vertaamaan sitä ihmisen ja koiran välillä. Ihmisellä geeni ei välttämättä ole aina sama ja mutaatio voiolla toisessa paikassa, solureitin muussa geenissä. Geenin toiminnan ja tautimekanismin ymmärtäminen on edellytys, että sairaudelle voidaan keksiä hoitomuotoja. Toisaalta, kun mutaatio löydetään, voidaan koirille kehittää
geenitesti ja katsoa, ketkä koirista kantavat kantavat tautia. Tätä kautta koirankasvattajat ja jalostajat hyötyvät tutkimuksesta nopeasti”, Lohi sanoo.
Hän on mukana Genoscoper Laboratories Oy yrityksessä, joka on hänen johdollaan rakentanut koirille ainutlaatuisen ja edullisen perimänlaajuisen geenitestin, MyDogDNA, joka testaa kerralla yli 100 sairauden ja ominaisuuden kantajuudet sekä perimän monimuotoisuutta ja rakennetta.
”Koirien geneettinen monimuotoisuus on heikentynyt jalostuksen myötä. Tautigeeniä kantavien koirien määrä on kasvanut, ja koska monet sairaudet puhkeavat aikuisiässä, on sairaita koiria jo ehditty käyttää siitokseen. Nurjan puolen vastakohtana sairautta aiheuttava geenimuoto voi yleistyä jalostuksen myötä tiettyyn koirarotuun. Kandidaattigeeni tunnistetaan helpommin ja vähemmillä näytteillä koirista kuin ihmisistä.”

Suuri määrä eläinlääkäreitä ja suomalaisia koiraharrastajia ympäri Suomen ei ole innostunut ohimenevän projektin vuoksi DNA-näytteenottotalkoisiin. Tutkimusryhmän päämääränä on rakentaa suomalaiskoirille ja -kissoille vastaavanlainen oma, laaja sekvenssi- ja varianttitietokanta kuin ihmisistä jo on (1000 Genomes).
”Suomalaisen tieteen lippulaiva on aina ollut geenitutkimus. Meillä on ainutlaatuisen tarkat terveystiedot potilaista sukutauluineen. Koirista ja pian kissoistakin löytyy vastaavat sukutaulutietokannat ja terveystietoa. Harvassa maassa on näin keskitetty, hyvä systeemi”, Lohi sanoo.
”Koirissa on 400 rotua. Tällä hetkellä koirasta on kuvattu kaikkiaan 700 sairautta ja koko ajan löytyy lisää. Tavoitteena on tietokanta, jossa on sekvensoitu joka rodusta koko perimä. Tämä nopeuttaa geenilöytöjä”, Lohi kertoo.
Lohi uskoo, että ison sekvenssitietokannan etuna on eräänlainen konsensus. Tämä saavutetaan,
kun sadat tai tuhannet perimät on sekvensoitu ja suuri varianttimäärä voidaan kartoittaa tarkasti. Samassa rodussa voi olla monta eri sairautta.
”Jos tietokantaan on sekvensoitu esimerkiksi 1000 koiran perimät 50 rodusta, on siellä arviolta 25 miljoonaa varianttia eri roduista. Tietokanta auttaa tulevissa projekteissa niin, että tutkimuksen kohteeksi voidaan ottaa pieni koira tai kissaperhe ja sekvensoida niistä vain muutama yksilö antamaan riittävän varman tuloksen oikeasta tautivariantista. Koirapotilaan variantteja verrataan tietokannan
tuhannen näytteen variantteihin, ja jos jokin tietty variantti löytyy potilaasta, mutta ei tietokannan referenssinäytteistä, voi sen päätellä olevan tautia aiheuttava. Tämän jälkeen asia varmistettaan isommassa aineistossa.”
”Tehokas ja kansallisesti merkittävä tietokanta auttaa pääsemään nopeammin kiinni tautigeeneihin. Nykyisellään tutkimuksessa joudutaan tekemään paljon työtä, jotta variantin sijainnista kromosomistossa saadaan riittävä kuva. Jatkossa otetaan näyte, sekvensoidaan koko perimä ja verrataan sitä suoraan tietokannan variantteihin.”

Arvion mukaan uudet bioteknologiset menetelmät tuottavat vuoteen 2020 mennessä miljoonakertaisesti dataa nykyhetkeen verrattuna. Lohi kertoo, että suuria määriä laskentaresursseja tarvitaan niin tutkimuksessa käytettäviin työmenetelmiin kuin työkaluihin.
”Ennen sekvensoitiin pieniä pätkiä perimästä. Nyt perimälistat ovat niin pitkiä, että niiden manuaalinen hallinta on täysin mahdotonta. Jos tutkimuksen kohteena on 200 koiraa ja jokaiselta koiralta luetaan kokonainen perimä eli 39 kromosomiparia, kestää analysointi perinteisellä menetelmällä useita kuukausia. Yhdestä perimästä tulee satoja gigoja raakadataa.”
”Kun on siirrytty perinteisestä, Sanger-menetelmän sekvensoinnista uuden sukupolven eli koko perimän sekvensointiin (NGS), data analysoidaan valtavia määriä uusilla menetelmillä. Puhutaan kollauksesta, jossa perimä ensin pilkotaan palasiksi tietokantaan, sekvensoidaan ja kasataan. Perimää läpiluettaessa käsittelyyn tulee ihmisen osalta kolme miljardia ja koiran osalta 2,5 miljardia geeniparia sekä erilaisia variantteja ja insertioita, jotka monimutkaistavat sekvenssin tulkintaa,” Lohi kuvaa tutkimusdatan haasteita.
”Varianttien selvittämisen jälkeen tutkitaan, onko variantti patogeeninen. Tässäkin vaiheessa tarvitaan laskentaresursseja. Bioinformatiikan työkaluilla voidaan ennustaa, minkä aminohappomuutoksen
variantti aiheuttaa perimässä. Tämän jälkeen ryhdytään tutkimaan tarkemmin aminohappomuutoksen
vaikutuksia ja siirrytään käyttämään proteiinitason työkaluja ja erilaisia algoritmeja.”
Verkkokalvon rappeumaa aiheuttavan geenin tutkimusryhmä paikansi perhoskoirissa kuuden sairaan ja 14 verrokin avulla. Geenivirhe tunnistettiin eksomi-sekvensointiteknologialla, jossa analysoitiin kerralla koko proteiinia koodaavat alueet. Monet sairautta aiheuttavista mutaatioista sijaitsevat
eksomeissa, vaikkakin se on vain puolitoista prosenttia perimästä. Tämän teknologian avulla, jota käytetään erityisesti tietokannassa olevien tautimuotojen etsimiseen, selvitettiin mutaatio, jota lähes joka viides perhoskoira kantaa perimässään.
Lohen tutkimusryhmä osallistui pilottiorganisaationa tieteen tietotekniikan keskuksen CSC:n projektiin, jossa kartoitettiin, millaisia aineistoja tutkijoille syntyy mittavan laskentakapasiteetin ja
muistitilan myötä. Projektin tavoitteena oli pilotoida malleja ja ratkaisuja siihen, millaisia resursseja tutkijat tarvitsevat ELIXIR-tutkimusinfrastruktuurissa.
Tiina Autio
15.7. 2015
Lue artikkeli PDF-muodossa
Lisätietoja:
CSC – Tieteen tietotekniikan keskus Oy
on valtion omistama, opetus- ja kulttuuriministeriön hallinnoima, voittoa tavoittelematon osakeyhtiö. CSC ylläpitää ja kehittää valtion omistamaa keskitettyä tietotekniikkainfrastruktuuria.
ELIXIR
rakentaa infrastruktuurin bioalan tutkimuksen tueksi. Se yhdistää 21 Euroopan maan ja Euroopan molekyylibiologian laboratorion EMBL:n johtavat organisaatiot yhteiseksi biologisen informaation infrastruktuuriksi. Sen Suomen keskus on CSC – Tieteen tietotekniikan keskus Oy.

Tiede maksaa, ja laskun kuittaa yhteiskunta. Mutta mitä tapahtuu tutkimuksessa syntyvälle tietoaineistolle? Data on biotieteen pääomaa, joka kannattaa sijoittaa oikein.
Biotieteiden tutkimuksen data on noussut 2000-luvulla Euroopan tiedepolitiikan keskiöön. Kansainvälinen tutkimus käyttää ja tuottaa valtavasti dataa. Jatkuvasti laajenevan ja monimutkaistuvan biotieteellisen datan luottamuksellinen säilytys ja jatkokäyttö herättävät kysymyksiä. Miten ja mihin data kannattaa tallentaa? Miten dataa, esimerkiksi geenitietokantoja säilytetään turvallisesti? Miten dataa jaellaan? Näitä kysymyksiä ratkoo kansainvälinen hanke ELIXIR.
ELIXIR tarjoaa ratkaisuja siihen, miten tutkimuksen tietoaineistoa avataan tiedettä edistävällä tavalla ja ketkä aineistoihin pääsevät käsiksi. Suomi oli ELIXIR-hankkeen ydinjoukossa alusta lähtien vuodesta 2007. Datan säilytykseen ja jakeluun liittyvät yhteistyö on edellytys biotieteen kilpailukyvylle
pienissä eurooppalaisissa valtioissa. Pienten maiden kannattaa jakaa kerran tehtyjä aineistojaan, pikemminkin kuin tuottaa niitä eri tutkimusyliopistoissa yhä uudelleen. Biotieteellinen tutkimus tarvitsee vertailuaineistoja, ja ELIXIR on kanava jakaa niitä.
Jos esimerkiksi suomalainen tutkimusryhmä tutkii Parkinsonin taudin periytyvyyttä, sen on elintärkeää päästä käsiksi geeniaineistoihin, joita muun Euroopan tutkimuslaboratoriot tuottavat. Mekanismien löytäminen on vaativaa, ja tutkijat tarvitsevat vähintään vertailukohdan miten terveen
ihmisen genomi toimii. Kun voidaan käyttää eurooppalaisten tuottamia aineistoja, suomalaisten ei tarvitse rakentaa tutkimuksen näyteaineiston lisäksi vertailuaineistoa. Se olisikin äärettömän kallista, ja se lykkäisi tutkimustulosten syntymistä vuosikymmenen päähän.
Kansainvälisten geeniaineistojen käyttö suomalaisessa yliopistossa ei kuitenkaan käy aivan käden käänteessä. Samalla tavalla kuin ihmisten liikutteluun maiden välillä, tarvitaan datan liikutteluun infrastruktuureja ja maiden välisiä sopimuksia. Ulkomaisten tutkimusyliopistojen täytyy olla varma tietoaineistoja käyttävän identiteetistä. Biotieteelliseen dataan liittyy usein tietoturvaa, joka on säädetty laissa. Lisäksi maiden välillä täytyy olla tehokkaat tietoliikenneyhteydet, jonka kautta valtavat aineistomassat voivat siirtyä. Internetin avoin laajakaista ei riitä. Vastaanottajalla täytyy lisäksi olla käytössään tallennustilaa ja ohjelmistoja, jonka avulla se voi käsitellä aineistoa.
Tietoaineiston hallinnointi, säilytys ja jakelu eivät aina herätä samaa hehkua ja innostusta, kuin tieteen läpimurrot. Byrokraattinen kieli kuitenkin hämää. Hitaasti rakentuva verkosto mahdollistaa tieteelliset läpimurrot, mutta on myös itsessään tieteelliseen innovaation verrattavissa oleva hanke.
Kansainvälisen yhteistyön ja tietoaineiston jakamisen vastakohta on valtava voimavarojen tuhlaus, kun keskenään kilpailevat eurooppalaiset yliopistot tekevät samaa perustutkimusta. Lopputulos hyödyttäisi
merkittävästi heikommin yhteiskuntaa; jos kaikki keksisivät genomia uudelleen, tutkimus maksaisi enemmän ja se tuottaisi vähemmän. Eurooppalaiset tippuisivat ulos biotieteen ja –teollisuuden kansainvälisestä kilpailusta.
Suomea ELIXIRissä edustaa CSC – Tieteen tietotekniikan keskus yhteistyössä Helsingin yliopiston molekyylilääketieteen instituutin (FIMM) sekä Terveyden ja hyvinvoinnin laitoksen kanssa.
”ELIXIR on jo iso juttu Suomen biotieteille, ja tulevaisuudessa siitä tulee vielä isompi” kertoo Suomen ELIXIR-hankkeen johtaja Tommi Nyrönen CSC:sta.
”ELIXIRin kautta suomalaisella biolääketieteellä on pääsy valtaviin aineistoihin. Saamme tulevaisuudessa tarkempaa tietoa esimerkiksi suomalaiseen geeniperimän harvinaisista poikkeamista kun voimme verrata sitä kansainväliseen vertailuaineistoon. Näin voimme myös tehdä tarkempia hoitosuunnitelmia.”
ELIXIRin johtotähti on, että tutkimuksen tietoaineistot ovat tieteen pääomaa. Aineistojen luotettava säilytys ja jakelu ovat edellytys tieteen tuottavuudelle. Infrastruktuurin rakentaminen ja ylläpito maksavat vain murto-osan verrattuna itse tutkimuksen kustannuksiin. Ja sen tuomat tieteelliset tuotot – niistä hyötyy Nyrösen mukaan sama taho joka tiedettä rahoittaa; yhteiskunta.
”Kun eurooppalaiset geenitutkijat saavat käyttää ristiin toistensa aineistoja, syntyy tarkempaa tietoa sairauden ja terveyden mekanismeista. Tieteelliset tulokset kiertävät yhteistyössä myös nopeammin hoitoihin,” kertoo Tommi Nyrönen.
Suomalaisen rauduskoivun perimän avaaminen voi hyödyttää esimerkiksi englantilaisen koivuruttoepidemian taltuttamisessa. Vertailun avulla voidaan tunnistaa vaikkapa miksi englantilaisten koivujen puolustusmekanismit toimivat heikommin kuin rauduskoivun vastaavat. Tamperelaisen lapsen vakava sairaus saa tarkemman luonteen geenikartoituksen ja vertailevan aineiston yhdistelmästä. Kun virhegeeni on tiedossa, voi hoitosuunnittelu alkaa. Eurooppalaiset viininviejämaat voivat tutkia yhteistyössä viinirypäleen tautien genetiikkaa ja saada jalostuksen kautta kilpailuetuja suhteessa muun maailman viinituottajiin.
ELIXIR hyödyttää myös yrityksiä. Hanke on jakanut esimerkiksi koiran perimän, minkä pohjalta Helsingin yliopiston tutkijat ovat kehittäneet kaupallisen sovelluksen. Sen avulla koirankasvattajat voivat seuloa siitoskoiristaan kaikkein terveimmät ja jalostaa vain niitä, jotka eivät kanna esimerkiksi
nivelsairauksien tautigeenejä.
Vaikka ELIXIR liputtaa yhteistyön, jakamisen ja avoimuuden puolesta, on tietoaineistojen avoimuus kuitenkin rajattua. Osa aineistosta on julkista, osa ei. Joka tapauksessa mistään www:n avoimuudesta ei ole kyse. ELIXIR tasapainottelee korkean tietoturvan ja avoimuuden välillä. Verkoston arkaluonteisimmat tietoaineistot ovat auki niille, joilla on oikeus tutkimuskäyttöön. Tutkijoiden tunnistamiseen ja ’’kulkulupien’’ myöntämiseen on luotu omat käytännöt ELIXIR-maiden välille.
Suomalaiset tutkijat käyttävät ELIXIRin resursseja CSC:n pilvipalvelun kautta. Palvelu on rakennettu niin, että tutkijan on helppo käyttää sitä. ELIXIRin käyttö on ’’epäteknistä’’. Toimivan ja aineettoman palvelun takana on kuitenkin valtavasti rautaa ja valokaapelia. Laitetasolla tarkasteltuna Suomen ELIXIR tarkoittaa CSC:n Kajaanin ja Keilarannan tietokonekeskuksia. Ne ovat yhteydessä suuritehoisen ja yksityisen laajakaistan – tai valopolun – kautta suoraan Cambridgeen, ELIXIRin päämajaan. Valopolun voi mieltää ELIXIR- palvelukeskuksien fyysiseksi napanuoraksi: se mahdollistaa massiivisten aineistojen jakamisen ELIXIR-maiden välillä.
Biotieteellisten aineistojen koosta viitteitä antaa se, että yksityisen ja äärettömän tehokkaan valopolun sisällä aineistojen siirtäminen maasta toiseen voi kestää kuukausia. Mutta pelkällä raudalla ja valokaapelilla ei ELIXIRiä ole rakennettu.
’’Se on vaatinut myös teetä ja keksejä’’ huomauttaa Tommi Nyrönen viitaten lukemattomiin neuvotteluihin ja kokouksiin, joita 16 maata on järjestänyt yhteisten sopimusten ja käytäntöjen eteen. Teen ja keksin määrä lasketaan sadoissa kiloissa ja litroissa!
Onko ELIXIR valmis? Vastaus on sama kuin kysyttäessä milloin tiede on valmis. Eri maat osallistuvat Nyrösen mukaan ELIXIRin rakennukseen eri panoksin
”ELIXIR on startannut myös eri puolilla Eurooppaa eri aikoihin. Joissain maissa on valmiimpaa kuin toisissa. Suomi on ollut ensimmäisten joukossa,” kertoo Nyrönen.
Suomi on muiden Pohjoismaiden tavoin ELIXIRin pioneerimaita. Mailla on hyvä maine ja asema kansainvälisessä ELIXIRissä. Maat ovat toimineet ELIXIRin ensimmäisten vaiheiden testilaboratoriona, ja niiden käyttökokemukset antavat askelmerkkejä miten palvelua Euroopassa kannattaa rakentaa.
Euroopassa ELIXIRin rakennustyö jatkuu. Suomessa seuraava askel on jatkaa Kajaania, Keilaniemeä ja Cambridgea yhdistävä valopolku Helsingin yliopiston Viikin kampukselle sekä Turun ja Oulun biokeskuksiin. Suomalaiset tutkijat ovat ottaneet ELIXIRin vastaan innostuneena. Toteutuneiden hankkeiden asiakastyytyväisyys on ollut huippuluokkaa.
”Suomalaiset tekevät hyvää työtä sekä biotieteellisen tutkimuksen että infrastruktuurin puolella. Mikä tärkeintä, keskusteluyhteys näiden välillä toimii. Tarvitsemme lisää valokaapelia ja keksejä. Tästä on hyvä jatkaa,” summaa Nyrönen.
Elina Kuorelahti
5.6.2015
Lue artikkeli PDF-muodossa
Sitaatti
Elina Kuorelahti, & Tommi Nyrönen. (2015). Life science in European cloud. https://doi.org/10.5281/zenodo.8176710


 ELIXIR is partly funded by the European Commission
ELIXIR is partly funded by the European Commission{kind=link}